 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semi-FedSER: Semi-supervised Learning for Speech Emotion Recognition On Federated Learning using Multiview Pseudo-Labeling
Mar 15, 2022

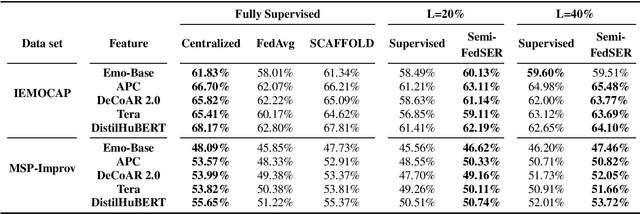
Speech Emotion Recognition (SER) application is frequently associated with privacy concerns as it often acquires and transmits speech data at the client-side to remote cloud platforms for further processing. These speech data can reveal not only speech content and affective information but the speaker's identity, demographic traits, and health status. Federated learning (FL) is a distributed machine learning algorithm that coordinates clients to train a model collaboratively without sharing local data. This algorithm shows enormous potential for SER applications as sharing raw speech or speech features from a user's device is vulnerable to privacy attacks. However, a major challenge in FL is limited availability of high-quality labeled data samples. In this work, we propose a semi-supervised federated learning framework, Semi-FedSER, that utilizes both labeled and unlabeled data samples to address the challenge of limited labeled data samples in FL. We show that our Semi-FedSER can generate desired SER performance even when the local label rate l=20 using two SER benchmark datasets: IEMOCAP and MSP-Improv.
On the Inclusion of Spatial Information for Spatio-Temporal Neural Networks
Jul 15, 2020
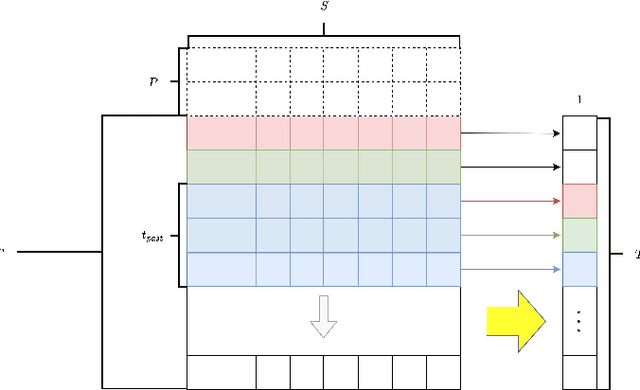
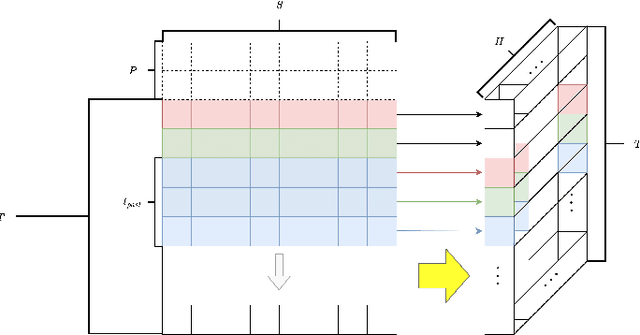
When confronting a spatio-temporal regression, it is sensible to feed the model with any available prior information about the spatial dimension. For example, it is common to define the architecture of neural networks based on spatial closeness, adjacency, or correlation. A common alternative, if spatial information is not available or is too costly to introduce it in the model, is to learn it as an extra step of the model. While the use of prior spatial knowledge, given or learnt, might be beneficial, in this work we question this principle by comparing spatial agnostic neural networks with state of the art models. Our results show that the typical inclusion of prior spatial information is not really needed in most cases. In order to validate this counterintuitive result, we perform thorough experiments over ten different datasets related to sustainable mobility and air quality, substantiating our conclusions on real world problems with direct implications for public health and economy.
