 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Information Bottleneck Problem and Its Applications in Machine Learning
Apr 30, 2020
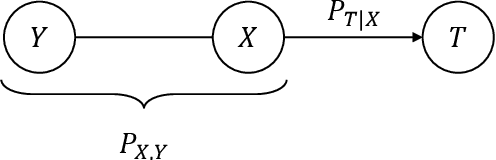
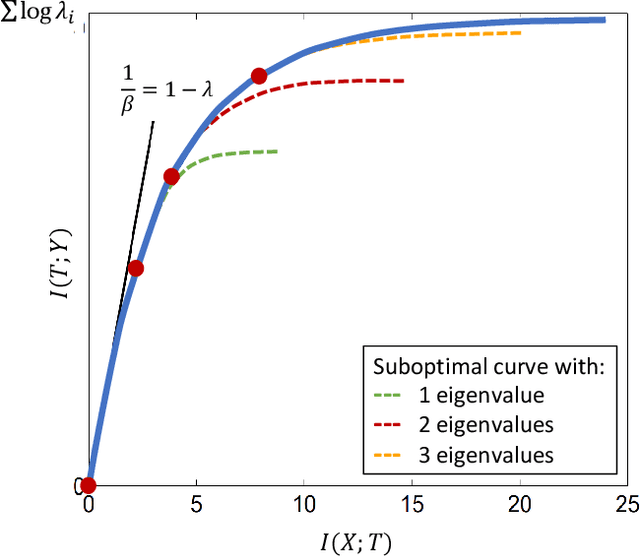
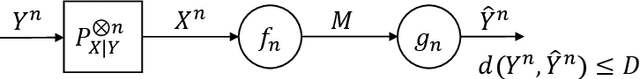
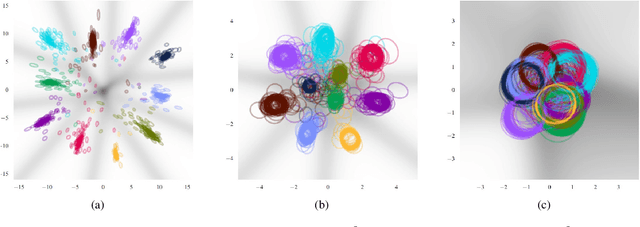
Inference capabilities of machine learning (ML) systems skyrocketed in recent years, now playing a pivotal role in various aspect of society. The goal in statistical learning is to use data to obtain simple algorithms for predicting a random variable $Y$ from a correlated observation $X$. Since the dimension of $X$ is typically huge, computationally feasible solutions should summarize it into a lower-dimensional feature vector $T$, from which $Y$ is predicted. The algorithm will successfully make the prediction if $T$ is a good proxy of $Y$, despite the said dimensionality-reduction. A myriad of ML algorithms (mostly employing deep learning (DL)) for finding such representations $T$ based on real-world data are now available. While these methods are often effective in practice, their success is hindered by the lack of a comprehensive theory to explain it. The information bottleneck (IB) theory recently emerged as a bold information-theoretic paradigm for analyzing DL systems. Adopting mutual information as the figure of merit, it suggests that the best representation $T$ should be maximally informative about $Y$ while minimizing the mutual information with $X$. In this tutorial we survey the information-theoretic origins of this abstract principle, and its recent impact on DL. For the latter, we cover implications of the IB problem on DL theory, as well as practical algorithms inspired by it. Our goal is to provide a unified and cohesive description. A clear view of current knowledge is particularly important for further leveraging IB and other information-theoretic ideas to study DL models.
