 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Prompt-based Generative Approach towards Multi-Hierarchical Medical Dialogue State Tracking
Mar 18, 2022

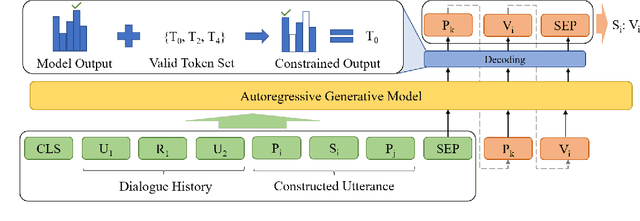


The medical dialogue system is a promising application that can provide great convenience for patients. The dialogue state tracking (DST) module in the medical dialogue system which interprets utterances into the machine-readable structure for downstream tasks is particularly challenging. Firstly, the states need to be able to represent compound entities such as symptoms with their body part or diseases with degrees of severity to provide enough information for decision support. Secondly, these named entities in the utterance might be discontinuous and scattered across sentences and speakers. These also make it difficult to annotate a large corpus which is essential for most methods. Therefore, we first define a multi-hierarchical state structure. We annotate and publish a medical dialogue dataset in Chinese. To the best of our knowledge, there are no publicly available ones before. Then we propose a Prompt-based Generative Approach which can generate slot values with multi-hierarchies incrementally using a top-down approach. A dialogue style prompt is also supplemented to utilize the large unlabeled dialogue corpus to alleviate the data scarcity problem. The experiments show that our approach outperforms other DST methods and is rather effective in the scenario with little data.
RETE: Retrieval-Enhanced Temporal Event Forecasting on Unified Query Product Evolutionary Graph
Feb 12, 2022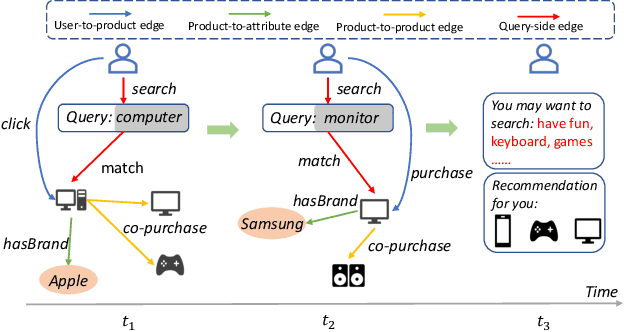
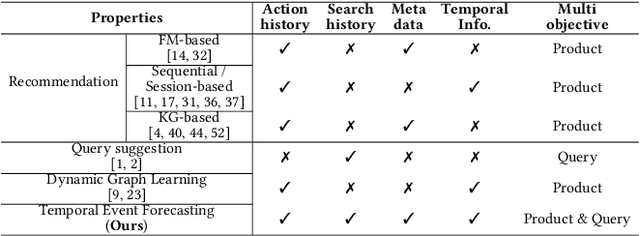
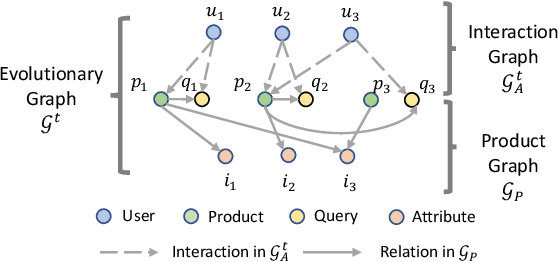
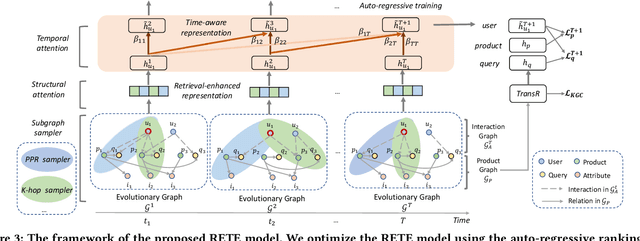
With the increasing demands on e-commerce platforms, numerous user action history is emerging. Those enriched action records are vital to understand users' interests and intents. Recently, prior works for user behavior prediction mainly focus on the interactions with product-side information. However, the interactions with search queries, which usually act as a bridge between users and products, are still under investigated. In this paper, we explore a new problem named temporal event forecasting, a generalized user behavior prediction task in a unified query product evolutionary graph, to embrace both query and product recommendation in a temporal manner. To fulfill this setting, there involves two challenges: (1) the action data for most users is scarce; (2) user preferences are dynamically evolving and shifting over time. To tackle those issues, we propose a novel Retrieval-Enhanced Temporal Event (RETE) forecasting framework. Unlike existing methods that enhance user representations via roughly absorbing information from connected entities in the whole graph, RETE efficiently and dynamically retrieves relevant entities centrally on each user as high-quality subgraphs, preventing the noise propagation from the densely evolutionary graph structures that incorporate abundant search queries. And meanwhile, RETE autoregressively accumulates retrieval-enhanced user representations from each time step, to capture evolutionary patterns for joint query and product prediction. Empirically, extensive experiments on both the public benchmark and four real-world industrial datasets demonstrate the effectiveness of the proposed RETE method.
