 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Multi-task Generalization Ability for Neural Text Matching via Prompt Learning
Apr 06, 2022
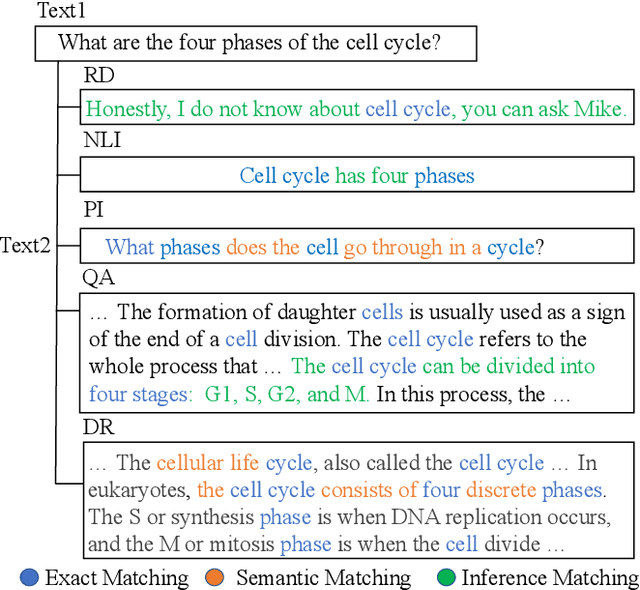

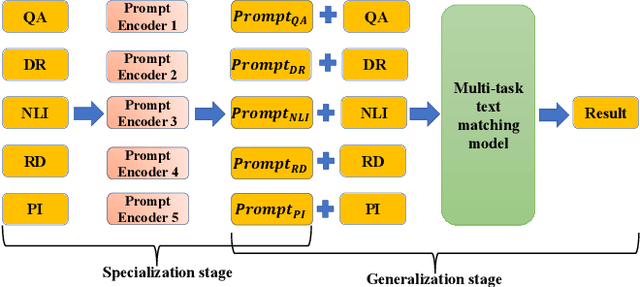
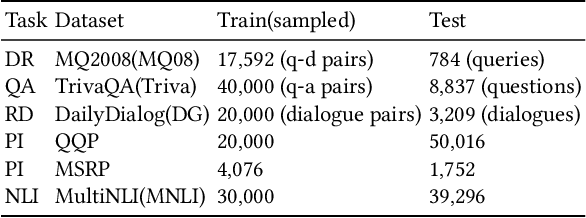
Text matching is a fundamental technique in both information retrieval and natural language processing. Text matching tasks share the same paradigm that determines the relationship between two given texts. Evidently, the relationships vary from task to task, e.g. relevance in document retrieval, semantic alignment in paraphrase identification and answerable judgment in question answering. However, the essential signals for text matching remain in a finite scope, i.e. exact matching, semantic matching, and inference matching. Recent state-of-the-art neural text matching models, e.g. pre-trained language models (PLMs), are hard to generalize to different tasks. It is because the end-to-end supervised learning on task-specific dataset makes model overemphasize the data sample bias and task-specific signals instead of the essential matching signals, which ruins the generalization of model to different tasks. To overcome this problem, we adopt a specialization-generalization training strategy and refer to it as Match-Prompt. In specialization stage, descriptions of different matching tasks are mapped to only a few prompt tokens. In generalization stage, text matching model explores the essential matching signals by being trained on diverse multiple matching tasks. High diverse matching tasks avoid model fitting the data sample bias on a specific task, so that model can focus on learning the essential matching signals. Meanwhile, the prompt tokens obtained in the first step are added to the corresponding tasks to help the model distinguish different task-specific matching signals. Experimental results on eighteen public datasets show that Match-Prompt can significantly improve multi-task generalization capability of PLMs in text matching, and yield better in-domain multi-task, out-of-domain multi-task and new task adaptation performance than task-specific model.
