 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
POS-BERT: Point Cloud One-Stage BERT Pre-Training
Apr 03, 2022
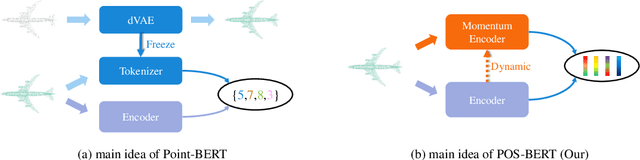
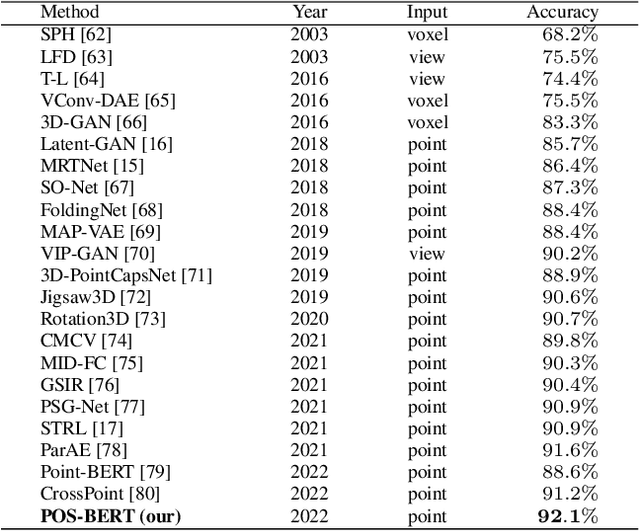
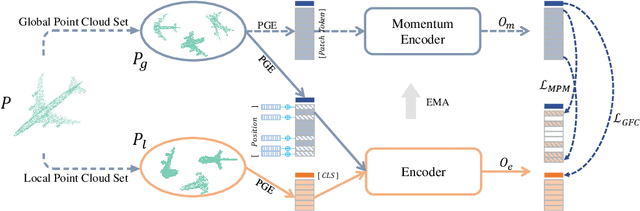
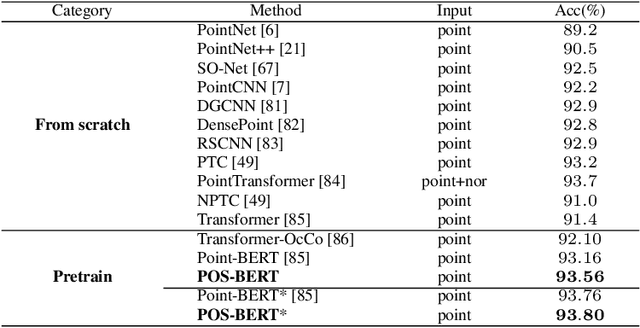
Recently, the pre-training paradigm combining Transformer and masked language modeling has achieved tremendous success in NLP, images, and point clouds, such as BERT. However, directly extending BERT from NLP to point clouds requires training a fixed discrete Variational AutoEncoder (dVAE) before pre-training, which results in a complex two-stage method called Point-BERT. Inspired by BERT and MoCo, we propose POS-BERT, a one-stage BERT pre-training method for point clouds. Specifically, we use the mask patch modeling (MPM) task to perform point cloud pre-training, which aims to recover masked patches information under the supervision of the corresponding tokenizer output. Unlike Point-BERT, its tokenizer is extra-trained and frozen. We propose to use the dynamically updated momentum encoder as the tokenizer, which is updated and outputs the dynamic supervision signal along with the training process. Further, in order to learn high-level semantic representation, we combine contrastive learning to maximize the class token consistency between different transformation point clouds. Extensive experiments have demonstrated that POS-BERT can extract high-quality pre-training features and promote downstream tasks to improve performance. Using the pre-training model without any fine-tuning to extract features and train linear SVM on ModelNet40, POS-BERT achieves the state-of-the-art classification accuracy, which exceeds Point-BERT by 3.5\%. In addition, our approach has significantly improved many downstream tasks, such as fine-tuned classification, few-shot classification, part segmentation. The code and trained-models will be available at: \url{https://github.com/fukexue/POS-BERT}.
