 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Slow-varying Dynamics Assisted Temporal Capsule Network for Machinery Remaining Useful Life Estimation
Mar 30, 2022
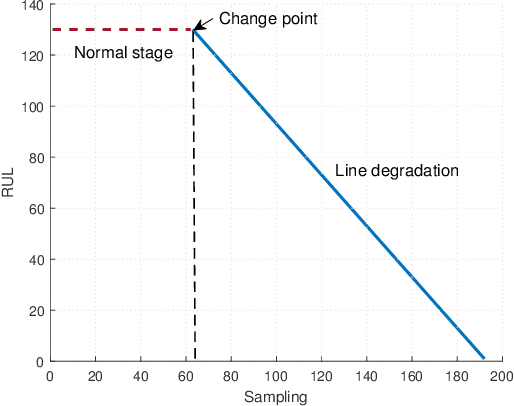
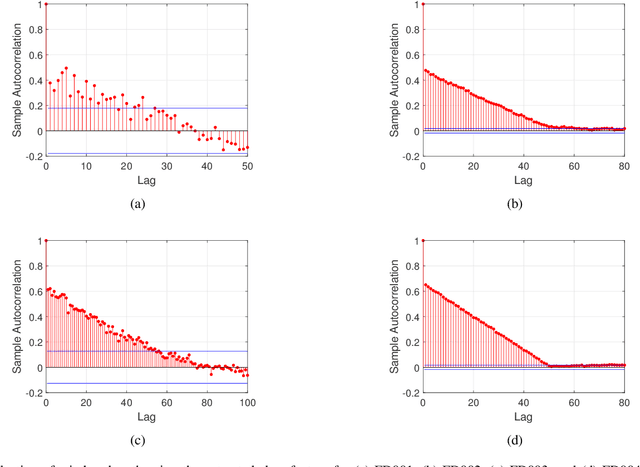
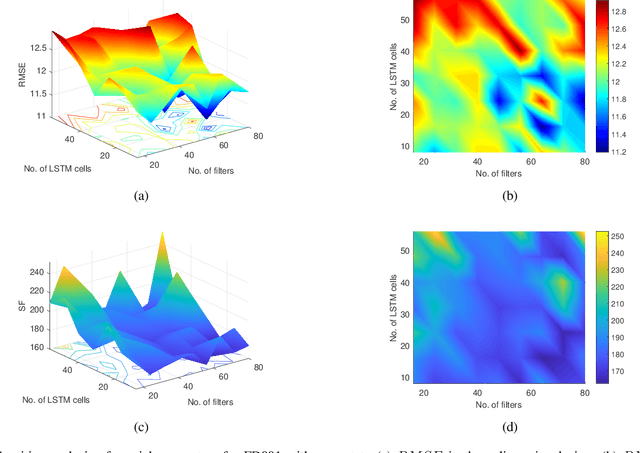
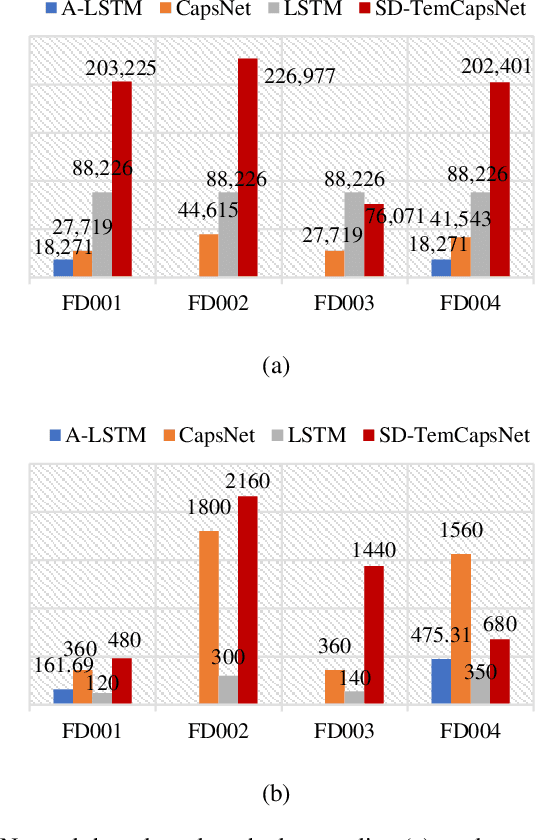
Capsule network (CapsNet) acts as a promising alternative to the typical convolutional neural network, which is the dominant network to develop the remaining useful life (RUL) estimation models for mechanical equipment. Although CapsNet comes with an impressive ability to represent the entities' hierarchical relationships through a high-dimensional vector embedding, it fails to capture the long-term temporal correlation of run-to-failure time series measured from degraded mechanical equipment. On the other hand, the slow-varying dynamics, which reveals the low-frequency information hidden in mechanical dynamical behaviour, is overlooked in the existing RUL estimation models, limiting the utmost ability of advanced networks. To address the aforementioned concerns, we propose a Slow-varying Dynamics assisted Temporal CapsNet (SD-TemCapsNet) to simultaneously learn the slow-varying dynamics and temporal dynamics from measurements for accurate RUL estimation. First, in light of the sensitivity of fault evolution, slow-varying features are decomposed from normal raw data to convey the low-frequency components corresponding to the system dynamics. Next, the long short-term memory (LSTM) mechanism is introduced into CapsNet to capture the temporal correlation of time series. To this end, experiments conducted on an aircraft engine and a milling machine verify that the proposed SD-TemCapsNet outperforms the mainstream methods. In comparison with CapsNet, the estimation accuracy of the aircraft engine with four different scenarios has been improved by 10.17%, 24.97%, 3.25%, and 13.03% concerning the index root mean squared error, respectively. Similarly, the estimation accuracy of the milling machine has been improved by 23.57% compared to LSTM and 19.54% compared to CapsNet.
