 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Quantifying Relevance in Learning and Inference
Feb 01, 2022
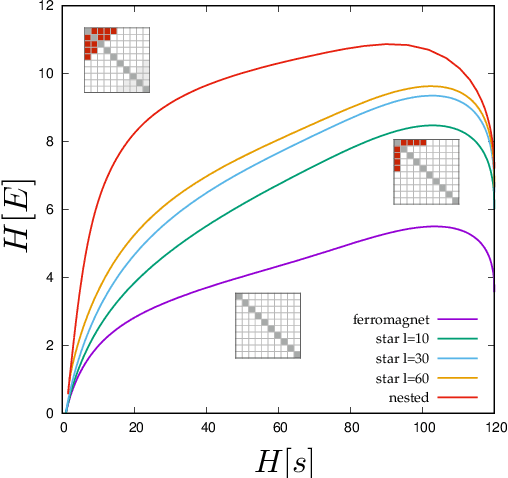
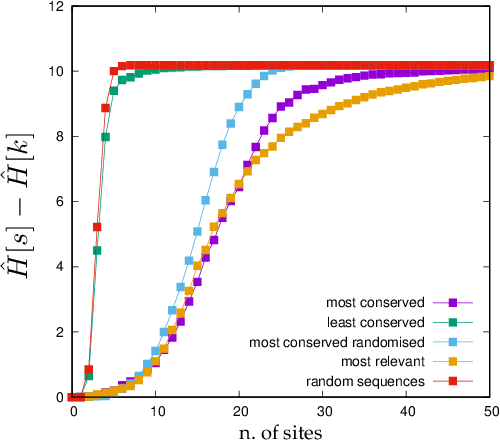
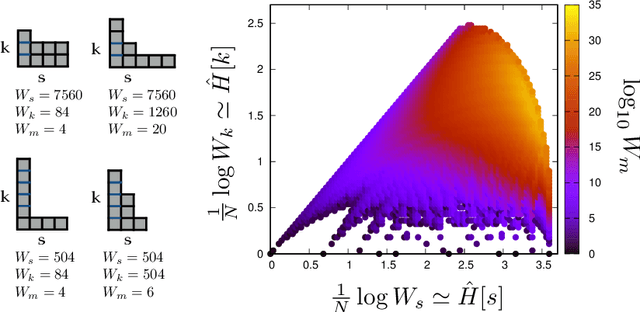
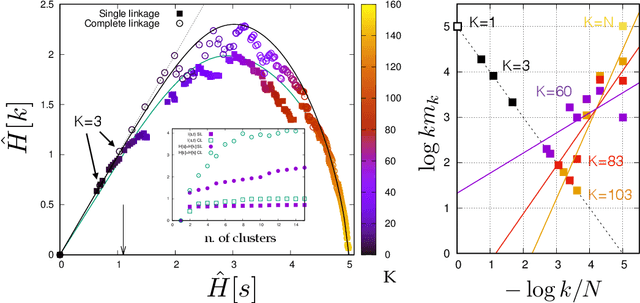
Learning is a distinctive feature of intelligent behaviour. High-throughput experimental data and Big Data promise to open new windows on complex systems such as cells, the brain or our societies. Yet, the puzzling success of Artificial Intelligence and Machine Learning shows that we still have a poor conceptual understanding of learning. These applications push statistical inference into uncharted territories where data is high-dimensional and scarce, and prior information on "true" models is scant if not totally absent. Here we review recent progress on understanding learning, based on the notion of "relevance". The relevance, as we define it here, quantifies the amount of information that a dataset or the internal representation of a learning machine contains on the generative model of the data. This allows us to define maximally informative samples, on one hand, and optimal learning machines on the other. These are ideal limits of samples and of machines, that contain the maximal amount of information about the unknown generative process, at a given resolution (or level of compression). Both ideal limits exhibit critical features in the statistical sense: Maximally informative samples are characterised by a power-law frequency distribution (statistical criticality) and optimal learning machines by an anomalously large susceptibility. The trade-off between resolution (i.e. compression) and relevance distinguishes the regime of noisy representations from that of lossy compression. These are separated by a special point characterised by Zipf's law statistics. This identifies samples obeying Zipf's law as the most compressed loss-less representations that are optimal in the sense of maximal relevance. Criticality in optimal learning machines manifests in an exponential degeneracy of energy levels, that leads to unusual thermodynamic properties.