On the Inclusion of Spatial Information for Spatio-Temporal Neural Networks
Jul 15, 2020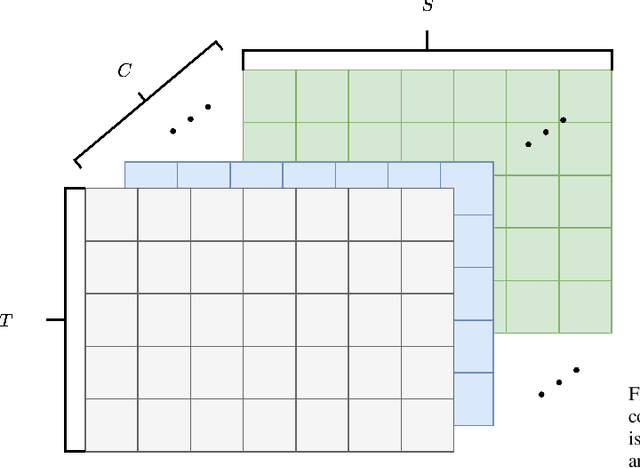
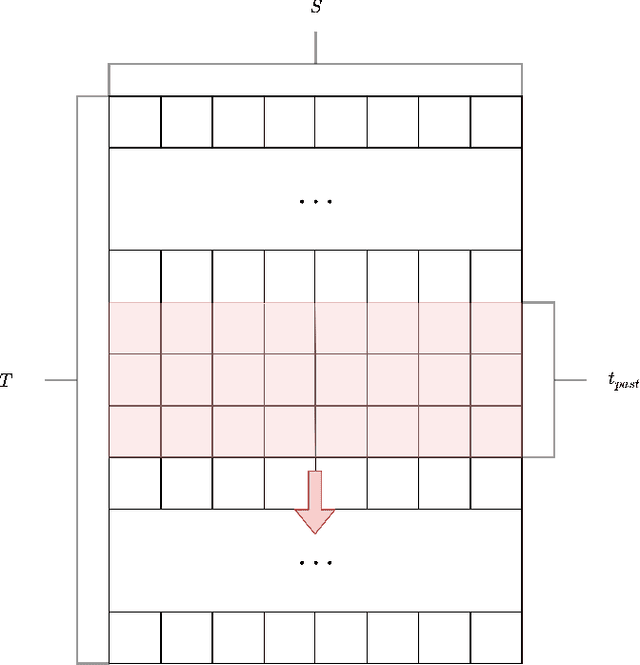
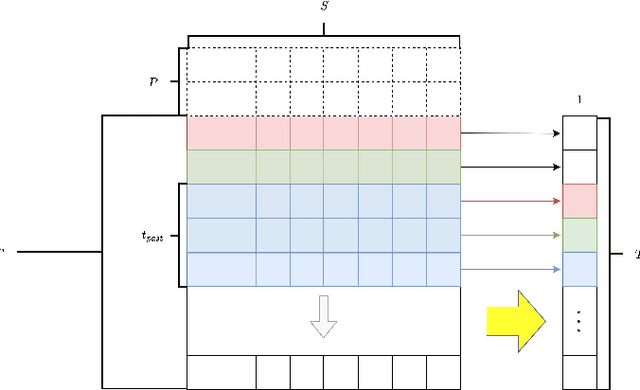
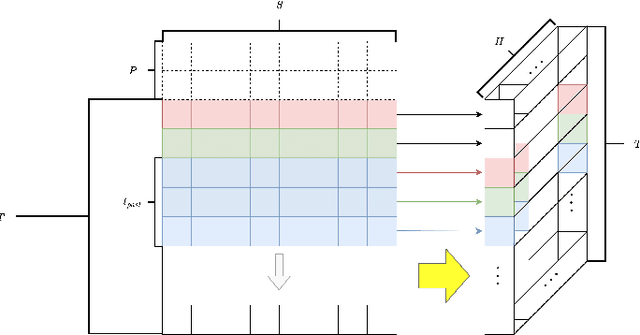
When confronting a spatio-temporal regression, it is sensible to feed the model with any available prior information about the spatial dimension. For example, it is common to define the architecture of neural networks based on spatial closeness, adjacency, or correlation. A common alternative, if spatial information is not available or is too costly to introduce it in the model, is to learn it as an extra step of the model. While the use of prior spatial knowledge, given or learnt, might be beneficial, in this work we question this principle by comparing spatial agnostic neural networks with state of the art models. Our results show that the typical inclusion of prior spatial information is not really needed in most cases. In order to validate this counterintuitive result, we perform thorough experiments over ten different datasets related to sustainable mobility and air quality, substantiating our conclusions on real world problems with direct implications for public health and economy.
