 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Hybrid Framework for Sequential Data Prediction with End-to-End Optimization
Mar 25, 2022
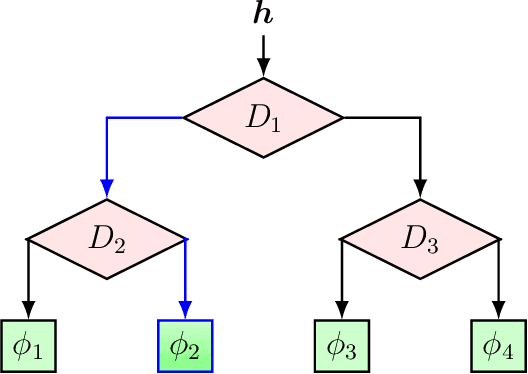
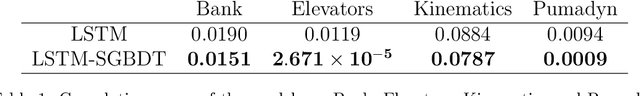
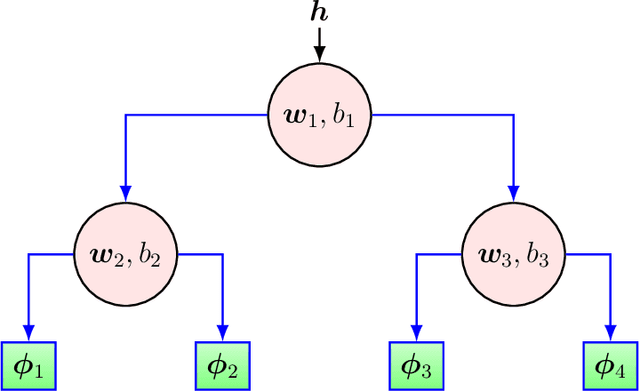

We investigate nonlinear prediction in an online setting and introduce a hybrid model that effectively mitigates, via an end-to-end architecture, the need for hand-designed features and manual model selection issues of conventional nonlinear prediction/regression methods. In particular, we use recursive structures to extract features from sequential signals, while preserving the state information, i.e., the history, and boosted decision trees to produce the final output. The connection is in an end-to-end fashion and we jointly optimize the whole architecture using stochastic gradient descent, for which we also provide the backward pass update equations. In particular, we employ a recurrent neural network (LSTM) for adaptive feature extraction from sequential data and a gradient boosting machinery (soft GBDT) for effective supervised regression. Our framework is generic so that one can use other deep learning architectures for feature extraction (such as RNNs and GRUs) and machine learning algorithms for decision making as long as they are differentiable. We demonstrate the learning behavior of our algorithm on synthetic data and the significant performance improvements over the conventional methods over various real life datasets. Furthermore, we openly share the source code of the proposed method to facilitate further research.
