 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Attention-based CNN-LSTM and XGBoost hybrid model for stock prediction
Apr 06, 2022
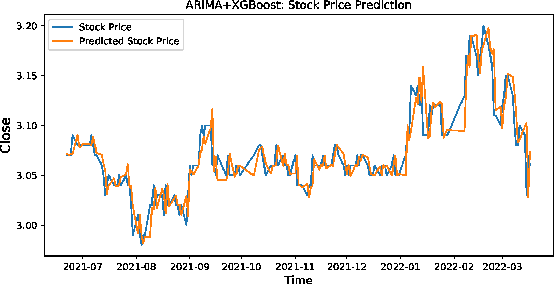
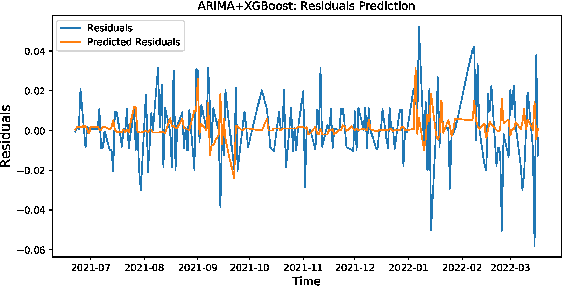
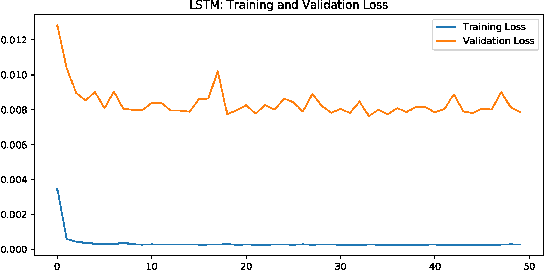
Stock market plays an important role in the economic development. Due to the complex volatility of the stock market, the research and prediction on the change of the stock price, can avoid the risk for the investors. The traditional time series model ARIMA can not describe the nonlinearity, and can not achieve satisfactory results in the stock prediction. As neural networks are with strong nonlinear generalization ability, this paper proposes an attention-based CNN-LSTM and XGBoost hybrid model to predict the stock price. The model constructed in this paper integrates the time series model, the Convolutional Neural Networks with Attention mechanism, the Long Short-Term Memory network, and XGBoost regressor in a non-linear relationship, and improves the prediction accuracy. The model can fully mine the historical information of the stock market in multiple periods. The stock data is first preprocessed through ARIMA. Then, the deep learning architecture formed in pretraining-finetuning framework is adopted. The pre-training model is the Attention-based CNN-LSTM model based on sequence-to-sequence framework. The model first uses convolution to extract the deep features of the original stock data, and then uses the Long Short-Term Memory networks to mine the long-term time series features. Finally, the XGBoost model is adopted for fine-tuning. The results show that the hybrid model is more effective and the prediction accuracy is relatively high, which can help investors or institutions to make decisions and achieve the purpose of expanding return and avoiding risk. Source code is available at https://github.com/zshicode/Attention-CLX-stock-prediction.
Transframer: Arbitrary Frame Prediction with Generative Models
Mar 18, 2022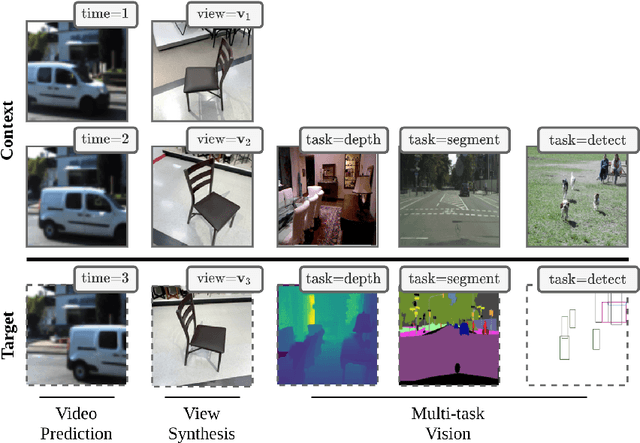

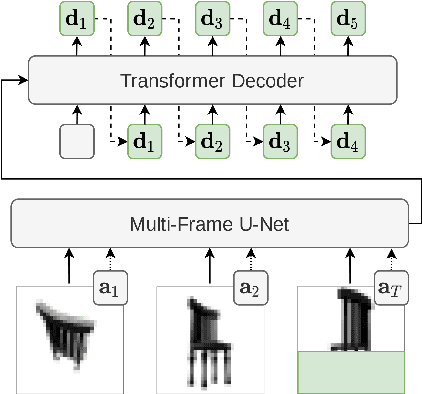

We present a general-purpose framework for image modelling and vision tasks based on probabilistic frame prediction. Our approach unifies a broad range of tasks, from image segmentation, to novel view synthesis and video interpolation. We pair this framework with an architecture we term Transframer, which uses U-Net and Transformer components to condition on annotated context frames, and outputs sequences of sparse, compressed image features. Transframer is the state-of-the-art on a variety of video generation benchmarks, is competitive with the strongest models on few-shot view synthesis, and can generate coherent 30 second videos from a single image without any explicit geometric information. A single generalist Transframer simultaneously produces promising results on 8 tasks, including semantic segmentation, image classification and optical flow prediction with no task-specific architectural components, demonstrating that multi-task computer vision can be tackled using probabilistic image models. Our approach can in principle be applied to a wide range of applications that require learning the conditional structure of annotated image-formatted data.