A Novel Generator with Auxiliary Branch for Improving GAN Performance
Dec 30, 2021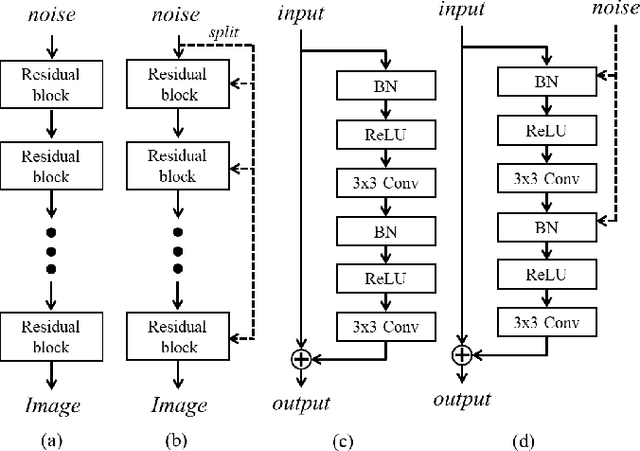
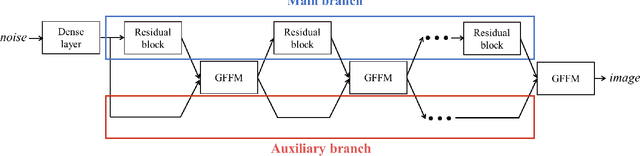
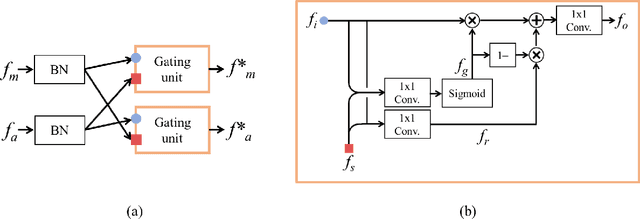
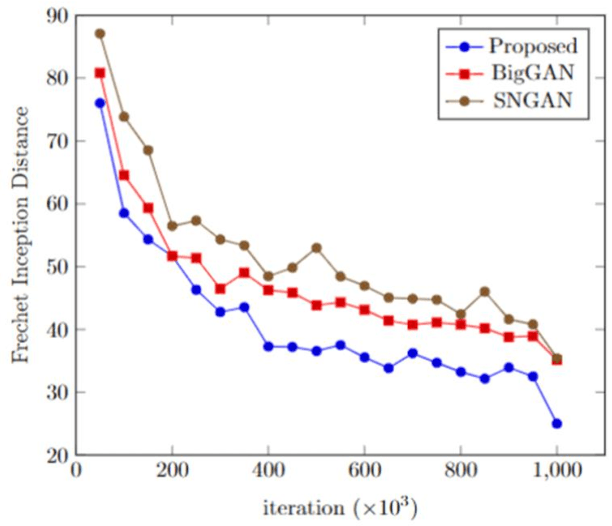
The generator in the generative adversarial network (GAN) learns image generation in a coarse-to-fine manner in which earlier layers learn an overall structure of the image and the latter ones refine the details. To propagate the coarse information well, recent works usually build their generators by stacking up multiple residual blocks. Although the residual block can produce the high-quality image as well as be trained stably, it often impedes the information flow in the network. To alleviate this problem, this brief introduces a novel generator architecture that produces the image by combining features obtained through two different branches: the main and auxiliary branches. The goal of the main branch is to produce the image by passing through the multiple residual blocks, whereas the auxiliary branch is to convey the coarse information in the earlier layer to the later one. To combine the features in the main and auxiliary branches successfully, we also propose a gated feature fusion module that controls the information flow in those branches. To prove the superiority of the proposed method, this brief provides extensive experiments using various standard datasets including CIFAR-10, CIFAR-100, LSUN, CelebA-HQ, AFHQ, and tiny- ImageNet. Furthermore, we conducted various ablation studies to demonstrate the generalization ability of the proposed method. Quantitative evaluations prove that the proposed method exhibits impressive GAN performance in terms of Inception score (IS) and Frechet inception distance (FID). For instance, the proposed method boosts the FID and IS scores on the tiny-ImageNet dataset from 35.13 to 25.00 and 20.23 to 25.57, respectively.