Stochastic Trajectory Prediction via Motion Indeterminacy Diffusion
Mar 25, 2022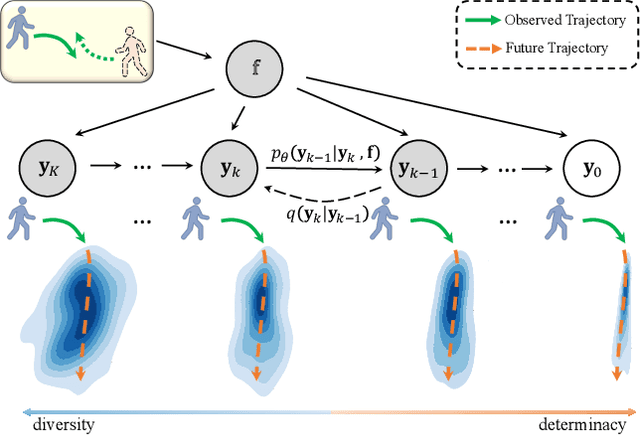
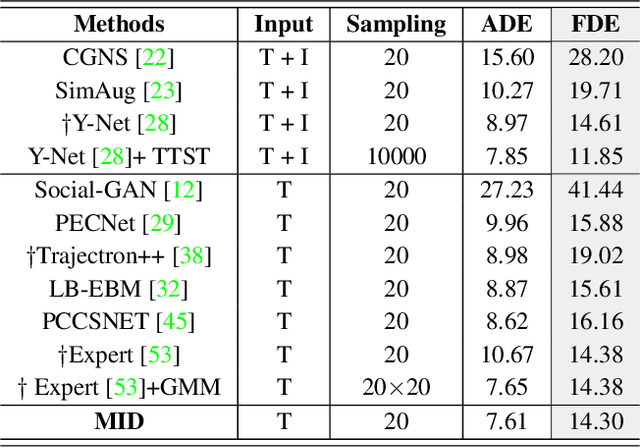
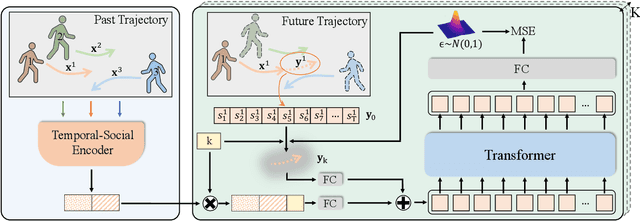
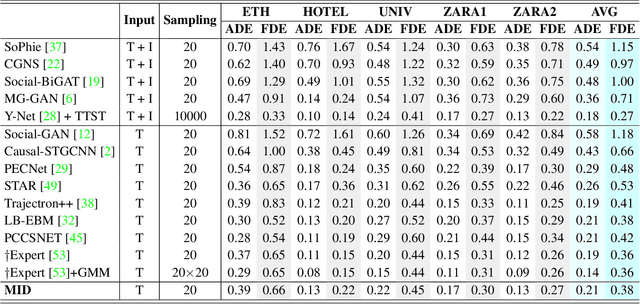
Human behavior has the nature of indeterminacy, which requires the pedestrian trajectory prediction system to model the multi-modality of future motion states. Unlike existing stochastic trajectory prediction methods which usually use a latent variable to represent multi-modality, we explicitly simulate the process of human motion variation from indeterminate to determinate. In this paper, we present a new framework to formulate the trajectory prediction task as a reverse process of motion indeterminacy diffusion (MID), in which we progressively discard indeterminacy from all the walkable areas until reaching the desired trajectory. This process is learned with a parameterized Markov chain conditioned by the observed trajectories. We can adjust the length of the chain to control the degree of indeterminacy and balance the diversity and determinacy of the predictions. Specifically, we encode the history behavior information and the social interactions as a state embedding and devise a Transformer-based diffusion model to capture the temporal dependencies of trajectories. Extensive experiments on the human trajectory prediction benchmarks including the Stanford Drone and ETH/UCY datasets demonstrate the superiority of our method. Code is available at https://github.com/gutianpei/MID.
