 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PCRP: Unsupervised Point Cloud Object Retrieval and Pose Estimation
Feb 16, 2022
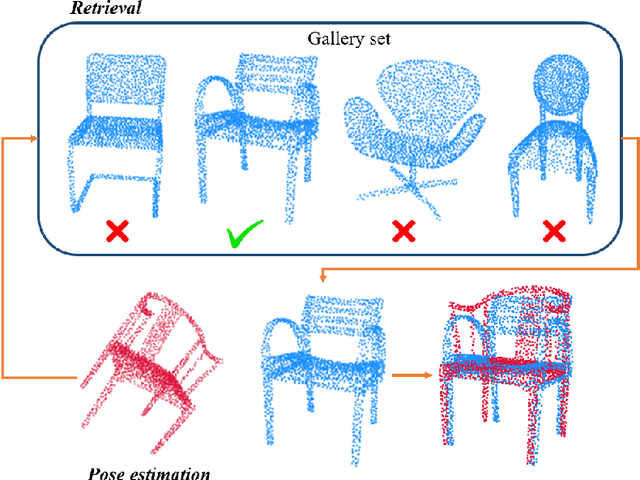
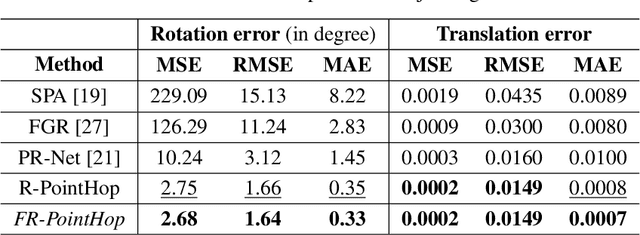
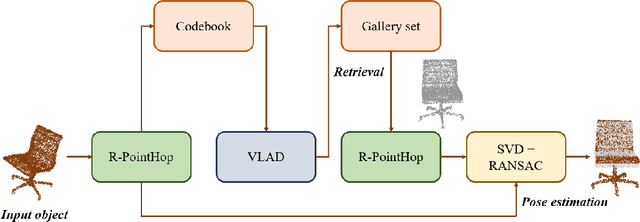
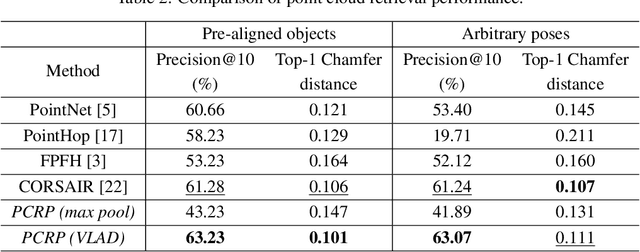
An unsupervised point cloud object retrieval and pose estimation method, called PCRP, is proposed in this work. It is assumed that there exists a gallery point cloud set that contains point cloud objects with given pose orientation information. PCRP attempts to register the unknown point cloud object with those in the gallery set so as to achieve content-based object retrieval and pose estimation jointly, where the point cloud registration task is built upon an enhanced version of the unsupervised R-PointHop method. Experiments on the ModelNet40 dataset demonstrate the superior performance of PCRP in comparison with traditional and learning based methods.
Learning Discrete Structured Representations by Adversarially Maximizing Mutual Information
Apr 08, 2020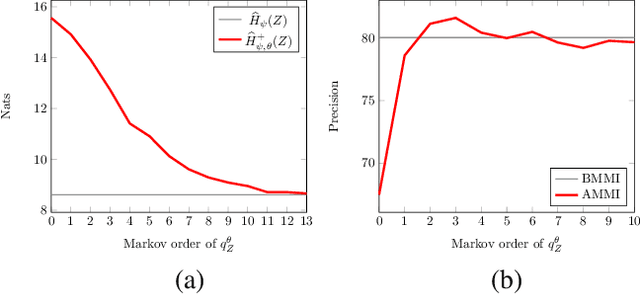
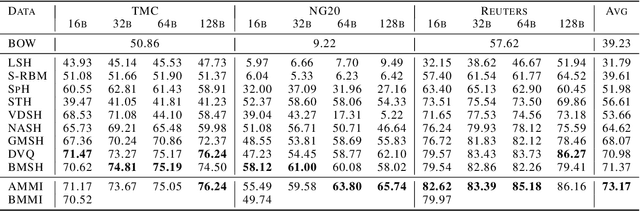

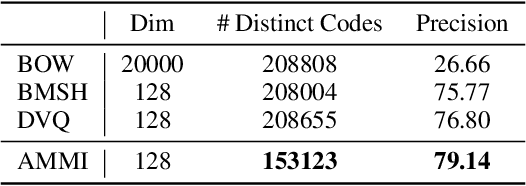
We propose learning discrete structured representations from unlabeled data by maximizing the mutual information between a structured latent variable and a target variable. Calculating mutual information is intractable in this setting. Our key technical contribution is an adversarial objective that can be used to tractably estimate mutual information assuming only the feasibility of cross entropy calculation. We develop a concrete realization of this general formulation with Markov distributions over binary encodings. We report critical and unexpected findings on practical aspects of the objective such as the choice of variational priors. We apply our model on document hashing and show that it outperforms current best baselines based on discrete and vector quantized variational autoencoders. It also yields highly compressed interpretable representations.
