 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improved and Efficient Conversational Slot Labeling through Question Answering
Apr 05, 2022

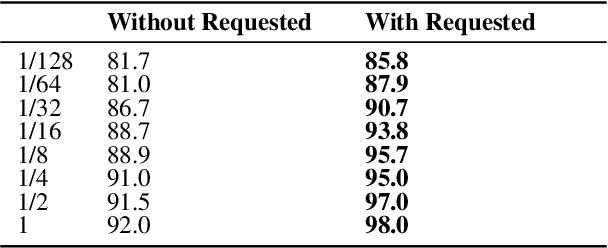
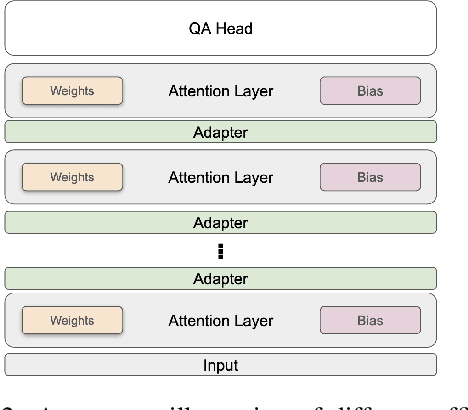
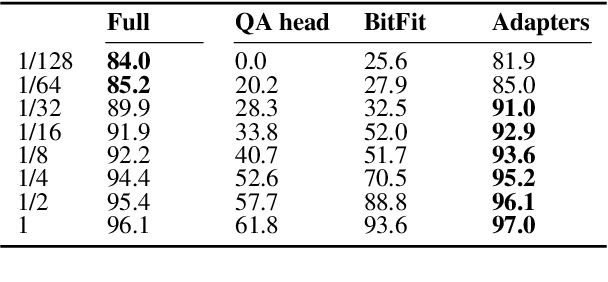
Transformer-based pretrained language models (PLMs) offer unmatched performance across the majority of natural language understanding (NLU) tasks, including a body of question answering (QA) tasks. We hypothesize that improvements in QA methodology can also be directly exploited in dialog NLU; however, dialog tasks must be \textit{reformatted} into QA tasks. In particular, we focus on modeling and studying \textit{slot labeling} (SL), a crucial component of NLU for dialog, through the QA optics, aiming to improve both its performance and efficiency, and make it more effective and resilient to working with limited task data. To this end, we make a series of contributions: 1) We demonstrate how QA-tuned PLMs can be applied to the SL task, reaching new state-of-the-art performance, with large gains especially pronounced in such low-data regimes. 2) We propose to leverage contextual information, required to tackle ambiguous values, simply through natural language. 3) Efficiency and compactness of QA-oriented fine-tuning are boosted through the use of lightweight yet effective adapter modules. 4) Trading-off some of the quality of QA datasets for their size, we experiment with larger automatically generated QA datasets for QA-tuning, arriving at even higher performance. Finally, our analysis suggests that our novel QA-based slot labeling models, supported by the PLMs, reach a performance ceiling in high-data regimes, calling for more challenging and more nuanced benchmarks in future work.