BERT-ASC: Auxiliary-Sentence Construction for Implicit Aspect Learning in Sentiment Analysis
Mar 22, 2022
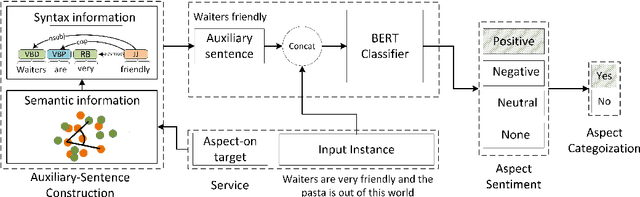
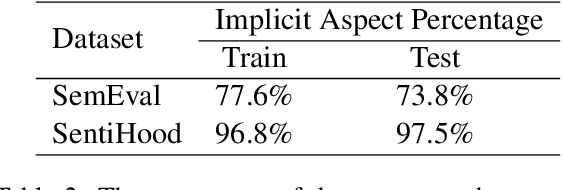

Aspect-based sentiment analysis (ABSA) task aims to associate a piece of text with a set of aspects and meanwhile infer their respective sentimental polarities. Up to now, the state-of-the-art approaches are built upon fine-tuning of various pre-trained language models. They commonly aim to learn the aspect-specific representation in the corpus. Unfortunately, the aspect is often expressed implicitly through a set of representatives and thus renders implicit mapping process unattainable unless sufficient labeled examples. In this paper, we propose to jointly address aspect categorization and aspect-based sentiment subtasks in a unified framework. Specifically, we first introduce a simple but effective mechanism that collaborates the semantic and syntactic information to construct auxiliary-sentences for the implicit aspect. Then, we encourage BERT to learn the aspect-specific representation in response to the automatically constructed auxiliary-sentence instead of the aspect itself. Finally, we empirically evaluate the performance of the proposed solution by a comparative study on real benchmark datasets for both ABSA and Targeted-ABSA tasks. Our extensive experiments show that it consistently achieves state-of-the-art performance in terms of aspect categorization and aspect-based sentiment across all datasets and the improvement margins are considerable.
STDAN: Deformable Attention Network for Space-Time Video Super-Resolution
Mar 14, 2022
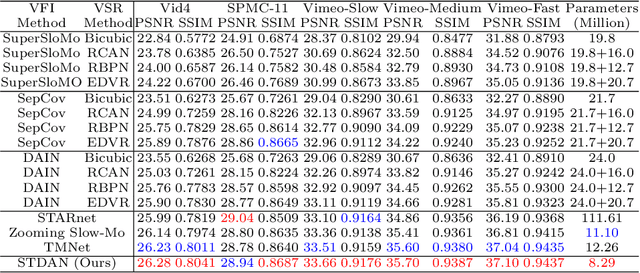
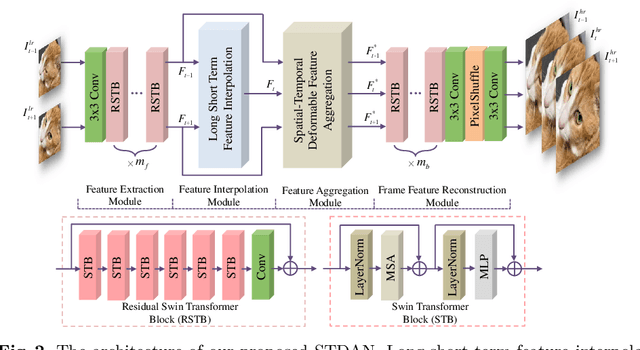
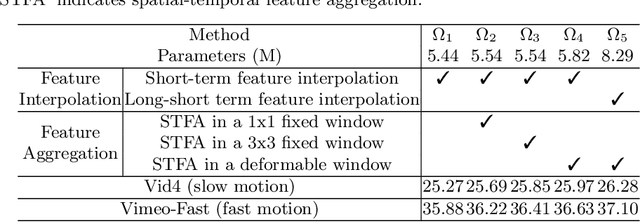
The target of space-time video super-resolution (STVSR) is to increase the spatial-temporal resolution of low-resolution (LR) and low frame rate (LFR) videos. Recent approaches based on deep learning have made significant improvements, but most of them only use two adjacent frames, that is, short-term features, to synthesize the missing frame embedding, which suffers from fully exploring