 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information-Theoretic Perspective of Federated Learning
Nov 15, 2019
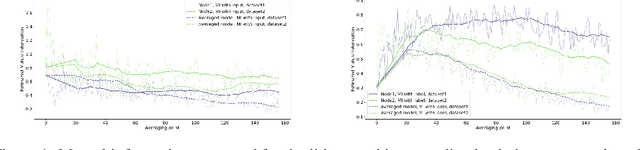
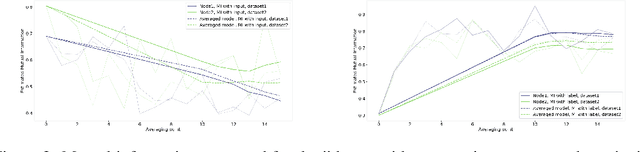
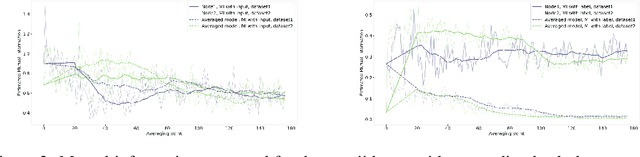
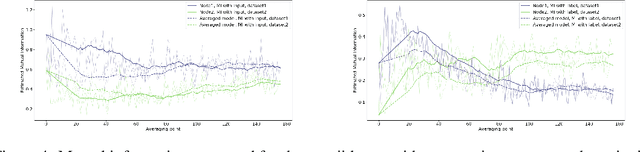
An approach to distributed machine learning is to train models on local datasets and aggregate these models into a single, stronger model. A popular instance of this form of parallelization is federated learning, where the nodes periodically send their local models to a coordinator that aggregates them and redistributes the aggregation back to continue training with it. The most frequently used form of aggregation is averaging the model parameters, e.g., the weights of a neural network. However, due to the non-convexity of the loss surface of neural networks, averaging can lead to detrimental effects and it remains an open question under which conditions averaging is beneficial. In this paper, we study this problem from the perspective of information theory: We measure the mutual information between representation and inputs as well as representation and labels in local models and compare it to the respective information contained in the representation of the averaged model. Our empirical results confirm previous observations about the practical usefulness of averaging for neural networks, even if local dataset distributions vary strongly. Furthermore, we obtain more insights about the impact of the aggregation frequency on the information flow and thus on the success of distributed learning. These insights will be helpful both in improving the current synchronization process and in further understanding the effects of model aggregation.
Occlusion-Aware Self-Supervised Monocular 6D Object Pose Estimation
Mar 19, 2022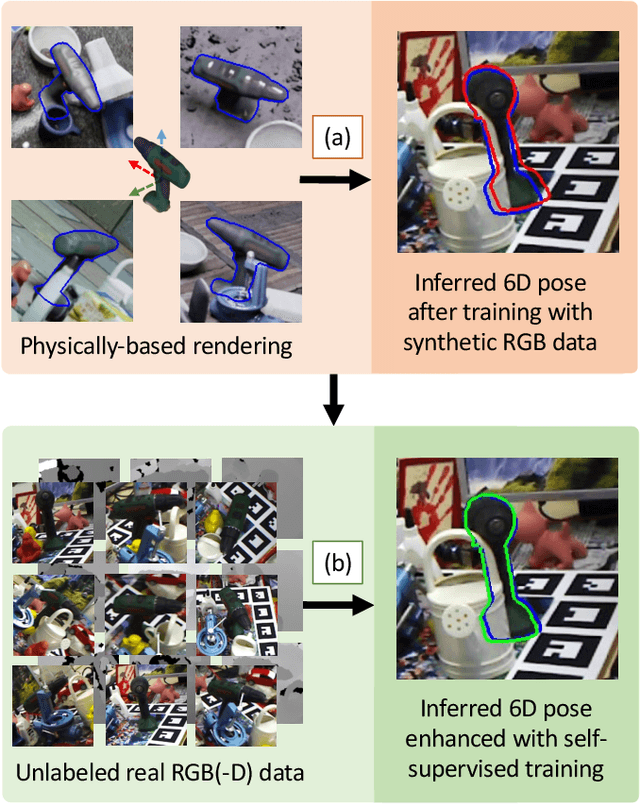

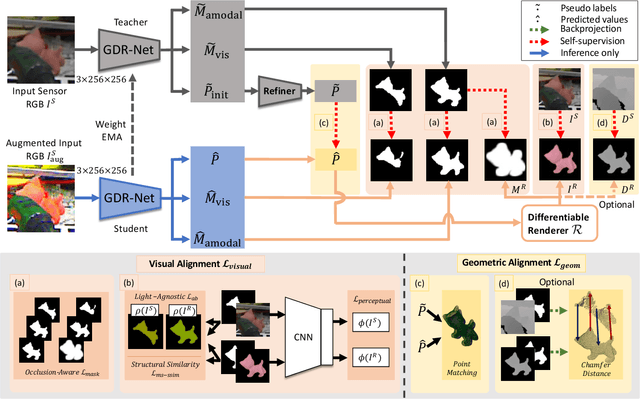

6D object pose estimation is a fundamental yet challenging problem in computer vision. Convolutional Neural Networks (CNNs) have recently proven to be capable of predicting reliable 6D pose estimates even under monocular settings. Nonetheless, CNNs are identified as being extremely data-driven, and acquiring adequate annotations is oftentimes very time-consuming and labor intensive. To overcome this limitation, we propose a novel monocular 6D pose estimation approach by means of self-supervised learning, removing the need for real annotations. After training our proposed network fully