Decoupled Multi-task Learning with Cyclical Self-Regulation for Face Parsing
Mar 28, 2022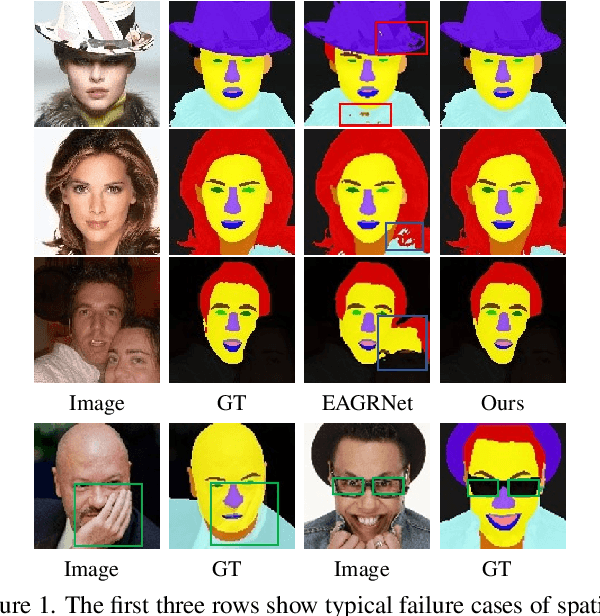
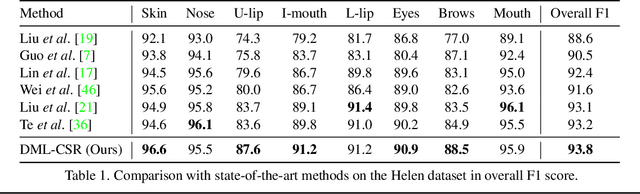
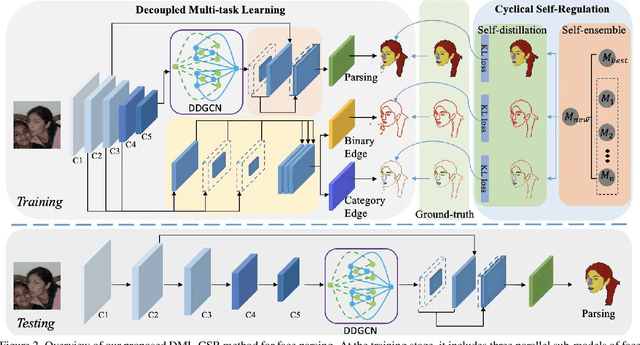
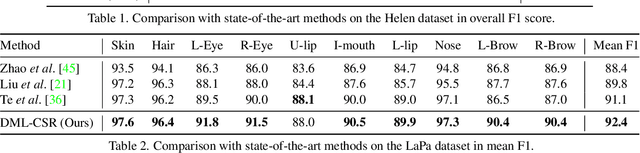
This paper probes intrinsic factors behind typical failure cases (e.g. spatial inconsistency and boundary confusion) produced by the existing state-of-the-art method in face parsing. To tackle these problems, we propose a novel Decoupled Multi-task Learning with Cyclical Self-Regulation (DML-CSR) for face parsing. Specifically, DML-CSR designs a multi-task model which comprises face parsing, binary edge, and category edge detection. These tasks only share low-level encoder weights without high-level interactions between each other, enabling to decouple auxiliary modules from the whole network at the inference stage. To address spatial inconsistency, we develop a dynamic dual graph convolutional network to capture global contextual information without using any extra pooling operation. To handle boundary confusion in both single and multiple face scenarios, we exploit binary and category edge detection to jointly obtain generic geometric structure and fine-grained semantic clues of human faces. Besides, to prevent noisy labels from degrading model generalization during training, cyclical self-regulation is proposed to self-ensemble several model instances to get a new model and the resulting model then is used to self-distill subsequent models, through alternating iterations. Experiments show that our method achieves the new state-of-the-art performance on the Helen, CelebAMask-HQ, and Lapa datasets. The source code is available at https://github.com/deepinsight/insightface/tree/master/parsing/dml_csr.