Fashionformer: A simple, Effective and Unified Baseline for Human Fashion Segmentation and Recognition
Apr 10, 2022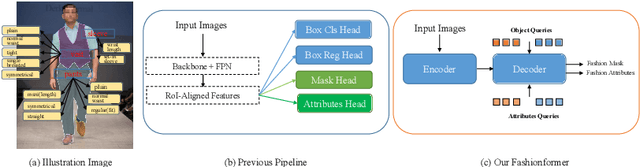
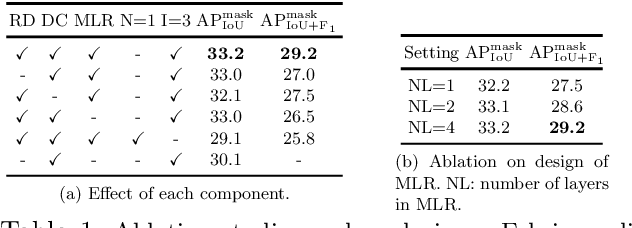
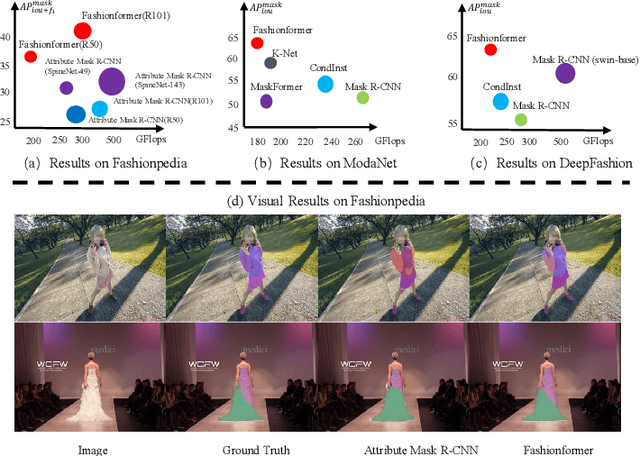
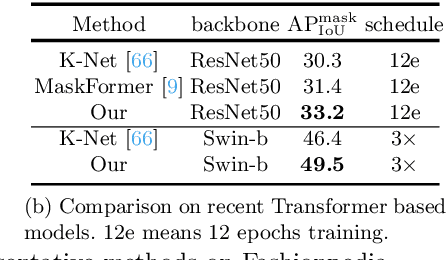
Human fashion understanding is one important computer vision task since it has the comprehensive information that can be used for real-world applications. In this work, we focus on joint human fashion segmentation and attribute recognition. Contrary to the previous works that separately model each task as a multi-head prediction problem, our insight is to bridge these two tasks with one unified model via vision transformer modeling to benefit each task. In particular, we introduce the object query for segmentation and the attribute query for attribute prediction. Both queries and their corresponding features can be linked via mask prediction. Then we adopt a two-stream query learning framework to learn the decoupled query representations. For attribute stream, we design a novel Multi-Layer Rendering module to explore more fine-grained features. The decoder design shares the same spirits with DETR, thus we name the proposed method Fahsionformer. Extensive experiments on three human fashion datasets including Fashionpedia, ModaNet and Deepfashion illustrate the effectiveness of our approach. In particular, our method with the same backbone achieve relative 10% improvements than previous works in case of \textit{a joint metric ( AP$^{\text{mask}}_{\text{IoU+F}_1}$) for both segmentation and attribute recognition}. To the best of our knowledge, we are the first unified end-to-end vision transformer framework for human fashion analysis. We hope this simple yet effective method can serve as a new flexible baseline for fashion analysis. Code will be available at https://github.com/xushilin1/FashionFormer.