Knowledge Graph Embedding Methods for Entity Alignment: An Experimental Review
Mar 17, 2022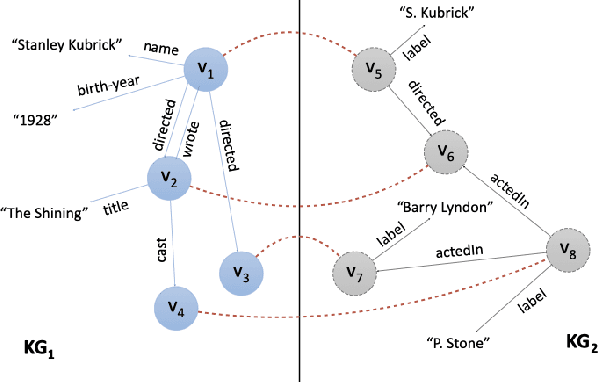
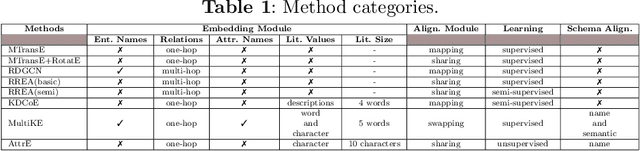
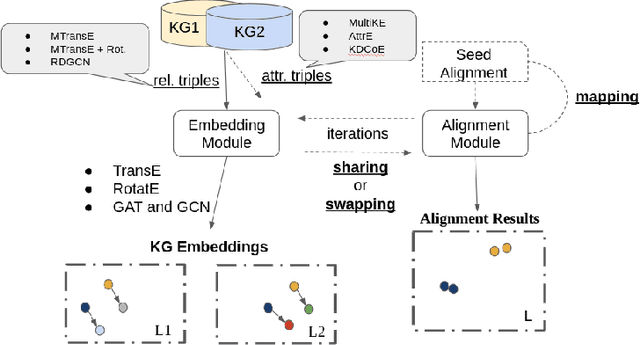

In recent years, we have witnessed the proliferation of knowledge graphs (KG) in various domains, aiming to support applications like question answering, recommendations, etc. A frequent task when integrating knowledge from different KGs is to find which subgraphs refer to the same real-world entity. Recently, embedding methods have been used for entity alignment tasks, that learn a vector-space representation of entities which preserves their similarity in the original KGs. A wide variety of supervised, unsupervised, and semi-supervised methods have been proposed that exploit both factual (attribute based) and structural information (relation based) of entities in the KGs. Still, a quantitative assessment of their strengths and weaknesses in real-world KGs according to different performance metrics and KG characteristics is missing from the literature. In this work, we conduct the first meta-level analysis of popular embedding methods for entity alignment, based on a statistically sound methodology. Our analysis reveals statistically significant correlations of different embedding methods with various meta-features extracted by KGs and rank them in a statistically significant way according to their effectiveness across all real-world KGs of our testbed. Finally, we study interesting trade-offs in terms of methods' effectiveness and efficiency.
Multi-Perspective Semantic Information Retrieval in the Biomedical Domain
Jul 17, 2020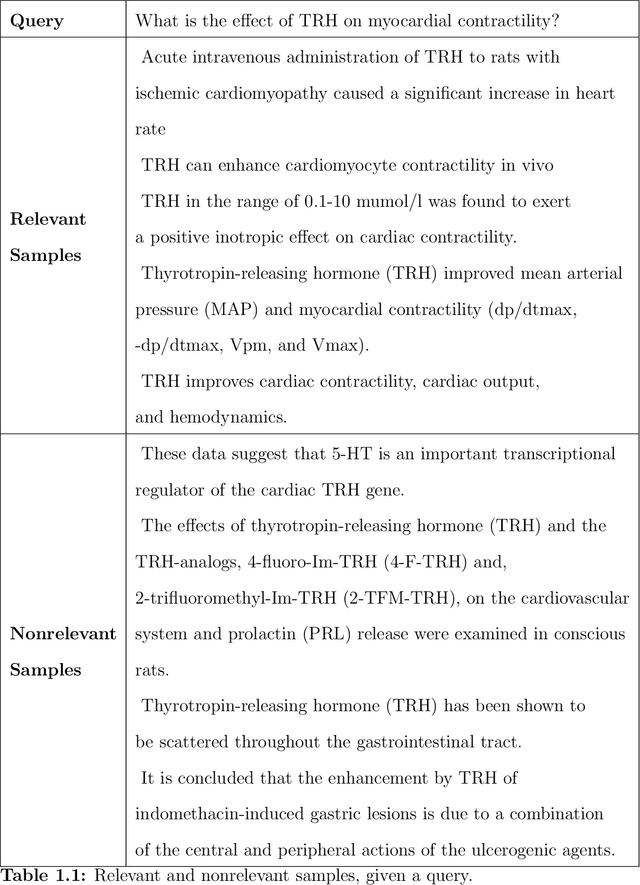
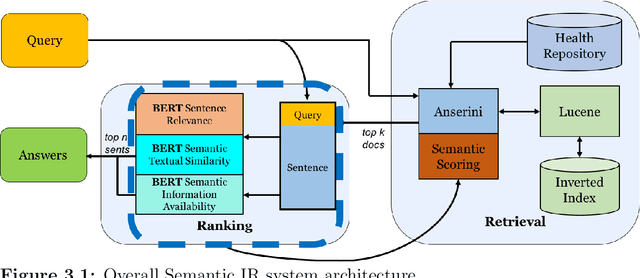
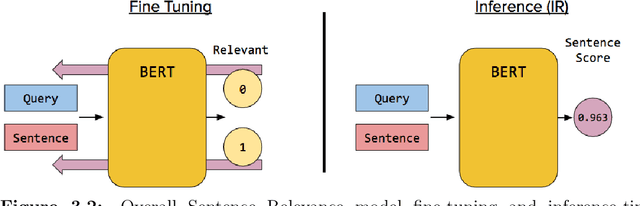
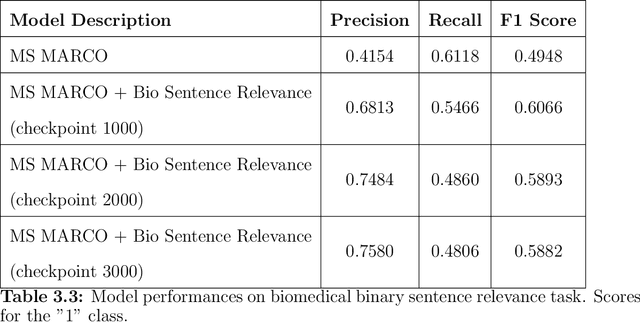
