 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Multi-Transformation Evolutionary Framework for Influence Maximization in Social Networks
Apr 07, 2022
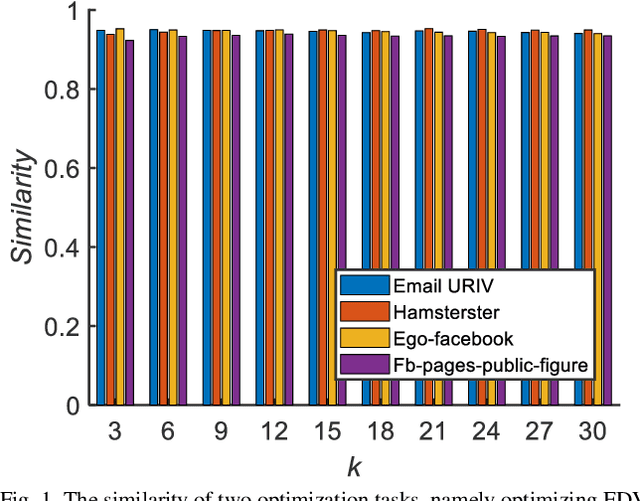
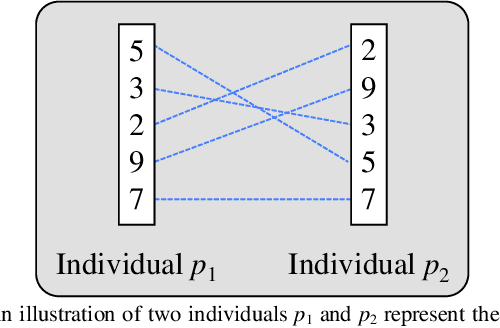
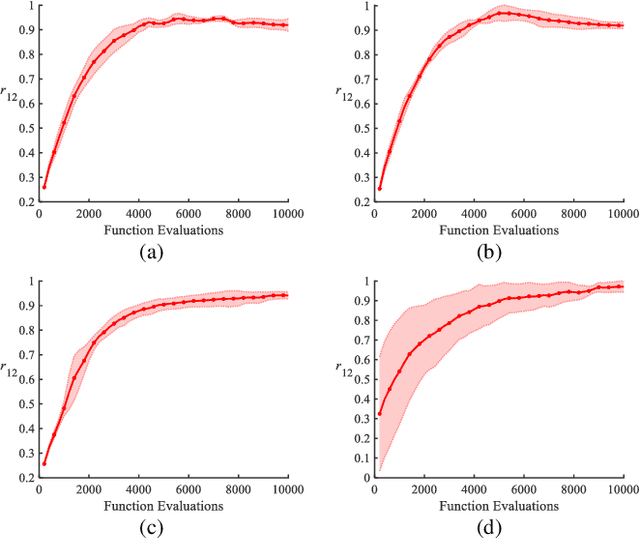
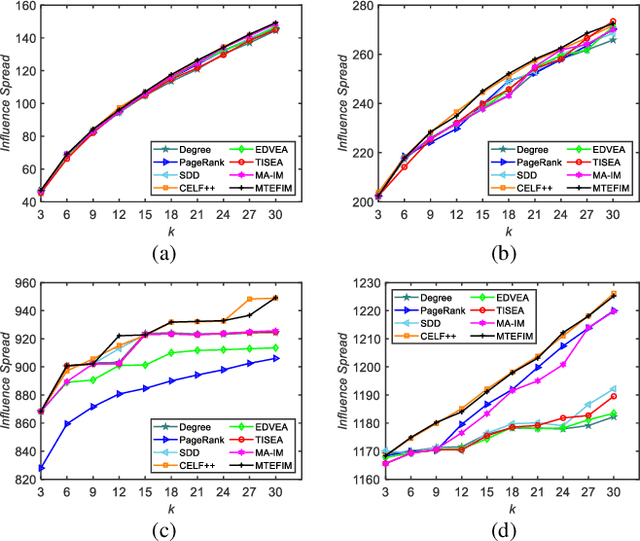
Influence maximization is a key issue for mining the deep information of social networks, which aims to select a seed set from the network to maximize the number of influenced nodes. To evaluate the influence spread of a seed set efficiently, existing works have proposed some proxy models (transformations) with lower computational costs to replace the expensive Monte Carlo simulation process. These alternate transformations based on network prior knowledge induce different search behaviors with similar characteristics from various perspectives. For a specific case, it is difficult for users to determine a suitable transformation a priori. Keeping those in mind, we propose a multi-transformation evolutionary framework for influence maximization (MTEFIM) to exploit the potential similarities and unique advantages of alternate transformations and avoid users to determine the most suitable one manually. In MTEFIM, multiple transformations are optimized simultaneously as multiple tasks. Each transformation is assigned an evolutionary solver. Three major components of MTEFIM are conducted: 1) estimating the potential relationship across transformations based on the degree of overlap across individuals (seed sets) of different populations, 2) transferring individuals across populations adaptively according to the inter-transformation relationship, 3) selecting the final output seed set containing all the proxy model knowledge. The effectiveness of MTEFIM is validated on four real-world social networks. Experimental results show that MTEFIM can efficiently utilize the potentially transferable knowledge across multiple transformations to achieve highly competitive performance compared to several popular IM-specific methods. The implementation of MTEFIM can be accessed at https://github.com/xiaofangxd/MTEFIM.
