 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An iterative clustering algorithm for the Contextual Stochastic Block Model with optimality guarantees
Dec 20, 2021
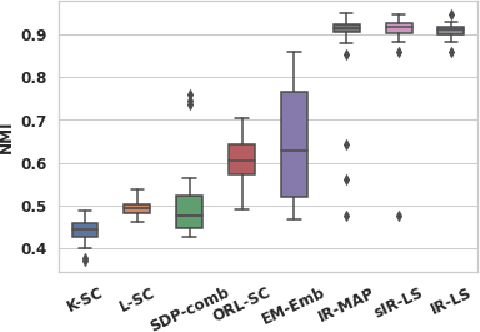

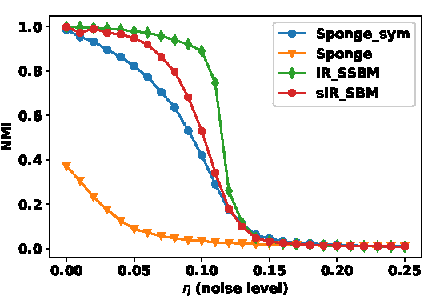
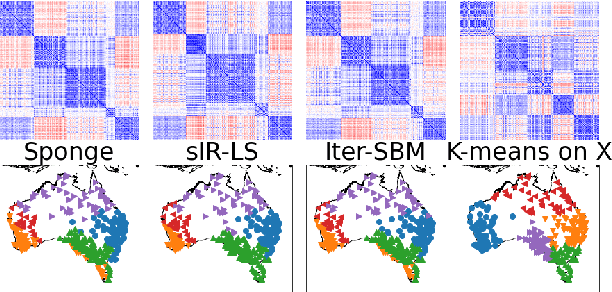
Real-world networks often come with side information that can help to improve the performance of network analysis tasks such as clustering. Despite a large number of empirical and theoretical studies conducted on network clustering methods during the past decade, the added value of side information and the methods used to incorporate it optimally in clustering algorithms are relatively less understood. We propose a new iterative algorithm to cluster networks with side information for nodes (in the form of covariates) and show that our algorithm is optimal under the Contextual Symmetric Stochastic Block Model. Our algorithm can be applied to general Contextual Stochastic Block Models and avoids hyperparameter tuning in contrast to previously proposed methods. We confirm our theoretical results on synthetic data experiments where our algorithm significantly outperforms other methods, and show that it can also be applied to signed graphs. Finally we demonstrate the practical interest of our method on real data.
Self-supervised HDR Imaging from Motion and Exposure Cues
Mar 23, 2022
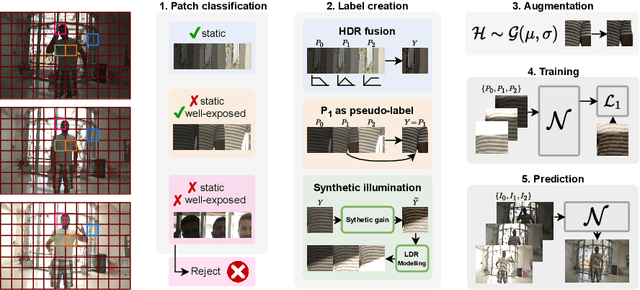
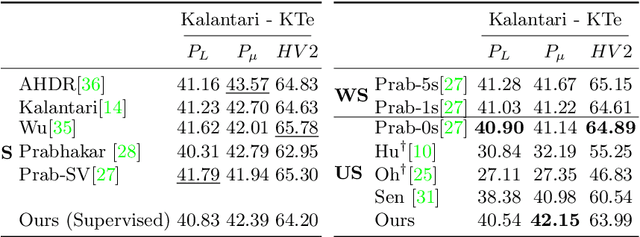
Recent High Dynamic Range (HDR) techniques extend the capabilities of current cameras where scenes with a wide range of illumination can not be accurately captured with a single low-dynamic-range (LDR) image. This is generally accomplished by capturing several LDR images with varying exposure values whose information is then incorporated into a merged HDR image. While such approaches work well for static scenes, dynamic scenes pose several challenges, mostly related to the difficulty of finding reliable pixel correspondences. Data-driven approaches tackle the problem by learning an end-to-end mapping with paired LDR-HDR training data, but in practice generating such HDR ground-truth labels for dynamic scenes is time-consuming and requires complex procedures that assume control of certain dynamic elements of the scene (e.g. actor pose) and repeatable lighting conditions (stop-motion capturing). In this work, we propose a novel self-supervised approach for learnable HDR estimation that alleviates the need for HDR ground-truth labels. We propose to leverage the internal statistics of LDR images to create HDR pseudo-labels. We separately exploit static and well-exposed parts of the input images, which in conjunction with synthetic illumination clipping and motion augmentation provide high quality training examples. Experimental results show that the HDR models trained using our proposed self-supervision approach achieve performance competitive with those trained under full supervision, and are to a large extent superior to previous methods that equally do not require any supervision.
