 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Large-scale Bilingual Language-Image Contrastive Learning
Mar 28, 2022
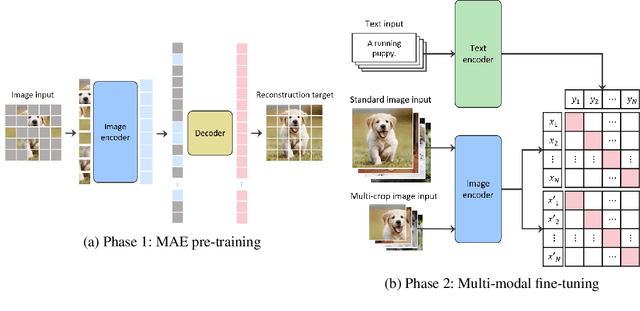
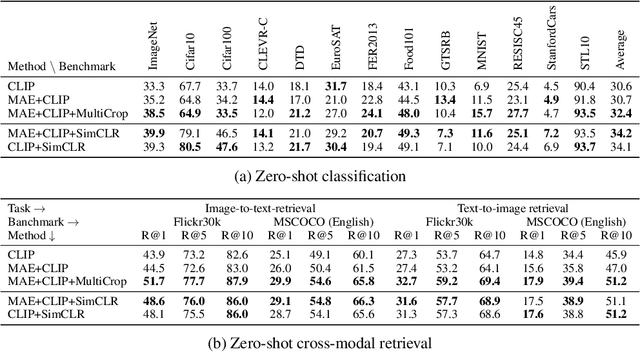
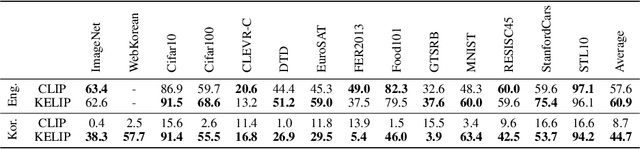
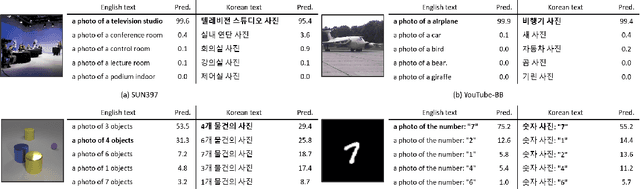
This paper is a technical report to share our experience and findings building a Korean and English bilingual multimodal model. While many of the multimodal datasets focus on English and multilingual multimodal research uses machine-translated texts, employing such machine-translated texts is limited to describing unique expressions, cultural information, and proper noun in languages other than English. In this work, we collect 1.1 billion image-text pairs (708 million Korean and 476 million English) and train a bilingual multimodal model named KELIP. We introduce simple yet effective training schemes, including MAE pre-training and multi-crop augmentation. Extensive experiments demonstrate that a model trained with such training schemes shows competitive performance in both languages. Moreover, we discuss multimodal-related research questions: 1) strong augmentation-based methods can distract the model from learning proper multimodal relations; 2) training multimodal model without cross-lingual relation can learn the relation via visual semantics; 3) our bilingual KELIP can capture cultural differences of visual semantics for the same meaning of words; 4) a large-scale multimodal model can be used for multimodal feature analogy. We hope that this work will provide helpful experience and findings for future research. We provide an open-source pre-trained KELIP.
