 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Policy-Based Bayesian Experimental Design for Non-Differentiable Implicit Models
Mar 08, 2022
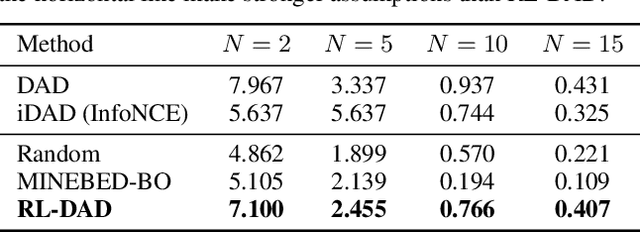
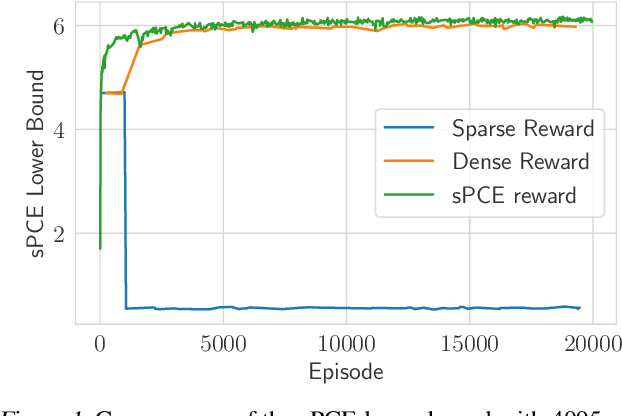
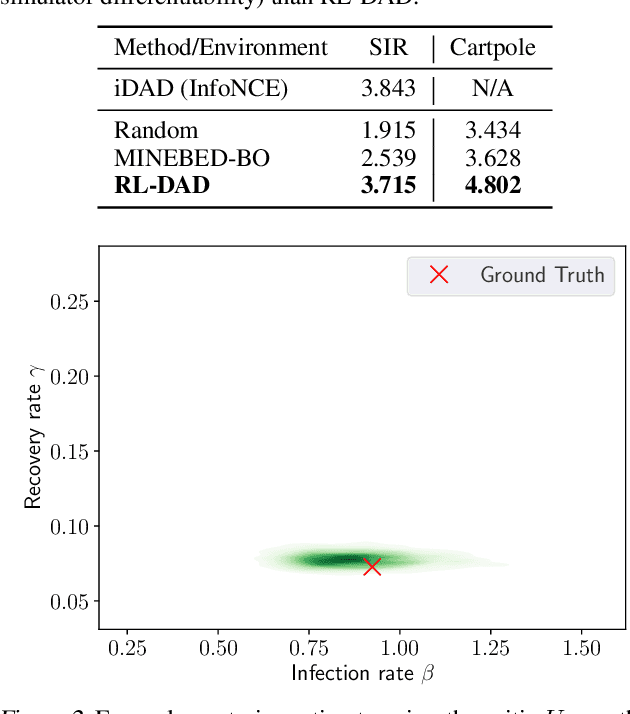
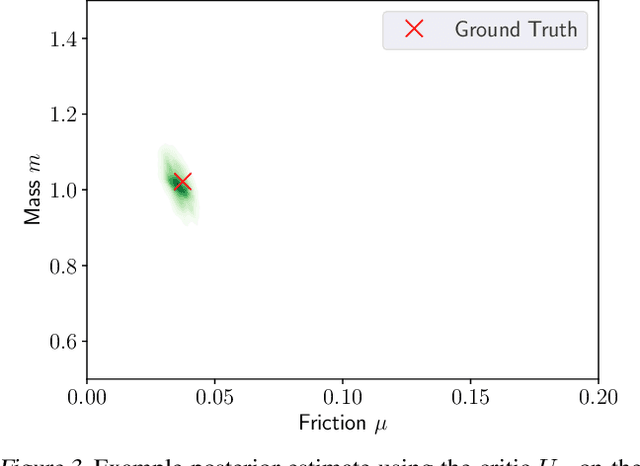
For applications in healthcare, physics, energy, robotics, and many other fields, designing maximally informative experiments is valuable, particularly when experiments are expensive, time-consuming, or pose safety hazards. While existing approaches can sequentially design experiments based on prior observation history, many of these methods do not extend to implicit models, where simulation is possible but computing the likelihood is intractable. Furthermore, they often require either significant online computation during deployment or a differentiable simulation system. We introduce Reinforcement Learning for Deep Adaptive Design (RL-DAD), a method for simulation-based optimal experimental design for non-differentiable implicit models. RL-DAD extends prior work in policy-based Bayesian Optimal Experimental Design (BOED) by reformulating it as a Markov Decision Process with a reward function based on likelihood-free information lower bounds, which is used to learn a policy via deep reinforcement learning. The learned design policy maps prior histories to experiment designs offline and can be quickly deployed during online execution. We evaluate RL-DAD and find that it performs competitively with baselines on three benchmarks.