Information Retrieval (IR) is the task of obtaining pieces of data (such as documents) that are relevant to a particular query or need from a large repository of information. IR is a valuable component of several downstream Natural Language Processing (NLP) tasks. Practically, IR is at the heart of many widely-used technologies like search engines. While probabilistic ranking functions like the Okapi BM25 function have been utilized in IR systems since the 1970's, modern neural approaches pose certain advantages compared to their classical counterparts. In particular, the release of BERT (Bidirectional Encoder Representations from Transformers) has had a significant impact in the NLP community by demonstrating how the use of a Masked Language Model trained on a large corpus of data can improve a variety of downstream NLP tasks, including sentence classification and passage re-ranking. IR Systems are also important in the biomedical and clinical domains. Given the increasing amount of scientific literature across biomedical domain, the ability find answers to specific clinical queries from a repository of millions of articles is a matter of practical value to medical professionals. Moreover, there are domain-specific challenges present, including handling clinical jargon and evaluating the similarity or relatedness of various medical symptoms when determining the relevance between a query and a sentence. This work presents contributions to several aspects of the Biomedical Semantic Information Retrieval domain. First, it introduces Multi-Perspective Sentence Relevance, a novel methodology of utilizing BERT-based models for contextual IR. The system is evaluated using the BioASQ Biomedical IR Challenge. Finally, practical contributions in the form of a live IR system for medics and a proposed challenge on the Living Systematic Review clinical task are provided.
