 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Ensemble Knowledge Guided Sub-network Search and Fine-tuning for Filter Pruning
Mar 25, 2022
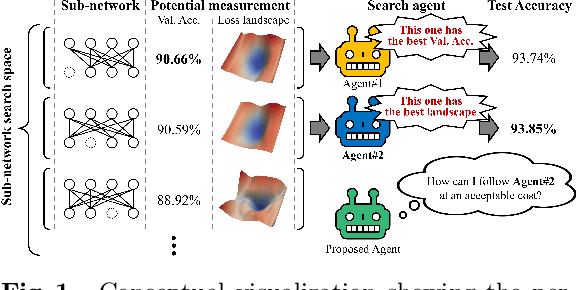
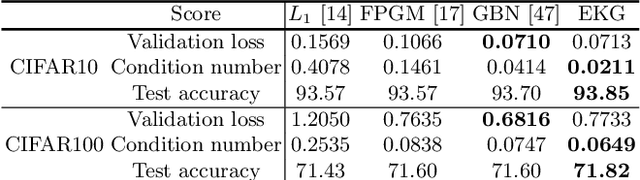
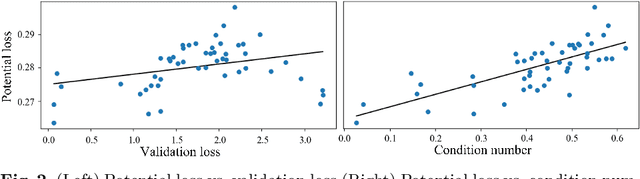
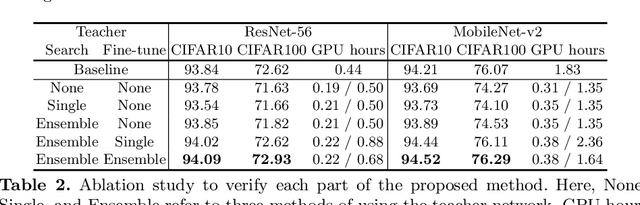
Conventional NAS-based pruning algorithms aim to find the sub-network with the best validation performance. However, validation performance does not successfully represent test performance, i.e., potential performance. Also, although fine-tuning the pruned network to restore the performance drop is an inevitable process, few studies have handled this issue. This paper proposes a novel sub-network search and fine-tuning method that is named Ensemble Knowledge Guidance (EKG). First, we experimentally prove that the fluctuation of the loss landscape is an effective metric to evaluate the potential performance. In order to search a sub-network with the smoothest loss landscape at a low cost, we propose a pseudo-supernet built by an ensemble sub-network knowledge distillation. Next, we propose a novel fine-tuning that re-uses the information of the search phase. We store the interim sub-networks, that is, the by-products of the search phase, and transfer their knowledge into the pruned network. Note that EKG is easy to be plugged-in and computationally efficient. For example, in the case of ResNet-50, about 45% of FLOPS is removed without any performance drop in only 315 GPU hours. The implemented code is available at https://github.com/sseung0703/EKG.
Programming Language Agnostic Mining of Code and Language Pairs with Sequence Labeling Based Question Answering
Mar 21, 2022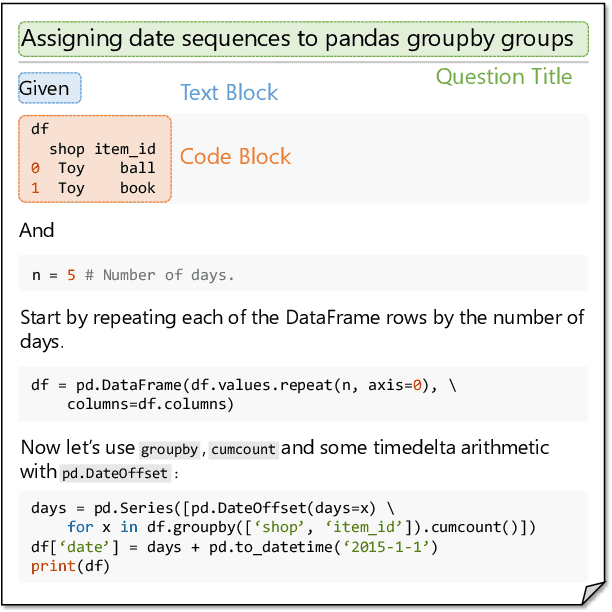
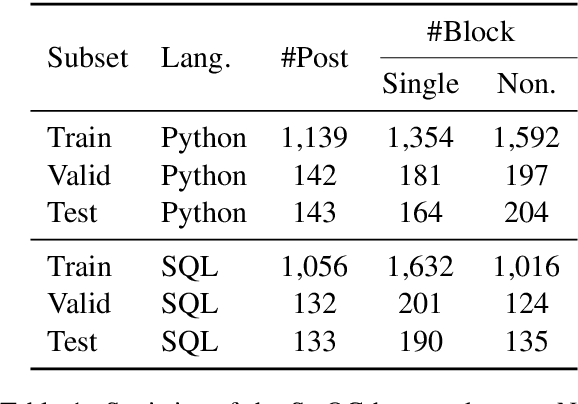
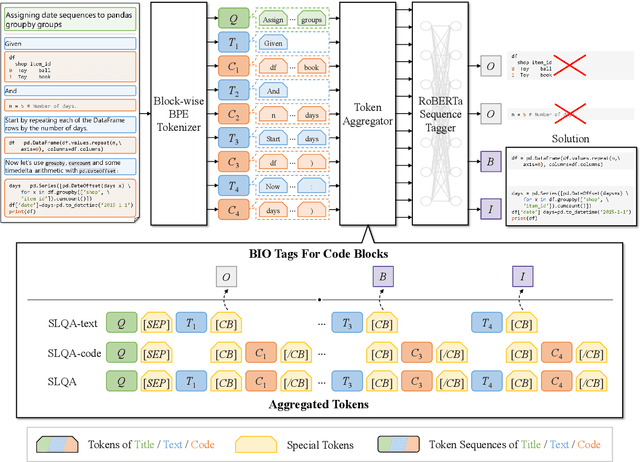
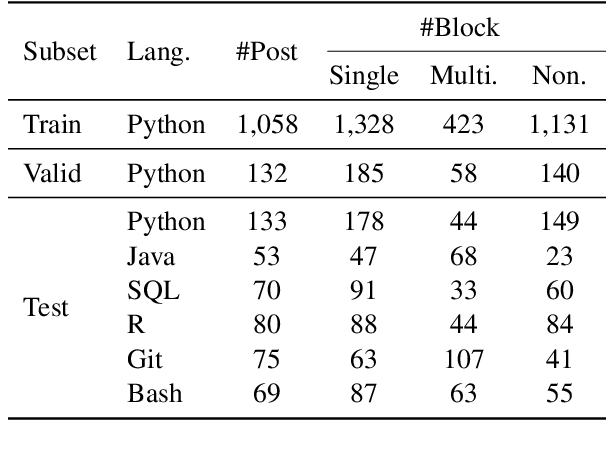
Mining aligned natural language (NL) and programming language (PL) pairs is a critical task to NL-PL understanding. Existing methods applied specialized hand-crafted features or separately-trained models for each PL. However, they usually suffered from low transferability across multiple PLs, especially for niche PLs with less annotated data. Fortunately, a Stack Overflow answer post is essentially a sequence of text and code blocks and its global textual context can provide PL-agnostic supplementary information. In this paper, we