 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Modelling variability in vibration-based PBSHM via a generalised population form
Mar 14, 2022

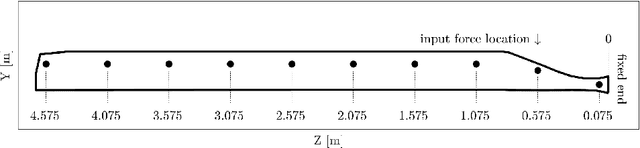

Structural health monitoring (SHM) has been an active research area for the last three decades, and has accumulated a number of critical advances over that period, as can be seen in the literature. However, SHM is still facing challenges because of the paucity of damage-state data, operational and environmental fluctuations, repeatability issues, and changes in boundary conditions. These issues present as inconsistencies in the captured features and can have a huge impact on the practical implementation, but more critically, on the generalisation of the technology. Population-based SHM has been designed to address some of these concerns by modelling and transferring missing information using data collected from groups of similar structures. In this work, vibration data were collected from four healthy, nominally-identical, full-scale composite helicopter blades. Manufacturing differences (e.g., slight differences in geometry and/or material properties), among the blades presented as variability in their structural dynamics, which can be very problematic for SHM based on machine learning from vibration data. This work aims to address this variability by defining a general model for the frequency response functions of the blades, called a form, using mixtures of Gaussian processes.
Improving Urban Mobility: using artificial intelligence and new technologies to connect supply and demand
Mar 18, 2022
As the demand for mobility in our society seems to increase, the various issues centered on urban mobility are among those that worry most city inhabitants in this planet. For instance, how to go from A to B in an efficient (but also less stressful) way? These questions and concerns have not changed even during the covid-19 pandemic; on the contrary, as the current stand, people who are avoiding public transportation are only contributing to an increase in the vehicular traffic. The are of intelligent transportation systems (ITS) aims at investigating how to employ information and communication technologies to problems related to transportation. This may mean monitoring and managing the infrastructure (e.g., traffic roads, traffic signals, etc.). However, currently, ITS is also targeting the management of demand. In this panorama, artificial intelligence plays an important role, especially with the advances in machine learning that translates in the use of computational vision, connected and autonomous vehicles, agent-based simulation, among others. In the present work, a survey of several works developed by our group are discussed in a holistic perspective, i.e., they cover not only the supply side (as commonly found in ITS works), but also the demand side, and, in an novel perspective, the integration of both.
A Unified Multi-Task Learning Framework of Real-Time Drone Supervision for Crowd Counting
Feb 08, 2022In this paper, a novel Unified Multi-Task Learning Framework of Real-Time Drone Supervision for Crowd Counting (MFCC) is proposed, which utilizes an image fusion network architecture to fuse images from the visible and thermal infrared image, and a crowd counting network architecture to estimate the density map. The purpose of our framework is to fuse two modalities, including visible and thermal infrared images captured by drones in real-time, that exploit the complementary information to accurately count the dense population and then automatically guide the flight of the drone to supervise the dense crowd. To this end, we propose the unified multi-task learning framework for crowd counting for the first time and re-design the unified training loss functions to align the image fusion network and crowd counting network. We also design the Assisted Learning Module (ALM) to fuse the density map feature to the image fusion encoder process for learning the counting features. To improve the accuracy, we propose the Extensive Context Extraction Module (ECEM) that is based on a dense connection architecture to encode multi-receptive-fields contextual information and apply the Multi-domain Attention Block (MAB) for concerning the head region in the drone view. Finally, we apply the prediction map to automatically guide the drones to supervise the dense crowd. The experimental results on the DroneRGBT dataset show that, compared with the existing methods, ours has comparable results on objective evaluations and an easier training process.