Machine Learning for Particle Flow Reconstruction at CMS
Mar 01, 2022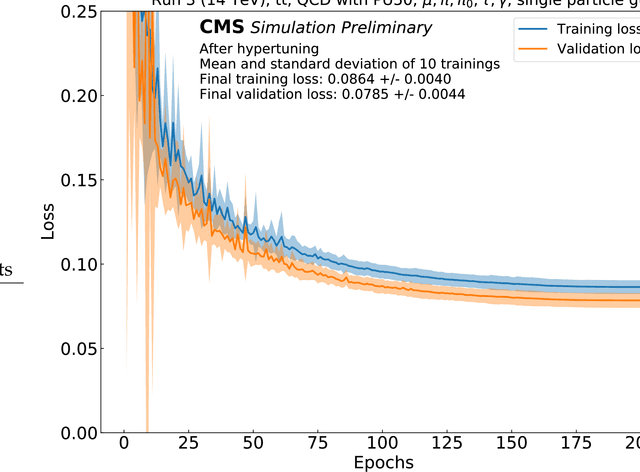
We provide details on the implementation of a machine-learning based particle flow algorithm for CMS. The standard particle flow algorithm reconstructs stable particles based on calorimeter clusters and tracks to provide a global event reconstruction that exploits the combined information of multiple detector subsystems, leading to strong improvements for quantities such as jets and missing transverse energy. We have studied a possible evolution of particle flow towards heterogeneous computing platforms such as GPUs using a graph neural network. The machine-learned PF model reconstructs particle candidates based on the full list of tracks and calorimeter clusters in the event. For validation, we determine the physics performance directly in the CMS software framework when the proposed algorithm is interfaced with the offline reconstruction of jets and missing transverse energy. We also report the computational performance of the algorithm, which scales approximately linearly in runtime and memory usage with the input size.
Exploiting Neural Query Translation into Cross Lingual Information Retrieval
Oct 26, 2020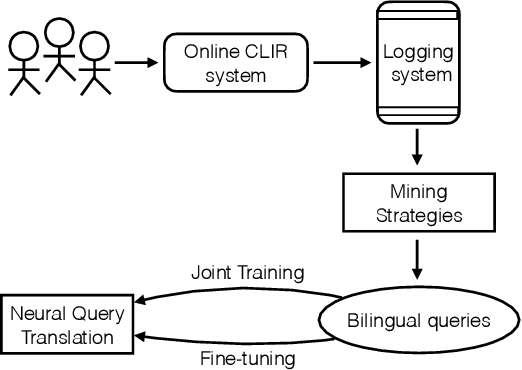
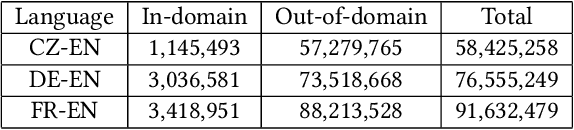
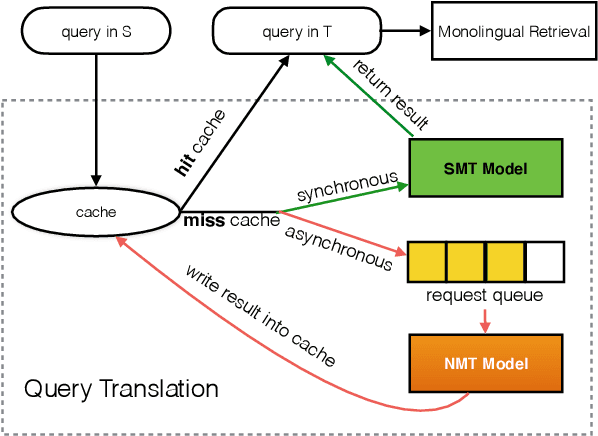

As a crucial role in cross-language information retrieval (CLIR), query translation has three main challenges: 1) the adequacy of translation; 2) the lack of in-domain parallel training data; and 3) the requisite of low latency. To this end, existing CLIR systems mainly exploit statistical-based machine translation (SMT) rather than the advanced neural machine translation (NMT), limiting the further improvements on both translation and retrieval quality. In this paper, we investigate how to exploit neural query translation model into CLIR system. Specifically, we propose a novel data augmentation method that extracts query translation pairs according to user clickthrough data, thus to alleviate the problem of domain-adaptation in NMT. Then, we introduce an asynchronous strategy which is able to leverage the advantages of the real-time in SMT and the veracity in NMT. Experimental results reveal that the proposed approach yields better retrieval quality than strong baselines and can be well applied into a real-world CLIR system, i.e. Aliexpress e-Commerce search engine. Readers can examine and test their cases on our website: https://aliexpress.com .
