 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Read before Generate! Faithful Long Form Question Answering with Machine Reading
Mar 01, 2022

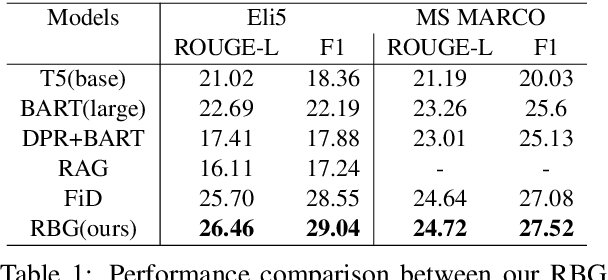
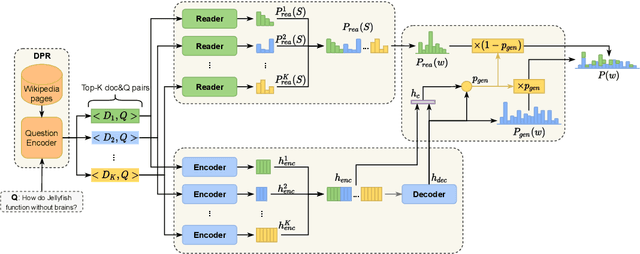
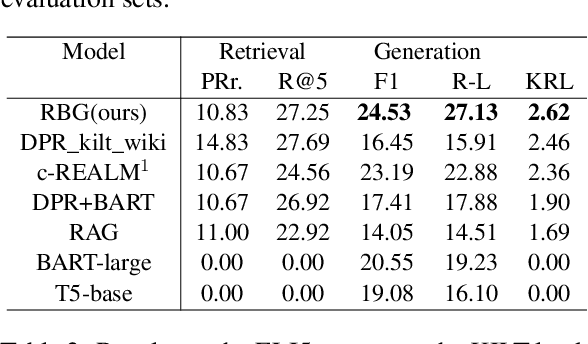
Long-form question answering (LFQA) aims to generate a paragraph-length answer for a given question. While current work on LFQA using large pre-trained model for generation are effective at producing fluent and somewhat relevant content, one primary challenge lies in how to generate a faithful answer that has less hallucinated content. We propose a new end-to-end framework that jointly models answer generation and machine reading. The key idea is to augment the generation model with fine-grained, answer-related salient information which can be viewed as an emphasis on faithful facts. State-of-the-art results on two LFQA datasets, ELI5 and MS MARCO, demonstrate the effectiveness of our method, in comparison with strong baselines on automatic and human evaluation metrics. A detailed analysis further proves the competency of our methods in generating fluent, relevant, and more faithful answers.
CrowdMLP: Weakly-Supervised Crowd Counting via Multi-Granularity MLP
Mar 15, 2022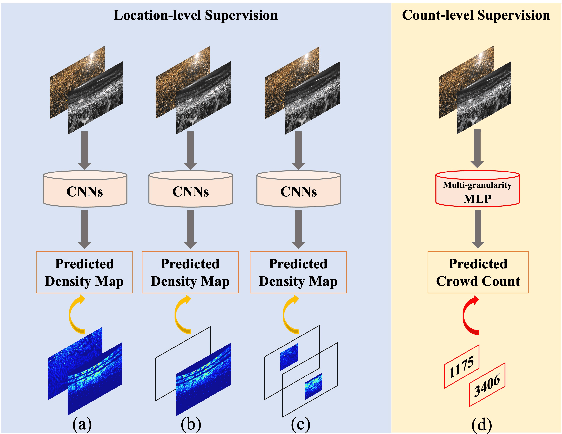
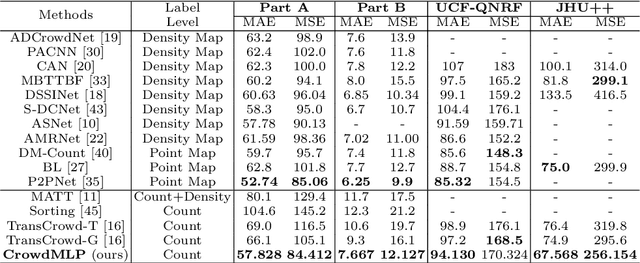
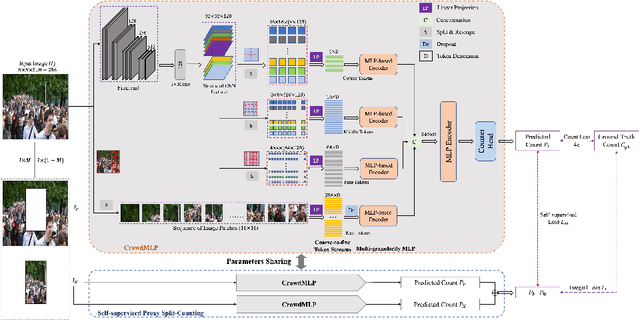
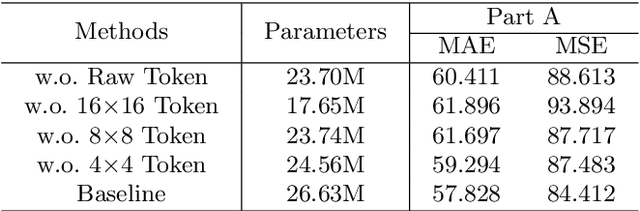
Existing state-of-the-art crowd counting algorithms rely excessively on location-level annotations, which are burdensome to acquire. When only count-level (weak) supervisory signals are available, it is arduous and error-prone to regress total counts due to the lack of explicit spatial constraints. To address this issue, a novel and