ros2_tracing: Multipurpose Low-Overhead Framework for Real-Time Tracing of ROS 2
Jan 02, 2022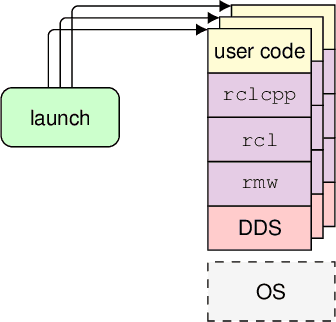
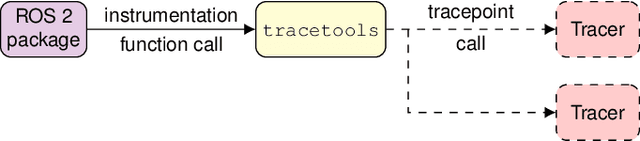
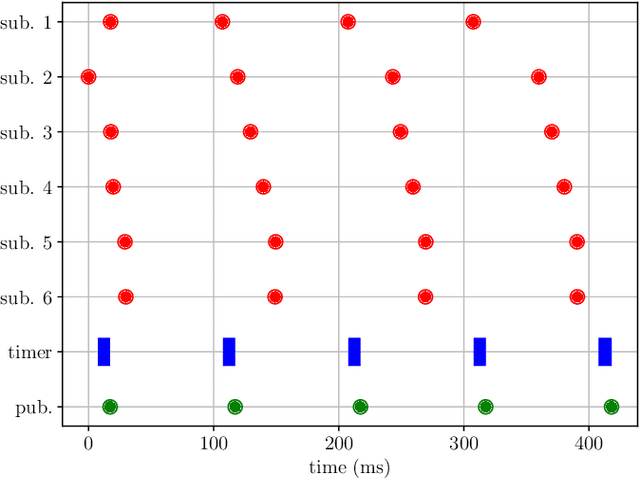
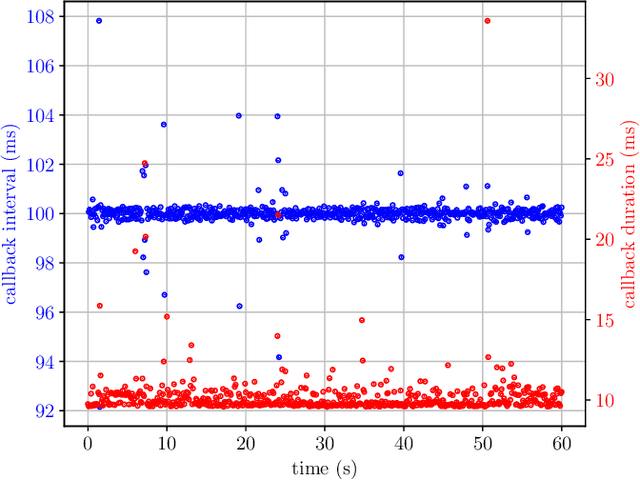
Testing and debugging have become major obstacles for robot software development, because of high system complexity and dynamic environments. Standard, middleware-based data recording does not provide sufficient information on internal computation and performance bottlenecks. Other existing methods also target very specific problems and thus cannot be used for multipurpose analysis. Moreover, they are not suitable for real-time applications. In this paper, we present ros2_tracing, a collection of flexible tracing tools and multipurpose instrumentation for ROS 2. It allows collecting runtime execution information on real-time distributed systems, using the low-overhead LTTng tracer. Tools also integrate tracing into the invaluable ROS 2 orchestration system and other usability tools. A message latency experiment shows that the end-to-end message latency overhead, when enabling all ROS 2 instrumentation, is below 0.0055 ms, which we believe is suitable for production real-time systems. ROS 2 execution information obtained using ros2_tracing can be combined with trace data from the operating system, enabling a wider range of precise analyses, that help understand an application execution, to find the cause of performance bottlenecks and other issues. The source code is available at: https://gitlab.com/ros-tracing/ros2_tracing.