Rubik's Cube Operator: A Plug And Play Permutation Module for Better Arranging High Dimensional Industrial Data in Deep Convolutional Processes
Mar 24, 2022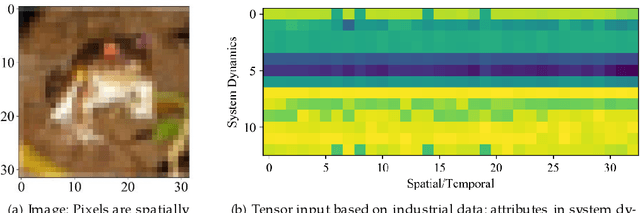
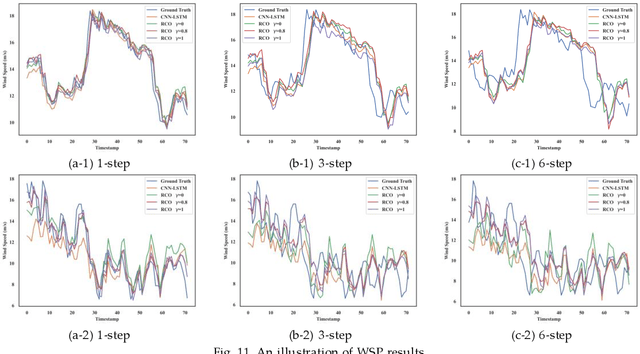
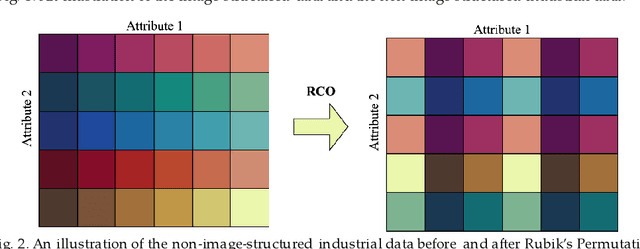
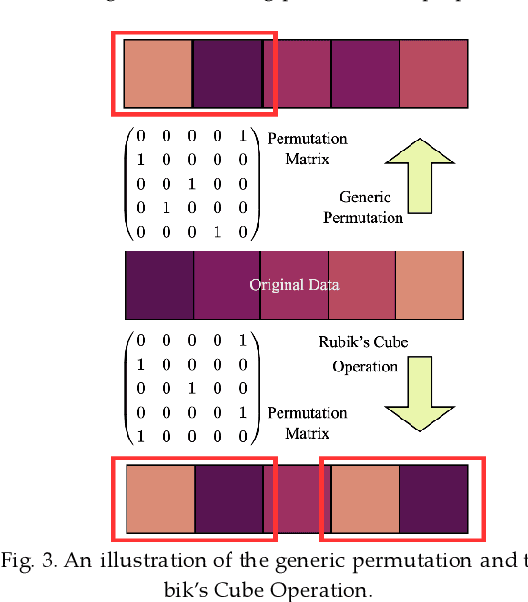
The convolutional neural network (CNN) has been widely applied to process the industrial data based tensor input, which integrates data records of distributed industrial systems from the spatial, temporal, and system dynamics aspects. However, unlike images, information in the industrial data based tensor is not necessarily spatially ordered. Thus, directly applying CNN is ineffective. To tackle such issue, we propose a plug and play module, the Rubik's Cube Operator (RCO), to adaptively permutate the data organization of the industrial data based tensor to an optimal or suboptimal order of attributes before being processed by CNNs, which can be updated with subsequent CNNs together via the gradient-based optimizer. The proposed RCO maintains K binary and right stochastic permutation matrices to permutate attributes of K axes of the input industrial data based tensor. A novel learning process is proposed to enable learning permutation matrices from data, where the Gumbel-Softmax is employed to reparameterize elements of permutation matrices, and the soft regularization loss is proposed and added to the task-specific loss to ensure the feature diversity of the permuted data. We verify the effectiveness of the proposed RCO via considering two representative learning tasks processing industrial data via CNNs, the wind power prediction (WPP) and the wind speed prediction (WSP) from the renewable energy domain. Computational experiments are conducted based on four datasets collected from different wind farms and the results demonstrate that the proposed RCO can improve the performance of CNN based networks significantly.