propose a Sequence Labeling based Question Answering (SLQA) method to mine NL-PL pairs in a PL-agnostic manner. In particular, we propose to apply the BIO tagging scheme instead of the conventional binary scheme to mine the code solutions which are often composed of multiple blocks of a post. Experiments on current single-PL single-block benchmarks and a manually-labeled cross-PL multi-block benchmark prove the effectiveness and transferability of SLQA. We further present a parallel NL-PL corpus named Lang2Code automatically mined with SLQA, which contains about 1.4M pairs on 6 PLs. Under statistical analysis and downstream evaluation, we demonstrate that Lang2Code is a large-scale high-quality data resource for further NL-PL research.
Human-Aware Object Placement for Visual Environment Reconstruction
Mar 28, 2022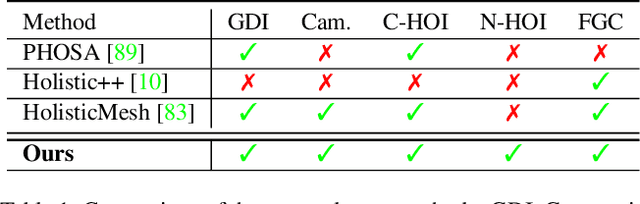

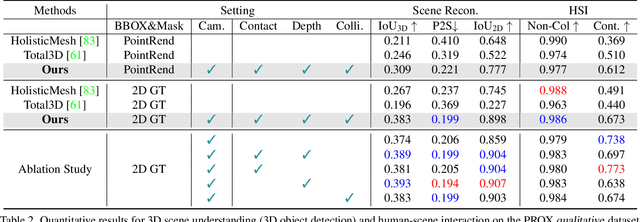
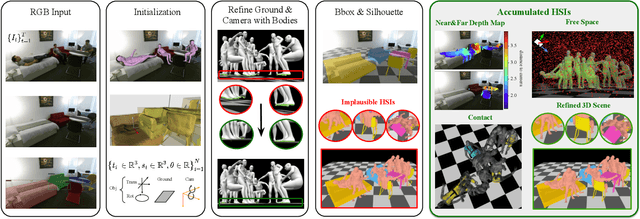
Humans are in constant contact with the world as they move through it and interact with it. This contact is a vital source of information for understanding 3D humans, 3D scenes, and the interactions between them. In fact, we demonstrate that these human-scene interactions (HSIs) can be leveraged to improve the 3D reconstruction of a scene from a monocular RGB video. Our key idea is that, as a person moves through a scene and interacts with it, we accumulate HSIs across multiple input images, and optimize the 3D scene to reconstruct a consistent, physically plausible and functional 3D scene layout. Our optimization-based approach exploits three types of HSI constraints: (1) humans that move in a scene are occluded or occlude objects, thus, defining the depth ordering of the objects, (2) humans move through free space and do not interpenetrate objects, (3) when humans and objects are in contact, the contact surfaces occupy the same place in space. Using these constraints in an optimization formulation across all observations, we significantly improve the 3D scene layout reconstruction. Furthermore, we show that our scene reconstruction can be used to refine the initial 3D human pose and shape (HPS) estimation. We evaluate the 3D scene layout reconstruction and HPS estimation qualitatively and quantitatively using the PROX and PiGraphs datasets. The code and data are available for research purposes at https://mover.is.tue.mpg.de/.