Privacy-preserving Generative Framework Against Membership Inference Attacks
Feb 11, 2022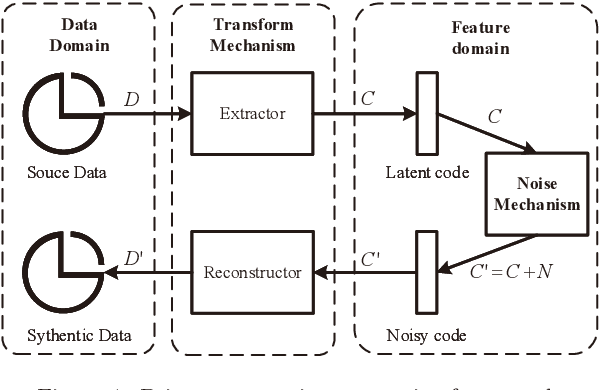
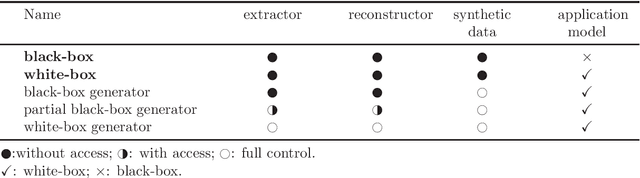
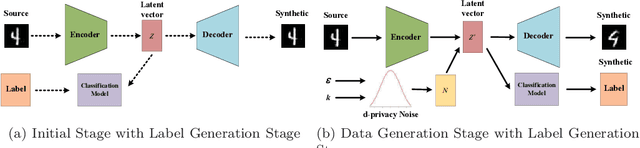

Artificial intelligence and machine learning have been integrated into all aspects of our lives and the privacy of personal data has attracted more and more attention. Since the generation of the model needs to extract the effective information of the training data, the model has the risk of leaking the privacy of the training data. Membership inference attacks can measure the model leakage of source data to a certain degree. In this paper, we design a privacy-preserving generative framework against membership inference attacks, through the information extraction and data generation capabilities of the generative model variational autoencoder (VAE) to generate synthetic data that meets the needs of differential privacy. Instead of adding noise to the model output or tampering with the training process of the target model, we directly process the original data. We first map the source data to the latent space through the VAE model to get the latent code, then perform noise process satisfying metric privacy on the latent code, and finally use the VAE model to reconstruct the synthetic data. Our experimental evaluation demonstrates that the machine learning model trained with newly generated synthetic data can effectively resist membership inference attacks and still maintain high utility.
Efficient Long Sequence Encoding via Synchronization
Mar 15, 2022
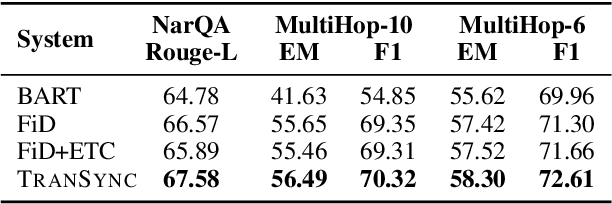
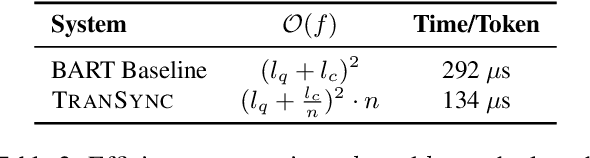
Pre-trained Transformer models have achieved successes in a wide range of NLP tasks, but are inefficient when dealing with long input sequences. Existing studies try to overcome this challenge via segmenting the long sequence followed by hierarchical encoding or post-hoc aggregation. We propose a synchronization mechanism for hierarchical encoding. Our approach first identifies anchor tokens across segments and groups them by their roles in the original input sequence. Then inside Transformer layer, anchor embeddings are synchronized within their group via a self-attention module. Our approach is a general framework with sufficient flexibility -- when adapted to a new task, it is easy to be enhanced with the task-specific anchor definitions. Experiments on two representative tasks with different types of long input texts, NarrativeQA summary setting and wild multi-hop reasoning from HotpotQA, demonstrate that our approach is able to improve the global information exchange among segments while maintaining efficiency.
On Mutual Information in Contrastive Learning for Visual Representations
May 27, 2020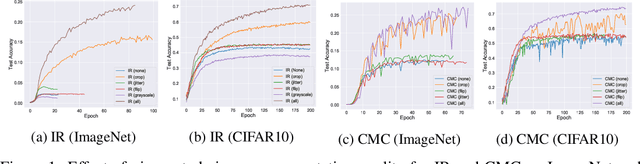
In recent years, several unsupervised, "contrastive" learning algorithms in vision have been shown to learn representations that perform remarkably well on transfer tasks. We show that this family of algorithms maximizes a lower bound on the mutual information between two or more "views" of an image; typical views come from a composition of image augmentations. Our bound generalizes the InfoNCE objective to support negative sampling from a restricted region of "difficult" contrasts. We find that the choice of (1) negative samples and (2) "views" are critical to the success of contrastive learning, the former of which is largely unexplored. The mutual information reformulation also simplifies and stabilizes previous learning objectives. In practice, our new objectives yield representations that outperform those learned with previous approaches for transfer to classification, bounding box detection, instance segmentation, and keypoint detection. The mutual information framework provides a unifying and rigorous comparison of approaches to contrastive learning and uncovers the choices that impact representation learning.
TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music
Feb 02, 2022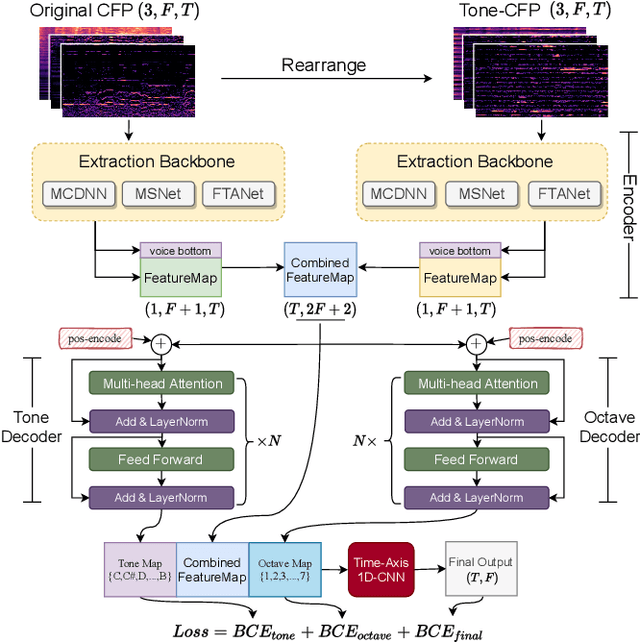
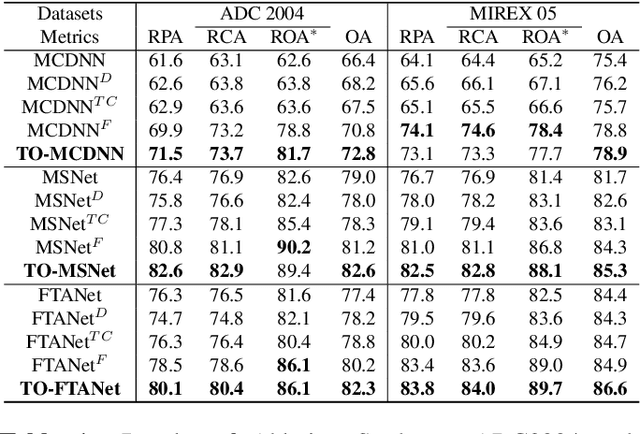
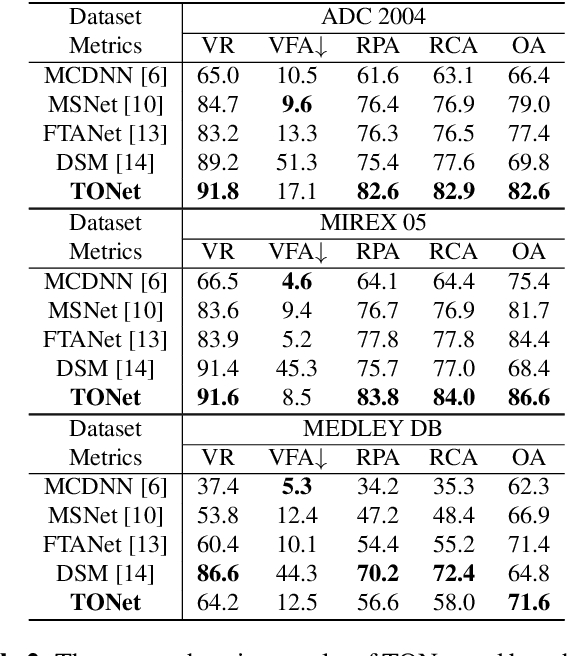
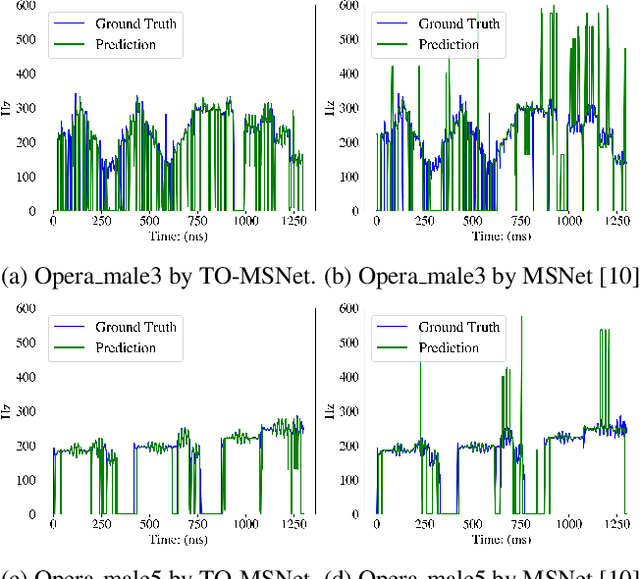
Singing melody extraction is an important problem in the field of music information retrieval. Existing methods typically rely on frequency-domain representations to estimate the sung frequencies. However, this design does not lead to human-level performance in the perception of melody information for both tone (pitch-class) and octave. In this paper, we propose TONet, a plug-and-play model that improves both tone and octave perceptions by leveraging a novel input representation and a novel network architecture. First, we present an improved input representation, the Tone-CFP, that explicitly groups harmonics via a rearrangement of frequency-bins. Second, we introduce an encoder-decoder architecture that is designed to obtain a salience feature map, a tone feature map, and an octave feature map. Third, we propose a tone-octave fusion mechanism to improve the final salience feature map. Experiments are done to verify the capability of TONet with various baseline backbone models. Our results show that tone-octave fusion with Tone-CFP can significantly improve the singing voice extraction performance across various datasets -- with substantial gains in octave and tone accuracy.
Leveraging Pre-trained BERT for Audio Captioning