NavDreams: Towards Camera-Only RL Navigation Among Humans
Mar 23, 2022
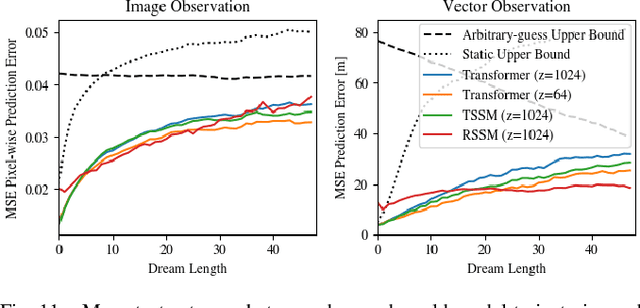
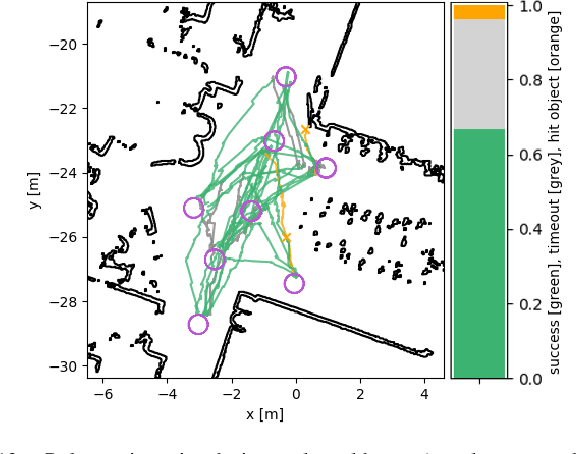
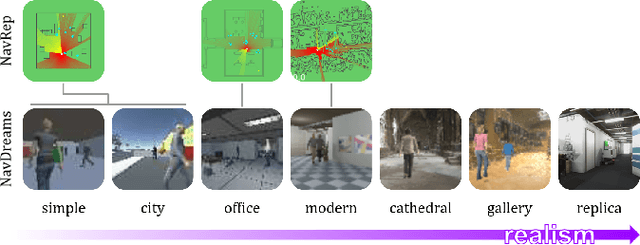
Autonomously navigating a robot in everyday crowded spaces requires solving complex perception and planning challenges. When using only monocular image sensor data as input, classical two-dimensional planning approaches cannot be used. While images present a significant challenge when it comes to perception and planning, they also allow capturing potentially important details, such as complex geometry, body movement, and other visual cues. In order to successfully solve the navigation task from only images, algorithms must be able to model the scene and its dynamics using only this channel of information. We investigate whether the world model concept, which has shown state-of-the-art results for modeling and learning policies in Atari games as well as promising results in 2D LiDAR-based crowd navigation, can also be applied to the camera-based navigation problem. To this end, we create simulated environments where a robot must navigate past static and moving humans without colliding in order to reach its goal. We find that state-of-the-art methods are able to achieve success in solving the navigation problem, and can generate dream-like predictions of future image-sequences which show consistent geometry and moving persons. We are also able to show that policy performance in our high-fidelity sim2real simulation scenario transfers to the real world by testing the policy on a real robot. We make our simulator, models and experiments available at https://github.com/danieldugas/NavDreams.
