 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GPTVQ: The Blessing of Dimensionality for LLM Quantization
Feb 23, 2024
In this work we show that the size versus accuracy trade-off of neural network quantization can be significantly improved by increasing the quantization dimensionality. We propose the GPTVQ method, a new fast method for post-training vector quantization (VQ) that scales well to Large Language Models (LLMs). Our method interleaves quantization of one or more columns with updates to the remaining unquantized weights, using information from the Hessian of the per-layer output reconstruction MSE. Quantization codebooks are initialized using an efficient data-aware version of the EM algorithm. The codebooks are then updated, and further compressed by using integer quantization and SVD-based compression. GPTVQ establishes a new state-of-the art in the size vs accuracy trade-offs on a wide range of LLMs such as Llama-v2 and Mistral. Furthermore, our method is efficient: on a single H100 it takes between 3 and 11 hours to process a Llamav2-70B model, depending on quantization setting. Lastly, with on-device timings for VQ decompression on a mobile CPU we show that VQ leads to improved latency compared to using a 4-bit integer format.
Deep Coupling Network For Multivariate Time Series Forecasting
Feb 23, 2024Multivariate time series (MTS) forecasting is crucial in many real-world applications. To achieve accurate MTS forecasting, it is essential to simultaneously consider both intra- and inter-series relationships among time series data. However, previous work has typically modeled intra- and inter-series relationships separately and has disregarded multi-order interactions present within and between time series data, which can seriously degrade forecasting accuracy. In this paper, we reexamine intra- and inter-series relationships from the perspective of mutual information and accordingly construct a comprehensive relationship learning mechanism tailored to simultaneously capture the intricate multi-order intra- and inter-series couplings. Based on the mechanism, we propose a novel deep coupling network for MTS forecasting, named DeepCN, which consists of a coupling mechanism dedicated to explicitly exploring the multi-order intra- and inter-series relationships among time series data concurrently, a coupled variable representation module aimed at encoding diverse variable patterns, and an inference module facilitating predictions through one forward step. Extensive experiments conducted on seven real-world datasets demonstrate that our proposed DeepCN achieves superior performance compared with the state-of-the-art baselines.
Physics-constrained polynomial chaos expansion for scientific machine learning and uncertainty quantification
Feb 23, 2024We present a novel physics-constrained polynomial chaos expansion as a surrogate modeling method capable of performing both scientific machine learning (SciML) and uncertainty quantification (UQ) tasks. The proposed method possesses a unique capability: it seamlessly integrates SciML into UQ and vice versa, which allows it to quantify the uncertainties in SciML tasks effectively and leverage SciML for improved uncertainty assessment during UQ-related tasks. The proposed surrogate model can effectively incorporate a variety of physical constraints, such as governing partial differential equations (PDEs) with associated initial and boundary conditions constraints, inequality-type constraints (e.g., monotonicity, convexity, non-negativity, among others), and additional a priori information in the training process to supplement limited data. This ensures physically realistic predictions and significantly reduces the need for expensive computational model evaluations to train the surrogate model. Furthermore, the proposed method has a built-in uncertainty quantification (UQ) feature to efficiently estimate output uncertainties. To demonstrate the effectiveness of the proposed method, we apply it to a diverse set of problems, including linear/non-linear PDEs with deterministic and stochastic parameters, data-driven surrogate modeling of a complex physical system, and UQ of a stochastic system with parameters modeled as random fields.
Multi-scale Spatio-temporal Transformer-based Imbalanced Longitudinal Learning for Glaucoma Forecasting from Irregular Time Series Images
Feb 21, 2024Glaucoma is one of the major eye diseases that leads to progressive optic nerve fiber damage and irreversible blindness, afflicting millions of individuals. Glaucoma forecast is a good solution to early screening and intervention of potential patients, which is helpful to prevent further deterioration of the disease. It leverages a series of historical fundus images of an eye and forecasts the likelihood of glaucoma occurrence in the future. However, the irregular sampling nature and the imbalanced class distribution are two challenges in the development of disease forecasting approaches. To this end, we introduce the Multi-scale Spatio-temporal Transformer Network (MST-former) based on the transformer architecture tailored for sequential image inputs, which can effectively learn representative semantic information from sequential images on both temporal and spatial dimensions. Specifically, we employ a multi-scale structure to extract features at various resolutions, which can largely exploit rich spatial information encoded in each image. Besides, we design a time distance matrix to scale time attention in a non-linear manner, which could effectively deal with the irregularly sampled data. Furthermore, we introduce a temperature-controlled Balanced Softmax Cross-entropy loss to address the class imbalance issue. Extensive experiments on the Sequential fundus Images for Glaucoma Forecast (SIGF) dataset demonstrate the superiority of the proposed MST-former method, achieving an AUC of 98.6% for glaucoma forecasting. Besides, our method shows excellent generalization capability on the Alzheimer's Disease Neuroimaging Initiative (ADNI) MRI dataset, with an accuracy of 90.3% for mild cognitive impairment and Alzheimer's disease prediction, outperforming the compared method by a large margin.
