 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Topic-Aware Encoding for Extractive Summarization
Dec 17, 2021

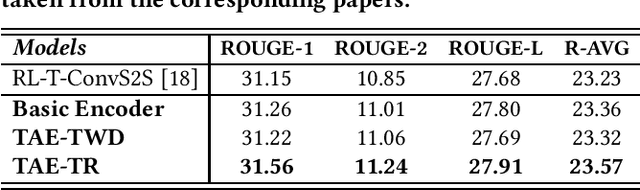
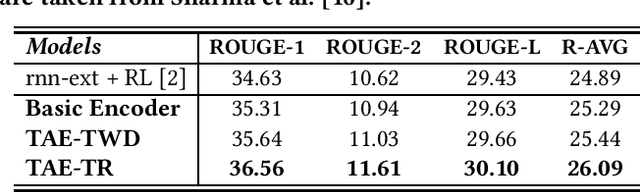
Document summarization provides an instrument for faster understanding the collection of text documents and has several real-life applications. With the growth of online text data, numerous summarization models have been proposed recently. The Sequence-to-Sequence (Seq2Seq) based neural summarization model is the most widely used in the summarization field due to its high performance. This is because semantic information and structure information in the text is adequately considered when encoding. However, the existing extractive summarization models pay little attention to and use the central topic information to assist the generation of summaries, which leads to models not ensuring the generated summary under the primary topic. A lengthy document can span several topics, and a single summary cannot do justice to all the topics. Therefore, the key to generating a high-quality summary is determining the central topic and building a summary based on it, especially for a long document. We propose a topic-aware encoding for document summarization to deal with this issue. This model effectively combines syntactic-level and topic-level information to build a comprehensive sentence representation. Specifically, a neural topic model is added in the neural-based sentence-level representation learning to adequately consider the central topic information for capturing the critical content in the original document. The experimental results on three public datasets show that our model outperforms the state-of-the-art models.
3D Multi-Object Tracking Using Graph Neural Networks with Cross-Edge Modality Attention
Mar 21, 2022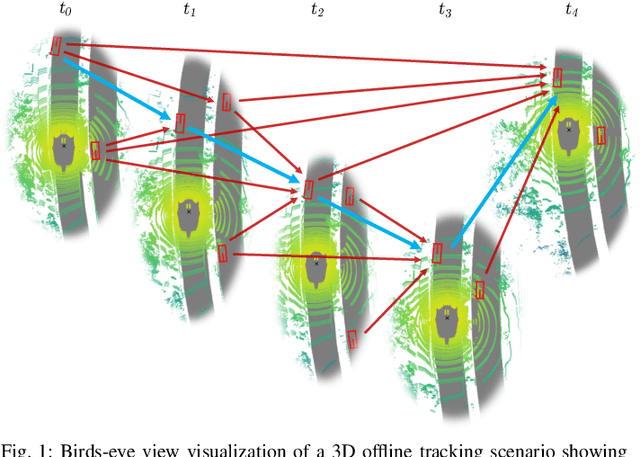
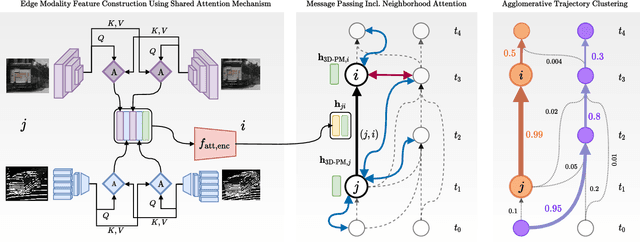
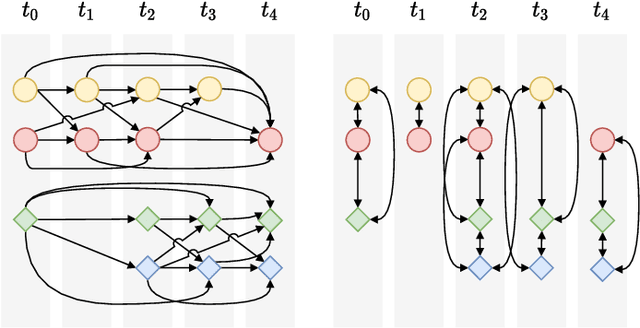
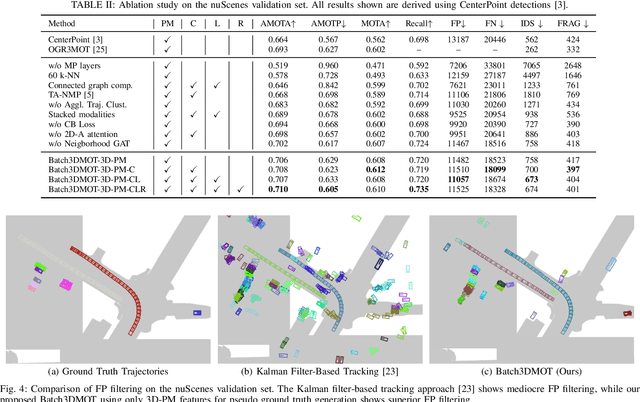