Enriching Word Embeddings with Temporal and Spatial Information
Oct 02, 2020
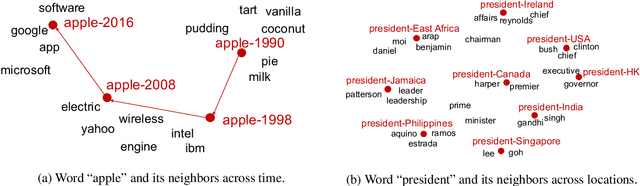
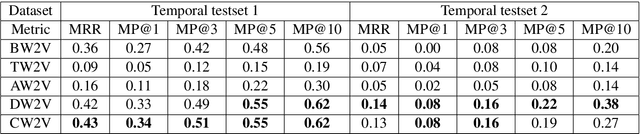
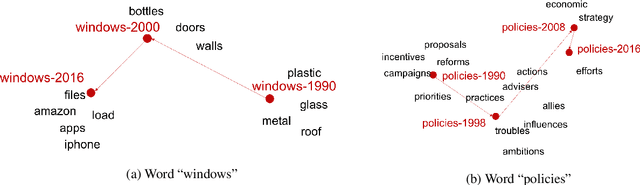
The meaning of a word is closely linked to sociocultural factors that can change over time and location, resulting in corresponding meaning changes. Taking a global view of words and their meanings in a widely used language, such as English, may require us to capture more refined semantics for use in time-specific or location-aware situations, such as the study of cultural trends or language use. However, popular vector representations for words do not adequately include temporal or spatial information. In this work, we present a model for learning word representation conditioned on time and location. In addition to capturing meaning changes over time and location, we require that the resulting word embeddings retain salient semantic and geometric properties. We train our model on time- and location-stamped corpora, and show using both quantitative and qualitative evaluations that it can capture semantics across time and locations. We note that our model compares favorably with the state-of-the-art for time-specific embedding, and serves as a new benchmark for location-specific embeddings.
Uplink-Downlink Duality and Precoding Strategies with Partial CSI in Cell-Free Wireless Networks
Jan 17, 2022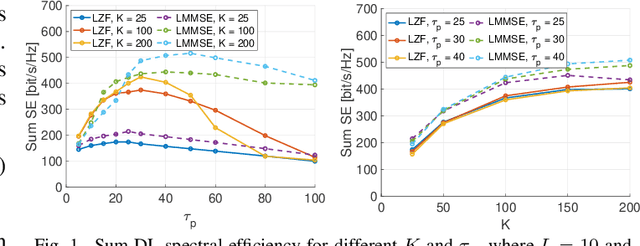
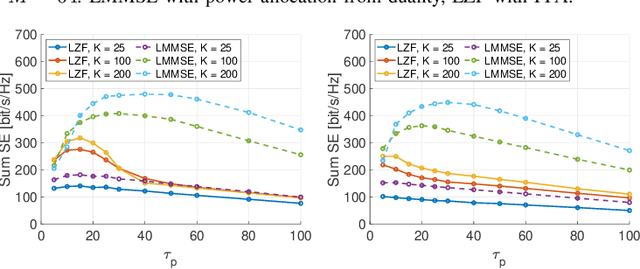
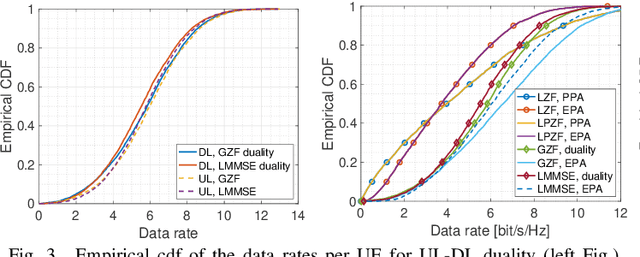
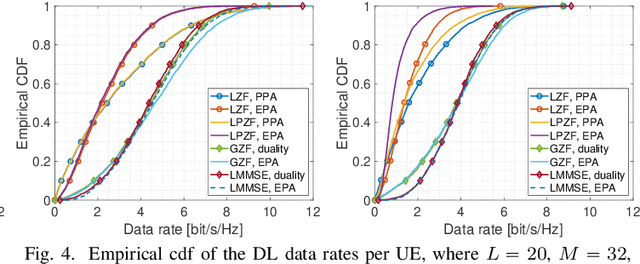
We consider a scalable user-centric wireless network with dynamic cluster formation as defined by Bj\"ornsson and Sanguinetti. After having shown the importance of dominant channel subspace information for uplink (UL) pilot decontamination and having examined different UL combining schemes in our previous work, here we investigate precoding strategies for the downlink (DL). Distributed scalable DL precoding and power allocation methods are evaluated for different antenna distributions, user densities and UL pilot dimensions. We compare distributed power allocation methods to a scheme based on a particular form of UL-DL duality which is computable by a central processor based on the available partial channel state information. The new duality method achieves almost symmetric "optimistic ergodic rates" for UL and DL while saving considerable computational complexity since the UL combining vectors are reused as DL precoders.