Rebalanced Siamese Contrastive Mining for Long-Tailed Recognition
Mar 22, 2022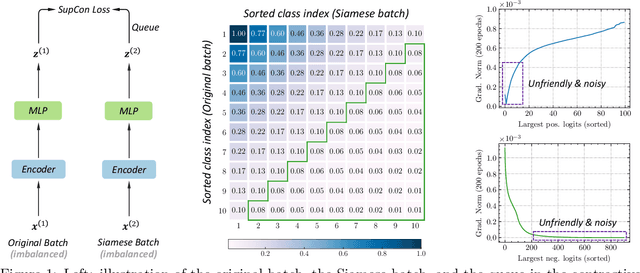
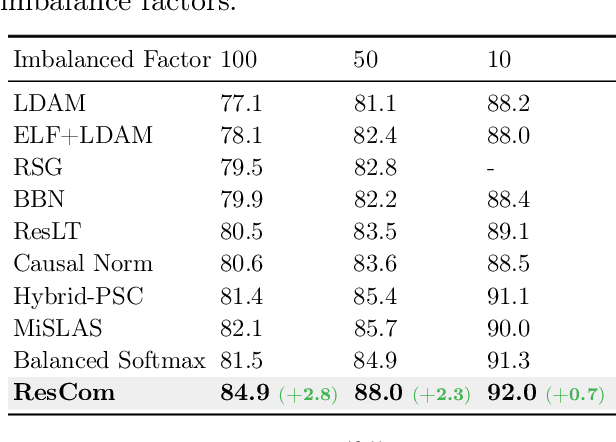
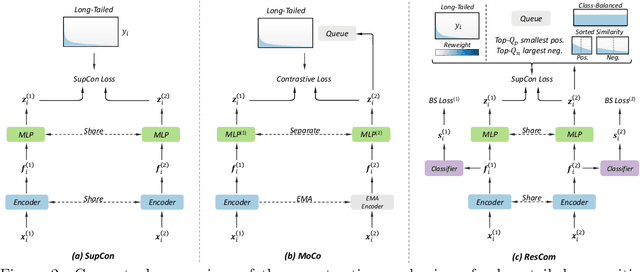
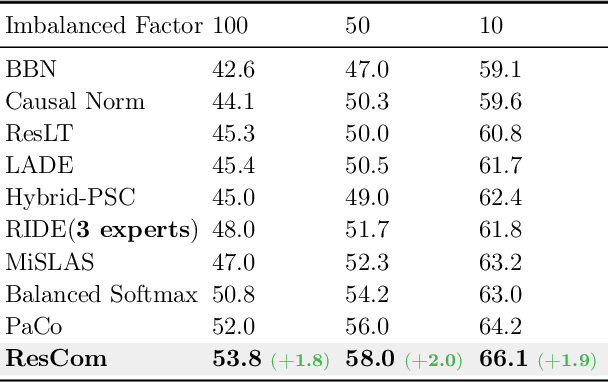
Deep neural networks perform poorly on heavily class-imbalanced datasets. Given the promising performance of contrastive learning, we propose $\mathbf{Re}$balanced $\mathbf{S}$iamese $\mathbf{Co}$ntrastive $\mathbf{m}$ining ( $\mathbf{ResCom}$) to tackle imbalanced recognition. Based on the mathematical analysis and simulation results, we claim that supervised contrastive learning suffers a dual class-imbalance problem at both the original batch and Siamese batch levels, which is more serious than long-tailed classification learning. In this paper, at the original batch level, we introduce a class-balanced supervised contrastive loss to assign adaptive weights for different classes. At the Siamese batch level, we present a class-balanced queue, which maintains the same number of keys for all classes. Furthermore, we note that the contrastive loss gradient with respect to the contrastive logits can be decoupled into the positives and negatives, and easy positives and easy negatives will make the contrastive gradient vanish. We propose supervised hard positive and negative pairs mining to pick up informative pairs for contrastive computation and improve representation learning. Finally, to approximately maximize the mutual information between the two views, we propose Siamese Balanced Softmax and joint it with the contrastive loss for one-stage training. ResCom outperforms the previous methods by large margins on multiple long-tailed recognition benchmarks. Our code will be made publicly available at: https://github.com/dvlab-research/ResCom.