Mar 27, 2022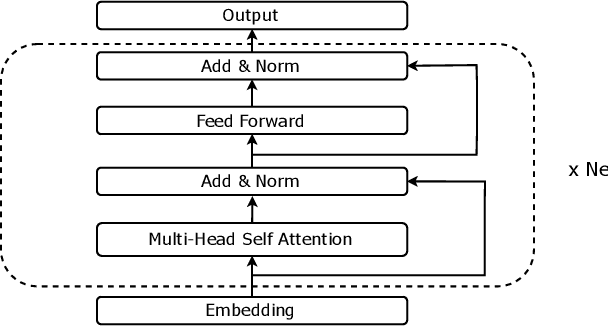
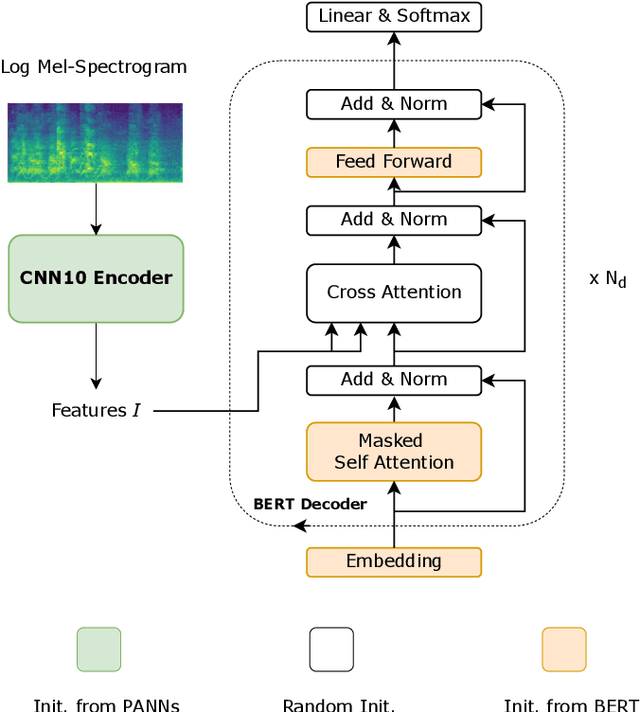
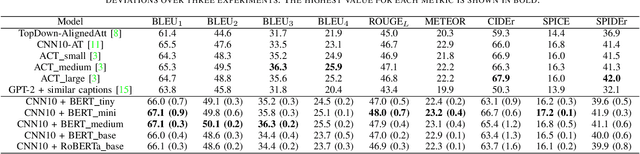
Audio captioning aims at using natural language to describe the content of an audio clip. Existing audio captioning systems are generally based on an encoder-decoder architecture, in which acoustic information is extracted by an audio encoder and then a language decoder is used to generate the captions. Training an audio captioning system often encounters the problem of data scarcity. Transferring knowledge from pre-trained audio models such as Pre-trained Audio Neural Networks (PANNs) have recently emerged as a useful method to mitigate this issue. However, there is less attention on exploiting pre-trained language models for the decoder, compared with the encoder. BERT is a pre-trained language model that has been extensively used in Natural Language Processing (NLP) tasks. Nevertheless, the potential of BERT as the language decoder for audio captioning has not been investigated. In this study, we demonstrate the efficacy of the pre-trained BERT model for audio captioning. Specifically, we apply PANNs as the encoder and initialize the decoder from the public pre-trained BERT models. We conduct an empirical study on the use of these BERT models for the decoder in the audio captioning model. Our models achieve competitive results with the existing audio captioning methods on the AudioCaps dataset.