Generalized Bayesian Additive Regression Trees Models: Beyond Conditional Conjugacy
Feb 20, 2022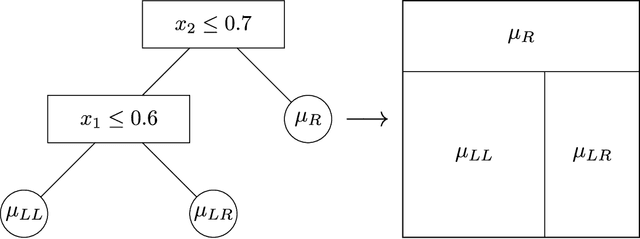

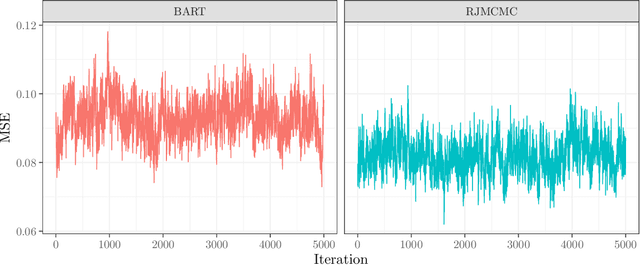
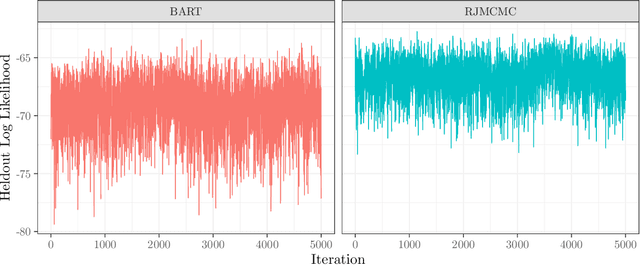
Bayesian additive regression trees have seen increased interest in recent years due to their ability to combine machine learning techniques with principled uncertainty quantification. The Bayesian backfitting algorithm used to fit BART models, however, limits their application to a small class of models for which conditional conjugacy exists. In this article, we greatly expand the domain of applicability of BART to arbitrary \emph{generalized BART} models by introducing a very simple, tuning-parameter-free, reversible jump Markov chain Monte Carlo algorithm. Our algorithm requires only that the user be able to compute the likelihood and (optionally) its gradient and Fisher information. The potential applications are very broad; we consider examples in survival analysis, structured heteroskedastic regression, and gamma shape regression.