efficient counter (referred to as CrowdMLP) is presented, which probes into modelling global dependencies of embeddings and regressing total counts by devising a multi-granularity MLP regressor. In specific, a locally-focused pre-trained frontend is cascaded to extract crude feature maps with intrinsic spatial cues, which prevent the model from collapsing into trivial outcomes. The crude embeddings, along with raw crowd scenes, are tokenized at different granularity levels. The multi-granularity MLP then proceeds to mix tokens at the dimensions of cardinality, channel, and spatial for mining global information. An effective proxy task, namely Split-Counting, is also proposed to evade the barrier of limited samples and the shortage of spatial hints in a self-supervised manner. Extensive experiments demonstrate that CrowdMLP significantly outperforms existing weakly-supervised counting algorithms and performs on par with state-of-the-art location-level supervised approaches.
Registration of Histopathogy Images Using Structural Information From Fine Grained Feature Maps
Jul 04, 2020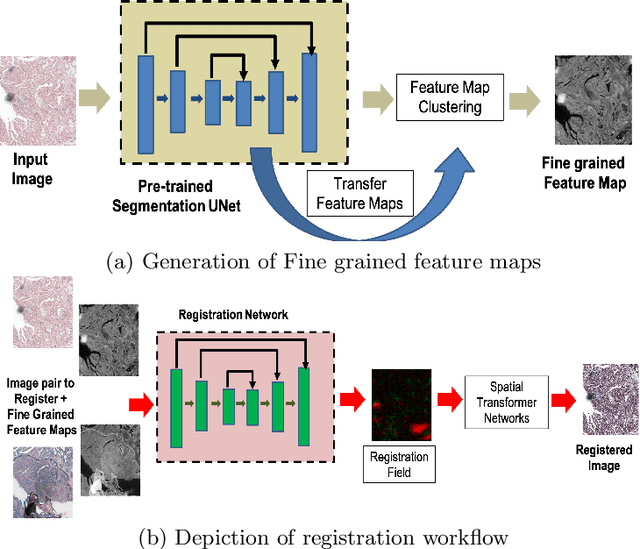
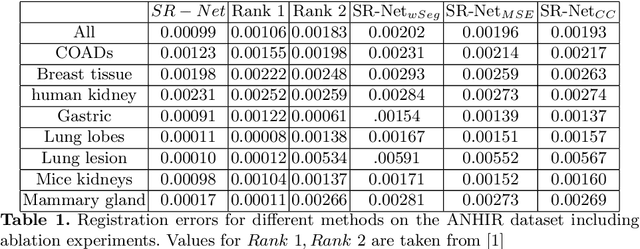
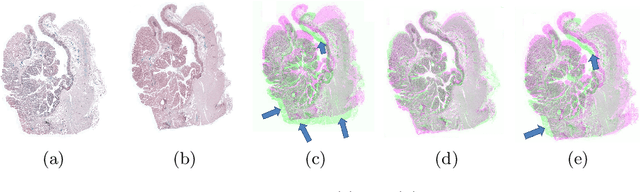
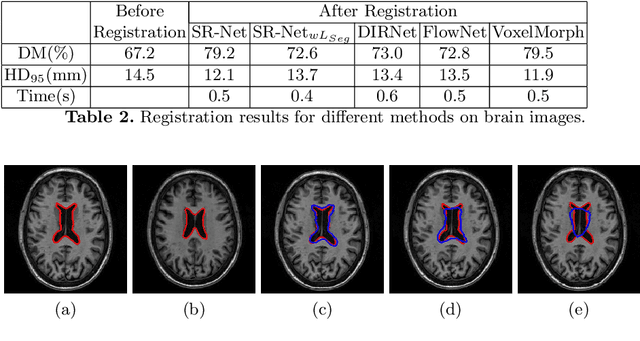
Registration is an important part of many clinical workflows and factually, including information of structures of interest improves registration performance. We propose a novel approach of combining segmentation information in a registration framework using self supervised segmentation feature maps extracted using a pre-trained segmentation network followed by clustering. Using self supervised feature maps enables us to use segmentation information despite the unavailability of manual segmentations. Experimental results show our approach effectively replaces manual segmentation maps and demonstrate the possibility of obtaining state of the art registration performance in real world cases where manual segmentation maps are unavailable.