ZUPT Aided GNSS Factor Graph with Inertial Navigation Integration for Wheeled Robots
Dec 14, 2021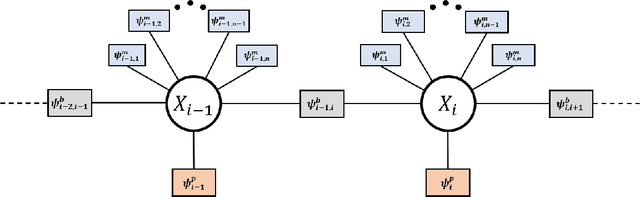
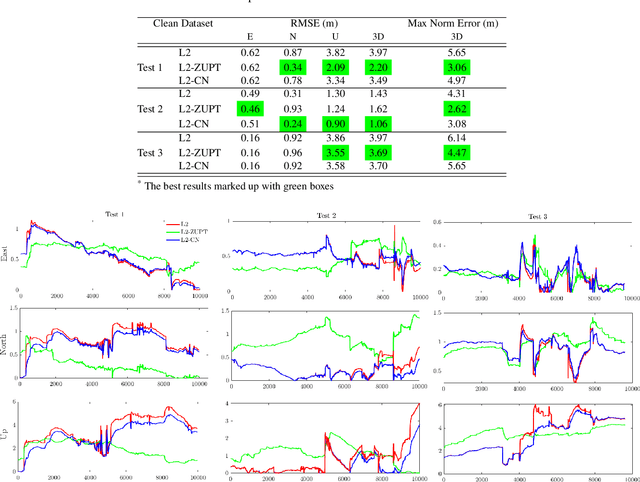
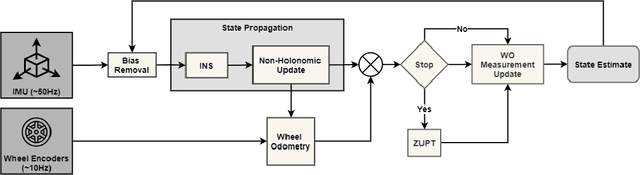
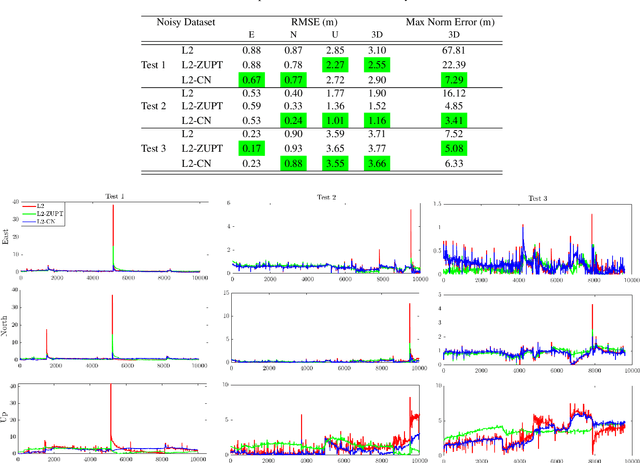
In this work, we demonstrate the importance of zero velocity information for global navigation satellite system (GNSS) based navigation. The effectiveness of using the zero velocity information with zero velocity update (ZUPT) for inertial navigation applications have been shown in the literature. Here we leverage this information and add it as a position constraint in a GNSS factor graph. We also compare its performance to a GNSS/inertial navigation system (INS) coupled factor graph. We tested our ZUPT aided factor graph method on three datasets and compared it with the GNSS-only factor graph.