A framework for spatial heat risk assessment using a generalized similarity measure
Feb 20, 2022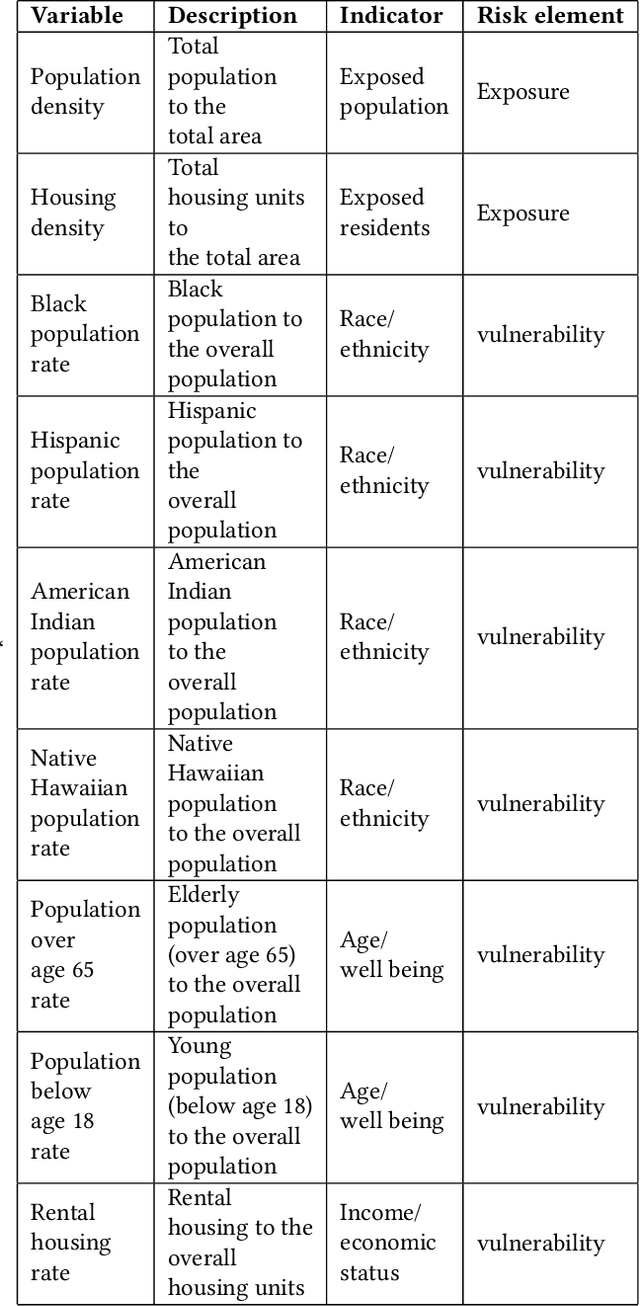
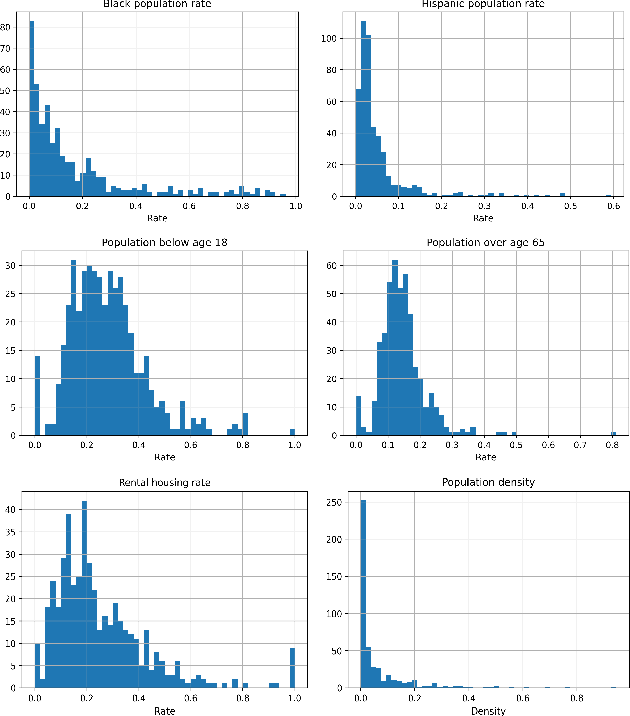
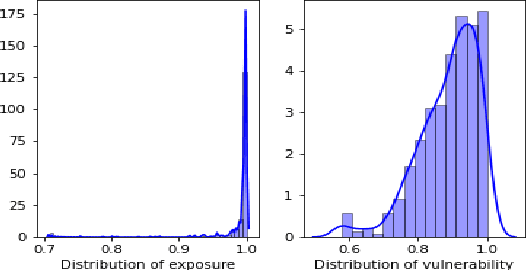
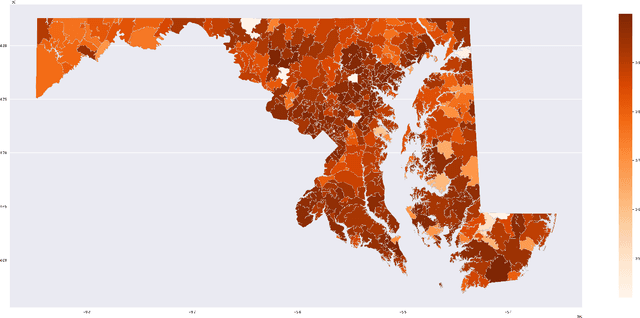
In this study, we develop a novel framework to assess health risks due to heat hazards across various localities (zip codes) across the state of Maryland with the help of two commonly used indicators i.e. exposure and vulnerability. Our approach quantifies each of the two aforementioned indicators by developing their corresponding feature vectors and subsequently computes indicator-specific reference vectors that signify a high risk environment by clustering the data points at the tail-end of an empirical risk spectrum. The proposed framework circumvents the information-theoretic entropy based aggregation methods whose usage varies with different views of entropy that are subjective in nature and more importantly generalizes the notion of risk-valuation using cosine similarity with unknown reference points.
