 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Micro-video Thumbnail Selection via a Multi-label Visual-semantic Embedding Model
Feb 07, 2022
The thumbnail, as the first sight of a micro-video, plays a pivotal role in attracting users to click and watch. While in the real scenario, the more the thumbnails satisfy the users, the more likely the micro-videos will be clicked. In this paper, we aim to select the thumbnail of a given micro-video that meets most users` interests. Towards this end, we present a multi-label visual-semantic embedding model to estimate the similarity between the pair of each frame and the popular topics that users are interested in. In this model, the visual and textual information is embedded into a shared semantic space, whereby the similarity can be measured directly, even the unseen words. Moreover, to compare the frame to all words from the popular topics, we devise an attention embedding space associated with the semantic-attention projection. With the help of these two embedding spaces, the popularity score of a frame, which is defined by the sum of similarity scores over the corresponding visual information and popular topic pairs, is achieved. Ultimately, we fuse the visual representation score and the popularity score of each frame to select the attractive thumbnail for the given micro-video. Extensive experiments conducted on a real-world dataset have well-verified that our model significantly outperforms several state-of-the-art baselines.
SwiftAgg+: Achieving Asymptotically Optimal Communication Load in Secure Aggregation for Federated Learning
Mar 24, 2022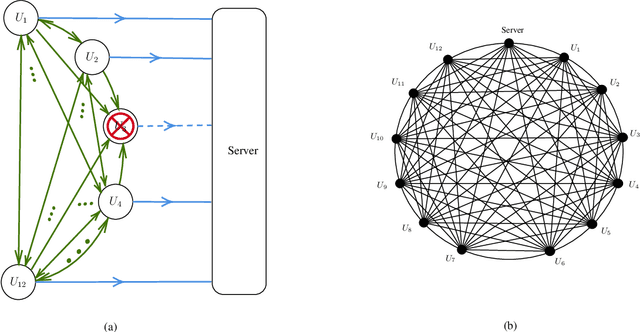
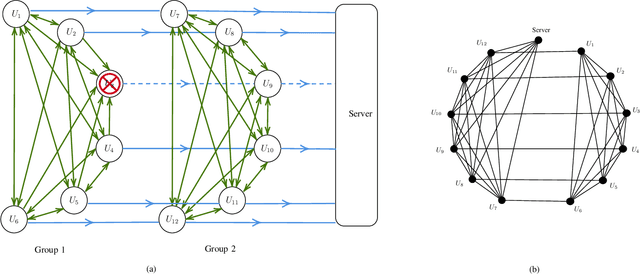
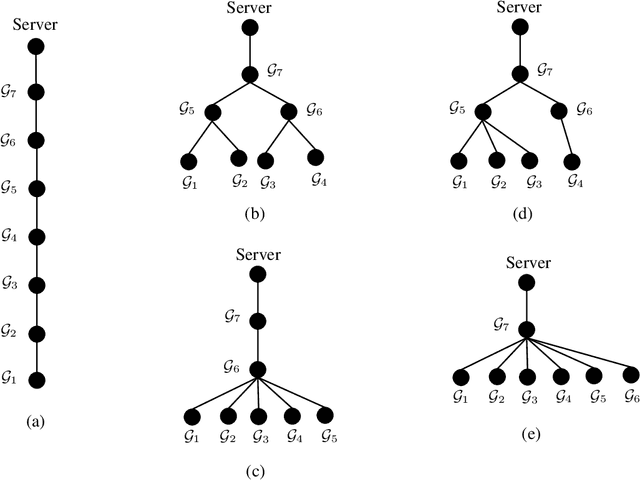
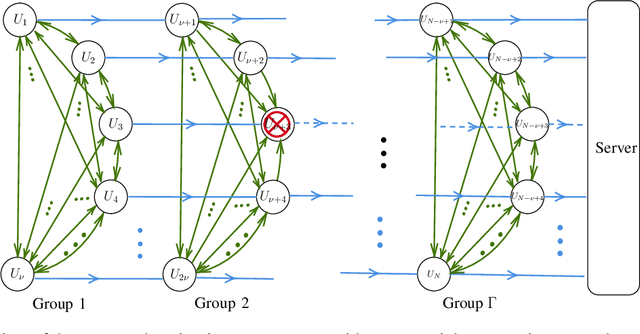
We propose SwiftAgg+, a novel secure aggregation protocol for federated learning systems, where a central server aggregates local models of $N\in\mathbb{N}$ distributed users, each of size $L \in \mathbb{N}$, trained on their local data, in a privacy-preserving manner. SwiftAgg+ can significantly reduce the communication overheads without any compromise on security, and achieve the optimum communication