PillarGrid: Deep Learning-based Cooperative Perception for 3D Object Detection from Onboard-Roadside LiDAR
Mar 12, 2022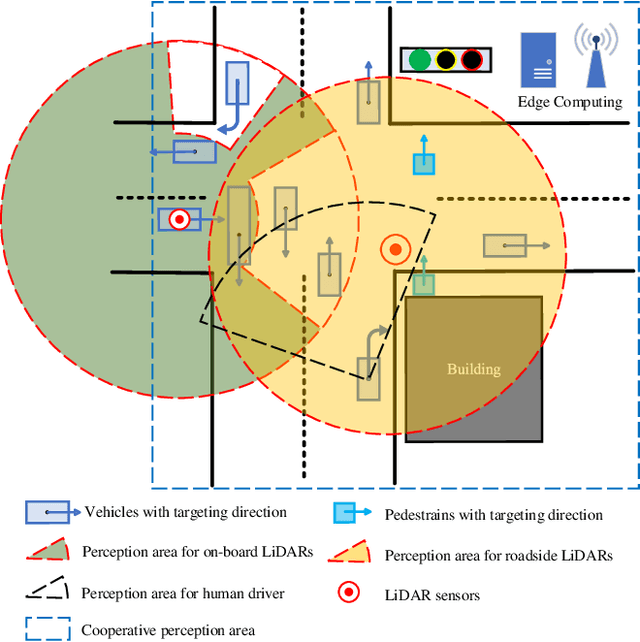
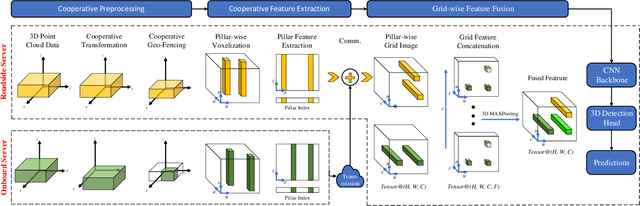
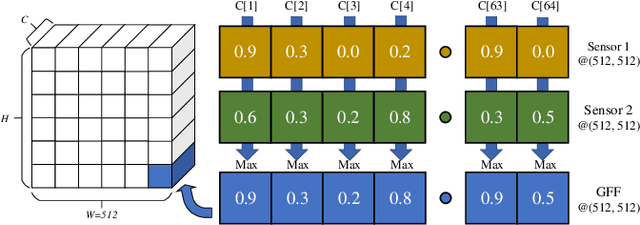
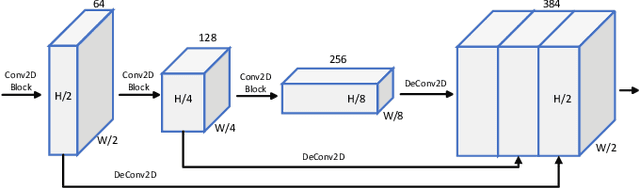
3D object detection plays a fundamental role in enabling autonomous driving, which is regarded as the significant key to unlocking the bottleneck of contemporary transportation systems from the perspectives of safety, mobility, and sustainability. Most of the state-of-the-art (SOTA) object detection methods from point clouds are developed based on a single onboard LiDAR, whose performance will be inevitably limited by the range and occlusion, especially in dense traffic scenarios. In this paper, we propose \textit{PillarGrid}, a novel cooperative perception method fusing information from multiple 3D LiDARs (both on-board and roadside), to enhance the situation awareness for connected and automated vehicles (CAVs). PillarGrid consists of four main phases: 1) cooperative preprocessing of point clouds, 2) pillar-wise voxelization and feature extraction, 3) grid-wise deep fusion of features from multiple sensors, and 4) convolutional neural network (CNN)-based augmented 3D object detection. A novel cooperative perception platform is developed for model training and testing. Extensive experimentation shows that PillarGrid outperforms the SOTA single-LiDAR-based 3D object detection methods with respect to both accuracy and range by a large margin.