SEN12MS-CR-TS: A Remote Sensing Data Set for Multi-modal Multi-temporal Cloud Removal
Jan 24, 2022


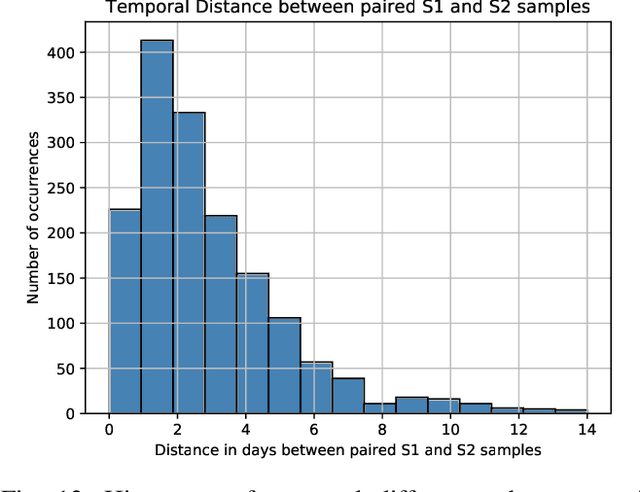
About half of all optical observations collected via spaceborne satellites are affected by haze or clouds. Consequently, cloud coverage affects the remote sensing practitioner's capabilities of a continuous and seamless monitoring of our planet. This work addresses the challenge of optical satellite image reconstruction and cloud removal by proposing a novel multi-modal and multi-temporal data set called SEN12MS-CR-TS. We propose two models highlighting the benefits and use cases of SEN12MS-CR-TS: First, a multi-modal multi-temporal 3D-Convolution Neural Network that predicts a cloud-free image from a sequence of cloudy optical and radar images. Second, a sequence-to-sequence translation model that predicts a cloud-free time series from a cloud-covered time series. Both approaches are evaluated experimentally, with their respective models trained and tested on SEN12MS-CR-TS. The conducted experiments highlight the contribution of our data set to the remote sensing community as well as the benefits of multi-modal and multi-temporal information to reconstruct noisy information. Our data set is available at https://patrickTUM.github.io/cloud_removal
Partitioning Image Representation in Contrastive Learning
Mar 20, 2022
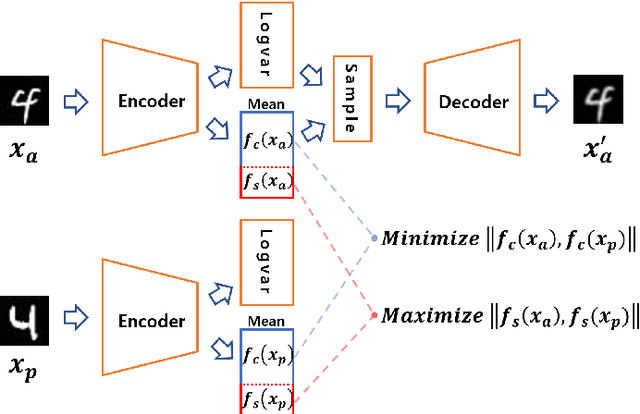
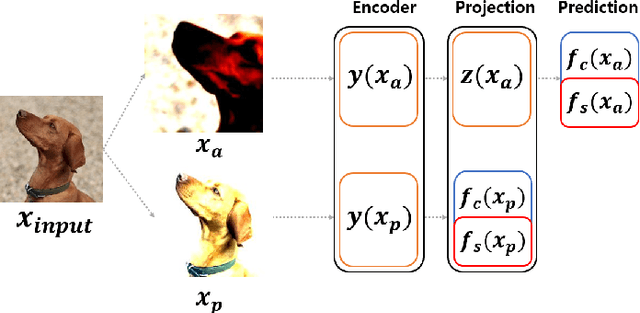
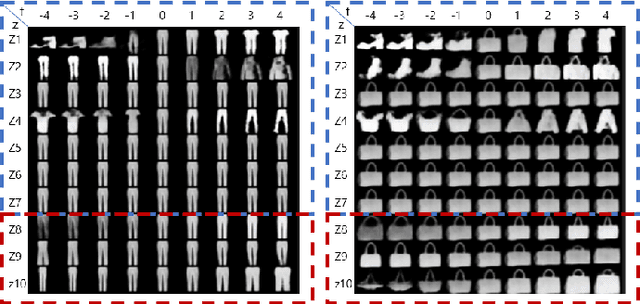
In contrastive learning in the image domain, the anchor and positive samples are forced to have as close representations as possible. However, forcing the two samples to have the same representation could be misleading because the data augmentation techniques make the two samples different. In this paper, we introduce a new representation, partitioned representation, which can learn both common and unique features of the anchor and positive samples in contrastive learning. The partitioned representation consists of two parts: the content part and the style part. The content part represents common features of the class, and the style part represents the own features of each sample, which can lead to the representation of the data augmentation method. We can achieve the partitioned representation simply by decomposing a loss function of contrastive learning into two terms on the two separate representations, respectively. To evaluate our representation with two parts, we take two framework models: Variational AutoEncoder (VAE) and BootstrapYour Own Latent(BYOL) to show the separability of content and style, and to confirm the generalization ability in classification, respectively. Based on the experiments, we show that our approach can separate two types of information in the VAE framework and outperforms the conventional BYOL in linear separability and a few-shot learning task as downstream tasks.
