 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Analysis of Voice Conversion and Code-Switching Synthesis Using VQ-VAE
Mar 28, 2022
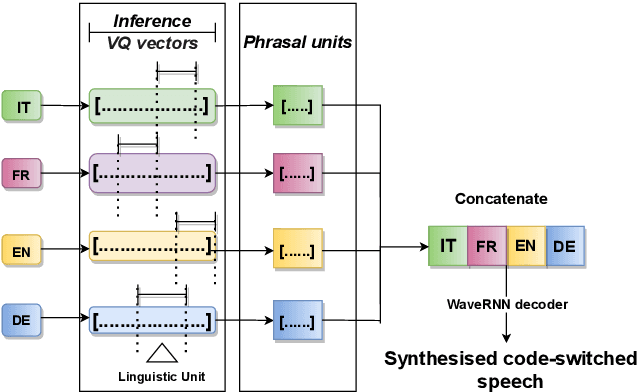
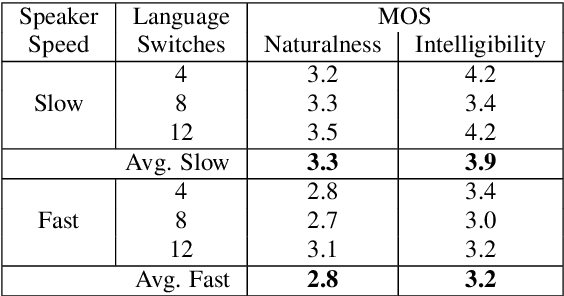
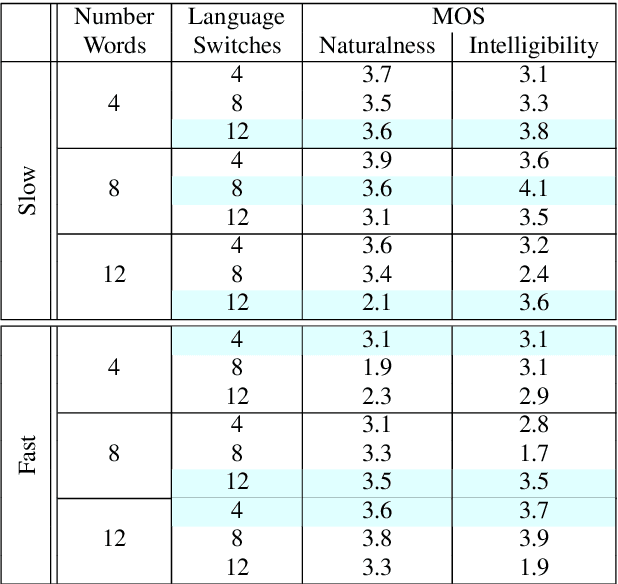
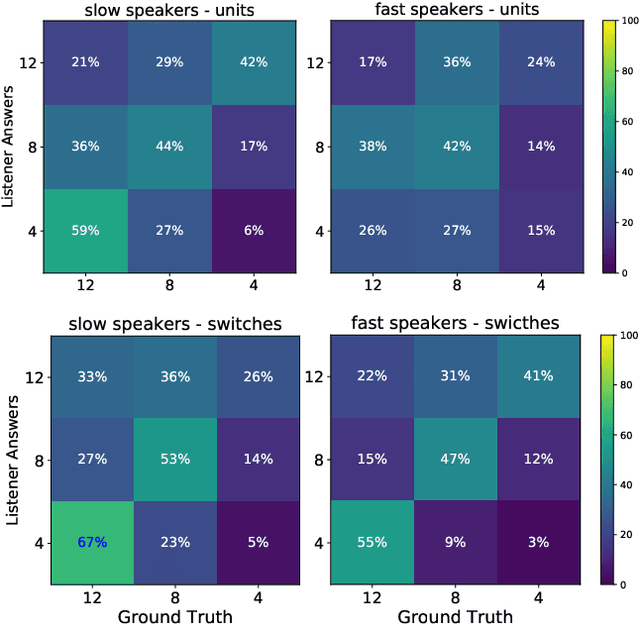
This paper presents an analysis of speech synthesis quality achieved by simultaneously performing voice conversion and language code-switching using multilingual VQ-VAE speech synthesis in German, French, English and Italian. In this paper, we utilize VQ code indices representing phone information from VQ-VAE to perform code-switching and a VQ speaker code to perform voice conversion in a single system with a neural vocoder. Our analysis examines several aspects of code-switching including the number of language switches and the number of words involved in each switch. We found that speech synthesis quality degrades after increasing the number of language switches within an utterance and decreasing the number of words. We also found some evidence of accent transfer when performing voice conversion across languages as observed when a speaker's original language differs from the language of a synthetic target utterance. We present results from our listening tests and discuss the inherent difficulties of assessing accent transfer in speech synthesis. Our work highlights some of the limitations and strengths of using a semi-supervised end-to-end system like VQ-VAE for handling multilingual synthesis. Our work provides insight into why multilingual speech synthesis is challenging and we suggest some directions for expanding work in this area.
