 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Error Correction Code Transformer
Mar 27, 2022
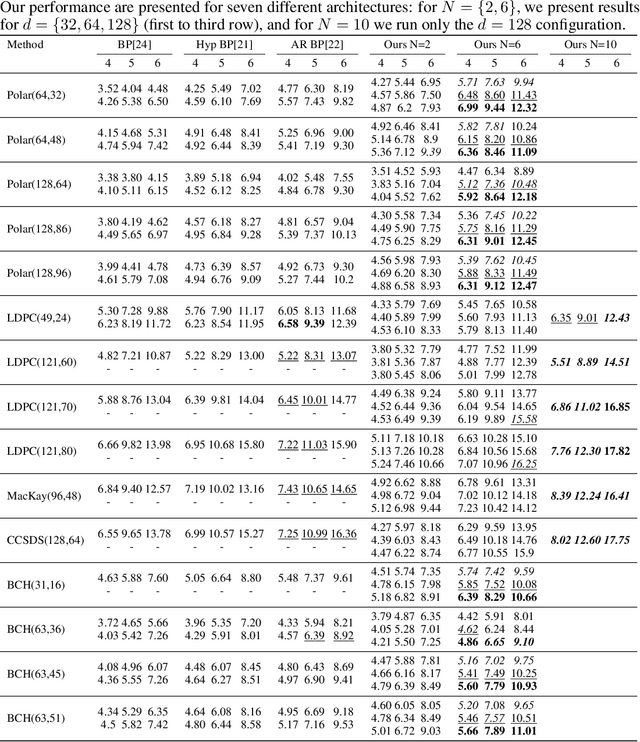

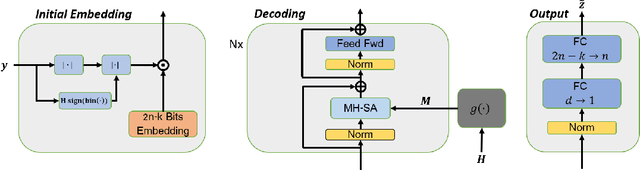
Error correction code is a major part of the communication physical layer, ensuring the reliable transfer of data over noisy channels. Recently, neural decoders were shown to outperform classical decoding techniques. However, the existing neural approaches present strong overfitting due to the exponential training complexity, or a restrictive inductive bias due to reliance on Belief Propagation. Recently, Transformers have become methods of choice in many applications thanks to their ability to represent complex interactions between elements. In this work, we propose to extend for the first time the Transformer architecture to the soft decoding of linear codes at arbitrary block lengths. We encode each channel's output dimension to high dimension for better representation of the bits information to be processed separately. The element-wise processing allows the analysis of the channel output reliability, while the algebraic code and the interaction between the bits are inserted into the model via an adapted masked self-attention module. The proposed approach demonstrates the extreme power and flexibility of Transformers and outperforms existing state-of-the-art neural decoders by large margins at a fraction of their time complexity.