Information Minimization In Emergent Languages
May 31, 2019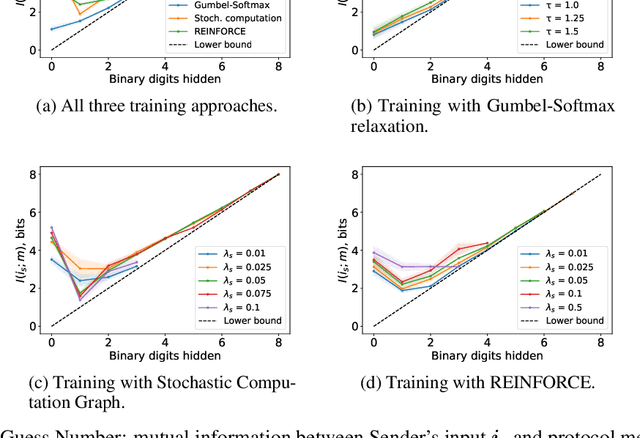
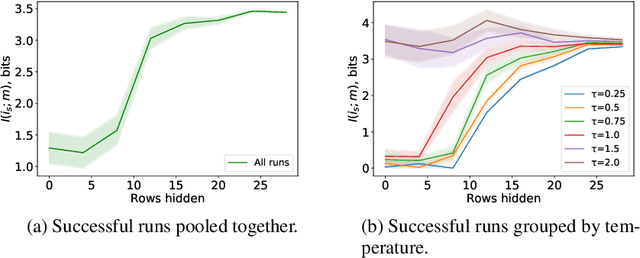
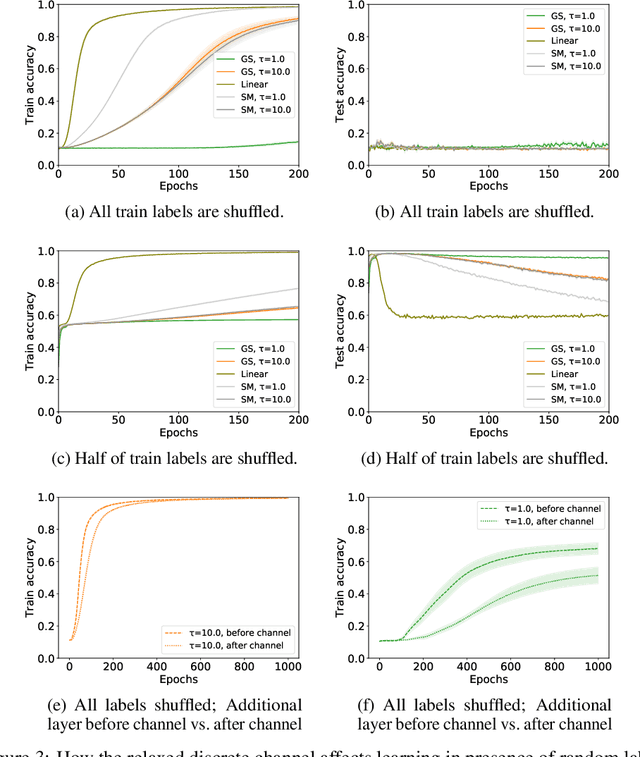
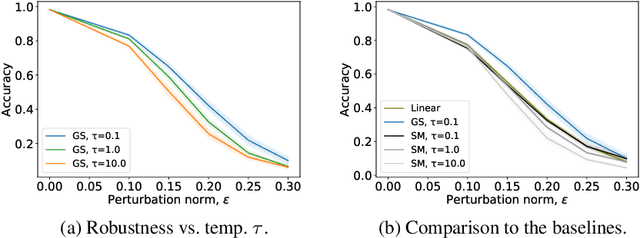
There is a growing interest in studying the languages emerging when neural agents are jointly trained to solve tasks that require communication through discrete messages. We investigate here the information-theoretic complexity of such languages, focusing on the most basic two-agent, one-symbol, one-exchange setup. We find that, under common training procedures, the emergent languages are subject to an information minimization pressure: The mutual information between the communicating agent's inputs and the messages is close to the minimum that still allows the task to be solved. After verifying this information minimization property, we perform experiments showing that a stronger discrete-channel-driven information minimization pressure leads to increased robustness to overfitting and to adversarial attacks. We conclude by discussing the implications of our findings for the studies of artificial and natural language emergence, and for representation learning.
Transport information Bregman divergences
Jan 04, 2021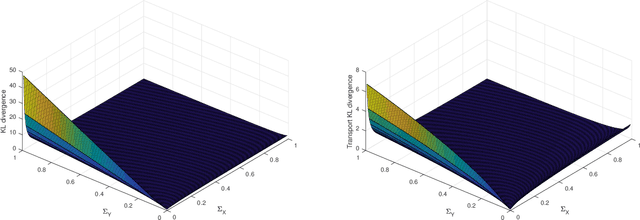
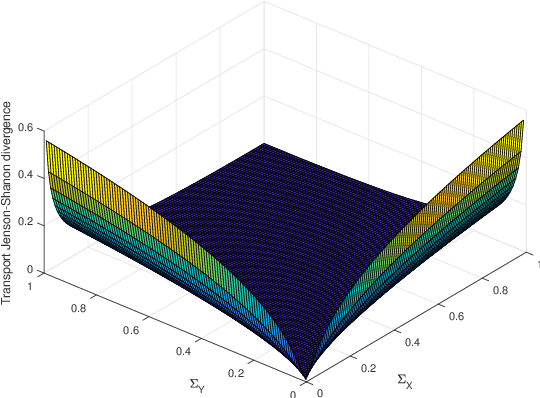
We study Bregman divergences in probability density space embedded with the $L^2$--Wasserstein metric. Several properties and dualities of transport Bregman divergences are provided. In particular, we derive the transport Kullback--Leibler (KL) divergence by a Bregman divergence of negative Boltzmann--Shannon entropy in $L^2$--Wasserstein space. We also derive analytical formulas and generalizations of transport KL divergence for one-dimensional probability densities and Gaussian families.