Online 3D multi-object tracking (MOT) has witnessed significant research interest in recent years, largely driven by demand from the autonomous systems community. However, 3D offline MOT is relatively less explored. Labeling 3D trajectory scene data at a large scale while not relying on high-cost human experts is still an open research question. In this work, we propose Batch3DMOT that follows the tracking-by-detection paradigm and represents real-world scenes as directed, acyclic, and category-disjoint tracking graphs that are attributed using various modalities such as camera, LiDAR, and radar. We present a multi-modal graph neural network that uses a cross-edge attention mechanism mitigating modality intermittence, which translates into sparsity in the graph domain. Additionally, we present attention-weighted convolutions over frame-wise k-NN neighborhoods as suitable means to allow information exchange across disconnected graph components. We evaluate our approach using various sensor modalities and model configurations on the challenging nuScenes and KITTI datasets. Extensive experiments demonstrate that our proposed approach yields an overall improvement of 2.8% in the AMOTA score on nuScenes thereby setting a new benchmark for 3D tracking methods and successfully enhances false positive filtering.
Abstractive Information Extraction from Scanned Invoices (AIESI) using End-to-end Sequential Approach
Sep 12, 2020


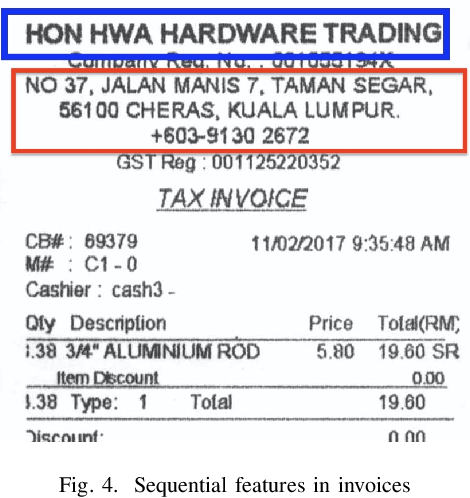
Recent proliferation in the field of Machine Learning and Deep Learning allows us to generate OCR models with higher accuracy. Optical Character Recognition(OCR) is the process of extracting text from documents and scanned images. For document data streamlining, we are interested in data like, Payee name, total amount, address, and etc. Extracted information helps to get complete insight of data, which can be helpful for fast document searching, efficient indexing in databases, data analytics, and etc. Using AIESI we can eliminate human effort for key parameters extraction from scanned documents. Abstract Information Extraction from Scanned Invoices (AIESI) is a process of extracting information like, date, total amount, payee name, and etc from scanned receipts. In this paper we proposed an improved method to ensemble all visual and textual features from invoices to extract key invoice parameters using Word wise BiLSTM.