Research Scholar Interest Mining Method based on Load Centrality
Mar 21, 2022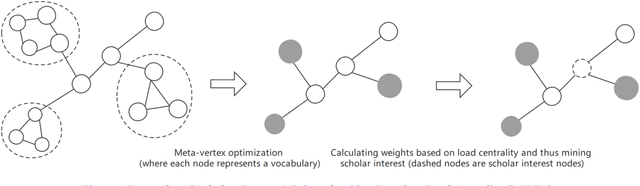
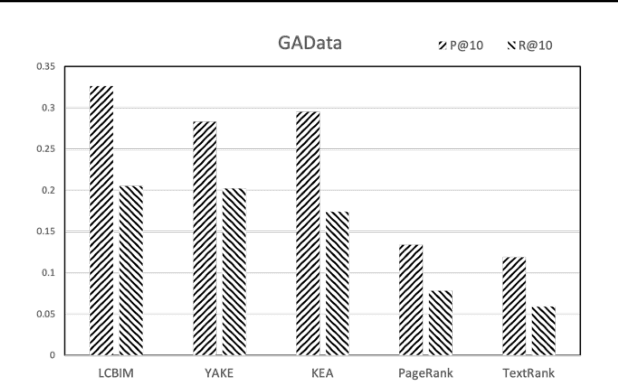
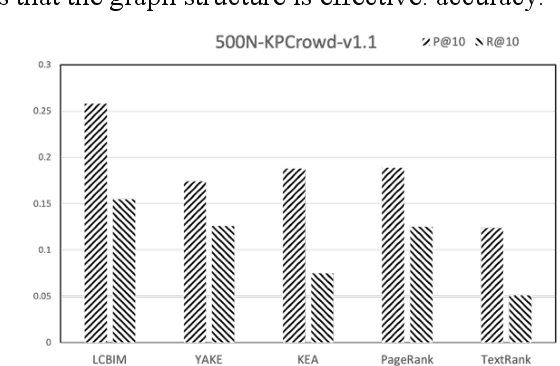
In the era of big data, it is possible to carry out cooperative research on the research results of researchers through papers, patents and other data, so as to study the role of researchers, and produce results in the analysis of results. For the important problems found in the research and application of reality, this paper also proposes a research scholar interest mining algorithm based on load centrality (LCBIM), which can accurately solve the problem according to the researcher's research papers and patent data. Graphs of creative algorithms in various fields of the study aggregated ideas, generated topic graphs by aggregating neighborhoods, used the generated topic information to construct with similar or similar topic spaces, and utilize keywords to construct one or more topics. The regional structure of each topic can be used to closely calculate the weight of the centrality research model of the node, which can analyze the field in the complete coverage principle. The scientific research cooperation based on the load rate center proposed in this paper can effectively extract the interests of scientific research scholars from papers and corpus.
Embedding Recurrent Layers with Dual-Path Strategy in a Variant of Convolutional Network for Speaker-Independent Speech Separation
Mar 25, 2022
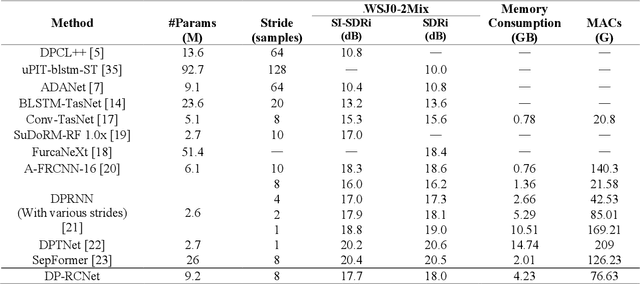
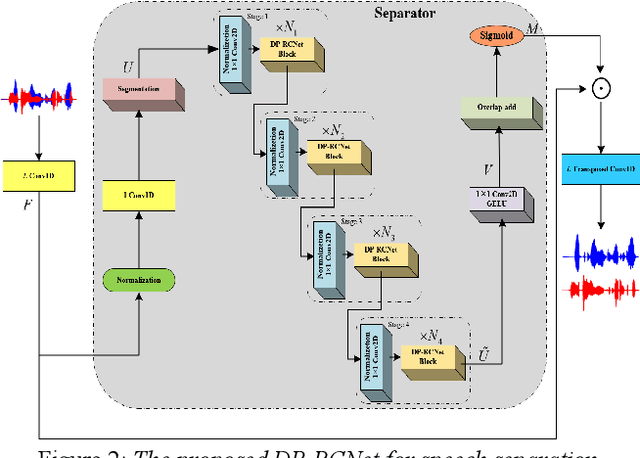
Speaker-independent speech separation has achieved remarkable performance in recent years with the development of deep neural network (DNN). Various network architectures, from traditional convolutional neural network (CNN) and recurrent neural network (RNN) to advanced transformer, have been designed sophistically to improve separation performance. However, the state-of-the-art models usually suffer from several flaws related to the computation, such as large model size, huge memory consumption and computational complexity. To find the balance between the performance and computational efficiency and to further explore the modeling ability of traditional network structure, we combine RNN and a newly proposed variant of convolutional network to cope with speech separation problem. By embedding two RNNs into basic block of this variant with the help of dual-path strategy, the proposed network can effectively learn the local information and global dependency. Besides, a four-staged structure enables the separation procedure to be performed gradually at finer and finer scales as the feature dimension increases. The experimental results on various datasets have proven the effectiveness of the proposed method and shown that a trade-off between the separation performance and computational efficiency is well achieved.