Real-time information retrieval from Identity cards
Mar 26, 2020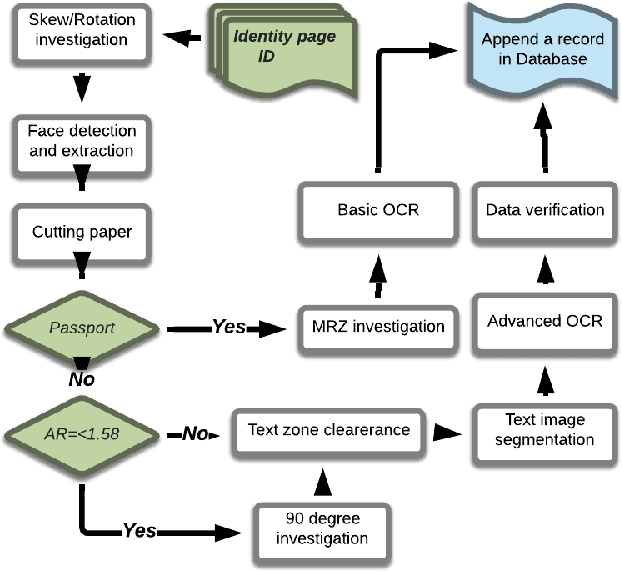



Information is frequently retrieved from valid personal ID cards by the authorised organisation to address different purposes. The successful information retrieval (IR) depends on the accuracy and timing process. A process which necessitates a long time to respond is frustrating for both sides in the exchange of data. This paper aims to propose a series of state-of-the-art methods for the journey of an Identification card (ID) from the scanning or capture phase to the point before Optical character recognition (OCR). The key factors for this proposal are the accuracy and speed of the process during the journey. The experimental results of this research prove that utilising the methods based on deep learning, such as Efficient and Accurate Scene Text (EAST) detector and Deep Neural Network (DNN) for face detection, instead of traditional methods increase the efficiency considerably.