VGAER: graph neural network reconstruction based community detection
Jan 29, 2022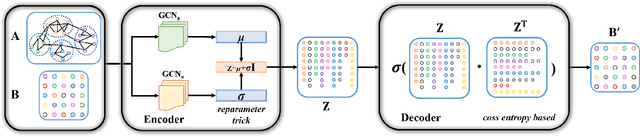
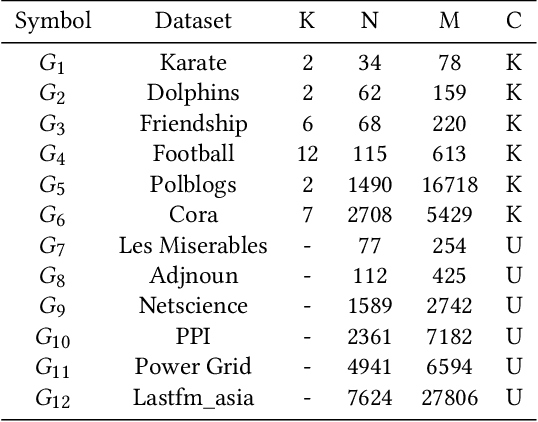
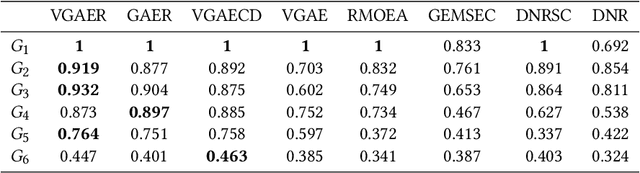
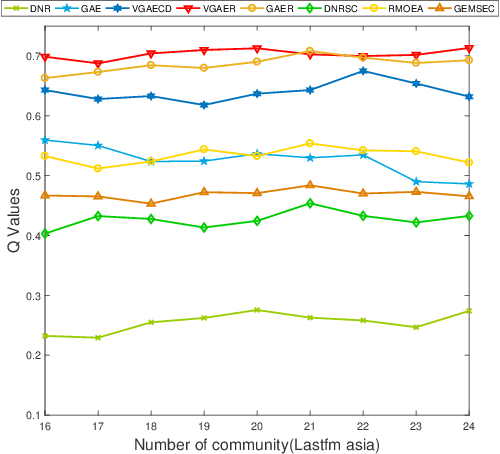
Community detection is a fundamental and important issue in network science, but there are only a few community detection algorithms based on graph neural networks, among which unsupervised algorithms are almost blank. By fusing the high-order modularity information with network features, this paper proposes a Variational Graph AutoEncoder Reconstruction based community detection VGAER for the first time, and gives its non-probabilistic version. They do not need any prior information. We have carefully designed corresponding input features, decoder, and downstream tasks based on the community detection task and these designs are concise, natural, and perform well (NMI values under our design are improved by 59.1% - 565.9%). Based on a series of experiments with wide range of datasets and advanced methods, VGAER has achieved superior performance and shows strong competitiveness and potential with a simpler design. Finally, we report the results of algorithm convergence analysis and t-SNE visualization, which clearly depicted the stable performance and powerful network modularity ability of VGAER. Our codes are available at https://github.com/qcydm/VGAER.