Sharp Thresholds of the Information Cascade Fragility Under a Mismatched Model
Jun 07, 2020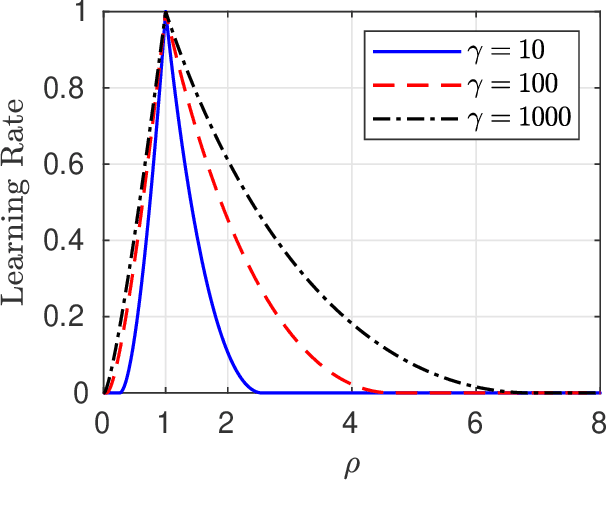
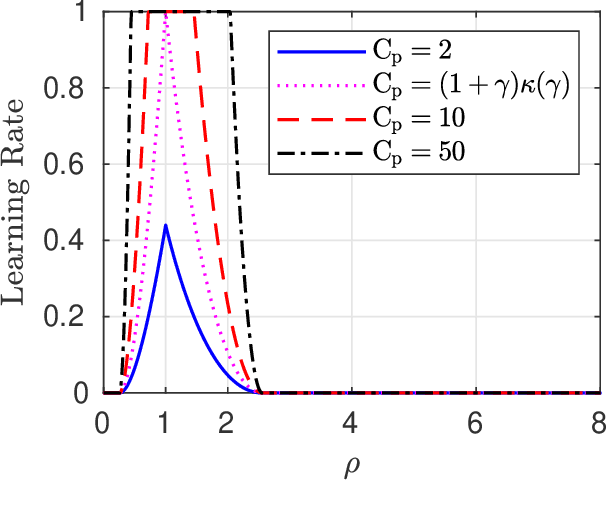
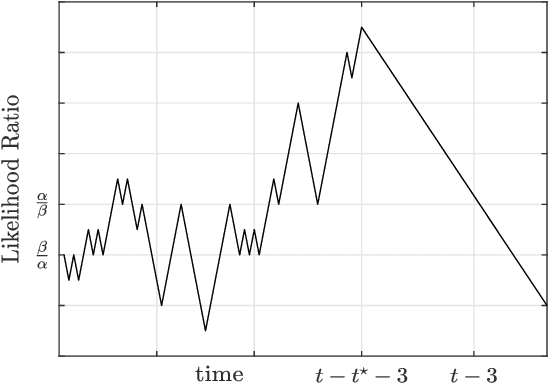
We analyze a sequential decision making model in which decision makers (or, players) take their decisions based on their own private information as well as the actions of previous decision makers. Such decision making processes often lead to what is known as the \emph{information cascade} or \emph{herding} phenomenon. Specifically, a cascade develops when it seems rational for some players to abandon their own private information and imitate the actions of earlier players. The risk, however, is that if the initial decisions were wrong, then the whole cascade will be wrong. Nonetheless, information cascade are known to be fragile: there exists a sequence of \emph{revealing} probabilities $\{p_{\ell}\}_{\ell\geq1}$, such that if with probability $p_{\ell}$ player $\ell$ ignores the decisions of previous players, and rely on his private information only, then wrong cascades can be avoided. Previous related papers which study the fragility of information cascades always assume that the revealing probabilities are known to all players perfectly, which might be unrealistic in practice. Accordingly, in this paper we study a mismatch model where players believe that the revealing probabilities are $\{q_\ell\}_{\ell\in\mathbb{N}}$ when they truly are $\{p_\ell\}_{\ell\in\mathbb{N}}$, and study the effect of this mismatch on information cascades. We consider both adversarial and probabilistic sequential decision making models, and derive closed-form expressions for the optimal learning rates at which the error probability associated with a certain decision maker goes to zero. We prove several novel phase transitions in the behaviour of the asymptotic learning rate.