Deep Gravity: enhancing mobility flows generation with deep neural networks and geographic information
Dec 30, 2020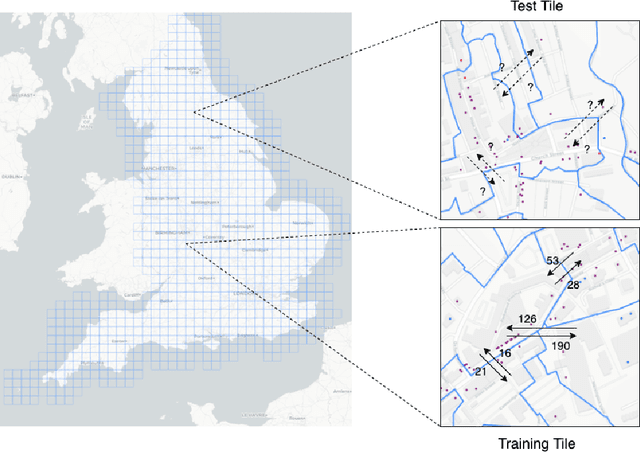
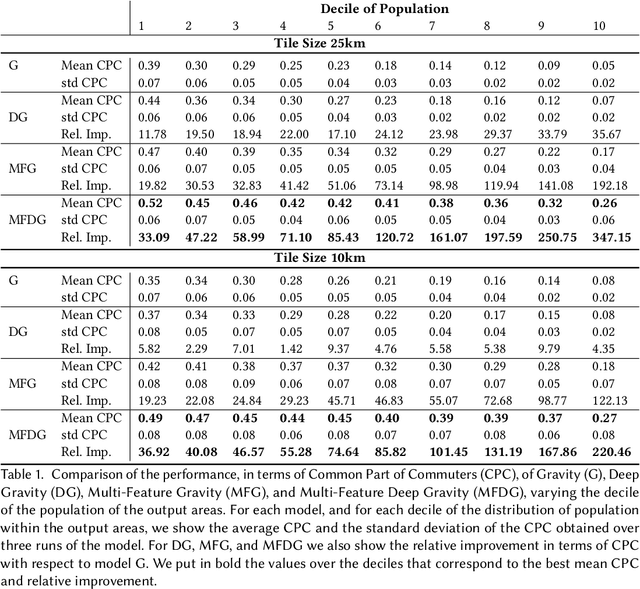
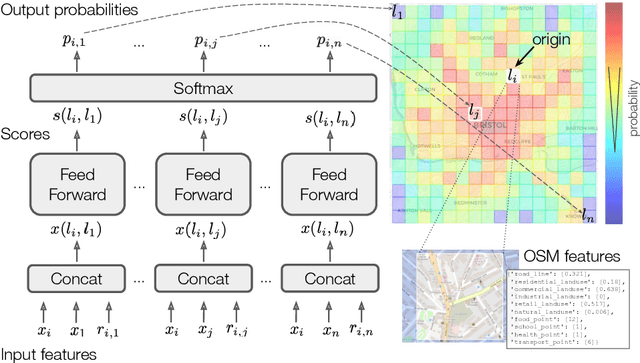
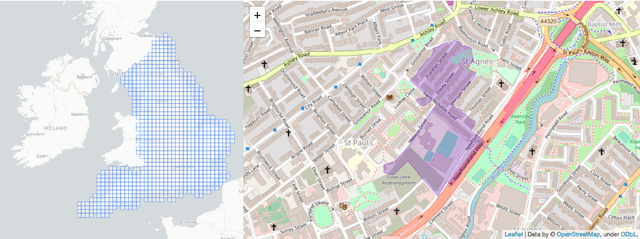
The movements of individuals within and among cities influence key aspects of our society, such as the objective and subjective well-being, the diffusion of innovations, the spreading of epidemics, and the quality of the environment. For this reason, there is increasing interest around the challenging problem of flow generation, which consists in generating the flows between a set of geographic locations, given the characteristics of the locations and without any information about the real flows. Existing solutions to flow generation are mainly based on mechanistic approaches, such as the gravity model and the radiation model, which suffer from underfitting and overdispersion, neglect important variables such as land use and the transportation network, and cannot describe non-linear relationships between these variables. In this paper, we propose the Multi-Feature Deep Gravity (MFDG) model as an effective solution to flow generation. On the one hand, the MFDG model exploits a large number of variables (e.g., characteristics of land use and the road network; transport, food, and health facilities) extracted from voluntary geographic information data (OpenStreetMap). On the other hand, our model exploits deep neural networks to describe complex non-linear relationships between those variables. Our experiments, conducted on commuting flows in England, show that the MFDG model achieves a significant increase in the performance (up to 250\% for highly populated areas) than mechanistic models that do not use deep neural networks, or that do not exploit geographic voluntary data. Our work presents a precise definition of the flow generation problem, which is a novel task for the deep learning community working with spatio-temporal data, and proposes a deep neural network model that significantly outperforms current state-of-the-art statistical models.
