 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Exploration of Active Learning for Affective Digital Phenotyping
Apr 06, 2022

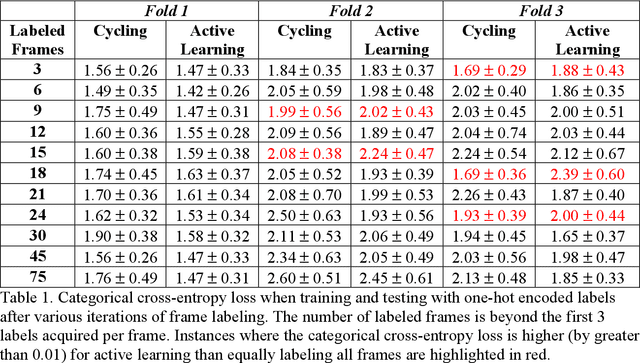
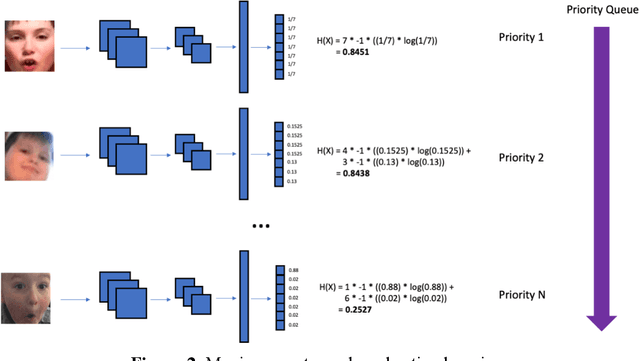
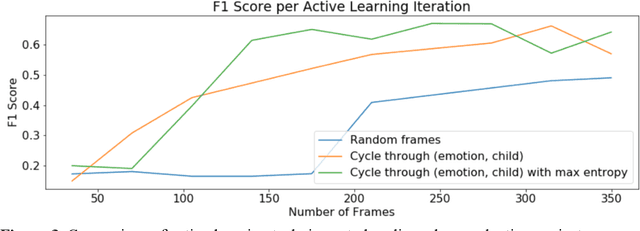
Some of the most severe bottlenecks preventing widespread development of machine learning models for human behavior include a dearth of labeled training data and difficulty of acquiring high quality labels. Active learning is a paradigm for using algorithms to computationally select a useful subset of data points to label using metrics for model uncertainty and data similarity. We explore active learning for naturalistic computer vision emotion data, a particularly heterogeneous and complex data space due to inherently subjective labels. Using frames collected from gameplay acquired from a therapeutic smartphone game for children with autism, we run a simulation of active learning using gameplay prompts as metadata to aid in the active learning process. We find that active learning using information generated during gameplay slightly outperforms random selection of the same number of labeled frames. We next investigate a method to conduct active learning with subjective data, such as in affective computing, and where multiple crowdsourced labels can be acquired for each image. Using the Child Affective Facial Expression (CAFE) dataset, we simulate an active learning process for crowdsourcing many labels and find that prioritizing frames using the entropy of the crowdsourced label distribution results in lower categorical cross-entropy loss compared to random frame selection. Collectively, these results demonstrate pilot evaluations of two novel active learning approaches for subjective affective data collected in noisy settings.