supervised with synthetic RGB data, we leverage current trends in noisy student training and differentiable rendering to further self-supervise the model on these unsupervised real RGB(-D) samples, seeking for a visually and geometrically optimal alignment. Moreover, employing both visible and amodal mask information, our self-supervision becomes very robust towards challenging scenarios such as occlusion. Extensive evaluations demonstrate that our proposed self-supervision outperforms all other methods relying on synthetic data or employing elaborate techniques from the domain adaptation realm. Noteworthy, our self-supervised approach consistently improves over its synthetically trained baseline and often almost closes the gap towards its fully supervised counterpart. The code and models are publicly available at https://github.com/THU-DA-6D-Pose-Group/self6dpp.git.
When Did It Happen? Duration-informed Temporal Localization of Narrated Actions in Vlogs
Feb 16, 2022



We consider the task of temporal human action localization in lifestyle vlogs. We introduce a novel dataset consisting of manual annotations of temporal localization for 13,000 narrated actions in 1,200 video clips. We present an extensive analysis of this data, which allows us to better understand how the language and visual modalities interact throughout the videos. We propose a simple yet effective method to localize the narrated actions based on their expected duration. Through several experiments and analyses, we show that our method brings complementary information with respect to previous methods, and leads to improvements over previous work for the task of temporal action localization.
General lower bounds for interactive high-dimensional estimation under information constraints
Oct 20, 2020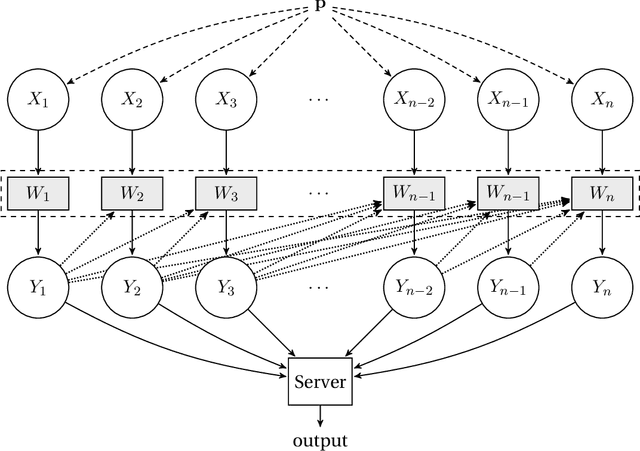


We consider the task of distributed parameter estimation using sequentially interactive protocols subject to local information constraints such as bandwidth limitations, local differential privacy, and restricted measurements. We provide a general framework enabling us to derive a variety of (tight) minimax lower bounds under different parametric families of distributions, both continuous and discrete, under any $\ell_p$ loss. Our lower bound framework is versatile, and yields "plug-and-play" bounds that are widely applicable to a large range of estimation problems. For the families considered, we further complement our lower bounds with matching upper bounds.