TransFuse: A Unified Transformer-based Image Fusion Framework using Self-supervised Learning
Jan 19, 2022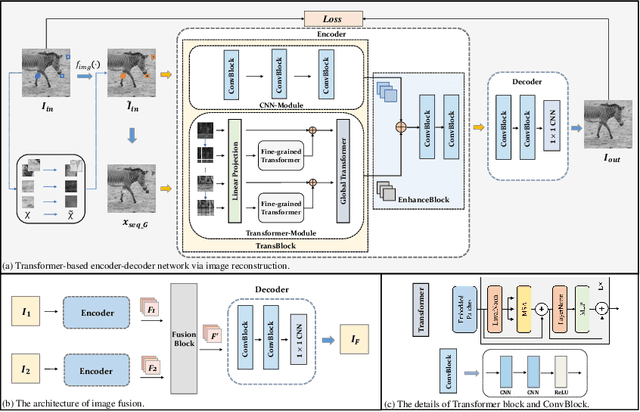
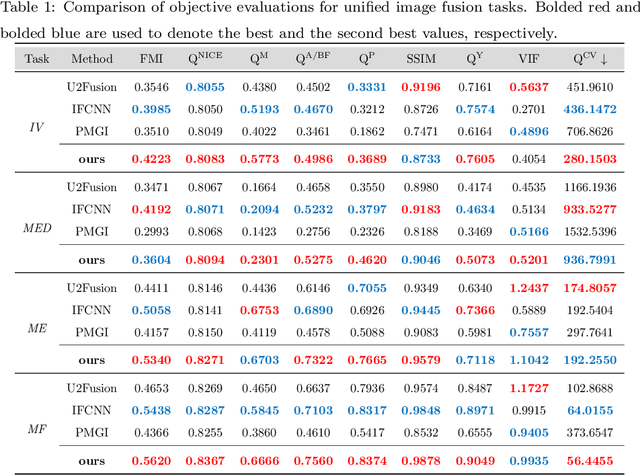
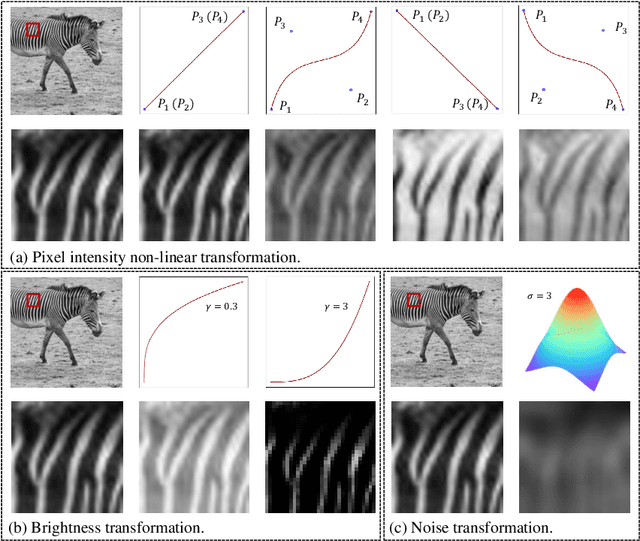
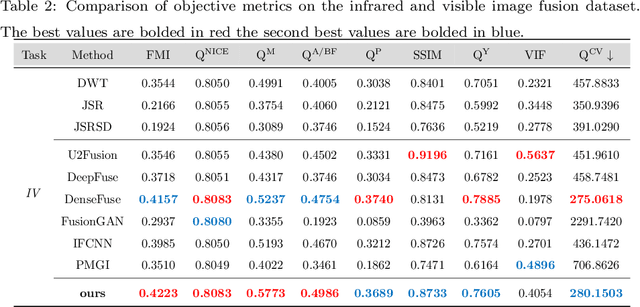
Image fusion is a technique to integrate information from multiple source images with complementary information to improve the richness of a single image. Due to insufficient task-specific training data and corresponding ground truth, most existing end-to-end image fusion methods easily fall into overfitting or tedious parameter optimization processes. Two-stage methods avoid the need of large amount of task-specific training data by training encoder-decoder network on large natural image datasets and utilizing the extracted features for fusion, but the domain gap between natural images and different fusion tasks results in limited performance. In this study, we design a novel encoder-decoder based image fusion framework and propose a destruction-reconstruction based self-supervised training scheme to encourage the network to learn task-specific features. Specifically, we propose three destruction-reconstruction self-supervised auxiliary tasks for multi-modal image fusion, multi-exposure image fusion and multi-focus image fusion based on pixel intensity non-linear transformation, brightness transformation and noise transformation, respectively. In order to encourage different fusion tasks to promote each other and increase the generalizability of the trained network, we integrate the three self-supervised auxiliary tasks by randomly choosing one of them to destroy a natural image