Knowledge Graph Augmented Network Towards Multiview Representation Learning for Aspect-based Sentiment Analysis
Jan 13, 2022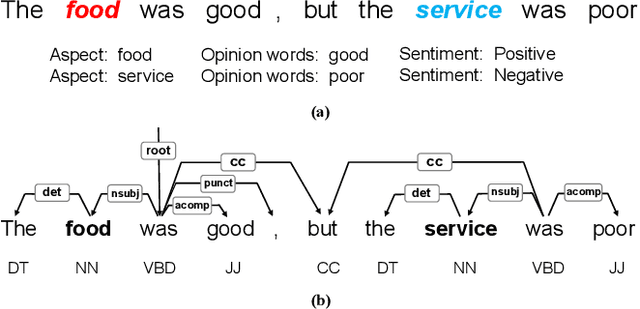
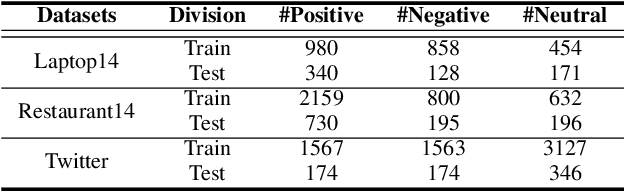
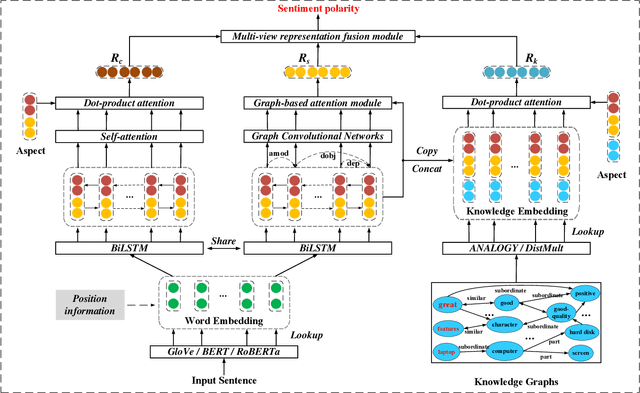
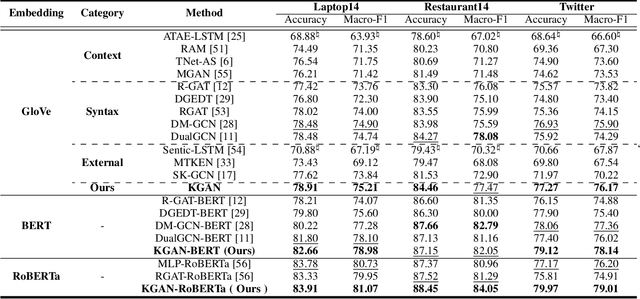
Aspect-based sentiment analysis (ABSA) is a fine-grained task of sentiment analysis. To better comprehend long complicated sentences and obtain accurate aspect-specific information, linguistic and commonsense knowledge are generally required in this task. However, most methods employ complicated and inefficient approaches to incorporate external knowledge, e.g., directly searching the graph nodes. Additionally, the complementarity between external knowledge and linguistic information has not been thoroughly studied. To this end, we propose a knowledge graph augmented network (KGAN), which aims to effectively incorporate external knowledge with explicitly syntactic and contextual information. In particular, KGAN captures the sentiment feature representations from multiple different perspectives, i.e., context-, syntax- and knowledge-based. First, KGAN learns the contextual and syntactic representations in parallel to fully extract the semantic features. Then, KGAN integrates the knowledge graphs into the embedding space, based on which the aspect-specific knowledge representations are further obtained via an attention mechanism. Last, we propose a hierarchical fusion module to complement these multiview representations in a local-to-global manner. Extensive experiments on three popular ABSA benchmarks demonstrate the effectiveness and robustness of our KGAN. Notably, with the help of the pretrained model of RoBERTa, KGAN achieves a new record of state-of-the-art performance.