the information flow of consecutive input LR frames. In addition, existing STVSR models hardly exploit the temporal contexts explicitly to assist high-resolution (HR) frame reconstruction. To address these issues, in this paper, we propose a deformable attention network called STDAN for STVSR. First, we devise a long-short term feature interpolation (LSTFI) module, which is capable of excavating abundant content from more neighboring input frames for the interpolation process through a bidirectional RNN structure. Second, we put forward a spatial-temporal deformable feature aggregation (STDFA) module, in which spatial and temporal contexts in dynamic video frames are adaptively captured and aggregated to enhance SR reconstruction. Experimental results on several datasets demonstrate that our approach outperforms state-of-the-art STVSR methods.
Few Shot Generative Model Adaption via Relaxed Spatial Structural Alignment
Mar 14, 2022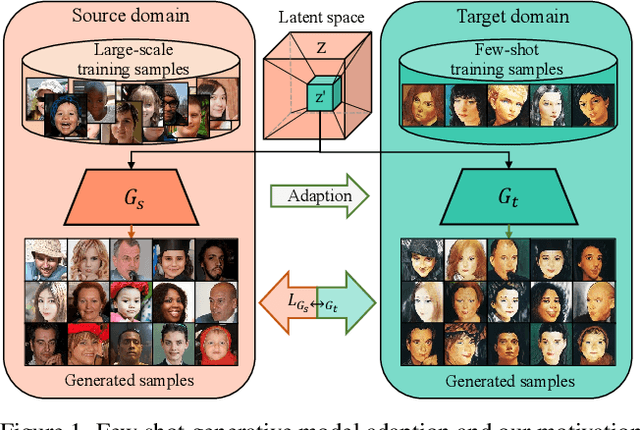
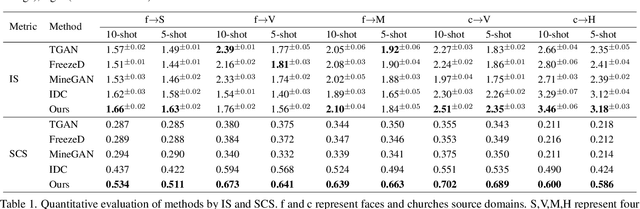
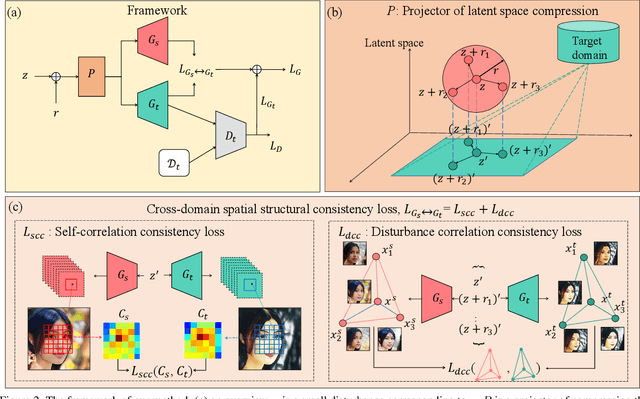

Training a generative adversarial network (GAN) with limited data has been a challenging task. A feasible solution is to start with a GAN well-trained on a large scale source domain and adapt it to the target domain with a few samples, termed as few shot generative model adaption. However, existing methods are prone to model overfitting and collapse in extremely few shot setting (less than 10). To solve this problem, we propose a relaxed spatial structural alignment method to calibrate the target generative models during the adaption. We design a cross-domain spatial structural consistency loss comprising the self-correlation and disturbance correlation consistency loss. It helps align the spatial structural information between the synthesis image pairs of the source and target domains. To relax the cross-domain alignment, we compress the original latent space of generative models to a subspace. Image pairs generated from the subspace are pulled closer. Qualitative and quantitative experiments show that our method consistently surpasses the state-of-the-art methods in few shot setting.