Guiding the underwater acoustic target recognition with interpretable contrastive learning
Feb 20, 2024Recognizing underwater targets from acoustic signals is a challenging task owing to the intricate ocean environments and variable underwater channels. While deep learning-based systems have become the mainstream approach for underwater acoustic target recognition, they have faced criticism for their lack of interpretability and weak generalization performance in practical applications. In this work, we apply the class activation mapping (CAM) to generate visual explanations for the predictions of a spectrogram-based recognition system. CAM can help to understand the behavior of recognition models by highlighting the regions of the input features that contribute the most to the prediction. Our explorations reveal that recognition models tend to focus on the low-frequency line spectrum and high-frequency periodic modulation information of underwater signals. Based on the observation, we propose an interpretable contrastive learning (ICL) strategy that employs two encoders to learn from acoustic features with different emphases (line spectrum and modulation information). By imposing constraints between encoders, the proposed strategy can enhance the generalization performance of the recognition system. Our experiments demonstrate that the proposed contrastive learning approach can improve the recognition accuracy and bring significant improvements across various underwater databases.
Multimodal Clinical Trial Outcome Prediction with Large Language Models
Feb 18, 2024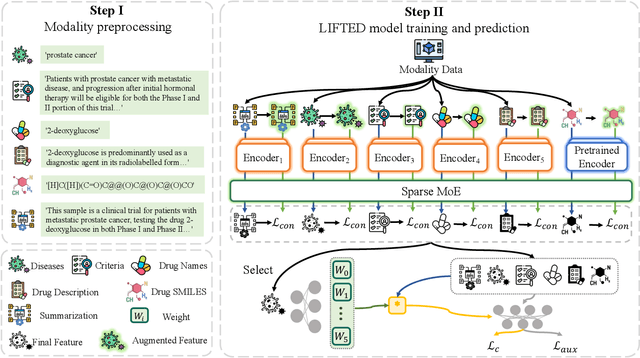
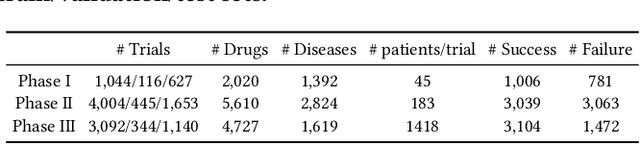
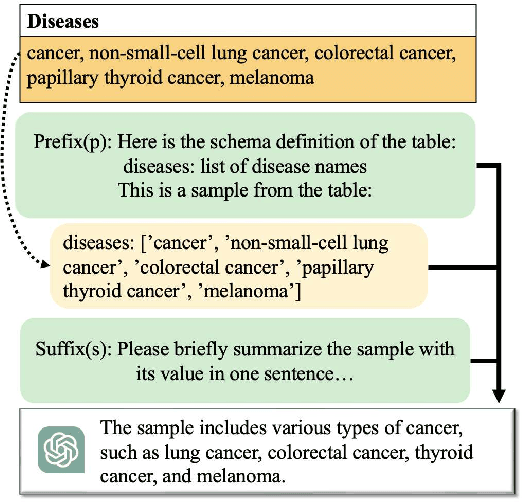
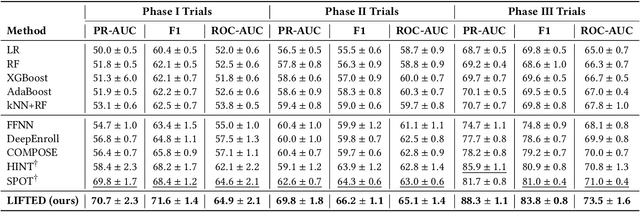
The clinical trial is a pivotal and costly process, often spanning multiple years and requiring substantial financial resources. Therefore, the development of clinical trial outcome prediction models aims to exclude drugs likely to fail and holds the potential for significant cost savings. Recent data-driven attempts leverage deep learning methods to integrate multimodal data for predicting clinical trial outcomes. However, these approaches rely on manually designed modal-specific encoders, which limits both the extensibility to adapt new modalities and the ability to discern similar information patterns across different modalities. To address these issues, we propose a multimodal mixture-of-experts (LIFTED) approach for clinical trial outcome prediction. Specifically, LIFTED unifies different modality data by transforming them into natural language descriptions. Then, LIFTED constructs unified noise-resilient encoders to extract information from modal-specific language descriptions. Subsequently, a sparse Mixture-of-Experts framework is employed to further refine the representations, enabling LIFTED to identify similar information patterns across different modalities and extract more consistent representations from those patterns using the same expert model. Finally, a mixture-of-experts module is further employed to dynamically integrate different modality representations for prediction, which gives LIFTED the ability to automatically weigh different modalities and pay more attention to critical information. The experiments demonstrate that LIFTED significantly enhances performance in predicting clinical trial outcomes across all three phases compared to the best baseline, showcasing the effectiveness of our proposed key components.