Hierarchical Graph Representation Learning for the Prediction of Drug-Target Binding Affinity
Mar 22, 2022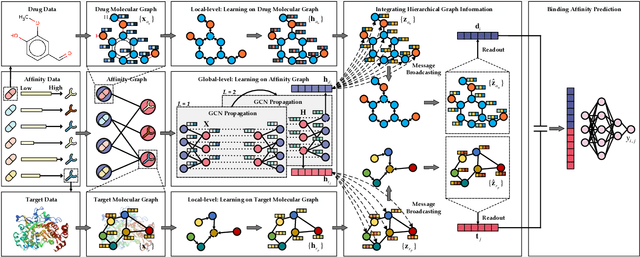
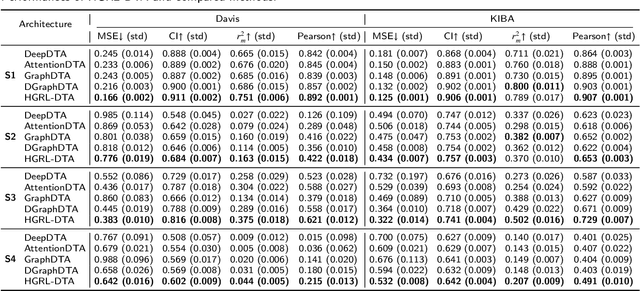
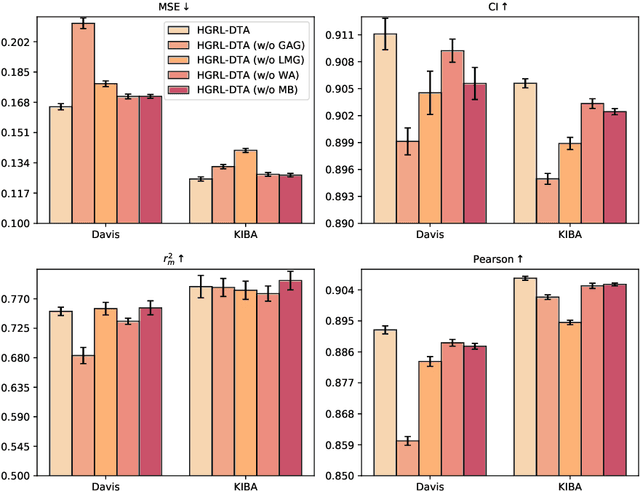
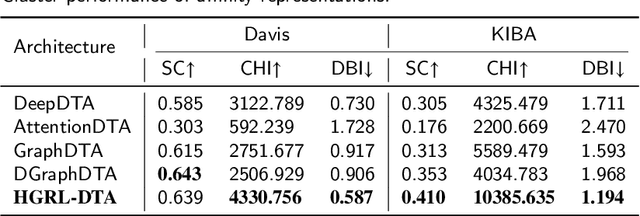
The identification of drug-target binding affinity (DTA) has attracted increasing attention in the drug discovery process due to the more specific interpretation than binary interaction prediction. Recently, numerous deep learning-based computational methods have been proposed to predict the binding affinities between drugs and targets benefiting from their satisfactory performance. However, the previous works mainly focus on encoding biological features and chemical structures of drugs and targets, with a lack of exploiting the essential topological information from the drug-target affinity network. In this paper, we propose a novel hierarchical graph representation learning model for the drug-target binding affinity prediction, namely HGRL-DTA. The main contribution of our model is to establish a hierarchical graph learning architecture to incorporate the intrinsic properties of drug/target molecules and the topological affinities of drug-target pairs. In this architecture, we adopt a message broadcasting mechanism to integrate the hierarchical representations learned from the global-level affinity graph and the local-level molecular graph. Besides, we design a similarity-based embedding map to solve the cold start problem of inferring representations for unseen drugs and targets. Comprehensive experimental results under different scenarios indicate that HGRL-DTA significantly outperforms the state-of-the-art models and shows better model generalization among all the scenarios.