Multi-Robot Collaborative Perception with Graph Neural Networks
Jan 23, 2022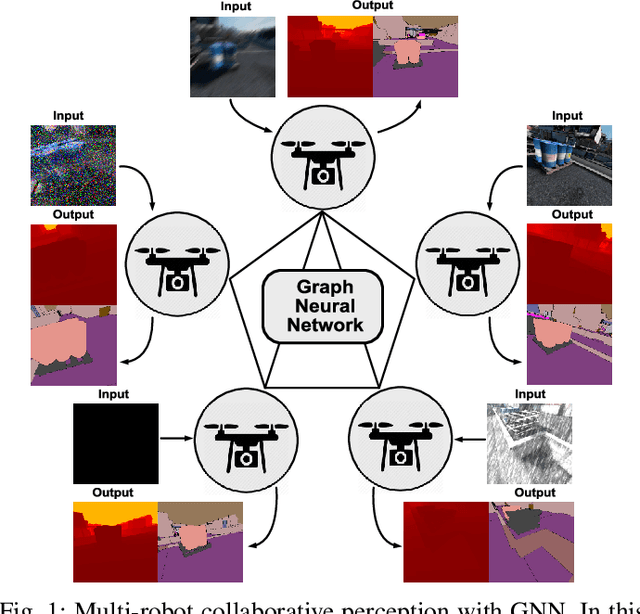

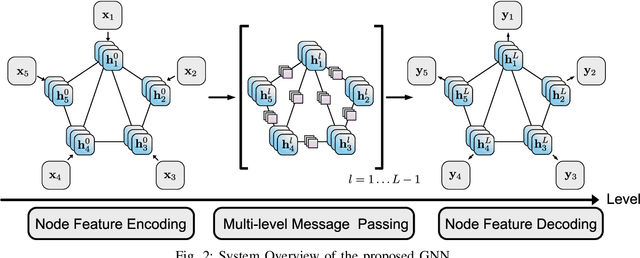
Multi-robot systems such as swarms of aerial robots are naturally suited to offer additional flexibility, resilience, and robustness in several tasks compared to a single robot by enabling cooperation among the agents. To enhance the autonomous robot decision-making process and situational awareness, multi-robot systems have to coordinate their perception capabilities to collect, share, and fuse environment information among the agents in an efficient and meaningful way such to accurately obtain context-appropriate information or gain resilience to sensor noise or failures. In this paper, we propose a general-purpose Graph Neural Network (GNN) with the main goal to increase, in multi-robot perception tasks, single robots' inference perception accuracy as well as resilience to sensor failures and disturbances. We show that the proposed framework can address multi-view visual perception problems such as monocular depth estimation and semantic segmentation. Several experiments both using photo-realistic and real data gathered from multiple aerial robots' viewpoints show the effectiveness of the proposed approach in challenging inference conditions including images corrupted by heavy noise and camera occlusions or failures.
Density-Aware Hyper-Graph Neural Networks for Graph-based Semi-supervised Node Classification
Jan 27, 2022
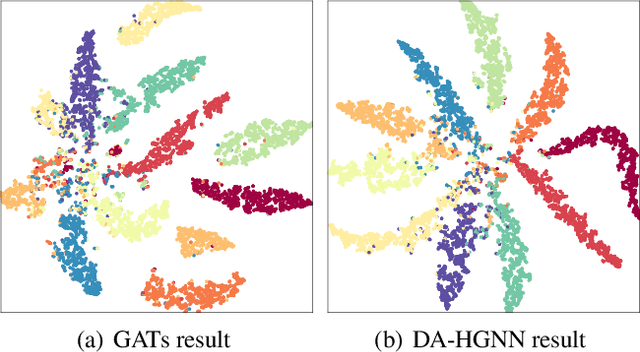
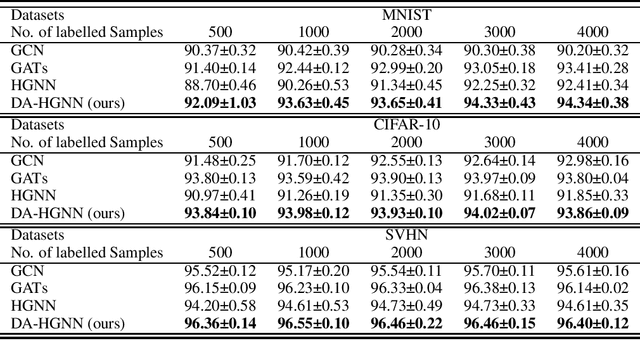

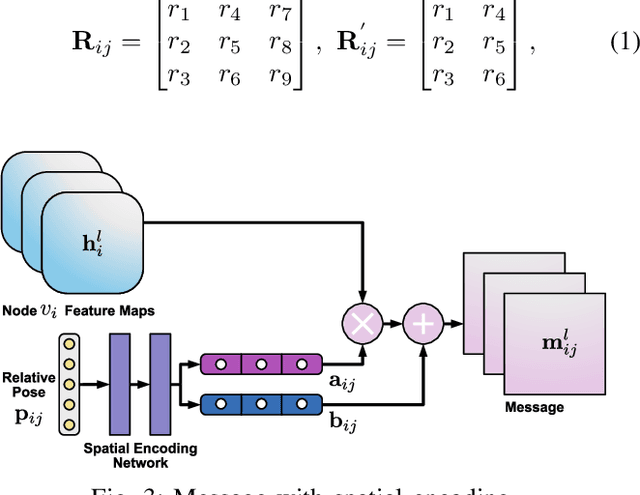
Graph-based semi-supervised learning, which can exploit the connectivity relationship between labeled and unlabeled data, has been shown to outperform the state-of-the-art in many artificial intelligence applications. One of the most challenging problems for graph-based semi-supervised node classification is how to use the implicit information among various data to improve the performance of classifying. Traditional studies on graph-based semi-supervised learning have focused on the pairwise connections among data. However, the data correlation in real applications could be beyond pairwise and more complicated. The density information has been demonstrated to be an important clue, but it is rarely explored in depth among existing graph-based semi-supervised node classification