An Introduction to Neural Data Compression
Feb 14, 2022
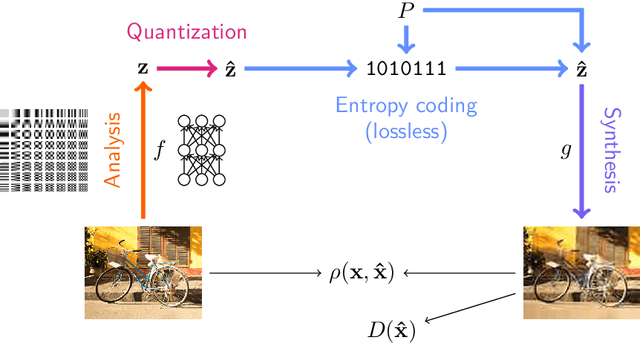
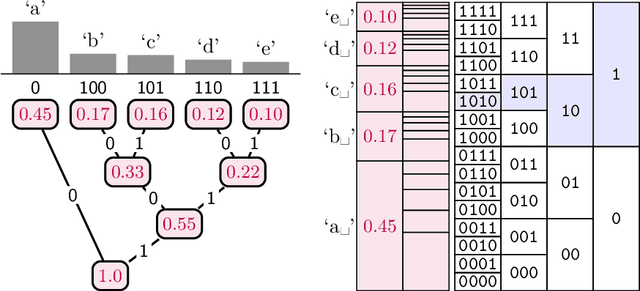
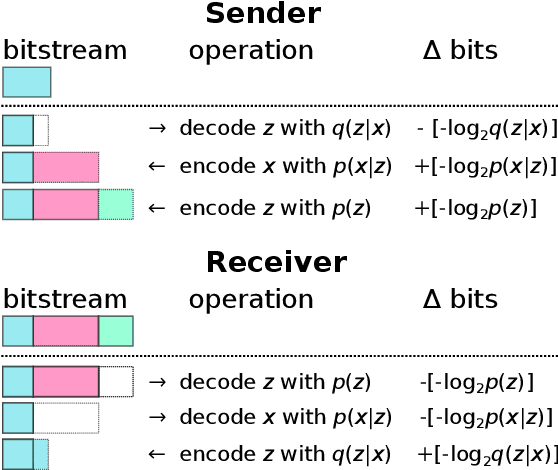
Neural compression is the application of neural networks and other machine learning methods to data compression. While machine learning deals with many concepts closely related to compression, entering the field of neural compression can be difficult due to its reliance on information theory, perceptual metrics, and other knowledge specific to the field. This introduction hopes to fill in the necessary background by reviewing basic coding topics such as entropy coding and rate-distortion theory, related machine learning ideas such as bits-back coding and perceptual metrics, and providing a guide through the representative works in the literature so far.