Do You Do Yoga? Understanding Twitter Users' Types and Motivations using Social and Textual Information
Jan 27, 2021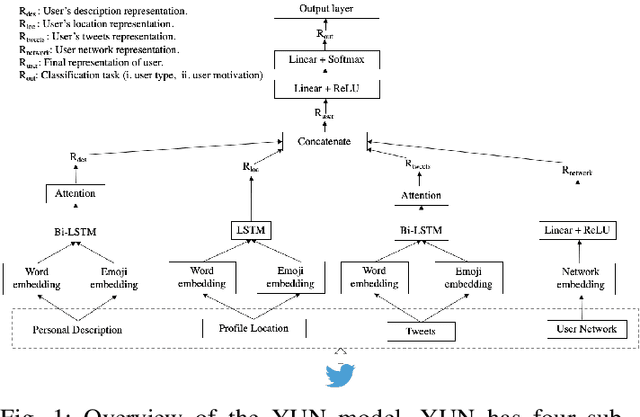
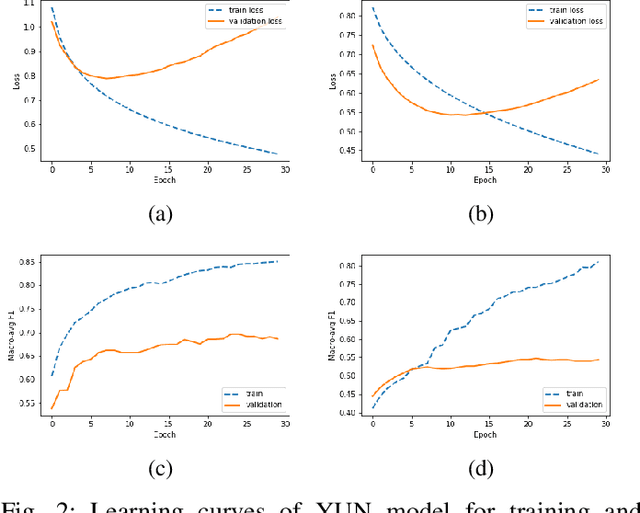
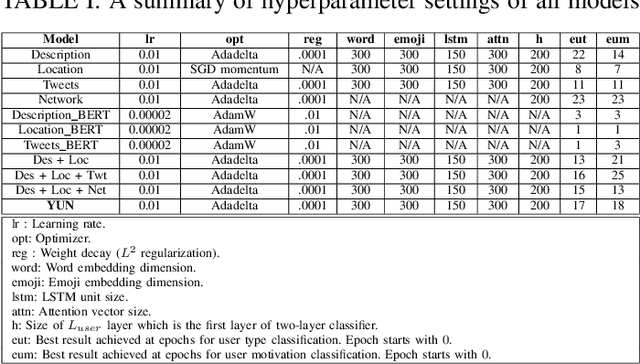
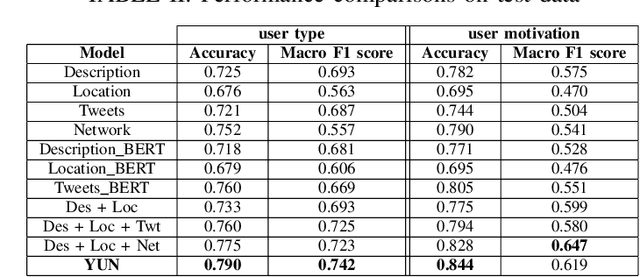
Leveraging social media data to understand people's lifestyle choices is an exciting domain to explore but requires a multiview formulation of the data. In this paper, we propose a joint embedding model based on the fusion of neural networks with attention mechanism by incorporating social and textual information of users to understand their activities and motivations. We use well-being related tweets from Twitter, focusing on 'Yoga'. We demonstrate our model on two downstream tasks: (i) finding user type such as either practitioner or promotional (promoting yoga studio/gym), other; (ii) finding user motivation i.e. health benefit, spirituality, love to tweet/retweet about yoga but do not practice yoga.