Topological data analysis of truncated contagion maps
Mar 03, 2022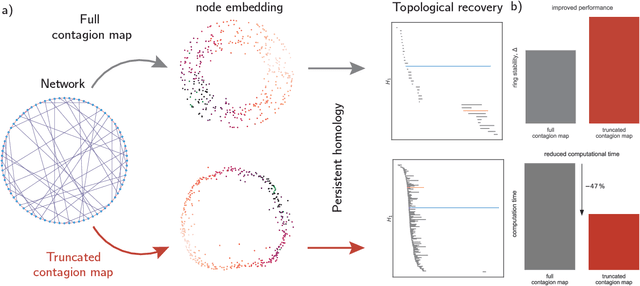

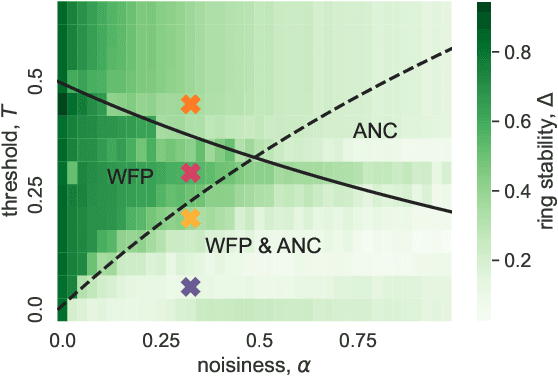
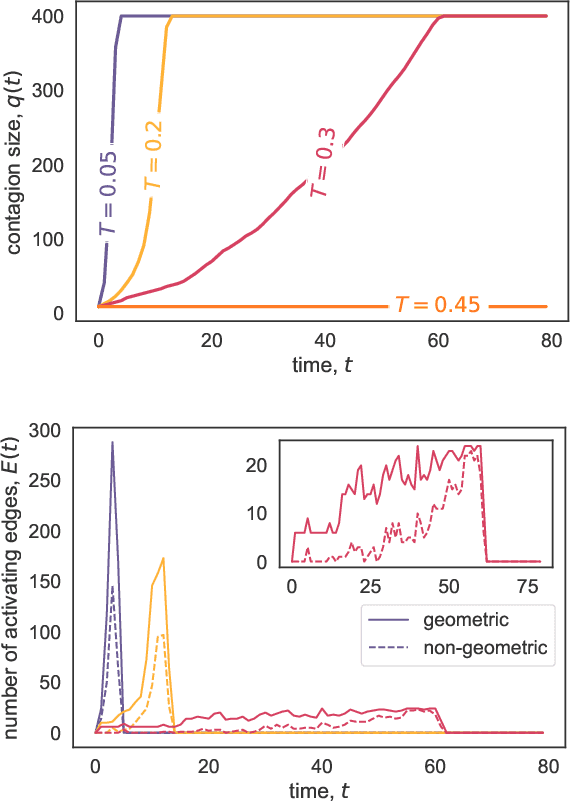
The investigation of dynamical processes on networks has been one focus for the study of contagion processes. It has been demonstrated that contagions can be used to obtain information about the embedding of nodes in a Euclidean space. Specifically, one can use the activation times of threshold contagions to construct contagion maps as a manifold-learning approach. One drawback of contagion maps is their high computational cost. Here, we demonstrate that a truncation of the threshold contagions may considerably speed up the construction of contagion maps. Finally, we show that contagion maps may be used to find an insightful low-dimensional embedding for single-cell RNA-sequencing data in the form of cell-similarity networks and so reveal biological manifolds. Overall, our work makes the use of contagion maps as manifold-learning approaches on empirical network data more viable.