A Review of Modern Fashion Recommender Systems
Feb 06, 2022


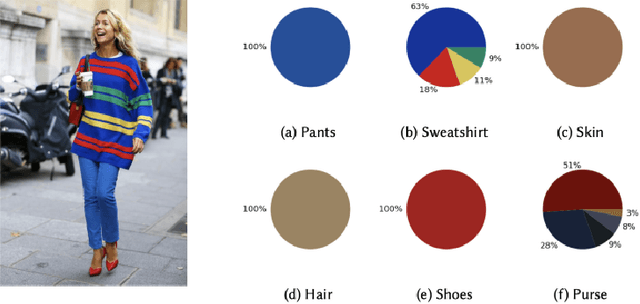
The textile and apparel industries have grown tremendously over the last years. Customers no longer have to visit many stores, stand in long queues, or try on garments in dressing rooms as millions of products are now available in online catalogs. However, given the plethora of options available, an effective recommendation system is necessary to properly sort, order, and communicate relevant product material or information to users. Effective fashion RS can have a noticeable impact on billions of customers' shopping experiences and increase sales and revenues on the provider-side. The goal of this survey is to provide a review of recommender systems that operate in the specific vertical domain of garment and fashion products. We have identified the most pressing challenges in fashion RS research and created a taxonomy that categorizes the literature according to the objective they are trying to accomplish (e.g., item or outfit recommendation, size recommendation, explainability, among others) and type of side-information (users, items, context). We have also identified the most important evaluation goals and perspectives (outfit generation, outfit recommendation, pairing recommendation, and fill-in-the-blank outfit compatibility prediction) and the most commonly used datasets and evaluation metrics.
On the Benefits of Selectivity in Pseudo-Labeling for Unsupervised Multi-Source-Free Domain Adaptation
Feb 01, 2022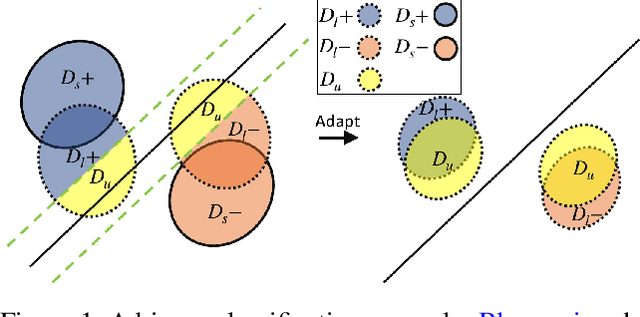
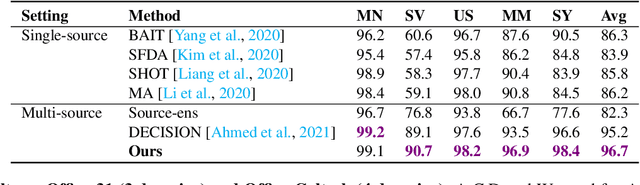
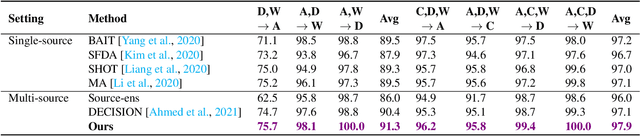
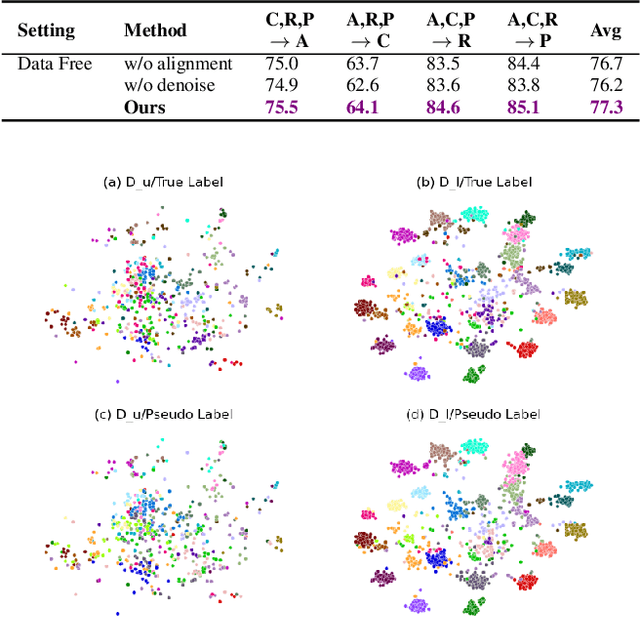
Due to privacy, storage, and other constraints, there is a growing need for unsupervised domain adaptation techniques in machine learning that do not require access to the data used to train a collection of source models. Existing methods for such multi-source-free domain adaptation typically train a target model using supervised techniques in conjunction with pseudo-labels for the target data, which are produced by the available source models. However, we show that assigning pseudo-labels to only a subset of the target data leads to improved performance. In particular, we develop an information-theoretic bound on the generalization error of the resulting target model that demonstrates an inherent bias-variance trade-off controlled by the subset choice. Guided by this analysis, we develop a method that partitions the target data into pseudo-labeled and unlabeled subsets to balance the trade-off. In addition to exploiting the pseudo-labeled subset, our algorithm further leverages the information in the unlabeled subset via a traditional unsupervised domain adaptation feature alignment procedure. Experiments on multiple benchmark datasets demonstrate the superior performance of the proposed method.