Bridging Information-Seeking Human Gaze and Machine Reading Comprehension
Sep 30, 2020
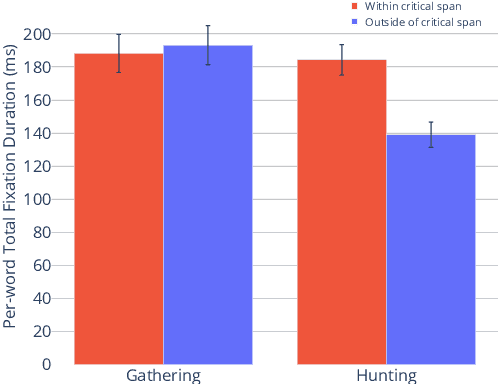
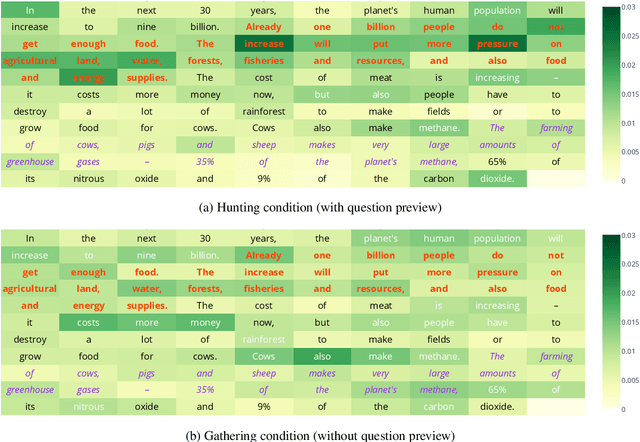
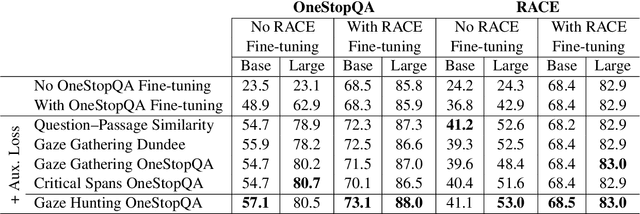
In this work, we analyze how human gaze during reading comprehension is conditioned on the given reading comprehension question, and whether this signal can be beneficial for machine reading comprehension. To this end, we collect a new eye-tracking dataset with a large number of participants engaging in a multiple choice reading comprehension task. Our analysis of this data reveals increased fixation times over parts of the text that are most relevant for answering the question. Motivated by this finding, we propose making automated reading comprehension more human-like by mimicking human information-seeking reading behavior during reading comprehension. We demonstrate that this approach leads to performance gains on multiple choice question answering in English for a state-of-the-art reading comprehension model.
Grounding Commands for Autonomous Vehicles via Layer Fusion with Region-specific Dynamic Layer Attention
Mar 14, 2022
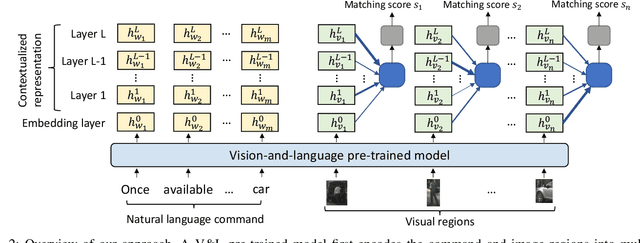
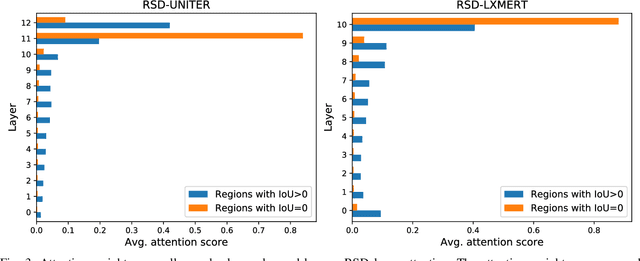
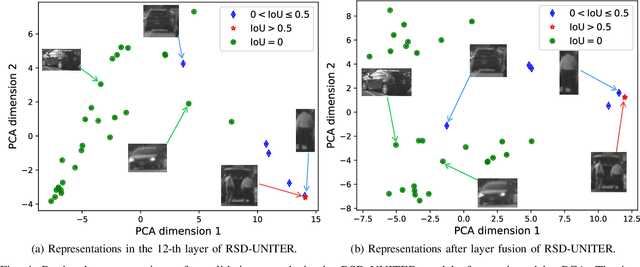
Grounding a command to the visual environment is an essential ingredient for interactions between autonomous vehicles and humans. In this work, we study the problem of language grounding for autonomous vehicles, which aims to localize a region in a visual scene according to a natural language command from a passenger. Prior work only employs the top layer representations of a vision-and-language pre-trained model to predict the region referred to by the command. However, such a method omits the useful features encoded in other layers, and thus results in inadequate understanding of the input scene and command. To tackle this limitation, we present the first layer fusion approach for this task. Since different visual regions may require distinct types of features to disambiguate them from each other, we further propose the region-specific dynamic (RSD) layer attention to adaptively fuse the multimodal information across layers for each region. Extensive experiments on the Talk2Car benchmark demonstrate that our approach helps predict more accurate regions and outperforms state-of-the-art methods.
