 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pattern-Division Multiplexing for Continuous-Aperture MIMO
Mar 27, 2022
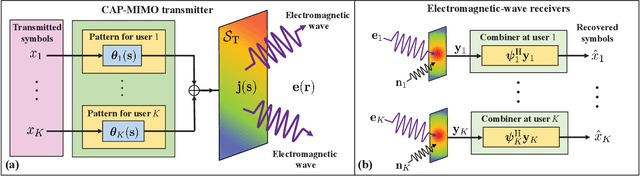
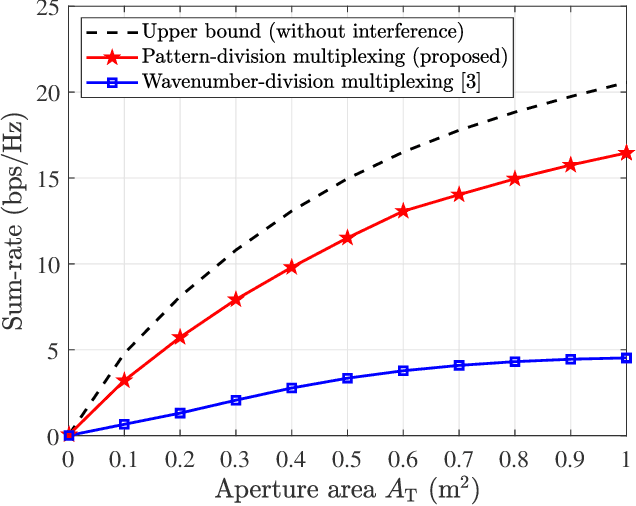
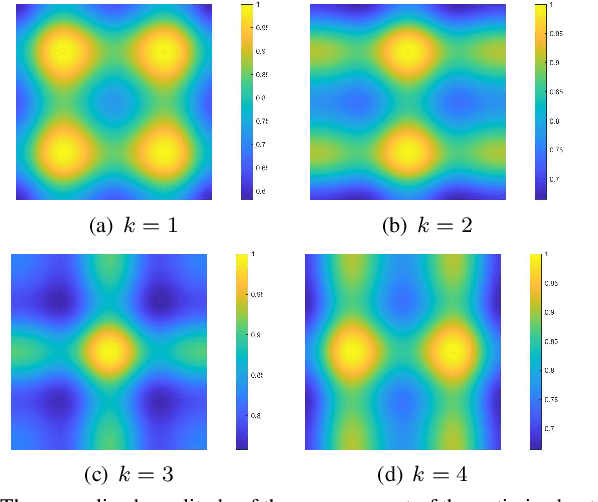
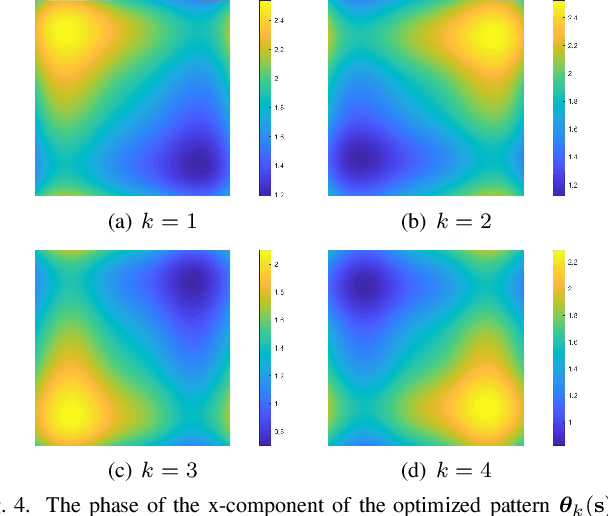
In recent years, continuous-aperture multiple-input multiple-output (CAP-MIMO) is reinvestigated to achieve improved communication performance with limited antenna apertures. Unlike the classical MIMO composed of discrete antennas, CAP-MIMO has a continuous antenna surface, which is expected to generate any current distribution (i.e., pattern) and induce controllable spatial electromagnetic waves. In this way, the information can be modulated on the electromagnetic waves, which makes it promising to approach the ultimate capacity of finite apertures. The pattern design for CAP-MIMO is the key factor to determine the communication performance, but it has not been well studied in the literature. In this paper, we propose the pattern-division multiplexing to design the patterns for CAP-MIMO. Specifically, we first derive the system model of a typical multi-user CAP-MIMO system, which allows us to formulate the sum-rate maximization problem. Then, we propose a general pattern-division multiplexing technique to transform the design of continuous pattern functions to the design of their projection lengths on finite orthogonal bases. Based on this technique, we further propose a pattern design scheme to solve the formulated sum-rate maximization problem. Simulation results show that, the sum-rate achieved by the proposed scheme is about 260% higher than that achieved by the benchmark scheme.