Exact learning and test theory
Jan 12, 2022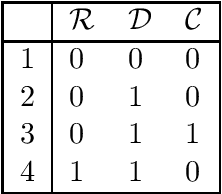
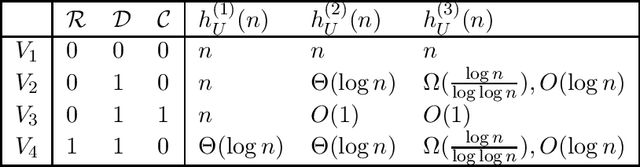
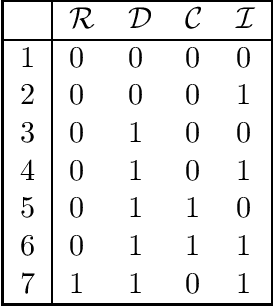
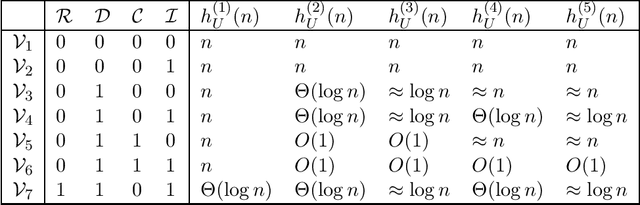
In this paper, based on results of exact learning and test theory, we study arbitrary infinite binary information systems each of which consists of an infinite set of elements and an infinite set of two-valued functions (attributes) defined on the set of elements. We consider the notion of a problem over information system, which is described by a finite number of attributes: for a given element, we should recognize values of these attributes. As algorithms for problem solving, we consider decision trees of two types: (i) using only proper hypotheses (an analog of proper equivalence queries from exact learning), and (ii) using both attributes and proper hypotheses. As time complexity, we study the depth of decision trees. In the worst case, with the growth of the number of attributes in the problem description, the minimum depth of decision trees of both types either is bounded from above by a constant or grows as a logarithm, or linearly. Based on these results and results obtained earlier for attributes and arbitrary hypotheses, we divide the set of all infinite binary information systems into seven complexity classes.
PathSAGE: Spatial Graph Attention Neural Networks With Random Path Sampling
Mar 11, 2022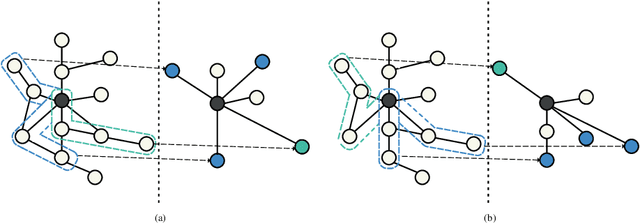
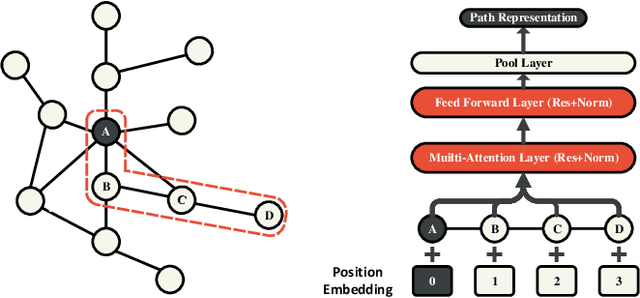
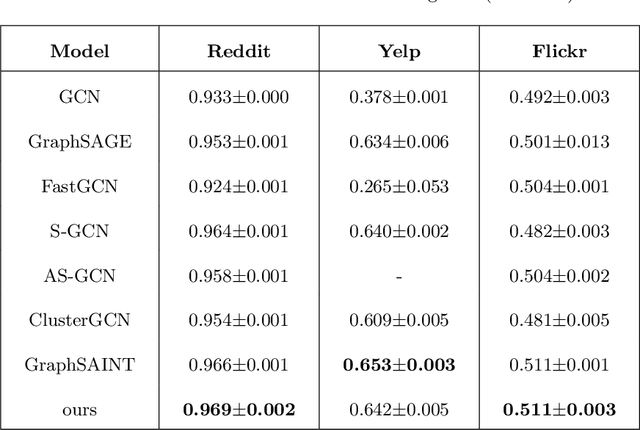
Graph Convolutional Networks (GCNs) achieve great success in non-Euclidean structure data processing recently. In existing studies, deeper layers are used in CCNs to extract deeper features of Euclidean structure data. However, for non-Euclidean structure data, too deep GCNs will confront with problems like "neighbor explosion" and "over-smoothing", it also cannot be applied to large datasets. To address these problems, we propose a model called PathSAGE, which can learn high-order topological information and improve the model's performance by expanding the receptive field. The model randomly samples paths starting from the central node and aggregates them by Transformer encoder. PathSAGE has only one layer of structure to aggregate nodes which avoid those problems above. The results of evaluation shows that our model achieves comparable performance with the state-of-the-art models in inductive learning tasks.