Radio-Assisted Human Detection
Dec 16, 2021
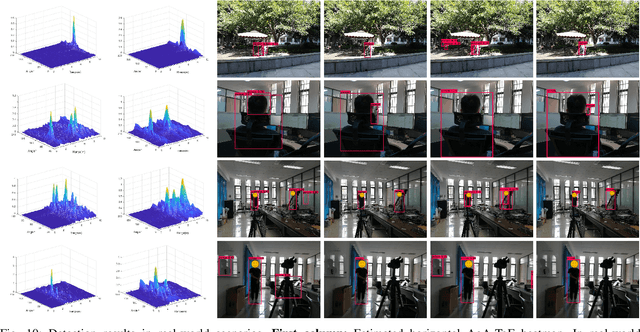
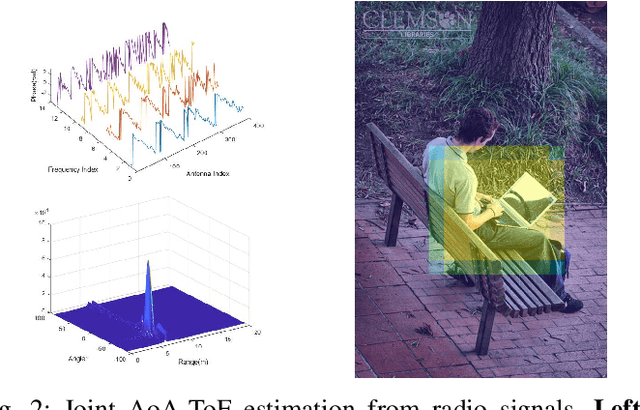
In this paper, we propose a radio-assisted human detection framework by incorporating radio information into the state-of-the-art detection methods, including anchor-based onestage detectors and two-stage detectors. We extract the radio localization and identifer information from the radio signals to assist the human detection, due to which the problem of false positives and false negatives can be greatly alleviated. For both detectors, we use the confidence score revision based on the radio localization to improve the detection performance. For two-stage detection methods, we propose to utilize the region proposals generated from radio localization rather than relying on region proposal network (RPN). Moreover, with the radio identifier information, a non-max suppression method with the radio localization constraint has also been proposed to further suppress the false detections and reduce miss detections. Experiments on the simulative Microsoft COCO dataset and Caltech pedestrian datasets show that the mean average precision (mAP) and the miss rate of the state-of-the-art detection methods can be improved with the aid of radio information. Finally, we conduct experiments in real-world scenarios to demonstrate the feasibility of our proposed method in practice.
EEG to fMRI Synthesis Benefits from Attentional Graphs of Electrode Relationships
Mar 07, 2022

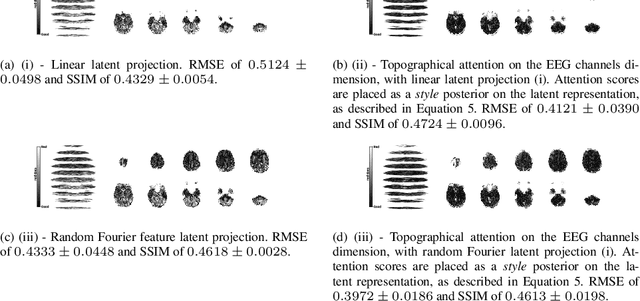
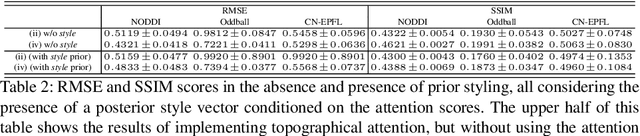
Topographical structures represent connections between entities and provide a comprehensive design of complex systems. Currently these structures are used to discover correlates of neuronal and haemodynamical activity. In this work, we incorporate them with neural processing techniques to perform regression, using electrophysiological activity to retrieve haemodynamics. To this end, we use Fourier features, attention mechanisms, shared space between modalities and incorporation of style in the latent representation. By combining these techniques, we propose several models that significantly outperform current state-of-the-art of this task in resting state and task-based recording settings. We report which EEG electrodes are the most relevant for the regression task and which relations impacted it the most. In addition, we observe that haemodynamic activity at the scalp, in contrast with sub-cortical regions, is relevant to the learned shared space. Overall, these results suggest that EEG electrode relationships are pivotal to retain information necessary for haemodynamical activity retrieval.