in model training. In addition, we design a new encoder that combines CNN and Transformer for feature extraction, so that the trained model can exploit both local and global information. Extensive experiments on multi-modal image fusion, multi-exposure image fusion and multi-focus image fusion tasks demonstrate that our proposed method achieves the state-of-the-art performance in both subjective and objective evaluations. The code will be publicly available soon.
nnSpeech: Speaker-Guided Conditional Variational Autoencoder for Zero-shot Multi-speaker Text-to-Speech
Feb 22, 2022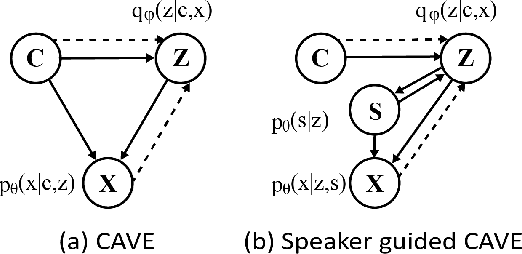
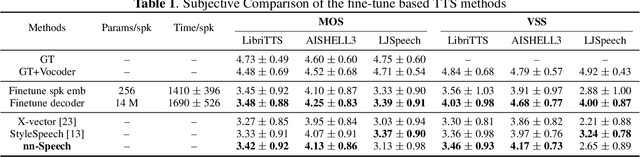
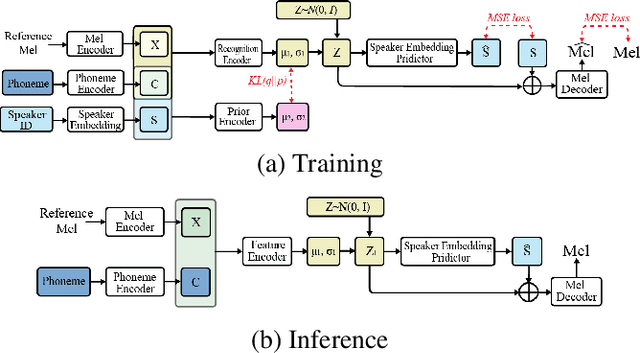
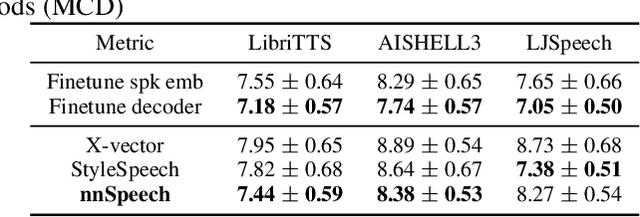
Multi-speaker text-to-speech (TTS) using a few adaption data is a challenge in practical applications. To address that, we propose a zero-shot multi-speaker TTS, named nnSpeech, that could synthesis a new speaker voice without fine-tuning and using only one adaption utterance. Compared with using a speaker representation module to extract the characteristics of new speakers, our method bases on a speaker-guided conditional variational autoencoder and can generate a variable Z, which contains both speaker characteristics and content information. The latent variable Z distribution is approximated by another variable conditioned on reference mel-spectrogram and phoneme. Experiments on the English corpus, Mandarin corpus, and cross-dataset proves that our model could generate natural and similar speech with only one adaption speech.
Modelling and Analysis of Car Following Algorithms for Fuel Economy Improvement in Connected and Autonomous Vehicles (CAVs)