Adaptive n-ary Activation Functions for Probabilistic Boolean Logic
Mar 16, 2022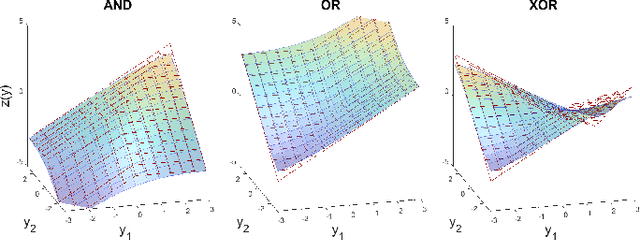
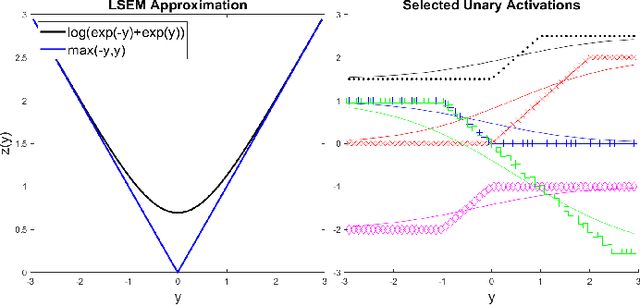
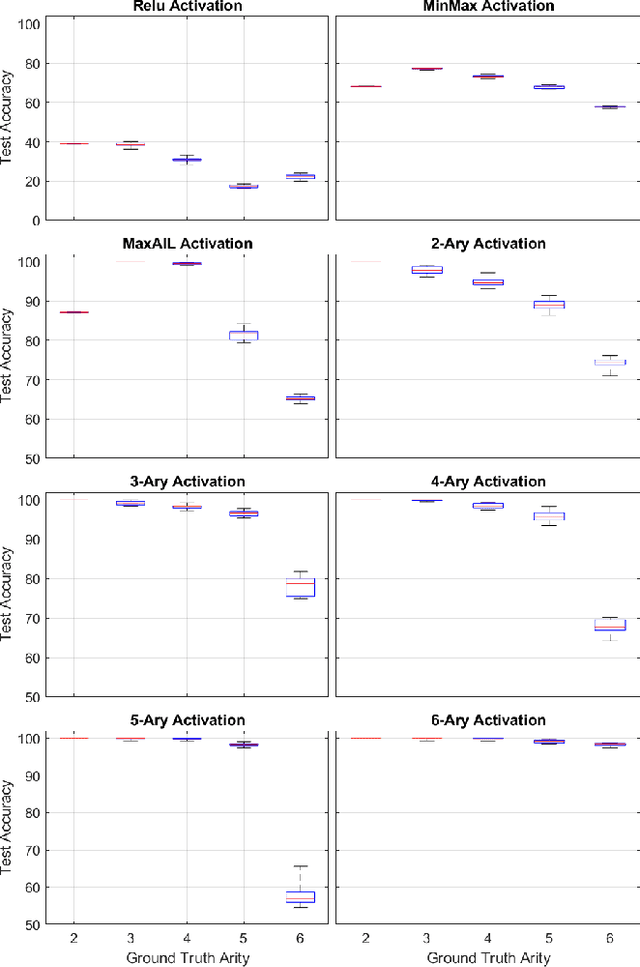
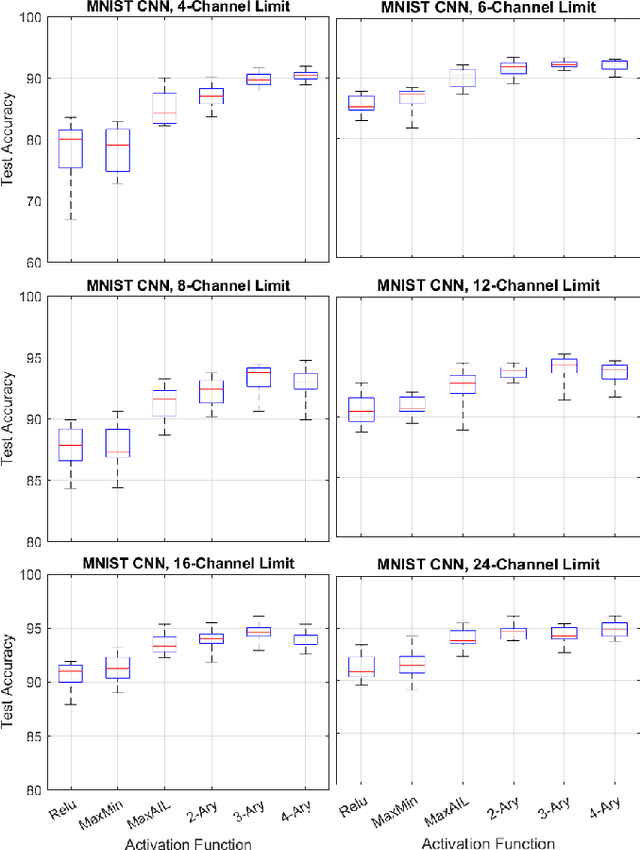
Balancing model complexity against the information contained in observed data is the central challenge to learning. In order for complexity-efficient models to exist and be discoverable in high dimensions, we require a computational framework that relates a credible notion of complexity to simple parameter representations. Further, this framework must allow excess complexity to be gradually removed via gradient-based optimization. Our n-ary, or n-argument, activation functions fill this gap by approximating belief functions (probabilistic Boolean logic) using logit representations of probability. Just as Boolean logic determines the truth of a consequent claim from relationships among a set of antecedent propositions, probabilistic formulations generalize predictions when antecedents, truth tables, and consequents all retain uncertainty. Our activation functions demonstrate the ability to learn arbitrary logic, such as the binary exclusive disjunction (p xor q) and ternary conditioned disjunction ( c ? p : q ), in a single layer using an activation function of matching or greater arity. Further, we represent belief tables using a basis that directly associates the number of nonzero parameters to the effective arity of the belief function, thus capturing a concrete relationship between logical complexity and efficient parameter representations. This opens optimization approaches to reduce logical complexity by inducing parameter sparsity.