Reinforcement Learning for Location-Aware Scheduling
Mar 07, 2022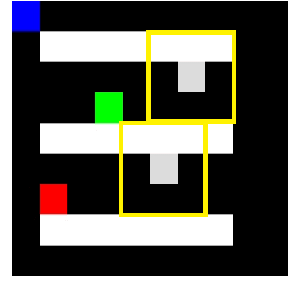
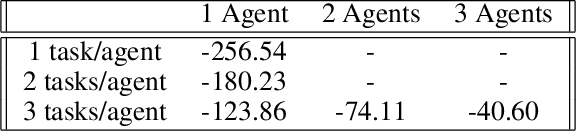
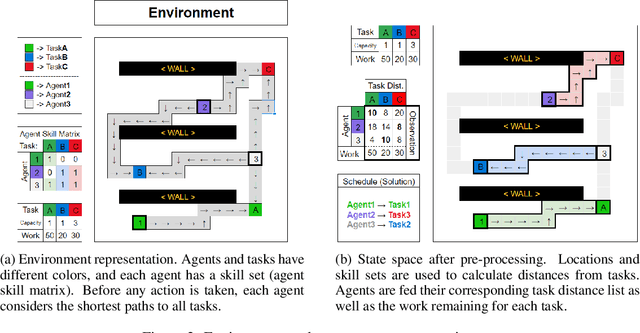
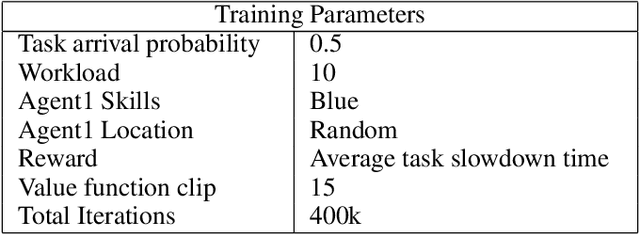
Recent techniques in dynamical scheduling and resource management have found applications in warehouse environments due to their ability to organize and prioritize tasks in a higher temporal resolution. The rise of deep reinforcement learning, as a learning paradigm, has enabled decentralized agent populations to discover complex coordination strategies. However, training multiple agents simultaneously introduce many obstacles in training as observation and action spaces become exponentially large. In our work, we experimentally quantify how various aspects of the warehouse environment (e.g., floor plan complexity, information about agents' live location, level of task parallelizability) affect performance and execution priority. To achieve efficiency, we propose a compact representation of the state and action space for location-aware multi-agent systems, wherein each agent has knowledge of only self and task coordinates, hence only partial observability of the underlying Markov Decision Process. Finally, we show how agents trained in certain environments maintain performance in completely unseen settings and also correlate performance degradation with floor plan geometry.
A Glyph-driven Topology Enhancement Network for Scene Text Recognition
Mar 07, 2022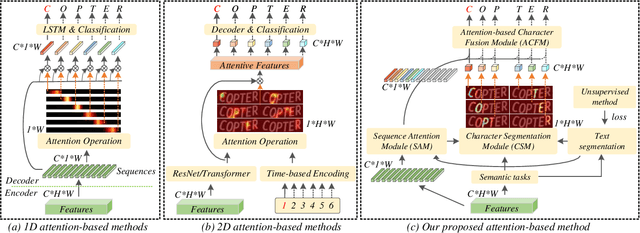
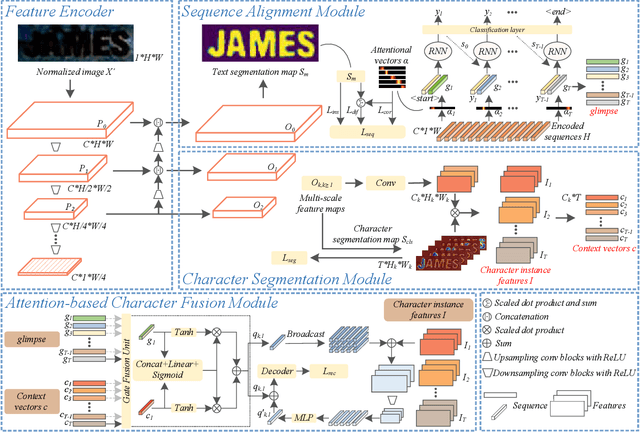
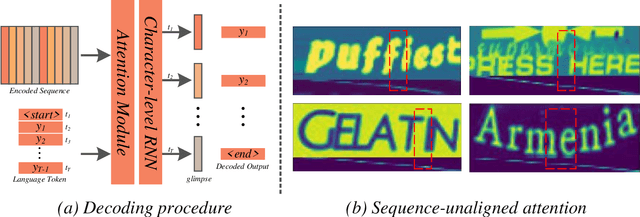

Attention-based methods by establishing one-dimensional (1D) and two-dimensional (2D) mechanisms with an encoder-decoder framework have dominated scene text recognition (STR) tasks due to their capabilities of building implicit language representations. However, 1D attention-based mechanisms suffer from alignment drift on latter characters. 2D attention-based mechanisms only roughly focus on the spatial regions of characters without excavating detailed topological structures, which reduces the visual performance. To mitigate the above issues, we propose a novel Glyph-driven Topology Enhancement Network (GTEN) to improve topological features representations in visual models for STR. Specifically, an unsupervised method is first employed to exploit 1D sequence-aligned attention weights. Second, we construct a supervised segmentation module to capture 2D ordered and pixel-wise topological information of glyphs without extra character-level annotations. Third, these resulting outputs fuse enhanced topological features to enrich semantic feature representations for STR. Experiments demonstrate that GTEN achieves competitive performance on IIIT5K-Words, Street View Text, ICDAR-series, SVT Perspective, and CUTE80 datasets.