methods. To develop a flexible and effective model for graph-based semi-supervised node classification, we propose a novel Density-Aware Hyper-Graph Neural Networks (DA-HGNN). In our proposed approach, hyper-graph is provided to explore the high-order semantic correlation among data, and a density-aware hyper-graph attention network is presented to explore the high-order connection relationship. Extensive experiments are conducted in various benchmark datasets, and the results demonstrate the effectiveness of the proposed approach.
Memory-augmented Deep Unfolding Network for Guided Image Super-resolution
Feb 12, 2022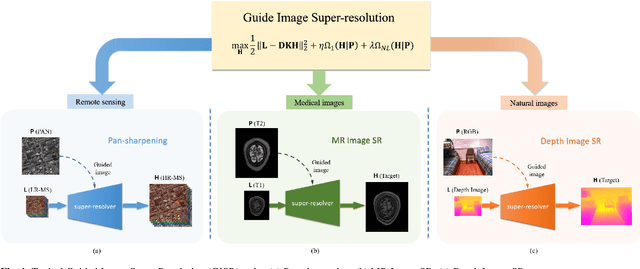
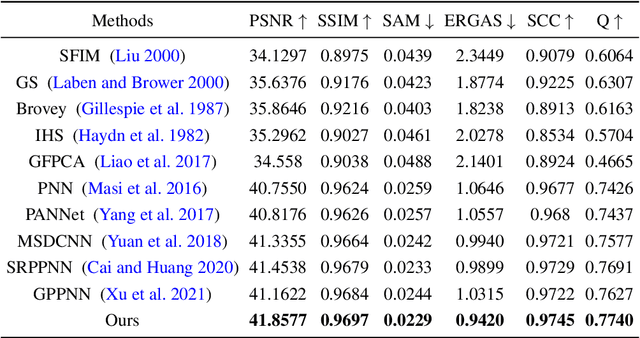
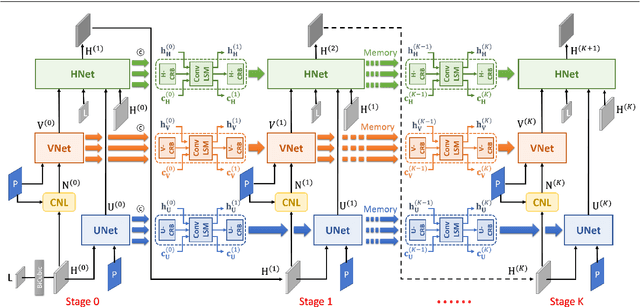
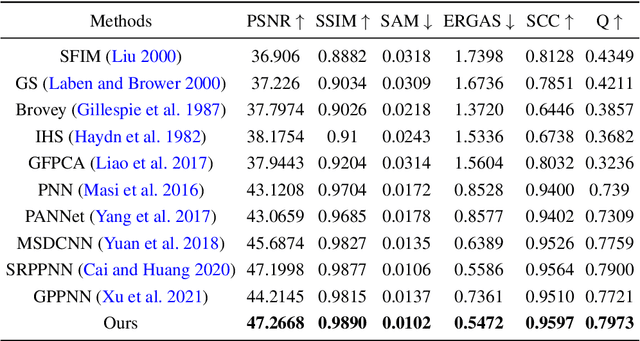
Guided image super-resolution (GISR) aims to obtain a high-resolution (HR) target image by enhancing the spatial resolution of a low-resolution (LR) target image under the guidance of a HR image. However, previous model-based methods mainly takes the entire image as a whole, and assume the prior distribution between the HR target image and the HR guidance image, simply ignoring many non-local common characteristics between them. To alleviate this issue, we firstly propose a maximal a posterior (MAP) estimation model for GISR with two types of prior on the HR target image, i.e., local implicit prior and global implicit prior. The local implicit prior aims to model the complex relationship between the HR target image and the HR guidance image from a local perspective, and the global implicit prior considers the non-local auto-regression property between the two images from a global perspective. Secondly, we design a novel alternating optimization algorithm to solve this model for GISR. The algorithm is in a concise framework that facilitates to be replicated into commonly used deep network structures. Thirdly, to reduce the information loss across iterative stages, the persistent memory mechanism is introduced to augment the information representation by exploiting the Long short-term memory unit (LSTM) in the image and feature spaces. In this way, a deep network with certain interpretation and high representation ability is built. Extensive experimental results validate the superiority of our method on a variety of GISR tasks, including Pan-sharpening, depth image super-resolution, and MR image super-resolution.