Contextual Attention Mechanism, SRGAN Based Inpainting System for Eliminating Interruptions from Images
Apr 06, 2022
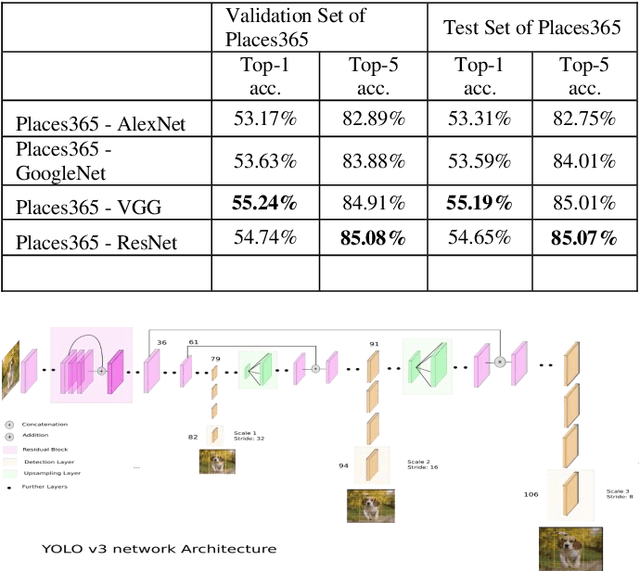
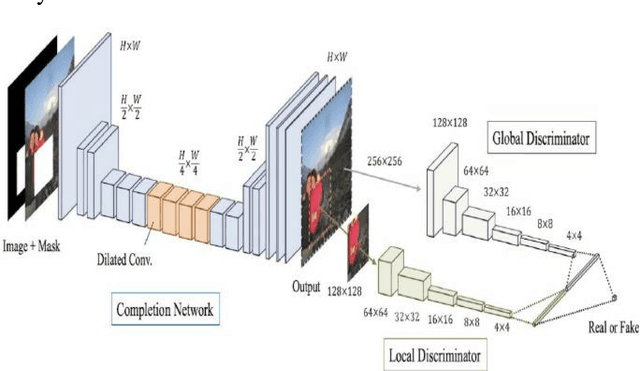
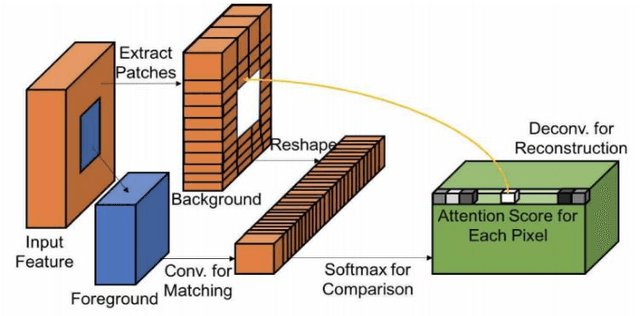
The new alternative is to use deep learning to inpaint any image by utilizing image classification and computer vision techniques. In general, image inpainting is a task of recreating or reconstructing any broken image which could be a photograph or oil/acrylic painting. With the advancement in the field of Artificial Intelligence, this topic has become popular among AI enthusiasts. With our approach, we propose an initial end-to-end pipeline for inpainting images using a complete Machine Learning approach instead of a conventional application-based approach. We first use the YOLO model to automatically identify and localize the object we wish to remove from the image. Using the result obtained from the model we can generate a mask for the same. After this, we provide the masked image and original image to the GAN model which uses the Contextual Attention method to fill in the region. It consists of two generator networks and two discriminator networks and is also called a coarse-to-fine network structure. The two generators use fully convolutional networks while the global discriminator gets hold of the entire image as input while the local discriminator gets the grip of the filled region as input. The contextual Attention mechanism is proposed to effectively borrow the neighbor information from distant spatial locations for reconstructing the missing pixels. The third part of our implementation uses SRGAN to resolve the inpainted image back to its original size. Our work is inspired by the paper Free-Form Image Inpainting with Gated Convolution and Generative Image Inpainting with Contextual Attention.