RGB-D SLAM Using Attention Guided Frame Association
Jan 28, 2022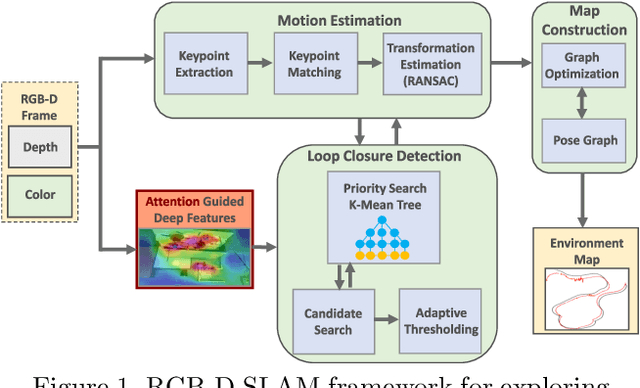
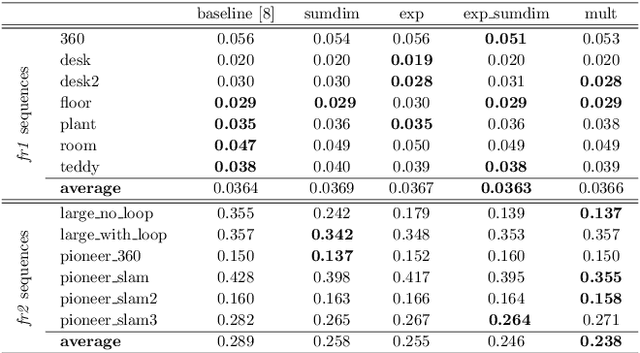
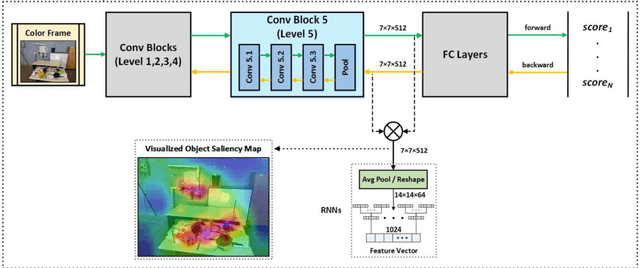
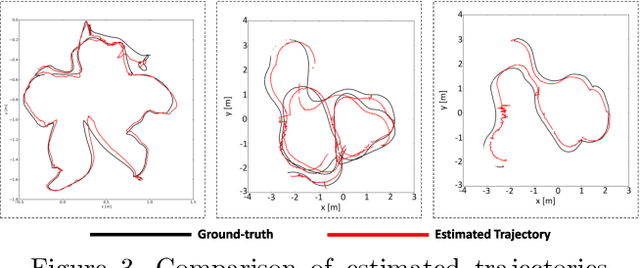
Deep learning models as an emerging topic have shown great progress in various fields. Especially, visualization tools such as class activation mapping methods provided visual explanation on the reasoning of convolutional neural networks (CNNs). By using the gradients of the network layers, it is possible to demonstrate where the networks pay attention during a specific image recognition task. Moreover, these gradients can be integrated with CNN features for localizing more generalized task dependent attentive (salient) objects in scenes. Despite this progress, there is not much explicit usage of this gradient (network attention) information to integrate with CNN representations for object semantics. This can be very useful for visual tasks such as simultaneous localization and mapping (SLAM) where CNN representations of spatially attentive object locations may lead to improved performance. Therefore, in this work, we propose the use of task specific network attention for RGB-D indoor SLAM. To do so, we integrate layer-wise object attention information (layer gradients) with CNN layer representations to improve frame association performance in a state-of-the-art RGB-D indoor SLAM method. Experiments show promising initial results with improved performance.