Mental State Classification Using Multi-graph Features
Feb 25, 2022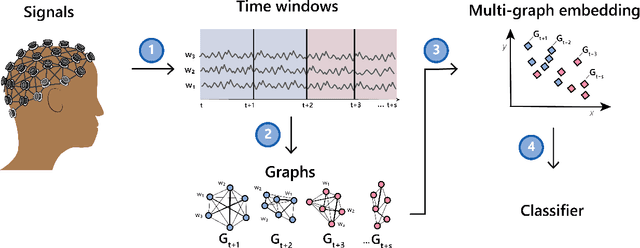
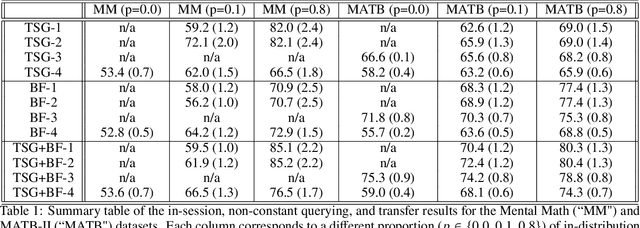
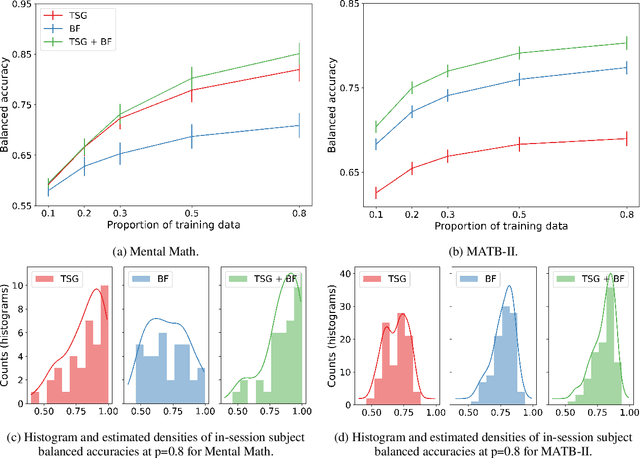
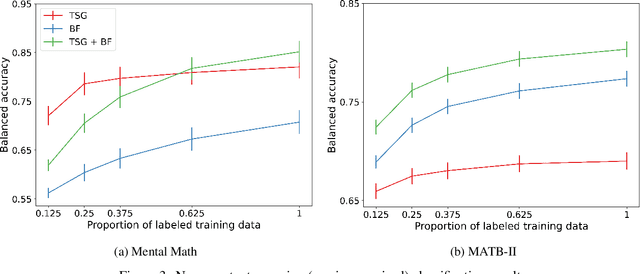
We consider the problem of extracting features from passive, multi-channel electroencephalogram (EEG) devices for downstream inference tasks related to high-level mental states such as stress and cognitive load. Our proposed method leverages recently developed multi-graph tools and applies them to the time series of graphs implied by the statistical dependence structure (e.g., correlation) amongst the multiple sensors. We compare the effectiveness of the proposed features to traditional band power-based features in the context of three classification experiments and find that the two feature sets offer complementary predictive information. We conclude by showing that the importance of particular channels and pairs of channels for classification when using the proposed features is neuroscientifically valid.
Pedagogical Demonstrations and Pragmatic Learning in Artificial Tutor-Learner Interactions
Feb 28, 2022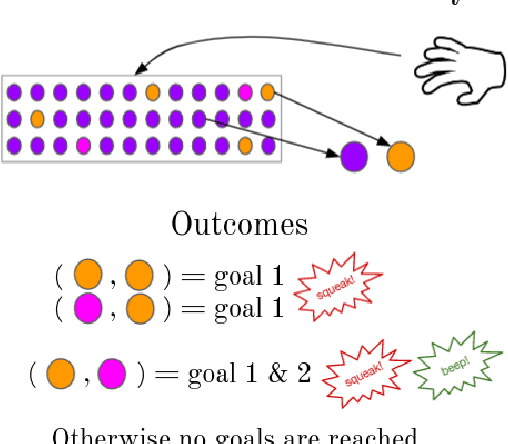
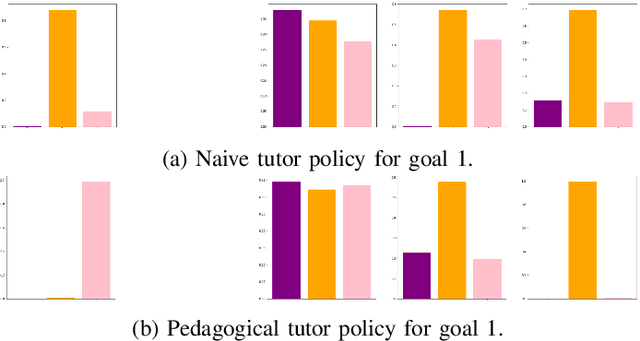
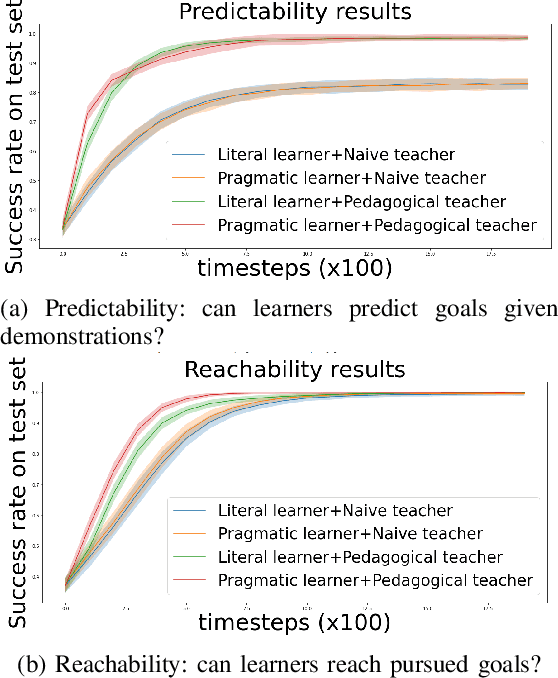
When demonstrating a task, human tutors pedagogically modify their behavior by either "showing" the task rather than just "doing" it (exaggerating on relevant parts of the demonstration) or by giving demonstrations that best disambiguate the communicated goal. Analogously, human learners pragmatically infer the communicative intent of the tutor: they interpret what the tutor is trying to teach them and deduce relevant information for learning. Without such mechanisms, traditional Learning from Demonstration (LfD) algorithms will consider such demonstrations as sub-optimal. In this paper, we investigate the implementation of such mechanisms in a tutor-learner setup where both participants are artificial agents in an environment with multiple goals. Using pedagogy from the tutor and pragmatism from the learner, we show substantial improvements over standard learning from demonstrations.
