 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Kernel Method to Nonlinear Location Estimation with RSS-based Fingerprint
Apr 07, 2022
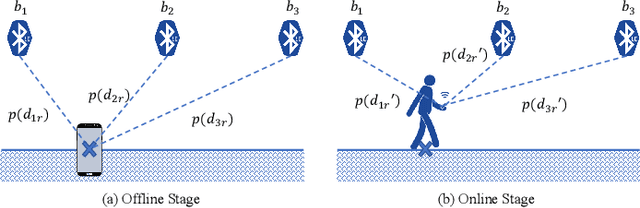
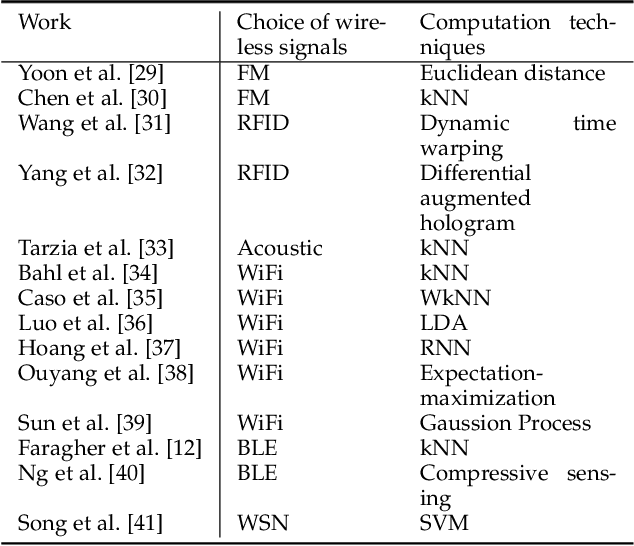

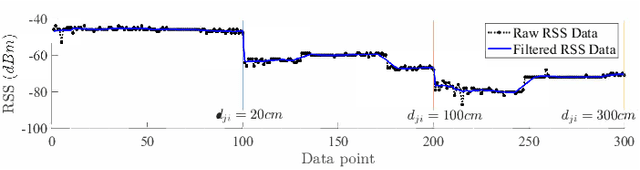
This paper presents a nonlinear location estimation to infer the position of a user holding a smartphone. We consider a large location with $M$ number of grid points, each grid point is labeled with a unique fingerprint consisting of the received signal strength (RSS) values measured from $N$ number of Bluetooth Low Energy (BLE) beacons. Given the fingerprint observed by the smartphone, the user's current location can be estimated by finding the top-k similar fingerprints from the list of fingerprints registered in the database. Besides the environmental factors, the dynamicity in holding the smartphone is another source to the variation in fingerprint measurements, yet there are not many studies addressing the fingerprint variability due to dynamic smartphone positions held by human hands during online detection. To this end, we propose a nonlinear location estimation using the kernel method. Specifically, our proposed method comprises of two steps: 1) a beacon selection strategy to select a subset of beacons that is insensitive to the subtle change of holding positions, and 2) a kernel method to compute the similarity between this subset of observed signals and all the fingerprints registered in the database. The experimental results based on large-scale data collected in a complex building indicate a substantial performance gain of our proposed approach in comparison to state-of-the-art methods. The dataset consisting of the signal information collected from the beacons is available online.