Semantically Grounded Visual Embeddings for Zero-Shot Learning
Jan 03, 2022
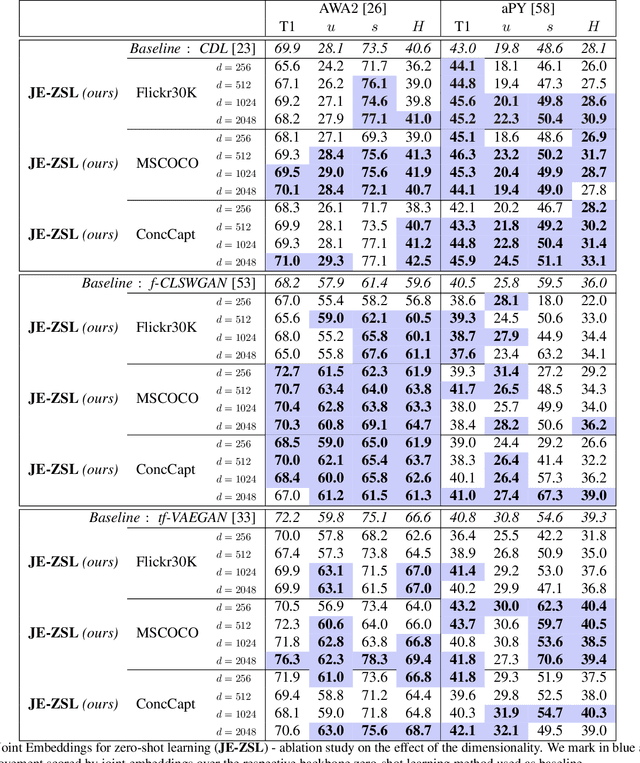
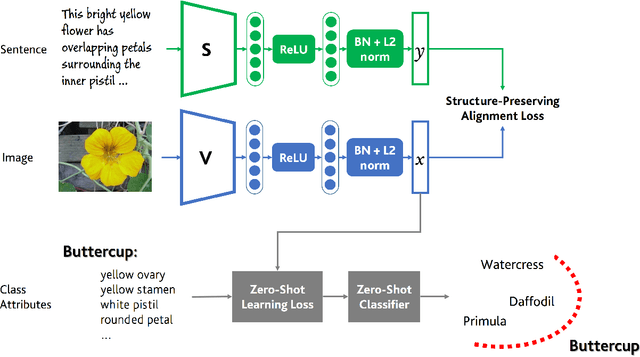
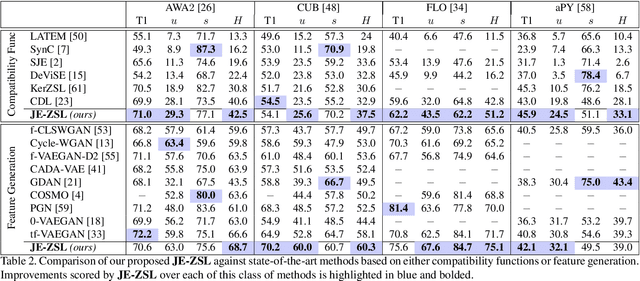
Zero-shot learning methods rely on fixed visual and semantic embeddings, extracted from independent vision and language models, both pre-trained for other large-scale tasks. This is a weakness of current zero-shot learning frameworks as such disjoint embeddings fail to adequately associate visual and textual information to their shared semantic content. Therefore, we propose to learn semantically grounded and enriched visual information by computing a joint image and text model with a two-stream network on a proxy task. To improve this alignment between image and textual representations, provided by attributes, we leverage ancillary captions to provide grounded semantic information. Our method, dubbed joint embeddings for zero-shot learning is evaluated on several benchmark datasets, improving the performance of existing state-of-the-art methods in both standard ($+1.6$\% on aPY, $+2.6\%$ on FLO) and generalized ($+2.1\%$ on AWA$2$, $+2.2\%$ on CUB) zero-shot recognition.
BARACK: Partially Supervised Group Robustness With Guarantees
Dec 31, 2021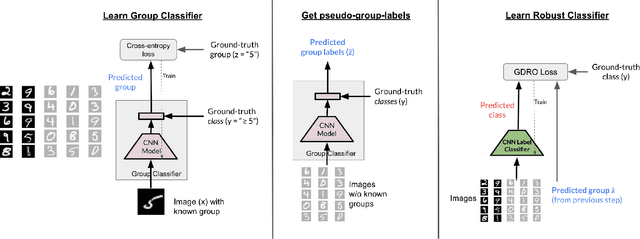



While neural networks have shown remarkable success on classification tasks in terms of average-case performance, they often fail to perform well on certain groups of the data. Such group information may be expensive to obtain; thus, recent works in robustness and fairness have proposed ways to improve worst-group performance even when group labels are unavailable for the training data. However, these methods generally underperform methods that utilize group information at training time. In this work, we assume access to a small number of group labels alongside a larger dataset without group labels. We propose BARACK, a simple two-step framework to utilize this partial group information to improve worst-group performance: train a model to predict the missing group labels for the training data, and then use these predicted group labels in a robust optimization objective. Theoretically, we provide generalization bounds for our approach in terms of the worst-group performance, showing how the generalization error scales with respect to both the total number of training points and the number of training points with group labels. Empirically, our method outperforms the baselines that do not use group information, even when only 1-33% of points have group labels. We provide ablation studies to support the robustness and extensibility of our framework.