3D Common Corruptions and Data Augmentation
Mar 02, 2022
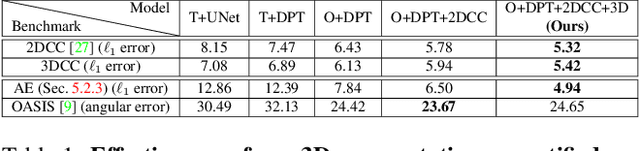

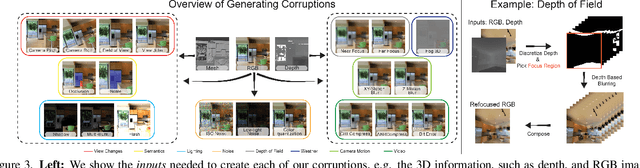
We introduce a set of image transformations that can be used as `corruptions' to evaluate the robustness of models as well as `data augmentation' mechanisms for training neural networks. The primary distinction of the proposed transformations is that, unlike existing approaches such as Common Corruptions, the geometry of the scene is incorporated in the transformations -- thus leading to corruptions that are more likely to occur in the real world. We show these transformations are `efficient' (can be computed on-the-fly), `extendable' (can be applied on most datasets of real images), expose vulnerability of existing models, and can effectively make models more robust when employed as `3D data augmentation' mechanisms. Our evaluations performed on several tasks and datasets suggest incorporating 3D information into robustness benchmarking and training opens up a promising direction for robustness research.
Bayesian optimization with improved scalability and derivative information for efficient design of nanophotonic structures
Jan 08, 2021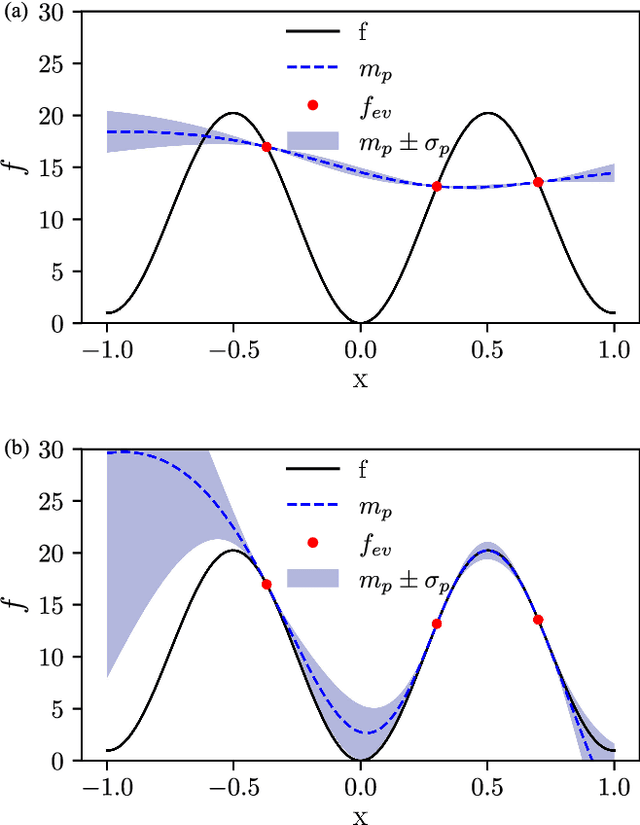
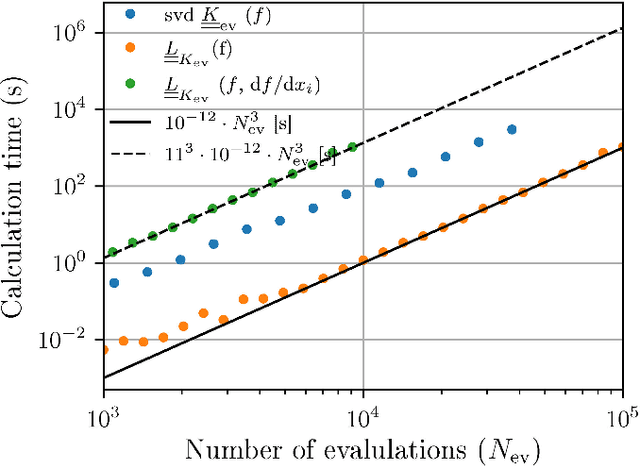
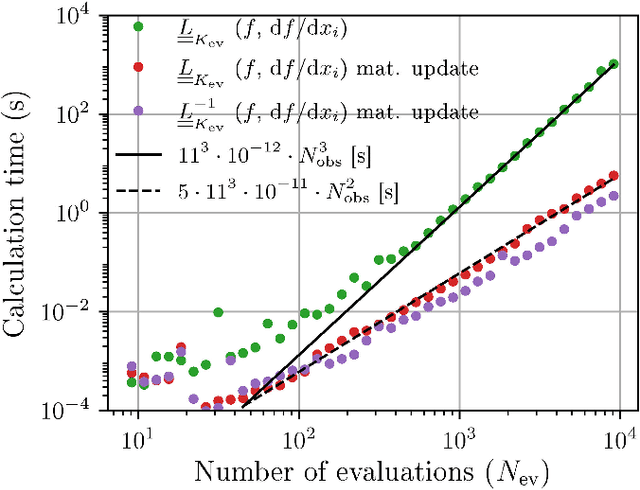
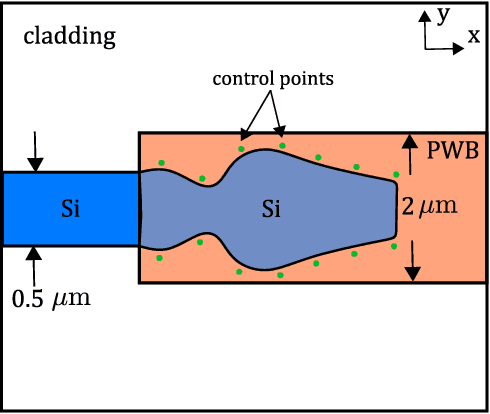