Improved Counting and Localization from Density Maps for Object Detection in 2D and 3D Microscopy Imaging
Mar 29, 2022
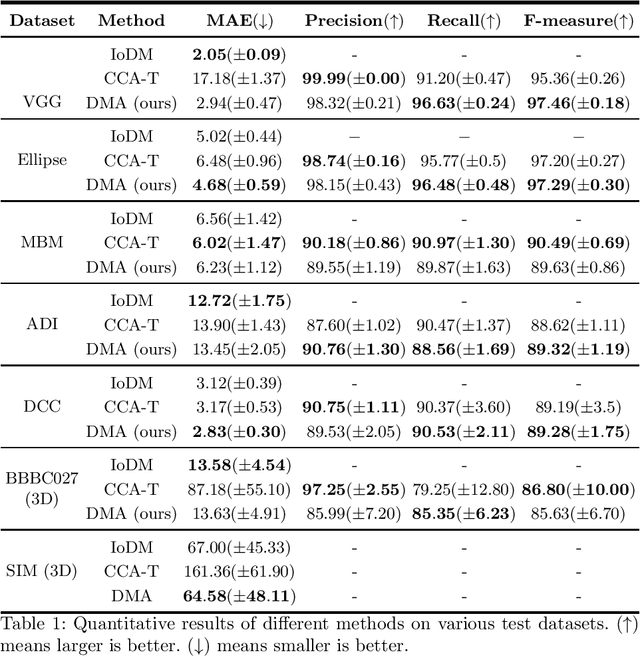
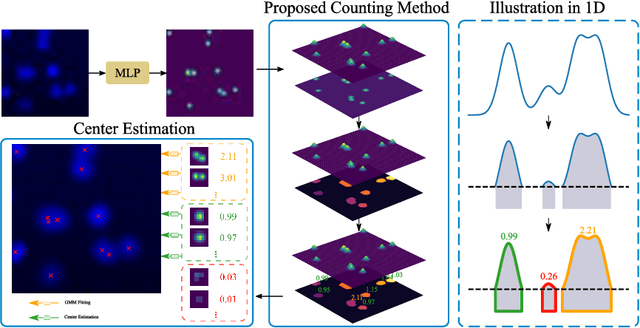
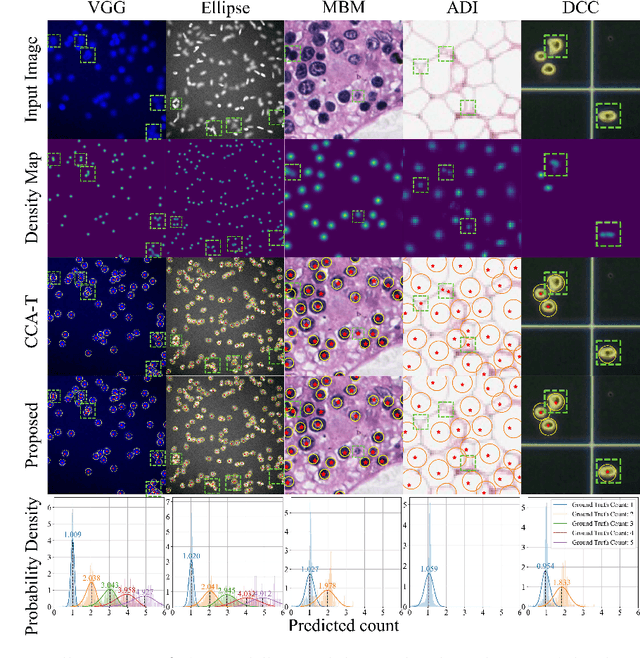
Object counting and localization are key steps for quantitative analysis in large-scale microscopy applications. This procedure becomes challenging when target objects are overlapping, are densely clustered, and/or present fuzzy boundaries. Previous methods producing density maps based on deep learning have reached a high level of accuracy for object counting by assuming that object counting is equivalent to the integration of the density map. However, this model fails when objects show significant overlap regarding accurate localization. We propose an alternative method to count and localize objects from the density map to overcome this limitation. Our procedure includes the following three key aspects: 1) Proposing a new counting method based on the statistical properties of the density map, 2) optimizing the counting results for those objects which are well-detected based on the proposed counting method, and 3) improving localization of poorly detected objects using the proposed counting method as prior information. Validation includes processing of microscopy data with known ground truth and comparison with other models that use conventional processing of the density map. Our results show improved performance in counting and localization of objects in 2D and 3D microscopy data. Furthermore, the proposed method is generic, considering various applications that rely on the density map approach. Our code will be released post-review.