TAE: A Semi-supervised Controllable Behavior-aware Trajectory Generator and Predictor
Mar 02, 2022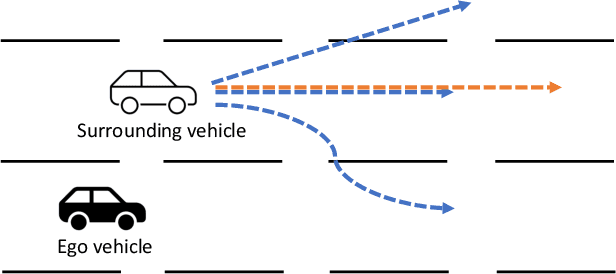
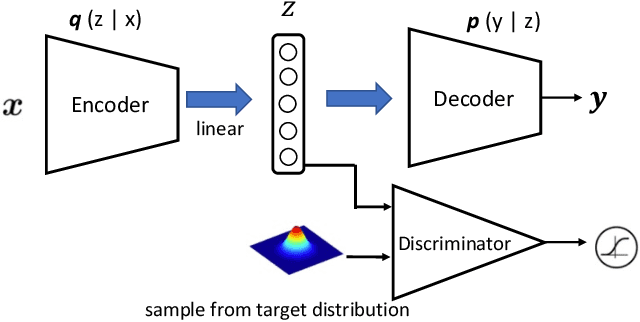
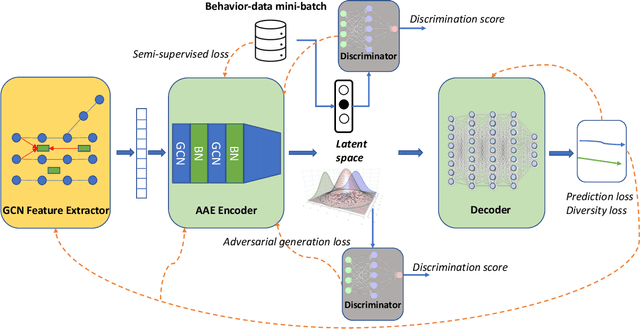
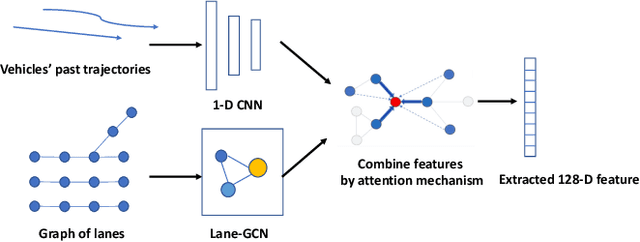
Trajectory generation and prediction are two interwoven tasks that play important roles in planner evaluation and decision making for intelligent vehicles. Most existing methods focus on one of the two and are optimized to directly output the final generated/predicted trajectories, which only contain limited information for critical scenario augmentation and safe planning. In this work, we propose a novel behavior-aware Trajectory Autoencoder (TAE) that explicitly models drivers' behavior such as aggressiveness and intention in the latent space, using semi-supervised adversarial autoencoder and domain knowledge in transportation. Our model addresses trajectory generation and prediction in a unified architecture and benefits both tasks: the model can generate diverse, controllable and realistic trajectories to enhance planner optimization in safety-critical and long-tailed scenarios, and it can provide prediction of critical behavior in addition to the final trajectories for decision making. Experimental results demonstrate that our method achieves promising performance on both trajectory generation and prediction.
