 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ScalableViT: Rethinking the Context-oriented Generalization of Vision Transformer
Mar 21, 2022


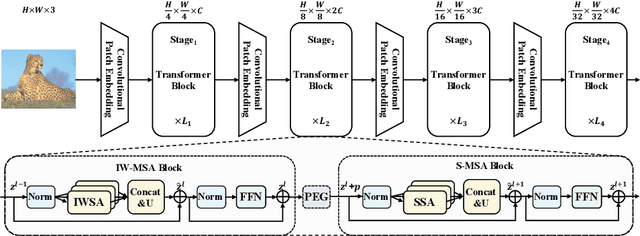
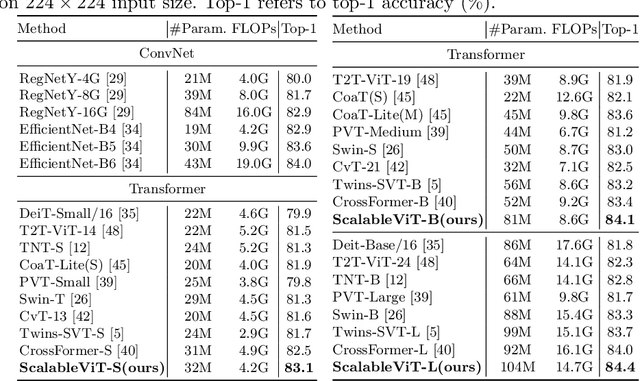
The vanilla self-attention mechanism inherently relies on pre-defined and steadfast computational dimensions. Such inflexibility restricts it from possessing context-oriented generalization that can bring more contextual cues and global representations. To mitigate this issue, we propose a Scalable Self-Attention (SSA) mechanism that leverages two scaling factors to release dimensions of query, key, and value matrix while unbinding them with the input. This scalability fetches context-oriented generalization and enhances object sensitivity, which pushes the whole network into a more effective trade-off state between accuracy and cost. Furthermore, we propose an Interactive Window-based Self-Attention (IWSA), which establishes interaction between non-overlapping regions by re-merging independent value tokens and aggregating spatial information from adjacent windows. By stacking the SSA and IWSA alternately, the Scalable Vision Transformer (ScalableViT) achieves state-of-the-art performance in general-purpose vision tasks. For example, ScalableViT-S outperforms Twins-SVT-S by 1.4% and Swin-T by 1.8% on ImageNet-1K classification.
Which side are you on? Insider-Outsider classification in conspiracy-theoretic social media
Mar 30, 2022
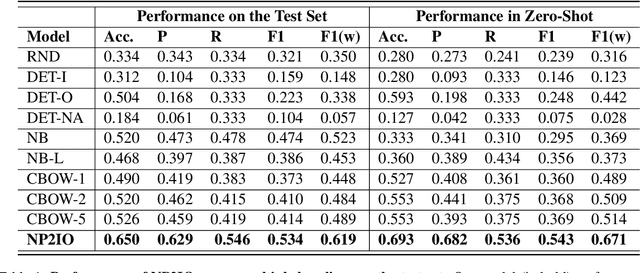
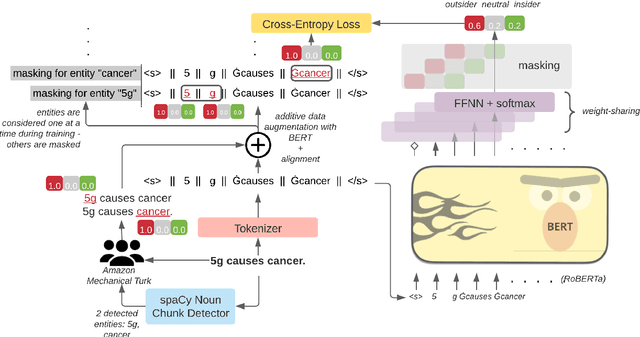
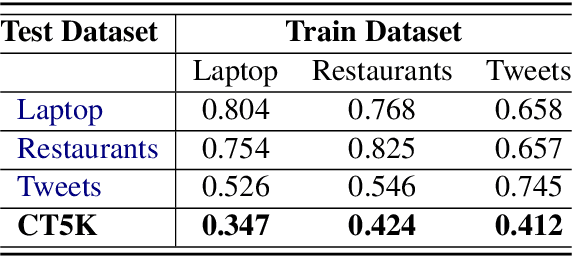
Social media is a breeding ground for threat narratives and related conspiracy theories. In these, an outside group threatens the integrity of an inside group, leading to the emergence of sharply defined group identities: Insiders -- agents with whom the authors identify and Outsiders -- agents who threaten the insiders. Inferring the members of these groups constitutes a challenging new NLP task: (i) Information is distributed over many poorly-constructed posts; (ii) Threats and threat agents are highly contextual, with the same post potentially having multiple agents assigned to membership in either group; (iii) An agent's identity is often implicit and transitive; and (iv) Phrases used to imply Outsider status often do not follow common negative sentiment patterns. To address these challenges, we define a novel Insider-Outsider classification task. Because we are not aware of any appropriate existing datasets or attendant models, we introduce a labeled dataset (CT5K) and design a model (NP2IO) to address this task. NP2IO leverages pretrained language modeling to classify Insiders and Outsiders. NP2IO is shown to be robust, generalizing to noun phrases not seen during training, and exceeding the performance of non-trivial baseline models by $20\%$.