LTSP: Long-Term Slice Propagation for Accurate Airway Segmentation
Feb 13, 2022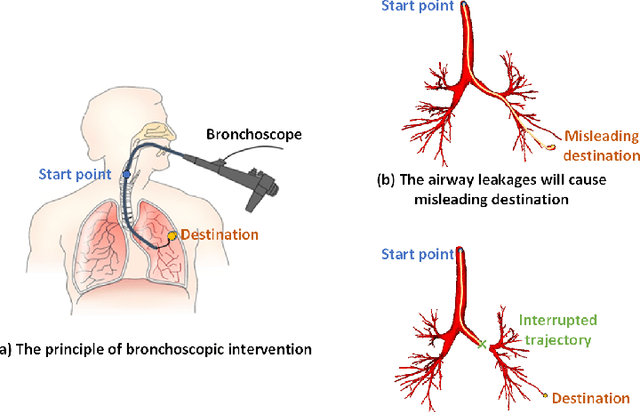
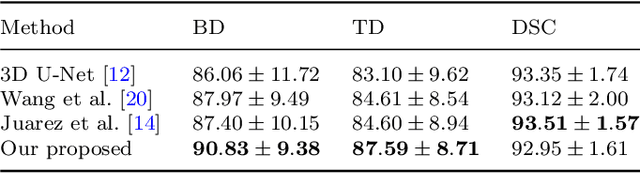
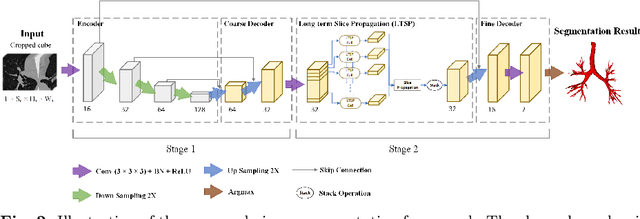
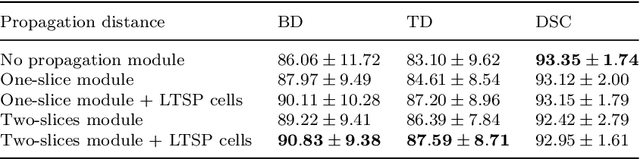
Purpose: Bronchoscopic intervention is a widely-used clinical technique for pulmonary diseases, which requires an accurate and topological complete airway map for its localization and guidance. The airway map could be extracted from chest computed tomography (CT) scans automatically by airway segmentation methods. Due to the complex tree-like structure of the airway, preserving its topology completeness while maintaining the segmentation accuracy is a challenging task. Methods: In this paper, a long-term slice propagation (LTSP) method is proposed for accurate airway segmentation from pathological CT scans. We also design a two-stage end-to-end segmentation framework utilizing the LTSP method in the decoding process. Stage 1 is used to generate a coarse feature map by an encoder-decoder architecture. Stage 2 is to adopt the proposed LTSP method for exploiting the continuity information and enhancing the weak airway features in the coarse feature map. The final segmentation result is predicted from the refined feature map. Results: Extensive experiments were conducted to evaluate the performance of the proposed method on 70 clinical CT scans. The results demonstrate the considerable improvements of the proposed method compared to some state-of-the-art methods as most breakages are eliminated and more tiny bronchi are detected. The ablation studies further confirm the effectiveness of the constituents of the proposed method. Conclusion: Slice continuity information is beneficial to accurate airway segmentation. Furthermore, by propagating the long-term slice feature, the airway topology connectivity is preserved with overall segmentation accuracy maintained.
Cartoon-texture evolution for two-region image segmentation
Mar 07, 2022
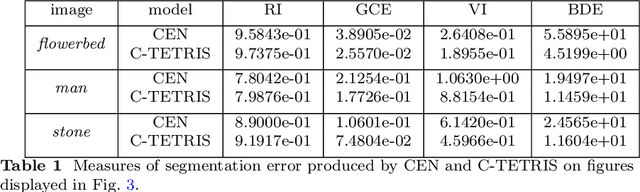
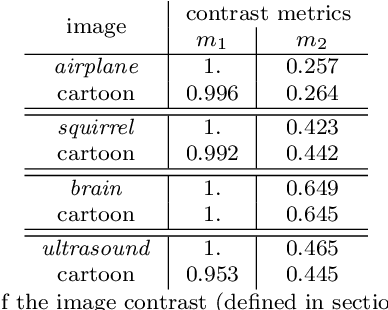

Two-region image segmentation is the process of dividing an image into two regions of interest, i.e., the foreground and the background. To this aim, Chan et al. [Chan, Esedo\=glu, Nikolova, SIAM Journal on Applied Mathematics 66(5), 1632-1648, 2006] designed a model well suited for smooth images. One drawback of this model is that it may produce a bad segmentation when the image contains oscillatory components. Based on a cartoon-texture decomposition of the image to be segmented, we propose a new model that is able to produce an accurate segmentation of images also containing noise or oscillatory information like texture. The novel model leads to a non-smooth constrained optimization problem which we solve by means of the ADMM method. The convergence of the numerical scheme is also proved. Several experiments on smooth, noisy, and textural images show the effectiveness of the proposed model.