CLRNet: Cross Layer Refinement Network for Lane Detection
Mar 19, 2022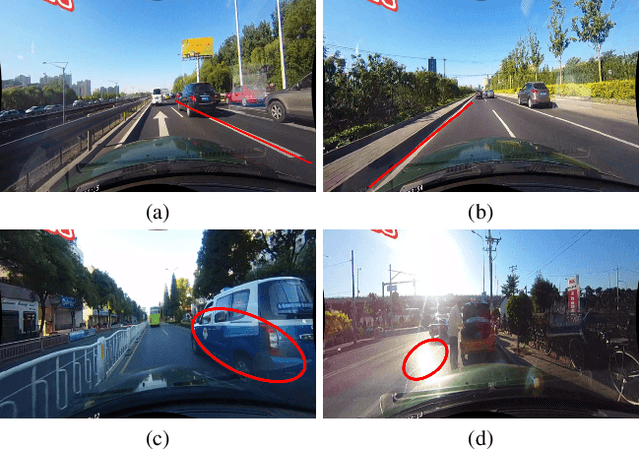
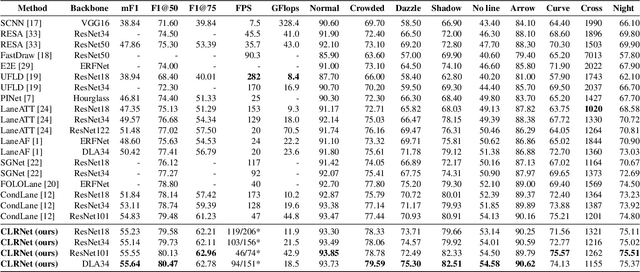
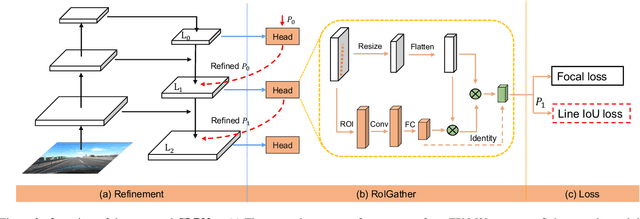
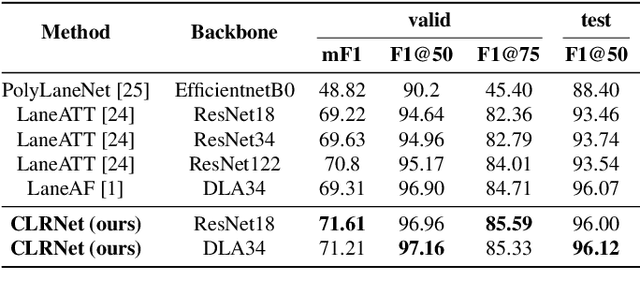
Lane is critical in the vision navigation system of the intelligent vehicle. Naturally, lane is a traffic sign with high-level semantics, whereas it owns the specific local pattern which needs detailed low-level features to localize accurately. Using different feature levels is of great importance for accurate lane detection, but it is still under-explored. In this work, we present Cross Layer Refinement Network (CLRNet) aiming at fully utilizing both high-level and low-level features in lane detection. In particular, it first detects lanes with high-level semantic features then performs refinement based on low-level features. In this way, we can exploit more contextual information to detect lanes while leveraging local detailed lane features to improve localization accuracy. We present ROIGather to gather global context, which further enhances the feature representation of lanes. In addition to our novel network design, we introduce Line IoU loss which regresses the lane line as a whole unit to improve the localization accuracy. Experiments demonstrate that the proposed method greatly outperforms the state-of-the-art lane detection approaches.