Modelling and Quantifying Membership Information Leakage in Machine Learning
Jan 29, 2020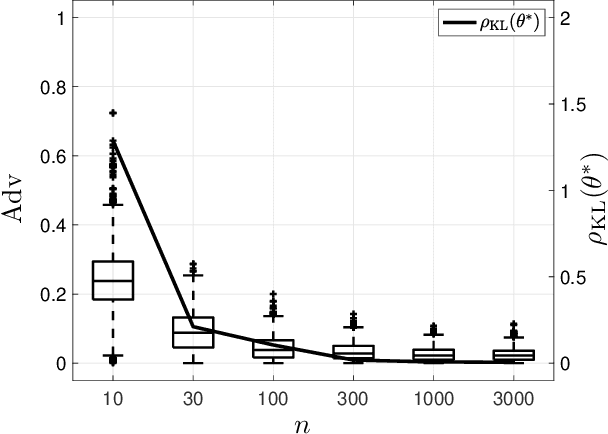
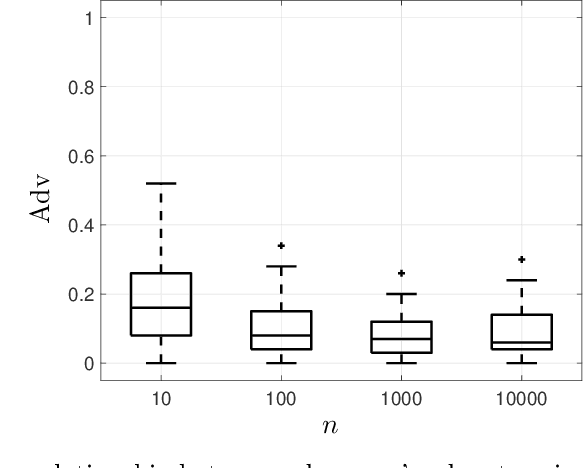
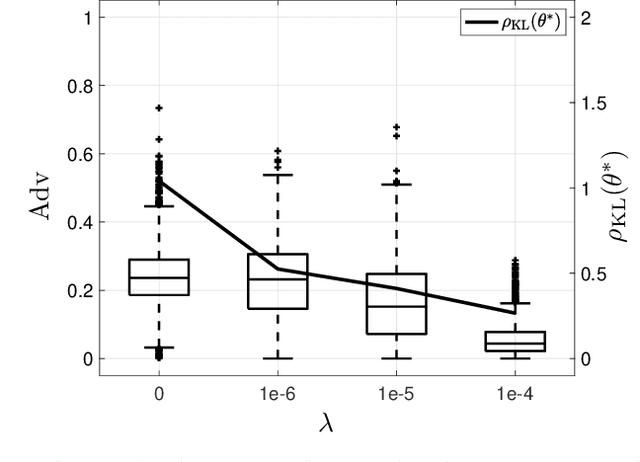
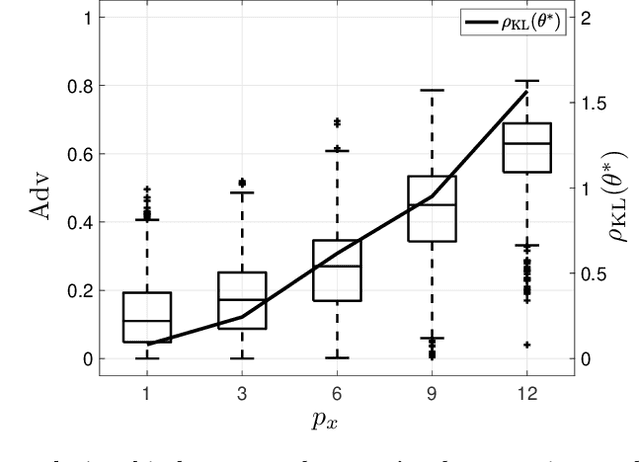
Machine learning models have been shown to be vulnerable to membership inference attacks, i.e., inferring whether individuals' data have been used for training models. The lack of understanding about factors contributing success of these attacks motivates the need for modelling membership information leakage using information theory and for investigating properties of machine learning models and training algorithms that can reduce membership information leakage. We use conditional mutual information leakage to measure the amount of information leakage from the trained machine learning model about the presence of an individual in the training dataset. We devise an upper bound for this measure of information leakage using Kullback--Leibler divergence that is more amenable to numerical computation. We prove a direct relationship between the Kullback--Leibler membership information leakage and the probability of success for a hypothesis-testing adversary examining whether a particular data record belongs to the training dataset of a machine learning model. We show that the mutual information leakage is a decreasing function of the training dataset size and the regularization weight. We also prove that, if the sensitivity of the machine learning model (defined in terms of the derivatives of the fitness with respect to model parameters) is high, more