load within a diminishing gap. Specifically, in presence of at most $D$ dropout users, SwiftAgg+ achieves average per-user communication load of $(1+\mathcal{O}(\frac{1}{N}))L$ and the server communication load of $(1+\mathcal{O}(\frac{1}{N}))L$, with a worst-case information-theoretic security guarantee, against any subset of up to $T$ semi-honest users who may also collude with the curious server. The proposed SwiftAgg+ has also a flexibility to reduce the number of active communication links at the cost of increasing the the communication load between the users and the server. In particular, for any $K\in\mathbb{N}$, SwiftAgg+ can achieve the uplink communication load of $(1+\frac{T}{K})L$, and per-user communication load of up to $(1-\frac{1}{N})(1+\frac{T+D}{K})L$, where the number of pair-wise active connections in the network is $\frac{N}{2}(K+T+D+1)$.
EEG to fMRI Synthesis Benefits from Attentional Graphs of Electrode Relationships
Mar 07, 2022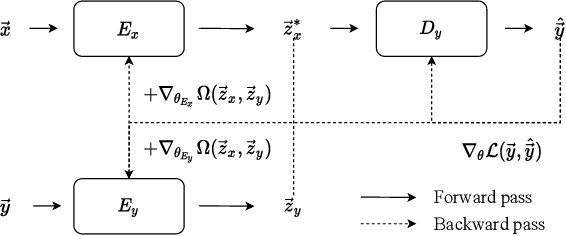

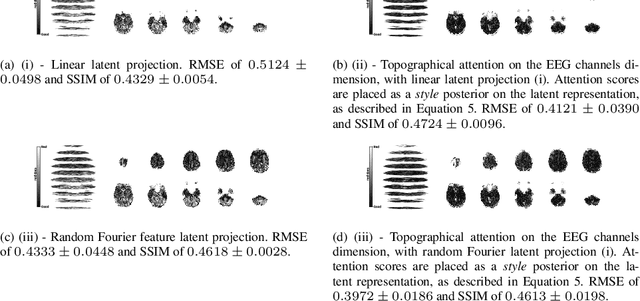
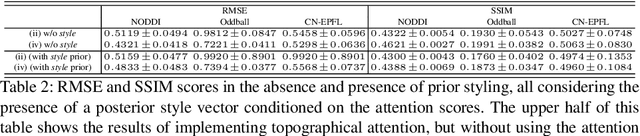
Topographical structures represent connections between entities and provide a comprehensive design of complex systems. Currently these structures are used to discover correlates of neuronal and haemodynamical activity. In this work, we incorporate them with neural processing techniques to perform regression, using electrophysiological activity to retrieve haemodynamics. To this end, we use Fourier features, attention mechanisms, shared space between modalities and incorporation of style in the latent representation. By combining these techniques, we propose several models that significantly outperform current state-of-the-art of this task in resting state and task-based recording settings. We report which EEG electrodes are the most relevant for the regression task and which relations impacted it the most. In addition, we observe that haemodynamic activity at the scalp, in contrast with sub-cortical regions, is relevant to the learned shared space. Overall, these results suggest that EEG electrode relationships are pivotal to retain information necessary for haemodynamical activity retrieval.