Human Detection of Political Deepfakes across Transcripts, Audio, and Video
Feb 25, 2022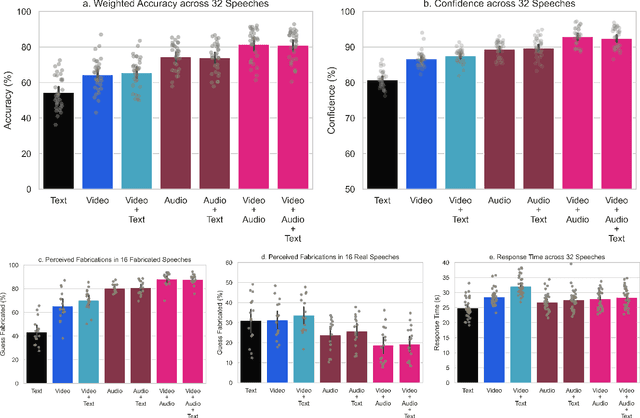

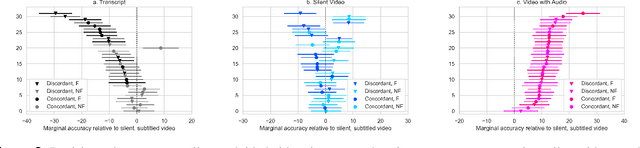
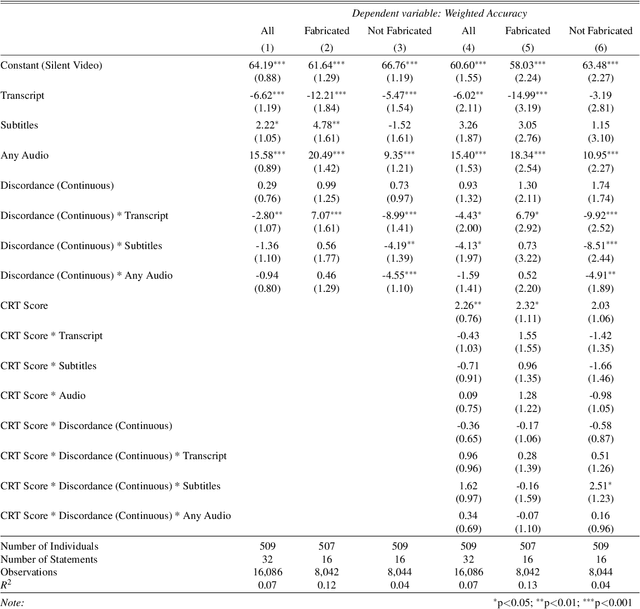
Recent advances in technology for hyper-realistic visual effects provoke the concern that deepfake videos of political speeches will soon be visually indistinguishable from authentic video recordings. Yet there exists little empirical research on how audio-visual information influences people's susceptibility to fall for political misinformation. The conventional wisdom in the field of communication research predicts that people will fall for fake news more often when the same version of a story is presented as a video as opposed to text. However, audio-visual manipulations often leave distortions that some but not all people may pick up on. Here, we evaluate how communication modalities influence people's ability to discern real political speeches from fabrications based on a randomized experiment with 5,727 participants who provide 61,792 truth discernment judgments. We show participants soundbites from political speeches that are randomly assigned to appear using permutations of text, audio, and video modalities. We find that communication modalities mediate discernment accuracy: participants are more accurate on video with audio than silent video, and more accurate on silent video than text transcripts. Likewise, we find participants rely more on how something is said (the audio-visual cues) rather than what is said (the speech content itself). However, political speeches that do not match public perceptions of politicians' beliefs reduce participants' reliance on visual cues. In particular, we find that reflective reasoning moderates the degree to which participants consider visual information: low performance on the Cognitive Reflection Test is associated with an underreliance on visual cues and an overreliance on what is said.