Low-rank features based double transformation matrices learning for image classification
Jan 28, 2022Linear regression is a supervised method that has been widely used in classification tasks. In order to apply linear regression to classification tasks, a technique for relaxing regression targets was proposed. However, methods based on this technique ignore the pressure on a single transformation matrix due to the complex information contained in the data. A single transformation matrix in this case is too strict to provide a flexible projection, thus it is necessary to adopt relaxation on transformation matrix. This paper proposes a double transformation matrices learning method based on latent low-rank feature extraction. The core idea is to use double transformation matrices for relaxation, and jointly projecting the learned principal and salient features from two directions into the label space, which can share the pressure of a single transformation matrix. Firstly, the low-rank features are learned by the latent low rank representation (LatLRR) method which processes the original data from two directions. In this process, sparse noise is also separated, which alleviates its interference on projection learning to some extent. Then, two transformation matrices are introduced to process the two features separately, and the information useful for the classification is extracted. Finally, the two transformation matrices can be easily obtained by alternate optimization methods. Through such processing, even when a large amount of redundant information is contained in samples, our method can also obtain projection results that are easy to classify. Experiments on multiple data sets demonstrate the effectiveness of our approach for classification, especially for complex scenarios.
A Multi-Stage Duplex Fusion ConvNet for Aerial Scene Classification
Mar 29, 2022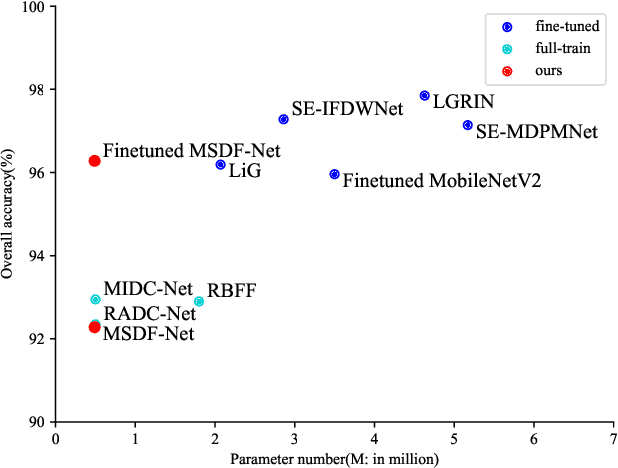

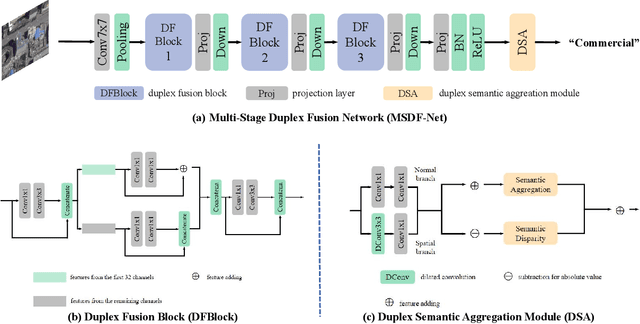

Existing deep learning based methods effectively prompt the performance of aerial scene classification. However, due to the large amount of parameters and computational cost, it is rather difficult to apply these methods to multiple real-time remote sensing applications such as on-board data preception on drones and satellites. In this paper, we address this task by developing a light-weight ConvNet named multi-stage duplex fusion network (MSDF-Net). The key idea is to use parameters as little as possible while obtaining as strong as possible scene representation capability. To this end, a residual-dense duplex fusion strategy is developed to enhance the feature propagation while re-using parameters as much as possible, and is realized by our duplex fusion block (DFblock). Specifically, our MSDF-Net consists of multi-stage structures with DFblock. Moreover, duplex semantic aggregation (DSA) module is developed to mine the remote sensing scene information from extracted convolutional features, which also contains two parallel branches for semantic description. Extensive experiments are conducted on three widely-used aerial scene classification benchmarks, and reflect that our MSDF-Net can achieve a competitive performance against the recent state-of-art while reducing up to 80% parameter numbers. Particularly, an accuracy of 92.96% is achieved on AID with only 0.49M parameters.