ARTEMIS: Attention-based Retrieval with Text-Explicit Matching and Implicit Similarity
Mar 15, 2022
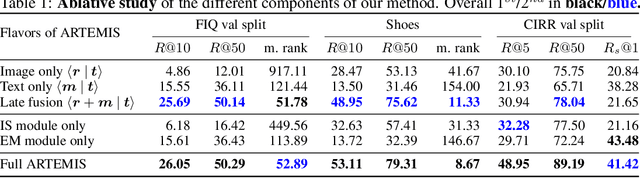
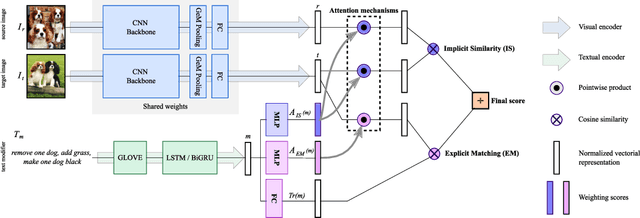
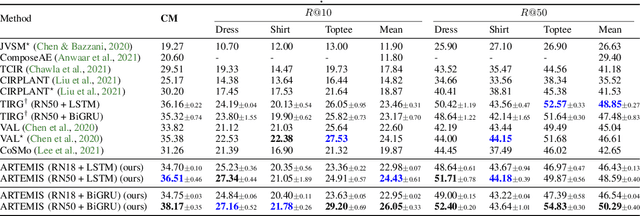
An intuitive way to search for images is to use queries composed of an example image and a complementary text. While the first provides rich and implicit context for the search, the latter explicitly calls for new traits, or specifies how some elements of the example image should be changed to retrieve the desired target image. Current approaches typically combine the features of each of the two elements of the query into a single representation, which can then be compared to the ones of the potential target images. Our work aims at shedding new light on the task by looking at it through the prism of two familiar and related frameworks: text-to-image and image-to-image retrieval. Taking inspiration from them, we exploit the specific relation of each query element with the targeted image and derive light-weight attention mechanisms which enable to mediate between the two complementary modalities. We validate our approach on several retrieval benchmarks, querying with images and their associated free-form text modifiers. Our method obtains state-of-the-art results without resorting to side information, multi-level features, heavy pre-training nor large architectures as in previous works.