CatIss: An Intelligent Tool for Categorizing Issues Reports using Transformers
Mar 31, 2022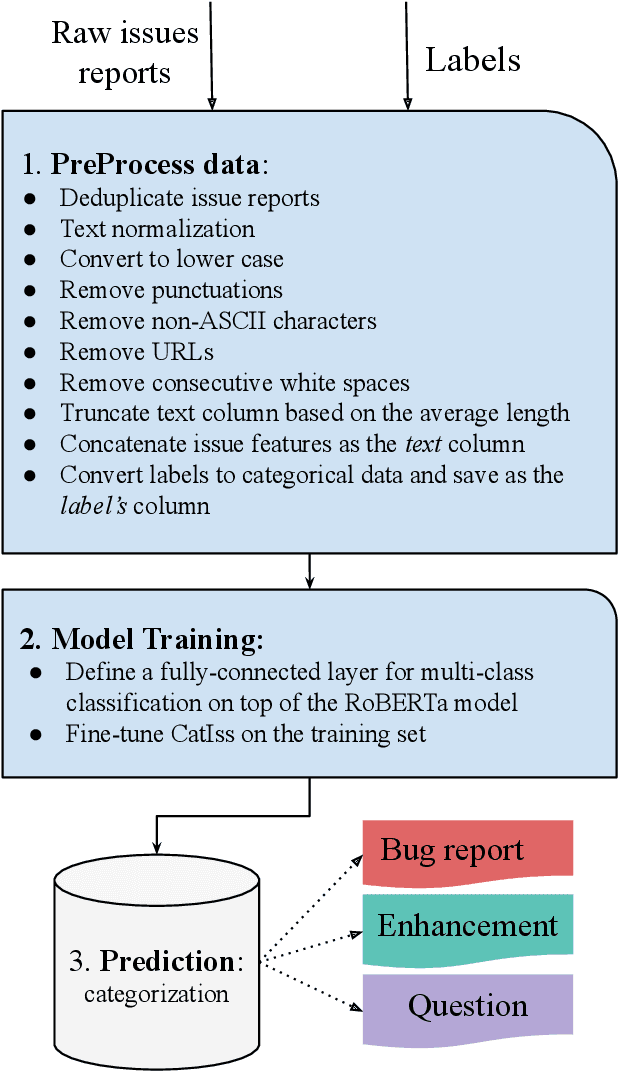
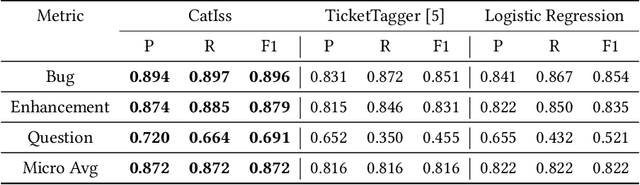
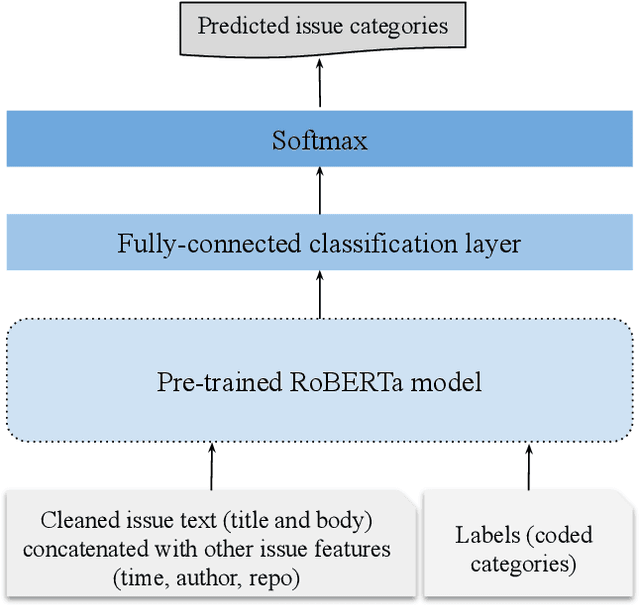
Users use Issue Tracking Systems to keep track and manage issue reports in their repositories. An issue is a rich source of software information that contains different reports including a problem, a request for new features, or merely a question about the software product. As the number of these issues increases, it becomes harder to manage them manually. Thus, automatic approaches are proposed to help facilitate the management of issue reports. This paper describes CatIss, an automatic CATegorizer of ISSue reports which is built upon the Transformer-based pre-trained RoBERTa model. CatIss classifies issue reports into three main categories of Bug reports, Enhancement/feature requests, and Questions. First, the datasets provided for the NLBSE tool competition are cleaned and preprocessed. Then, the pre-trained RoBERTa model is fine-tuned on the preprocessed dataset. Evaluating CatIss on about 80 thousand issue reports from GitHub, indicates that it performs very well surpassing the competition baseline, TicketTagger, and achieving 87.2% F1-score (micro average). Additionally, as CatIss is trained on a wide set of repositories, it is a generic prediction model, hence applicable for any unseen software project or projects with little historical data. Scripts for cleaning the datasets, training CatIss, and evaluating the model are publicly available.