Reliability and Validity of the Polar V800 Sports Watch for Estimating Vertical Jump Height
Mar 28, 2022
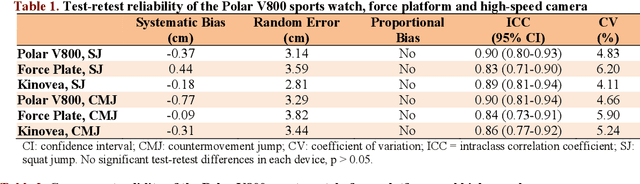
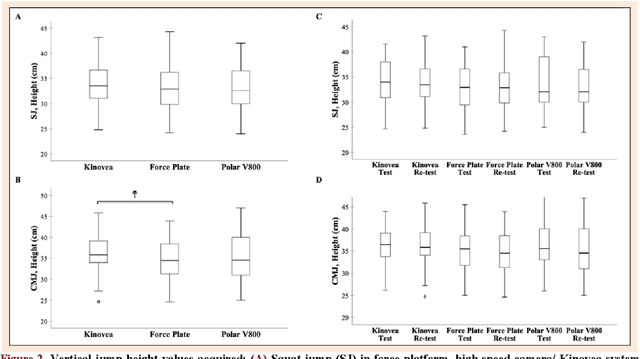
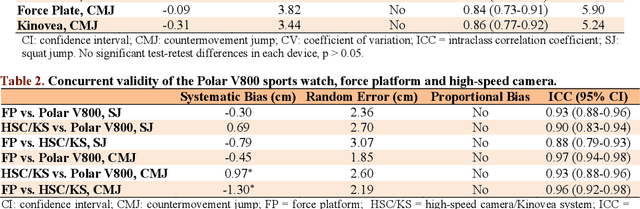
This study aimed to assess the reliability and validity of the Polar V800 to measure vertical jump height. Twenty-two physically active healthy men (age: 22.89 +- 4.23 years; body mass: 70.74 +- 8.04 kg; height: 1.74 +- 0.76 m) were recruited for the study. The reliability was evaluated by comparing measurements acquired by the Polar V800 in two identical testing sessions one week apart. Validity was assessed by comparing measurements simultaneously obtained using a force platform (gold standard), high-speed camera and the Polar V800 during squat jump (SJ) and countermovement jump (CMJ) tests. In the test-retest reliability, high intraclass correlation coefficients (ICCs) were observed (mean: 0.90, SJ and CMJ) in the Polar V800. There was no significant systematic bias +- random errors (p > 0.05) between test-retest. Low coefficients of variation (<5%) were detected in both jumps in the Polar V800. In the validity assessment, similar jump height was detected among devices (p > 0.05). There was almost perfect agreement between the Polar V800 compared to a force platform for the SJ and CMJ tests (Mean ICCs = 0.95; no systematic bias +- random errors in SJ mean: -0.38 +- 2.10 cm, p > 0.05). Mean ICC between the Polar V800 versus high-speed camera was 0.91 for the SJ and CMJ tests, however, a significant systematic bias +- random error (0.97 +- 2.60 cm; p = 0.01) was detected in CMJ test. The Polar V800 offers valid, compared to force platform, and reliable information about vertical jump height performance in physically active healthy young men.
* 9 pages, published in Journal of sports science and medicine, 20, 149 157
End-to-end system for object detection from sub-sampled radar data
Mar 08, 2022
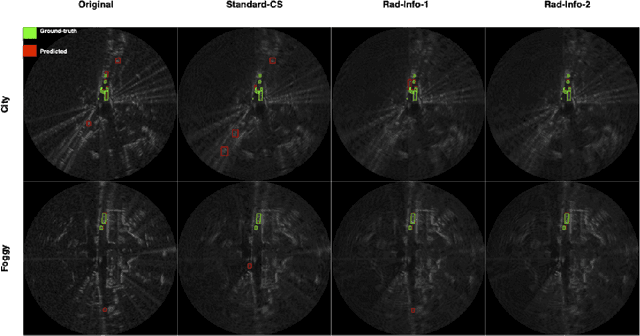
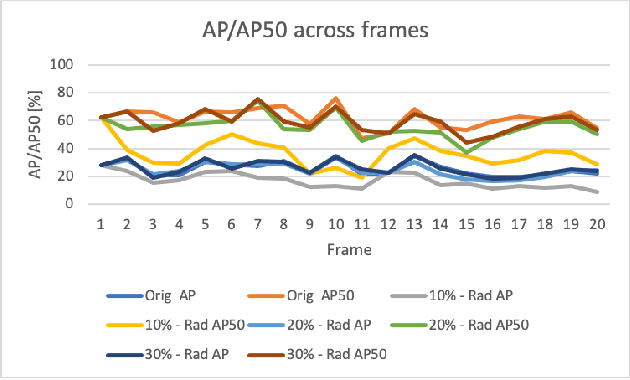
Robust and accurate sensing is of critical importance for advancing autonomous automotive systems. The need to acquire situational awareness in complex urban conditions using sensors such as radar has motivated research on power and latency-efficient signal acquisition methods. In this paper, we present an end-to-end signal processing pipeline, capable of operating in extreme weather conditions, that relies on sub-sampled radar data to perform object detection in vehicular settings. The results of the object detection are further utilized to sub-sample forthcoming radar data, which stands in contrast to prior work where the sub-sampling relies on image information. We show robust detection based on radar data reconstructed using 20% of samples under extreme weather conditions such as snow or fog, and on low-illuminated nights. Additionally, we generate 20% sampled radar data in a fine-tuning set and show 1.1% gain in AP50 across scenes and 3% AP50 gain in motorway condition.