Prediction-Aware Quality Enhancement of VVC Using CNN
Dec 08, 2021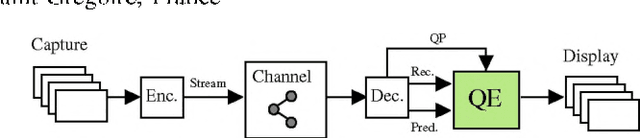

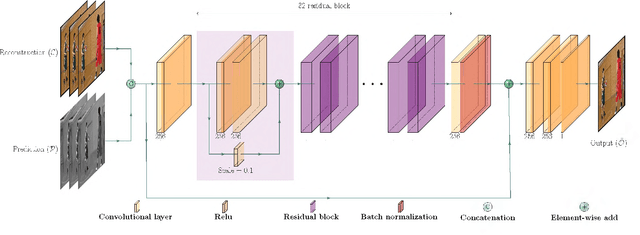
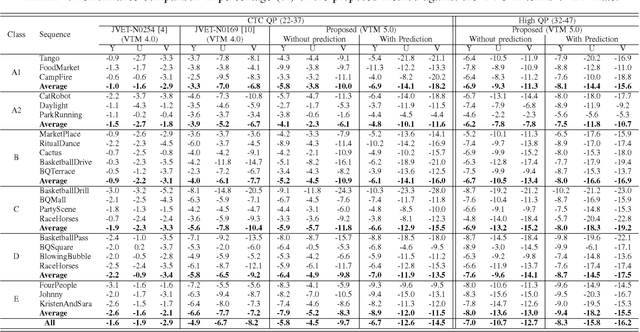
The upcoming video coding standard, Versatile Video Coding (VVC), has shown great improvement compared to its predecessor, High Efficiency Video Coding (HEVC), in terms of bitrate saving. Despite its substantial performance, compressed videos might still suffer from quality degradation at low bitrates due to coding artifacts such as blockiness, blurriness and ringing. In this work, we exploit Convolutional Neural Networks (CNN) to enhance quality of VVC coded frames after decoding in order to reduce low bitrate artifacts. The main contribution of this work is the use of coding information from the compressed bitstream. More precisely, the prediction information of intra frames is used for training the network in addition to the reconstruction information. The proposed method is applied on both luminance and chrominance components of intra coded frames of VVC. Experiments on VVC Test Model (VTM) show that, both in low and high bitrates, the use of coding information can improve the BD-rate performance by about 1% and 6% for luma and chroma components, respectively.