CLRNet: Cross Layer Refinement Network for Lane Detection
Mar 19, 2022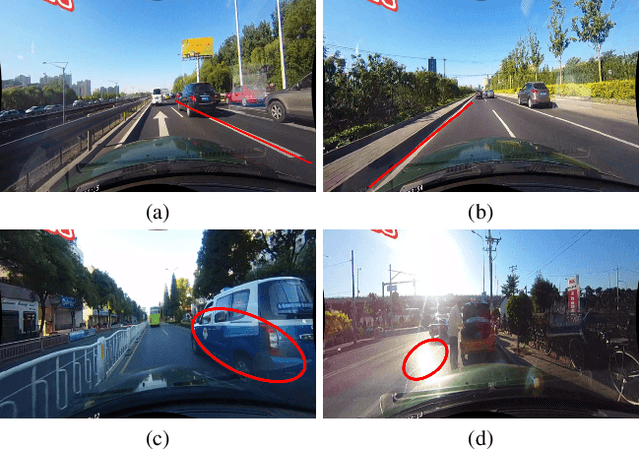
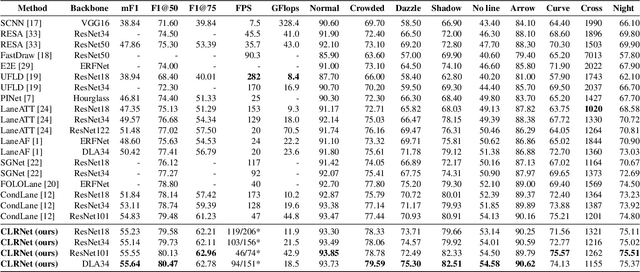
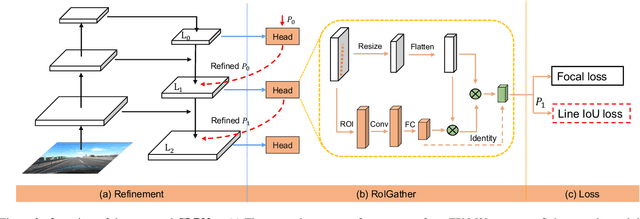
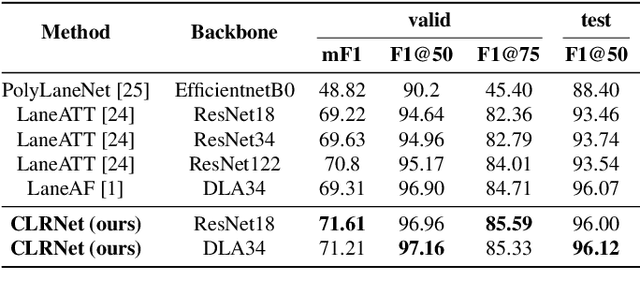
Lane is critical in the vision navigation system of the intelligent vehicle. Naturally, lane is a traffic sign with high-level semantics, whereas it owns the specific local pattern which needs detailed low-level features to localize accurately. Using different feature levels is of great importance for accurate lane detection, but it is still under-explored. In this work, we present Cross Layer Refinement Network (CLRNet) aiming at fully utilizing both high-level and low-level features in lane detection. In particular, it first detects lanes with high-level semantic features then performs refinement based on low-level features. In this way, we can exploit more contextual information to detect lanes while leveraging local detailed lane features to improve localization accuracy. We present ROIGather to gather global context, which further enhances the feature representation of lanes. In addition to our novel network design, we introduce Line IoU loss which regresses the lane line as a whole unit to improve the localization accuracy. Experiments demonstrate that the proposed method greatly outperforms the state-of-the-art lane detection approaches.