VisualWordGrid: Information Extraction From Scanned Documents Using A Multimodal Approach
Oct 13, 2020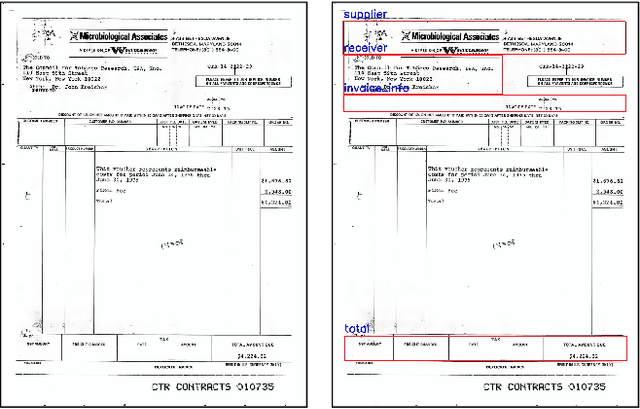

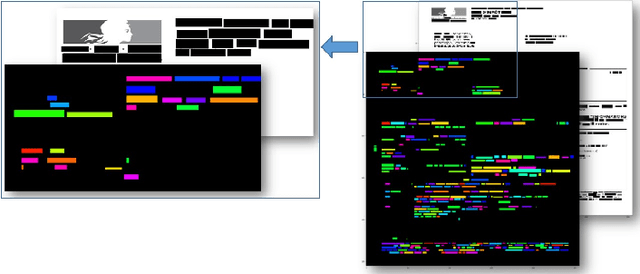
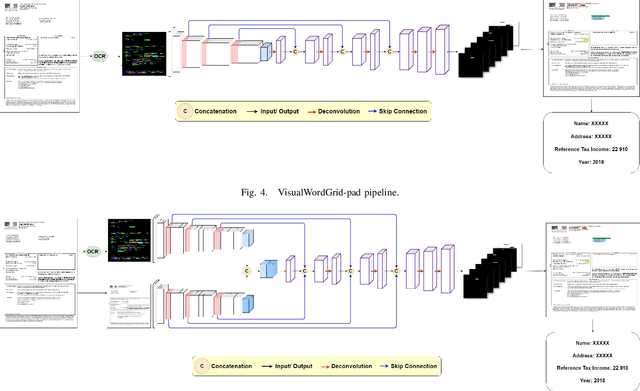
We introduce a novel approach for scanned document representation to perform field extraction. It allows the simultaneous encoding of the textual, visual and layout information in a 3D matrix used as an input to a segmentation model. We improve the recent Chargrid and Wordgrid models in several ways, first by taking into account the visual modality, then by boosting its robustness in regards to small datasets while keeping the inference time low. Our approach is tested on public and private document-image datasets, showing higher performances compared to the recent state-of-the-art methods.
Speech watermarking: an approach for the forensic analysis of digital telephonic recordings
Mar 12, 2022
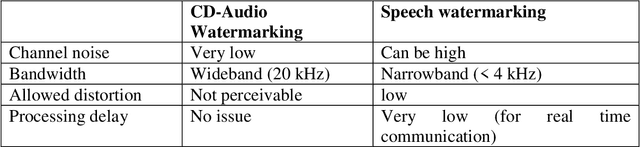
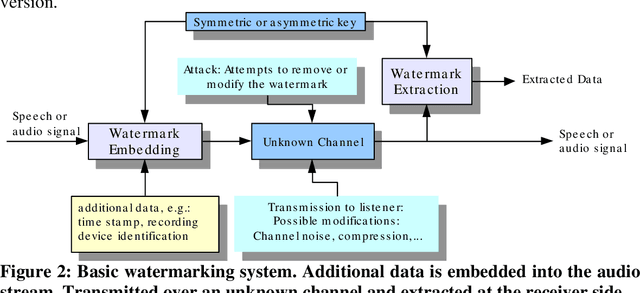
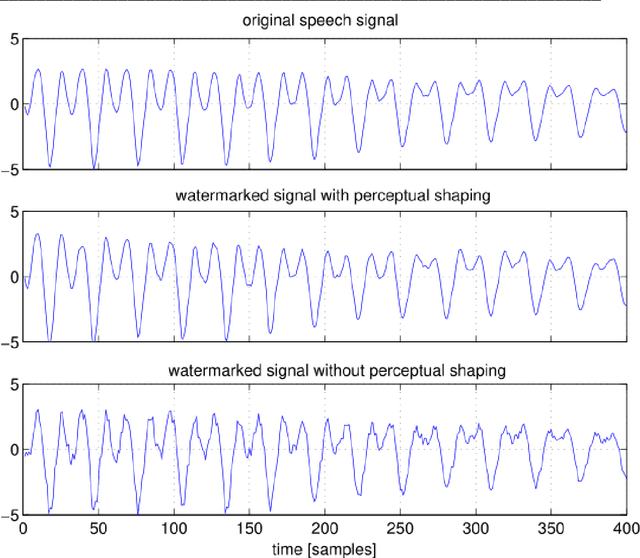
In this article, the authors discuss the problem of forensic authentication of digital audio recordings. Although forensic audio has been addressed in several articles, the existing approaches are focused on analog magnetic recordings, which are less prevalent because of the large amount of digital recorders available on the market (optical, solid state, hard disks, etc.). An approach based on digital signal processing that consists of spread spectrum techniques for speech watermarking is presented. This approach presents the advantage that the authentication is based on the signal itself rather than the recording format. Thus, it is valid for usual