Privacy-preserving Generative Framework Against Membership Inference Attacks
Feb 11, 2022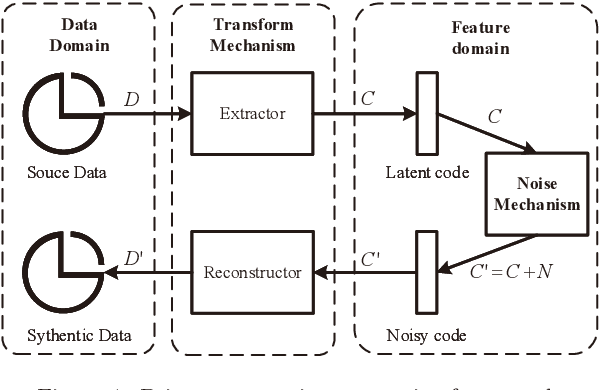
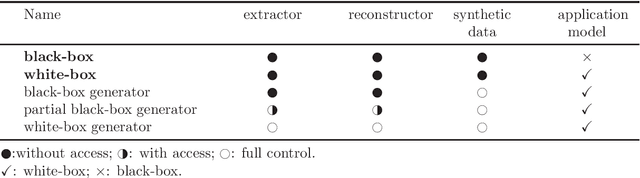
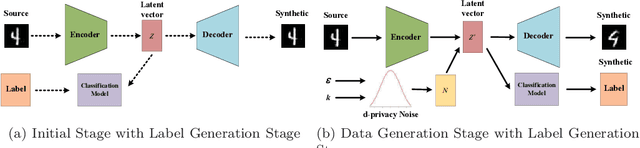

Artificial intelligence and machine learning have been integrated into all aspects of our lives and the privacy of personal data has attracted more and more attention. Since the generation of the model needs to extract the effective information of the training data, the model has the risk of leaking the privacy of the training data. Membership inference attacks can measure the model leakage of source data to a certain degree. In this paper, we design a privacy-preserving generative framework against membership inference attacks, through the information extraction and data generation capabilities of the generative model variational autoencoder (VAE) to generate synthetic data that meets the needs of differential privacy. Instead of adding noise to the model output or tampering with the training process of the target model, we directly process the original data. We first map the source data to the latent space through the VAE model to get the latent code, then perform noise process satisfying metric privacy on the latent code, and finally use the VAE model to reconstruct the synthetic data. Our experimental evaluation demonstrates that the machine learning model trained with newly generated synthetic data can effectively resist membership inference attacks and still maintain high utility.
Interpretability of Fine-grained Classification of Sadness and Depression
Mar 20, 2022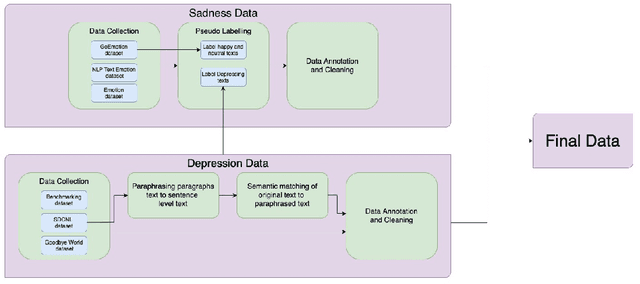

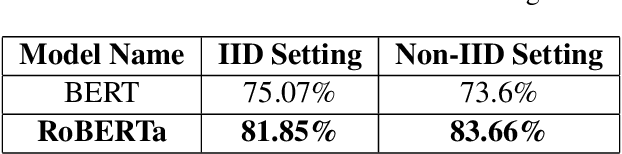

While sadness is a human emotion that people experience at certain times throughout their lives, inflicting them with emotional disappointment and pain, depression is a longer term mental illness which impairs social, occupational, and other vital regions of functioning making it a much more serious issue and needs to be catered to at the earliest. NLP techniques can be utilized for the detection and subsequent diagnosis of these emotions. Most of the open sourced data on the web deal with sadness as a part of depression, as an emotion even though the difference in severity of both is huge. Thus, we create our own novel dataset illustrating the difference between the two. In this paper, we aim to highlight the difference between the two and highlight how interpretable our models are to distinctly label sadness and depression. Due to the sensitive nature of such information, privacy measures need to be taken for handling and training of such data. Hence, we also explore the effect of Federated Learning (FL) on contextualised language models.
