 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Language-Independent Speaker Anonymization Approach using Self-Supervised Pre-Trained Models
Feb 26, 2022
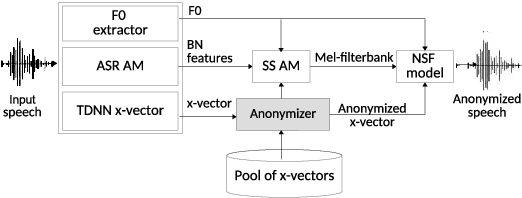
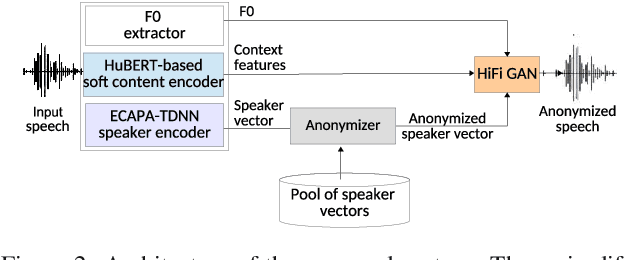

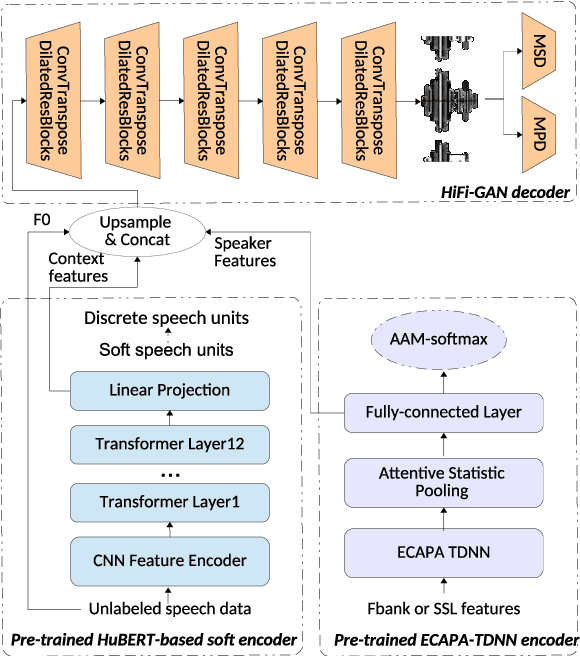
Speaker anonymization aims to protect the privacy of speakers while preserving spoken linguistic information from speech. Current mainstream neural network speaker anonymization systems are complicated, containing an F0 extractor, speaker encoder, automatic speech recognition acoustic model (ASR AM), speech synthesis acoustic model and speech waveform generation model. Moreover, as an ASR AM is language-dependent, trained on English data, it is hard to adapt it into another language. In this paper, we propose a simpler self-supervised learning (SSL)-based method for language-independent speaker anonymization without any explicit language-dependent model, which can be easily used for other languages. Extensive experiments were conducted on the VoicePrivacy Challenge 2020 datasets in English and AISHELL-3 datasets in Mandarin to demonstrate the effectiveness of our proposed SSL-based language-independent speaker anonymization method.