On the (Limited) Generalization of MasterFace Attacks and Its Relation to the Capacity of Face Representations
Apr 01, 2022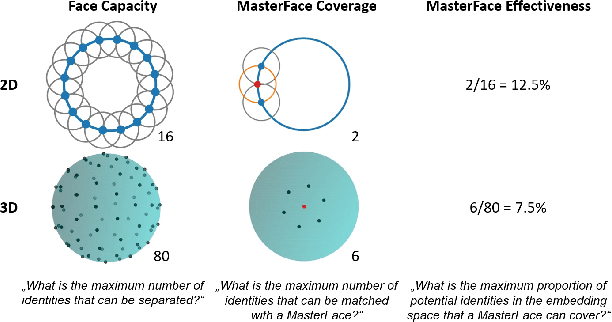

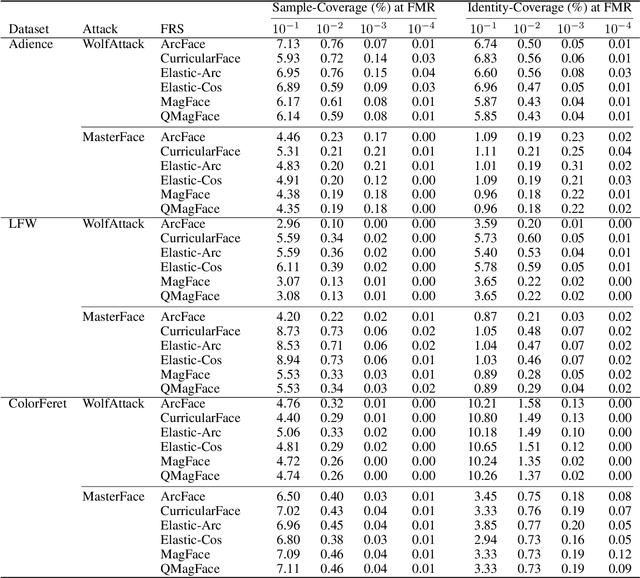
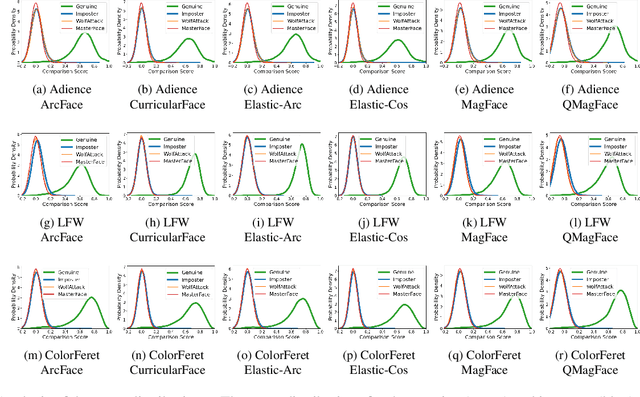
A MasterFace is a face image that can successfully match against a large portion of the population. Since their generation does not require access to the information of the enrolled subjects, MasterFace attacks represent a potential security risk for widely-used face recognition systems. Previous works proposed methods for generating such images and demonstrated that these attacks can strongly compromise face recognition. However, previous works followed evaluation settings consisting of older recognition models, limited cross-dataset and cross-model evaluations, and the use of low-scale testing data. This makes it hard to state the generalizability of these attacks. In this work, we comprehensively analyse the generalizability of MasterFace attacks in empirical and theoretical investigations. The empirical investigations include the use of six state-of-the-art FR models, cross-dataset and cross-model evaluation protocols, and utilizing testing datasets of significantly higher size and variance. The results indicate a low generalizability when MasterFaces are training on a different face recognition model than the one used for testing. In these cases, the attack performance is similar to zero-effort imposter attacks. In the theoretical investigations, we define and estimate the face capacity and the maximum MasterFace coverage under the assumption that identities in the face space are well separated. The current trend of increasing the fairness and generalizability in face recognition indicates that the vulnerability of future systems might further decrease. Future works might analyse the utility of MasterFaces for understanding and enhancing the robustness of face recognition models.