recording devices in police-controlled telephone intercepts. In addition, our proposal allows for the introduction of relevant information such as the recording date and time and all the relevant data (this is not always possible with classical systems). Our experimental results reveal that the speech watermarking procedure does not interfere in a significant way with the posterior forensic speaker identification.
* 15 pages
Hierarchical Intention Tracking for Robust Human-Robot Collaboration in Industrial Assembly Tasks
Mar 17, 2022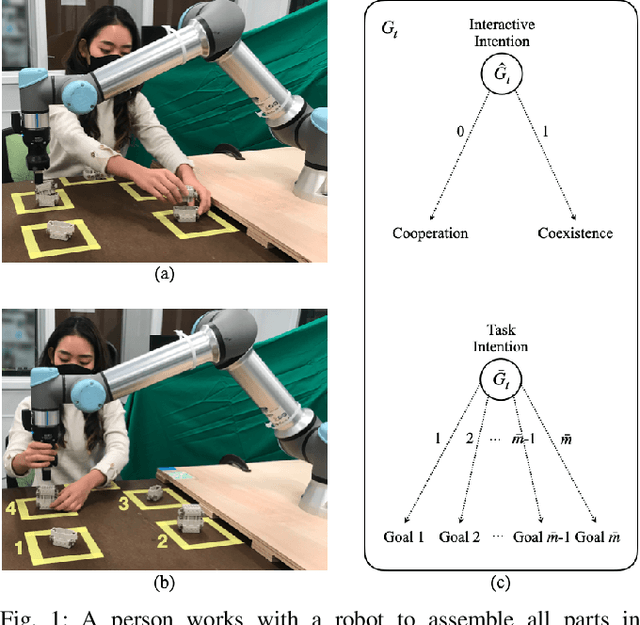
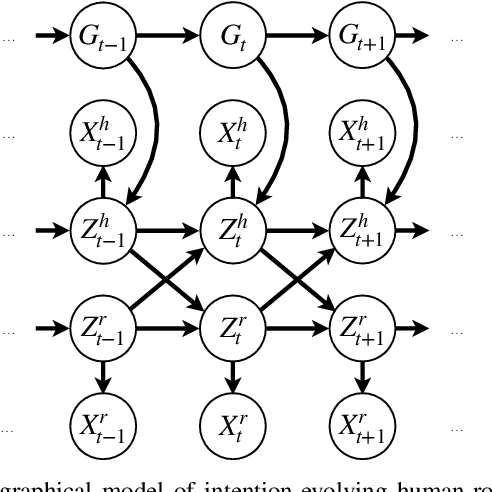
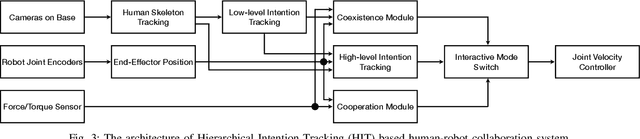

Collaborative robots require effective intention estimation to safely and smoothly work with humans in less structured tasks such as industrial assembly. During these tasks, human intention continuously changes across multiple steps, and is composed of a hierarchy including high-level interactive intention and low-level task intention. Thus, we propose the concept of intention tracking and introduce a collaborative robot system with a hierarchical framework that concurrently tracks intentions at both levels by observing force/torque measurements, robot state sequences, and tracked human trajectories. The high-level intention estimate enables the robot to both (1) safely avoid collision with the human to minimize interruption and (2) cooperatively approach the human and help recover from an assembly failure through admittance control. The low-level intention estimate provides the robot with task-specific information (e.g., which part the human is working on) for concurrent task execution. We implement the system on a UR5e robot, and demonstrate robust, seamless and ergonomic collaboration between the human and the robot in an assembly use case through an ablative pilot study.