Optimizing Convolutional Neural Network Architecture via Information Field
Sep 11, 2020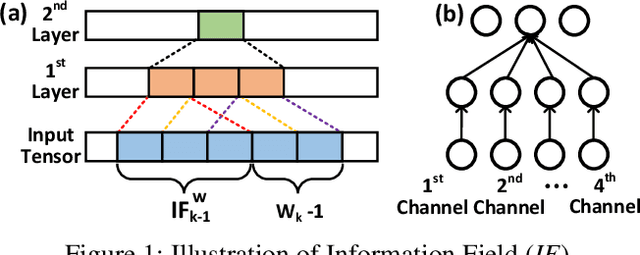
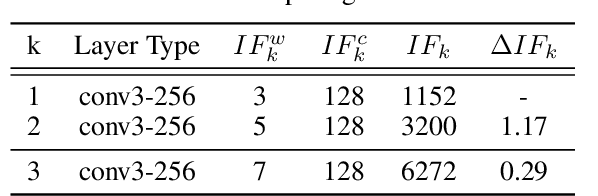
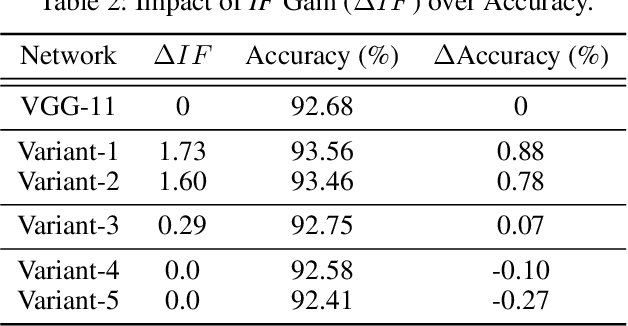
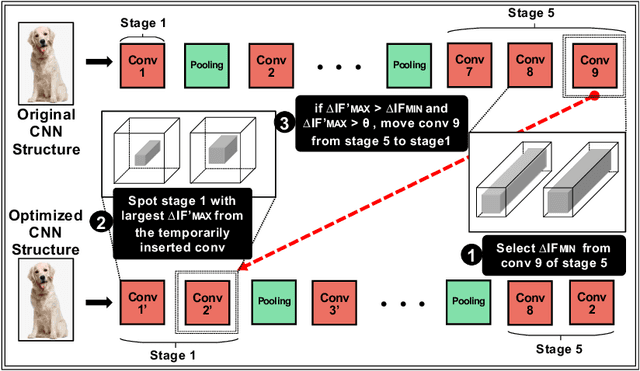
CNN architecture design has attracted tremendous attention of improving model accuracy or reducing model complexity. However, existing works either introduce repeated training overhead in the search process or lack an interpretable metric to guide the design. To clear the hurdles, we propose Information Field (IF), an explainable and easy-to-compute metric, to estimate the quality of a CNN architecture and guide the search process of designs. To validate the effectiveness of IF, we build a static optimizer to improve the CNN architectures at both the stage level and the kernel level. Our optimizer not only provides a clear and reproducible procedure but also mitigates unnecessary training efforts in the architecture search process. Experiments show that the models generated by our optimizer can achieve up to 5.47% accuracy improvement and up to 65.38% parameters deduction, compared with state-of-the-art CNN structures like MobileNet and ResNet.
Uplink-Downlink Duality and Precoding Strategies with Partial CSI in Cell-Free Wireless Networks
Jan 13, 2022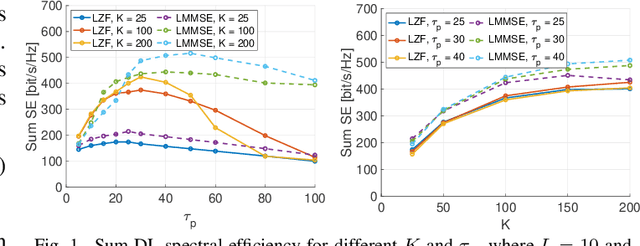
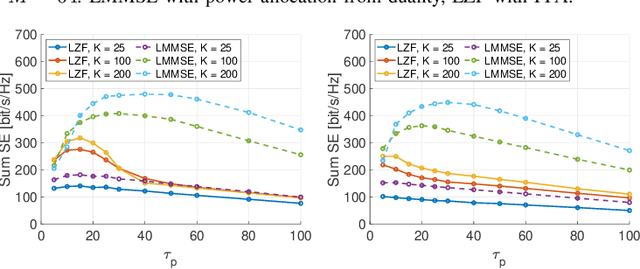
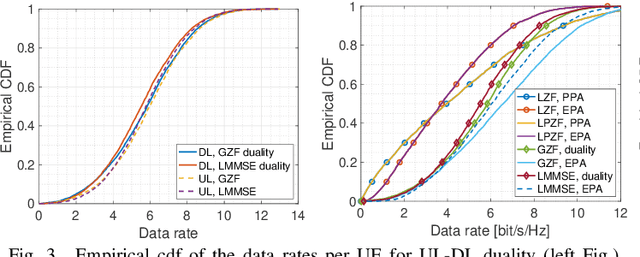
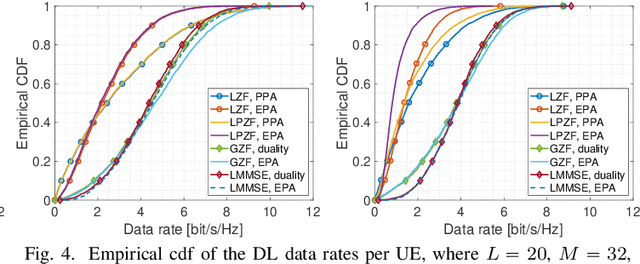
We consider a scalable user-centric wireless network with dynamic cluster formation as defined by Bj\"ornsson and Sanguinetti. After having shown the importance of dominant channel subspace information for uplink (UL) pilot decontamination and having examined different UL combining schemes in our previous work, here we investigate precoding strategies for the downlink (DL). Distributed scalable DL precoding and power allocation methods are evaluated for different antenna distributions, user densities and UL pilot dimensions. We compare distributed power allocation methods to a scheme based on a particular form of UL-DL duality which is computable by a central processor based on the available partial channel state information. The new duality method achieves almost symmetric "optimistic ergodic rates" for UL and DL while saving considerable computational complexity since the UL combining vectors are reused as DL precoders.