Modelling and Quantifying Membership Information Leakage in Machine Learning
Jan 29, 2020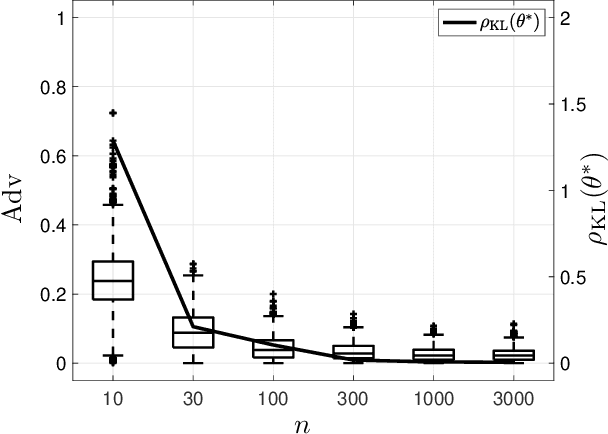
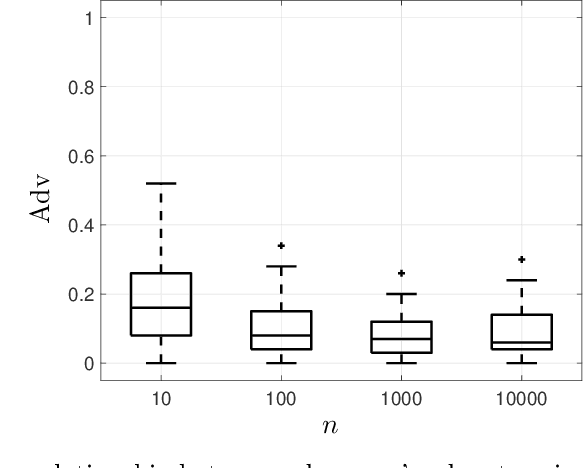
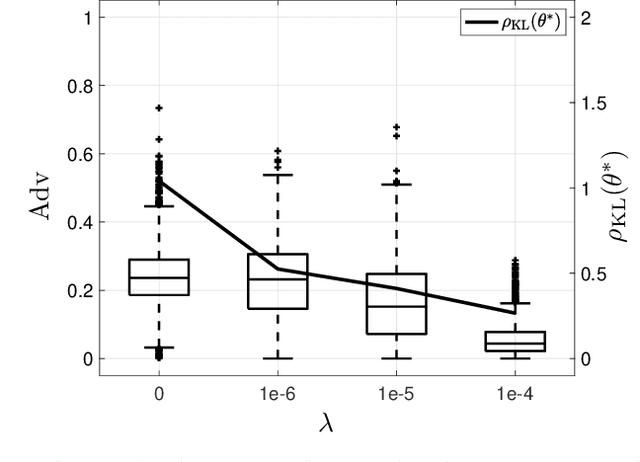
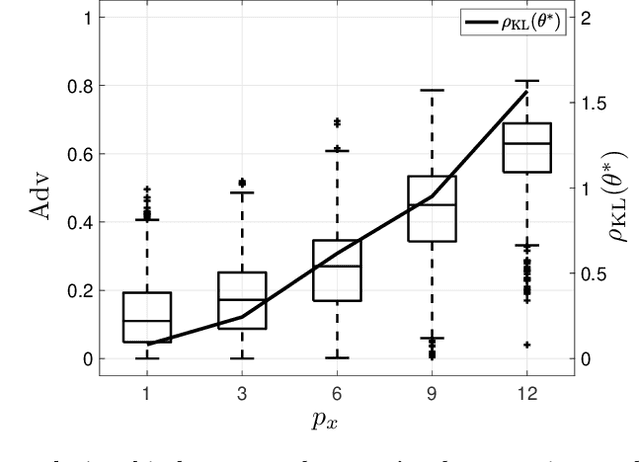
Machine learning models have been shown to be vulnerable to membership inference attacks, i.e., inferring whether individuals' data have been used for training models. The lack of understanding about factors contributing success of these attacks motivates the need for modelling membership information leakage using information theory and for investigating properties of machine learning models and training algorithms that can reduce membership information leakage. We use conditional mutual information leakage to measure the amount of information leakage from the trained machine learning model about the presence of an individual in the training dataset. We devise an upper bound for this measure of information leakage using Kullback--Leibler divergence that is more amenable to numerical computation. We prove a direct relationship between the Kullback--Leibler membership information leakage and the probability of success for a hypothesis-testing adversary examining whether a particular data record belongs to the training dataset of a machine learning model. We show that the mutual information leakage is a decreasing function of the training dataset size and the regularization weight. We also prove that, if the sensitivity of the machine learning model (defined in terms of the derivatives of the fitness with respect to model parameters) is high, more membership information is potentially leaked. This illustrates that complex models, such as deep neural networks, are more susceptible to membership inference attacks