PAC-Bayesian Lifelong Learning For Multi-Armed Bandits
Mar 07, 2022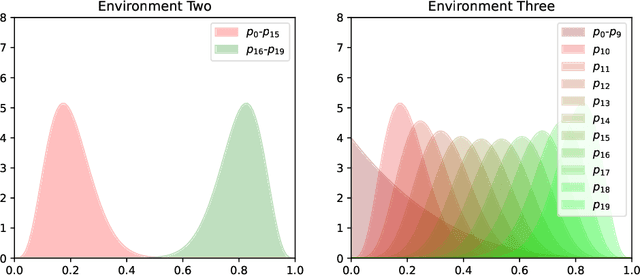
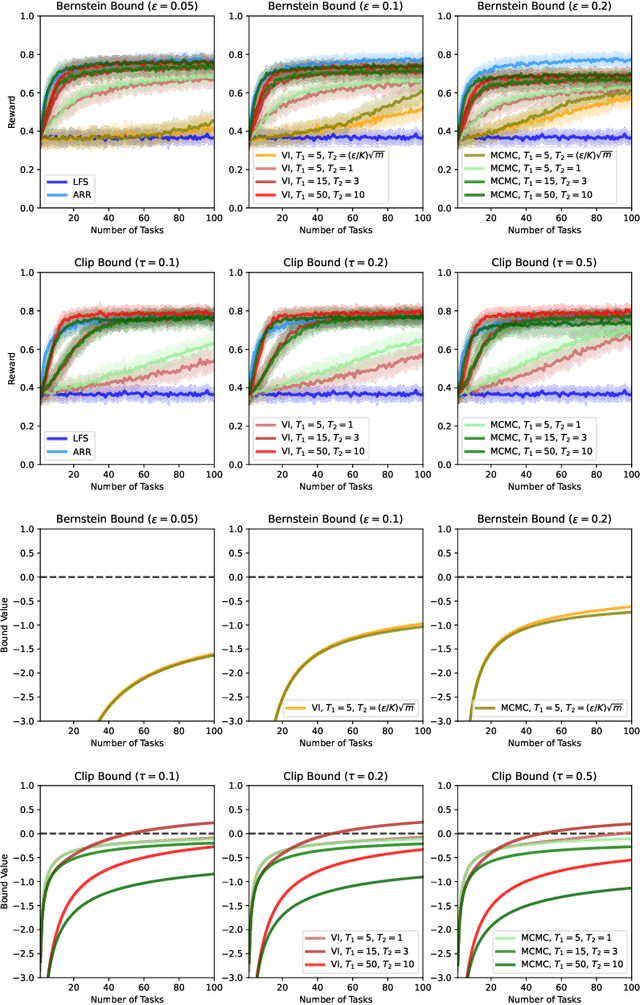
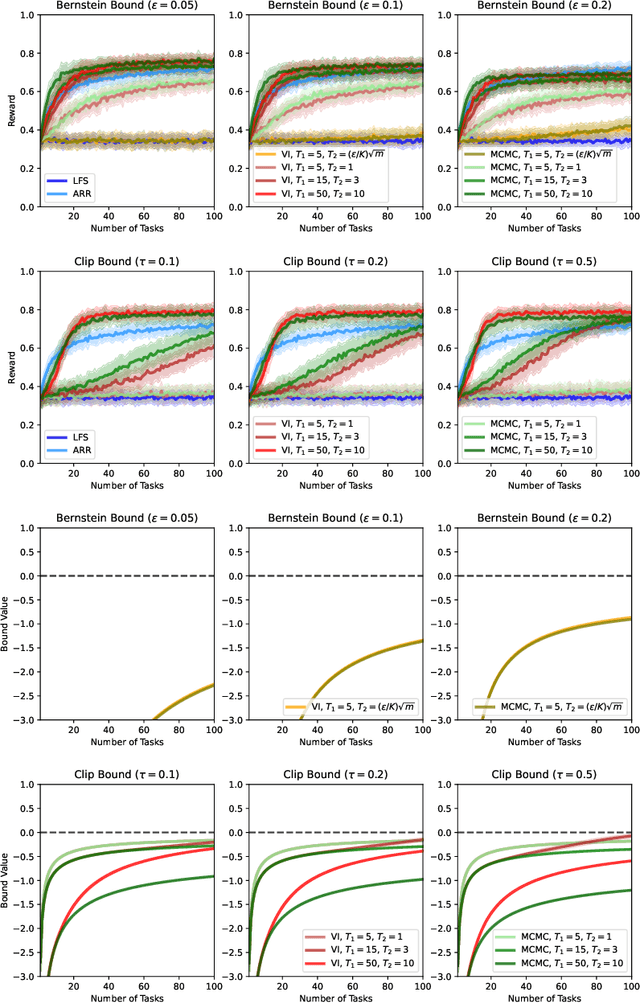
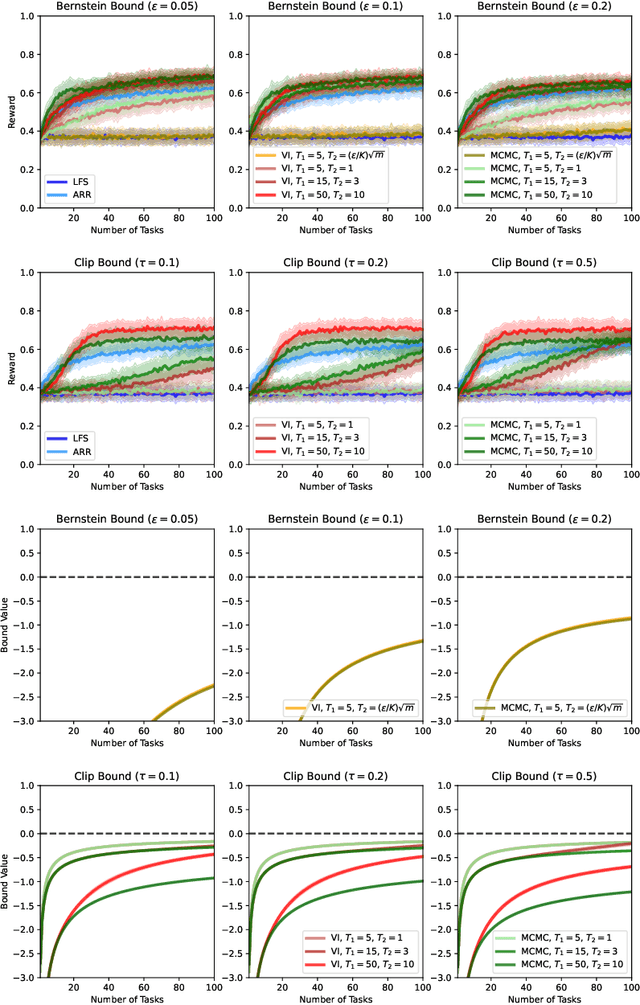
We present a PAC-Bayesian analysis of lifelong learning. In the lifelong learning problem, a sequence of learning tasks is observed one-at-a-time, and the goal is to transfer information acquired from previous tasks to new learning tasks. We consider the case when each learning task is a multi-armed bandit problem. We derive lower bounds on the expected average reward that would be obtained if a given multi-armed bandit algorithm was run in a new task with a particular prior and for a set number of steps. We propose lifelong learning algorithms that use our new bounds as learning objectives. Our proposed algorithms are evaluated in several lifelong multi-armed bandit problems and are found to perform better than a baseline method that does not use generalisation bounds.
* 29 pages, 5 figures
TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music
Feb 02, 2022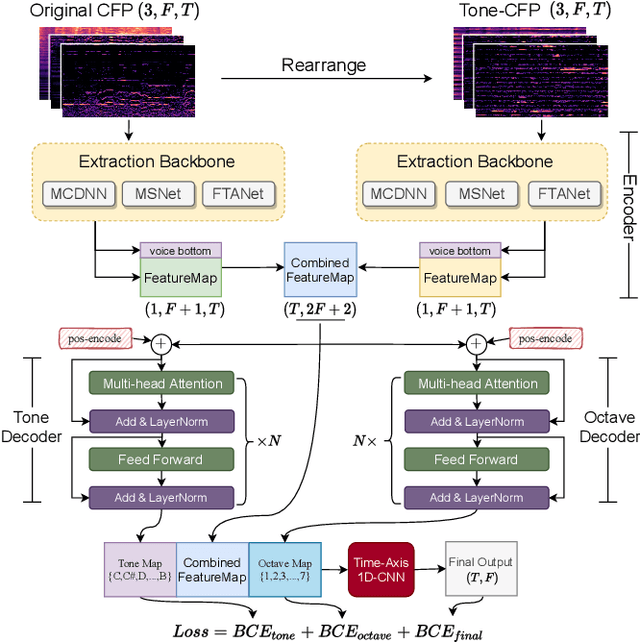
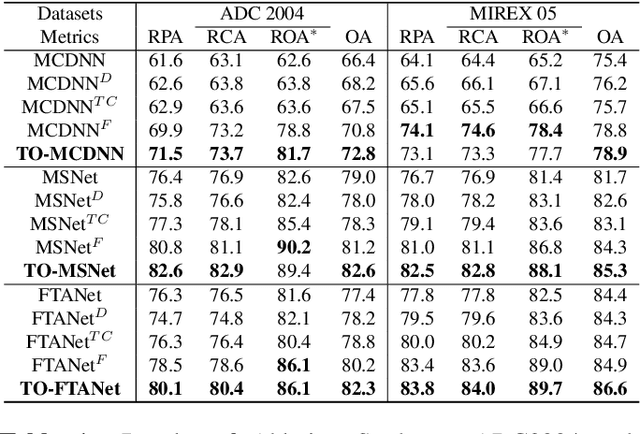
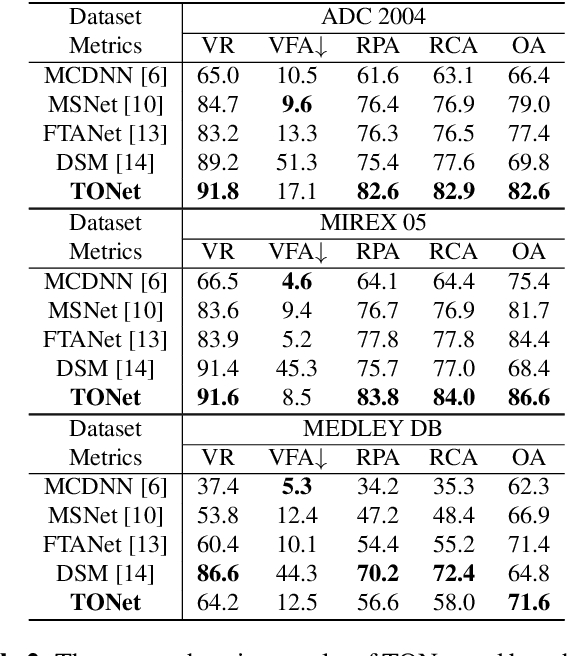
Singing melody extraction is an important problem in the field of music information retrieval. Existing methods typically rely on frequency-domain representations to estimate the sung frequencies. However, this design does not lead to human-level performance in the perception of