SepViT: Separable Vision Transformer
Apr 03, 2022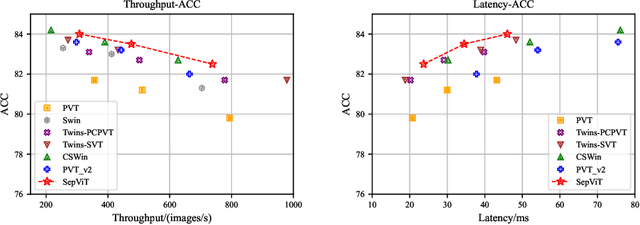

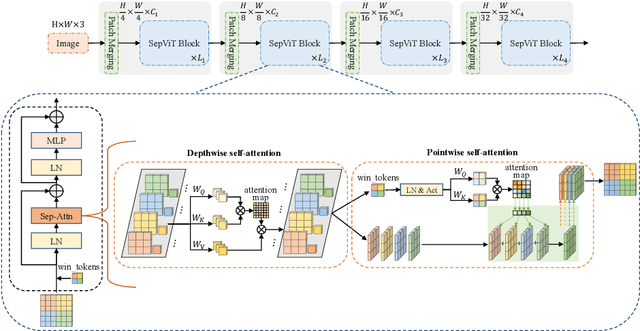
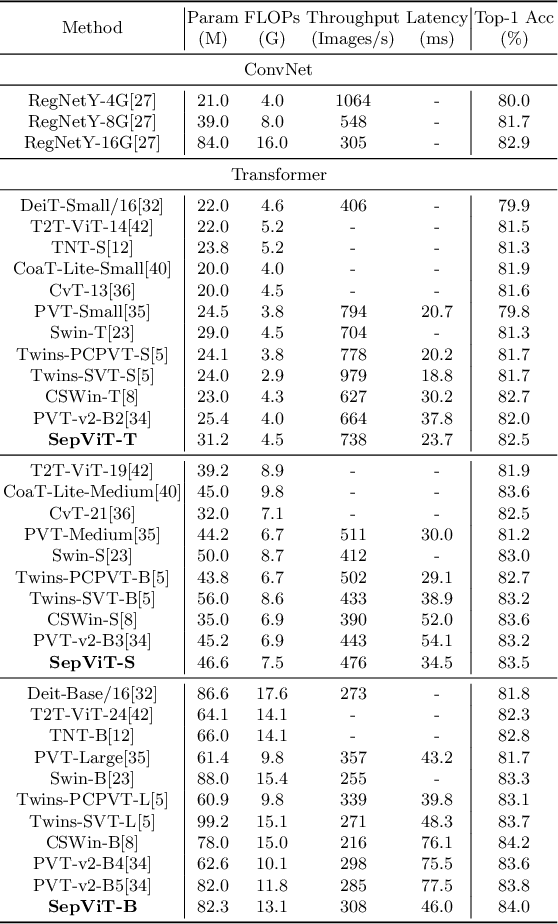
Vision Transformers have witnessed prevailing success in a series of vision tasks. However, they often require enormous amount of computations to achieve high performance, which is burdensome to deploy on resource-constrained devices. To address these issues, we draw lessons from depthwise separable convolution and imitate its ideology to design the Separable Vision Transformer, abbreviated as SepViT. SepViT helps to carry out the information interaction within and among the windows via a depthwise separable self-attention. The novel window token embedding and grouped self-attention are employed to model the attention relationship among windows with negligible computational cost and capture a long-range visual dependencies of multiple windows, respectively. Extensive experiments on various benchmark tasks demonstrate SepViT can achieve state-of-the-art results in terms of trade-off between accuracy and latency. Among them, SepViT achieves 84.0% top-1 accuracy on ImageNet-1K classification while decreasing the latency by 40%, compared to the ones with similar accuracy (e.g., CSWin, PVTV2). As for the downstream vision tasks, SepViT with fewer FLOPs can achieve 50.4% mIoU on ADE20K semantic segmentation task, 47.5 AP on the RetinaNet-based COCO detection task, 48.7 box AP and 43.9 mask AP on Mask R-CNN-based COCO detection and segmentation tasks.