Dynamic and Efficient Gray-Box Hyperparameter Optimization for Deep Learning
Feb 20, 2022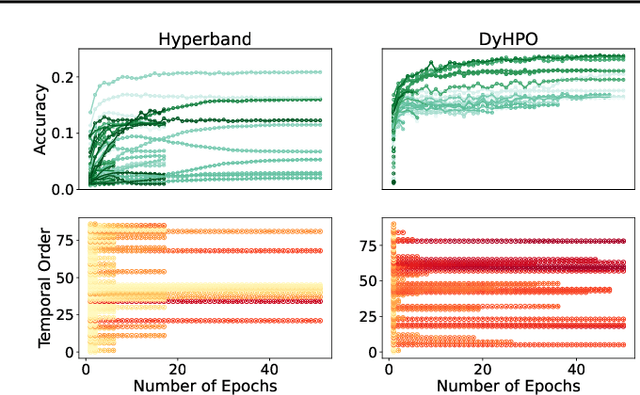
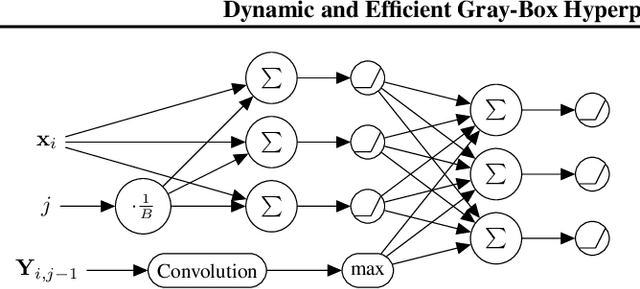
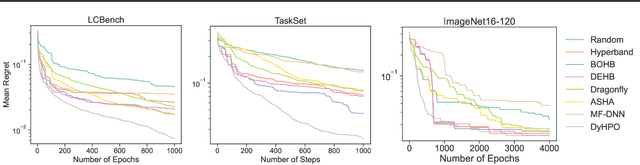
Gray-box hyperparameter optimization techniques have recently emerged as a promising direction for tuning Deep Learning methods. In this work, we introduce DyHPO, a method that learns to dynamically decide which configuration to try next, and for what budget. Our technique is a modification to the classical Bayesian optimization for a gray-box setup. Concretely, we propose a new surrogate for Gaussian Processes that embeds the learning curve dynamics and a new acquisition function that incorporates multi-budget information. We demonstrate the significant superiority of DyHPO against state-of-the-art hyperparameter optimization baselines through large-scale experiments comprising 50 datasets (Tabular, Image, NLP) and diverse neural networks (MLP, CNN/NAS, RNN).
Real-time information retrieval from Identity cards
Mar 26, 2020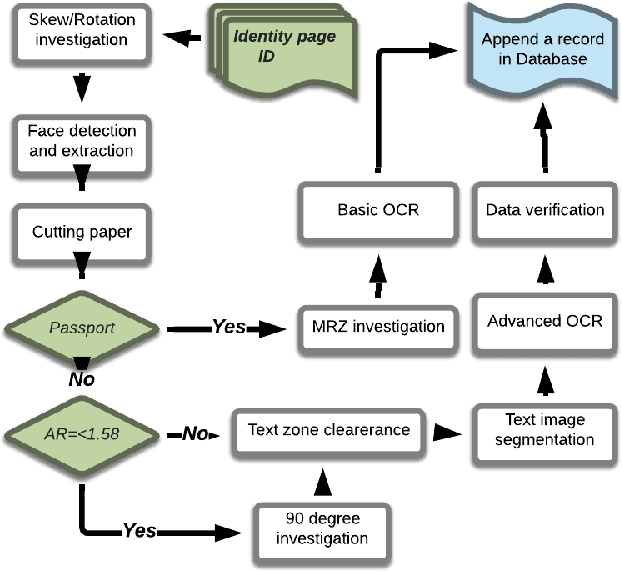



Information is frequently retrieved from valid personal ID cards by the authorised organisation to address different purposes. The successful information retrieval (IR) depends on the accuracy and timing process. A process which necessitates a long time to respond is frustrating for both sides in the exchange of data. This paper aims to propose a series of state-of-the-art methods for the journey of an Identification card (ID) from the scanning or capture phase to the point before Optical character recognition (OCR). The key factors for this proposal are the accuracy and speed of the process during the journey. The experimental results of this research prove that utilising the methods based on deep learning, such as Efficient and Accurate Scene Text (EAST) detector and Deep Neural Network (DNN) for face detection, instead of traditional methods increase the efficiency considerably.