melody information for both tone (pitch-class) and octave. In this paper, we propose TONet, a plug-and-play model that improves both tone and octave perceptions by leveraging a novel input representation and a novel network architecture. First, we present an improved input representation, the Tone-CFP, that explicitly groups harmonics via a rearrangement of frequency-bins. Second, we introduce an encoder-decoder architecture that is designed to obtain a salience feature map, a tone feature map, and an octave feature map. Third, we propose a tone-octave fusion mechanism to improve the final salience feature map. Experiments are done to verify the capability of TONet with various baseline backbone models. Our results show that tone-octave fusion with Tone-CFP can significantly improve the singing voice extraction performance across various datasets -- with substantial gains in octave and tone accuracy.
BERTuit: Understanding Spanish language in Twitter through a native transformer
Apr 07, 2022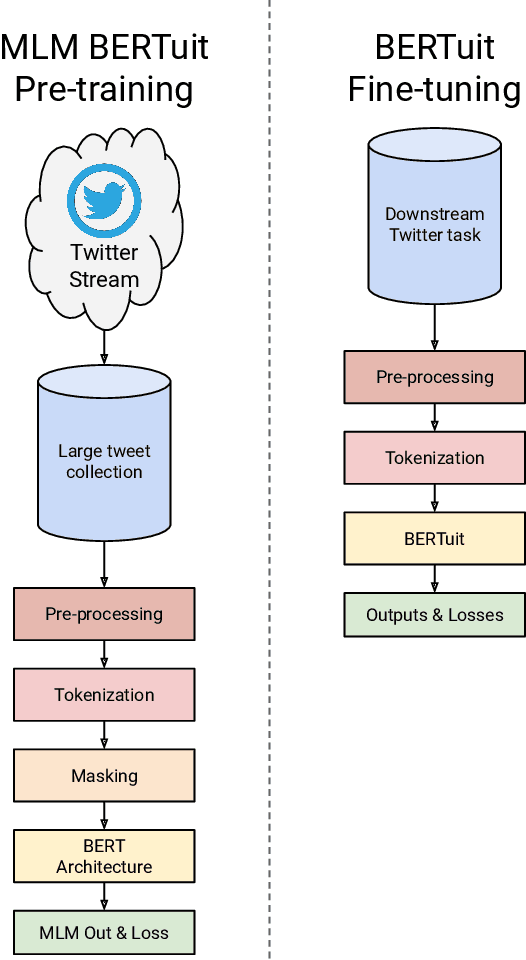

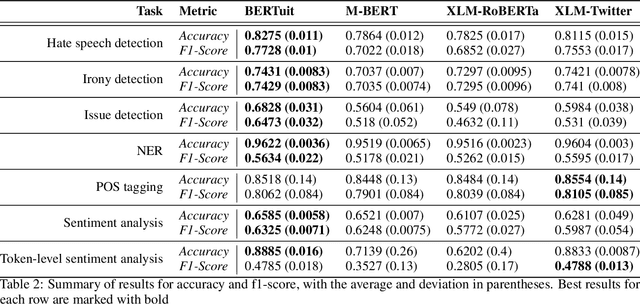
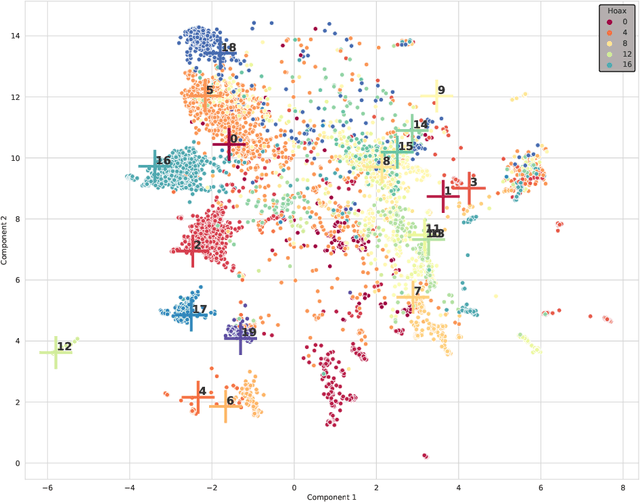
The appearance of complex attention-based language models such as BERT, Roberta or GPT-3 has allowed to address highly complex tasks in a plethora of scenarios. However, when applied to specific domains, these models encounter considerable difficulties. This is the case of Social Networks such as Twitter, an ever-changing stream of information written with informal and complex