Semantic Communications: Principles and Challenges
Jan 06, 2022
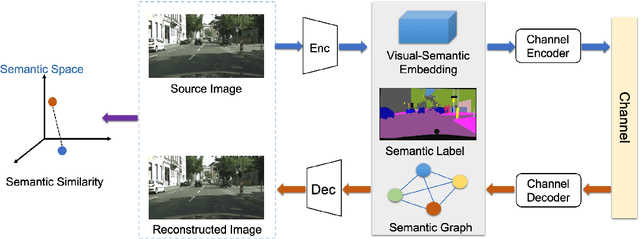
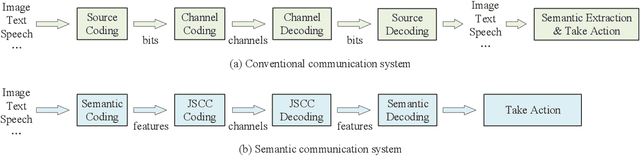
Semantic communication, regarded as the breakthrough beyond Shannon paradigm, aims at the successful transmission of semantic information conveyed by the source rather than the accurate reception of each single symbol or bit regardless of its meaning. This article provides an overview on semantic communications. After a brief review on Shannon information theory, we discuss semantic communications with theory, frameworks, and system design enabled by deep learning. Different from the symbol/bit error rate used for measuring the conventional communication systems, new performance metrics for semantic communications are also discussed. The article is concluded by several open questions.
Juggling With Representations: On the Information Transfer Between Imagery, Point Clouds, and Meshes for Multi-Modal Semantics
Mar 12, 2021

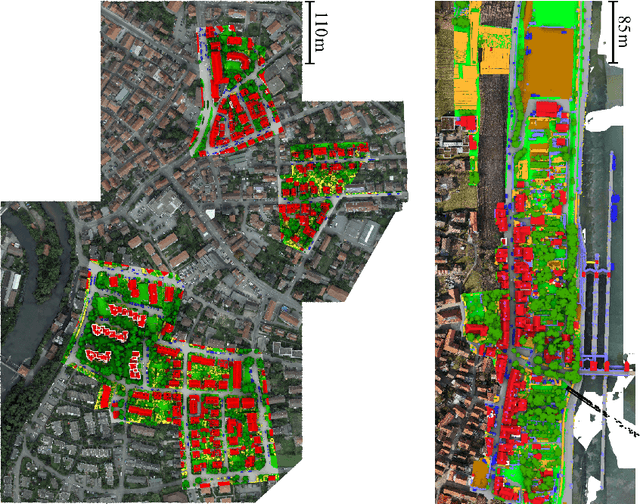
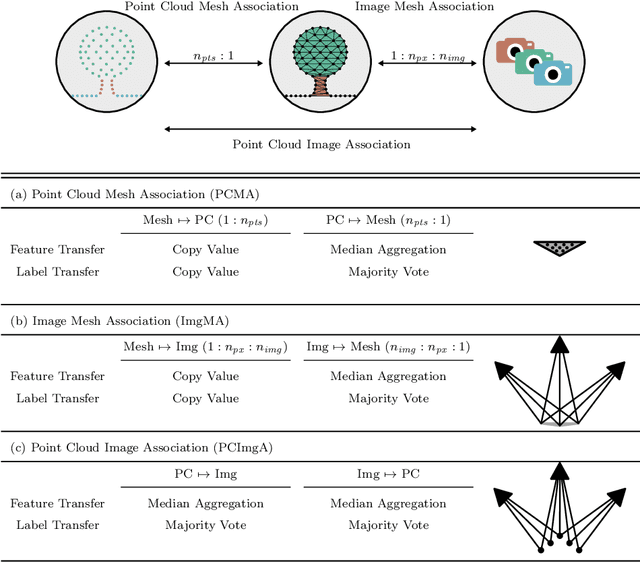
The automatic semantic segmentation of the huge amount of acquired remote sensing data has become an important task in the last decade. Images and Point Clouds (PCs) are fundamental data representations, particularly in urban mapping applications. Textured 3D meshes integrate both data representations geometrically by wiring the PC and texturing the surface elements with available imagery. We present a mesh-centered holistic geometry-driven methodology that explicitly integrates entities of imagery, PC and mesh. Due to its integrative character, we choose the mesh as the core representation that also helps to solve the visibility problem for points in imagery. Utilizing the proposed multi-modal fusion as the backbone and considering the established entity relationships, we enable the sharing of information across the modalities imagery, PC and mesh in a two-fold manner: (i) feature transfer and (ii) label transfer. By these means, we achieve to enrich feature vectors to multi-modal feature vectors for each representation. Concurrently, we achieve to label all representations consistently while reducing the manual label effort to a single representation. Consequently, we facilitate to train machine learning algorithms and to semantically segment any of these data representations - both in a multi-modal and single-modal sense. The paper presents the association mechanism and the subsequent information transfer, which we believe are cornerstones for multi-modal scene analysis. Furthermore, we discuss the preconditions and limitations of the presented approach in detail. We demonstrate the effectiveness of our methodology on the ISPRS 3D semantic labeling contest (Vaihingen 3D) and a proprietary data set (Hessigheim 3D).