Applications of blockchain and artificial intelligence technologies for enabling prosumers in smart grids: A review
Feb 21, 2022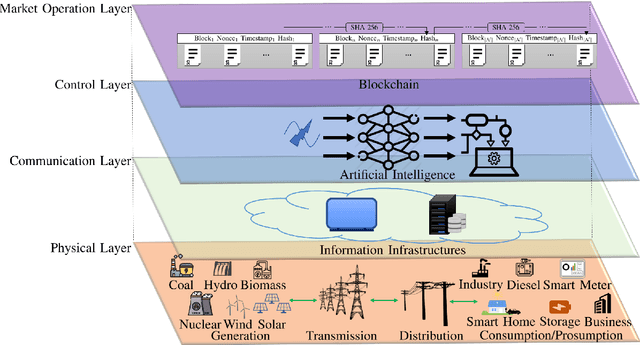

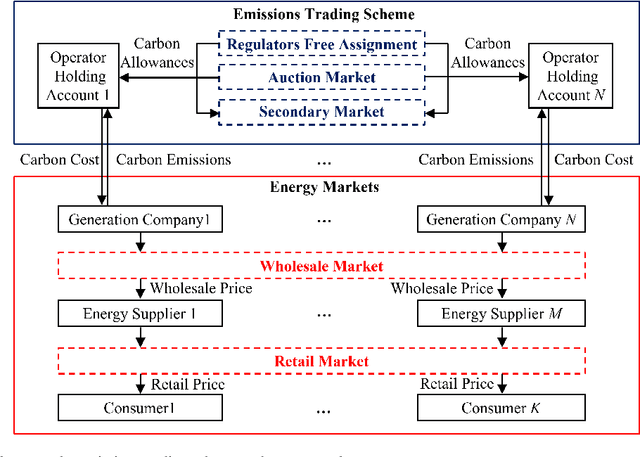
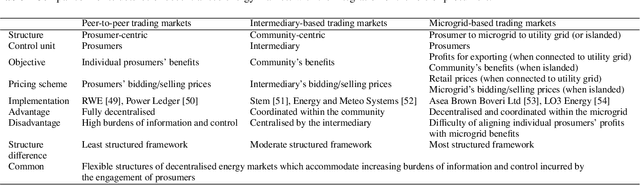
Governments' net zero emission target aims at increasing the share of renewable energy sources as well as influencing the behaviours of consumers to support the cost-effective balancing of energy supply and demand. These will be achieved by the advanced information and control infrastructures of smart grids which allow the interoperability among various stakeholders. Under this circumstance, increasing number of consumers produce, store, and consume energy, giving them a new role of prosumers. The integration of prosumers and accommodation of incurred bidirectional flows of energy and information rely on two key factors: flexible structures of energy markets and intelligent operations of power systems. The blockchain and artificial intelligence (AI) are innovative technologies to fulfil these two factors, by which the blockchain provides decentralised trading platforms for energy markets and the AI supports the optimal operational control of power systems. This paper attempts to address how to incorporate the blockchain and AI in the smart grids for facilitating prosumers to participate in energy markets. To achieve this objective, first, this paper reviews how policy designs price carbon emissions caused by the fossil-fuel based generation so as to facilitate the integration of prosumers with renewable energy sources. Second, the potential structures of energy markets with the support of the blockchain technologies are discussed. Last, how to apply the AI for enhancing the state monitoring and decision making during the operations of power systems is introduced.