OPAL: Occlusion Pattern Aware Loss for Unsupervised Light Field Disparity Estimation
Mar 31, 2022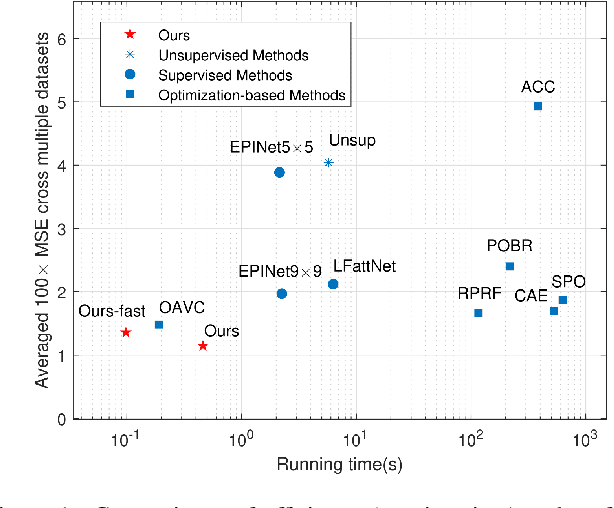
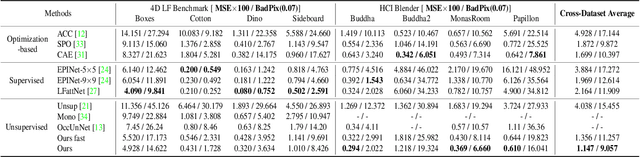
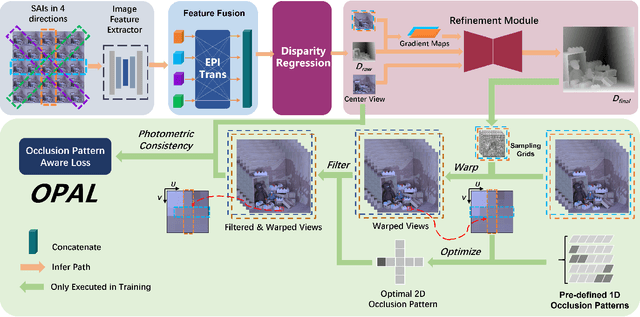
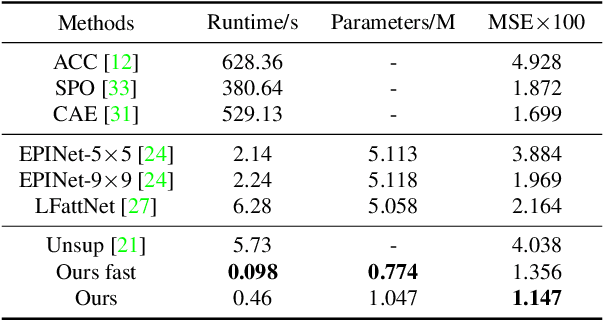
Light field disparity estimation is an essential task in computer vision with various applications. Although supervised learning-based methods have achieved both higher accuracy and efficiency than traditional optimization-based methods, the dependency on ground-truth disparity for training limits the overall generalization performance not to say for real-world scenarios where the ground-truth disparity is hard to capture. In this paper, we argue that unsupervised methods can achieve comparable accuracy, but, more importantly, much higher generalization capacity and efficiency than supervised methods. Specifically, we present the Occlusion Pattern Aware Loss, named OPAL, which successfully extracts and encodes the general occlusion patterns inherent in the light field for loss calculation. OPAL enables: i) accurate and robust estimation by effectively handling occlusions without using any ground-truth information for training and ii) much efficient performance by significantly reducing the network parameters required for accurate inference. Besides, a transformer-based network and a refinement module are proposed for achieving even more accurate results. Extensive experiments demonstrate our method not only significantly improves the accuracy compared with the SOTA unsupervised methods, but also possesses strong generalization capacity, even for real-world data, compared with supervised methods. Our code will be made publicly available.
Nemo: Guiding and Contextualizing Weak Supervision for Interactive Data Programming
Mar 23, 2022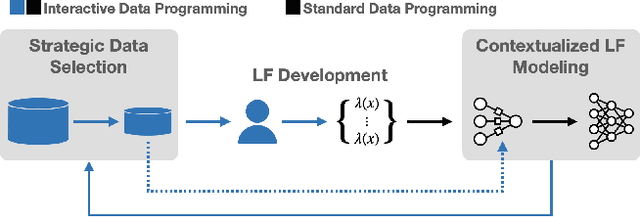
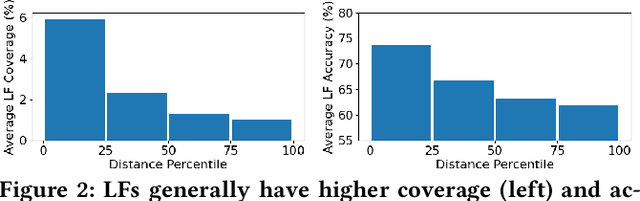
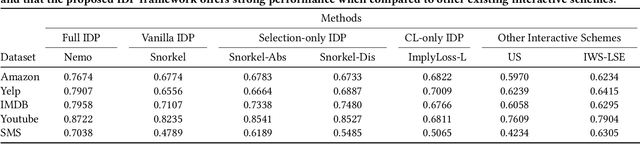
Weak Supervision (WS) techniques allow users to efficiently create large training datasets by programmatically labeling data with heuristic sources of supervision. While the success of WS relies heavily on the provided labeling heuristics, the process of how these heuristics are created in practice has remained under-explored. In this work, we formalize the development process of labeling heuristics as an interactive procedure, built around the existing workflow where users draw ideas from a selected set of development data for designing the heuristic sources. With the formalism, we study two core problems of how to strategically select the development data to guide users in efficiently creating informative heuristics, and how to exploit the information within the development process to contextualize and better learn from the resultant heuristics. Building upon two novel methodologies that effectively tackle the respective problems considered, we present Nemo, an end-to-end interactive system that improves the overall productivity of WS learning pipeline by an average 20% (and up to 47% in one task) compared to the prevailing WS approach.