Online Service Migration in Edge Computing with Incomplete Information: A Deep Recurrent Actor-Critic Method
Dec 17, 2020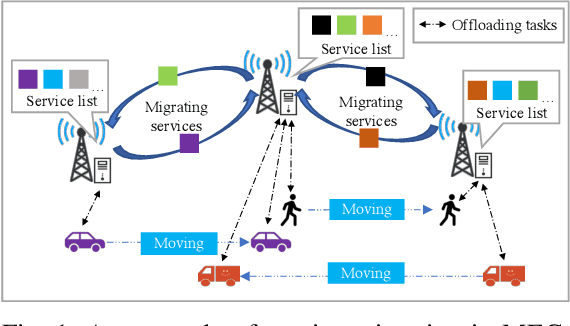
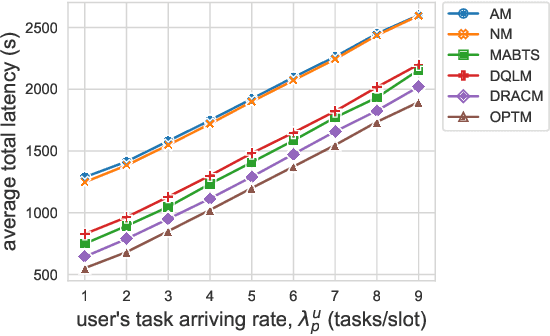
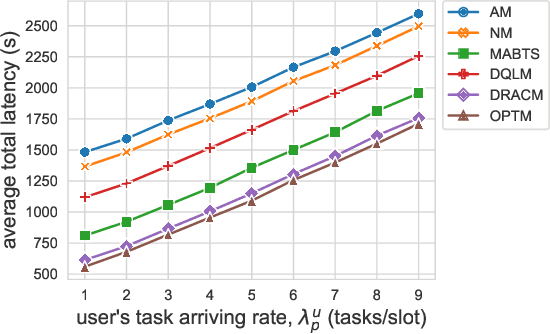
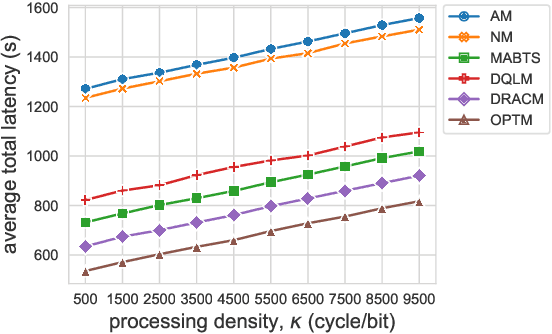
Multi-access Edge Computing (MEC) is a key technology in the fifth-generation (5G) network and beyond. MEC extends cloud computing to the network edge (e.g., base stations, MEC servers) to support emerging resource-intensive applications on mobile devices. As a crucial problem in MEC, service migration needs to decide where to migrate user services for maintaining high Quality-of-Service (QoS), when users roam between MEC servers with limited coverage and capacity. However, finding an optimal migration policy is intractable due to the highly dynamic MEC environment and user mobility. Many existing works make centralized migration decisions based on complete system-level information, which can be time-consuming and suffer from the scalability issue with the rapidly increasing number of mobile users. To address these challenges, we propose a new learning-driven method, namely Deep Recurrent Actor-Critic based service Migration (DRACM), which is user-centric and can make effective online migration decisions given incomplete system-level information. Specifically, the service migration problem is modeled as a Partially Observable Markov Decision Process (POMDP). To solve the POMDP, we design an encoder network that combines a Long Short-Term Memory (LSTM) and an embedding matrix for effective extraction of hidden information. We then propose a tailored off-policy actor-critic algorithm with a clipped surrogate objective for efficient training. Results from extensive experiments based on real-world mobility traces demonstrate that our method consistently outperforms both the heuristic and state-of-the-art learning-driven algorithms, and achieves near-optimal results on various MEC scenarios.