On Mutual Information in Contrastive Learning for Visual Representations
May 27, 2020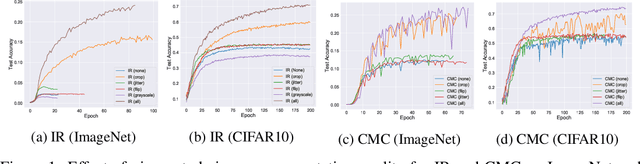
In recent years, several unsupervised, "contrastive" learning algorithms in vision have been shown to learn representations that perform remarkably well on transfer tasks. We show that this family of algorithms maximizes a lower bound on the mutual information between two or more "views" of an image; typical views come from a composition of image augmentations. Our bound generalizes the InfoNCE objective to support negative sampling from a restricted region of "difficult" contrasts. We find that the choice of (1) negative samples and (2) "views" are critical to the success of contrastive learning, the former of which is largely unexplored. The mutual information reformulation also simplifies and stabilizes previous learning objectives. In practice, our new objectives yield representations that outperform those learned with previous approaches for transfer to classification, bounding box detection, instance segmentation, and keypoint detection. The mutual information framework provides a unifying and rigorous comparison of approaches to contrastive learning and uncovers the choices that impact representation learning.
PathSAGE: Spatial Graph Attention Neural Networks With Random Path Sampling
Mar 11, 2022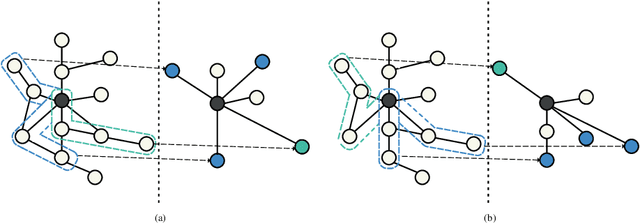
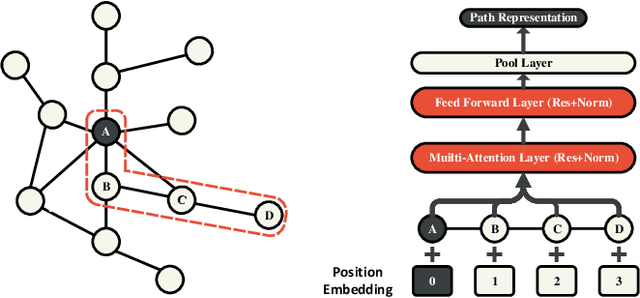
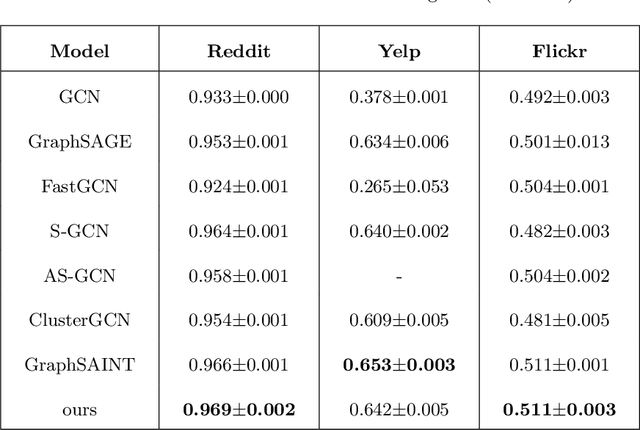
Graph Convolutional Networks (GCNs) achieve great success in non-Euclidean structure data processing recently. In existing studies, deeper layers are used in CCNs to extract deeper features of Euclidean structure data. However, for non-Euclidean structure data, too deep GCNs will confront with problems like "neighbor explosion" and "over-smoothing", it also cannot be applied to large datasets. To address these problems, we propose a model called PathSAGE, which can learn high-order topological information and improve the model's performance by expanding the receptive field. The model randomly samples paths starting from the central node and aggregates them by Transformer encoder. PathSAGE has only one layer of structure to aggregate nodes which avoid those problems above. The results of evaluation shows that our model achieves comparable performance with the state-of-the-art models in inductive learning tasks.