Know Your Surroundings: Exploiting Scene Information for Object Tracking
May 01, 2020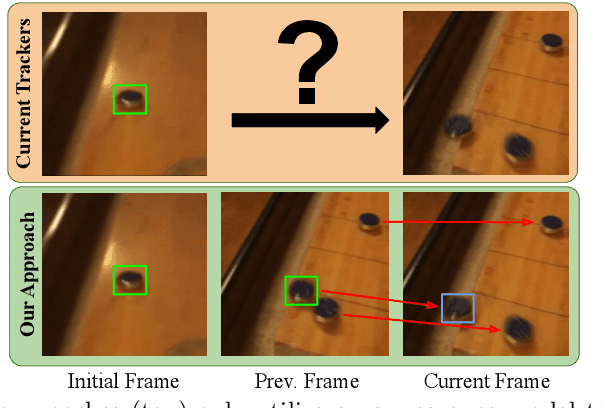

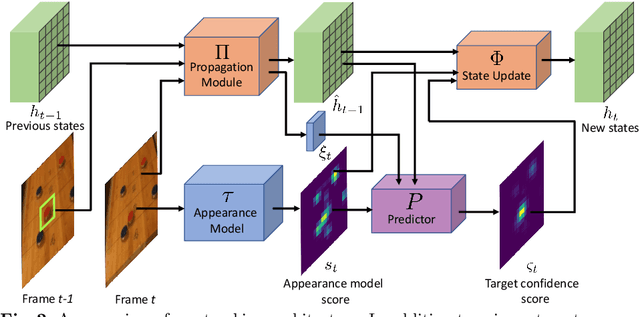

Current state-of-the-art trackers only rely on a target appearance model in order to localize the object in each frame. Such approaches are however prone to fail in case of e.g. fast appearance changes or presence of distractor objects, where a target appearance model alone is insufficient for robust tracking. Having the knowledge about the presence and locations of other objects in the surrounding scene can be highly beneficial in such cases. This scene information can be propagated through the sequence and used to, for instance, explicitly avoid distractor objects and eliminate target candidate regions. In this work, we propose a novel tracking architecture which can utilize scene information for tracking. Our tracker represents such information as dense localized state vectors, which can encode, for example, if the local region is target, background, or distractor. These state vectors are propagated through the sequence and combined with the appearance model output to localize the target. Our network is learned to effectively utilize the scene information by directly maximizing tracking performance on video segments. The proposed approach sets a new state-of-the-art on 3 tracking benchmarks, achieving an AO score of 63.6% on the recent GOT-10k dataset.