Object-centric and memory-guided normality reconstruction for video anomaly detection
Mar 07, 2022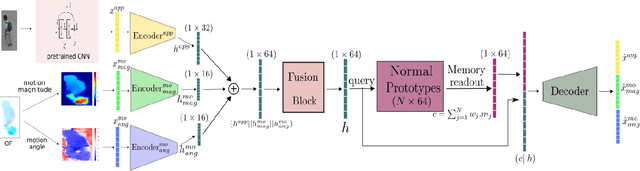
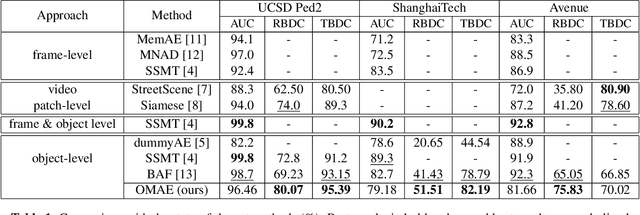
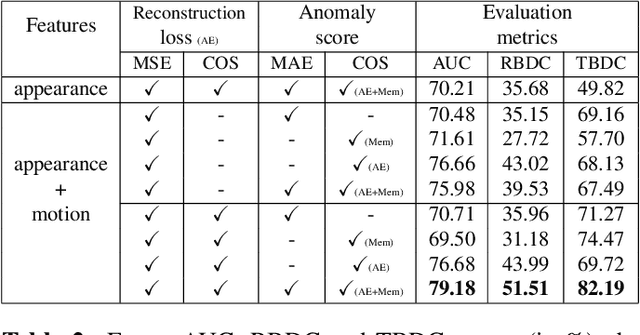
This paper addresses video anomaly detection problem for videosurveillance. Due to the inherent rarity and heterogeneity of abnormal events, the problem is viewed as a normality modeling strategy, in which our model learns object-centric normal patterns without seeing anomalous samples during training. The main contributions consist in coupling pretrained object-level action features prototypes with a cosine distance-based anomaly estimation function, therefore extending previous methods by introducing additional constraints to the mainstream reconstruction-based strategy. Our framework leverages both appearance and motion information to learn object-level behavior and captures prototypical patterns within a memory module. Experiments on several well-known datasets demonstrate the effectiveness of our method as it outperforms current state-of-the-art on most relevant spatio-temporal evaluation metrics.
Mushrooms Detection, Localization and 3D Pose Estimation using RGB-D Sensor for Robotic-picking Applications
Jan 08, 2022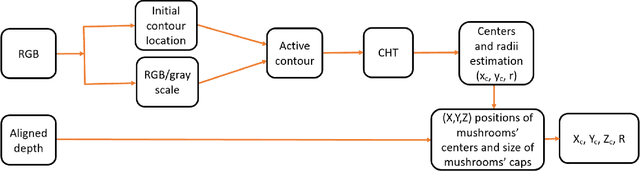
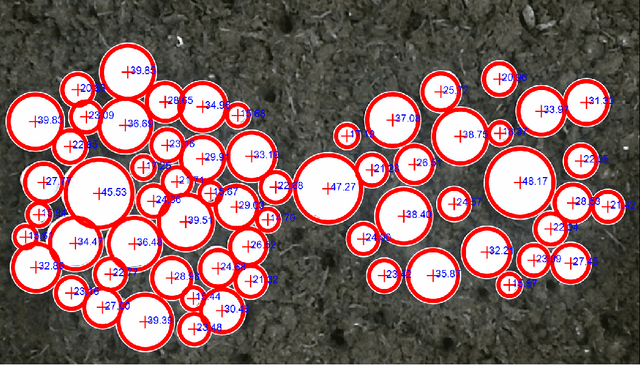
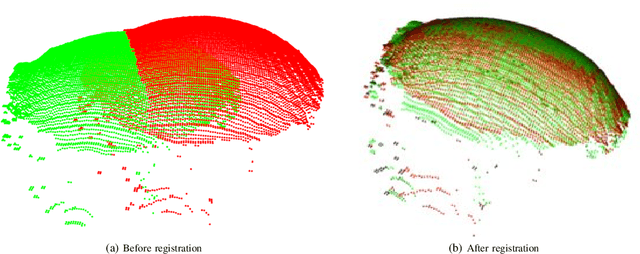

In this paper, we propose mushrooms detection, localization and 3D pose estimation algorithm using RGB-D data acquired from a low-cost consumer RGB-D sensor. We use the RGB and depth information for different purposes. From RGB color, we first extract initial contour locations of the mushrooms and then provide both the initial contour locations and the original image to active contour for mushrooms segmentation. These segmented mushrooms are then used as input to a circular Hough transform for each mushroom detection including its center and radius. Once each mushroom's center position in the RGB image is known, we then use the depth information to locate it in 3D space i.e. in world coordinate system. In case of missing depth information at the detected center of each mushroom, we estimate from the nearest available depth information within the radius of each mushroom. We also estimate the 3D pose of each mushroom using a pre-prepared upright mushroom model. We use a global registration followed by local refine registration approach for this 3D pose estimation. From the estimated 3D pose, we use only the rotation part expressed in quaternion as an orientation of each mushroom. These estimated (X,Y,Z) positions, diameters and orientations of the mushrooms are used for robotic-picking applications. We carry out extensive experiments on both 3D printed and real mushrooms which show that our method has an interesting performance.