Reinforcement Learning for Location-Aware Scheduling
Mar 07, 2022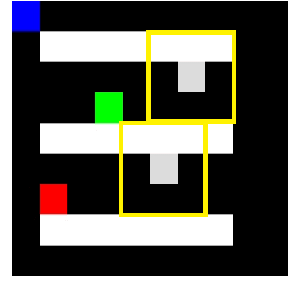
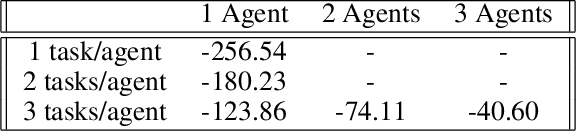
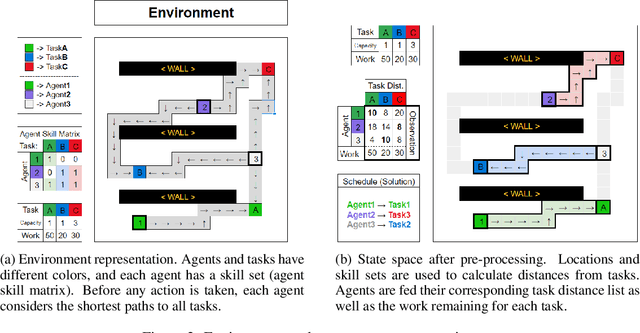
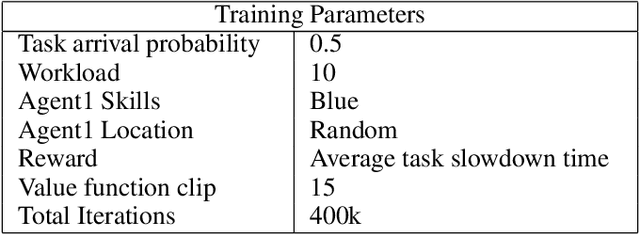
Recent techniques in dynamical scheduling and resource management have found applications in warehouse environments due to their ability to organize and prioritize tasks in a higher temporal resolution. The rise of deep reinforcement learning, as a learning paradigm, has enabled decentralized agent populations to discover complex coordination strategies. However, training multiple agents simultaneously introduce many obstacles in training as observation and action spaces become exponentially large. In our work, we experimentally quantify how various aspects of the warehouse environment (e.g., floor plan complexity, information about agents' live location, level of task parallelizability) affect performance and execution priority. To achieve efficiency, we propose a compact representation of the state and action space for location-aware multi-agent systems, wherein each agent has knowledge of only self and task coordinates, hence only partial observability of the underlying Markov Decision Process. Finally, we show how agents trained in certain environments maintain performance in completely unseen settings and also correlate performance degradation with floor plan geometry.
A Joint Morphological Profiles and Patch Tensor Change Detection for Hyperspectral Imagery
Jan 20, 2022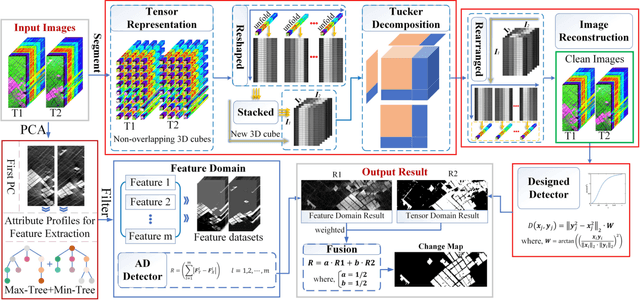

Multi-temporal hyperspectral images can be used to detect changed information, which has gradually attracted researchers' attention. However, traditional change detection algorithms have not deeply explored the relevance of spatial and spectral changed features, which leads to low detection accuracy. To better excavate both spectral and spatial information of changed features, a joint morphology and patch-tensor change detection (JMPT) method is proposed. Initially, a patch-based tensor strategy is adopted to exploit similar property of spatial structure, where the non-overlapping local patch image is reshaped into a new tensor cube, and then three-order Tucker decompositon and image reconstruction strategies are adopted to obtain more robust multi-temporal hyperspectral datasets. Meanwhile, multiple morphological profiles including max-tree and min-tree are applied to extract different attributes of multi-temporal images. Finally, these results are fused to general a final change detection map. Experiments conducted on two real hyperspectral datasets demonstrate that the proposed detector achieves better detection performance.