Biological error correction codes generate fault-tolerant neural networks
Feb 25, 2022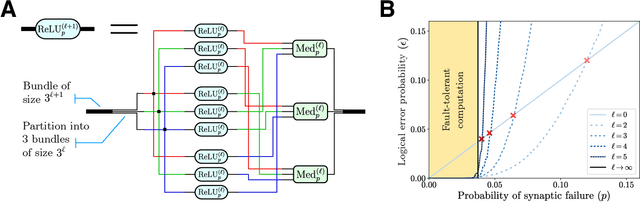
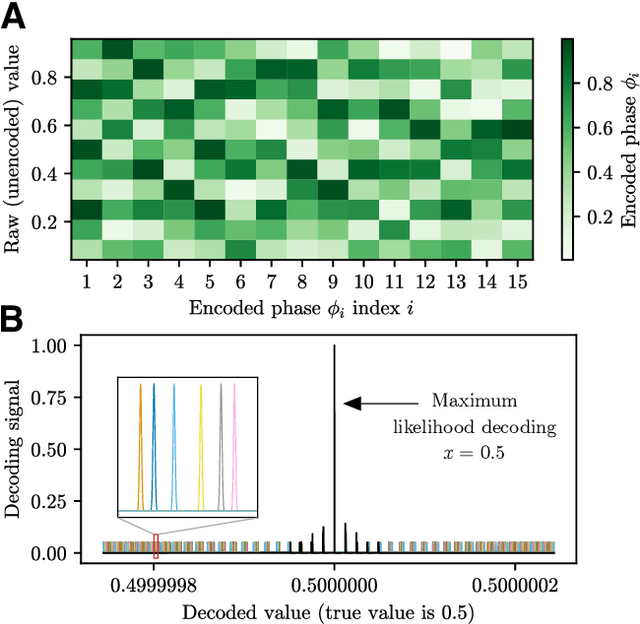
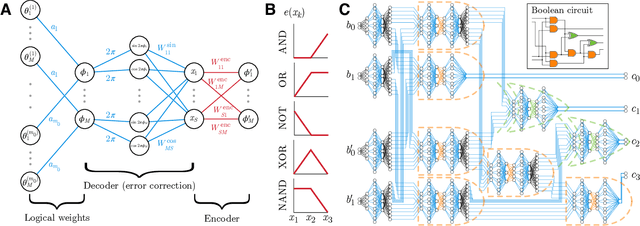
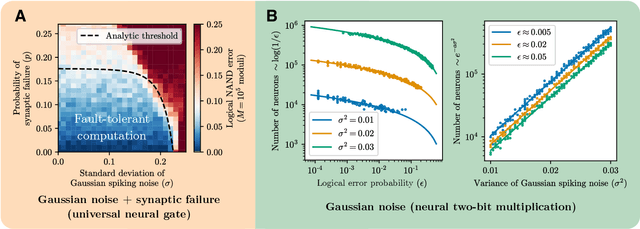
It has been an open question in deep learning if fault-tolerant computation is possible: can arbitrarily reliable computation be achieved using only unreliable neurons? In the mammalian cortex, analog error correction codes known as grid codes have been observed to protect states against neural spiking noise, but their role in information processing is unclear. Here, we use these biological codes to show that a universal fault-tolerant neural network can be achieved if the faultiness of each neuron lies below a sharp threshold, which we find coincides in order of magnitude with noise observed in biological neurons. The discovery of a sharp phase transition from faulty to fault-tolerant neural computation opens a path towards understanding noisy analog systems in artificial intelligence and neuroscience.
Automated Attack Synthesis by Extracting Finite State Machines from Protocol Specification Documents
Feb 18, 2022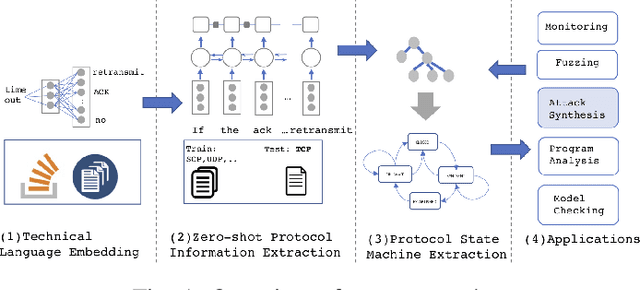
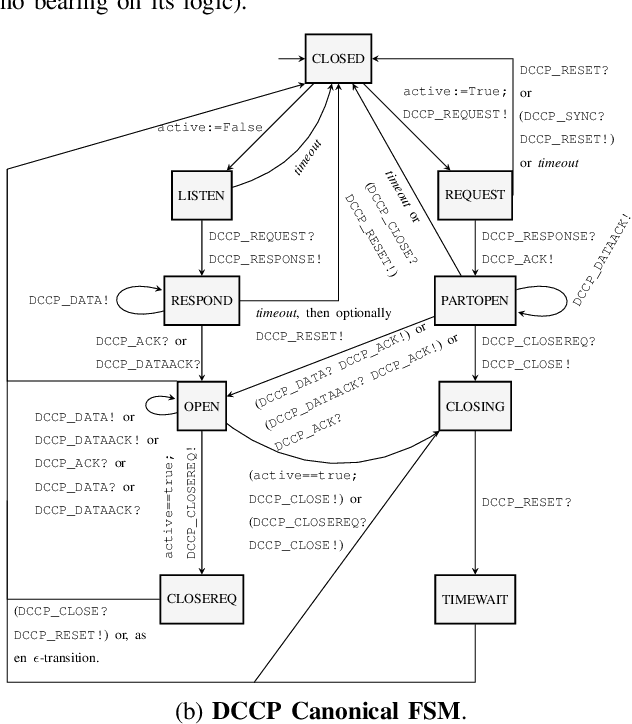

Automated attack discovery techniques, such as attacker synthesis or model-based fuzzing, provide powerful ways to ensure network protocols operate correctly and securely. Such techniques, in general, require a formal representation of the protocol, often in the form of a finite state machine (FSM). Unfortunately, many protocols are only described in English prose, and implementing even a simple