Knowledge Extraction in Low-Resource Scenarios: Survey and Perspective
Feb 16, 2022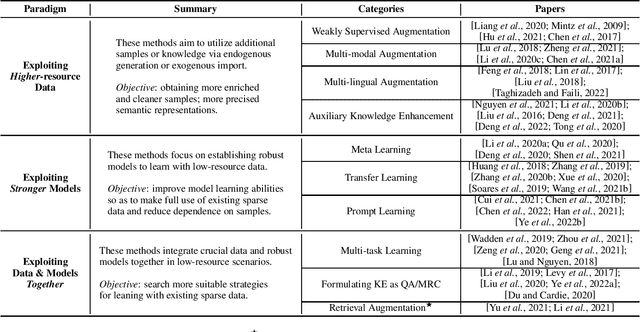
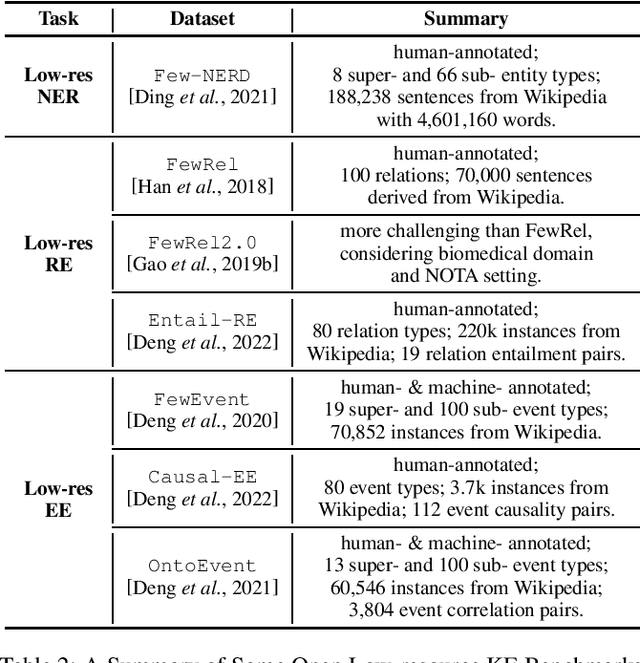
Knowledge Extraction (KE) which aims to extract structural information from unstructured texts often suffers from data scarcity and emerging unseen types, i.e., low-resource scenarios. Many neural approaches on low-resource KE have been widely investigated and achieved impressive performance. In this paper, we present a literature review towards KE in low-resource scenarios, and systematically categorize existing works into three paradigms: (1) exploiting higher-resource data, (2) exploiting stronger models, and (3) exploiting data and models together. In addition, we describe promising applications and outline some potential directions for future research. We hope that our survey can help both the academic and industrial community to better understand this field, inspire more ideas and boost broader applications.
Interpretable Prediction of Lung Squamous Cell Carcinoma Recurrence With Self-supervised Learning
Mar 23, 2022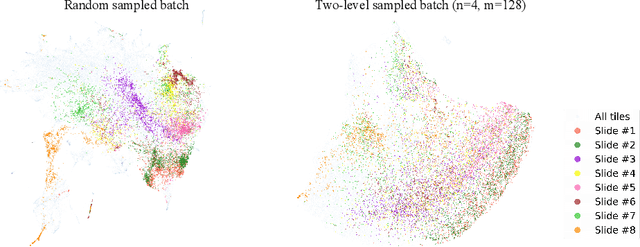
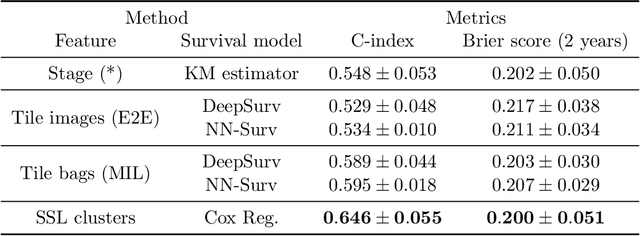
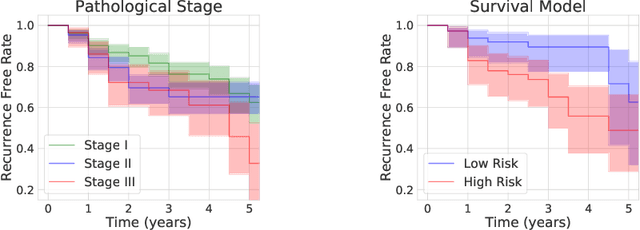

Lung squamous cell carcinoma (LSCC) has a high recurrence and metastasis rate. Factors influencing recurrence and metastasis are currently unknown and there are no distinct histopathological or morphological features indicating the risks of recurrence and metastasis in LSCC. Our study focuses on the recurrence prediction of LSCC based on H&E-stained histopathological whole-slide images (WSI). Due to the small size of LSCC cohorts in terms of patients with available recurrence information, standard end-to-end learning with various convolutional neural networks for this task tends to overfit. Also, the predictions made by these models are hard to interpret. Histopathology WSIs are typically very large and are therefore processed as a set of smaller tiles. In this work, we propose a novel conditional self-supervised learning (SSL) method to learn representations of WSI at the tile level first, and leverage clustering algorithms to identify the tiles with similar histopathological representations. The resulting representations and clusters from self-supervision are used as features of a survival model for recurrence prediction at the patient level. Using two publicly available datasets from TCGA and CPTAC, we show that our LSCC recurrence prediction survival model outperforms both LSCC pathological stage-based approach and machine learning baselines such as multiple instance learning. The proposed method also enables us to explain the recurrence histopathological risk factors via the derived clusters. This can help pathologists derive new hypotheses regarding morphological features associated with LSCC recurrence.