Guided Semi-Supervised Non-negative Matrix Factorization on Legal Documents
Jan 31, 2022
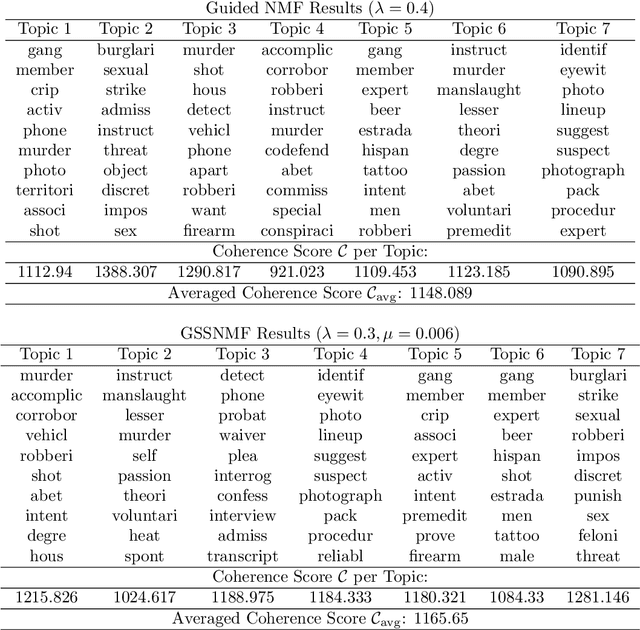
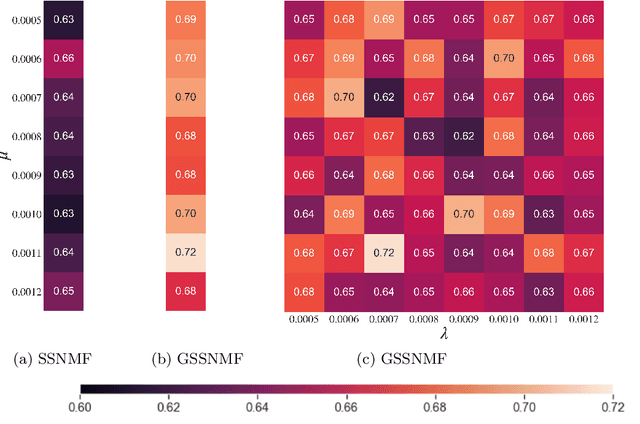
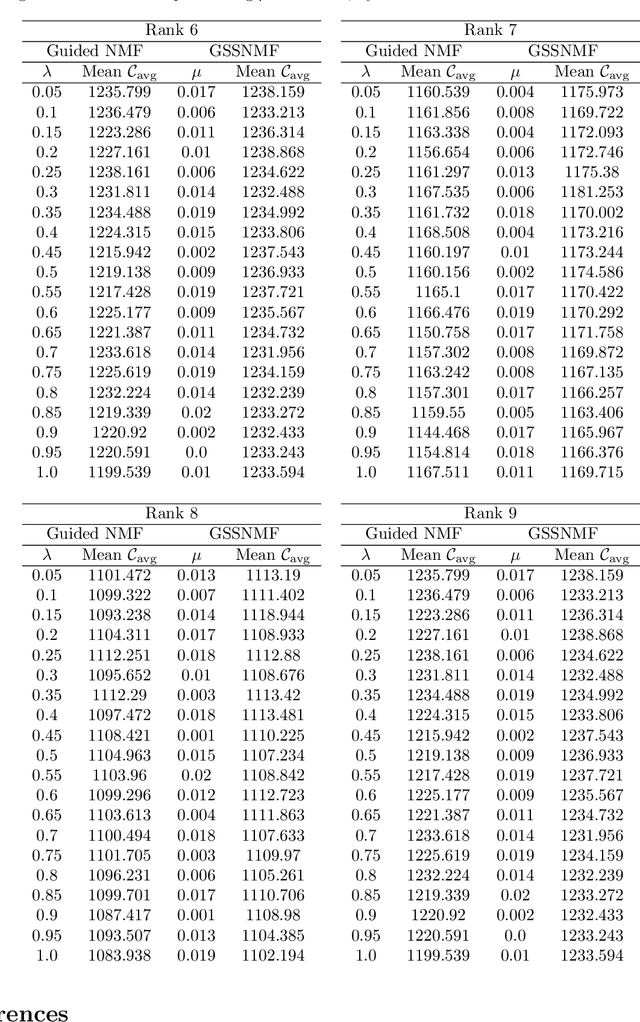
Classification and topic modeling are popular techniques in machine learning that extract information from large-scale datasets. By incorporating a priori information such as labels or important features, methods have been developed to perform classification and topic modeling tasks; however, most methods that can perform both do not allow for guidance of the topics or features. In this paper, we propose a method, namely Guided Semi-Supervised Non-negative Matrix Factorization (GSSNMF), that performs both classification and topic modeling by incorporating supervision from both pre-assigned document class labels and user-designed seed words. We test the performance of this method through its application to legal documents provided by the California Innocence Project, a nonprofit that works to free innocent convicted persons and reform the justice system. The results show that our proposed method improves both classification accuracy and topic coherence in comparison to past methods like Semi-Supervised Non-negative Matrix Factorization (SSNMF) and Guided Non-negative Matrix Factorization (Guided NMF).