Categorical Representation Learning and RG flow operators for algorithmic classifiers
Mar 15, 2022
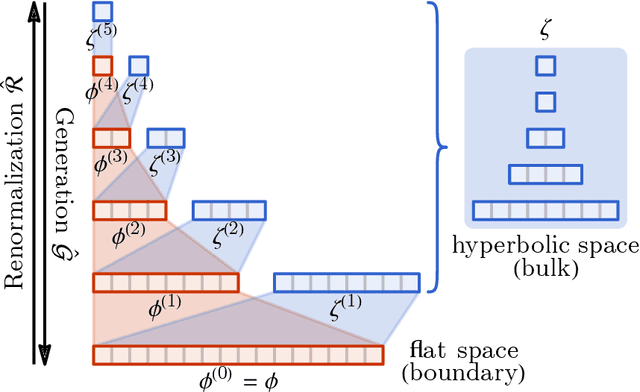

Following the earlier formalism of the categorical representation learning (arXiv:2103.14770) by the first two authors, we discuss the construction of the "RG-flow based categorifier". Borrowing ideas from theory of renormalization group flows (RG) in quantum field theory, holographic duality, and hyperbolic geometry, and mixing them with neural ODE's, we construct a new algorithmic natural language processing (NLP) architecture, called the RG-flow categorifier or for short the RG categorifier, which is capable of data classification and generation in all layers. We apply our algorithmic platform to biomedical data sets and show its performance in the field of sequence-to-function mapping. In particular we apply the RG categorifier to particular genomic sequences of flu viruses and show how our technology is capable of extracting the information from given genomic sequences, find their hidden symmetries and dominant features, classify them and use the trained data to make stochastic prediction of new plausible generated sequences associated with new set of viruses which could avoid the human immune system. The content of the current article is part of the recent US patent application submitted by first two authors (U.S. Patent Application No.: 63/313.504).