Leveraging Pre-trained BERT for Audio Captioning
Mar 27, 2022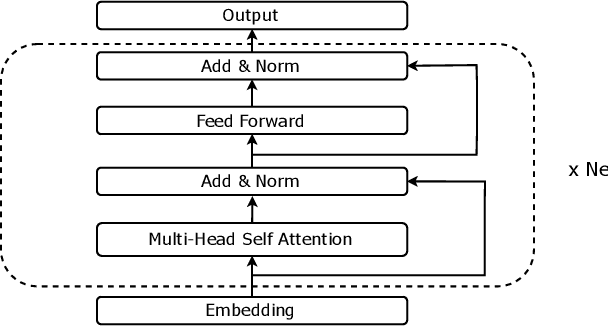
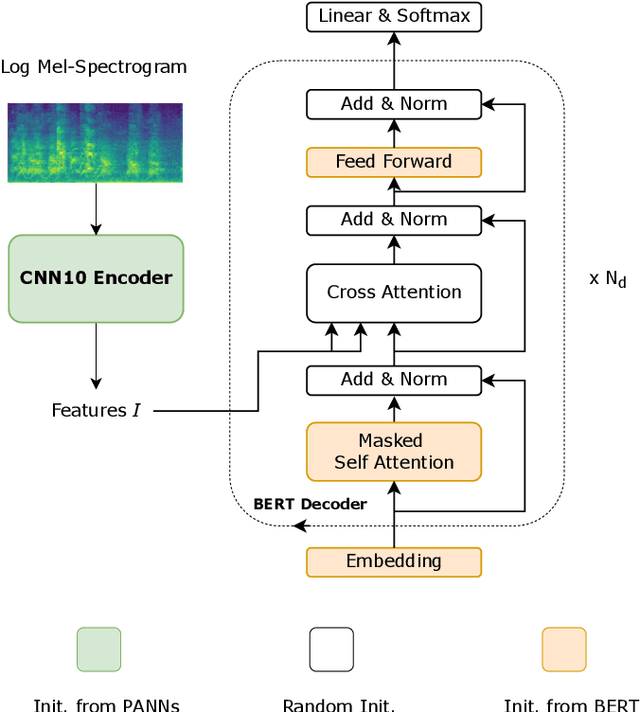
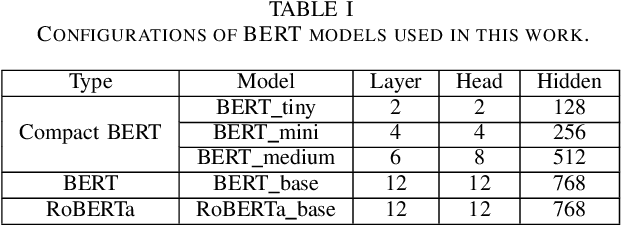
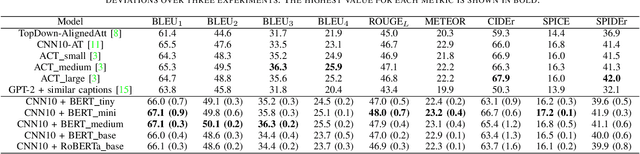
Audio captioning aims at using natural language to describe the content of an audio clip. Existing audio captioning systems are generally based on an encoder-decoder architecture, in which acoustic information is extracted by an audio encoder and then a language decoder is used to generate the captions. Training an audio captioning system often encounters the problem of data scarcity. Transferring knowledge from pre-trained audio models such as Pre-trained Audio Neural Networks (PANNs) have recently emerged as a useful method to mitigate this issue. However, there is less attention on exploiting pre-trained language models for the decoder, compared with the encoder. BERT is a pre-trained language model that has been extensively used in Natural Language Processing (NLP) tasks. Nevertheless, the potential of BERT as the language decoder for audio captioning has not been investigated. In this study, we demonstrate the efficacy of the pre-trained BERT model for audio captioning. Specifically, we apply PANNs as the encoder and initialize the decoder from the public pre-trained BERT models. We conduct an empirical study on the use of these BERT models for the decoder in the audio captioning model. Our models achieve competitive results with the existing audio captioning methods on the AudioCaps dataset.