A Sentinel-2 multi-year, multi-country benchmark dataset for crop classification and segmentation with deep learning
Apr 02, 2022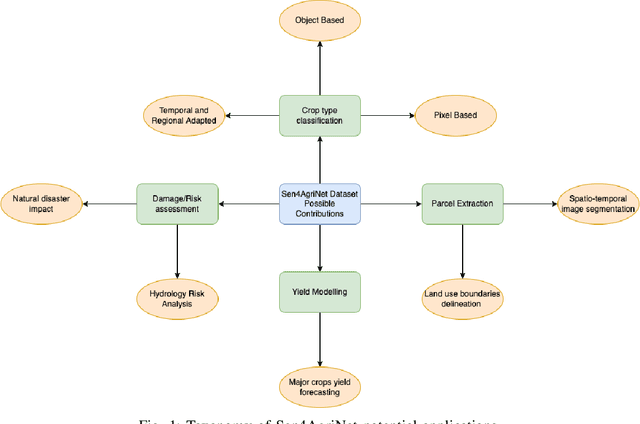
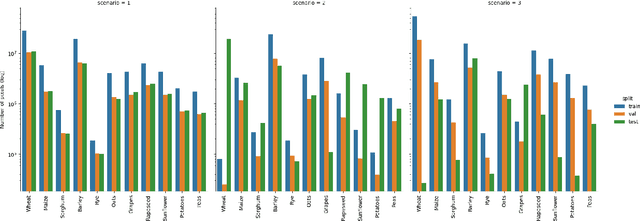
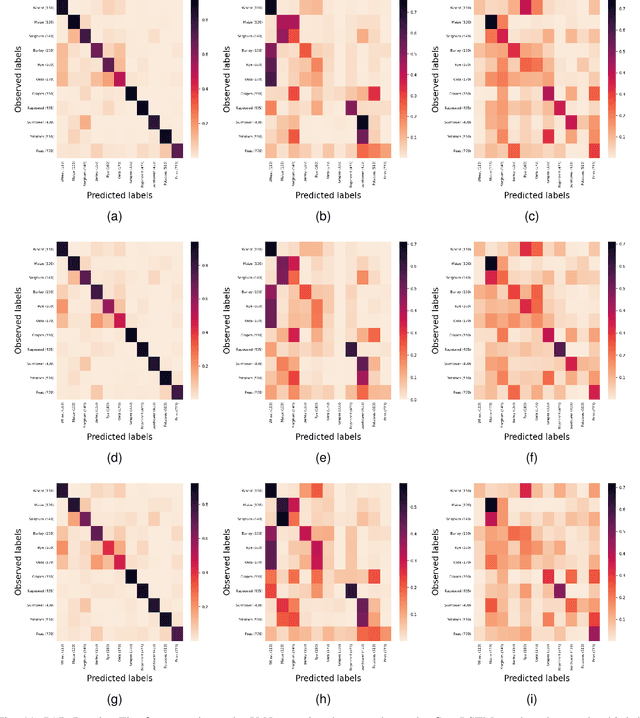
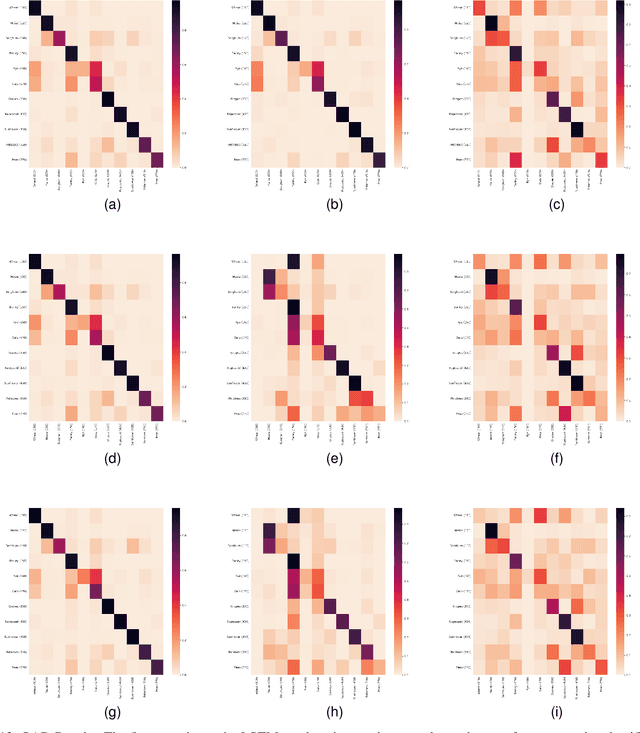
In this work we introduce Sen4AgriNet, a Sentinel-2 based time series multi country benchmark dataset, tailored for agricultural monitoring applications with Machine and Deep Learning. Sen4AgriNet dataset is annotated from farmer declarations collected via the Land Parcel Identification System (LPIS) for harmonizing country wide labels. These declarations have only recently been made available as open data, allowing for the first time the labeling of satellite imagery from ground truth data. We proceed to propose and standardise a new crop type taxonomy across Europe that address Common Agriculture Policy (CAP) needs, based on the Food and Agriculture Organization (FAO) Indicative Crop Classification scheme. Sen4AgriNet is the only multi-country, multi-year dataset that includes all spectral information. It is constructed to cover the period 2016-2020 for Catalonia and France, while it can be extended to include additional countries. Currently, it contains 42.5 million parcels, which makes it significantly larger than other available archives. We extract two sub-datasets to highlight its value for diverse Deep Learning applications; the Object Aggregated Dataset (OAD) and the Patches Assembled Dataset (PAD). OAD capitalizes zonal statistics of each parcel, thus creating a powerful label-to-features instance for classification algorithms. On the other hand, PAD structure generalizes the classification problem to parcel extraction and semantic segmentation and labeling. The PAD and OAD are examined under three different scenarios to showcase and model the effects of spatial and temporal variability across different years and different countries.