MT-Clinical BERT: Scaling Clinical Information Extraction with Multitask Learning
Apr 21, 2020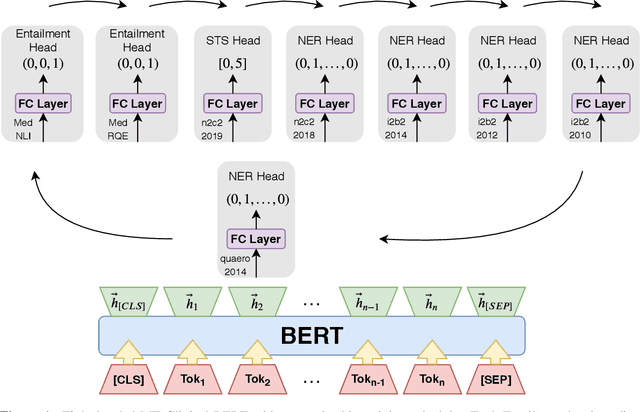
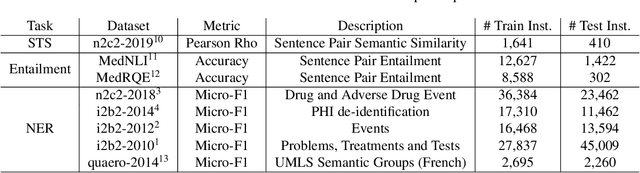
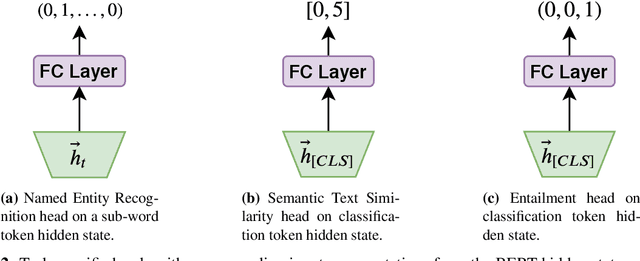
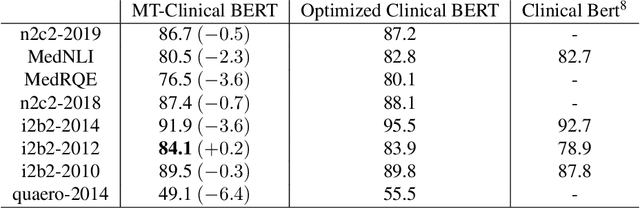
Clinical notes contain an abundance of important but not-readily accessible information about patients. Systems to automatically extract this information rely on large amounts of training data for which their exists limited resources to create. Furthermore, they are developed dis-jointly; meaning that no information can be shared amongst task-specific systems. This bottle-neck unnecessarily complicates practical application, reduces the performance capabilities of each individual solution and associates the engineering debt of managing multiple information extraction systems. We address these challenges by developing Multitask-Clinical BERT: a single deep learning model that simultaneously performs eight clinical tasks spanning entity extraction, PHI identification, language entailment and similarity by sharing representations amongst tasks. We find our single system performs competitively with all state-the-art task-specific systems while also benefiting from massive computational benefits at inference.