Gait Events Prediction using Hybrid CNN-RNN-based Deep Learning models through a Single Waist-worn Wearable Sensor
Feb 28, 2022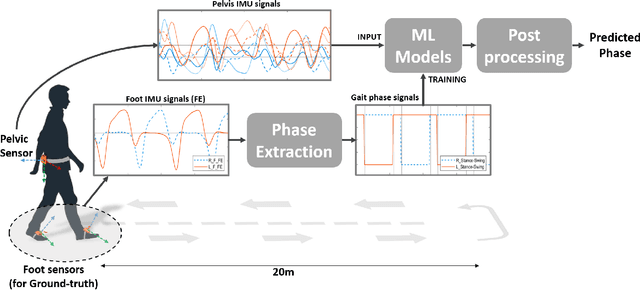
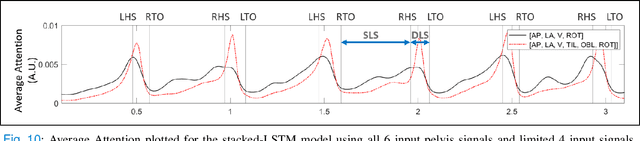
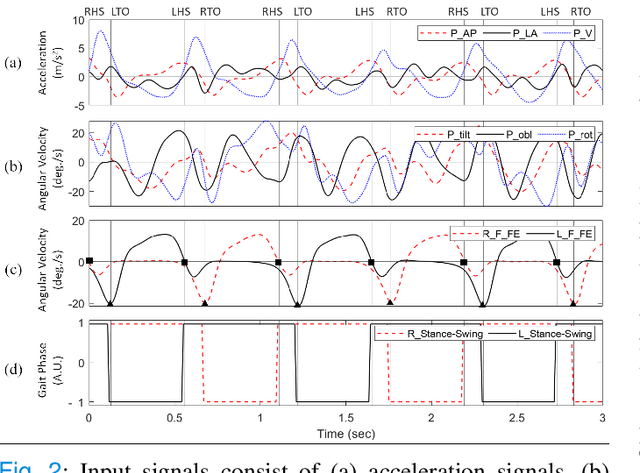

Elderly gait is a source of rich information about their physical and mental health condition. As an alternative to the multiple sensors on the lower body parts, a single sensor on the pelvis has a positional advantage and an abundance of information acquirable. This study aimed to explore a way of improving the accuracy of gait event detection in the elderly using a single sensor on the waist and deep learning models. Data was gathered from elderly subjects equipped with three IMU sensors while they walked. The input was taken only from the waist sensor was used to train 16 deep-learning models including CNN, RNN, and CNN-RNN hybrid with or without the Bidirectional and Attention mechanism. The groundtruth was extracted from foot IMU sensors. Fairly high accuracy of 99.73% and 93.89% was achieved by the CNN-BiGRU-Att model at the tolerance window of $\pm$6TS ($\pm$6ms) and $\pm$1TS ($\pm$1ms) respectively. Advancing from the previous studies exploring gait event detection, the model showed a great improvement in terms of its prediction error having an MAE of 6.239ms and 5.24ms for HS and TO events respectively at the tolerance window of $\pm$1TS. The results showed that the use of CNN-RNN hybrid models with Attention and Bidirectional mechanisms is promising for accurate gait event detection using a single waist sensor. The study can contribute to reducing the burden of gait detection and increase its applicability in future wearable devices that can be used for remote health monitoring (RHM) or diagnosis based thereon.