* Accepted by Renewable & Sustainable Energy Reviews on 21 Feb 2022
Multi-Unit Diffusion Auctions with Intermediaries
Mar 15, 2022
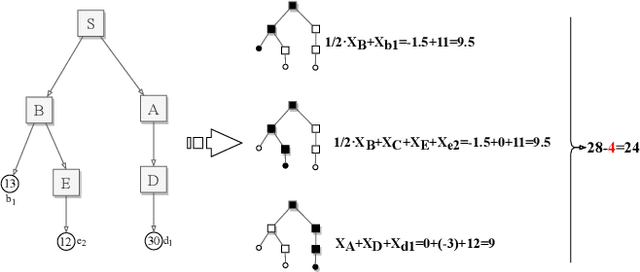
This paper studies multi-unit auctions powered by intermediaries, where each intermediary owns a private set of unit-demand buyers and all intermediaries are networked with each other. Our goal is to incentivize the intermediaries to diffuse the auction information to individuals they can reach, including their private buyers and neighboring intermediaries, so that more potential buyers are able to participate in the auction. To this end, we build a diffusion-based auction framework which incorporates the strategic interaction of intermediaries. It is showed that the classic Vickrey-Clarke-Groves (VCG) mechanism within the framework can achieve the maximum social welfare, but it may decrease the seller's revenue or even lead to a deficit. To overcome the revenue issue, we propose a novel auction, called critical neighborhood auction, which not only maximizes the social welfare, but also improves the seller's revenue comparing to the VCG mechanism with/without intermediaries.
Learning Asymmetric Embedding for Attributed Networks via Convolutional Neural Network
Feb 13, 2022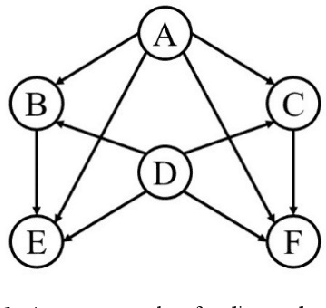

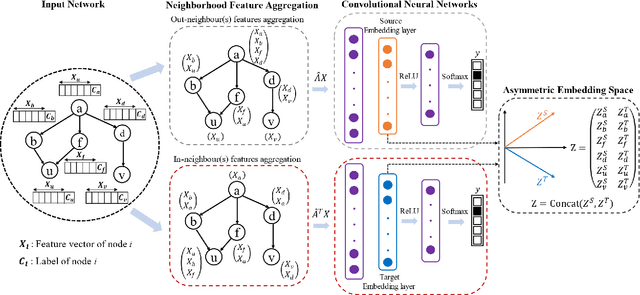
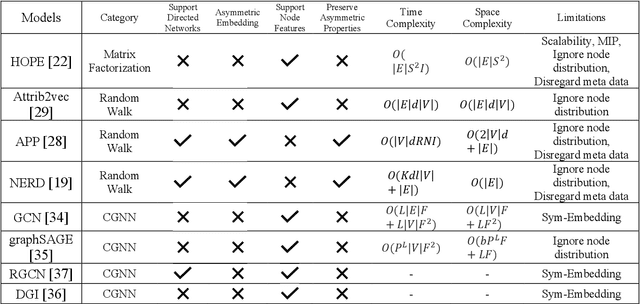
Recently network embedding has gained increasing attention due to its advantages in facilitating network computation tasks such as link prediction, node classification and node clustering. The objective of network embedding is to represent network nodes in a low-dimensional vector space while retaining as much information as possible from the original network including structural, relational, and semantic information. However, asymmetric nature of directed networks poses many challenges as how to best preserve edge directions in the embedding process. Here, we propose a novel deep asymmetric attributed network embedding model based on convolutional graph neural network, called AAGCN. The main idea is to maximally preserve the asymmetric proximity and asymmetric similarity of directed attributed networks. AAGCN introduces two neighbourhood feature aggregation schemes to separately aggregate the features of a node with the features of its in- and out- neighbours. Then, it learns two embedding vectors for each node, one source embedding vector and one target embedding vector. The final representations are the results of concatenating source and target embedding vectors. We test the performance of AAGCN on three real-world networks for network reconstruction, link prediction, node classification and visualization tasks. The experimental results show the superiority of AAGCN against state-of-the-art embedding methods.