MT-Clinical BERT: Scaling Clinical Information Extraction with Multitask Learning
Apr 21, 2020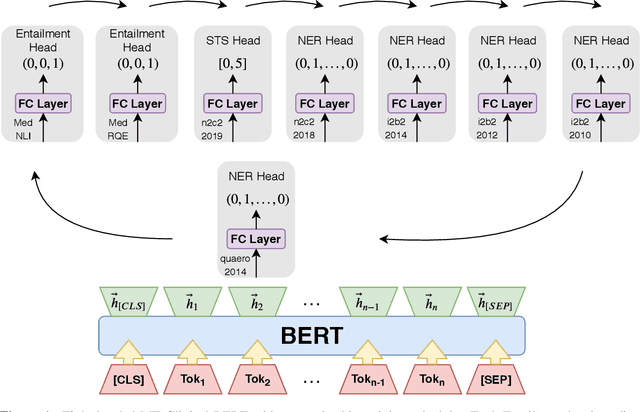
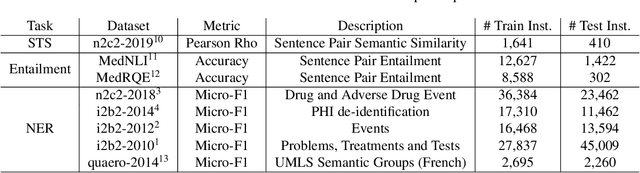
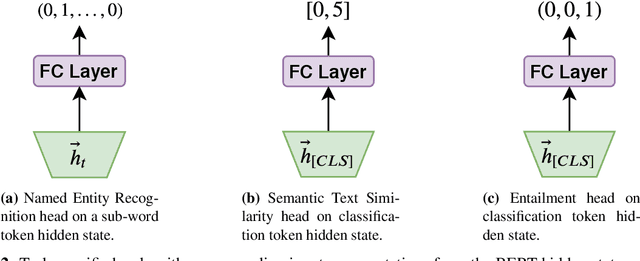
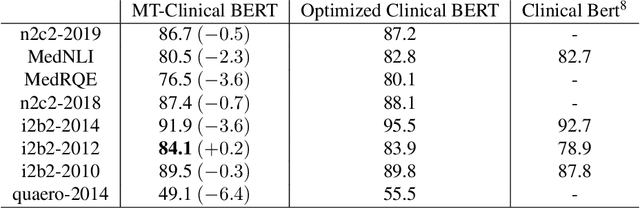
Clinical notes contain an abundance of important but not-readily accessible information about patients. Systems to automatically extract this information rely on large amounts of training data for which their exists limited resources to create. Furthermore, they are developed dis-jointly; meaning that no information can be shared amongst task-specific systems. This bottle-neck unnecessarily complicates practical application, reduces the performance capabilities of each individual solution and associates the engineering debt of managing multiple information extraction systems. We address these challenges by developing Multitask-Clinical BERT: a single deep learning model that simultaneously performs eight clinical tasks spanning entity extraction, PHI identification, language entailment and similarity by sharing representations amongst tasks. We find our single system performs competitively with all state-the-art task-specific systems while also benefiting from massive computational benefits at inference.
Language-Independent Speaker Anonymization Approach using Self-Supervised Pre-Trained Models
Feb 26, 2022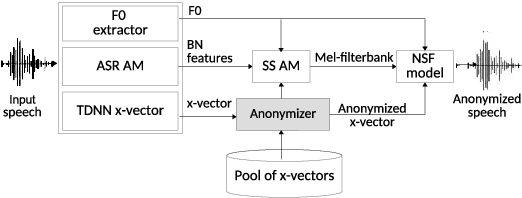
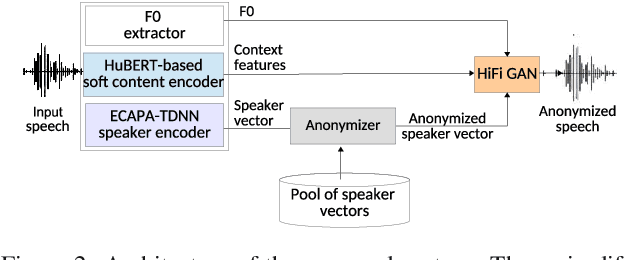

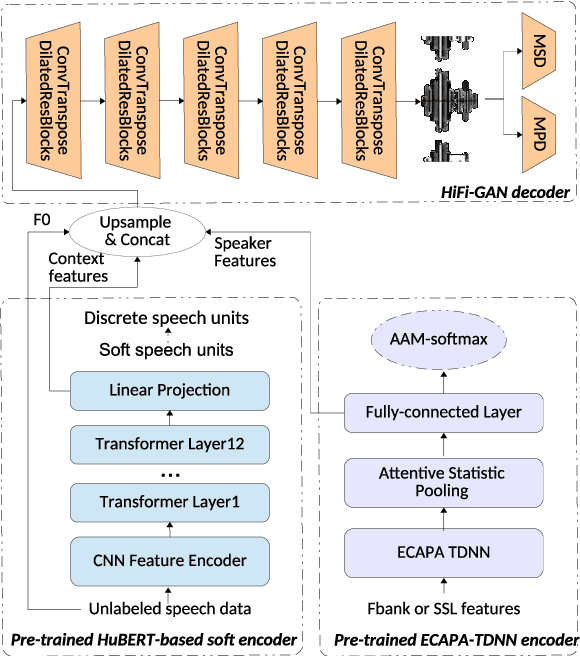
Speaker anonymization aims to protect the privacy of speakers while preserving spoken linguistic information from speech. Current mainstream neural network speaker anonymization systems are complicated, containing an F0 extractor, speaker encoder, automatic speech recognition acoustic model (ASR AM), speech synthesis acoustic model and speech waveform generation model. Moreover, as an ASR AM is language-dependent, trained on English data, it is hard to adapt it into another language. In this paper, we propose a simpler self-supervised