Learning Bi-typed Multi-relational Heterogeneous Graph via Dual Hierarchical Attention Networks
Jan 25, 2022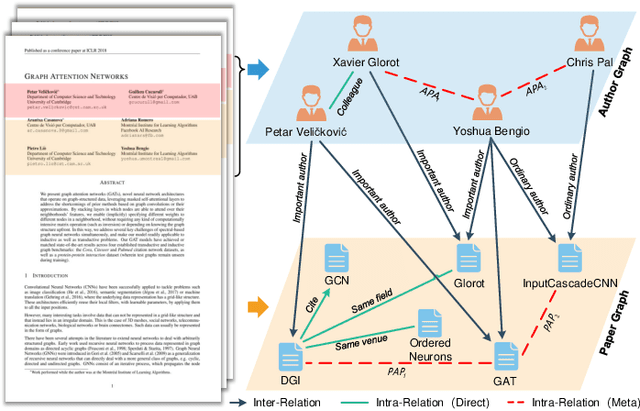
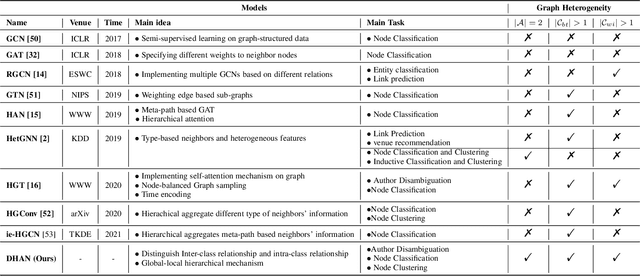
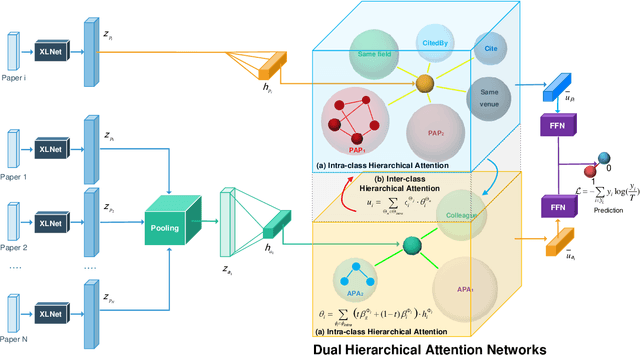

Bi-type multi-relational heterogeneous graph (BMHG) is one of the most common graphs in practice, for example, academic networks, e-commerce user behavior graph and enterprise knowledge graph. It is a critical and challenge problem on how to learn the numerical representation for each node to characterize subtle structures. However, most previous studies treat all node relations in BMHG as the same class of relation without distinguishing the different characteristics between the intra-class relations and inter-class relations of the bi-typed nodes, causing the loss of significant structure information. To address this issue, we propose a novel Dual Hierarchical Attention Networks (DHAN) based on the bi-typed multi-relational heterogeneous graphs to learn comprehensive node representations with the intra-class and inter-class attention-based encoder under a hierarchical mechanism. Specifically, the former encoder aggregates information from the same type of nodes, while the latter aggregates node representations from its different types of neighbors. Moreover, to sufficiently model node multi-relational information in BMHG, we adopt a newly proposed hierarchical mechanism. By doing so, the proposed dual hierarchical attention operations enable our model to fully capture the complex structures of the bi-typed multi-relational heterogeneous graphs. Experimental results on various tasks against the state-of-the-arts sufficiently confirm the capability of DHAN in learning node representations on the BMHGs.