Construction of Large-Scale Misinformation Labeled Datasets from Social Media Discourse using Label Refinement
Feb 24, 2022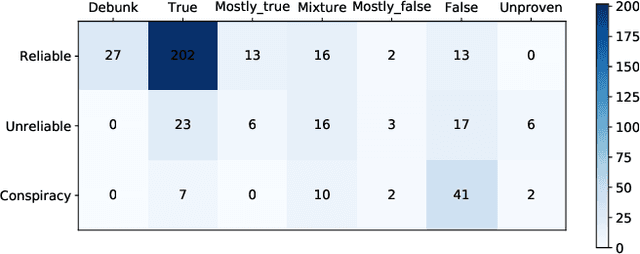

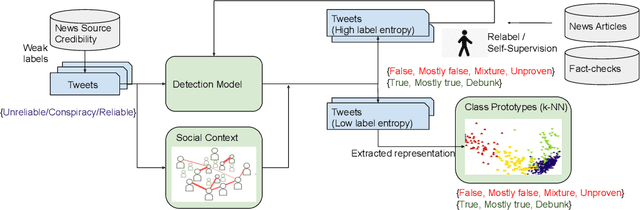

Malicious accounts spreading misinformation has led to widespread false and misleading narratives in recent times, especially during the COVID-19 pandemic, and social media platforms struggle to eliminate these contents rapidly. This is because adapting to new domains requires human intensive fact-checking that is slow and difficult to scale. To address this challenge, we propose to leverage news-source credibility labels as weak labels for social media posts and propose model-guided refinement of labels to construct large-scale, diverse misinformation labeled datasets in new domains. The weak labels can be inaccurate at the article or social media post level where the stance of the user does not align with the news source or article credibility. We propose a framework to use a detection model self-trained on the initial weak labels with uncertainty sampling based on entropy in predictions of the model to identify potentially inaccurate labels and correct for them using self-supervision or relabeling. The framework will incorporate social context of the post in terms of the community of its associated user for surfacing inaccurate labels towards building a large-scale dataset with minimum human effort. To provide labeled datasets with distinction of misleading narratives where information might be missing significant context or has inaccurate ancillary details, the proposed framework will use the few labeled samples as class prototypes to separate high confidence samples into false, unproven, mixture, mostly false, mostly true, true, and debunk information. The approach is demonstrated for providing a large-scale misinformation dataset on COVID-19 vaccines.
Significant Low-dimensional Spectral-temporal Features for Seizure Detection
Feb 13, 2022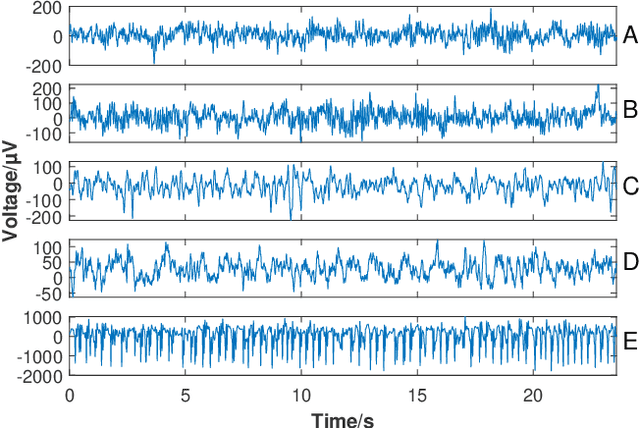
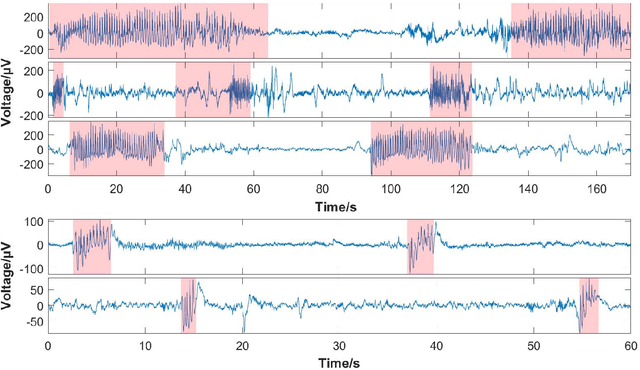
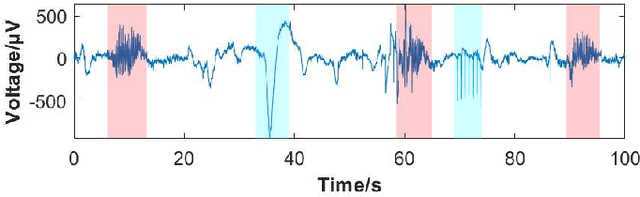
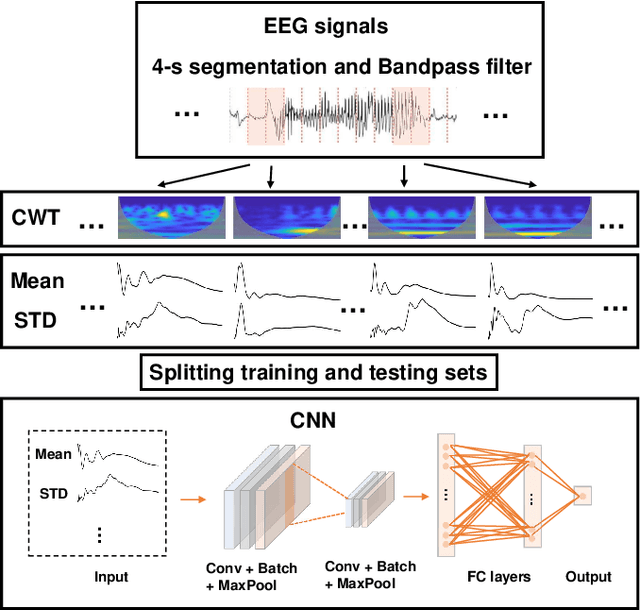