Towards a Data Privacy-Predictive Performance Trade-off
Jan 13, 2022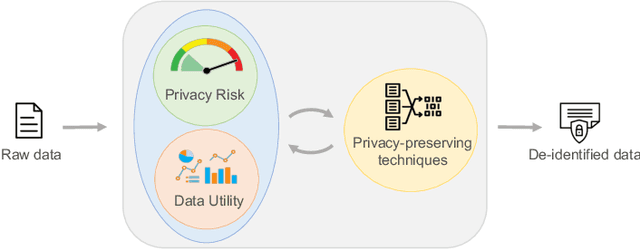
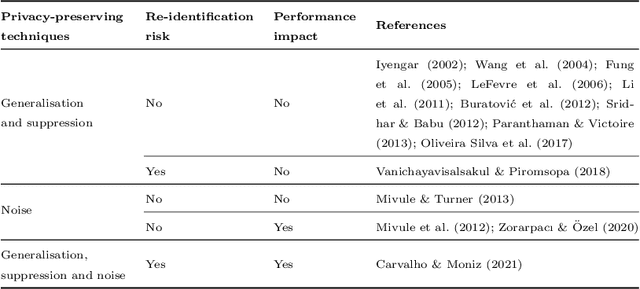
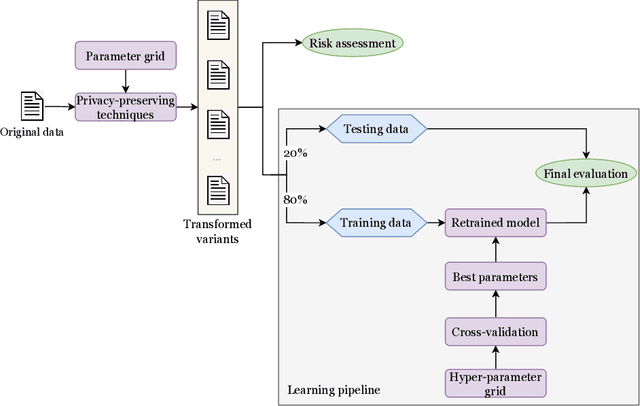
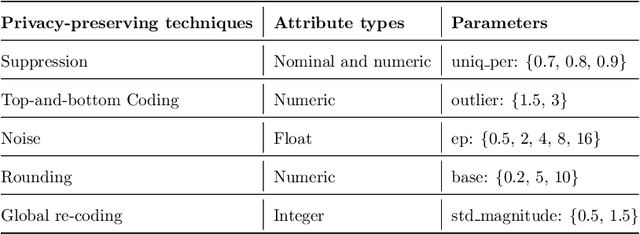
Machine learning is increasingly used in the most diverse applications and domains, whether in healthcare, to predict pathologies, or in the financial sector to detect fraud. One of the linchpins for efficiency and accuracy in machine learning is data utility. However, when it contains personal information, full access may be restricted due to laws and regulations aiming to protect individuals' privacy. Therefore, data owners must ensure that any data shared guarantees such privacy. Removal or transformation of private information (de-identification) are among the most common techniques. Intuitively, one can anticipate that reducing detail or distorting information would result in losses for model predictive performance. However, previous work concerning classification tasks using de-identified data generally demonstrates that predictive performance can be preserved in specific applications. In this paper, we aim to evaluate the existence of a trade-off between data privacy and predictive performance in classification tasks. We leverage a large set of privacy-preserving techniques and learning algorithms to provide an assessment of re-identification ability and the impact of transformed variants on predictive performance. Unlike previous literature, we confirm that the higher the level of privacy (lower re-identification risk), the higher the impact on predictive performance, pointing towards clear evidence of a trade-off.