Reasoning About Generalization via Conditional Mutual Information
Jan 24, 2020We provide an information-theoretic framework for studying the generalization properties of machine learning algorithms. Our framework ties together existing approaches, including uniform convergence bounds and recent methods for adaptive data analysis. Specifically, we use Conditional Mutual Information (CMI) to quantify how well the input (i.e., the training data) can be recognized given the output (i.e., the trained model) of the learning algorithm. We show that bounds on CMI can be obtained from VC dimension, compression schemes, differential privacy, and other methods. We then show that bounded CMI implies various forms of generalization.
A comparative analysis of Graph Neural Networks and commonly used machine learning algorithms on fake news detection
Mar 26, 2022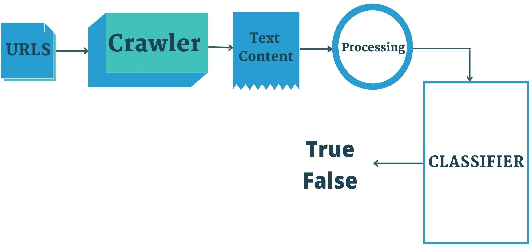
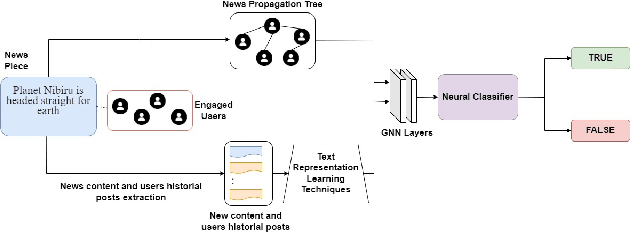
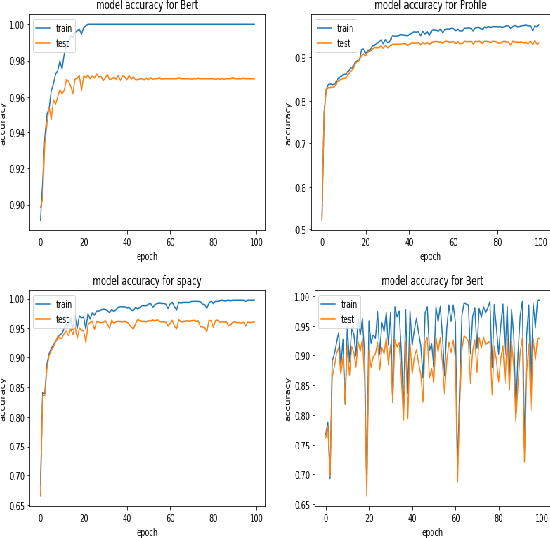
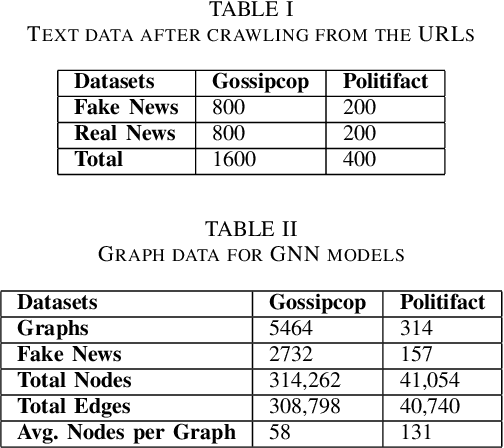
Fake news on social media is increasingly regarded as one of the most concerning issues. Low cost, simple accessibility via social platforms, and a plethora of low-budget online news sources are some of the factors that contribute to the spread of false news. Most of the existing fake news detection algorithms are solely focused on the news content only but engaged users prior posts or social activities provide a wealth of information about their views on news and have significant ability to improve fake news identification. Graph Neural Networks are a form of deep learning approach that conducts prediction on graph-described data. Social media platforms are followed graph structure in their representation, Graph Neural Network are special types of neural networks that could be usually applied to graphs, making it much easier to execute edge, node, and graph-level prediction. Therefore, in this paper, we present a comparative analysis among some commonly used machine learning algorithms and Graph Neural Networks for detecting the spread of false news on social media platforms. In this study, we take the UPFD dataset and implement several existing machine learning algorithms on text data only. Besides this, we create different GNN layers for fusing graph-structured news propagation data and the text data as the node feature in our GNN models. GNNs provide the best solutions to the dilemma of identifying false news in our research.