We propose the combination of forward shape derivatives and the use of an iterative inversion scheme for Bayesian optimization to find optimal designs of nanophotonic devices. This approach widens the range of applicability of Bayesian optmization to situations where a larger number of iterations is required and where derivative information is available. This was previously impractical because the computational efforts required to identify the next evaluation point in the parameter space became much larger than the actual evaluation of the objective function. We demonstrate an implementation of the method by optimizing a waveguide edge coupler.
Waveform Design for Wireless Power Transfer with Power Amplifier and Energy Harvester Non-Linearities
Apr 06, 2022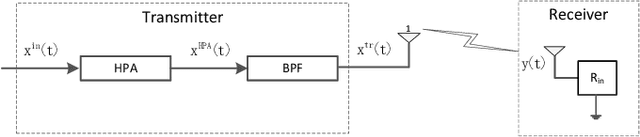
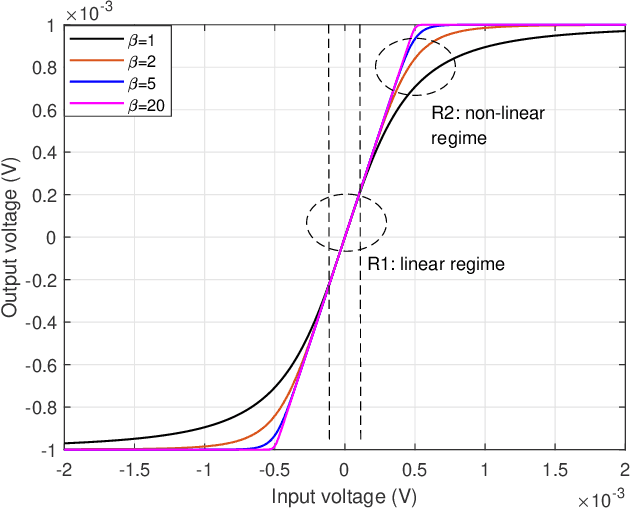
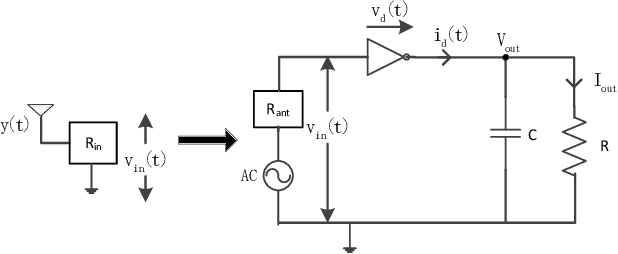
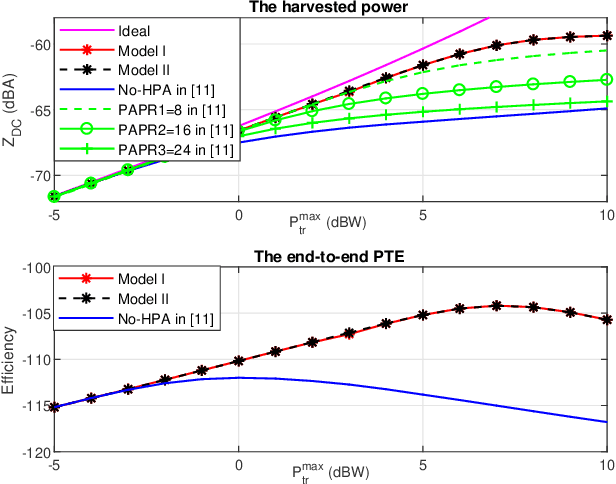
Waveform optimization has shown its great potential to boost the performance of far-field wireless power transfer (WPT). Current research has optimized transmit waveform, adaptive to channel state information (CSI), to maximize the harvested power in WPT while accounting for energy harvester (EH)'s non-linearity. However, the existing transmit waveform design disregards the non-linear high power amplifiers (HPA) at the transmitter. Driven by this, this paper optimizes the multi-carrier waveform at the input of HPA to maximize the harvested DC power considering both HPA's and EH's non-linearities. Two optimization models are formulated based on whether the frequencies of the multi-carrier waveform are concentrated within the transmit pass band or not. Analysis and simulations show that, while EH's non-linearity boosts the power harvesting performance, HPA's non-linearity degrades the harvested power. Hence, the optimal waveform shifts from multi-carrier that exploits EH's non-linearity to single-carrier that reduces HPA's detrimental non-linear distortion as the operational regime of WPT becomes more sensitive to HPA's non-linearity and less sensitive to EH's non-linearity (and inversely). Simultaneously, operating towards HPA's non-linear regime by increasing the input signal power benefits the harvested power since HPA's DC power supply is better exploited, whereas the end-to-end power transfer efficiency (PTE) might decrease because of the increasing non-linear degradation. Throughout the simulations, the proposed waveforms show significant gain over those not accounting for HPA's non-linearity, especially in frequency-flat channels. We also compare the two proposed waveforms and show that the severity of HPA's non-linearity dictates which of the two proposed waveforms is more beneficial.