Meta-Learning for Online Update of Recommender Systems
Mar 19, 2022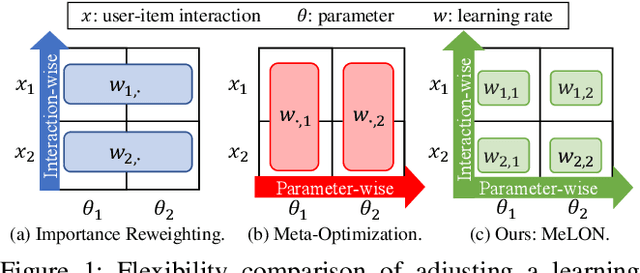
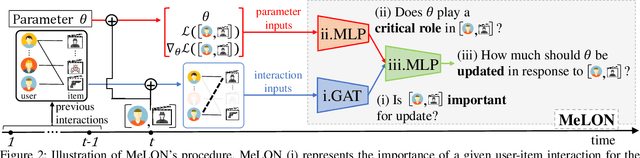
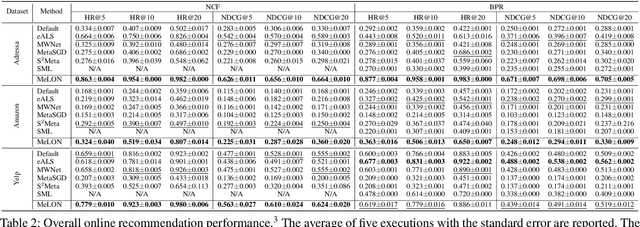
Online recommender systems should be always aligned with users' current interest to accurately suggest items that each user would like. Since user interest usually evolves over time, the update strategy should be flexible to quickly catch users' current interest from continuously generated new user-item interactions. Existing update strategies focus either on the importance of each user-item interaction or the learning rate for each recommender parameter, but such one-directional flexibility is insufficient to adapt to varying relationships between interactions and parameters. In this paper, we propose MeLON, a meta-learning based novel online recommender update strategy that supports two-directional flexibility. It is featured with an adaptive learning rate for each parameter-interaction pair for inducing a recommender to quickly learn users' up-to-date interest. The procedure of MeLON is optimized following a meta-learning approach: it learns how a recommender learns to generate the optimal learning rates for future updates. Specifically, MeLON first enriches the meaning of each interaction based on previous interactions and identifies the role of each parameter for the interaction; and then combines these two pieces of information to generate an adaptive learning rate. Theoretical analysis and extensive evaluation on three real-world online recommender datasets validate the effectiveness of MeLON.
* 11 pages, 6 figures
Towards Rich, Portable, and Large-Scale Pedestrian Data Collection
Mar 03, 2022


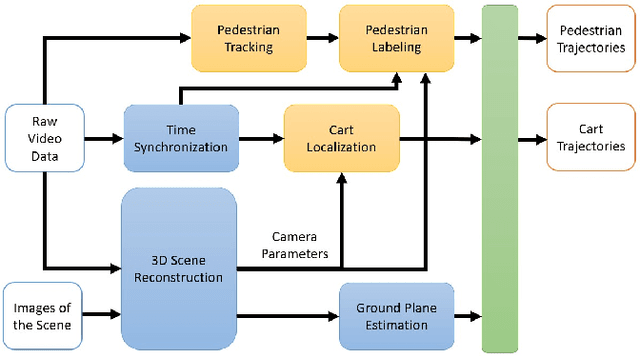
Recently, pedestrian behavior research has shifted towards machine learning based methods and converged on the topic of modeling pedestrian interactions. For this, a large-scale dataset that contains rich information is needed. We propose a data collection system that is portable, which facilitates accessible large-scale data collection in diverse environments. We also couple the system with a semi-autonomous labeling pipeline for fast trajectory label production. We demonstrate the effectiveness of our system by further introducing a dataset we have collected -- the TBD pedestrian dataset. Compared with existing pedestrian datasets, our dataset contains three components: human verified labels grounded in the metric space, a combination of top-down and perspective views, and naturalistic human behavior in the presence of a socially appropriate "robot". In addition, the TBD pedestrian dataset is larger in quantity compared to similar existing datasets and contains unique pedestrian behavior.