network protocol as an FSM is time-consuming and prone to subtle logical errors. Automatically extracting protocol FSMs from documentation can significantly contribute to increased use of these techniques and result in more robust and secure protocol implementations. In this work we focus on attacker synthesis as a representative technique for protocol security, and on RFCs as a representative format for protocol prose description. Unlike other works that rely on rule-based approaches or use off-the-shelf NLP tools directly, we suggest a data-driven approach for extracting FSMs from RFC documents. Specifically, we use a hybrid approach consisting of three key steps: (1) large-scale word-representation learning for technical language, (2) focused zero-shot learning for mapping protocol text to a protocol-independent information language, and (3) rule-based mapping from protocol-independent information to a specific protocol FSM. We show the generalizability of our FSM extraction by using the RFCs for six different protocols: BGPv4, DCCP, LTP, PPTP, SCTP and TCP. We demonstrate how automated extraction of an FSM from an RFC can be applied to the synthesis of attacks, with TCP and DCCP as case-studies. Our approach shows that it is possible to automate attacker synthesis against protocols by using textual specifications such as RFCs.
Vision Transformers in Medical Computer Vision -- A Contemplative Retrospection
Mar 29, 2022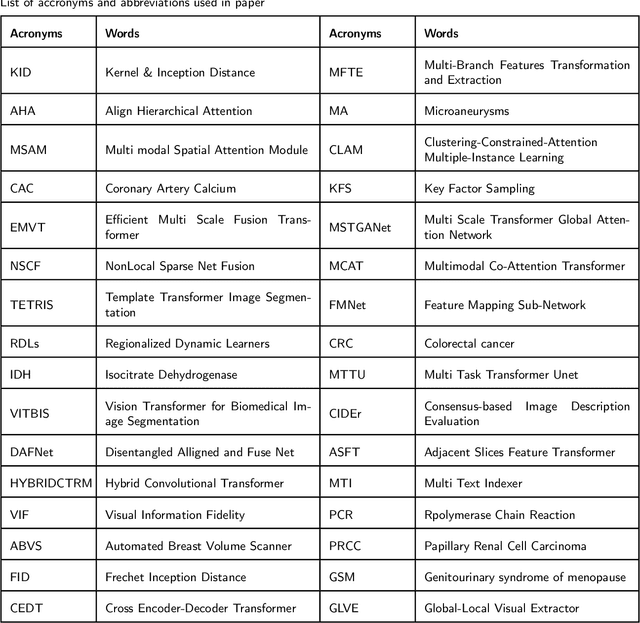
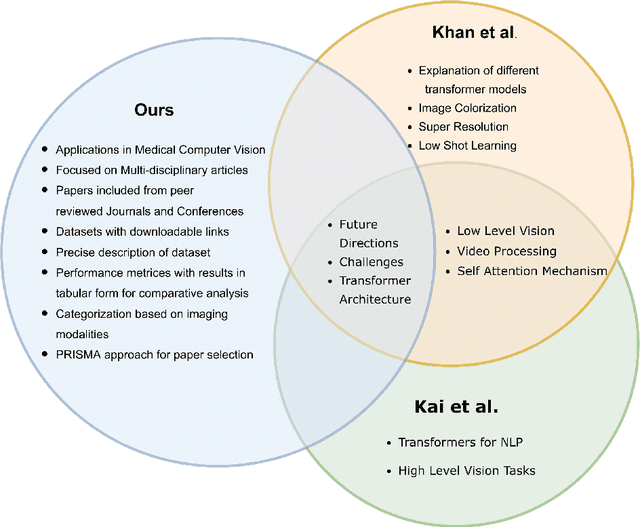
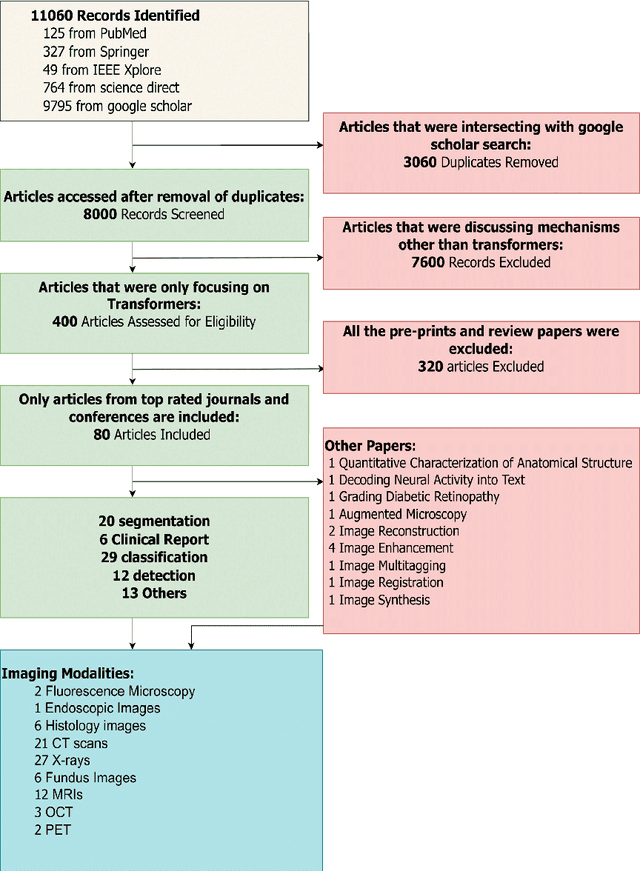
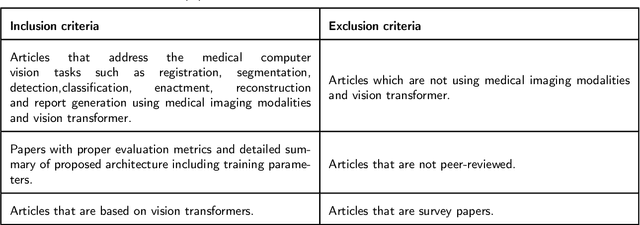
Recent escalation in the field of computer vision underpins a huddle of algorithms with the magnificent potential to unravel the information contained within images. These computer vision algorithms are being practised in medical image analysis and are transfiguring the perception and interpretation of Imaging data. Among these algorithms, Vision Transformers are evolved as one of the most contemporary and dominant architectures that are being used in the field of computer vision. These are immensely utilized by a plenty of researchers to perform new as well as former experiments. Here, in this article we investigate the intersection of Vision Transformers and Medical images and proffered an overview of various ViTs based frameworks that are being used by different researchers in order to decipher the obstacles in Medical Computer Vision. We surveyed the application of Vision transformers in different areas of medical computer vision such as image-based disease classification, anatomical structure segmentation, registration, region-based lesion Detection, captioning, report generation, reconstruction using multiple medical imaging modalities that greatly assist in medical diagnosis and hence treatment process. Along with this, we also demystify several imaging modalities used in Medical Computer Vision. Moreover, to get more insight and deeper understanding, self-attention mechanism of transformers is also explained briefly. Conclusively, we also put some light on available data sets, adopted methodology, their performance measures, challenges and their solutions in form of discussion. We hope that this review article will open future directions for researchers in medical computer vision.