InstructionNER: A Multi-Task Instruction-Based Generative Framework for Few-shot NER
Mar 08, 2022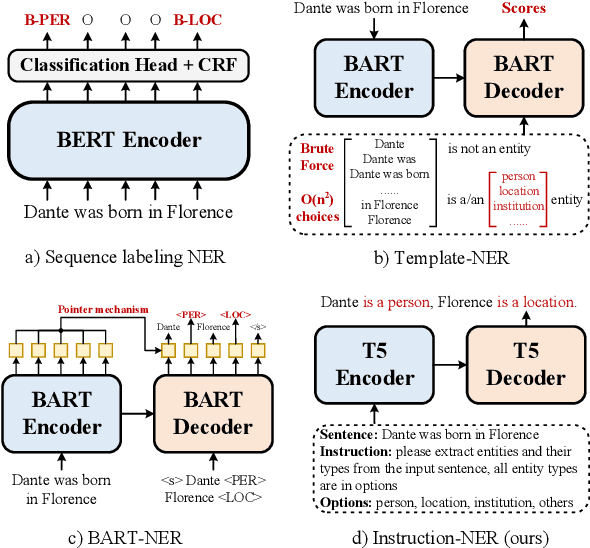
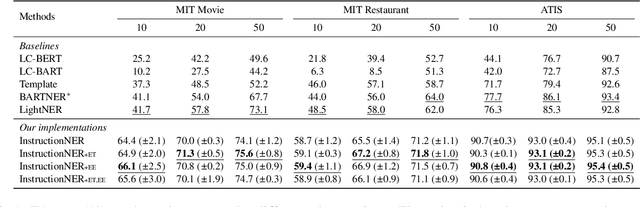
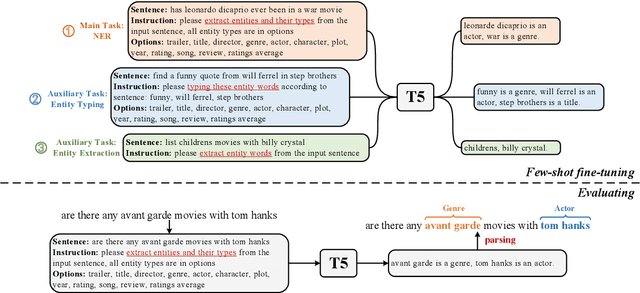

Recently, prompt-based methods have achieved significant performance in few-shot learning scenarios by bridging the gap between language model pre-training and fine-tuning for downstream tasks. However, existing prompt templates are mostly designed for sentence-level tasks and are inappropriate for sequence labeling objectives. To address the above issue, we propose a multi-task instruction-based generative framework, named InstructionNER, for low-resource named entity recognition. Specifically, we reformulate the NER task as a generation problem, which enriches source sentences with task-specific instructions and answer options, then inferences the entities and types in natural language. We further propose two auxiliary tasks, including entity extraction and entity typing, which enable the model to capture more boundary information of entities and deepen the understanding of entity type semantics, respectively. Experimental results show that our method consistently outperforms other baselines on five datasets in few-shot settings.
TRACER: Extreme Attention Guided Salient Object Tracing Network
Dec 14, 2021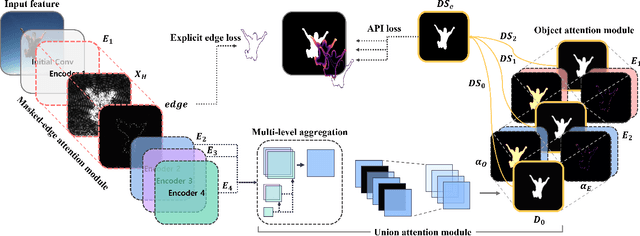
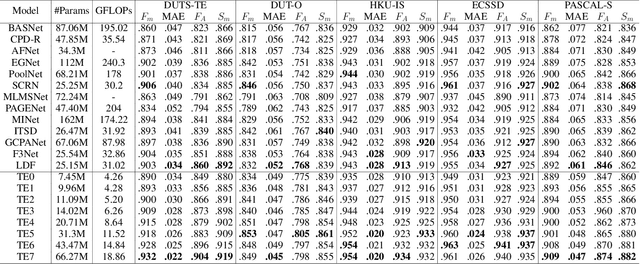


Existing studies on salient object detection (SOD) focus on extracting distinct objects with edge information and aggregating multi-level features to improve SOD performance. To achieve satisfactory performance, the methods employ refined edge information and low multi-level discrepancy. However, both performance gain and computational efficiency cannot be attained, which has motivated us to study the inefficiencies in existing encoder-decoder structures to avoid this trade-off. We propose TRACER, which detects salient objects with explicit edges by incorporating attention guided tracing modules. We employ a masked edge attention module at the end of the first encoder using a fast Fourier transform to propagate the refined edge information to the downstream feature extraction. In the multi-level aggregation phase, the union attention module identifies the complementary channel and important spatial information. To improve the decoder performance and computational efficiency, we minimize the decoder block usage with object attention module. This module extracts undetected objects and edge information from refined channels and spatial representations. Subsequently, we propose an adaptive pixel intensity loss function to deal with the relatively important pixels unlike conventional loss functions which treat all pixels equally. A comparison with 13 existing methods reveals that TRACER achieves state-of-the-art performance on five benchmark datasets. In particular, TRACER-Efficient3 (TE3) outperforms LDF, an existing method while requiring 1.8x fewer learning parameters and less time; TE3 is 5x faster.