Optimal quantum kernels for small data classification
Mar 25, 2022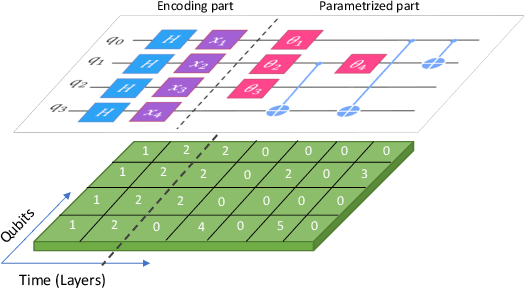
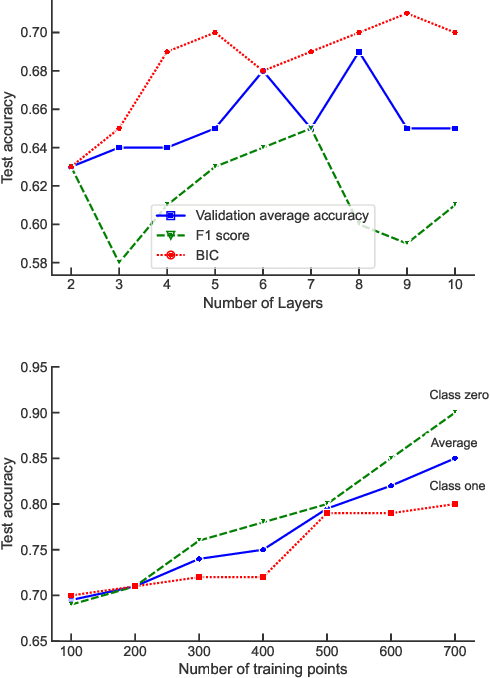
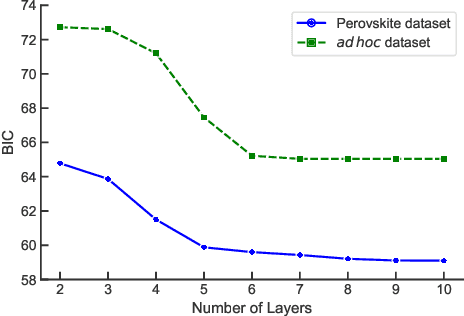
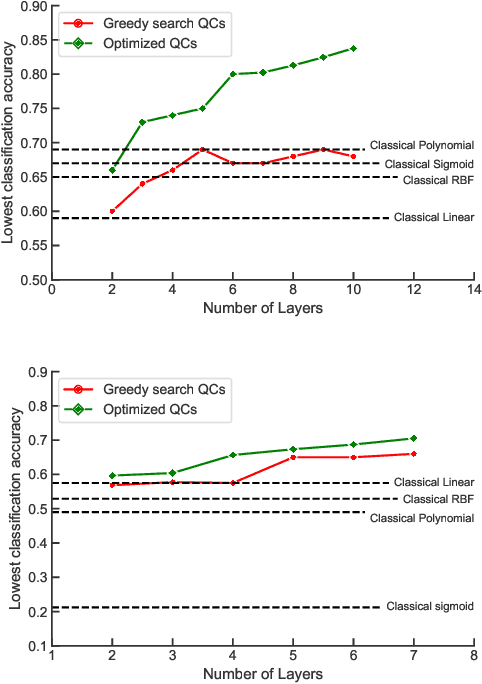
While quantum machine learning (ML) has been proposed to be one of the most promising applications of quantum computing, how to build quantum ML models that outperform classical ML remains a major open question. Here, we demonstrate an algorithm for constructing quantum kernels for support vector machines that adapts quantum gate sequences to data. The algorithm includes three essential ingredients: greedy search in the space of quantum circuits, Bayesian information criterion as circuit selection metric and Bayesian optimization of the parameters of the optimal quantum circuit identified. The performance of the resulting quantum models for classification problems with a small number of training points significantly exceeds that of optimized classical models with conventional kernels. In addition, we illustrate the possibility of mapping quantum circuits onto molecular fingerprints and show that performant quantum kernels can be isolated in the resulting chemical space. This suggests that methods developed for optimization and interpolation of molecular properties across chemical spaces can be used for building quantum circuits for quantum machine learning with enhanced performance.
Fourier Disentangled Space-Time Attention for Aerial Video Recognition
Mar 21, 2022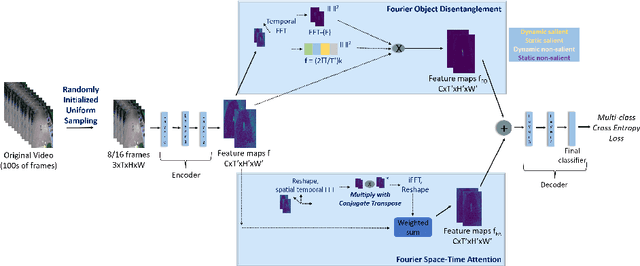


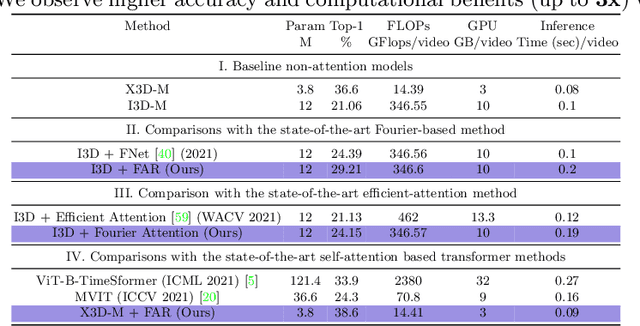
We present an algorithm, Fourier Activity Recognition (FAR), for UAV video activity recognition. Our formulation uses a novel Fourier object disentanglement method to innately separate out the human agent (which is typically small) from the background. Our disentanglement technique operates in the frequency domain to characterize the extent of temporal change of spatial pixels, and exploits convolution-multiplication properties of Fourier transform to map this representation to the corresponding object-background entangled features obtained from the network. To encapsulate contextual information and long-range space-time dependencies, we present a novel Fourier Attention algorithm, which emulates the benefits of self-attention by modeling the weighted outer product in the frequency domain. Our Fourier attention formulation uses much fewer computations than self-attention. We have evaluated our approach on multiple UAV datasets including UAV Human RGB, UAV Human Night, Drone Action, and NEC Drone. We demonstrate a relative improvement of 8.02% - 38.69% in top-1 accuracy and up to 3 times faster over prior works.