VRT: A Video Restoration Transformer
Jan 28, 2022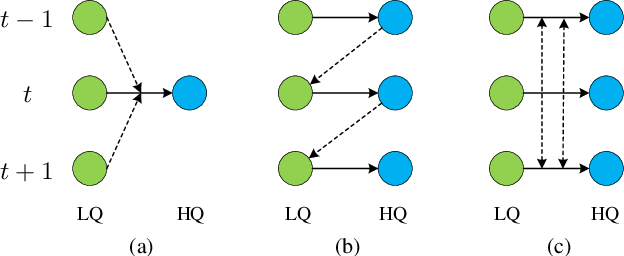
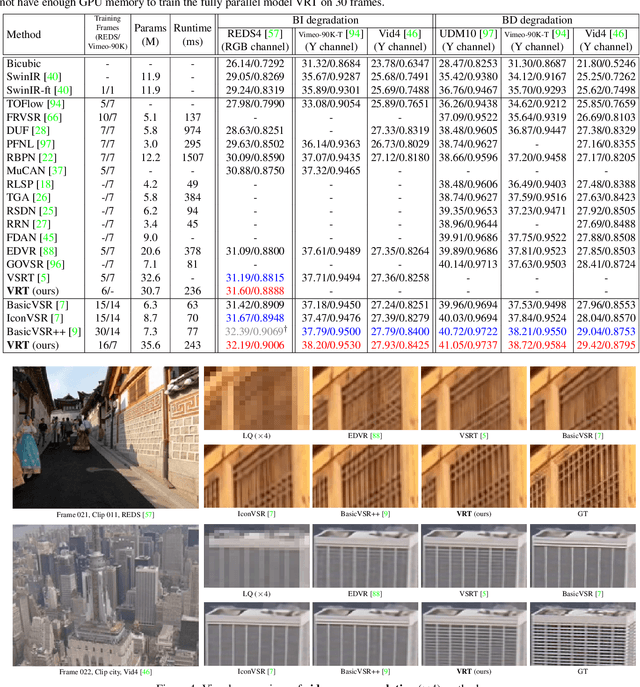
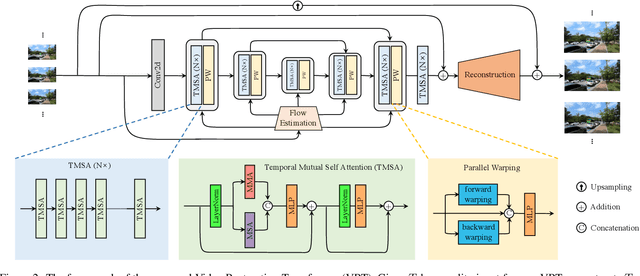
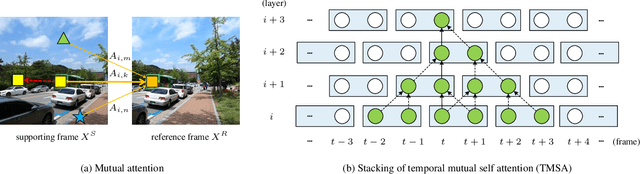
Video restoration (e.g., video super-resolution) aims to restore high-quality frames from low-quality frames. Different from single image restoration, video restoration generally requires to utilize temporal information from multiple adjacent but usually misaligned video frames. Existing deep methods generally tackle with this by exploiting a sliding window strategy or a recurrent architecture, which either is restricted by frame-by-frame restoration or lacks long-range modelling ability. In this paper, we propose a Video Restoration Transformer (VRT) with parallel frame prediction and long-range temporal dependency modelling abilities. More specifically, VRT is composed of multiple scales, each of which consists of two kinds of modules: temporal mutual self attention (TMSA) and parallel warping. TMSA divides the video into small clips, on which mutual attention is applied for joint motion estimation, feature alignment and feature fusion, while self attention is used for feature extraction. To enable cross-clip interactions, the video sequence is shifted for every other layer. Besides, parallel warping is used to further fuse information from neighboring frames by parallel feature warping. Experimental results on three tasks, including video super-resolution, video deblurring and video denoising, demonstrate that VRT outperforms the state-of-the-art methods by large margins ($\textbf{up to 2.16dB}$) on nine benchmark datasets.