Multi-model Ensemble Analysis with Neural Network Gaussian Processes
Feb 08, 2022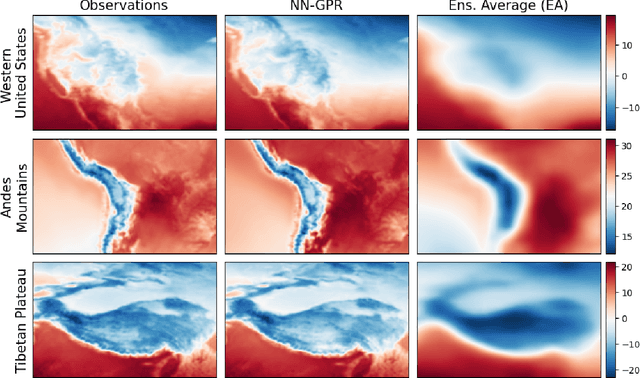
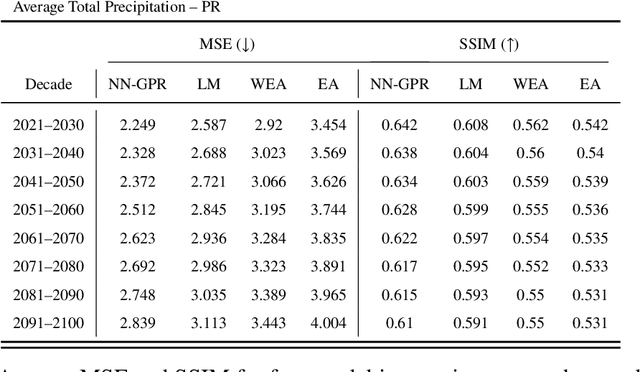
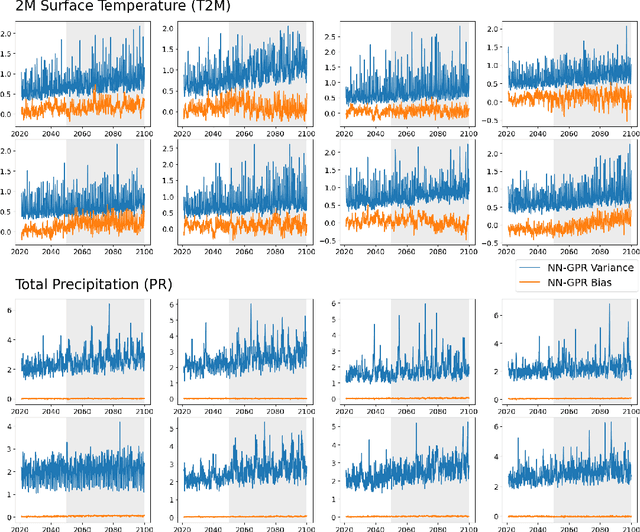
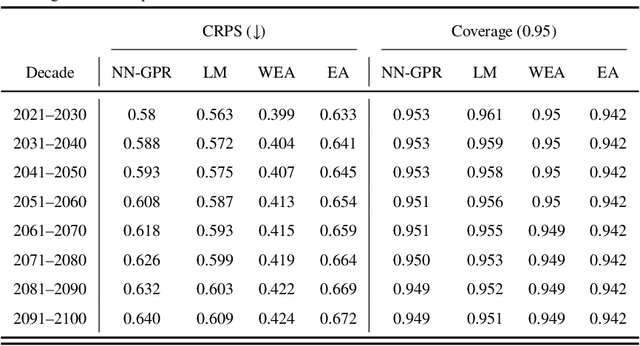
Multi-model ensemble analysis integrates information from multiple climate models into a unified projection. However, existing integration approaches based on model averaging can dilute fine-scale spatial information and incur bias from rescaling low-resolution climate models. We propose a statistical approach, called NN-GPR, using Gaussian process regression (GPR) with an infinitely wide deep neural network based covariance function. NN-GPR requires no assumptions about the relationships between models, no interpolation to a common grid, no stationarity assumptions, and automatically downscales as part of its prediction algorithm. Model experiments show that NN-GPR can be highly skillful at surface temperature and precipitation forecasting by preserving geospatial signals at multiple scales and capturing inter-annual variability. Our projections particularly show improved accuracy and uncertainty quantification skill in regions of high variability, which allows us to cheaply assess tail behavior at a 0.44$^\circ$/50 km spatial resolution without a regional climate model (RCM). Evaluations on reanalysis data and SSP245 forced climate models show that NN-GPR produces similar, overall climatologies to the model ensemble while better capturing fine scale spatial patterns. Finally, we compare NN-GPR's regional predictions against two RCMs and show that NN-GPR can rival the performance of RCMs using only global model data as input.