Maximizing Self-supervision from Thermal Image for Effective Self-supervised Learning of Depth and Ego-motion
Jan 12, 2022

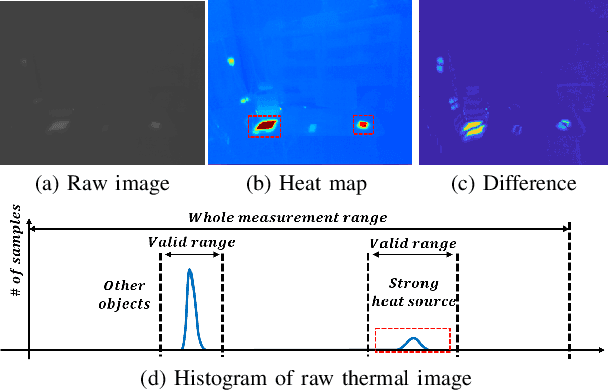
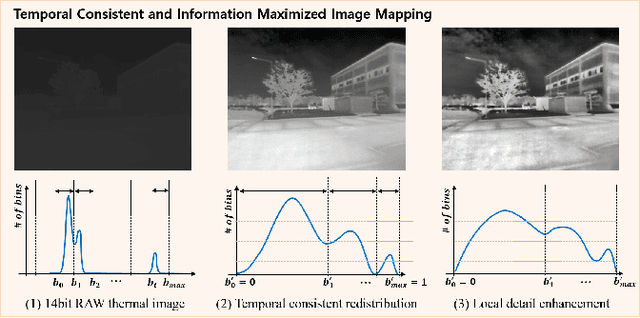
Recently, self-supervised learning of depth and ego-motion from thermal images shows strong robustness and reliability under challenging scenarios. However, the inherent thermal image properties such as weak contrast, blurry edges, and noise hinder to generate effective self-supervision from thermal images. Therefore, most research relies on additional self-supervision sources such as well-lit RGB images, generative models, and Lidar information. In this paper, we conduct an in-depth analysis of thermal image characteristics that degenerates self-supervision from thermal images. Based on the analysis, we propose an effective thermal image mapping method that significantly increases image information, such as overall structure, contrast, and details, while preserving temporal consistency. The proposed method shows outperformed depth and pose results than previous state-of-the-art networks without leveraging additional RGB guidance.
Zero Pixel Directional Boundary by Vector Transform
Mar 16, 2022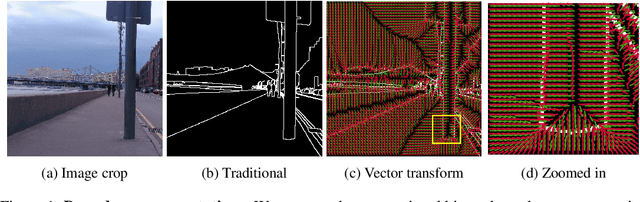
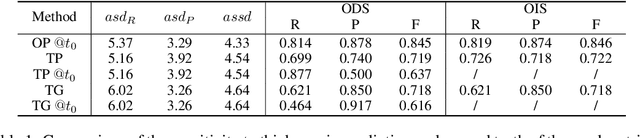
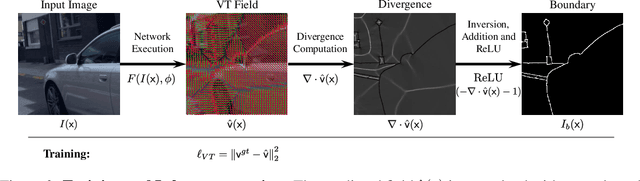
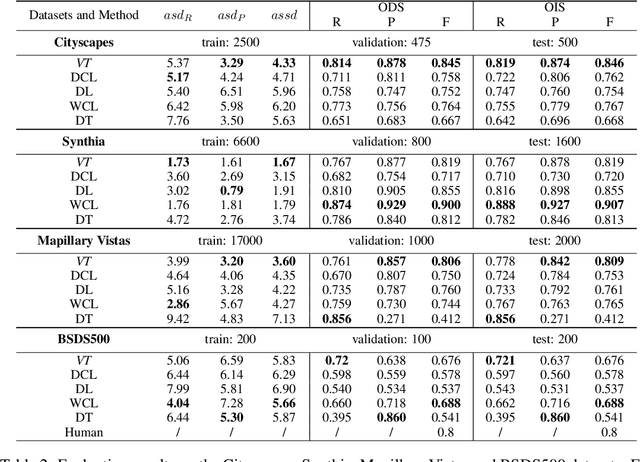
Boundaries are among the primary visual cues used by human and computer vision systems. One of the key problems in boundary detection is the label representation, which typically leads to class imbalance and, as a consequence, to thick boundaries that require non-differential post-processing steps to be thinned. In this paper, we re-interpret boundaries as 1-D surfaces and formulate a one-to-one vector transform function that allows for training of boundary prediction completely avoiding the class imbalance issue. Specifically, we define the boundary representation at any point as the unit vector pointing to the closest boundary