Multimodal Entity Tagging with Multimodal Knowledge Base
Dec 21, 2021
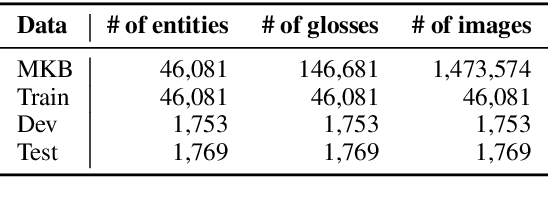
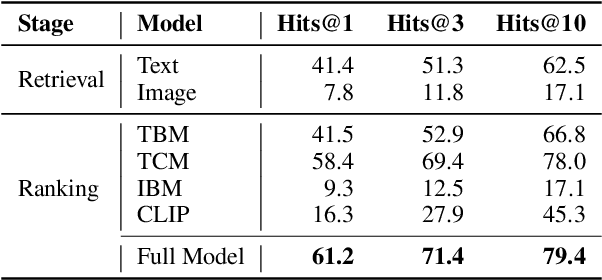
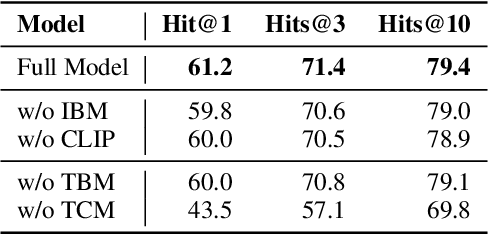
To enhance research on multimodal knowledge base and multimodal information processing, we propose a new task called multimodal entity tagging (MET) with a multimodal knowledge base (MKB). We also develop a dataset for the problem using an existing MKB. In an MKB, there are entities and their associated texts and images. In MET, given a text-image pair, one uses the information in the MKB to automatically identify the related entity in the text-image pair. We solve the task by using the information retrieval paradigm and implement several baselines using state-of-the-art methods in NLP and CV. We conduct extensive experiments and make analyses on the experimental results. The results show that the task is challenging, but current technologies can achieve relatively high performance. We will release the dataset, code, and models for future research.
QPIC: Query-Based Pairwise Human-Object Interaction Detection with Image-Wide Contextual Information
Mar 09, 2021
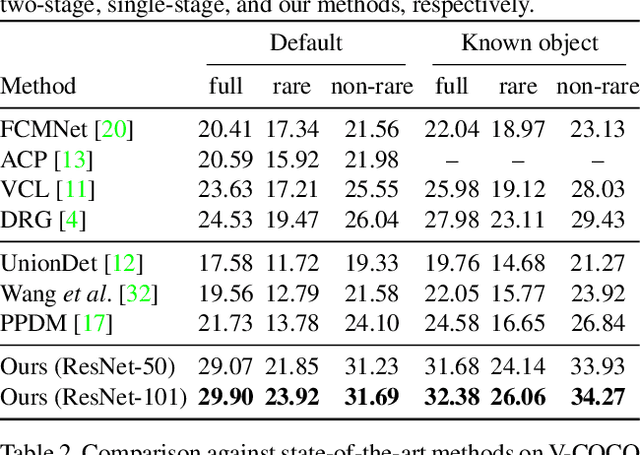
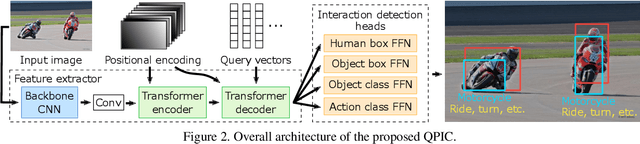
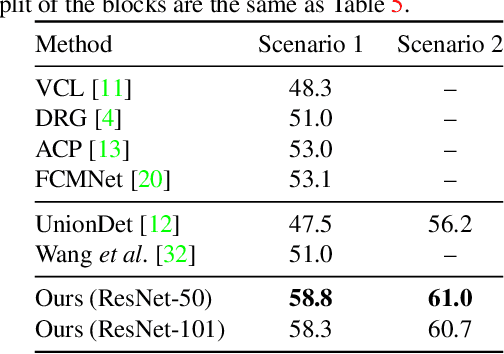
We propose a simple, intuitive yet powerful method for human-object interaction (HOI) detection. HOIs are so diverse in spatial distribution in an image that existing CNN-based methods face the following three major drawbacks; they cannot leverage image-wide features due to CNN's locality, they rely on a manually defined location-of-interest for the feature aggregation, which sometimes does not cover contextually important regions, and they cannot help but mix up the features for multiple HOI instances if they are located closely. To overcome these drawbacks, we propose a transformer-based feature extractor, in which an attention mechanism and query-based detection play key roles. The attention mechanism is effective in aggregating contextually important information image-wide, while the queries, which we design in such a way that each query captures at most one human-object pair, can avoid mixing up the features from multiple instances. This transformer-based feature extractor produces so effective embeddings that the subsequent detection heads may be fairly simple and intuitive. The extensive analysis reveals that the proposed method successfully extracts contextually important features, and thus outperforms existing methods by large margins (5.37 mAP on HICO-DET, and 5.7 mAP on V-COCO). The source codes are available at $\href{https://github.com/hitachi-rd-cv/qpic}{\text{this https URL}}$.