QPIC: Query-Based Pairwise Human-Object Interaction Detection with Image-Wide Contextual Information
Mar 09, 2021
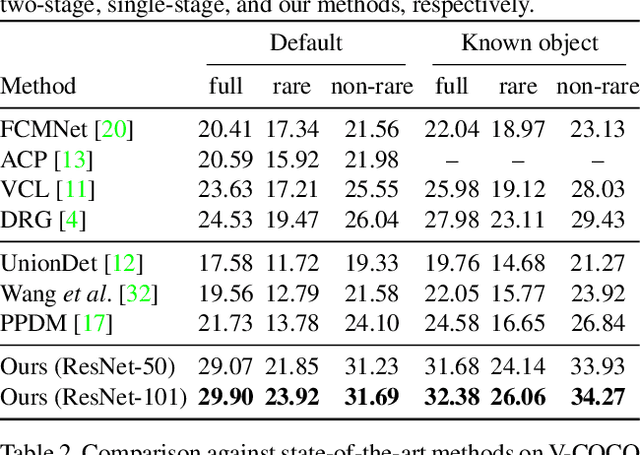
We propose a simple, intuitive yet powerful method for human-object interaction (HOI) detection. HOIs are so diverse in spatial distribution in an image that existing CNN-based methods face the following three major drawbacks; they cannot leverage image-wide features due to CNN's locality, they rely on a manually defined location-of-interest for the feature aggregation, which sometimes does not cover contextually important regions, and they cannot help but mix up the features for multiple HOI instances if they are located closely. To overcome these drawbacks, we propose a transformer-based feature extractor, in which an attention mechanism and query-based detection play key roles. The attention mechanism is effective in aggregating contextually important information image-wide, while the queries, which we design in such a way that each query captures at most one human-object pair, can avoid mixing up the features from multiple instances. This transformer-based feature extractor produces so effective embeddings that the subsequent detection heads may be fairly simple and intuitive. The extensive analysis reveals that the proposed method successfully extracts contextually important features, and thus outperforms existing methods by large margins (5.37 mAP on HICO-DET, and 5.7 mAP on V-COCO). The source codes are available at $\href{https://github.com/hitachi-rd-cv/qpic}{\text{this https URL}}$.
Multilingual Detection of Personal Employment Status on Twitter
Mar 17, 2022
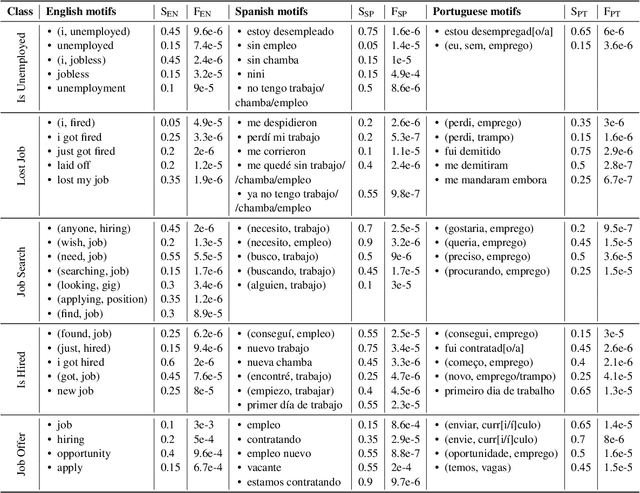
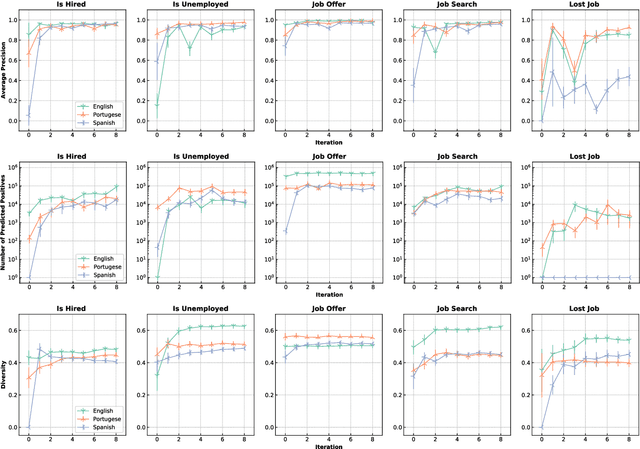

Detecting disclosures of individuals' employment status on social media can provide valuable information to match job seekers with suitable vacancies, offer social protection, or measure labor market flows. However, identifying such personal disclosures is a challenging task due to their rarity in a sea of social media content and the variety of linguistic forms used to describe them. Here, we examine three Active Learning (AL) strategies in real-world settings of extreme class imbalance, and identify five types of disclosures about individuals' employment status (e.g. job loss) in three languages using BERT-based classification models. Our findings show that, even under extreme imbalance settings, a small number of AL iterations is sufficient to obtain large and significant gains in precision, recall, and diversity of results compared to a supervised baseline with the same number of labels. We also find that no AL strategy consistently outperforms the rest. Qualitative analysis suggests that AL helps focus the attention mechanism of BERT on core terms and adjust the boundaries of semantic expansion, highlighting the importance of interpretable models to provide greater control and visibility into this dynamic learning process.