Revisiting Domain Generalized Stereo Matching Networks from a Feature Consistency Perspective
Mar 21, 2022
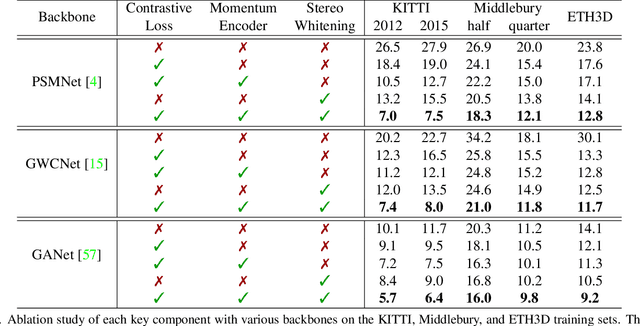
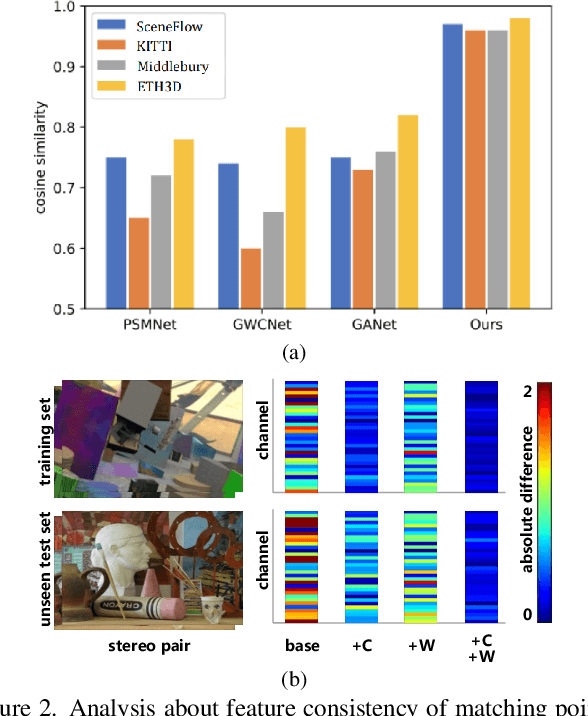

Despite recent stereo matching networks achieving impressive performance given sufficient training data, they suffer from domain shifts and generalize poorly to unseen domains. We argue that maintaining feature consistency between matching pixels is a vital factor for promoting the generalization capability of stereo matching networks, which has not been adequately considered. Here we address this issue by proposing a simple pixel-wise contrastive learning across the viewpoints. The stereo contrastive feature loss function explicitly constrains the consistency between learned features of matching pixel pairs which are observations of the same 3D points. A stereo selective whitening loss is further introduced to better preserve the stereo feature consistency across domains, which decorrelates stereo features from stereo viewpoint-specific style information. Counter-intuitively, the generalization of feature consistency between two viewpoints in the same scene translates to the generalization of stereo matching performance to unseen domains. Our method is generic in nature as it can be easily embedded into existing stereo networks and does not require access to the samples in the target domain. When trained on synthetic data and generalized to four real-world testing sets, our method achieves superior performance over several state-of-the-art networks.