Learning Pixel-Level Distinctions for Video Highlight Detection
Apr 10, 2022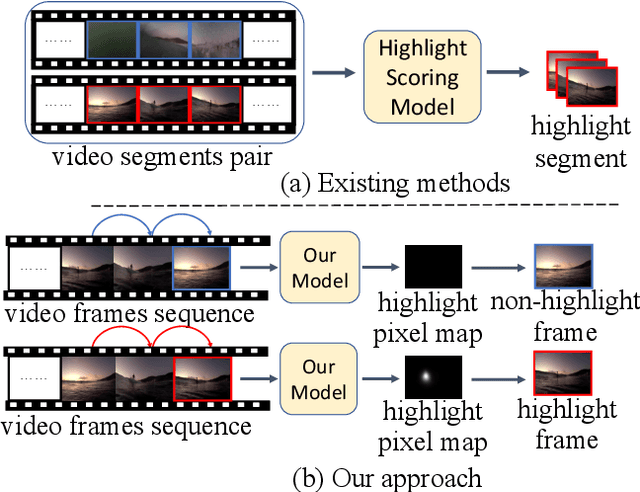

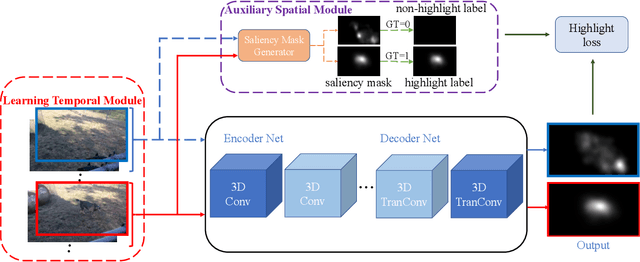
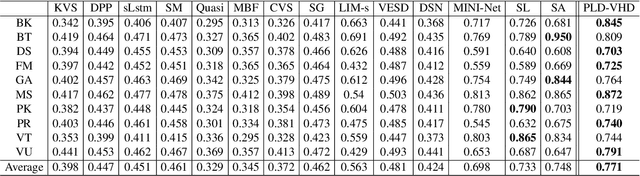
The goal of video highlight detection is to select the most attractive segments from a long video to depict the most interesting parts of the video. Existing methods typically focus on modeling relationship between different video segments in order to learning a model that can assign highlight scores to these segments; however, these approaches do not explicitly consider the contextual dependency within individual segments. To this end, we propose to learn pixel-level distinctions to improve the video highlight detection. This pixel-level distinction indicates whether or not each pixel in one video belongs to an interesting section. The advantages of modeling such fine-level distinctions are two-fold. First, it allows us to exploit the temporal and spatial relations of the content in one video, since the distinction of a pixel in one frame is highly dependent on both the content before this frame and the content around this pixel in this frame. Second, learning the pixel-level distinction also gives a good explanation to the video highlight task regarding what contents in a highlight segment will be attractive to people. We design an encoder-decoder network to estimate the pixel-level distinction, in which we leverage the 3D convolutional neural networks to exploit the temporal context information, and further take advantage of the visual saliency to model the spatial distinction. State-of-the-art performance on three public benchmarks clearly validates the effectiveness of our framework for video highlight detection.
RELIC: Retrieving Evidence for Literary Claims
Mar 18, 2022


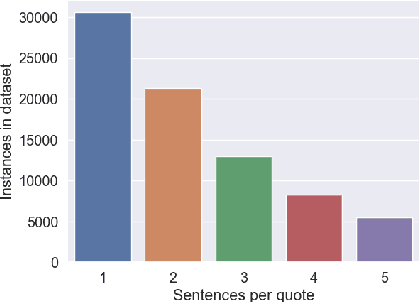
Humanities scholars commonly provide evidence for claims that they make about a work of literature (e.g., a novel) in the form of quotations from the work. We collect a large-scale dataset (RELiC) of 78K literary quotations and surrounding critical analysis and use it to formulate the novel task of literary evidence retrieval, in which models are given an excerpt of literary analysis surrounding a masked quotation and asked to retrieve the quoted passage from the set of all passages in the work. Solving this retrieval task requires a deep understanding of complex literary and linguistic phenomena, which proves challenging to methods that overwhelmingly rely on lexical and semantic similarity matching. We implement a RoBERTa-based dense passage retriever for this task that outperforms existing pretrained information retrieval baselines; however, experiments and analysis by human domain experts indicate that there is substantial room for improvement over our dense retriever.
Temporal Walk Centrality: Ranking Nodes in Evolving Networks
Feb 08, 2022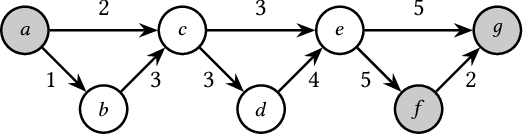



We propose the Temporal Walk Centrality, which quantifies the importance of a node by measuring its ability to obtain and distribute information in a temporal network. In contrast to the widely-used betweenness centrality, we assume that information does not necessarily spread on shortest paths but on temporal random walks that satisfy the time constraints of the network. We show that temporal walk centrality can identify nodes playing central roles in dissemination processes that might not be detected by related betweenness concepts and other common static and temporal centrality measures. We propose exact and approximation algorithms with different running times depending on the properties of the temporal network and parameters of our new centrality measure. A technical contribution is a general approach to lift existing algebraic methods for counting walks in static networks to temporal networks. Our experiments on real-world temporal networks show the efficiency and accuracy of our algorithms. Finally, we demonstrate that the rankings by temporal walk centrality often differ significantly from those of other state-of-the-art temporal centralities.