surface. Our problem formulation leads to the estimation of direction as well as richer contextual information of the boundary, and, if desired, the availability of zero-pixel thin boundaries also at training time. Our method uses no hyper-parameter in the training loss and a fixed stable hyper-parameter at inference. We provide theoretical justification/discussions of the vector transform representation. We evaluate the proposed loss method using a standard architecture and show the excellent performance over other losses and representations on several datasets.
A Glyph-driven Topology Enhancement Network for Scene Text Recognition
Mar 07, 2022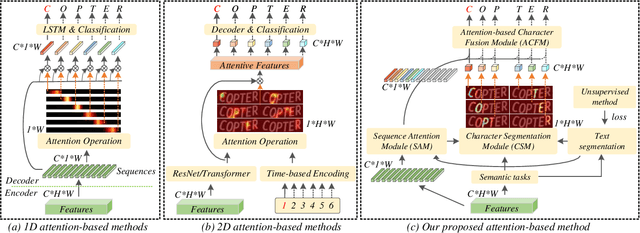
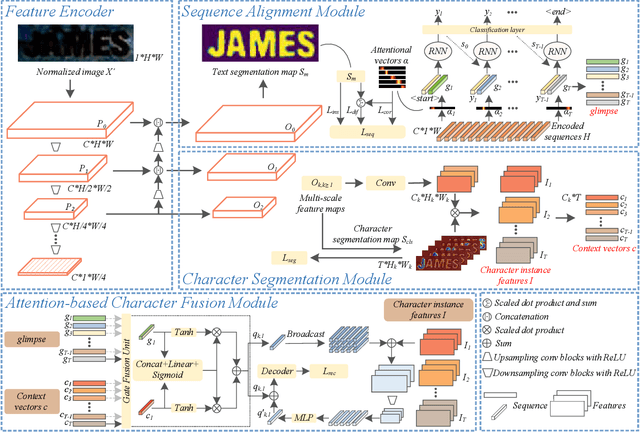
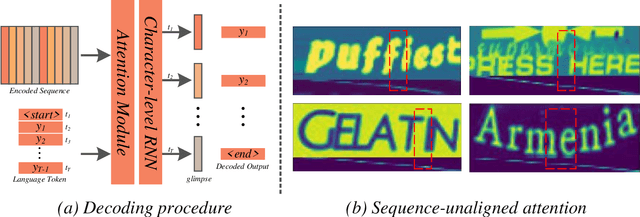

Attention-based methods by establishing one-dimensional (1D) and two-dimensional (2D) mechanisms with an encoder-decoder framework have dominated scene text recognition (STR) tasks due to their capabilities of building implicit language representations. However, 1D attention-based mechanisms suffer from alignment drift on latter characters. 2D attention-based mechanisms only roughly focus on the spatial regions of characters without excavating detailed topological structures, which reduces the visual performance. To mitigate the above issues, we propose a novel Glyph-driven Topology Enhancement Network (GTEN) to improve topological features representations in visual models for STR. Specifically, an unsupervised method is first employed to exploit 1D sequence-aligned attention weights. Second, we construct a supervised segmentation module to capture 2D ordered and pixel-wise topological information of glyphs without extra character-level annotations. Third, these resulting outputs fuse enhanced topological features to enrich semantic feature representations for STR. Experiments demonstrate that GTEN achieves competitive performance on IIIT5K-Words, Street View Text, ICDAR-series, SVT Perspective, and CUTE80 datasets.