GENEOnet: A new machine learning paradigm based on Group Equivariant Non-Expansive Operators. An application to protein pocket detection
Jan 31, 2022Nowadays there is a big spotlight cast on the development of techniques of explainable machine learning. Here we introduce a new computational paradigm based on Group Equivariant Non-Expansive Operators, that can be regarded as the product of a rising mathematical theory of information-processing observers. This approach, that can be adjusted to different situations, may have many advantages over other common tools, like Neural Networks, such as: knowledge injection and information engineering, selection of relevant features, small number of parameters and higher transparency. We chose to test our method, called GENEOnet, on a key problem in drug design: detecting pockets on the surface of proteins that can host ligands. Experimental results confirmed that our method works well even with a quite small training set, providing thus a great computational advantage, while the final comparison with other state-of-the-art methods shows that GENEOnet provides better or comparable results in terms of accuracy.
Incentive Mechanism Design for Joint Resource Allocation in Blockchain-based Federated Learning
Feb 18, 2022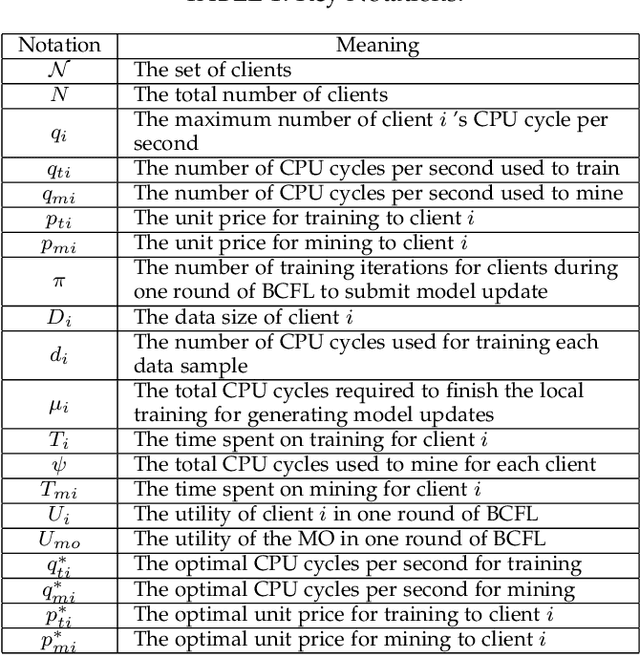
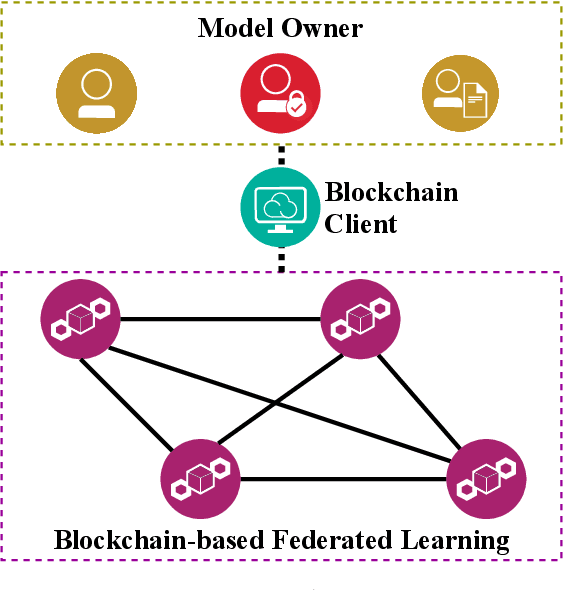
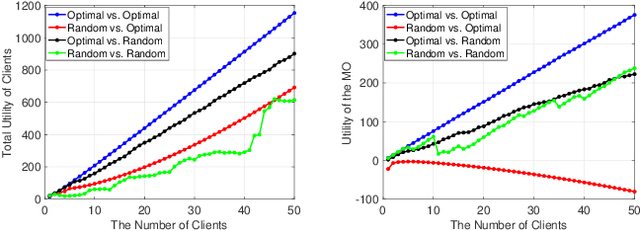
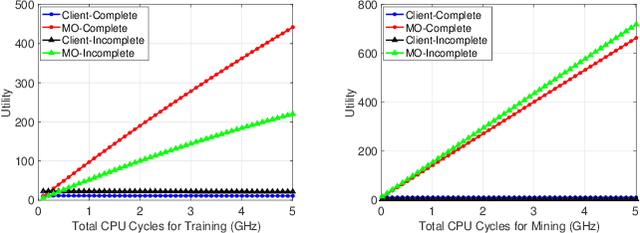