Mar 25, 2022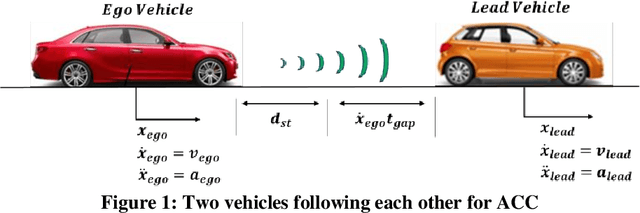
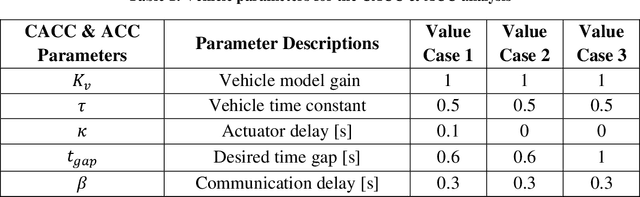
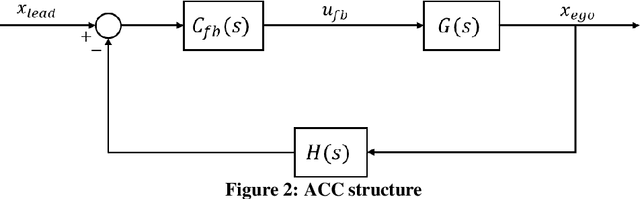

Connectivity in ground vehicles allows vehicles to share crucial vehicle data, such as vehicle acceleration, with each other. Using sensors such as cameras, radars and lidars, on the other hand, the intravehicular distance between a leader vehicle and a host vehicle can be detected, as well as the relative speed. Cooperative Adaptive Cruise Control (CACC) builds upon ground vehicle connectivity and sensor information to form convoys with automated car following. CACC can also be used to improve fuel economy and mobility performance of vehicles in the said convoy. In this paper, 3 car following algorithms for fuel economy of CAVs are presented. An Adaptive Cruise Control (ACC) algorithm was designed as the benchmark model for comparison. A Cooperative Adaptive Cruise Control (CACC) was designed, which uses lead vehicle acceleration received through V2V in car following. an Ecological Cooperative Adaptive Cruise Control (Eco-CACC) model was developed that takes the erratic lead vehicle acceleration as a disturbance to be attenuated. A High Level (HL) controller was designed for decision making when the lead vehicle was an erratic driver. Model-in-the-Loop (MIL) and Hardware-in-the-Loop (HIL) simulations were run to test these car following algorithms for fuel economy performance. The results show that the HL controller was able to attain a smooth speed profile that consumed less fuel through using CACC and Eco-CACC than its ACC counterpart when the lead vehicle was erratic.