in comparison to simpler models with fewer degrees of freedom. We show that the amount of the membership information leakage is reduced by $\mathcal{O}(\log^{1/2}(\delta^{-1})\epsilon^{-1})$ when using Gaussian $(\epsilon,\delta)$-differentially-private additive noises.
Multi-label classification of promotions in digital leaflets using textual and visual information
Oct 07, 2020

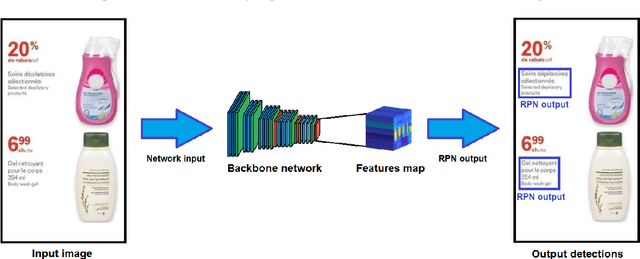

Product descriptions in e-commerce platforms contain detailed and valuable information about retailers assortment. In particular, coding promotions within digital leaflets are of great interest in e-commerce as they capture the attention of consumers by showing regular promotions for different products. However, this information is embedded into images, making it difficult to extract and process for downstream tasks. In this paper, we present an end-to-end approach that classifies promotions within digital leaflets into their corresponding product categories using both visual and textual information. Our approach can be divided into three key components: 1) region detection, 2) text recognition and 3) text classification. In many cases, a single promotion refers to multiple product categories, so we introduce a multi-label objective in the classification head. We demonstrate the effectiveness of our approach for two separated tasks: 1) image-based detection of the descriptions for each individual promotion and 2) multi-label classification of the product categories using the text from the product descriptions. We train and evaluate our models using a private dataset composed of images from digital leaflets obtained by Nielsen. Results show that we consistently outperform the proposed baseline by a large margin in all the experiments.