Decoupling and Recoupling Spatiotemporal Representation for RGB-D-based Motion Recognition
Dec 16, 2021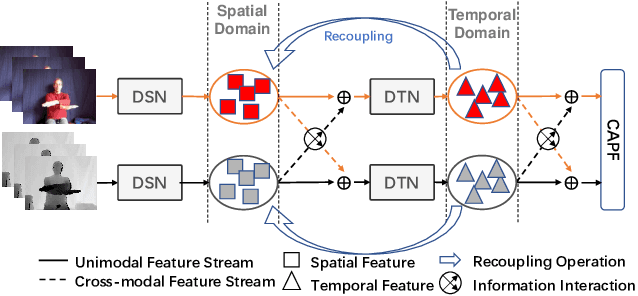
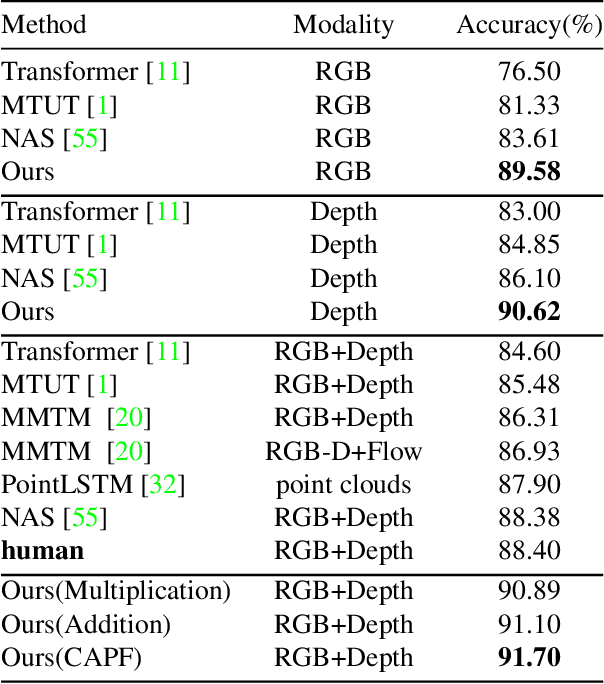
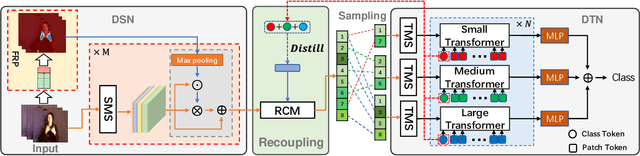
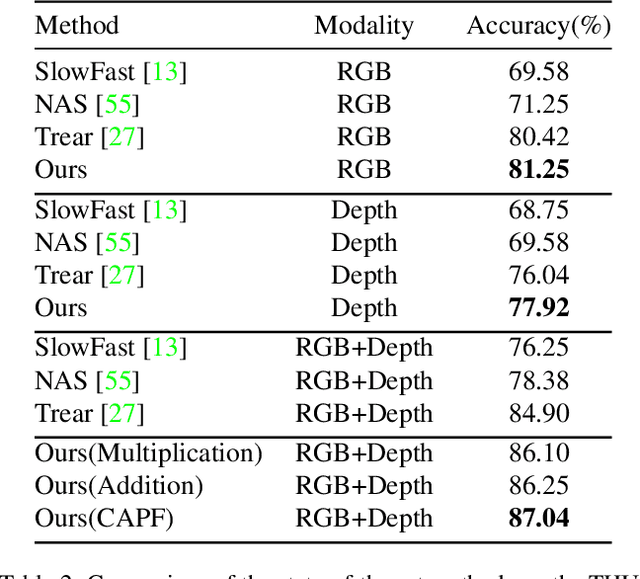
Decoupling spatiotemporal representation refers to decomposing the spatial and temporal features into dimension-independent factors. Although previous RGB-D-based motion recognition methods have achieved promising performance through the tightly coupled multi-modal spatiotemporal representation, they still suffer from (i) optimization difficulty under small data setting due to the tightly spatiotemporal-entangled modeling;(ii) information redundancy as it usually contains lots of marginal information that is weakly relevant to classification; and (iii) low interaction between multi-modal spatiotemporal information caused by insufficient late fusion. To alleviate these drawbacks, we propose to decouple and recouple spatiotemporal representation for RGB-D-based motion recognition. Specifically, we disentangle the task of learning spatiotemporal representation into 3 sub-tasks: (1) Learning high-quality and dimension independent features through a decoupled spatial and temporal modeling network. (2) Recoupling the decoupled representation to establish stronger space-time dependency. (3) Introducing a Cross-modal Adaptive Posterior Fusion (CAPF) mechanism to capture cross-modal spatiotemporal information from RGB-D data. Seamless combination of these novel designs forms a robust spatialtemporal representation and achieves better performance than state-of-the-art methods on four public motion datasets. Our code is available at https://github.com/damo-cv/MotionRGBD.