PseudoProp: Robust Pseudo-Label Generation for Semi-Supervised Object Detection in Autonomous Driving Systems
Mar 11, 2022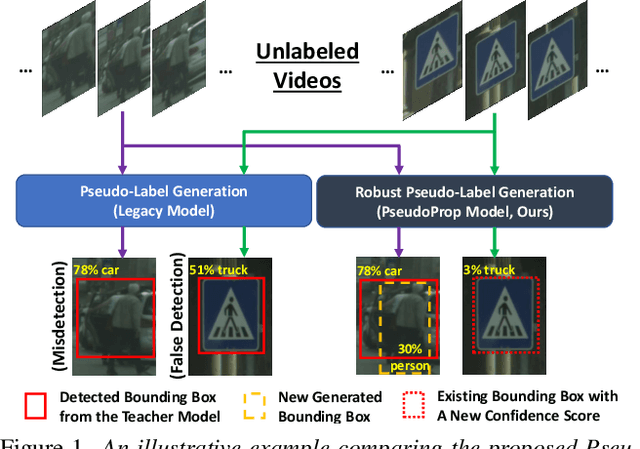
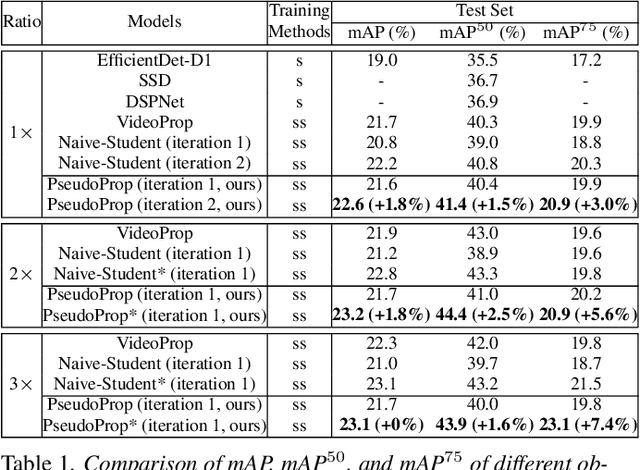
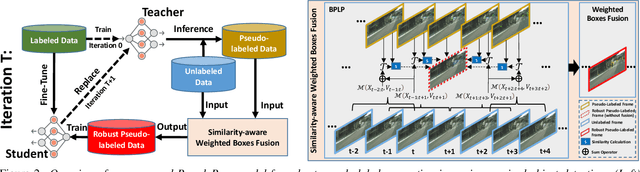
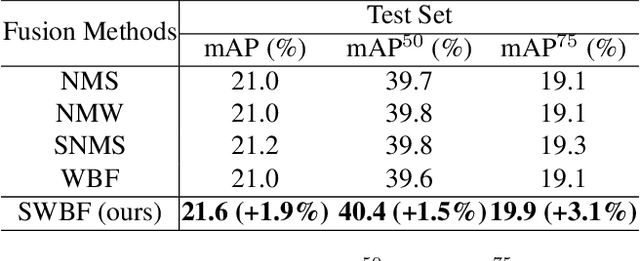
Semi-supervised object detection methods are widely used in autonomous driving systems, where only a fraction of objects are labeled. To propagate information from the labeled objects to the unlabeled ones, pseudo-labels for unlabeled objects must be generated. Although pseudo-labels have proven to improve the performance of semi-supervised object detection significantly, the applications of image-based methods to video frames result in numerous miss or false detections using such generated pseudo-labels. In this paper, we propose a new approach, PseudoProp, to generate robust pseudo-labels by leveraging motion continuity in video frames. Specifically, PseudoProp uses a novel bidirectional pseudo-label propagation approach to compensate for misdetection. A feature-based fusion technique is also used to suppress inference noise. Extensive experiments on the large-scale Cityscapes dataset demonstrate that our method outperforms the state-of-the-art semi-supervised object detection methods by 7.4% on mAP75.