Bayesian optimization with improved scalability and derivative information for efficient design of nanophotonic structures
Jan 08, 2021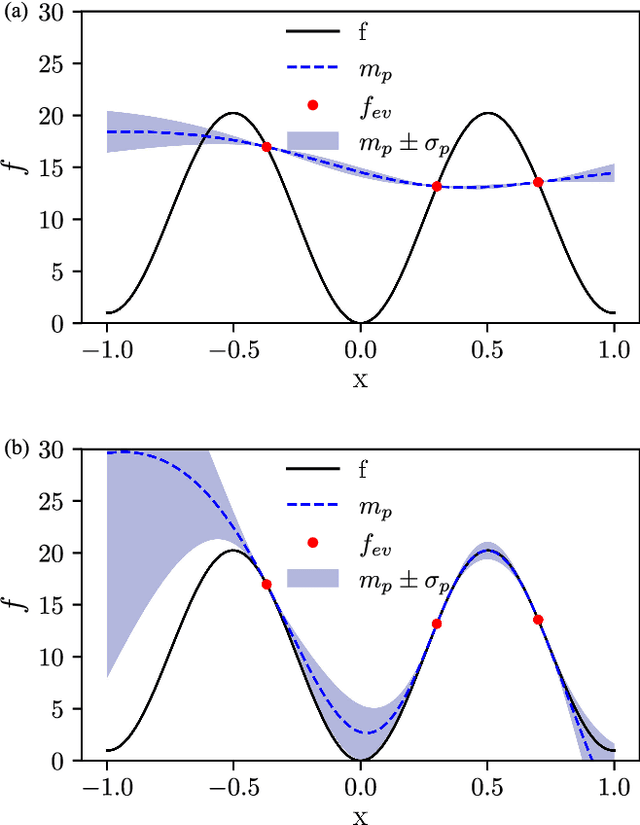
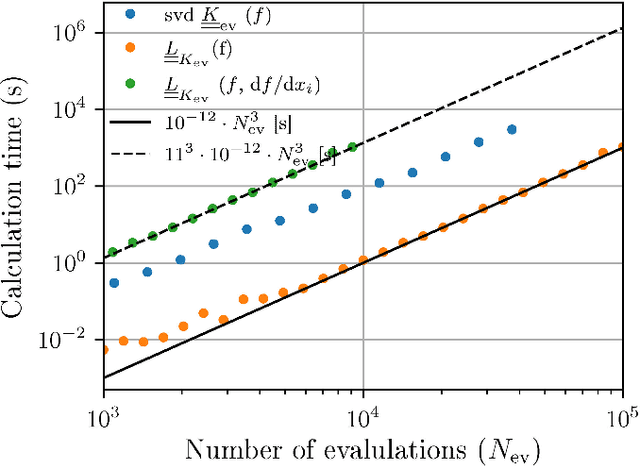
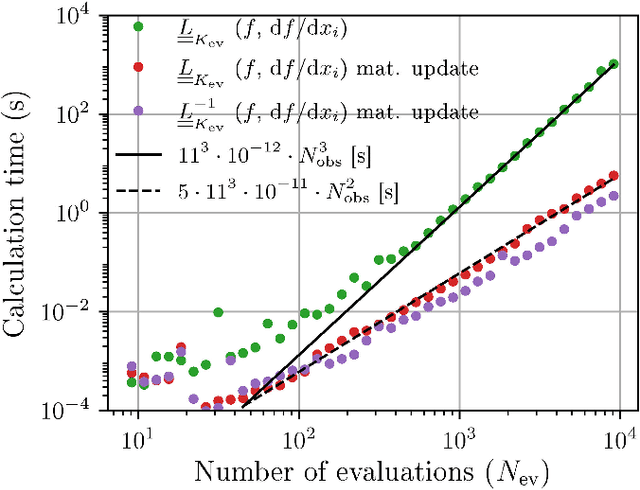
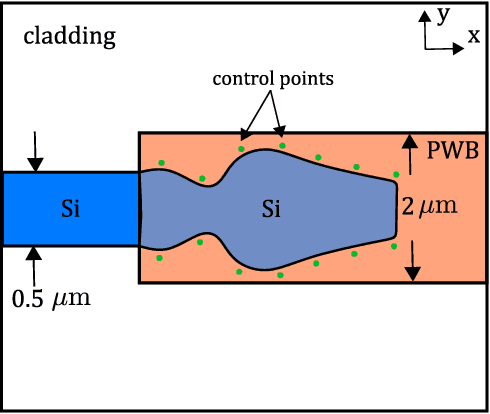
We propose the combination of forward shape derivatives and the use of an iterative inversion scheme for Bayesian optimization to find optimal designs of nanophotonic devices. This approach widens the range of applicability of Bayesian optmization to situations where a larger number of iterations is required and where derivative information is available. This was previously impractical because the computational efforts required to identify the next evaluation point in the parameter space became much larger than the actual evaluation of the objective function. We demonstrate an implementation of the method by optimizing a waveguide edge coupler.