Zoom Out and Observe: News Environment Perception for Fake News Detection
Mar 21, 2022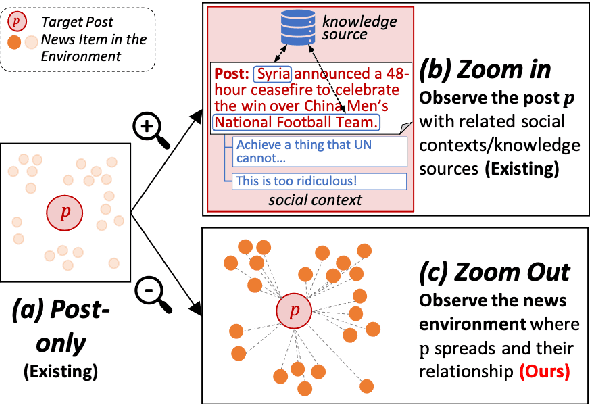
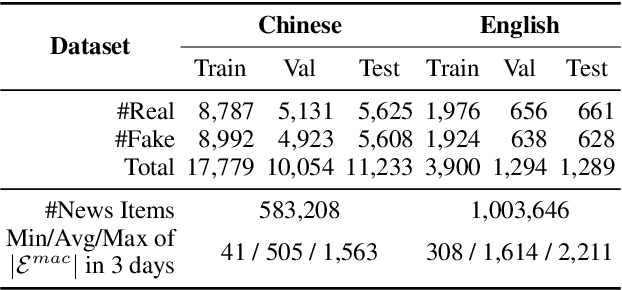
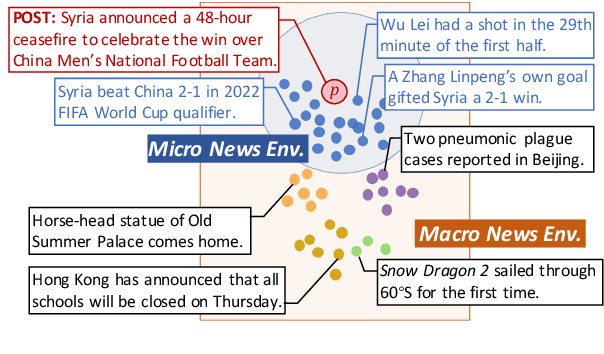
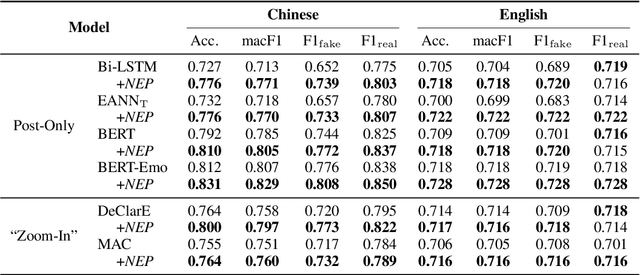
Fake news detection is crucial for preventing the dissemination of misinformation on social media. To differentiate fake news from real ones, existing methods observe the language patterns of the news post and "zoom in" to verify its content with knowledge sources or check its readers' replies. However, these methods neglect the information in the external news environment where a fake news post is created and disseminated. The news environment represents recent mainstream media opinion and public attention, which is an important inspiration of fake news fabrication because fake news is often designed to ride the wave of popular events and catch public attention with unexpected novel content for greater exposure and spread. To capture the environmental signals of news posts, we "zoom out" to observe the news environment and propose the News Environment Perception Framework (NEP). For each post, we construct its macro and micro news environment from recent mainstream news. Then we design a popularity-oriented and a novelty-oriented module to perceive useful signals and further assist final prediction. Experiments on our newly built datasets show that the NEP can efficiently improve the performance of basic fake news detectors.