learning (SSL)-based method for language-independent speaker anonymization without any explicit language-dependent model, which can be easily used for other languages. Extensive experiments were conducted on the VoicePrivacy Challenge 2020 datasets in English and AISHELL-3 datasets in Mandarin to demonstrate the effectiveness of our proposed SSL-based language-independent speaker anonymization method.
Meta-Learning for Online Update of Recommender Systems
Mar 19, 2022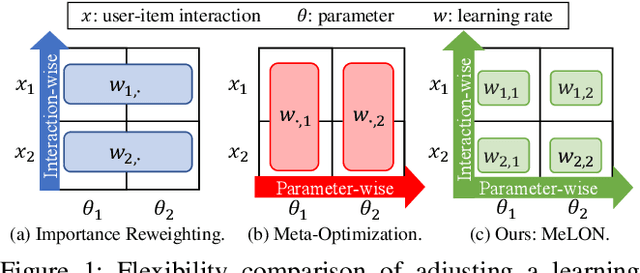
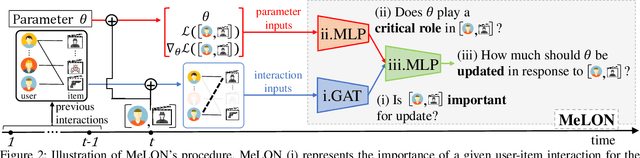
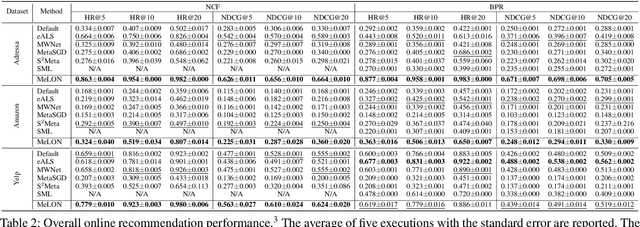
Online recommender systems should be always aligned with users' current interest to accurately suggest items that each user would like. Since user interest usually evolves over time, the update strategy should be flexible to quickly catch users' current interest from continuously generated new user-item interactions. Existing update strategies focus either on the importance of each user-item interaction or the learning rate for each recommender parameter, but such one-directional flexibility is insufficient to adapt to varying relationships between interactions and parameters. In this paper, we propose MeLON, a meta-learning based novel online recommender update strategy that supports two-directional flexibility. It is featured with an adaptive learning rate for each parameter-interaction pair for inducing a recommender to quickly learn users' up-to-date interest. The procedure of MeLON is optimized following a meta-learning approach: it learns how a recommender learns to generate the optimal learning rates for future updates. Specifically, MeLON first enriches the meaning of each interaction based on previous interactions and identifies the role of each parameter for the interaction; and then combines these two pieces of information to generate an adaptive learning rate. Theoretical analysis and extensive evaluation on three real-world online recommender datasets validate the effectiveness of MeLON.
* 11 pages, 6 figures