TRIE: End-to-End Text Reading and Information Extraction for Document Understanding
May 27, 2020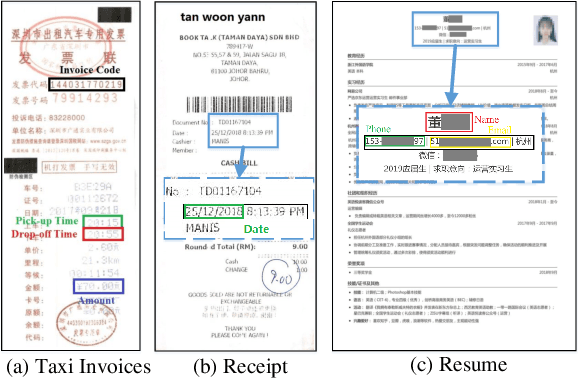
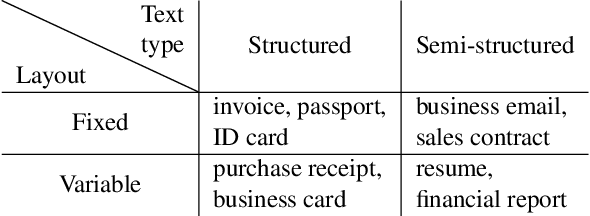
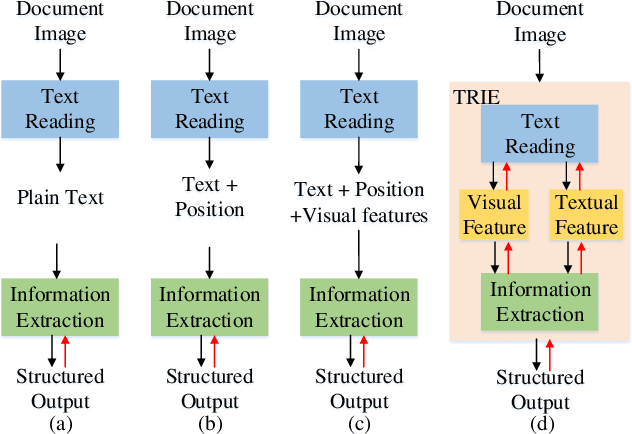
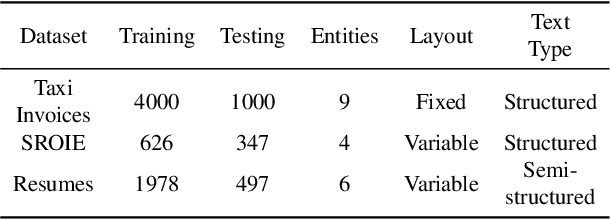
Since real-world ubiquitous documents (e.g., invoices, tickets, resumes and leaflets) contain rich information, automatic document image understanding has become a hot topic. Most existing works decouple the problem into two separate tasks, (1) text reading for detecting and recognizing texts in the images and (2) information extraction for analyzing and extracting key elements from previously extracted plain text. However, they mainly focus on improving information extraction task, while neglecting the fact that text reading and information extraction are mutually correlated. In this paper, we propose a unified end-to-end text reading and information extraction network, where the two tasks can reinforce each other. Specifically, the multimodal visual and textual features of text reading are fused for information extraction and in turn, the semantics in information extraction contribute to the optimization of text reading. On three real-world datasets with diverse document images (from fixed layout to variable layout, from structured text to semi-structured text), our proposed method significantly outperforms the state-of-the-art methods in both efficiency and accuracy.
Meta-optic Accelerators for Object Classifiers
Jan 26, 2022Rapid advances in deep learning have led to paradigm shifts in a number of fields, from medical image analysis to autonomous systems. These advances, however, have resulted in digital neural networks with large computational requirements, resulting in high energy consumption and limitations in real-time decision making when computation resources are limited. Here, we demonstrate a meta-optic based neural network accelerator that can off-load computationally expensive convolution operations into high-speed and low-power optics. In this architecture, metasurfaces enable both spatial multiplexing and additional information channels, such as polarization, in object classification. End-to-end design is used to co-optimize the optical and digital systems resulting in a robust classifier that achieves 95% accurate classification of handwriting digits and 94% accuracy in classifying both the digit and its polarization state. This approach could enable compact, high-speed, and low-power image and information processing systems for a wide range of applications in machine-vision and artificial intelligence.