The Variational Bandwidth Bottleneck: Stochastic Evaluation on an Information Budget
Apr 24, 2020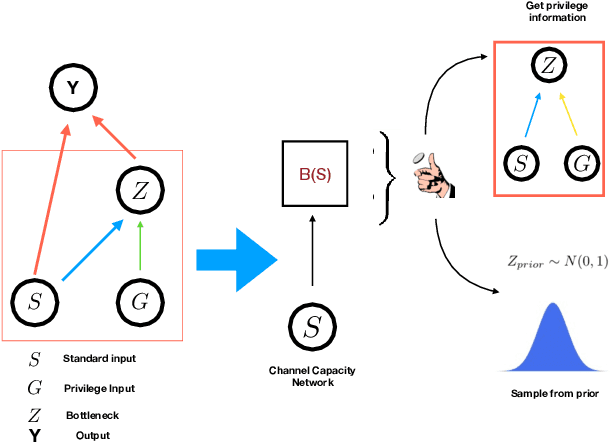

In many applications, it is desirable to extract only the relevant information from complex input data, which involves making a decision about which input features are relevant. The information bottleneck method formalizes this as an information-theoretic optimization problem by maintaining an optimal tradeoff between compression (throwing away irrelevant input information), and predicting the target. In many problem settings, including the reinforcement learning problems we consider in this work, we might prefer to compress only part of the input. This is typically the case when we have a standard conditioning input, such as a state observation, and a "privileged" input, which might correspond to the goal of a task, the output of a costly planning algorithm, or communication with another agent. In such cases, we might prefer to compress the privileged input, either to achieve better generalization (e.g., with respect to goals) or to minimize access to costly information (e.g., in the case of communication). Practical implementations of the information bottleneck based on variational inference require access to the privileged input in order to compute the bottleneck variable, so although they perform compression, this compression operation itself needs