Siamese Attribute-missing Graph Auto-encoder
Dec 09, 2021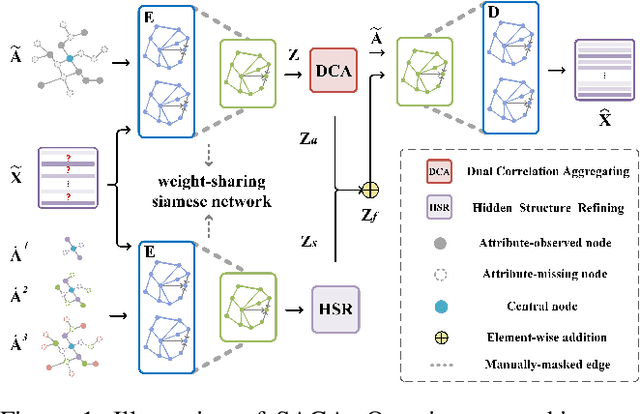
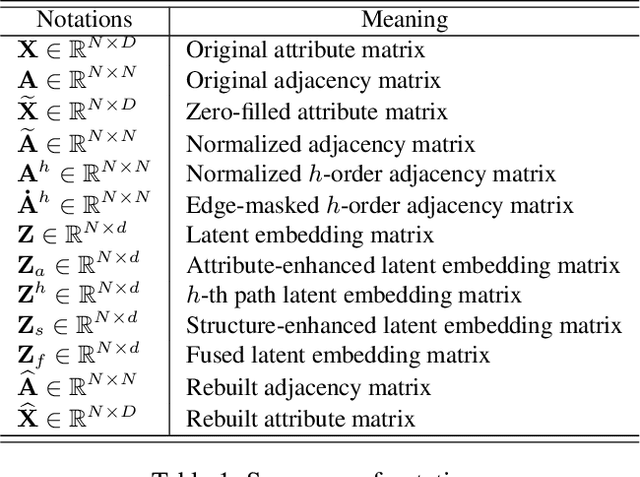
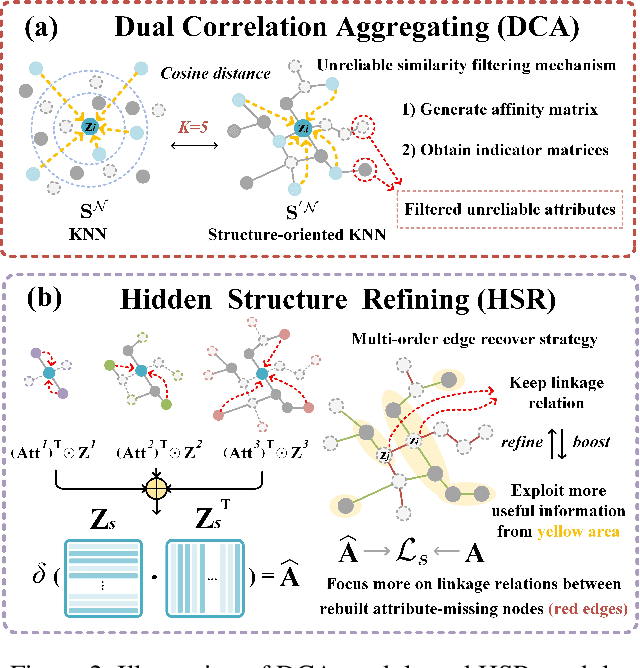
Graph representation learning (GRL) on attribute-missing graphs, which is a common yet challenging problem, has recently attracted considerable attention. We observe that existing literature: 1) isolates the learning of attribute and structure embedding thus fails to take full advantages of the two types of information; 2) imposes too strict distribution assumption on the latent space variables, leading to less discriminative feature representations. In this paper, based on the idea of introducing intimate information interaction between the two information sources, we propose our Siamese Attribute-missing Graph Auto-encoder (SAGA). Specifically, three strategies have been conducted. First, we entangle the attribute embedding and structure embedding by introducing a siamese network structure to share the parameters learned by both processes, which allows the network training to benefit from more abundant and diverse information. Second, we introduce a K-nearest neighbor (KNN) and structural constraint enhanced learning mechanism to improve the quality of latent features of the missing attributes by filtering unreliable connections. Third, we manually mask the connections on multiple adjacent matrices and force the structural information embedding sub-network to recover the true adjacent matrix, thus enforcing the resulting network to be able to selectively exploit more high-order discriminative features for data completion. Extensive experiments on six benchmark datasets demonstrate the superiority of our SAGA against the state-of-the-art methods.