Benchmarking Deep AUROC Optimization: Loss Functions and Algorithmic Choices
Mar 29, 2022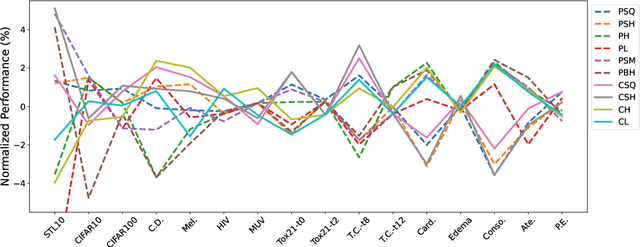
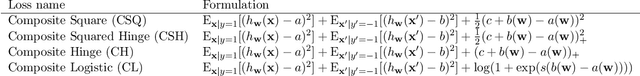
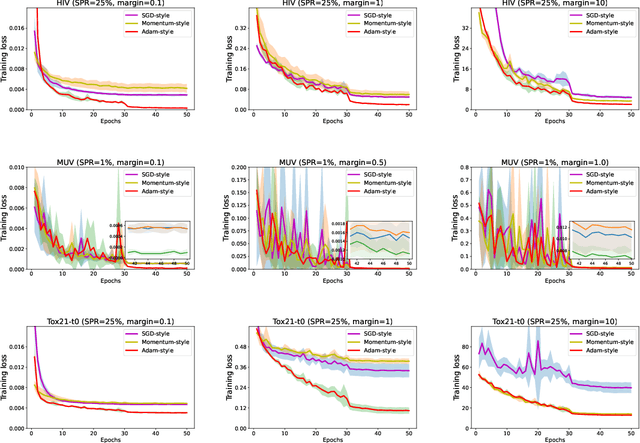
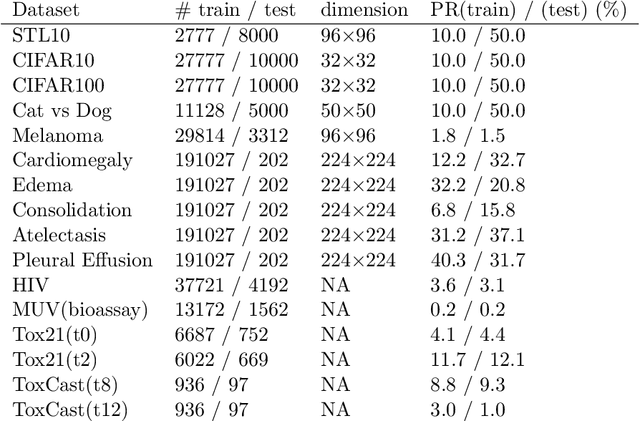
The area under the ROC curve (AUROC) has been vigorously applied for imbalanced classification and moreover combined with deep learning techniques. However, there is no existing work that provides sound information for peers to choose appropriate deep AUROC maximization techniques. In this work, we fill this gap from three aspects. (i) We benchmark a variety of loss functions with different algorithmic choices for deep AUROC optimization problem. We study the loss functions in two categories: pairwise loss and composite loss, which includes a total of 10 loss functions. Interestingly, we find composite loss, as an innovative loss function class, shows more competitive performance than pairwise loss from both training convergence and testing generalization perspectives. Nevertheless, data with more corrupted labels favors a pairwise symmetric loss. (ii) Moreover, we benchmark and highlight the essential algorithmic choices such as positive sampling rate, regularization, normalization/activation, and optimizers. Key findings include: higher positive sampling rate is likely to be beneficial for deep AUROC maximization; different datasets favors different weights of regularizations; appropriate normalization techniques, such as sigmoid and $\ell_2$ score normalization, could improve model performance. (iii) For optimization aspect, we benchmark SGD-type, Momentum-type, and Adam-type optimizers for both pairwise and composite loss. Our findings show that although Adam-type method is more competitive from training perspective, but it does not outperform others from testing perspective.