Supervising Remote Sensing Change Detection Models with 3D Surface Semantics
Feb 26, 2022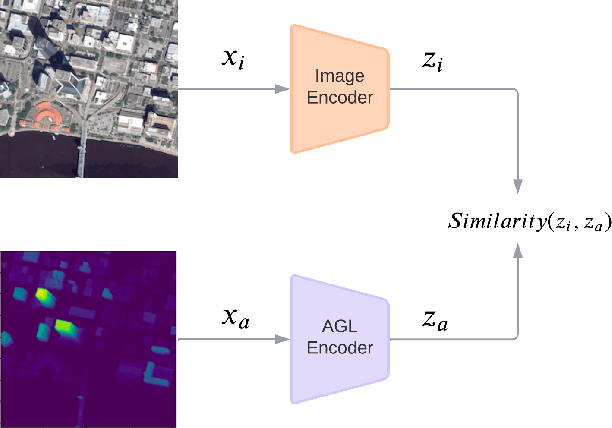
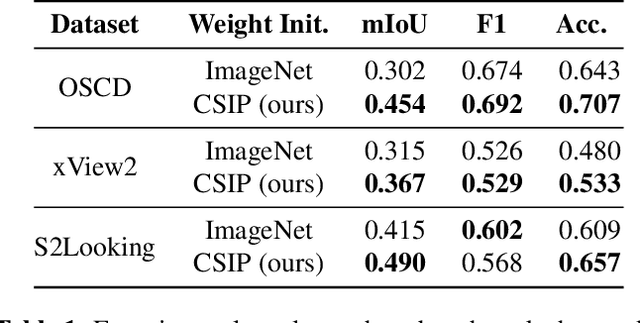
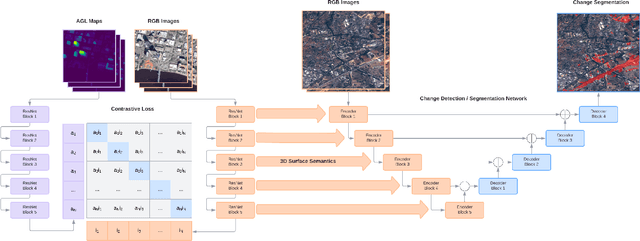
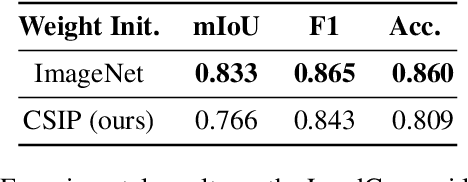
Remote sensing change detection, identifying changes between scenes of the same location, is an active area of research with a broad range of applications. Recent advances in multimodal self-supervised pretraining have resulted in state-of-the-art methods which surpass vision models trained solely on optical imagery. In the remote sensing field, there is a wealth of overlapping 2D and 3D modalities which can be exploited to supervise representation learning in vision models. In this paper we propose Contrastive Surface-Image Pretraining (CSIP) for joint learning using optical RGB and above ground level (AGL) map pairs. We then evaluate these pretrained models on several building segmentation and change detection datasets to show that our method does, in fact, extract features relevant to downstream applications where natural and artificial surface information is relevant.
It Takes Two to Tango: Combining Visual and Textual Information for Detecting Duplicate Video-Based Bug Reports
Jan 22, 2021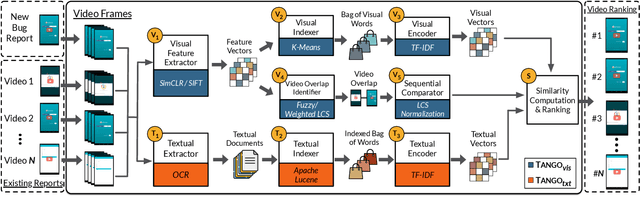
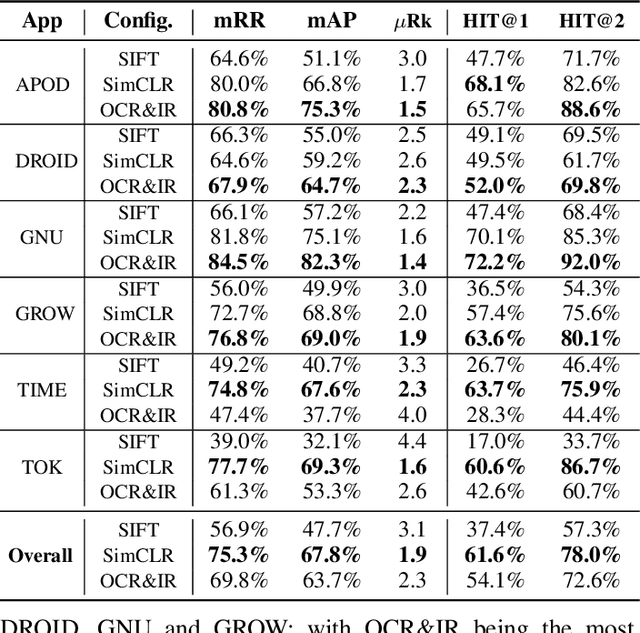
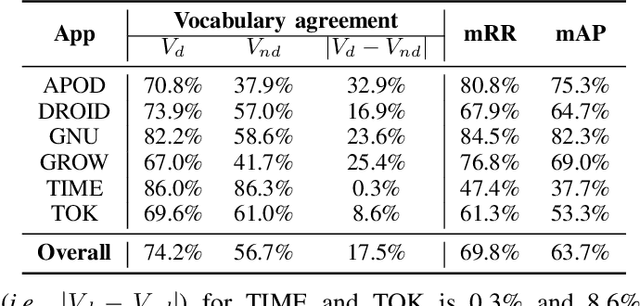
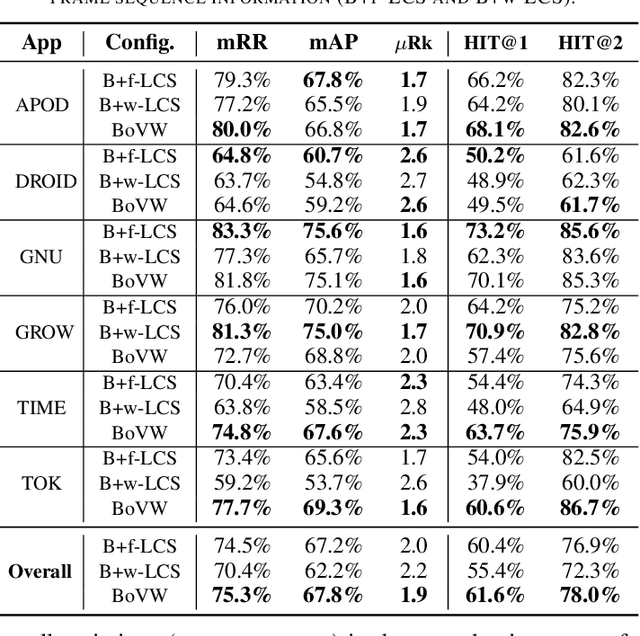
When a bug manifests in a user-facing application, it is likely to be exposed through the graphical user interface (GUI). Given the importance of visual information to the process of identifying and understanding such bugs, users are increasingly making use of screenshots and screen-recordings as a means to report issues to developers. However, when such information is reported en masse, such as during crowd-sourced testing, managing these artifacts can be a time-consuming process. As the reporting of screen-recordings in particular becomes more popular, developers are likely to face challenges related to manually identifying videos that depict