Logical Reasoning for Task Oriented Dialogue Systems
Feb 08, 2022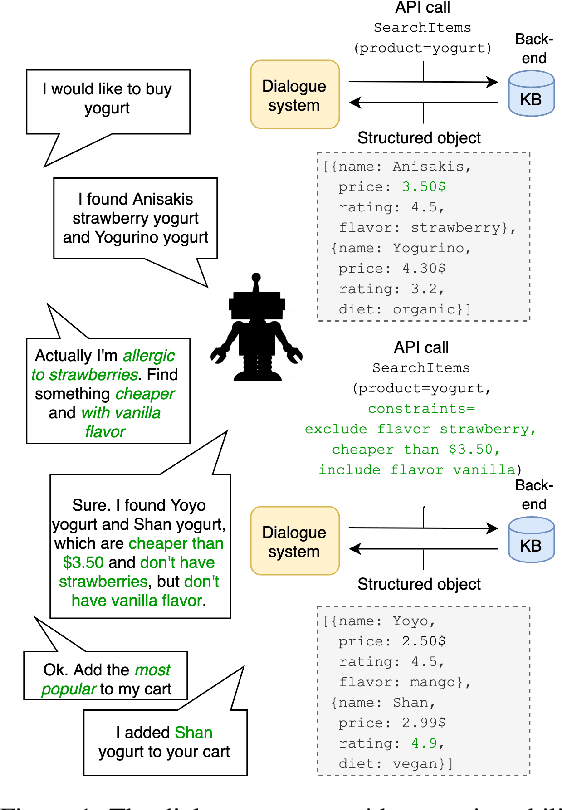

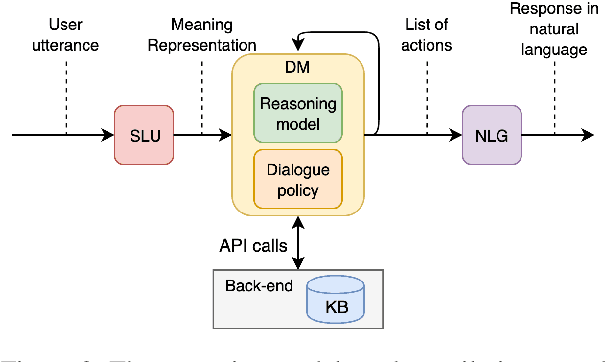

In recent years, large pretrained models have been used in dialogue systems to improve successful task completion rates. However, lack of reasoning capabilities of dialogue platforms make it difficult to provide relevant and fluent responses, unless the designers of a conversational experience spend a considerable amount of time implementing these capabilities in external rule based modules. In this work, we propose a novel method to fine-tune pretrained transformer models such as Roberta and T5. to reason over a set of facts in a given dialogue context. Our method includes a synthetic data generation mechanism which helps the model learn logical relations, such as comparison between list of numerical values, inverse relations (and negation), inclusion and exclusion for categorical attributes, and application of a combination of attributes over both numerical and categorical values, and spoken form for numerical values, without need for additional training dataset. We show that the transformer based model can perform logical reasoning to answer questions when the dialogue context contains all the required information, otherwise it is able to extract appropriate constraints to pass to downstream components (e.g. a knowledge base) when partial information is available. We observe that transformer based models such as UnifiedQA-T5 can be fine-tuned to perform logical reasoning (such as numerical and categorical attributes' comparison) over attributes that been seen in training time (e.g., accuracy of 90\%+ for comparison of smaller than $k_{\max}$=5 values over heldout test dataset).