Contextualized Sensorimotor Norms: multi-dimensional measures of sensorimotor strength for ambiguous English words, in context
Mar 10, 2022
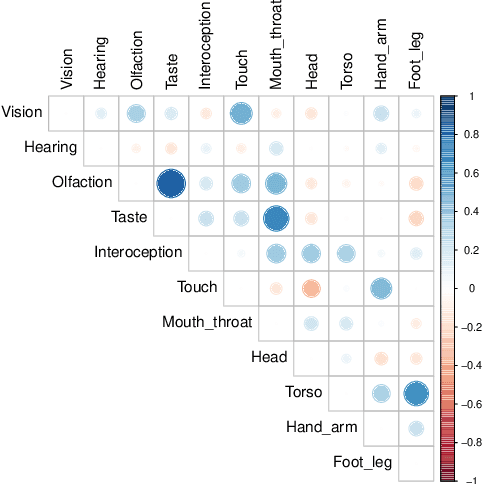
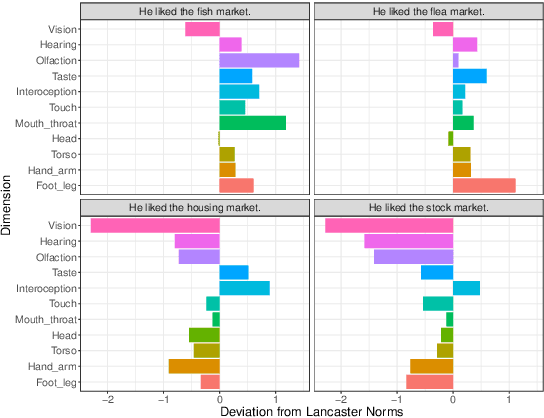
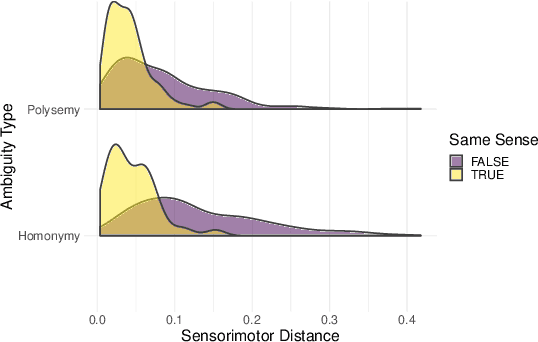
Most large language models are trained on linguistic input alone, yet humans appear to ground their understanding of words in sensorimotor experience. A natural solution is to augment LM representations with human judgments of a word's sensorimotor associations (e.g., the Lancaster Sensorimotor Norms), but this raises another challenge: most words are ambiguous, and judgments of words in isolation fail to account for this multiplicity of meaning (e.g., "wooden table" vs. "data table"). We attempted to address this problem by building a new lexical resource of contextualized sensorimotor judgments for 112 English words, each rated in four different contexts (448 sentences total). We show that these ratings encode overlapping but distinct information from the Lancaster Sensorimotor Norms, and that they also predict other measures of interest (e.g., relatedness), above and beyond measures derived from BERT. Beyond shedding light on theoretical questions, we suggest that these ratings could be of use as a "challenge set" for researchers building grounded language models.