Occlusion-Aware Self-Supervised Monocular 6D Object Pose Estimation
Mar 19, 2022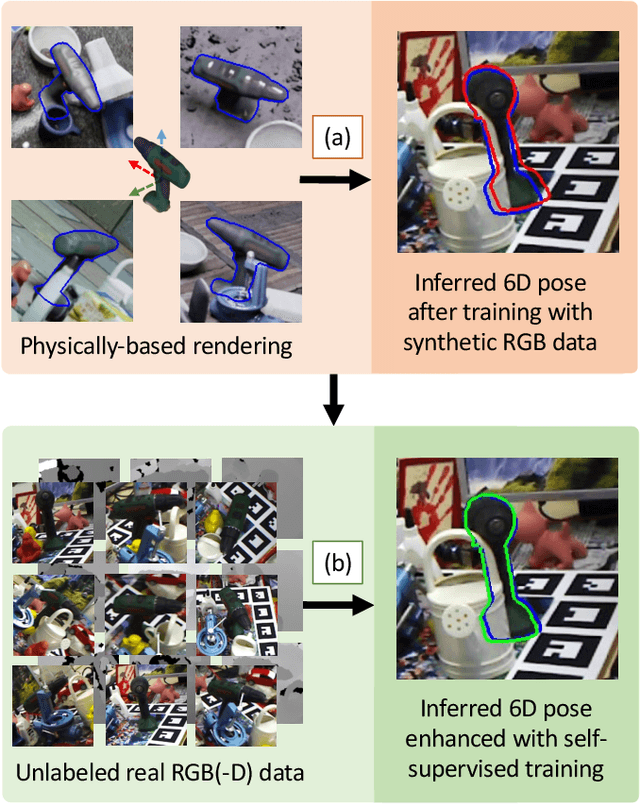

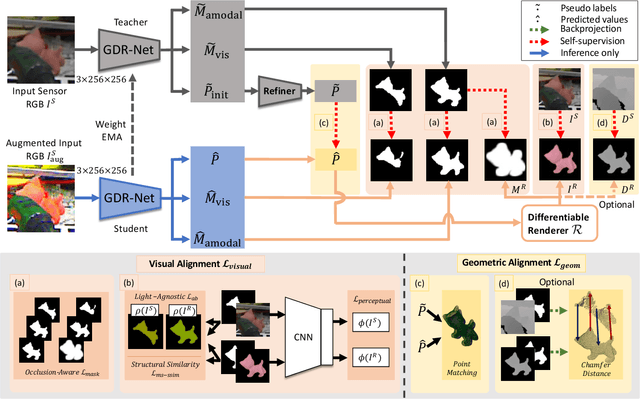

6D object pose estimation is a fundamental yet challenging problem in computer vision. Convolutional Neural Networks (CNNs) have recently proven to be capable of predicting reliable 6D pose estimates even under monocular settings. Nonetheless, CNNs are identified as being extremely data-driven, and acquiring adequate annotations is oftentimes very time-consuming and labor intensive. To overcome this limitation, we propose a novel monocular 6D pose estimation approach by means of self-supervised learning, removing the need for real annotations. After training our proposed network fully supervised with synthetic RGB data, we leverage current trends in noisy student training and differentiable rendering to further self-supervise the model on these unsupervised real RGB(-D) samples, seeking for a visually and geometrically optimal alignment. Moreover, employing both visible and amodal mask information, our self-supervision becomes very robust towards challenging scenarios such as occlusion. Extensive evaluations demonstrate that our proposed self-supervision outperforms all other methods relying on synthetic data or employing elaborate techniques from the domain adaptation realm. Noteworthy, our self-supervised approach consistently improves over its synthetically trained baseline and often almost closes the gap towards its fully supervised counterpart. The code and models are publicly available at https://github.com/THU-DA-6D-Pose-Group/self6dpp.git.
SWIS: Self-Supervised Representation Learning For Writer Independent Offline Signature Verification
Feb 26, 2022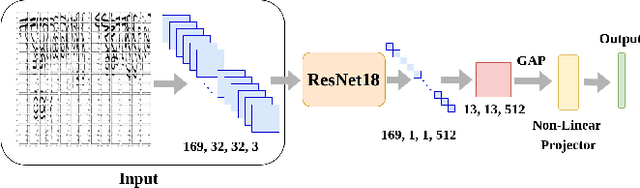

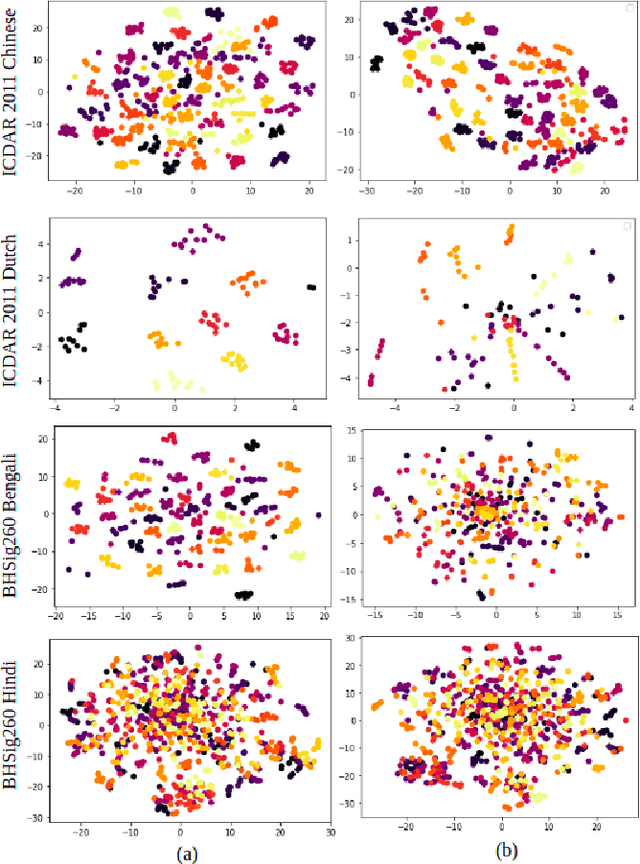