Error Correction Code Transformer
Mar 27, 2022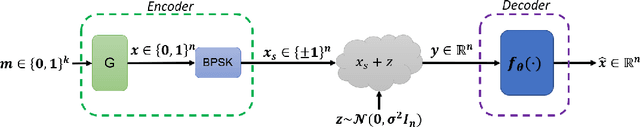
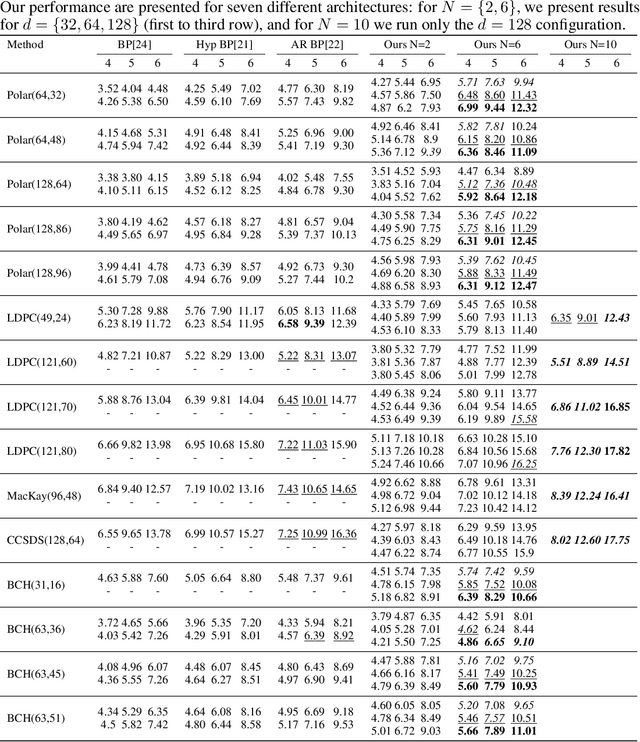

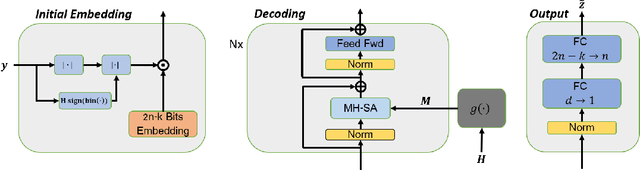
Error correction code is a major part of the communication physical layer, ensuring the reliable transfer of data over noisy channels. Recently, neural decoders were shown to outperform classical decoding techniques. However, the existing neural approaches present strong overfitting due to the exponential training complexity, or a restrictive inductive bias due to reliance on Belief Propagation. Recently, Transformers have become methods of choice in many applications thanks to their ability to represent complex interactions between elements. In this work, we propose to extend for the first time the Transformer architecture to the soft decoding of linear codes at arbitrary block lengths. We encode each channel's output dimension to high dimension for better representation of the bits information to be processed separately. The element-wise processing allows the analysis of the channel output reliability, while the algebraic code and the interaction between the bits are inserted into the model via an adapted masked self-attention module. The proposed approach demonstrates the extreme power and flexibility of Transformers and outperforms existing state-of-the-art neural decoders by large margins at a fraction of their time complexity.