Generalizing Information to the Evolution of Rational Belief
Nov 21, 2019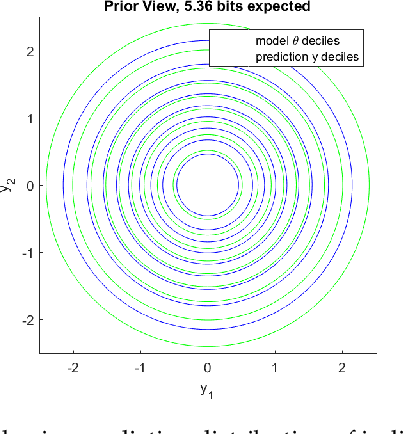
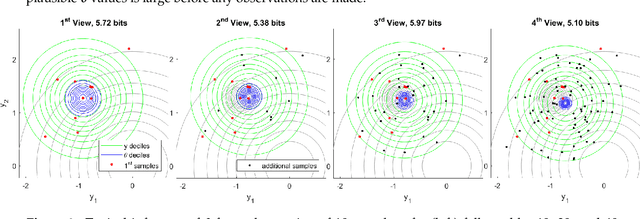
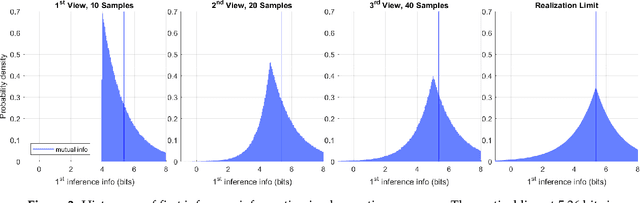
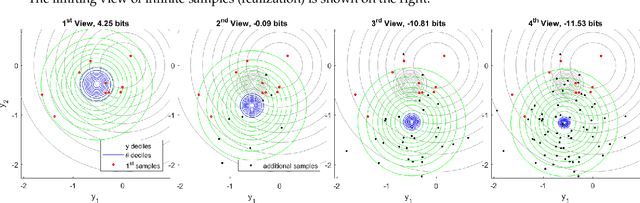
Information theory provides a mathematical foundation to measure uncertainty in belief. Belief is represented by a probability distribution that captures our understanding of an outcome's plausibility. Information measures based on Shannon's concept of entropy include realization information, Kullback-Leibler divergence, Lindley's information in experiment, cross entropy, and mutual information. We derive a general theory of information from first principles that accounts for evolving belief and recovers all of these measures. Rather than simply gauging uncertainty, information is understood in this theory to measure change in belief. We may then regard entropy as the information we expect to gain upon realization of a discrete latent random variable. This theory of information is compatible with the Bayesian paradigm in which rational belief is updated as evidence becomes available. Furthermore, this theory admits novel measures of information with well-defined properties, which we explore in both analysis and experiment. This view of information illuminates the study of machine learning by allowing us to quantify information captured by a predictive model and distinguish it from residual information contained in training data. We gain related insights regarding feature selection, anomaly detection, and novel Bayesian approaches.