Translation and Rotation Equivariant Normalizing Flow (TRENF) for Optimal Cosmological Analysis
Feb 10, 2022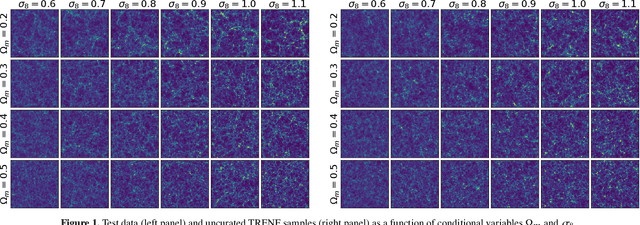
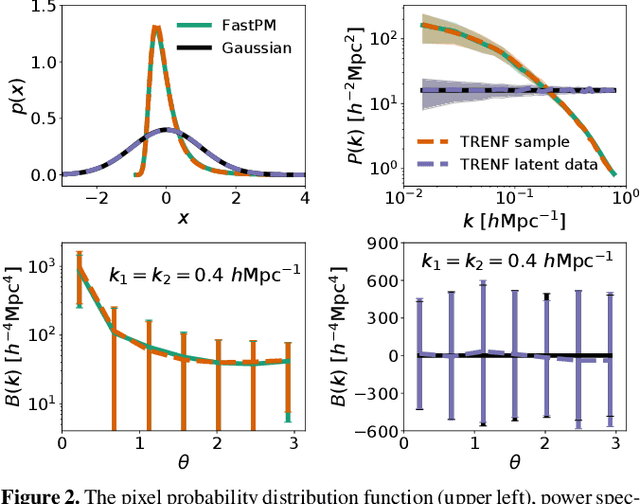
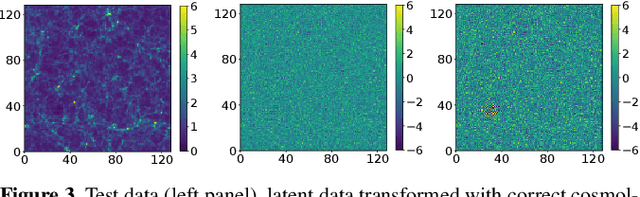
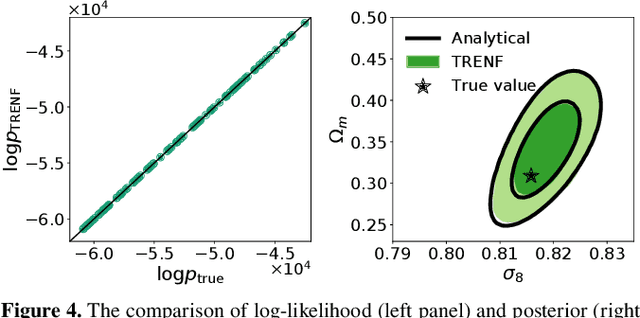
Our universe is homogeneous and isotropic, and its perturbations obey translation and rotation symmetry. In this work we develop Translation and Rotation Equivariant Normalizing Flow (TRENF), a generative Normalizing Flow (NF) model which explicitly incorporates these symmetries, defining the data likelihood via a sequence of Fourier space-based convolutions and pixel-wise nonlinear transforms. TRENF gives direct access to the high dimensional data likelihood p(x|y) as a function of the labels y, such as cosmological parameters. In contrast to traditional analyses based on summary statistics, the NF approach has no loss of information since it preserves the full dimensionality of the data. On Gaussian random fields, the TRENF likelihood agrees well with the analytical expression and saturates the Fisher information content in the labels y. On nonlinear cosmological overdensity fields from N-body simulations, TRENF leads to significant improvements in constraining power over the standard power spectrum summary statistic. TRENF is also a generative model of the data, and we show that TRENF samples agree well with the N-body simulations it trained on, and that the inverse mapping of the data agrees well with a Gaussian white noise both visually and on various summary statistics: when this is perfectly achieved the resulting p(x|y) likelihood analysis becomes optimal. Finally, we develop a generalization of this model that can handle effects that break the symmetry of the data, such as the survey mask, which enables likelihood analysis on data without periodic boundaries.