language, where each message requires careful evaluation to be understood even by humans given the important role that context plays. Addressing tasks in this domain through Natural Language Processing involves severe challenges. When powerful state-of-the-art multilingual language models are applied to this scenario, language specific nuances use to get lost in translation. To face these challenges we present \textbf{BERTuit}, the larger transformer proposed so far for Spanish language, pre-trained on a massive dataset of 230M Spanish tweets using RoBERTa optimization. Our motivation is to provide a powerful resource to better understand Spanish Twitter and to be used on applications focused on this social network, with special emphasis on solutions devoted to tackle the spreading of misinformation in this platform. BERTuit is evaluated on several tasks and compared against M-BERT, XLM-RoBERTa and XLM-T, very competitive multilingual transformers. The utility of our approach is shown with applications, in this case: a zero-shot methodology to visualize groups of hoaxes and profiling authors spreading disinformation. Misinformation spreads wildly on platforms such as Twitter in languages other than English, meaning performance of transformers may suffer when transferred outside English speaking communities.
Semi-Weakly Supervised Object Detection by Sampling Pseudo Ground-Truth Boxes
Apr 01, 2022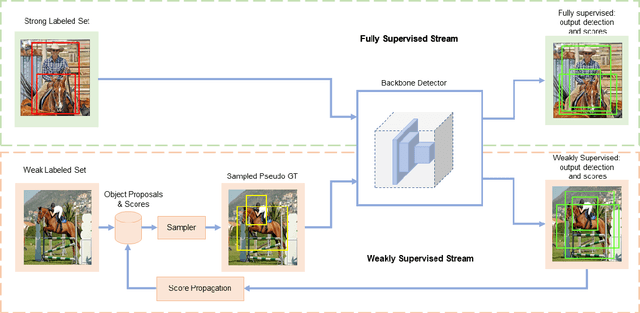

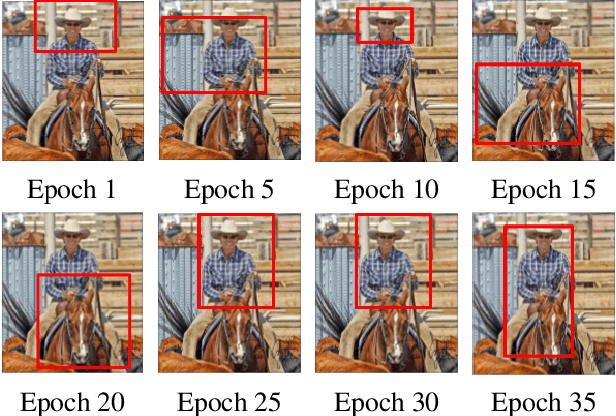

Semi- and weakly-supervised learning have recently attracted considerable attention in the object detection literature since they can alleviate the cost of annotation needed to successfully train deep learning models. State-of-art approaches for semi-supervised learning rely on student-teacher models trained using a multi-stage process, and considerable data augmentation. Custom networks have been developed for the weakly-supervised setting, making it difficult to adapt to different detectors. In this paper, a weakly semi-supervised training method is introduced that reduces these training challenges, yet achieves state-of-the-art performance by leveraging only a small fraction of fully-labeled images with information in weakly-labeled images. In particular, our generic sampling-based learning strategy produces pseudo-ground-truth (GT) bounding box annotations in an online fashion, eliminating the need for multi-stage training, and student-teacher network configurations. These pseudo GT boxes are sampled from weakly-labeled images based on the categorical score of object proposals accumulated via a score propagation process. Empirical results on the Pascal VOC dataset, indicate that the proposed approach improves performance by 5.0% when using VOC 2007 as fully-labeled, and VOC 2012 as weak-labeled data. Also, with 5-10% fully annotated images, we observed an improvement of more than 10% in mAP, showing that a modest investment in image-level annotation, can substantially improve detection performance.