Article Reranking by Memory-Enhanced Key Sentence Matching for Detecting Previously Fact-Checked Claims
Dec 20, 2021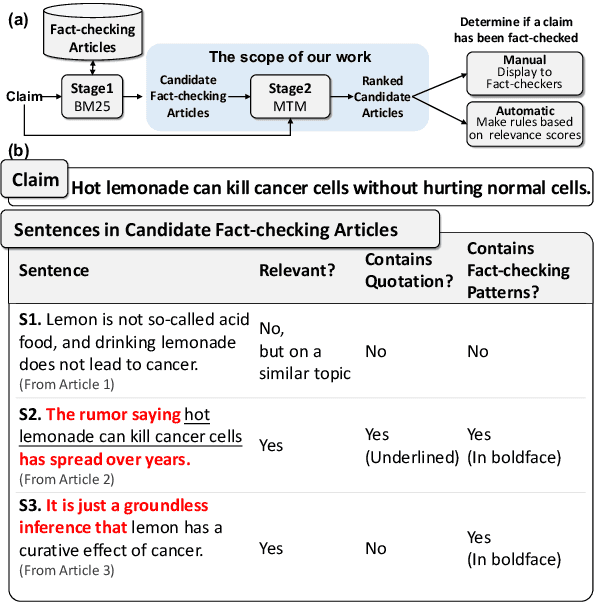
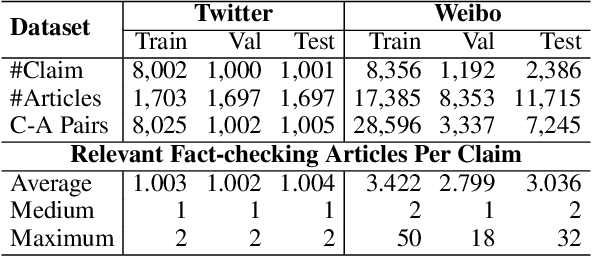
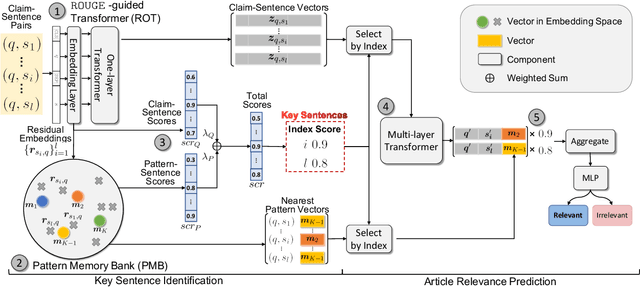
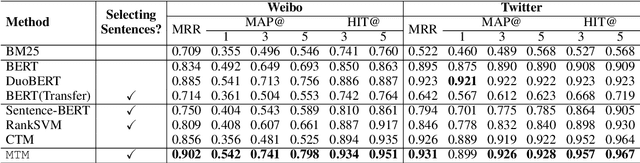
False claims that have been previously fact-checked can still spread on social media. To mitigate their continual spread, detecting previously fact-checked claims is indispensable. Given a claim, existing works focus on providing evidence for detection by reranking candidate fact-checking articles (FC-articles) retrieved by BM25. However, these performances may be limited because they ignore the following characteristics of FC-articles: (1) claims are often quoted to describe the checked events, providing lexical information besides semantics; (2) sentence templates to introduce or debunk claims are common across articles, providing pattern information. Models that ignore the two aspects only leverage semantic relevance and may be misled by sentences that describe similar but irrelevant events. In this paper, we propose a novel reranker, MTM (Memory-enhanced Transformers for Matching) to rank FC-articles using key sentences selected with event (lexical and semantic) and pattern information. For event information, we propose a ROUGE-guided Transformer which is finetuned with regression of ROUGE. For pattern information, we generate pattern vectors for matching with sentences. By fusing event and pattern information, we select key sentences to represent an article and then predict if the article fact-checks the given claim using the claim, key sentences, and patterns. Experiments on two real-world datasets show that MTM outperforms existing methods. Human evaluation proves that MTM can capture key sentences for explanations. The code and the dataset are at https://github.com/ICTMCG/MTM.