An Exploratory Study on Code Attention in BERT
Apr 05, 2022
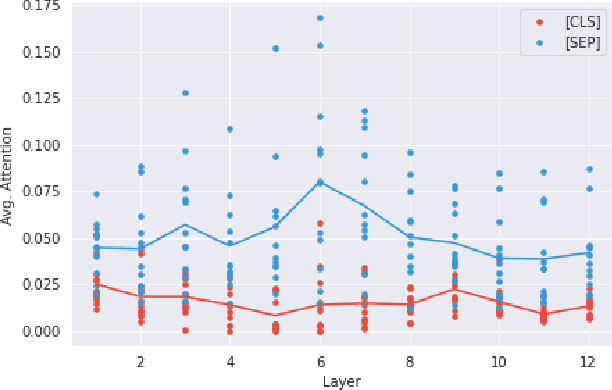

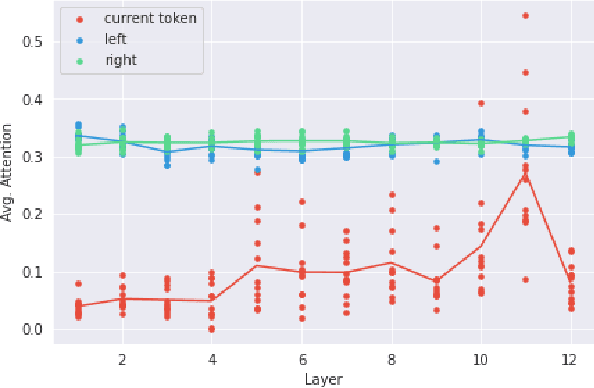
Many recent models in software engineering introduced deep neural models based on the Transformer architecture or use transformer-based Pre-trained Language Models (PLM) trained on code. Although these models achieve the state of the arts results in many downstream tasks such as code summarization and bug detection, they are based on Transformer and PLM, which are mainly studied in the Natural Language Processing (NLP) field. The current studies rely on the reasoning and practices from NLP for these models in code, despite the differences between natural languages and programming languages. There is also limited literature on explaining how code is modeled. Here, we investigate the attention behavior of PLM on code and compare it with natural language. We pre-trained BERT, a Transformer based PLM, on code and explored what kind of information it learns, both semantic and syntactic. We run several experiments to analyze the attention values of code constructs on each other and what BERT learns in each layer. Our analyses show that BERT pays more attention to syntactic entities, specifically identifiers and separators, in contrast to the most attended token [CLS] in NLP. This observation motivated us to leverage identifiers to represent the code sequence instead of the [CLS] token when used for code clone detection. Our results show that employing embeddings from identifiers increases the performance of BERT by 605% and 4% F1-score in its lower layers and the upper layers, respectively. When identifiers' embeddings are used in CodeBERT, a code-based PLM, the performance is improved by 21-24% in the F1-score of clone detection. The findings can benefit the research community by using code-specific representations instead of applying the common embeddings used in NLP, and open new directions for developing smaller models with similar performance.