membership information is potentially leaked. This illustrates that complex models, such as deep neural networks, are more susceptible to membership inference attacks in comparison to simpler models with fewer degrees of freedom. We show that the amount of the membership information leakage is reduced by $\mathcal{O}(\log^{1/2}(\delta^{-1})\epsilon^{-1})$ when using Gaussian $(\epsilon,\delta)$-differentially-private additive noises.
MUXConv: Information Multiplexing in Convolutional Neural Networks
Mar 31, 2020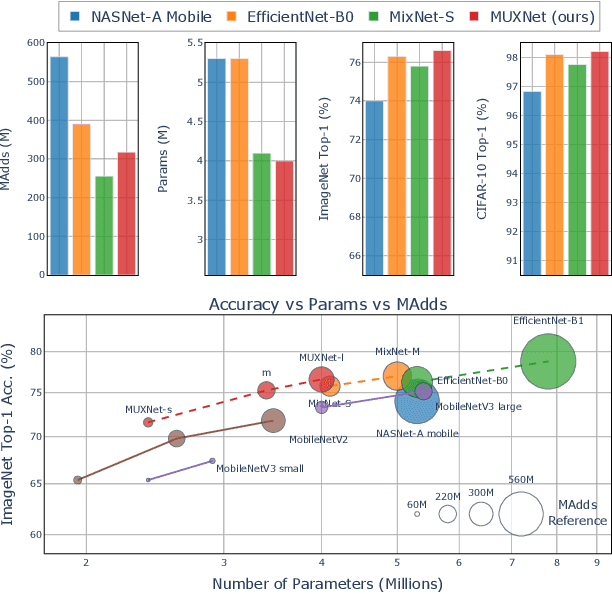
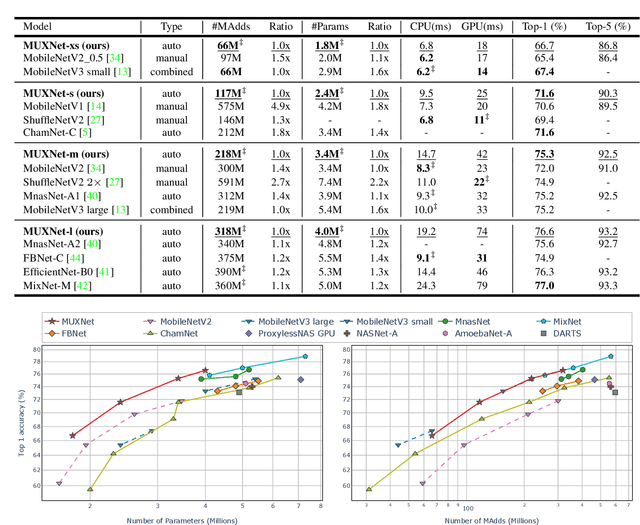
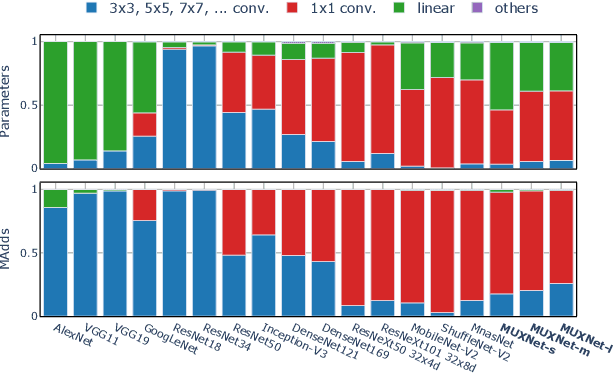
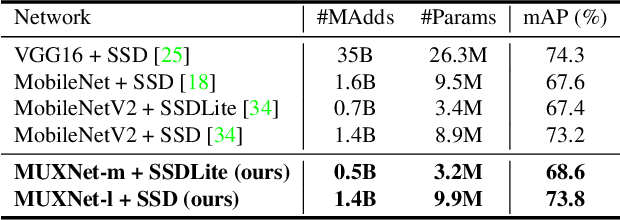
Convolutional neural networks have witnessed remarkable improvements in computational efficiency in recent years. A key driving force has been the idea of trading-off model expressivity and efficiency through a combination of $1\times 1$ and depth-wise separable convolutions in lieu of a standard convolutional layer. The price of the efficiency, however, is the sub-optimal flow of information across space and channels in the network. To overcome this limitation, we present MUXConv, a layer that is designed to increase the flow of information by progressively multiplexing channel and spatial information in the network, while mitigating computational complexity. Furthermore, to demonstrate the effectiveness of MUXConv, we integrate it within an efficient multi-objective evolutionary algorithm to search for the optimal model hyper-parameters while simultaneously optimizing accuracy, compactness, and computational efficiency. On ImageNet, the resulting models, dubbed MUXNets, match the performance (75.3% top-1 accuracy) and multiply-add operations (218M) of MobileNetV3 while being 1.6$\times$ more compact, and outperform other mobile models in all the three criteria. MUXNet also performs well