Blockchain-based federated learning (BCFL) has recently gained tremendous attention because of its advantages such as decentralization and privacy protection of raw data. However, there has been few research focusing on the allocation of resources for clients in BCFL. In the BCFL framework where the FL clients and the blockchain miners are the same devices, clients broadcast the trained model updates to the blockchain network and then perform mining to generate new blocks. Since each client has a limited amount of computing resources, the problem of allocating computing resources into training and mining needs to be carefully addressed. In this paper, we design an incentive mechanism to assign each client appropriate rewards for training and mining, and then the client will determine the amount of computing power to allocate for each subtask based on these rewards using the two-stage Stackelberg game. After analyzing the utilities of the model owner (MO) (i.e., the BCFL task publisher) and clients, we transform the game model into two optimization problems, which are sequentially solved to derive the optimal strategies for both the MO and clients. Further, considering the fact that local training related information of each client may not be known by others, we extend the game model with analytical solutions to the incomplete information scenario. Extensive experimental results demonstrate the validity of our proposed schemes.
CholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Apr 10, 2022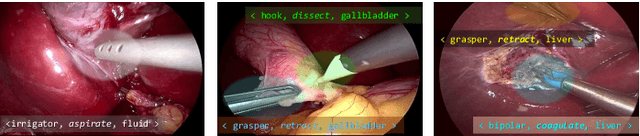

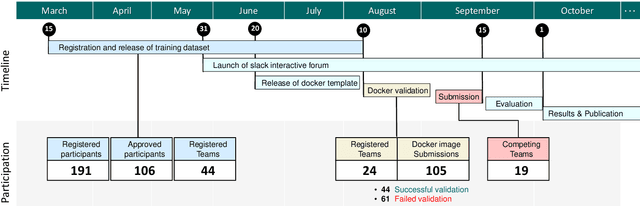
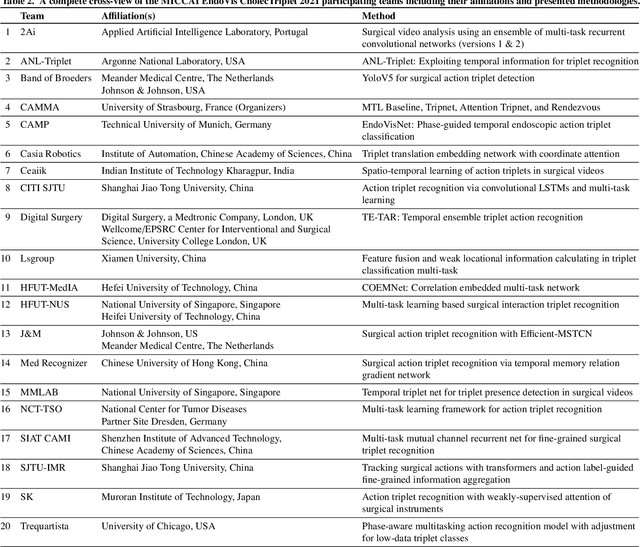
Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.