Graph-based Active Learning for Semi-supervised Classification of SAR Data
Mar 31, 2022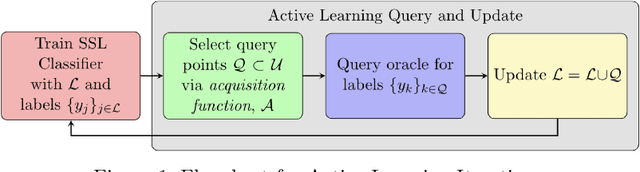
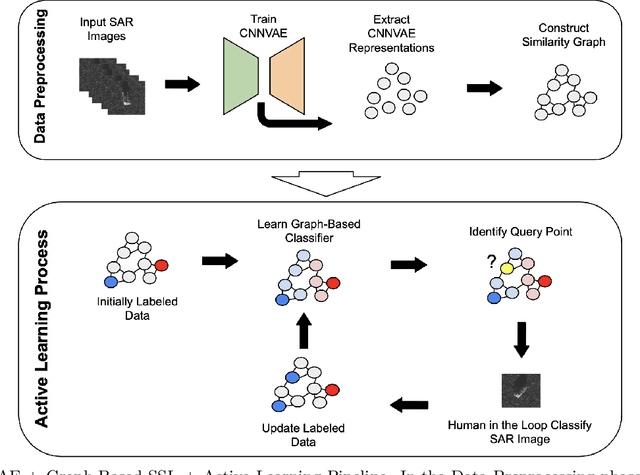

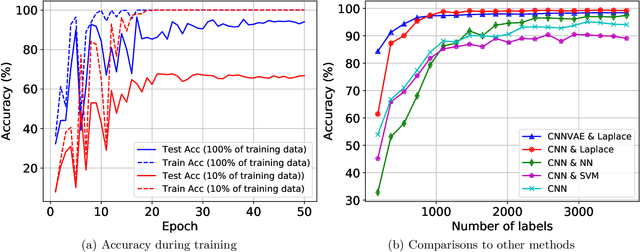
We present a novel method for classification of Synthetic Aperture Radar (SAR) data by combining ideas from graph-based learning and neural network methods within an active learning framework. Graph-based methods in machine learning are based on a similarity graph constructed from the data. When the data consists of raw images composed of scenes, extraneous information can make the classification task more difficult. In recent years, neural network methods have been shown to provide a promising framework for extracting patterns from SAR images. These methods, however, require ample training data to avoid overfitting. At the same time, such training data are often unavailable for applications of interest, such as automatic target recognition (ATR) and SAR data. We use a Convolutional Neural Network Variational Autoencoder (CNNVAE) to embed SAR data into a feature space, and then construct a similarity graph from the embedded data and apply graph-based semi-supervised learning techniques. The CNNVAE feature embedding and graph construction requires no labeled data, which reduces overfitting and improves the generalization performance of graph learning at low label rates. Furthermore, the method easily incorporates a human-in-the-loop for active learning in the data-labeling process. We present promising results and compare them to other standard machine learning methods on the Moving and Stationary Target Acquisition and Recognition (MSTAR) dataset for ATR with small amounts of labeled data.