TCTrack: Temporal Contexts for Aerial Tracking
Mar 05, 2022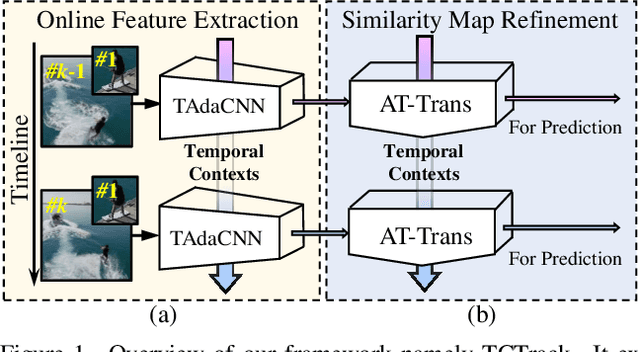
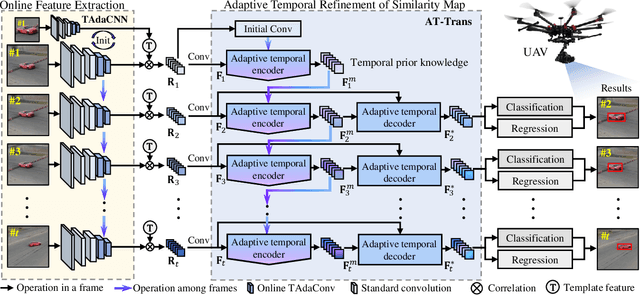
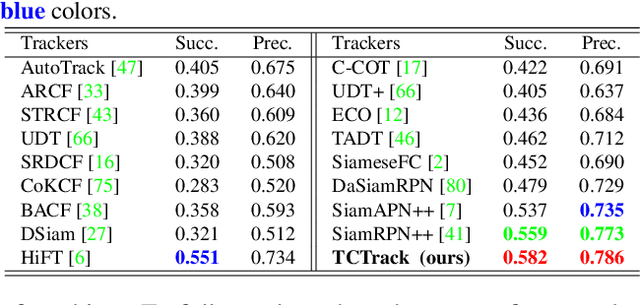
Temporal contexts among consecutive frames are far from being fully utilized in existing visual trackers. In this work, we present TCTrack, a comprehensive framework to fully exploit temporal contexts for aerial tracking. The temporal contexts are incorporated at \textbf{two levels}: the extraction of \textbf{features} and the refinement of \textbf{similarity maps}. Specifically, for feature extraction, an online temporally adaptive convolution is proposed to enhance the spatial features using temporal information, which is achieved by dynamically calibrating the convolution weights according to the previous frames. For similarity map refinement, we propose an adaptive temporal transformer, which first effectively encodes temporal knowledge in a memory-efficient way, before the temporal knowledge is decoded for accurate adjustment of the similarity map. TCTrack is effective and efficient: evaluation on four aerial tracking benchmarks shows its impressive performance; real-world UAV tests show its high speed of over 27 FPS on NVIDIA Jetson AGX Xavier.