Unified theory of atom-centered representations and graph convolutional machine-learning schemes
Feb 03, 2022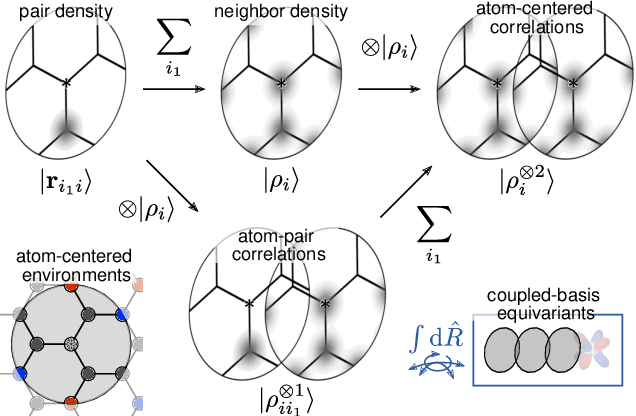
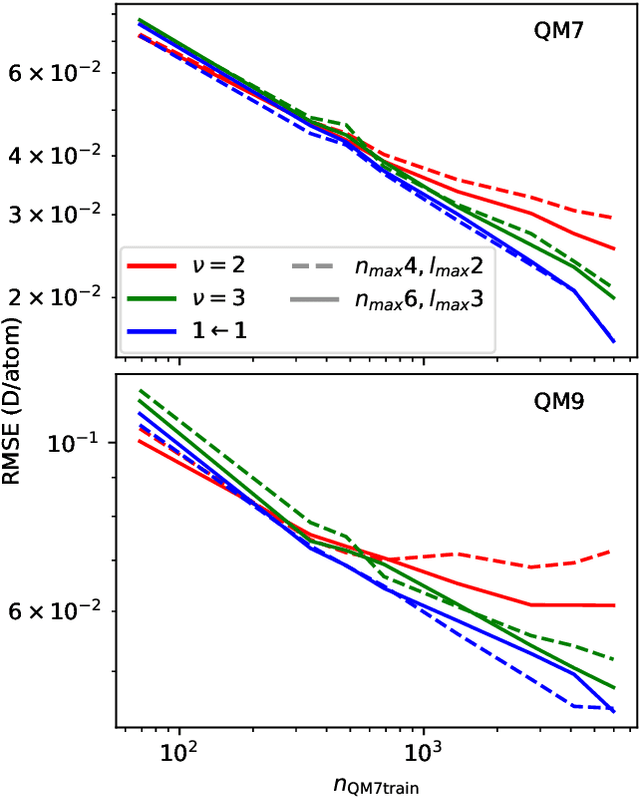

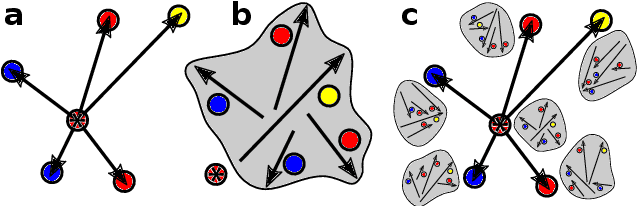
Data-driven schemes that associate molecular and crystal structures with their microscopic properties share the need for a concise, effective description of the arrangement of their atomic constituents. Many types of models rely on descriptions of atom-centered environments, that are associated with an atomic property or with an atomic contribution to an extensive macroscopic quantity. Frameworks in this class can be understood in terms of atom-centered density correlations (ACDC), that are used as a basis for a body-ordered, symmetry-adapted expansion of the targets. Several other schemes, that gather information on the relationship between neighboring atoms using graph-convolutional (or message-passing) ideas, cannot be directly mapped to correlations centered around a single atom. We generalize the ACDC framework to include multi-centered information, generating representations that provide a complete linear basis to regress symmetric functions of atomic coordinates, and form the basis to systematize our understanding of both atom-centered and graph-convolutional machine-learning schemes.