Robust Real-time LiDAR-inertial Initialization
Mar 27, 2022
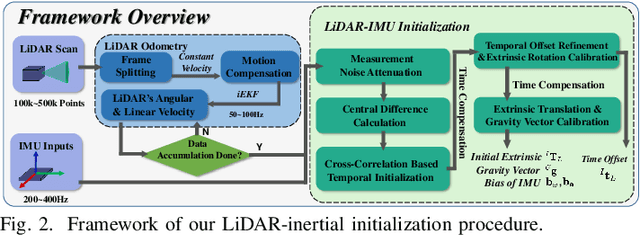

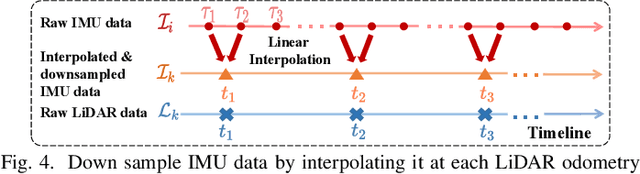
For most LiDAR-inertial odometry, accurate initial states, including temporal offset and extrinsic transformation between LiDAR and 6-axis IMUs, play a significant role and are often considered as prerequisites. However, such information may not be always available in customized LiDAR-inertial systems. In this paper, we propose LI-Init: a full and real-time LiDAR-inertial system initialization process that calibrates the temporal offset and extrinsic parameter between LiDARs and IMUs, and also the gravity vector and IMU bias by aligning the state estimated from LiDAR measurements with that measured by IMU. We implement the proposed method as an initialization module, which, if enabled, automatically detects the degree of excitation of the collected data and calibrate, on-the-fly, the temporal offset, extrinsic, gravity vector, and IMU bias, which are then used as high-quality initial state values for real-time LiDAR-inertial odometry systems. Experiments conducted with different types of LiDARs and LiDAR-inertial combinations show the robustness, adaptability and efficiency of our initialization method. The implementation of our LiDAR-inertial initialization procedure LI-Init and test data are open-sourced on Github and also integrated into a state-of-the-art LiDAR-inertial odometry system FAST-LIO2.
A Comprehensive Review of Computer Vision in Sports: Open Issues, Future Trends and Research Directions
Mar 23, 2022

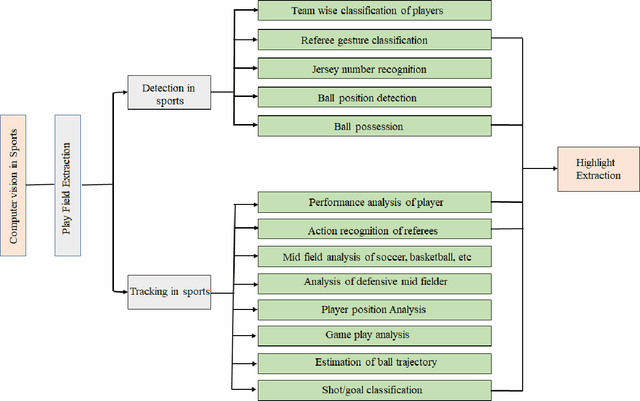
Recent developments in video analysis of sports and computer vision techniques have achieved significant improvements to enable a variety of critical operations. To provide enhanced information, such as detailed complex analysis in sports like soccer, basketball, cricket, badminton, etc., studies have focused mainly on computer vision techniques employed to carry out different tasks. This paper presents a comprehensive review of sports video analysis for various applications high-level analysis such as detection and classification of players, tracking player or ball in sports and predicting the trajectories of player or ball, recognizing the teams strategies, classifying various events in sports. The paper further discusses published works in a variety of application-specific tasks related to sports and the present researchers views regarding them. Since there is a wide research scope in sports for deploying computer vision techniques in various sports, some of the publicly available datasets related to a particular sport have been provided. This work reviews a detailed discussion on some of the artificial intelligence(AI)applications in sports vision, GPU-based work stations, and embedded platforms. Finally, this review identifies the research directions, probable challenges, and future trends in the area of visual recognition in sports.