Enhancing Cancer Prediction in Challenging Screen-Detected Incident Lung Nodules Using Time-Series Deep Learning
Mar 30, 2022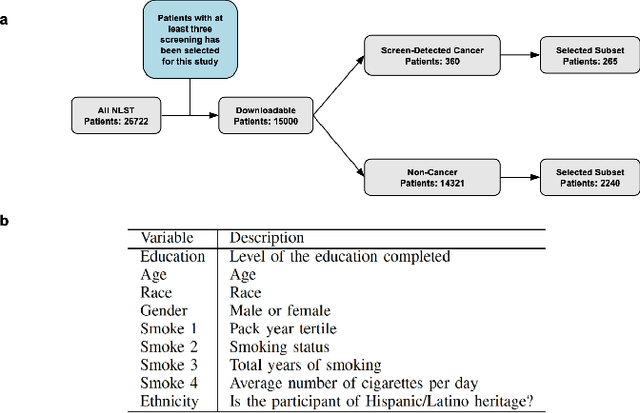
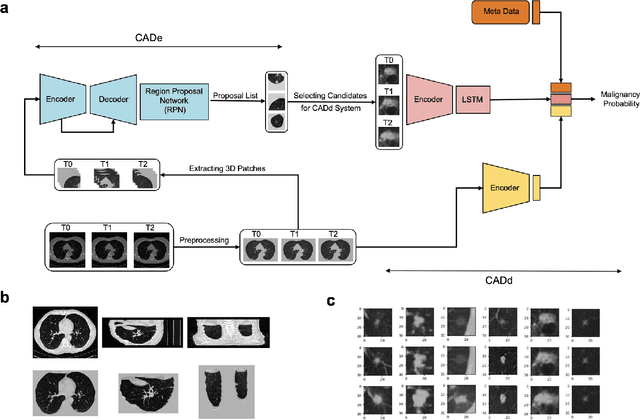
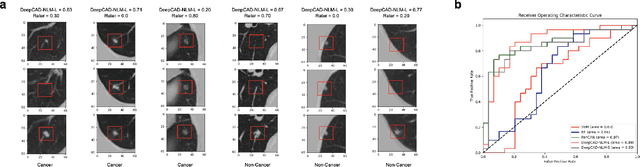

Lung cancer is the leading cause of cancer-related mortality worldwide. Lung cancer screening (LCS) using annual low-dose computed tomography (CT) scanning has been proven to significantly reduce lung cancer mortality by detecting cancerous lung nodules at an earlier stage. Improving risk stratification of malignancy risk in lung nodules can be enhanced using machine/deep learning algorithms. However most existing algorithms: a) have primarily assessed single time-point CT data alone thereby failing to utilize the inherent advantages contained within longitudinal imaging datasets; b) have not integrated into computer models pertinent clinical data that might inform risk prediction; c) have not assessed algorithm performance on the spectrum of nodules that are most challenging for radiologists to interpret and where assistance from analytic tools would be most beneficial. Here we show the performance of our time-series deep learning model (DeepCAD-NLM-L) which integrates multi-model information across three longitudinal data domains: nodule-specific, lung-specific, and clinical demographic data. We compared our time-series deep learning model to a) radiologist performance on CTs from the National Lung Screening Trial enriched with the most challenging nodules for diagnosis; b) a nodule management algorithm from a North London LCS study (SUMMIT). Our model demonstrated comparable and complementary performance to radiologists when interpreting challenging lung nodules and showed improved performance (AUC=88\%) against models utilizing single time-point data only. The results emphasise the importance of time-series, multi-modal analysis when interpreting malignancy risk in LCS.
Fundamental Performance Limits for Sensor-Based Robot Control and Policy Learning
Jan 31, 2022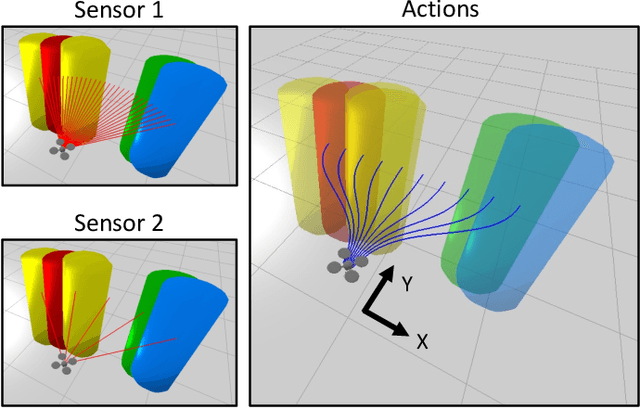
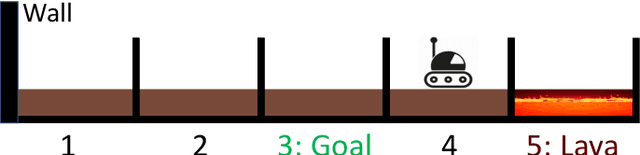
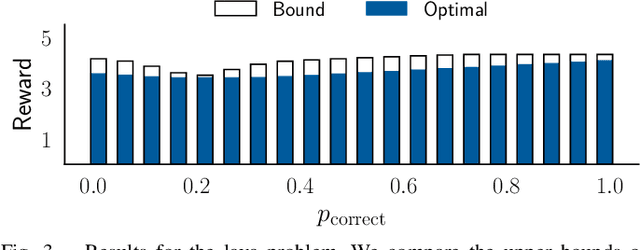
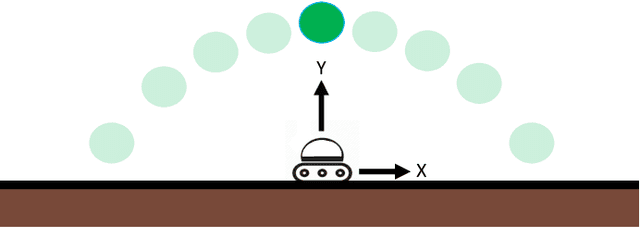