ECOL: Early Detection of COVID Lies Using Content, Prior Knowledge and Source Information
Jan 14, 2021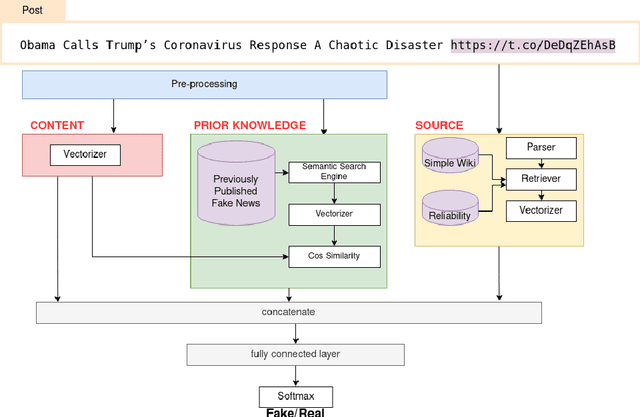
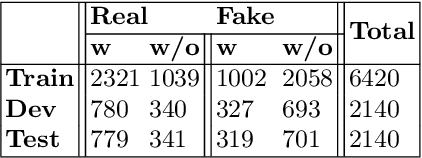
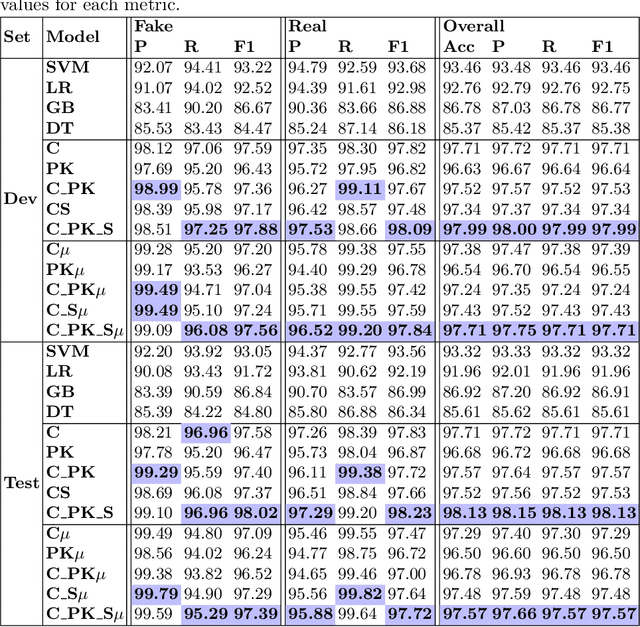
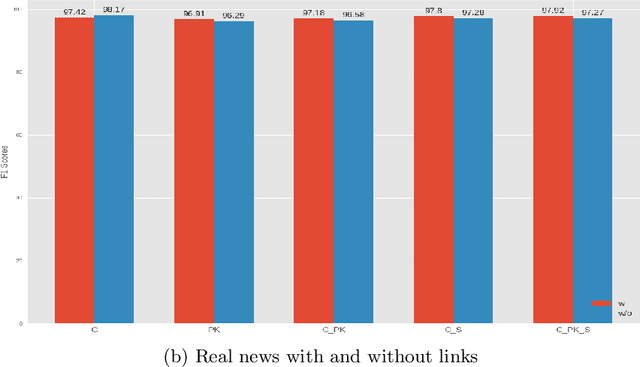
Social media platforms are vulnerable to fake news dissemination, which causes negative consequences such as panic and wrong medication in the healthcare domain. Therefore, it is important to automatically detect fake news in an early stage before they get widely spread. This paper analyzes the impact of incorporating content information, prior knowledge, and credibility of sources into models for the early detection of fake news. We propose a framework modeling those features by using BERT language model and external sources, namely Simple English Wikipedia and source reliability tags. The conducted experiments on CONSTRAINT datasets demonstrated the benefit of integrating these features for the early detection of fake news in the healthcare domain.