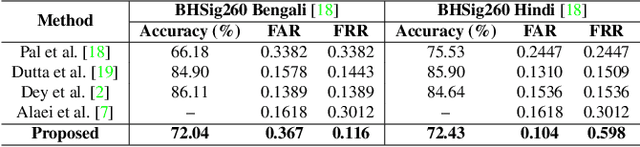
Writer independent offline signature verification is one of the most challenging tasks in pattern recognition as there is often a scarcity of training data. To handle such data scarcity problem, in this paper, we propose a novel self-supervised learning (SSL) framework for writer independent offline signature verification. To our knowledge, this is the first attempt to utilize self-supervised setting for the signature verification task. The objective of self-supervised representation learning from the signature images is achieved by minimizing the cross-covariance between two random variables belonging to different feature directions and ensuring a positive cross-covariance between the random variables denoting the same feature direction. This ensures that the features are decorrelated linearly and the redundant information is discarded. Through experimental results on different data sets, we obtained encouraging results.
On the complexity of Dark Chinese Chess
Dec 06, 2021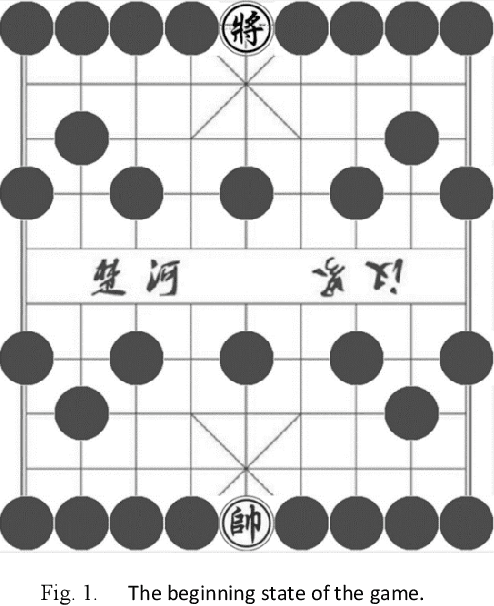
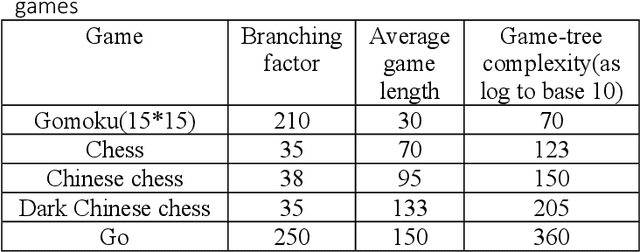
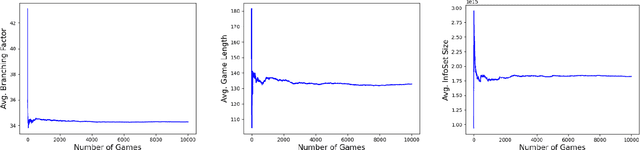
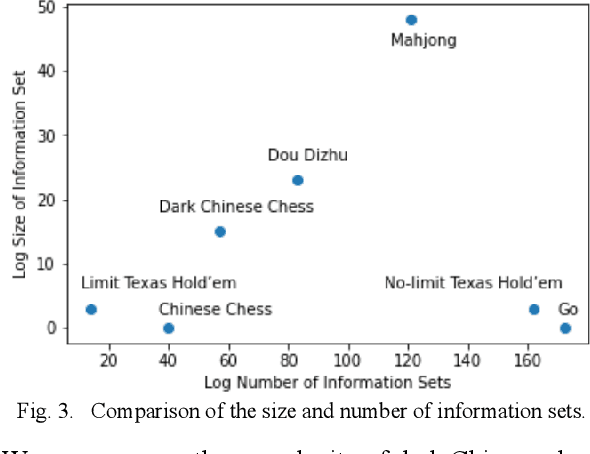
This paper provides a complexity analysis for the game of dark Chinese chess (a.k.a. "JieQi"), a variation of Chinese chess. Dark Chinese chess combines some of the most complicated aspects of board and card games, such as long-term strategy or planning, large state space, stochastic, and imperfect-information, which make it closer to the real world decision-making problem and pose great challenges to game AI. Here we design a self-play program to calculate the game tree complexity and average information set size of the game, and propose an algorithm to calculate the number of information sets.