Reviewing continual learning from the perspective of human-level intelligence
Nov 23, 2021
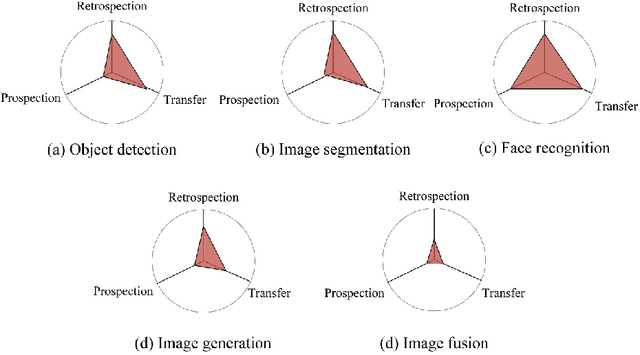
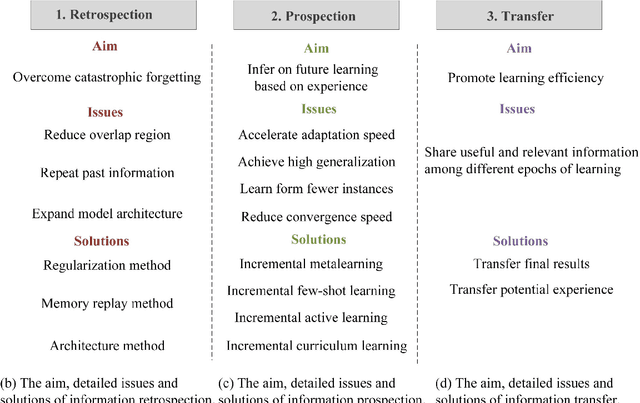
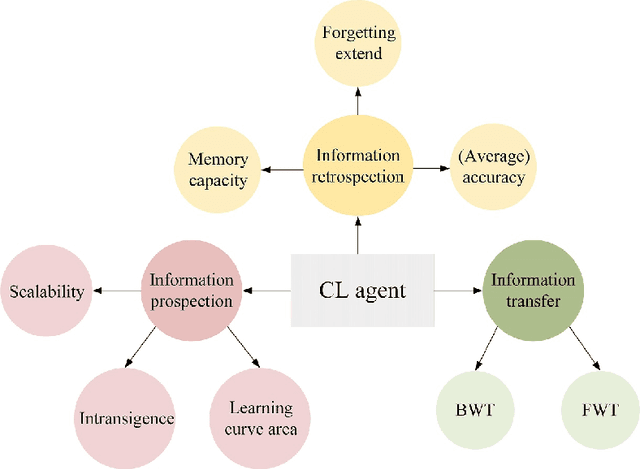
Humans' continual learning (CL) ability is closely related to Stability Versus Plasticity Dilemma that describes how humans achieve ongoing learning capacity and preservation for learned information. The notion of CL has always been present in artificial intelligence (AI) since its births. This paper proposes a comprehensive review of CL. Different from previous reviews that mainly focus on the catastrophic forgetting phenomenon in CL, this paper surveys CL from a more macroscopic perspective based on the Stability Versus Plasticity mechanism. Analogous to biological counterpart, "smart" AI agents are supposed to i) remember previously learned information (information retrospection); ii) infer on new information continuously (information prospection:); iii) transfer useful information (information transfer), to achieve high-level CL. According to the taxonomy, evaluation metrics, algorithms, applications as well as some open issues are then introduced. Our main contributions concern i) rechecking CL from the level of artificial general intelligence; ii) providing a detailed and extensive overview on CL topics; iii) presenting some novel ideas on the potential development of CL.