Natural Language in Requirements Engineering for Structure Inference -- An Integrative Review
Feb 10, 2022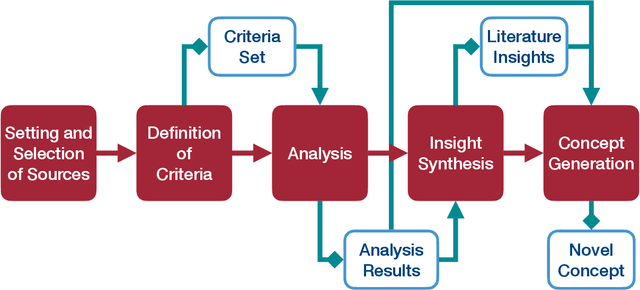
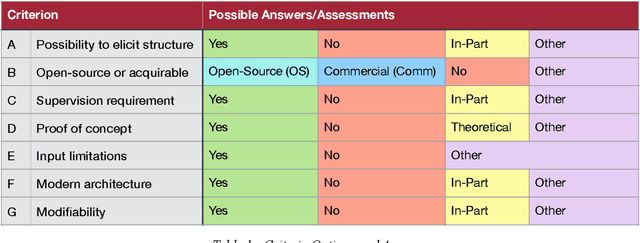
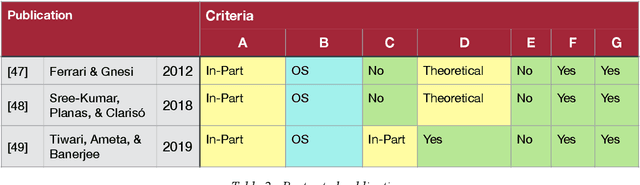
The automatic extraction of structure from text can be difficult for machines. Yet, the elicitation of this information can provide many benefits and opportunities for various applications. Benefits have also been identified for the area of Requirements Engineering. To evaluate what work has been done and is currently available, the paper at hand provides an integrative review regarding Natural Language Processing (NLP) tools for Requirements Engineering. This assessment was conducted to provide a foundation for future work as well as deduce insights from the stats quo. To conduct the review, the history of Requirements Engineering and NLP are described as well as an evaluation of over 136 NLP tools. To assess these tools, a set of criteria was defined. The results are that currently no open source approach exists that allows for the direct/primary extraction of information structure and even closed source solutions show limitations such as supervision or input limitations, which eliminates the possibility for fully automatic and universal application. As a results, the authors deduce that the current approaches are not applicable and a different methodology is necessary. An approach that allows for individual management of the algorithm, knowledge base, and text corpus is a possibility being pursued.
Graph Representation Learning via Graphical Mutual Information Maximization
Feb 04, 2020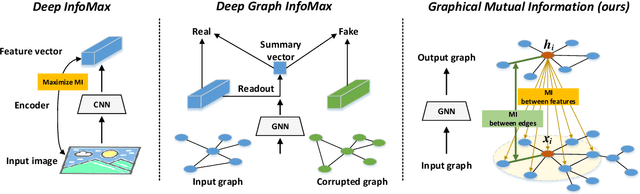
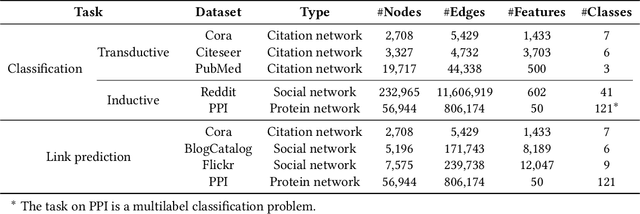
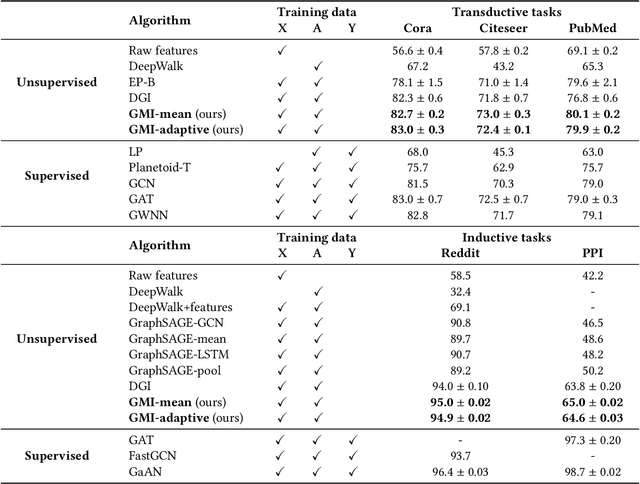
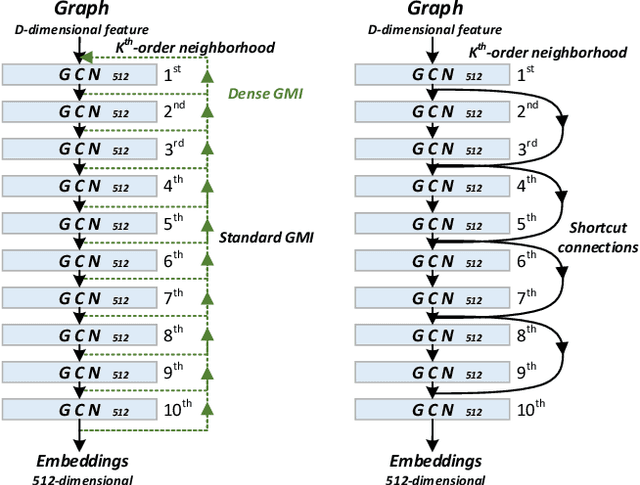
The richness in the content of various information networks such as social networks and communication networks provides the unprecedented potential for learning high-quality expressive representations without external supervision. This paper investigates how to preserve and extract the abundant information from graph-structured data into embedding space in an unsupervised manner. To this end, we propose a novel concept, Graphical Mutual Information (GMI), to measure the correlation between input graphs and high-level hidden representations. GMI generalizes the idea of conventional mutual information computations from vector space to the graph domain where measuring mutual information from two aspects of node features and topological structure is