Our goal is to develop theory and algorithms for establishing fundamental limits on performance for a given task imposed by a robot's sensors. In order to achieve this, we define a quantity that captures the amount of task-relevant information provided by a sensor. Using a novel version of the generalized Fano inequality from information theory, we demonstrate that this quantity provides an upper bound on the highest achievable expected reward for one-step decision making tasks. We then extend this bound to multi-step problems via a dynamic programming approach. We present algorithms for numerically computing the resulting bounds, and demonstrate our approach on three examples: (i) the lava problem from the literature on partially observable Markov decision processes, (ii) an example with continuous state and observation spaces corresponding to a robot catching a freely-falling object, and (iii) obstacle avoidance using a depth sensor with non-Gaussian noise. We demonstrate the ability of our approach to establish strong limits on achievable performance for these problems by comparing our upper bounds with achievable lower bounds (computed by synthesizing or learning concrete control policies).
Learning Discrete Structured Representations by Adversarially Maximizing Mutual Information
Apr 08, 2020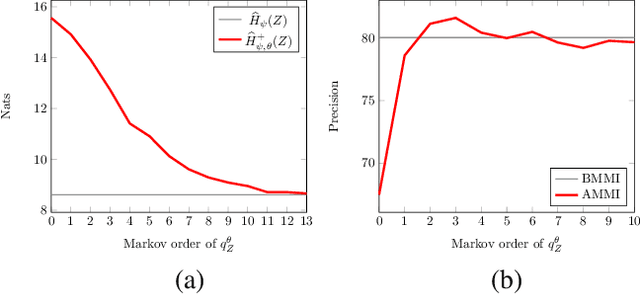
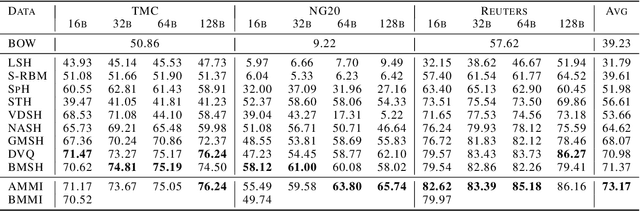

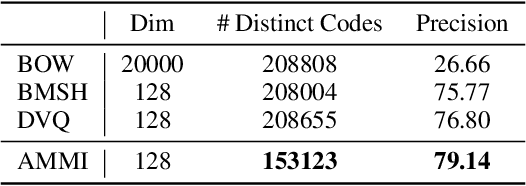
We propose learning discrete structured representations from unlabeled data by maximizing the mutual information between a structured latent variable and a target variable. Calculating mutual information is intractable in this setting. Our key technical contribution is an adversarial objective that can be used to tractably estimate mutual information assuming only the feasibility of cross entropy calculation. We develop a concrete realization of this general formulation with Markov distributions over binary encodings. We report critical and unexpected findings on practical aspects of the objective such as the choice of variational priors. We apply our model on document hashing and show that it outperforms current best baselines based on discrete and vector quantized variational autoencoders. It also yields highly compressed interpretable representations.