Pyramid Feature Alignment Network for Video Deblurring
Mar 28, 2022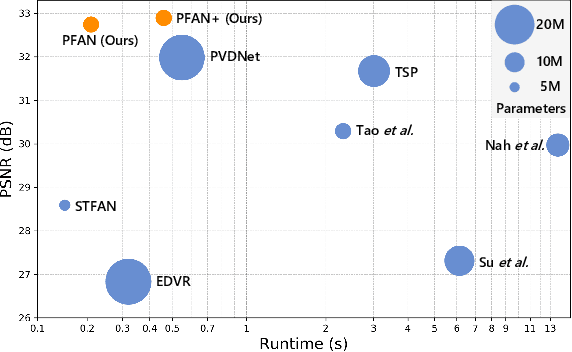
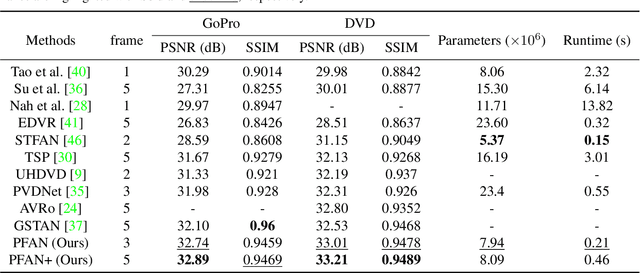
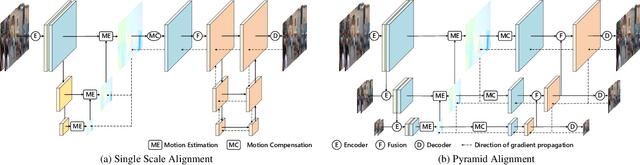

Video deblurring remains a challenging task due to various causes of blurring. Traditional methods have considered how to utilize neighboring frames by the single-scale alignment for restoration. However, they typically suffer from misalignment caused by severe blur. In this work, we aim to better utilize neighboring frames with high efficient feature alignment. We propose a Pyramid Feature Alignment Network (PFAN) for video deblurring. First, the multi-scale feature of blurry frames is extracted with the strategy of Structure-to-Detail Downsampling (SDD) before alignment. This downsampling strategy makes the edges sharper, which is helpful for alignment. Then we align the feature at each scale and reconstruct the image at the corresponding scale. This strategy effectively supervises the alignment at each scale, overcoming the problem of propagated errors from the above scales at the alignment stage. To better handle the challenges of complex and large motions, instead of aligning features at each scale separately, lower-scale motion information is used to guide the higher-scale motion estimation. Accordingly, a Cascade Guided Deformable Alignment (CGDA) is proposed to integrate coarse motion into deformable convolution for finer and more accurate alignment. As demonstrated in extensive experiments, our proposed PFAN achieves superior performance with competitive speed compared to the state-of-the-art methods.
Syntax-Aware Network for Handwritten Mathematical Expression Recognition
Mar 28, 2022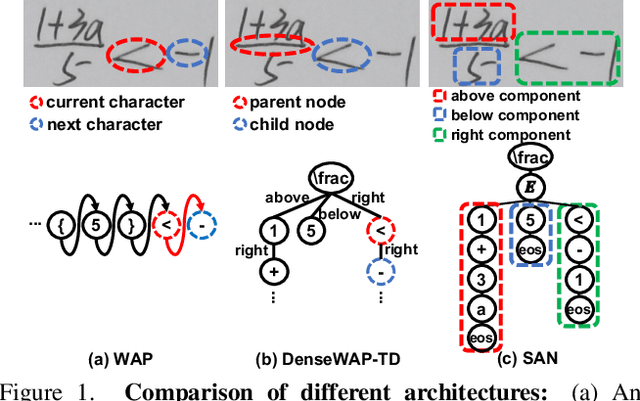

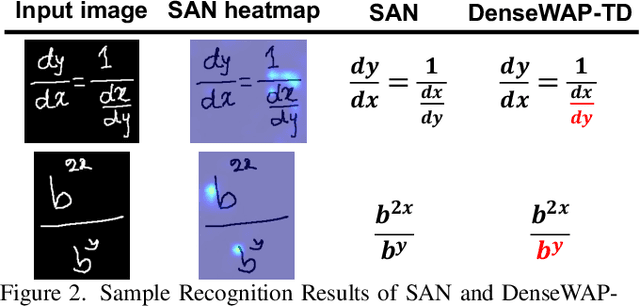
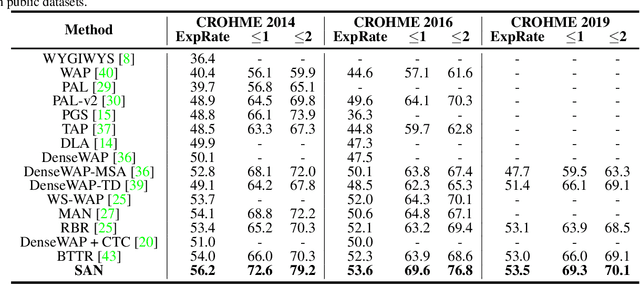
Handwritten mathematical expression recognition (HMER) is a challenging task that has many potential applications. Recent methods for HMER have achieved outstanding performance with an encoder-decoder architecture. However, these methods adhere to the paradigm that the prediction is made "from one character to another", which inevitably yields prediction errors due to the complicated structures of mathematical expressions or crabbed handwritings. In this paper, we propose a simple and efficient method for HMER, which is the first to incorporate syntax information into an encoder-decoder network. Specifically, we present a set of grammar rules for converting the LaTeX markup sequence of each expression into a parsing tree; then, we model the markup sequence prediction as a tree traverse process with a deep neural network. In this way, the proposed method can effectively describe the syntax context of expressions, alleviating the structure prediction errors of HMER. Experiments on three benchmark datasets demonstrate that our method achieves better recognition performance than prior arts. To further validate the effectiveness of our method, we create a large-scale dataset consisting of 100k handwritten mathematical expression images acquired from ten thousand writers. The source code, new dataset, and pre-trained models of this work will be publicly available.