SEN12MS-CR-TS: A Remote Sensing Data Set for Multi-modal Multi-temporal Cloud Removal
Jan 24, 2022


About half of all optical observations collected via spaceborne satellites are affected by haze or clouds. Consequently, cloud coverage affects the remote sensing practitioner's capabilities of a continuous and seamless monitoring of our planet. This work addresses the challenge of optical satellite image reconstruction and cloud removal by proposing a novel multi-modal and multi-temporal data set called SEN12MS-CR-TS. We propose two models highlighting the benefits and use cases of SEN12MS-CR-TS: First, a multi-modal multi-temporal 3D-Convolution Neural Network that predicts a cloud-free image from a sequence of cloudy optical and radar images. Second, a sequence-to-sequence translation model that predicts a cloud-free time series from a cloud-covered time series. Both approaches are evaluated experimentally, with their respective models trained and tested on SEN12MS-CR-TS. The conducted experiments highlight the contribution of our data set to the remote sensing community as well as the benefits of multi-modal and multi-temporal information to reconstruct noisy information. Our data set is available at https://patrickTUM.github.io/cloud_removal
A Deep Learning Approach for Digital ColorReconstruction of Lenticular Films
Feb 10, 2022
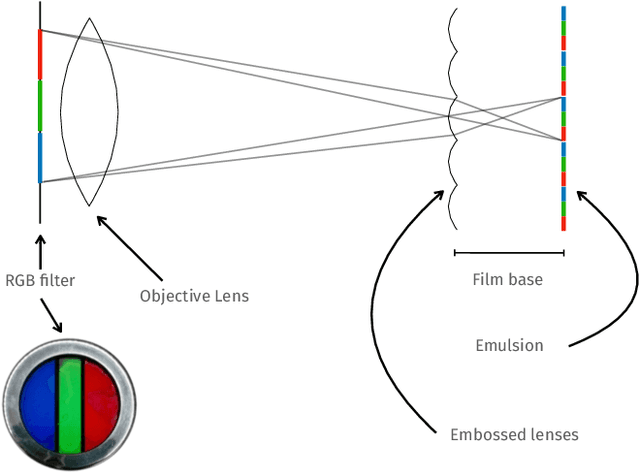

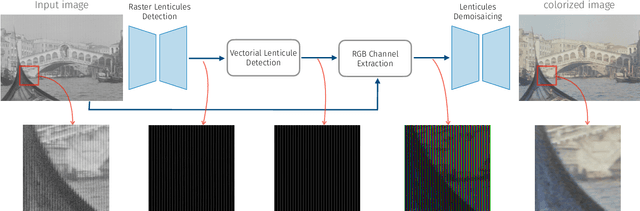
We propose the first accurate digitization and color reconstruction process for historical lenticular film that is robust to artifacts. Lenticular films emerged in the 1920s and were one of the first technologies that permitted to capture full color information in motion. The technology leverages an RGB filter and cylindrical lenticules embossed on the film surface to encode the color in the horizontal spatial dimension of the image. To project the pictures the encoding process was reversed using an appropriate analog device. In this work, we introduce an automated, fully digital pipeline to process the scan of lenticular films and colorize the image. Our method merges deep learning with a model-based approach in order to maximize the performance while making sure that the reconstructed colored images truthfully match the encoded color information. Our model employs different strategies to achieve an effective color reconstruction, in particular (i) we use data augmentation to create a robust lenticule segmentation network, (ii) we fit the lenticules raster prediction to obtain a precise vectorial lenticule localization, and (iii) we train a colorization network that predicts interpolation coefficients in order to obtain a truthful colorization. We validate the proposed method on a lenticular film dataset and compare it to other approaches. Since no colored groundtruth is available as reference, we conduct a user study to validate our method in a subjective manner. The results of the study show that the proposed method is largely preferred with respect to other existing and baseline methods.
Mutual Information Decay Curves and Hyper-Parameter Grid Search Design for Recurrent Neural Architectures
Dec 08, 2020
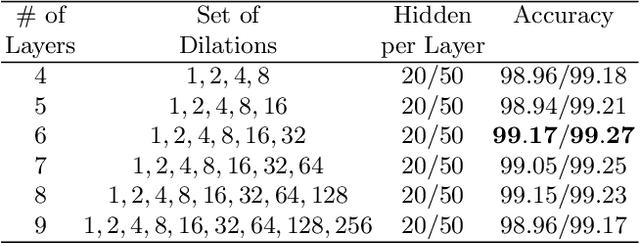
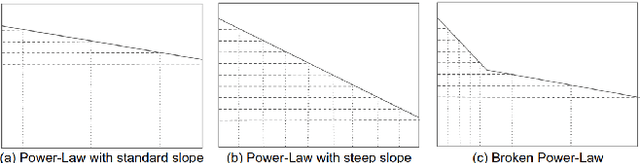
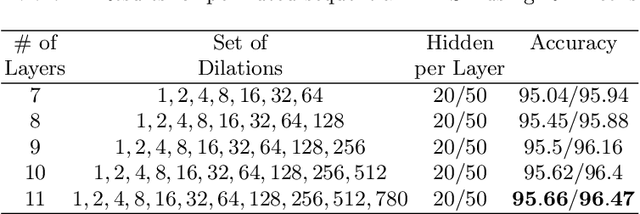
We present an approach to design the grid searches for hyper-parameter optimization for recurrent neural architectures. The basis for this approach is the use of mutual information to analyze long distance dependencies (LDDs) within a dataset. We also report a set of experiments that demonstrate how using this approach, we obtain state-of-the-art results for DilatedRNNs across a range of benchmark datasets.