unrestricted, lossless access. In this work, we propose the variational bandwidth bottleneck, which decides for each example on the estimated value of the privileged information before seeing it, i.e., only based on the standard input, and then accordingly chooses stochastically, whether to access the privileged input or not. We formulate a tractable approximation to this framework and demonstrate in a series of reinforcement learning experiments that it can improve generalization and reduce access to computationally costly information.
Does prior knowledge in the form of multiple low-dose PET images (at different dose levels) improve standard-dose PET prediction?
Feb 22, 2022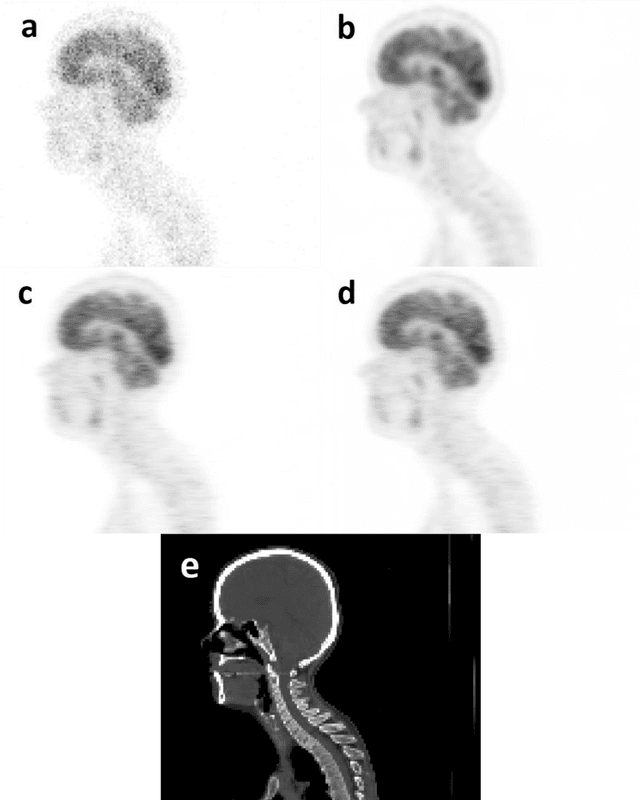
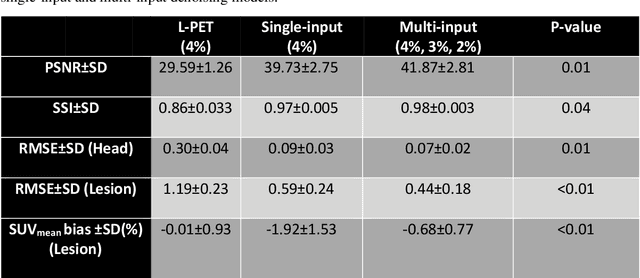
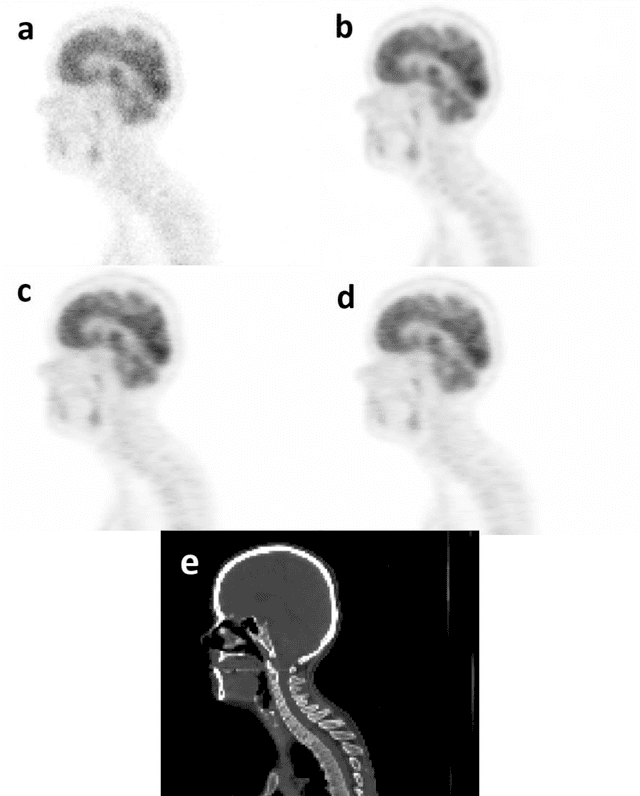
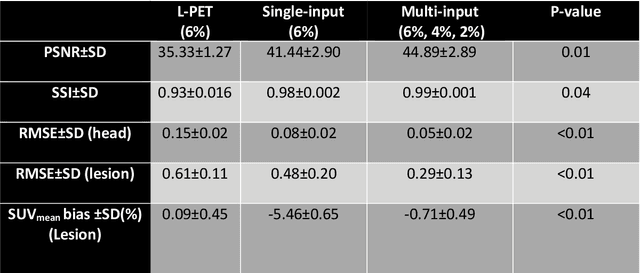
Reducing the injected dose would result in quality degradation and loss of information in PET imaging. To address this issue, deep learning methods have been introduced to predict standard PET images (S-PET) from the corresponding low-dose versions (L-PET). The existing deep learning-based denoising methods solely rely on a single dose level of PET images to predict the S-PET images. In this work, we proposed to exploit the prior knowledge in the form of multiple low-dose levels of PET images (in addition to the target low-dose level) to estimate the S-PET images.