WiFiEye -- Seeing over WiFi Made Accessible
Apr 06, 2022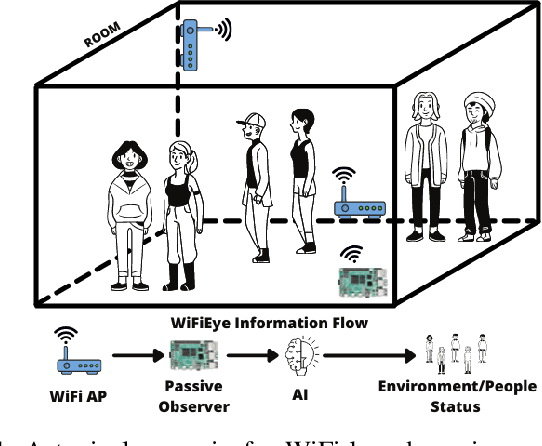
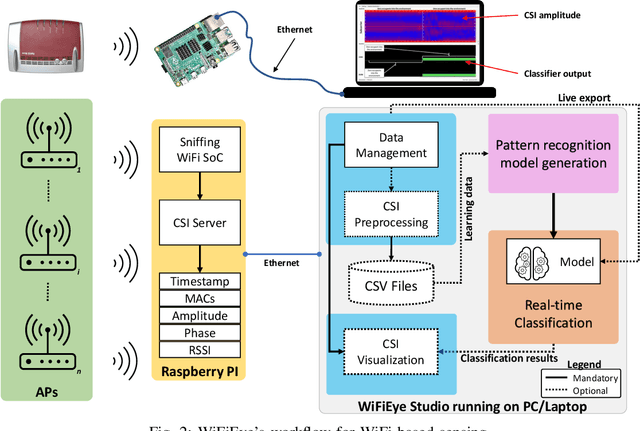


While commonly used for communication purposes, an increasing number of recent studies consider WiFi for sensing. In particular, wireless signals are altered (e.g., reflected and attenuated) by the human body and objects in the environment. This can be perceived by an observer to infer information on human activities or changes in the environment and, hence, to "see" over WiFi. Until now, works on WiFi-based sensing have resulted in a set of custom software tools - each designed for a specific purpose. Moreover, given how scattered the literature is, it is difficult to even identify all steps/functions necessary to build a basic system for WiFi-based sensing. This has led to a high entry barrier, hindering further research in this area. There has been no effort to integrate these tools or to build a general software framework that can serve as the basis for further research, e.g., on using machine learning to interpret the altered WiFi signals. To address this issue, in this paper, we propose WiFiEye - a generic software framework that makes all necessary steps/functions available "out of the box". This way, WiFiEye allows researchers to easily bootstrap new WiFi-based sensing applications, thereby, focusing on research rather than on implementation aspects. To illustrate WiFiEye's workflow, we present a case study on WiFi-based human activity recognition.
Making a (Counterfactual) Difference One Rationale at a Time
Jan 13, 2022

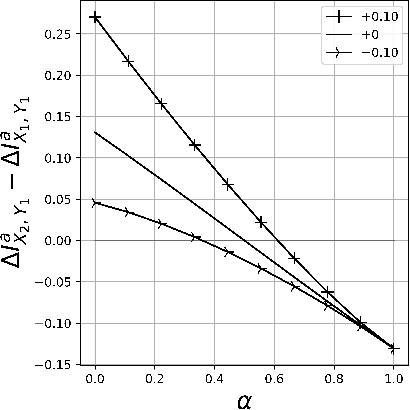
Rationales, snippets of extracted text that explain an inference, have emerged as a popular framework for interpretable natural language processing (NLP). Rationale models typically consist of two cooperating modules: a selector and a classifier with the goal of maximizing the mutual information (MMI) between the "selected" text and the document label. Despite their promises, MMI-based methods often pick up on spurious text patterns and result in models with nonsensical behaviors. In this work, we investigate whether counterfactual data augmentation (CDA), without human assistance, can improve the performance of the selector by lowering the mutual information between spurious signals and the document label. Our counterfactuals are produced in an unsupervised fashion using class-dependent generative models. From an information theoretic lens, we derive properties of the unaugmented dataset for which our CDA approach would succeed. The effectiveness of CDA is empirically evaluated by comparing against several baselines including an improved MMI-based rationale schema on two multi aspect datasets. Our results show that CDA produces rationales that better capture the signal of interest.