DXM-TransFuse U-net: Dual Cross-Modal Transformer Fusion U-net for Automated Nerve Identification
Feb 27, 2022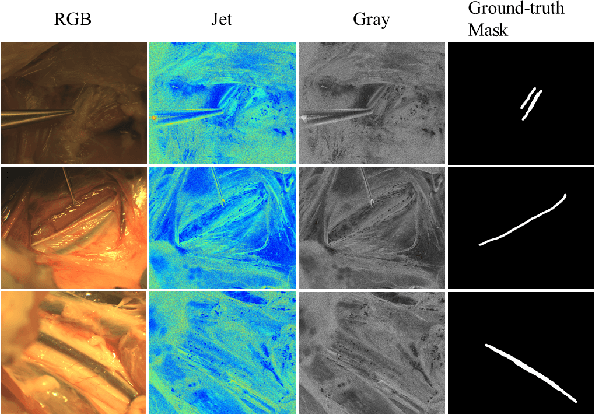

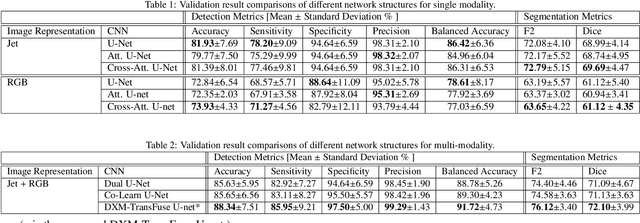
Accurate nerve identification is critical during surgical procedures for preventing any damages to nerve tissues. Nerve injuries can lead to long-term detrimental effects for patients as well as financial overburdens. In this study, we develop a deep-learning network framework using the U-Net architecture with a Transformer block based fusion module at the bottleneck to identify nerve tissues from a multi-modal optical imaging system. By leveraging and extracting the feature maps of each modality independently and using each modalities information for cross-modal interactions, we aim to provide a solution that would further increase the effectiveness of the imaging systems for enabling the noninvasive intraoperative nerve identification.
Memory-guided Image De-raining Using Time-Lapse Data
Jan 06, 2022


This paper addresses the problem of single image de-raining, that is, the task of recovering clean and rain-free background scenes from a single image obscured by a rainy artifact. Although recent advances adopt real-world time-lapse data to overcome the need for paired rain-clean images, they are limited to fully exploit the time-lapse data. The main cause is that, in terms of network architectures, they could not capture long-term rain streak information in the time-lapse data during training owing to the lack of memory components. To address this problem, we propose a novel network architecture based on a memory network that explicitly helps to capture long-term rain streak information in the time-lapse data. Our network comprises the encoder-decoder networks and a memory network. The features extracted from the encoder are read and updated in the memory network that contains several memory items to store rain streak-aware feature representations. With the read/update operation, the memory network retrieves relevant memory items in terms of the queries, enabling the memory items to represent the various rain streaks included in the time-lapse data. To boost the discriminative power of memory features, we also present a novel background selective whitening (BSW) loss for capturing only rain streak information in the memory network by erasing the background information. Experimental results on standard benchmarks demonstrate the effectiveness and superiority of our approach.