Reading-strategy Inspired Visual Representation Learning for Text-to-Video Retrieval
Jan 23, 2022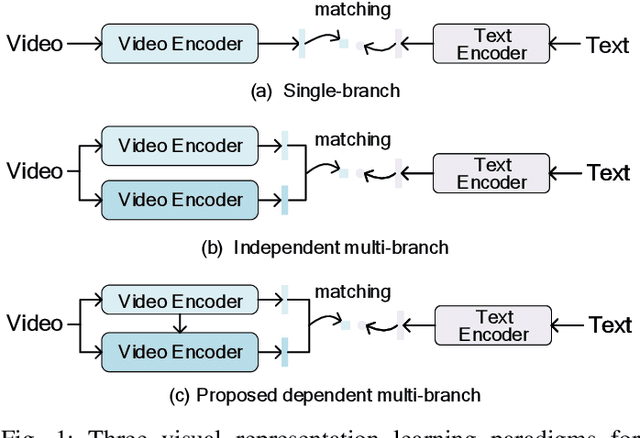
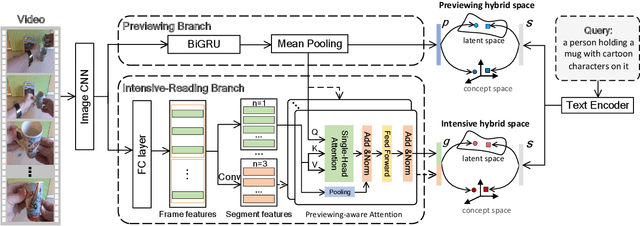
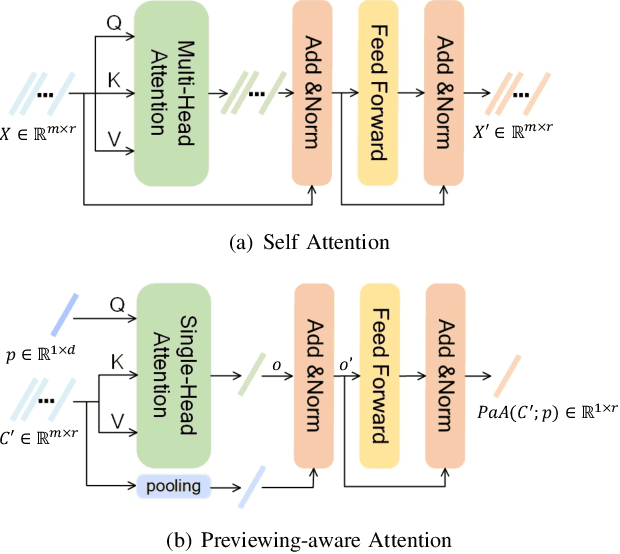
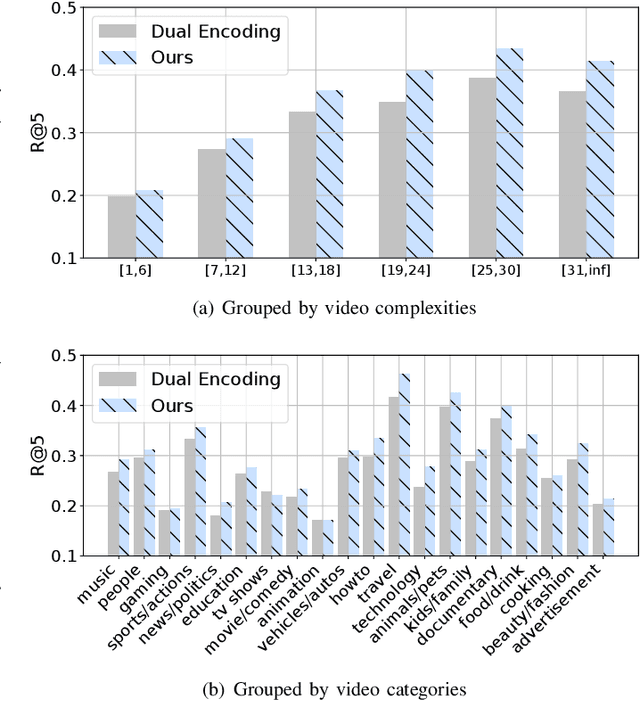
This paper aims for the task of text-to-video retrieval, where given a query in the form of a natural-language sentence, it is asked to retrieve videos which are semantically relevant to the given query, from a great number of unlabeled videos. The success of this task depends on cross-modal representation learning that projects both videos and sentences into common spaces for semantic similarity computation. In this work, we concentrate on video representation learning, an essential component for text-to-video retrieval. Inspired by the reading strategy of humans, we propose a Reading-strategy Inspired Visual Representation Learning (RIVRL) to represent videos, which consists of two branches: a previewing branch and an intensive-reading branch. The previewing branch is designed to briefly capture the overview information of videos, while the intensive-reading branch is designed to obtain more in-depth information. Moreover, the intensive-reading branch is aware of the video overview captured by the previewing branch. Such holistic information is found to be useful for the intensive-reading branch to extract more fine-grained features. Extensive experiments on three datasets are conducted, where our model RIVRL achieves a new state-of-the-art on TGIF and VATEX. Moreover, on MSR-VTT, our model using two video features shows comparable performance to the state-of-the-art using seven video features and even outperforms models pre-trained on the large-scale HowTo100M dataset.