Product Market Demand Analysis Using NLP in Banglish Text with Sentiment Analysis and Named Entity Recognition
Apr 04, 2022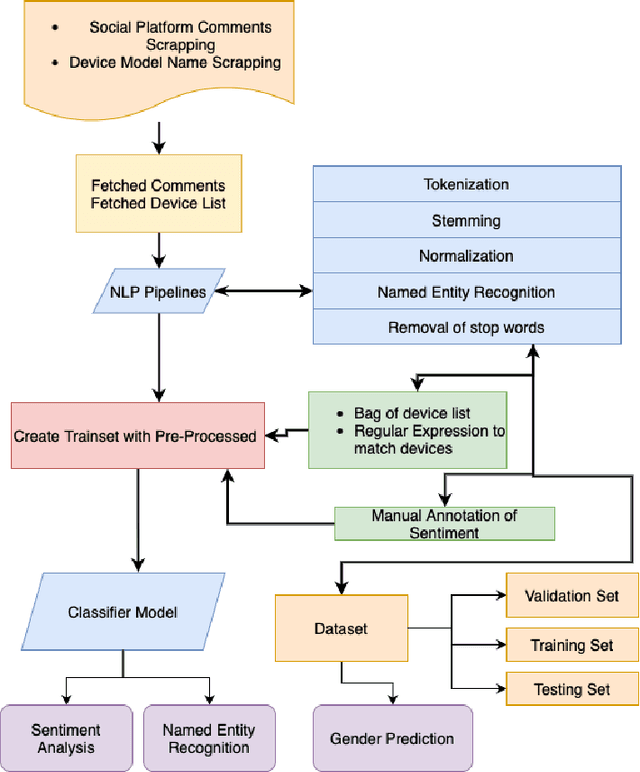

Product market demand analysis plays a significant role for originating business strategies due to its noticeable impact on the competitive business field. Furthermore, there are roughly 228 million native Bengali speakers, the majority of whom use Banglish text to interact with one another on social media. Consumers are buying and evaluating items on social media with Banglish text as social media emerges as an online marketplace for entrepreneurs. People use social media to find preferred smartphone brands and models by sharing their positive and bad experiences with them. For this reason, our goal is to gather Banglish text data and use sentiment analysis and named entity identification to assess Bangladeshi market demand for smartphones in order to determine the most popular smartphones by gender. We scraped product related data from social media with instant data scrapers and crawled data from Wikipedia and other sites for product information with python web scrapers. Using Python's Pandas and Seaborn libraries, the raw data is filtered using NLP methods. To train our datasets for named entity recognition, we utilized Spacey's custom NER model, Amazon Comprehend Custom NER. A tensorflow sequential model was deployed with parameter tweaking for sentiment analysis. Meanwhile, we used the Google Cloud Translation API to estimate the gender of the reviewers using the BanglaLinga library. In this article, we use natural language processing (NLP) approaches and several machine learning models to identify the most in-demand items and services in the Bangladeshi market. Our model has an accuracy of 87.99% in Spacy Custom Named Entity recognition, 95.51% in Amazon Comprehend Custom NER, and 87.02% in the Sequential model for demand analysis. After Spacy's study, we were able to manage 80% of mistakes related to misspelled words using a mix of Levenshtein distance and ratio algorithms.