duplicate bugs. Due to their graphical nature, screen-recordings present challenges for automated analysis that preclude the use of current duplicate bug report detection techniques. To overcome these challenges and aid developers in this task, this paper presents Tango, a duplicate detection technique that operates purely on video-based bug reports by leveraging both visual and textual information. Tango combines tailored computer vision techniques, optical character recognition, and text retrieval. We evaluated multiple configurations of Tango in a comprehensive empirical evaluation on 4,860 duplicate detection tasks that involved a total of 180 screen-recordings from six Android apps. Additionally, we conducted a user study investigating the effort required for developers to manually detect duplicate video-based bug reports and compared this to the effort required to use Tango. The results reveal that Tango's optimal configuration is highly effective at detecting duplicate video-based bug reports, accurately ranking target duplicate videos in the top-2 returned results in 83% of the tasks. Additionally, our user study shows that, on average, Tango can reduce developer effort by over 60%, illustrating its practicality.
A Novel Generator with Auxiliary Branch for Improving GAN Performance
Dec 30, 2021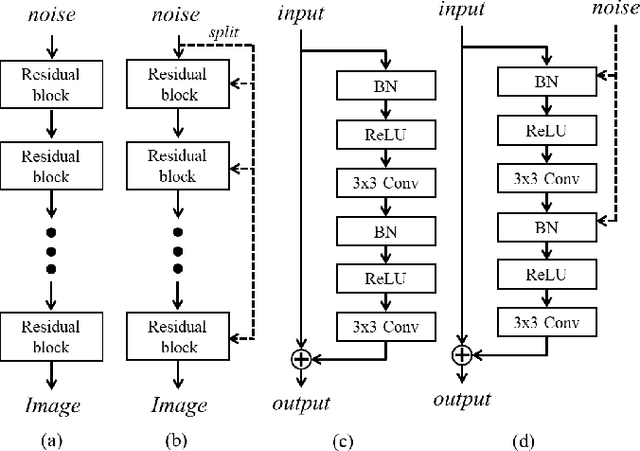
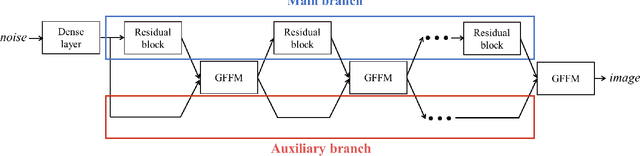
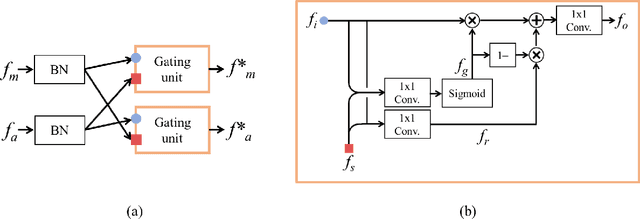
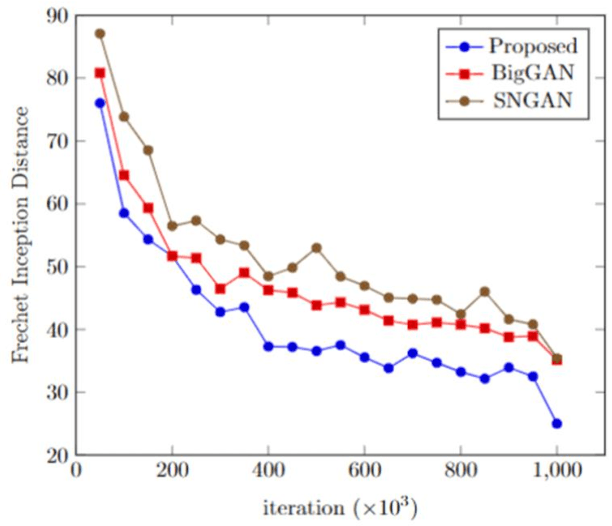
The generator in the generative adversarial network (GAN) learns image generation in a coarse-to-fine manner in which earlier layers learn an overall structure of the image and the latter ones refine the details. To propagate the coarse information well, recent works usually build their generators by stacking up multiple residual blocks. Although the residual block can produce the high-quality image as well as be trained stably, it often impedes the information flow in the network. To alleviate this problem, this brief introduces a novel generator architecture that produces the image by