Efficient-VDVAE: Less is more
Mar 25, 2022


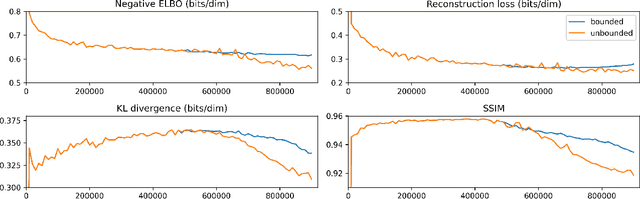
Hierarchical VAEs have emerged in recent years as a reliable option for maximum likelihood estimation. However, instability issues and demanding computational requirements have hindered research progress in the area. We present simple modifications to the Very Deep VAE to make it converge up to $2.6\times$ faster, save up to $20\times$ in memory load and improve stability during training. Despite these changes, our models achieve comparable or better negative log-likelihood performance than current state-of-the-art models on all $7$ commonly used image datasets we evaluated on. We also make an argument against using 5-bit benchmarks as a way to measure hierarchical VAE's performance due to undesirable biases caused by the 5-bit quantization. Additionally, we empirically demonstrate that roughly $3\%$ of the hierarchical VAE's latent space dimensions is sufficient to encode most of the image information, without loss of performance, opening up the doors to efficiently leverage the hierarchical VAEs' latent space in downstream tasks. We release our source code and models at https://github.com/Rayhane-mamah/Efficient-VDVAE .
Structure Extraction in Task-Oriented Dialogues with Slot Clustering
Mar 15, 2022
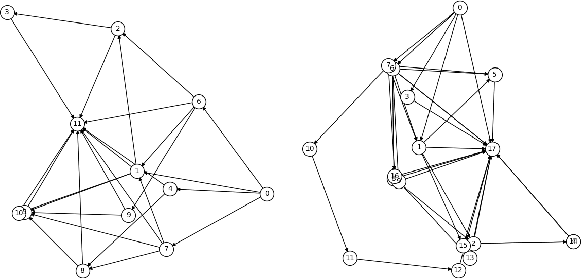


Extracting structure information from dialogue data can help us better understand user and system behaviors. In task-oriented dialogues, dialogue structure has often been considered as transition graphs among dialogue states. However, annotating dialogue states manually is expensive and time-consuming. In this paper, we propose a simple yet effective approach for structure extraction in task-oriented dialogues. We first detect and cluster possible slot tokens with a pre-trained model to approximate dialogue ontology for a target domain. Then we track the status of each identified token group and derive a state transition structure. Empirical results show that our approach outperforms unsupervised baseline models by far in dialogue structure extraction. In addition, we show that data augmentation based on extracted structures enriches the surface formats of training data and can achieve a significant performance boost in dialogue response generation.
Expert-Calibrated Learning for Online Optimization with Switching Costs
Apr 18, 2022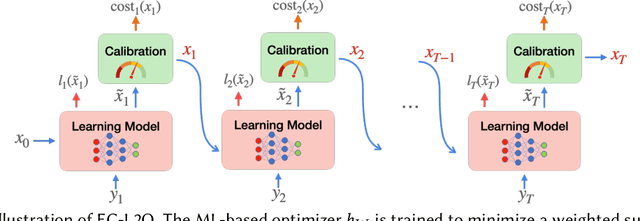
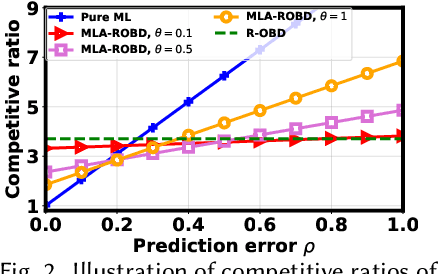
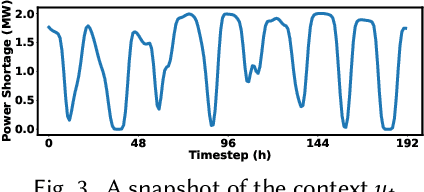
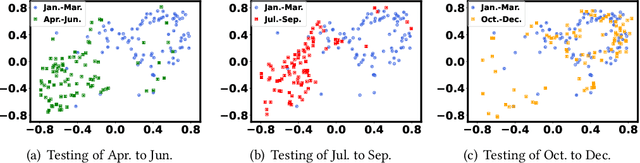
We study online convex optimization with switching costs, a practically important but also extremely challenging problem due to the lack of complete offline information. By tapping into the power of machine learning (ML) based optimizers, ML-augmented online algorithms (also referred to as expert calibration in this paper) have been emerging as state of the art, with provable worst-case performance guarantees. Nonetheless, by using the standard practice of training an ML model as a standalone optimizer and plugging it into an ML-augmented algorithm, the average cost performance can be even worse than purely using ML predictions. In order to address the "how to learn" challenge, we propose EC-L2O (expert-calibrated learning to optimize), which trains an ML-based optimizer by explicitly taking into account the downstream expert calibrator. To accomplish this, we propose a new differentiable expert calibrator that generalizes regularized online balanced descent and offers a provably better competitive ratio than pure ML predictions when the prediction error is large. For training, our loss function is a weighted sum of two different losses -- one minimizing the average ML prediction error for better robustness, and the other one minimizing the post-calibration average cost. We also provide theoretical analysis for EC-L2O, highlighting that expert calibration can be even beneficial for the average cost performance and that the high-percentile tail ratio of the cost achieved by EC-L2O to that of the offline optimal oracle (i.e., tail cost ratio) can be bounded. Finally, we test EC-L2O by running simulations for sustainable datacenter demand response. Our results demonstrate that EC-L2O can empirically achieve a lower average cost as well as a lower competitive ratio than the existing baseline algorithms.