Seizure onset detection in electroencephalography (EEG) signals is a challenging task due to the non-stereotyped seizure activities as well as their stochastic and non-stationary characteristics in nature. Joint spectral-temporal features are believed to contain sufficient and powerful feature information for absence seizure detection. However, the resulting high-dimensional features involve redundant information and require heavy computational load. Here, we discover significant low-dimensional spectral-temporal features in terms of mean-standard deviation of wavelet transform coefficient (MS-WTC), based on which a novel absence seizure detection framework is developed. The EEG signals are transformed into the spectral-temporal domain, with their low-dimensional features fed into a convolutional neural network. Superior detection performance is achieved on the widely-used benchmark dataset as well as a clinical dataset from the Chinese 301 Hospital. For the former, seven classification tasks were evaluated with the accuracy from 99.8% to 100.0%, while for the latter, the method achieved a mean accuracy of 94.7%, overwhelming other methods with low-dimensional temporal and spectral features. Experimental results on two seizure datasets demonstrate reliability, efficiency and stability of our proposed MS-WTC method, validating the significance of the extracted low-dimensional spectral-temporal features.
Why adversarial training can hurt robust accuracy
Mar 03, 2022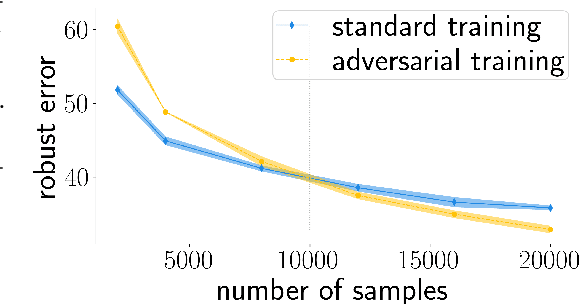
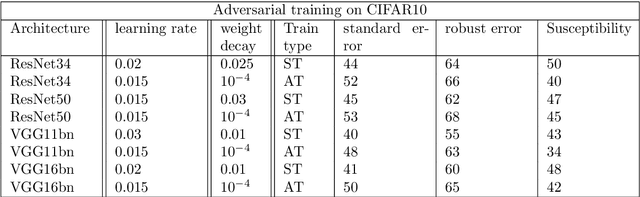

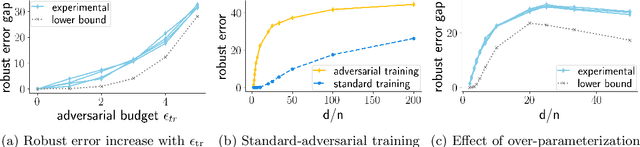
Machine learning classifiers with high test accuracy often perform poorly under adversarial attacks. It is commonly believed that adversarial training alleviates this issue. In this paper, we demonstrate that, surprisingly, the opposite may be true -- Even though adversarial training helps when enough data is available, it may hurt robust generalization in the small sample size regime. We first prove this phenomenon for a high-dimensional linear classification setting with noiseless observations. Our proof provides explanatory insights that may also transfer to feature learning models. Further, we observe in experiments on standard image datasets that the same behavior occurs for perceptible attacks that effectively reduce class information such as mask attacks and object corruptions.