Profile Guided Optimization without Profiles: A Machine Learning Approach
Jan 04, 2022

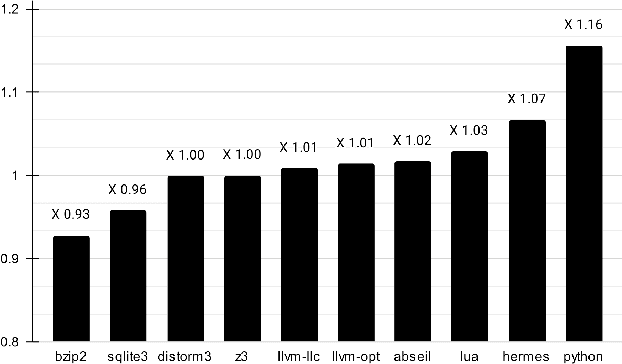
Profile guided optimization is an effective technique for improving the optimization ability of compilers based on dynamic behavior, but collecting profile data is expensive, cumbersome, and requires regular updating to remain fresh. We present a novel statistical approach to inferring branch probabilities that improves the performance of programs that are compiled without profile guided optimizations. We perform offline training using information that is collected from a large corpus of binaries that have branch probabilities information. The learned model is used by the compiler to predict the branch probabilities of regular uninstrumented programs, which the compiler can then use to inform optimization decisions. We integrate our technique directly in LLVM, supplementing the existing human-engineered compiler heuristics. We evaluate our technique on a suite of benchmarks, demonstrating some gains over compiling without profile information. In deployment, our technique requires no profiling runs and has negligible effect on compilation time.
Localized Feature Aggregation Module for Semantic Segmentation
Dec 03, 2021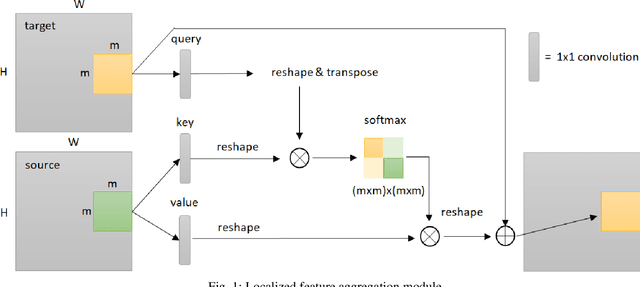
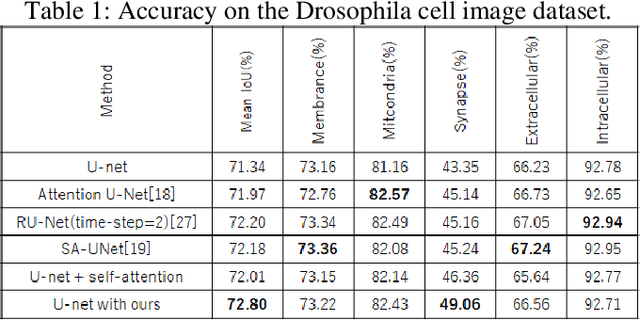
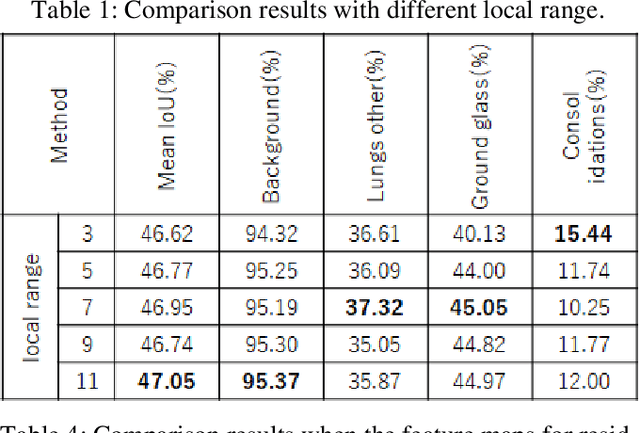
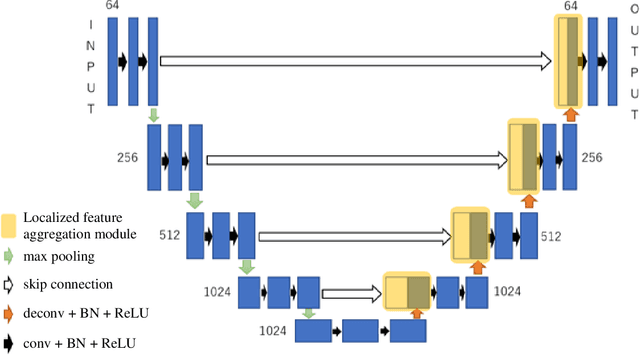
We propose a new information aggregation method which called Localized Feature Aggregation Module based on the similarity between the feature maps of an encoder and a decoder. The proposed method recovers positional information by emphasizing the similarity between decoder's feature maps with superior semantic information and encoder's feature maps with superior positional information. The proposed method can learn positional information more efficiently than conventional concatenation in the U-net and attention U-net. Additionally, the proposed method also uses localized attention range to reduce the computational cost. Two innovations contributed to improve the segmentation accuracy with lower computational cost. By experiments on the Drosophila cell image dataset and COVID-19 image dataset, we confirmed that our method outperformed conventional methods.