Comparison of EEG based epilepsy diagnosis using neural networks and wavelet transform
Apr 09, 2022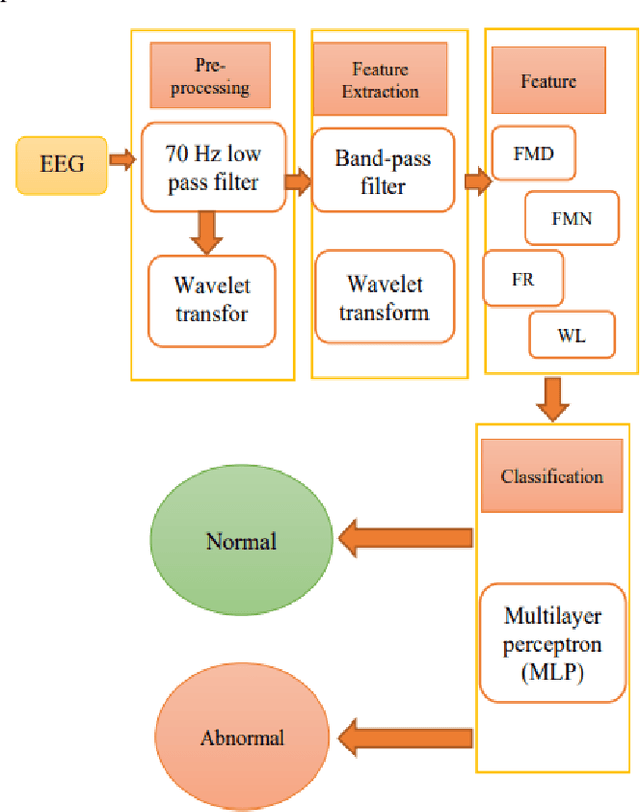
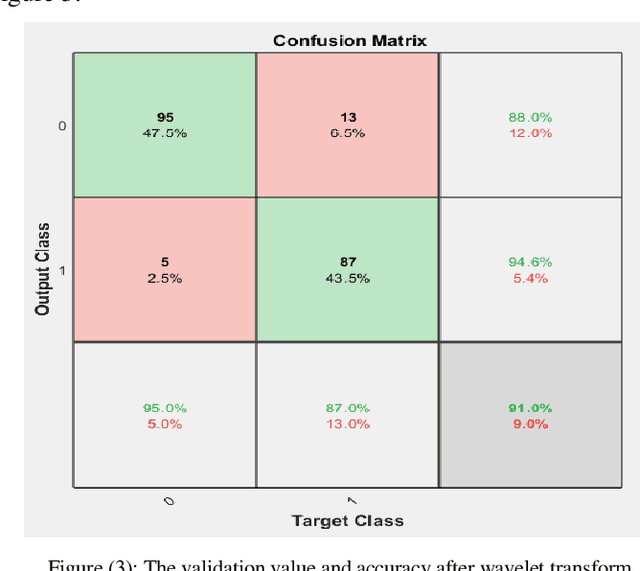
Epilepsy is one of the common neurological disorders characterized by recurrent and uncontrollable seizures, which seriously affect the life of patients. In many cases, electroencephalograms signal can provide important physiological information about the activity of the human brain which can be used to diagnose epilepsy. However, visual inspection of a large number of electroencephalogram signals is very time-consuming and can often lead to inconsistencies in physicians' diagnoses. Quantification of abnormalities in brain signals can indicate brain conditions and pathology so the electroencephalogram (EEG) signal plays a key role in the diagnosis of epilepsy. In this article, an attempt has been made to create a single instruction for diagnosing epilepsy, which consists of two steps. In the first step, a low-pass filter was used to preprocess the data and three separate mid-pass filters for different frequency bands and a multilayer neural network were designed. In the second step, the wavelet transform technique was used to process data. In particular, this paper proposes a multilayer perceptron neural network classifier for the diagnosis of epilepsy, that requires normal data and epilepsy data for education, but this classifier can recognize normal disorders, epilepsy, and even other disorders taught in educational examples. Also, the value of using electroencephalogram signal has been evaluated in two ways: using wavelet transform and non-using wavelet transform. Finally, the evaluation results indicate a relatively uniform impact factor on the use or non-use of wavelet transform on the improvement of epilepsy data functions, but in the end, it was shown that the use of perceptron multilayer neural network can provide a higher accuracy coefficient for experts.