AMCAD: Adaptive Mixed-Curvature Representation based Advertisement Retrieval System
Mar 28, 2022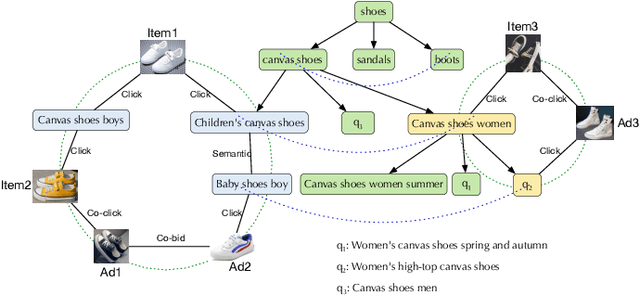
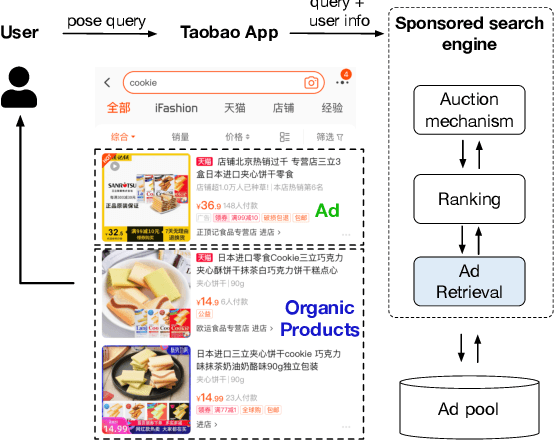
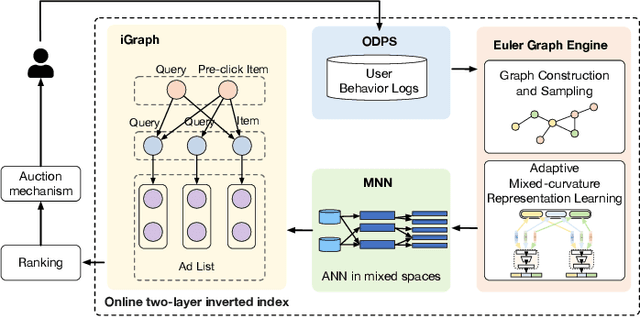
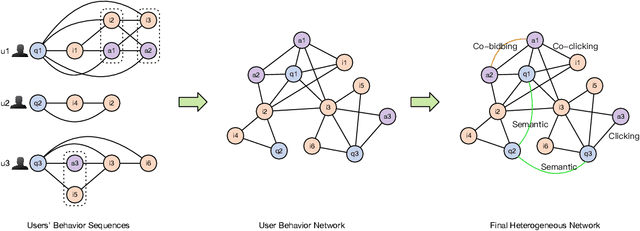
Graph embedding based retrieval has become one of the most popular techniques in the information retrieval community and search engine industry. The classical paradigm mainly relies on the flat Euclidean geometry. In recent years, hyperbolic (negative curvature) and spherical (positive curvature) representation methods have shown their superiority to capture hierarchical and cyclic data structures respectively. However, in industrial scenarios such as e-commerce sponsored search platforms, the large-scale heterogeneous query-item-advertisement interaction graphs often have multiple structures coexisting. Existing methods either only consider a single geometry space, or combine several spaces manually, which are incapable and inflexible to model the complexity and heterogeneity in the real scenario. To tackle this challenge, we present a web-scale Adaptive Mixed-Curvature ADvertisement retrieval system (AMCAD) to automatically capture the complex and heterogeneous graph structures in non-Euclidean spaces. Specifically, entities are represented in adaptive mixed-curvature spaces, where the types and curvatures of the subspaces are trained to be optimal combinations. Besides, an attentive edge-wise space projector is designed to model the similarities between heterogeneous nodes according to local graph structures and the relation types. Moreover, to deploy AMCAD in Taobao, one of the largest ecommerce platforms with hundreds of million users, we design an efficient two-layer online retrieval framework for the task of graph based advertisement retrieval. Extensive evaluations on real-world datasets and A/B tests on online traffic are conducted to illustrate the effectiveness of the proposed system.