combining features obtained through two different branches: the main and auxiliary branches. The goal of the main branch is to produce the image by passing through the multiple residual blocks, whereas the auxiliary branch is to convey the coarse information in the earlier layer to the later one. To combine the features in the main and auxiliary branches successfully, we also propose a gated feature fusion module that controls the information flow in those branches. To prove the superiority of the proposed method, this brief provides extensive experiments using various standard datasets including CIFAR-10, CIFAR-100, LSUN, CelebA-HQ, AFHQ, and tiny- ImageNet. Furthermore, we conducted various ablation studies to demonstrate the generalization ability of the proposed method. Quantitative evaluations prove that the proposed method exhibits impressive GAN performance in terms of Inception score (IS) and Frechet inception distance (FID). For instance, the proposed method boosts the FID and IS scores on the tiny-ImageNet dataset from 35.13 to 25.00 and 20.23 to 25.57, respectively.
A study of deep perceptual metrics for image quality assessment
Feb 17, 2022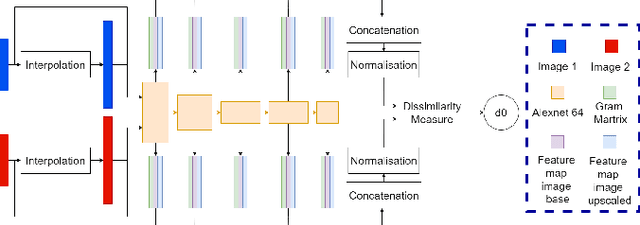
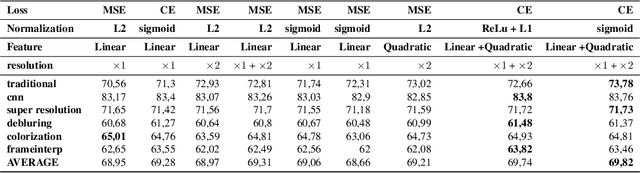
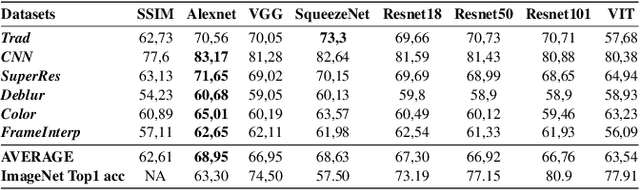
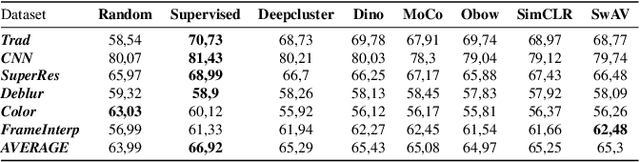
Several metrics exist to quantify the similarity between images, but they are inefficient when it comes to measure the similarity of highly distorted images. In this work, we propose to empirically investigate perceptual metrics based on deep neural networks for tackling the Image Quality Assessment (IQA) task. We study deep perceptual metrics according to different hyperparameters like the network's architecture or training procedure. Finally, we propose our multi-resolution perceptual metric (MR-Perceptual), that allows us to aggregate perceptual information at different resolutions and outperforms standard perceptual metrics on IQA tasks with varying image deformations. Our code is available at https://github.com/ENSTA-U2IS/MR_perceptual