Towards Learning Neural Representations from Shadows
Mar 29, 2022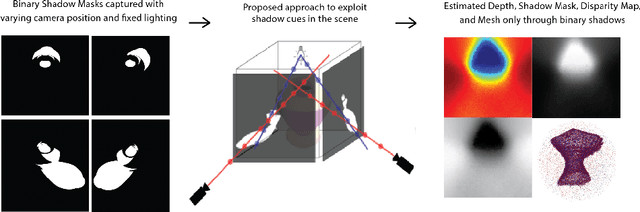
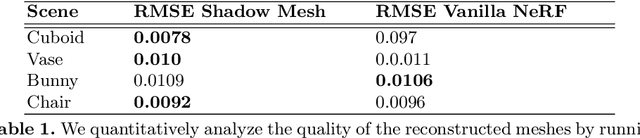
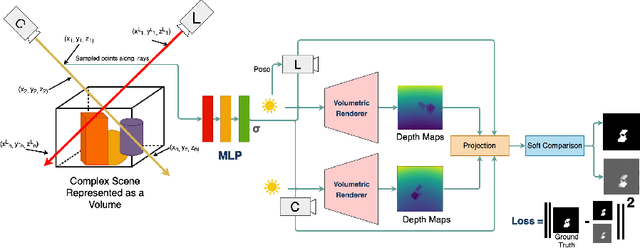
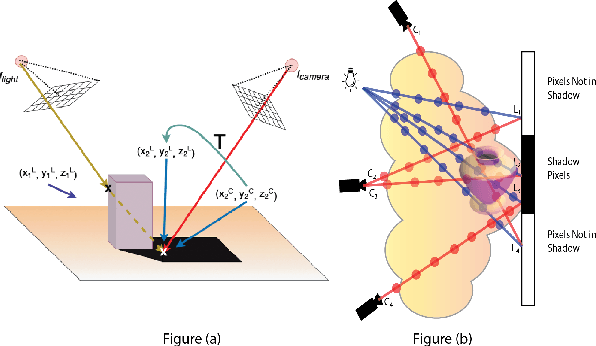
We present a method that learns neural scene representations from only shadows present in the scene. While traditional shape-from-shadow (SfS) algorithms reconstruct geometry from shadows, they assume a fixed scanning setup and fail to generalize to complex scenes. Neural rendering algorithms, on the other hand, rely on photometric consistency between RGB images but largely ignore physical cues such as shadows, which have been shown to provide valuable information about the scene. We observe that shadows are a powerful cue that can constrain neural scene representations to learn SfS, and even outperform NeRF to reconstruct otherwise hidden geometry. We propose a graphics-inspired differentiable approach to render accurate shadows with volumetric rendering, predicting a shadow map that can be compared to the ground truth shadow. Even with just binary shadow maps, we show that neural rendering can localize the object and estimate coarse geometry. Our approach reveals that sparse cues in images can be used to estimate geometry using differentiable volumetric rendering. Moreover, our framework is highly generalizable and can work alongside existing 3D reconstruction techniques that otherwise only use photometric consistency. Our code is made available in our supplementary materials.