under transfer learning and when adapted to object detection. On the ChestX-Ray 14 benchmark, its accuracy is comparable to the state-of-the-art while being $3.3\times$ more compact and $14\times$ more efficient. Similarly, detection on PASCAL VOC 2007 is 1.2% more accurate, 28% faster and 6% more compact compared to MobileNetV2. Code is available from https://github.com/human-analysis/MUXConv
Covariance Recovery for One-Bit Sampled Data With Time-Varying Sampling Thresholds-Part I: Stationary Signals
Mar 16, 2022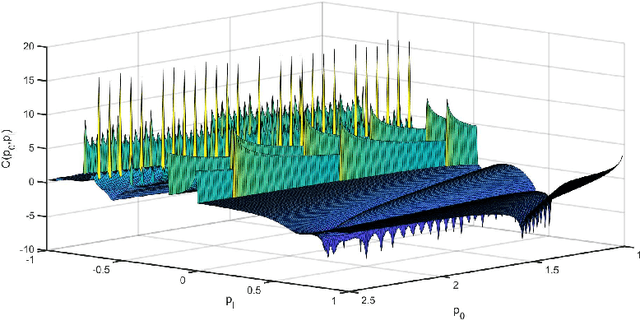
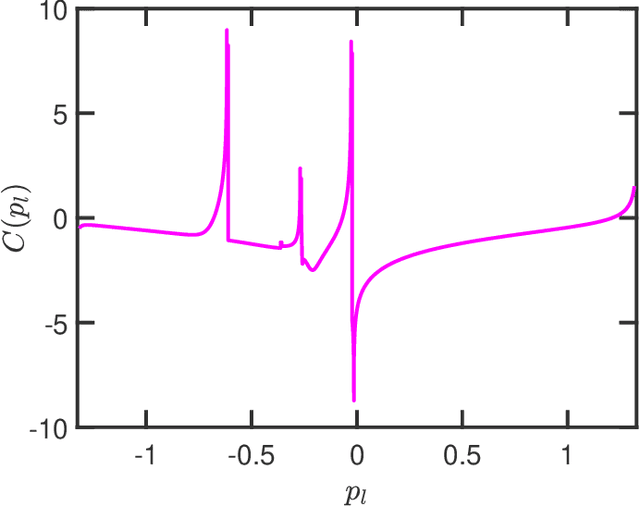
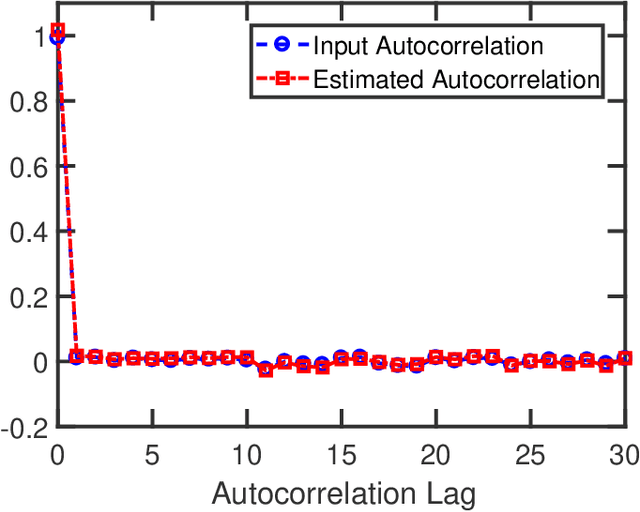
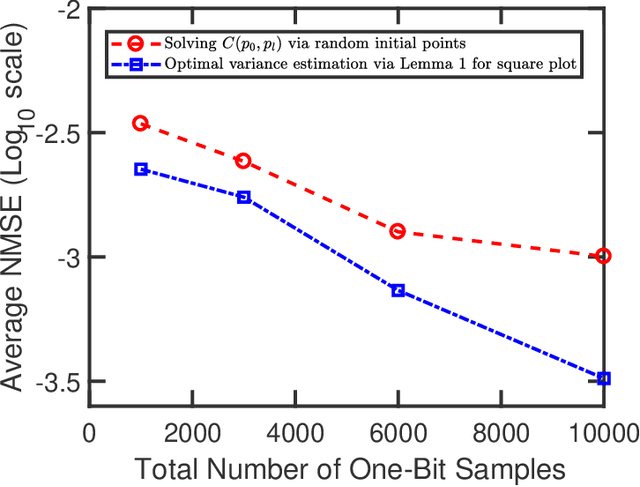
One-bit quantization, which relies on comparing the signals of interest with given threshold levels, has attracted considerable attention in signal processing for communications and sensing. A useful tool for covariance recovery in such settings is the arcsine law, that estimates the normalized covariance matrix of zero-mean stationary input signals. This relation, however, only considers a zero sampling threshold, which can cause a remarkable information loss. In this paper, the idea of the arcsine law is extended to the case where one-bit analog-to-digital converters (ADCs) apply time-varying thresholds. Specifically, three distinct approaches are proposed, investigated, and compared, to recover the autocorrelation sequence of the stationary signals of interest. Additionally, we will study a modification of the Bussgang law, a famous relation facilitating the recovery of the cross-correlation between the one-bit sampled data and the zero-mean stationary input signal. Similar to the case of the arcsine law, the Bussgang law only considers a zero sampling threshold. This relation is also extended to accommodate the more general case of time-varying thresholds for the stationary input signals.