indispensable. GMI exhibits several benefits: First, it is invariant to the isomorphic transformation of input graphs---an inevitable constraint in many existing graph representation learning algorithms; Besides, it can be efficiently estimated and maximized by current mutual information estimation methods such as MINE; Finally, our theoretical analysis confirms its correctness and rationality. With the aid of GMI, we develop an unsupervised learning model trained by maximizing GMI between the input and output of a graph neural encoder. Considerable experiments on transductive as well as inductive node classification and link prediction demonstrate that our method outperforms state-of-the-art unsupervised counterparts, and even sometimes exceeds the performance of supervised ones.
IHGNN: Interactive Hypergraph Neural Network for Personalized Product Search
Feb 10, 2022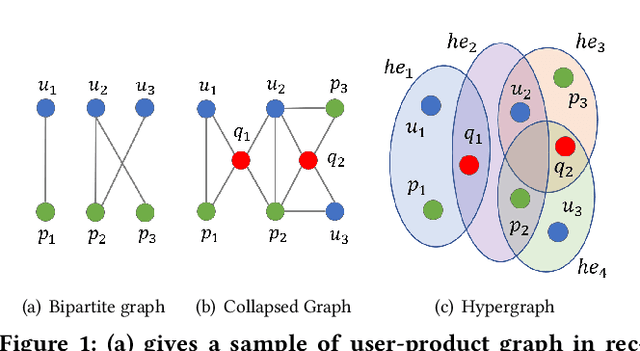
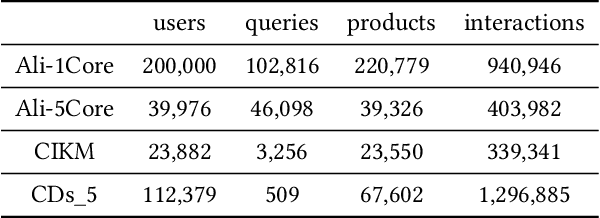
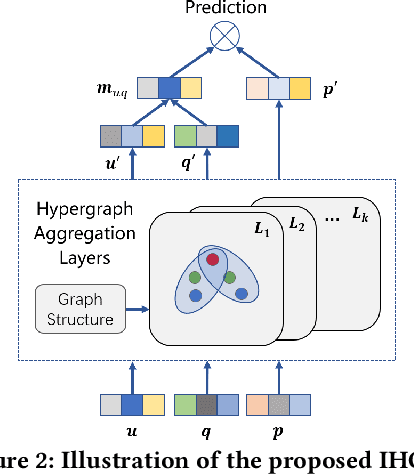
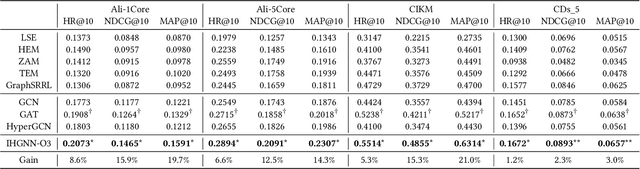
A good personalized product search (PPS) system should not only focus on retrieving relevant products, but also consider user personalized preference. Recent work on PPS mainly adopts the representation learning paradigm, e.g., learning representations for each entity (including user, product and query) from historical user behaviors (aka. user-product-query interactions). However, we argue that existing methods do not sufficiently exploit the crucial collaborative signal, which is latent in historical interactions to reveal the affinity between the entities. Collaborative signal is quite helpful for generating high-quality representation, exploiting which would benefit the representation learning of one node from its connected nodes. To tackle this limitation, in this work, we propose a new model IHGNN for personalized product search. IHGNN resorts to a hypergraph constructed from the historical user-product-query interactions, which could completely preserve ternary relations and express collaborative signal based on the topological structure. On this basis, we develop a specific interactive hypergraph neural network to explicitly encode the structure information (i.e., collaborative signal) into the embedding process. It collects the information from the hypergraph neighbors and explicitly models neighbor feature interaction to enhance the representation of the target entity. Extensive experiments on three real-world datasets validate the superiority of our proposal over the state-of-the-arts.