Improving Multi-task Generalization Ability for Neural Text Matching via Prompt Learning
Apr 06, 2022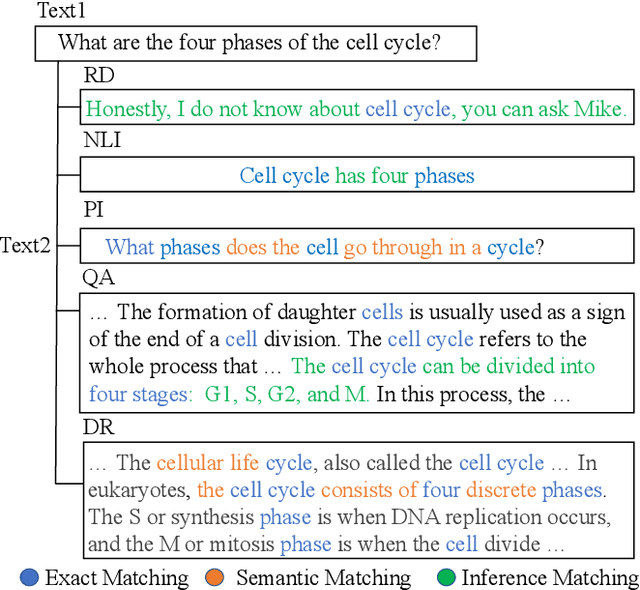

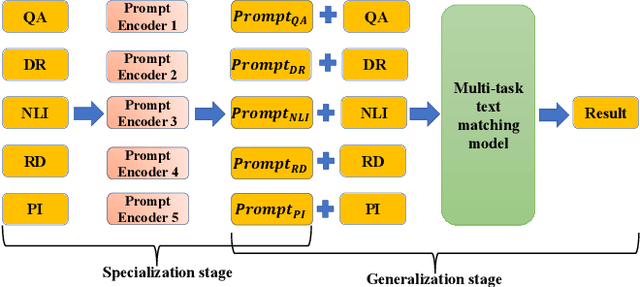
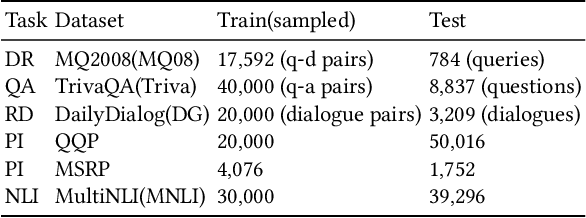
Text matching is a fundamental technique in both information retrieval and natural language processing. Text matching tasks share the same paradigm that determines the relationship between two given texts. Evidently, the relationships vary from task to task, e.g. relevance in document retrieval, semantic alignment in paraphrase identification and answerable judgment in question answering. However, the essential signals for text matching remain in a finite scope, i.e. exact matching, semantic matching, and inference matching. Recent state-of-the-art neural text matching models, e.g. pre-trained language models (PLMs), are hard to generalize to different tasks. It is because the end-to-end supervised learning on task-specific dataset makes model overemphasize the data sample bias and task-specific signals instead of the essential matching signals, which ruins the generalization of model to different tasks. To overcome this problem, we adopt a specialization-generalization training strategy and refer to it as Match-Prompt. In specialization stage, descriptions of different matching tasks are mapped to only a few prompt tokens. In generalization stage, text matching model explores the essential matching signals by being trained on diverse multiple matching tasks. High diverse matching tasks avoid model fitting the data sample bias on a specific task, so that model can focus on learning the essential matching signals. Meanwhile, the prompt tokens obtained in the first step are added to the corresponding tasks to help the model distinguish different task-specific matching signals. Experimental results on eighteen public datasets show that Match-Prompt can significantly improve multi-task generalization capability of PLMs in text matching, and yield better in-domain multi-task, out-of-domain multi-task and new task adaptation performance than task-specific model.