Multifaceted Improvements for Conversational Open-Domain Question Answering
Apr 01, 2022
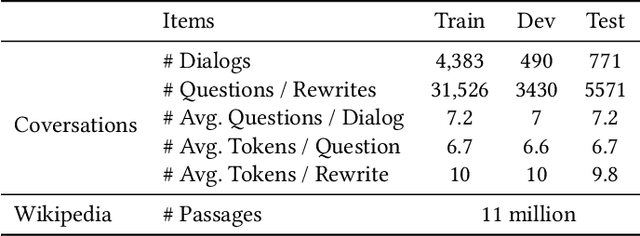
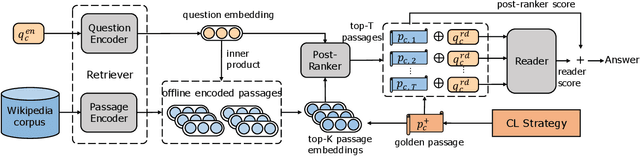
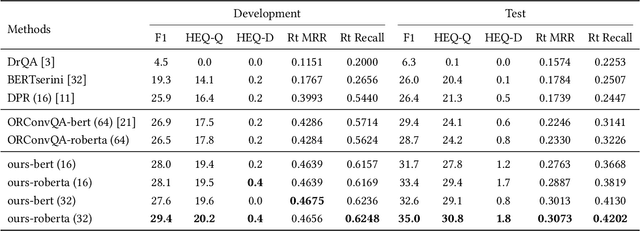
Open-domain question answering (OpenQA) is an important branch of textual QA which discovers answers for the given questions based on a large number of unstructured documents. Effectively mining correct answers from the open-domain sources still has a fair way to go. Existing OpenQA systems might suffer from the issues of question complexity and ambiguity, as well as insufficient background knowledge. Recently, conversational OpenQA is proposed to address these issues with the abundant contextual information in the conversation. Promising as it might be, there exist several fundamental limitations including the inaccurate question understanding, the coarse ranking for passage selection, and the inconsistent usage of golden passage in the training and inference phases. To alleviate these limitations, in this paper, we propose a framework with Multifaceted Improvements for Conversational open-domain Question Answering (MICQA). Specifically, MICQA has three significant advantages. First, the proposed KL-divergence based regularization is able to lead to a better question understanding for retrieval and answer reading. Second, the added post-ranker module can push more relevant passages to the top placements and be selected for reader with a two-aspect constrains. Third, the well designed curriculum learning strategy effectively narrows the gap between the golden passage settings of training and inference, and encourages the reader to find true answer without the golden passage assistance. Extensive experiments conducted on the publicly available dataset OR-QuAC demonstrate the superiority of MICQA over the state-of-the-art model in conversational OpenQA task.