Research on Dual Channel News Headline Classification Based on ERNIE Pre-training Model
Feb 14, 2022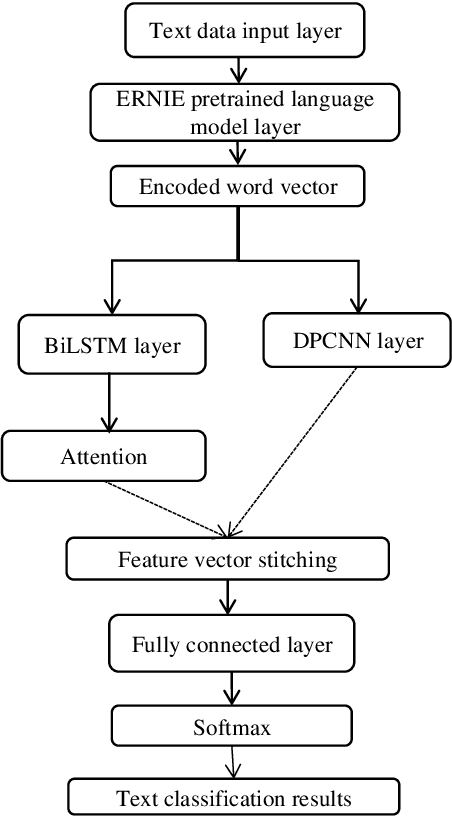
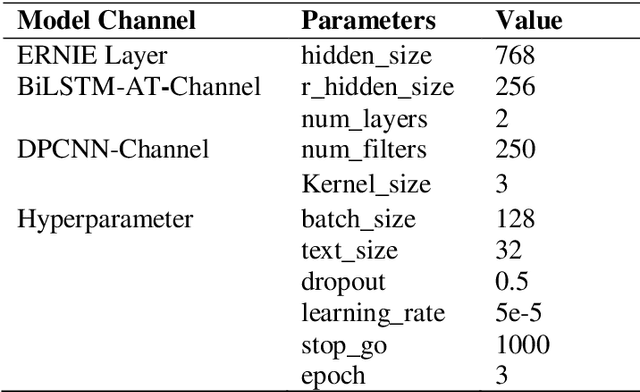
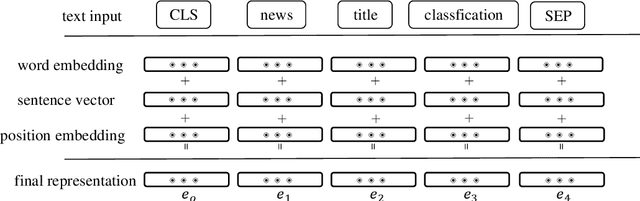
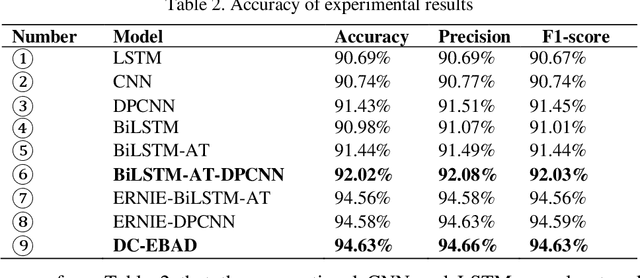
The classification of news headlines is an important direction in the field of NLP, and its data has the characteristics of compactness, uniqueness and various forms. Aiming at the problem that the traditional neural network model cannot adequately capture the underlying feature information of the data and cannot jointly extract key global features and deep local features, a dual-channel network model DC-EBAD based on the ERNIE pre-training model is proposed. Use ERNIE to extract the lexical, semantic and contextual feature information at the bottom of the text, generate dynamic word vector representations fused with context, and then use the BiLSTM-AT network channel to secondary extract the global features of the data and use the attention mechanism to give key parts higher The weight of the DPCNN channel is used to overcome the long-distance text dependence problem and obtain deep local features. The local and global feature vectors are spliced, and finally passed to the fully connected layer, and the final classification result is output through Softmax. The experimental results show that the proposed model improves the accuracy, precision and F1-score of news headline classification compared with the traditional neural network model and the single-channel model under the same conditions. It can be seen that it can perform well in the multi-classification application of news headline text under large data volume.