Graph Representation Learning via Contrasting Cluster Assignments
Dec 15, 2021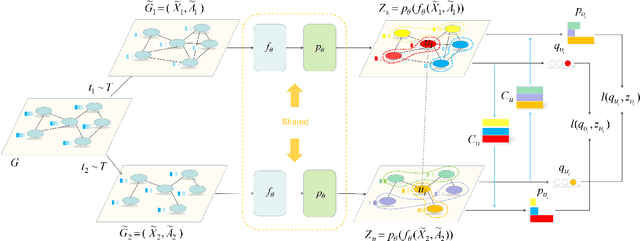
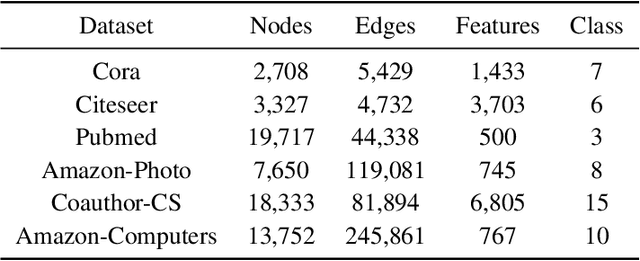
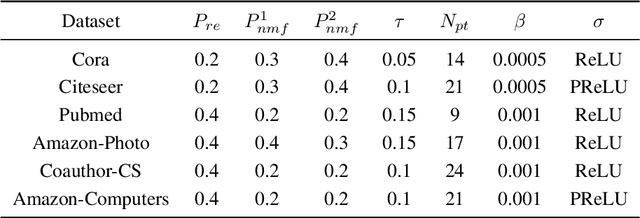
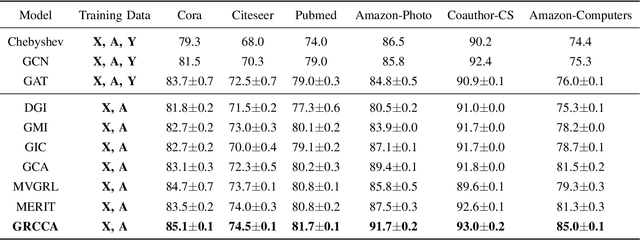
With the rise of contrastive learning, unsupervised graph representation learning has been booming recently, even surpassing the supervised counterparts in some machine learning tasks. Most of existing contrastive models for graph representation learning either focus on maximizing mutual information between local and global embeddings, or primarily depend on contrasting embeddings at node level. However, they are still not exquisite enough to comprehensively explore the local and global views of network topology. Although the former considers local-global relationship, its coarse global information leads to grudging cooperation between local and global views. The latter pays attention to node-level feature alignment, so that the role of global view appears inconspicuous. To avoid falling into these two extreme cases, we propose a novel unsupervised graph representation model by contrasting cluster assignments, called as GRCCA. It is motivated to make good use of local and global information synthetically through combining clustering algorithms and contrastive learning. This not only facilitates the contrastive effect, but also provides the more high-quality graph information. Meanwhile, GRCCA further excavates cluster-level information, which make it get insight to the elusive association between nodes beyond graph topology. Specifically, we first generate two augmented graphs with distinct graph augmentation strategies, then employ clustering algorithms to obtain their cluster assignments and prototypes respectively. The proposed GRCCA further compels the identical nodes from different augmented graphs to recognize their cluster assignments mutually by minimizing a cross entropy loss. To demonstrate its effectiveness, we compare with the state-of-the-art models in three different downstream tasks. The experimental results show that GRCCA has strong competitiveness in most tasks.