NL-FCOS: Improving FCOS through Non-Local Modules for Object Detection
Mar 29, 2022


During the last years, we have seen significant advances in the object detection task, mainly due to the outperforming results of convolutional neural networks. In this vein, anchor-based models have achieved the best results. However, these models require prior information about the aspect and scales of target objects, needing more hyperparameters to fit. In addition, using anchors to fit bounding boxes seems far from how our visual system does the same visual task. Instead, our visual system uses the interactions of different scene parts to semantically identify objects, called perceptual grouping. An object detection methodology closer to the natural model is anchor-free detection, where models like FCOS or Centernet have shown competitive results, but these have not yet exploited the concept of perceptual grouping. Therefore, to increase the effectiveness of anchor-free models keeping the inference time low, we propose to add non-local attention (NL modules) modules to boost the feature map of the underlying backbone. NL modules implement the perceptual grouping mechanism, allowing receptive fields to cooperate in visual representation learning. We show that non-local modules combined with an FCOS head (NL-FCOS) are practical and efficient. Thus, we establish state-of-the-art performance in clothing detection and handwritten amount recognition problems.
Reviewing continual learning from the perspective of human-level intelligence
Nov 23, 2021
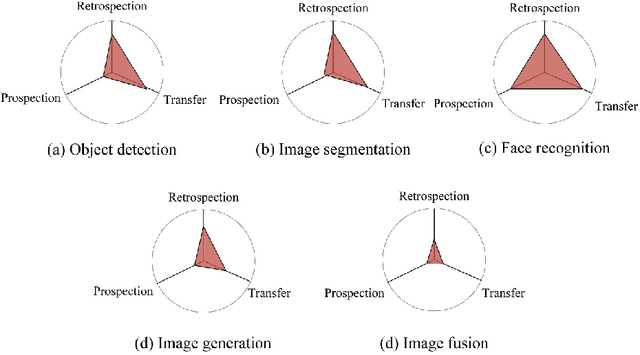
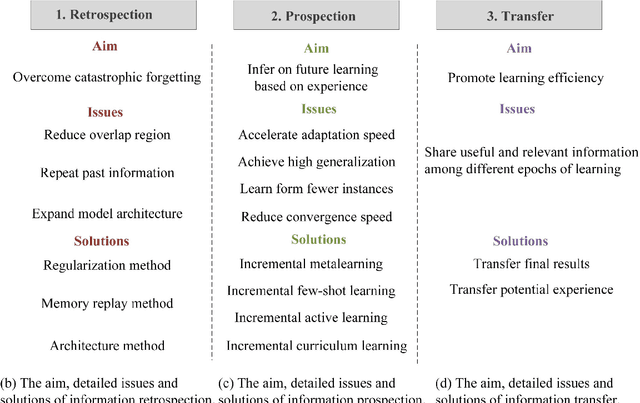
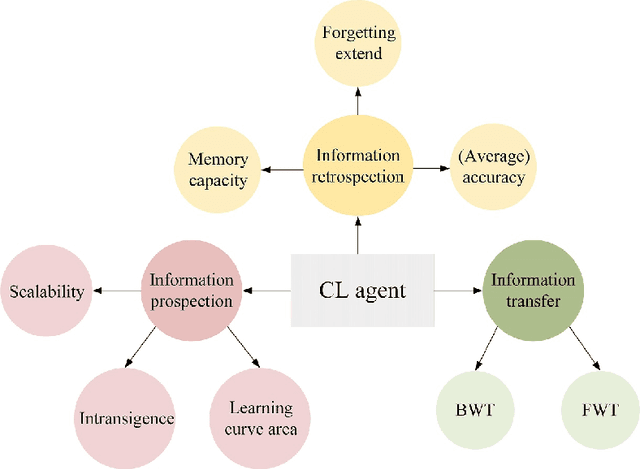
Humans' continual learning (CL) ability is closely related to Stability Versus Plasticity Dilemma that describes how humans achieve ongoing learning capacity and preservation for learned information. The notion of CL has always been present in artificial intelligence (AI) since its births. This paper proposes a comprehensive review of CL. Different from previous reviews that mainly focus on the catastrophic forgetting phenomenon in CL, this paper surveys CL from a more macroscopic perspective based on the Stability Versus Plasticity mechanism. Analogous to biological counterpart, "smart" AI agents are supposed to i) remember previously learned information (information retrospection); ii) infer on new information continuously (information prospection:); iii) transfer useful information (information transfer), to achieve high-level CL. According to the taxonomy, evaluation metrics, algorithms, applications as well as some open issues are then introduced. Our main contributions concern i) rechecking CL from the level of artificial general intelligence; ii) providing a detailed and extensive overview on CL topics; iii) presenting some novel ideas on the potential development of CL.