BERTVision -- A Parameter-Efficient Approach for Question Answering
Feb 24, 2022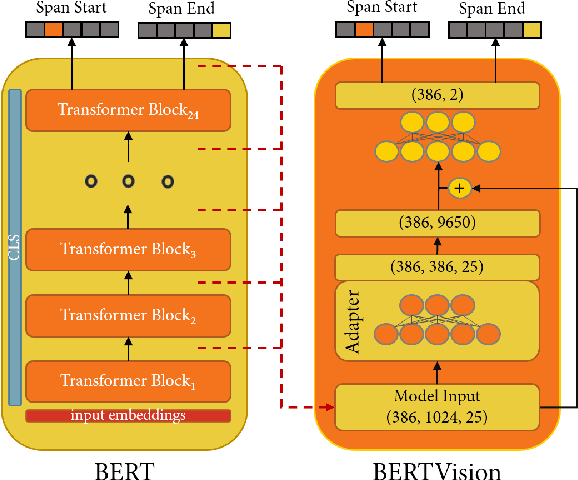
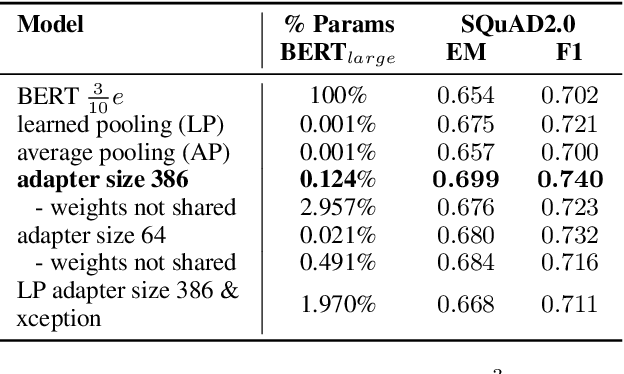
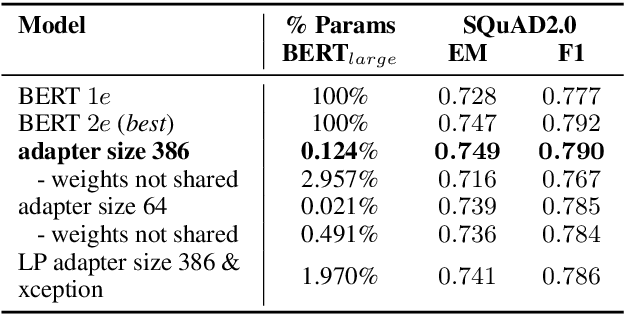
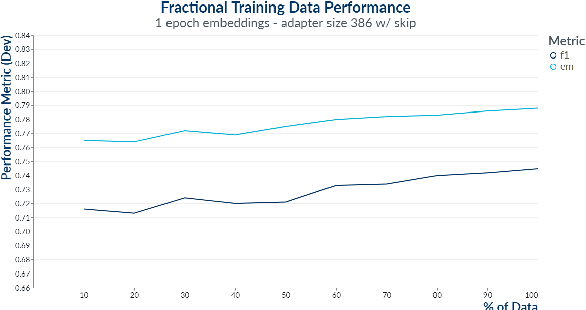
We present a highly parameter efficient approach for Question Answering that significantly reduces the need for extended BERT fine-tuning. Our method uses information from the hidden state activations of each BERT transformer layer, which is discarded during typical BERT inference. Our best model achieves maximal BERT performance at a fraction of the training time and GPU or TPU expense. Performance is further improved by ensembling our model with BERTs predictions. Furthermore, we find that near optimal performance can be achieved for QA span annotation using less training data. Our experiments show that this approach works well not only for span annotation, but also for classification, suggesting that it may be extensible to a wider range of tasks.