Big data analytics to classify earthwork-related locations: A Chengdu study
Feb 22, 2024Air pollution has significantly intensified, leading to severe health consequences worldwide. Earthwork-related locations (ERLs) constitute significant sources of urban dust pollution. The effective management of ERLs has long posed challenges for governmental and environmental agencies, primarily due to their classification under different regulatory authorities, information barriers, delays in data updating, and a lack of dust suppression measures for various sources of dust pollution. To address these challenges, we classified urban dust pollution sources using dump truck trajectory, urban point of interest (POI), and land cover data. We compared several prediction models and investigated the relationship between features and dust pollution sources using real data. The results demonstrate that high-accuracy classification can be achieved with a limited number of features. This method was successfully implemented in the system called Alpha MAPS in Chengdu to provide decision support for urban pollution control.
How Susceptible are Large Language Models to Ideological Manipulation?
Feb 22, 2024Large Language Models (LLMs) possess the potential to exert substantial influence on public perceptions and interactions with information. This raises concerns about the societal impact that could arise if the ideologies within these models can be easily manipulated. In this work, we investigate how effectively LLMs can learn and generalize ideological biases from their instruction-tuning data. Our findings reveal a concerning vulnerability: exposure to only a small amount of ideologically driven samples significantly alters the ideology of LLMs. Notably, LLMs demonstrate a startling ability to absorb ideology from one topic and generalize it to even unrelated ones. The ease with which LLMs' ideologies can be skewed underscores the risks associated with intentionally poisoned training data by malicious actors or inadvertently introduced biases by data annotators. It also emphasizes the imperative for robust safeguards to mitigate the influence of ideological manipulations on LLMs.
Scaffolding Coordinates to Promote Vision-Language Coordination in Large Multi-Modal Models
Feb 19, 2024State-of-the-art Large Multi-Modal Models (LMMs) have demonstrated exceptional capabilities in vision-language tasks. Despite their advanced functionalities, the performances of LMMs are still limited in challenging scenarios that require complex reasoning with multiple levels of visual information. Existing prompting techniques for LMMs focus on either improving textual reasoning or leveraging tools for image preprocessing, lacking a simple and general visual prompting scheme to promote vision-language coordination in LMMs. In this work, we propose Scaffold prompting that scaffolds coordinates to promote vision-language coordination. Specifically, Scaffold overlays a dot matrix within the image as visual information anchors and leverages multi-dimensional coordinates as textual positional references. Extensive experiments on a wide range of challenging vision-language tasks demonstrate the superiority of Scaffold over GPT-4V with the textual CoT prompting. Our code is released in https://github.com/leixy20/Scaffold.
Knowledge Graph-based Session Recommendation with Adaptive Propagation
Feb 17, 2024Session-based recommender systems (SBRSs) predict users' next interacted items based on their historical activities. While most SBRSs capture purchasing intentions locally within each session, capturing items' global information across different sessions is crucial in characterizing their general properties. Previous works capture this cross-session information by constructing graphs and incorporating neighbor information. However, this incorporation cannot vary adaptively according to the unique intention of each session, and the constructed graphs consist of only one type of user-item interaction. To address these limitations, we propose knowledge graph-based session recommendation with session-adaptive propagation. Specifically, we build a knowledge graph by connecting items with multi-typed edges to characterize various user-item interactions. Then, we adaptively aggregate items' neighbor information considering user intention within the learned session. Experimental results demonstrate that equipping our constructed knowledge graph and session-adaptive propagation enhances session recommendation backbones by 10%-20%. Moreover, we provide an industrial case study showing our proposed framework achieves 2% performance boost over an existing well-deployed model at The Home Depot e-platform.