Face recognition via compact second order image gradient orientations
Jan 29, 2022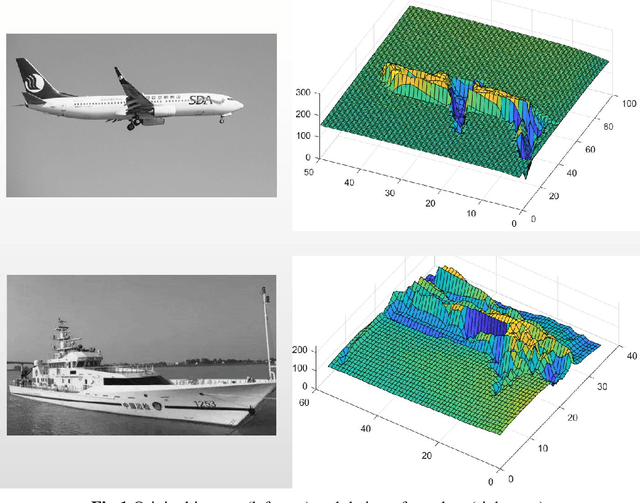
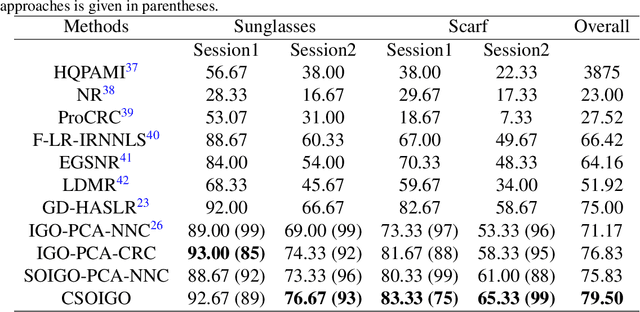

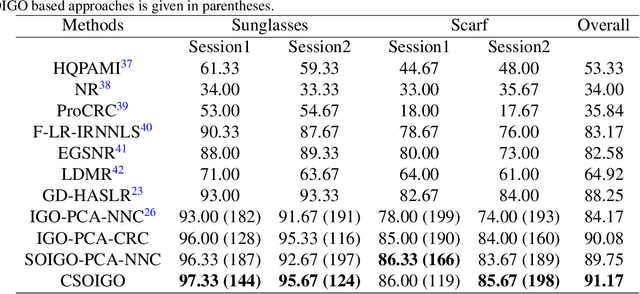
Conventional subspace learning approaches based on image gradient orientations only employ the first-order gradient information. However, recent researches on human vision system (HVS) uncover that the neural image is a landscape or a surface whose geometric properties can be captured through the second order gradient information. The second order image gradient orientations (SOIGO) can mitigate the adverse effect of noises in face images. To reduce the redundancy of SOIGO, we propose compact SOIGO (CSOIGO) by applying linear complex principal component analysis (PCA) in SOIGO. Combined with collaborative representation based classification (CRC) algorithm, the classification performance of CSOIGO is further enhanced. CSOIGO is evaluated under real-world disguise, synthesized occlusion and mixed variations. Experimental results indicate that the proposed method is superior to its competing approaches with few training samples, and even outperforms some prevailing deep neural network based approaches. The source code of CSOIGO is available at https://github.com/yinhefeng/SOIGO.