Deep Temporal Interpolation of Radar-based Precipitation
Mar 01, 2022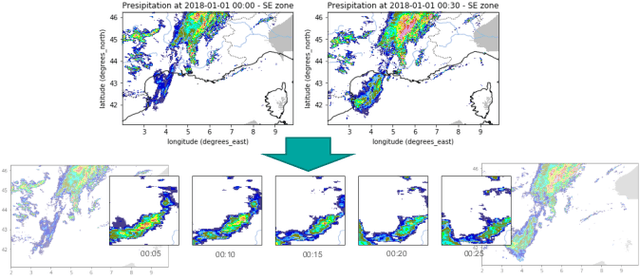
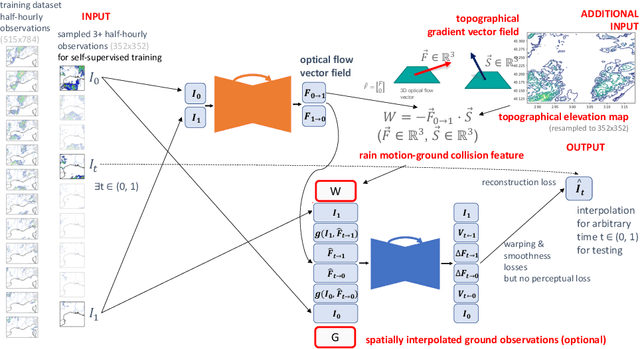
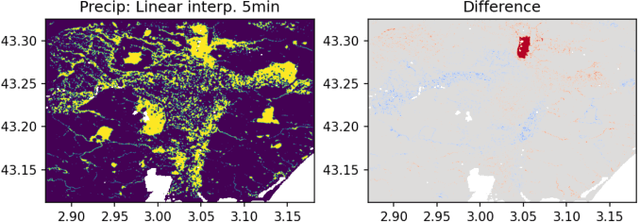
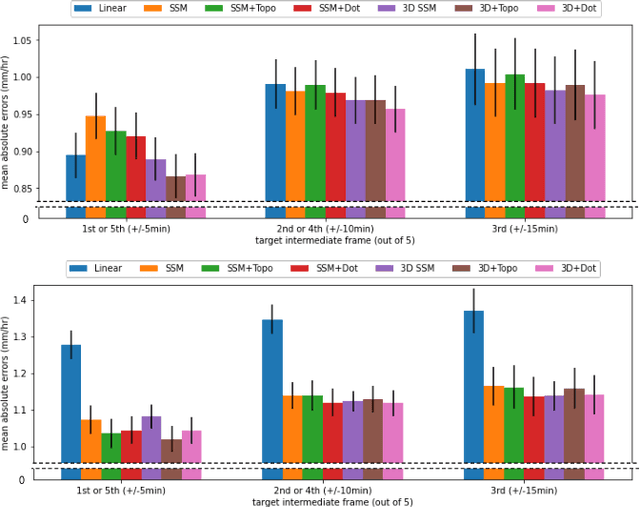
When providing the boundary conditions for hydrological flood models and estimating the associated risk, interpolating precipitation at very high temporal resolutions (e.g. 5 minutes) is essential not to miss the cause of flooding in local regions. In this paper, we study optical flow-based interpolation of globally available weather radar images from satellites. The proposed approach uses deep neural networks for the interpolation of multiple video frames, while terrain information is combined with temporarily coarse-grained precipitation radar observation as inputs for self-supervised training. An experiment with the Meteonet radar precipitation dataset for the flood risk simulation in Aude, a department in Southern France (2018), demonstrated the advantage of the proposed method over a linear interpolation baseline, with up to 20% error reduction.