OPAL: Occlusion Pattern Aware Loss for Unsupervised Light Field Disparity Estimation
Mar 31, 2022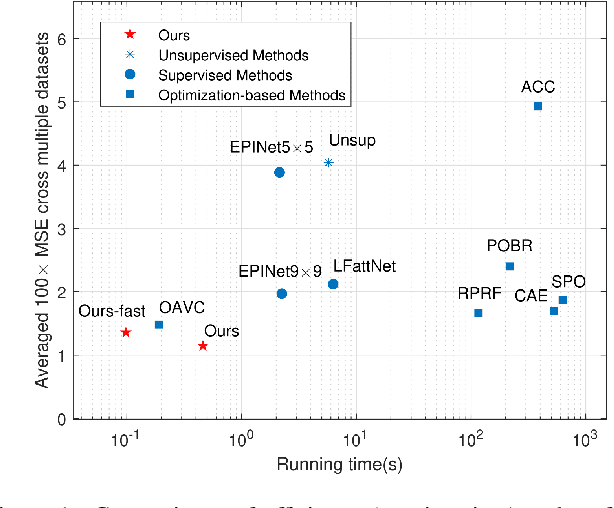
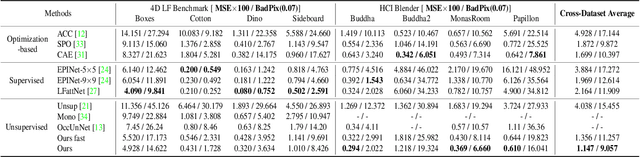
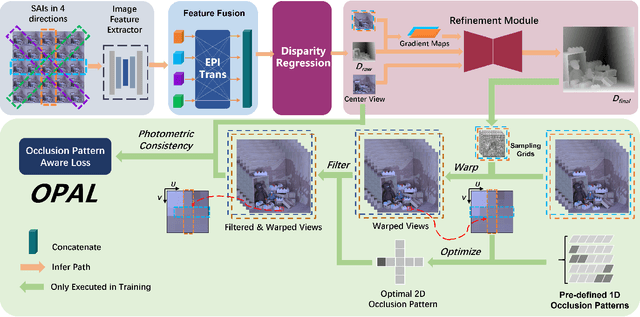
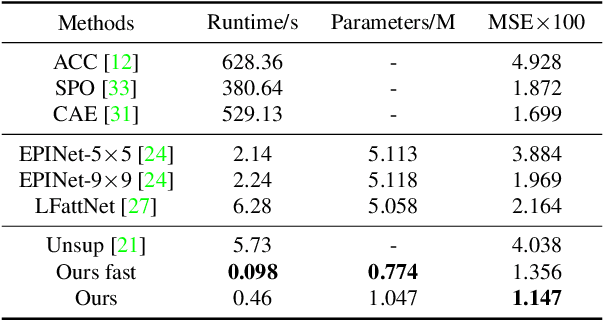
Light field disparity estimation is an essential task in computer vision with various applications. Although supervised learning-based methods have achieved both higher accuracy and efficiency than traditional optimization-based methods, the dependency on ground-truth disparity for training limits the overall generalization performance not to say for real-world scenarios where the ground-truth disparity is hard to capture. In this paper, we argue that unsupervised methods can achieve comparable accuracy, but, more importantly, much higher generalization capacity and efficiency than supervised methods. Specifically, we present the Occlusion Pattern Aware Loss, named OPAL, which successfully extracts and encodes the general occlusion patterns inherent in the light field for loss calculation. OPAL enables: i) accurate and robust estimation by effectively handling occlusions without using any ground-truth information for training and ii) much efficient performance by significantly reducing the network parameters required for accurate inference. Besides, a transformer-based network and a refinement module are proposed for achieving even more accurate results. Extensive experiments demonstrate our method not only significantly improves the accuracy compared with the SOTA unsupervised methods, but also possesses strong generalization capacity, even for real-world data, compared with supervised methods. Our code will be made publicly available.