Stochastic Contextual Dueling Bandits under Linear Stochastic Transitivity Models
Feb 09, 2022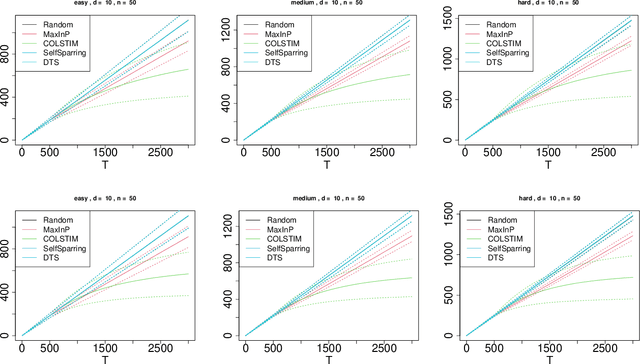
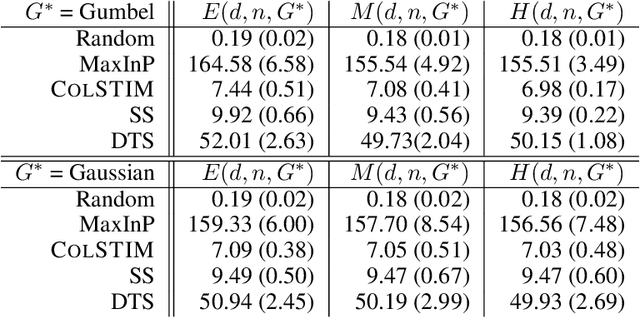
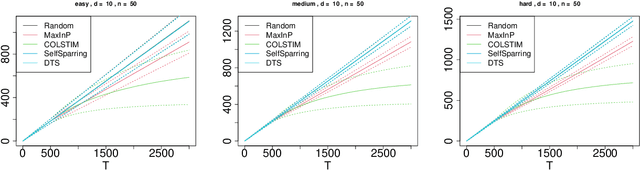
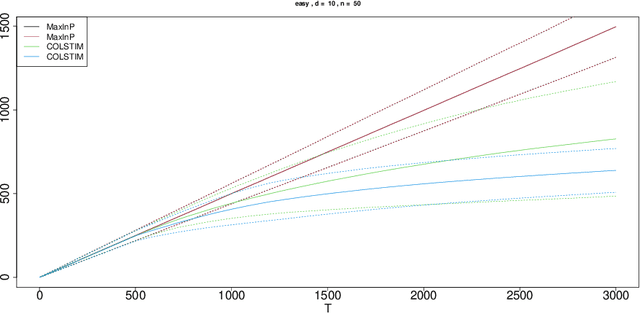
We consider the regret minimization task in a dueling bandits problem with context information. In every round of the sequential decision problem, the learner makes a context-dependent selection of two choice alternatives (arms) to be compared with each other and receives feedback in the form of noisy preference information. We assume that the feedback process is determined by a linear stochastic transitivity model with contextualized utilities (CoLST), and the learner's task is to include the best arm (with highest latent context-dependent utility) in the duel. We propose a computationally efficient algorithm, $\texttt{CoLSTIM}$, which makes its choice based on imitating the feedback process using perturbed context-dependent utility estimates of the underlying CoLST model. If each arm is associated with a $d$-dimensional feature vector, we show that $\texttt{CoLSTIM}$ achieves a regret of order $\tilde O( \sqrt{dT})$ after $T$ learning rounds. Additionally, we also establish the optimality of $\texttt{CoLSTIM}$ by showing a lower bound for the weak regret that refines the existing average regret analysis. Our experiments demonstrate its superiority over state-of-art algorithms for special cases of CoLST models.