TIGGER: Scalable Generative Modelling for Temporal Interaction Graphs
Mar 08, 2022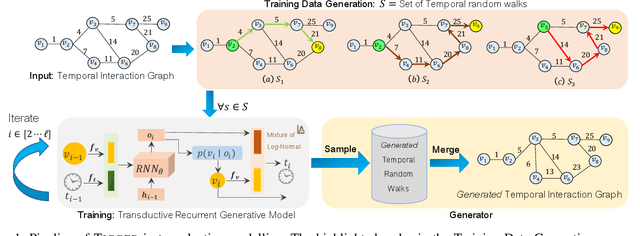
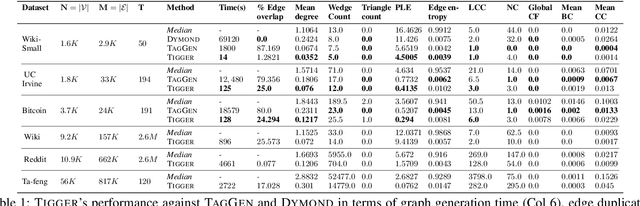

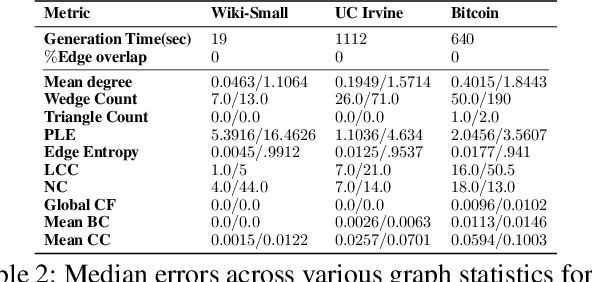
There has been a recent surge in learning generative models for graphs. While impressive progress has been made on static graphs, work on generative modeling of temporal graphs is at a nascent stage with significant scope for improvement. First, existing generative models do not scale with either the time horizon or the number of nodes. Second, existing techniques are transductive in nature and thus do not facilitate knowledge transfer. Finally, due to relying on one-to-one node mapping from source to the generated graph, existing models leak node identity information and do not allow up-scaling/down-scaling the source graph size. In this paper, we bridge these gaps with a novel generative model called TIGGER. TIGGER derives its power through a combination of temporal point processes with auto-regressive modeling enabling both transductive and inductive variants. Through extensive experiments on real datasets, we establish TIGGER generates graphs of superior fidelity, while also being up to 3 orders of magnitude faster than the state-of-the-art.