Look Backward and Forward: Self-Knowledge Distillation with Bidirectional Decoder for Neural Machine Translation
Mar 10, 2022

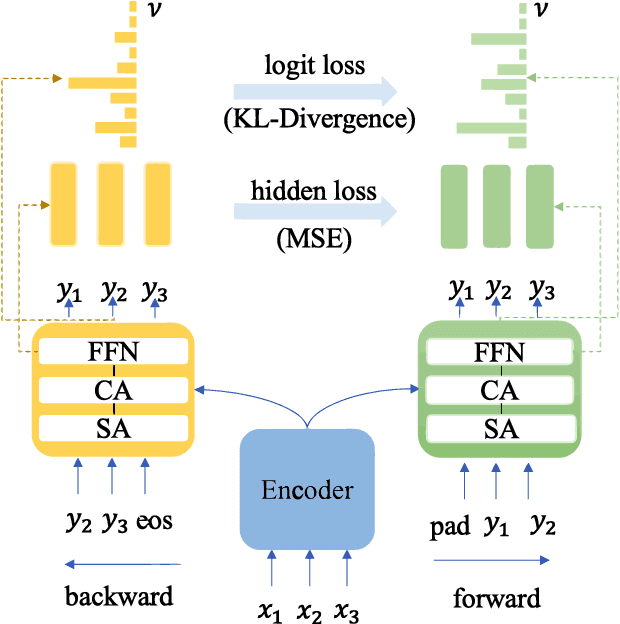
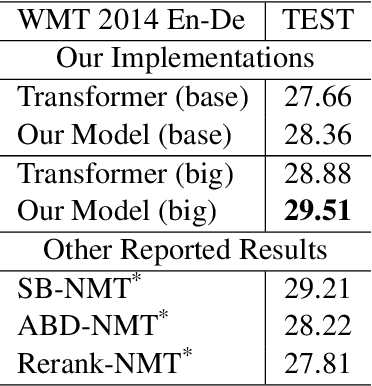
Neural Machine Translation(NMT) models are usually trained via unidirectional decoder which corresponds to optimizing one-step-ahead prediction. However, this kind of unidirectional decoding framework may incline to focus on local structure rather than global coherence. To alleviate this problem, we propose a novel method, Self-Knowledge Distillation with Bidirectional Decoder for Neural Machine Translation(SBD-NMT). We deploy a backward decoder which can act as an effective regularization method to the forward decoder. By leveraging the backward decoder's information about the longer-term future, distilling knowledge learned in the backward decoder can encourage auto-regressive NMT models to plan ahead. Experiments show that our method is significantly better than the strong Transformer baselines on multiple machine translation data sets. Our codes will be released on github soon.
On Mutual Information in Contrastive Learning for Visual Representations
Jun 05, 2020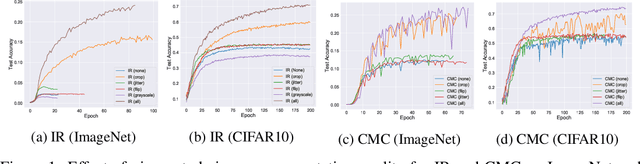
In recent years, several unsupervised, "contrastive" learning algorithms in vision have been shown to learn representations that perform remarkably well on transfer tasks. We show that this family of algorithms maximizes a lower bound on the mutual information between two or more "views" of an image where typical views come from a composition of image augmentations. Our bound generalizes the InfoNCE objective to support negative sampling from a restricted region of "difficult" contrasts. We find that the choice of negative samples and views are critical to the success of these algorithms. Reformulating previous learning objectives in terms of mutual information also simplifies and stabilizes them. In practice, our new objectives yield representations that outperform those learned with previous approaches for transfer to classification, bounding box detection, instance segmentation, and keypoint detection. % experiments show that choosing more difficult negative samples results in a stronger representation, outperforming those learned with IR, LA, and CMC in classification, bounding box detection, instance segmentation, and keypoint detection. The mutual information framework provides a unifying comparison of approaches to contrastive learning and uncovers the choices that impact representation learning.