Dynamic-subarray with Fixed Phase Shifters for Energy-efficient Terahertz Hybrid Beamforming under Partial CSI
Mar 29, 2022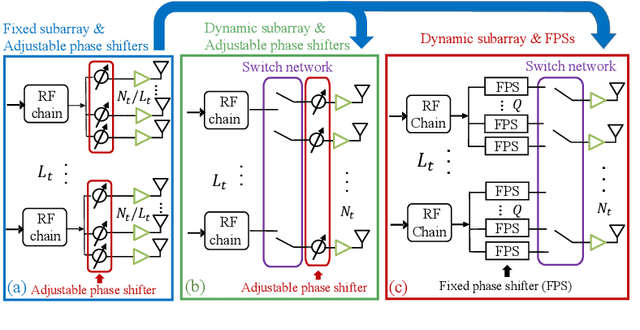
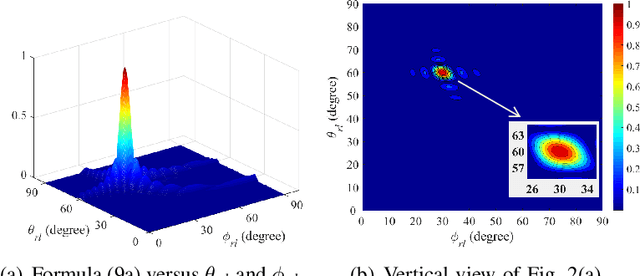
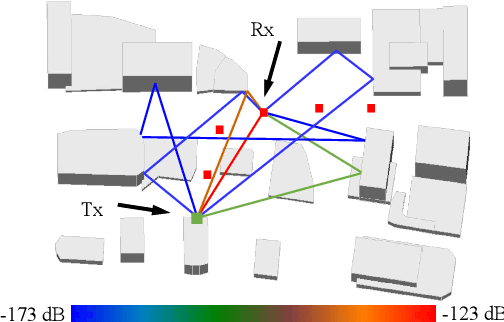
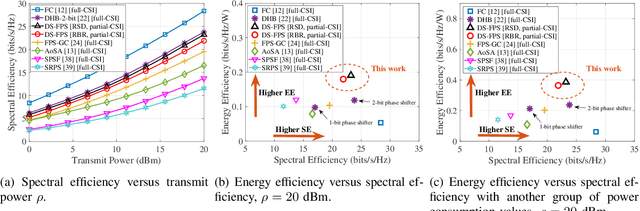
Terahertz (THz) communications are regarded as a pillar technology for the 6G systems, by offering multi-ten-GHz bandwidth. To overcome the huge propagation loss while reducing the hardware complexity, THz ultra-massive (UM) MIMO systems with hybrid beamforming are proposed to offer high array gain. Notably, the adjustable-phase-shifters considered in most existing hybrid beamforming studies are power-hungry and difficult to realize in the THz band. Moreover, due to the ultra-massive antennas, full channel-state-information (CSI) is challenging to obtain. To address these practical concerns, in this paper, an energy-efficient dynamic-subarray with fixed-phase-shifters (DS-FPS) architecture is proposed for THz hybrid beamforming. To compensate for the spectral efficiency loss caused by the fixed-phase of FPS, a switch network is inserted to enable dynamic connections. In addition, by considering the partial CSI, we propose a row-successive-decomposition (RSD) algorithm to design the hybrid beamforming matrices for DS-FPS. A row-by-row (RBR) algorithm is further proposed to reduce computational complexity. Extensive simulation results show that, the proposed DS-FPS architecture with the RSD and RBR algorithms achieves much higher energy efficiency than the existing architectures. Moreover, the DS-FPS architecture with partial CSI achieves 97% spectral efficiency of that with full CSI.
End-to-End Compressed Video Representation Learning for Generic Event Boundary Detection
Mar 29, 2022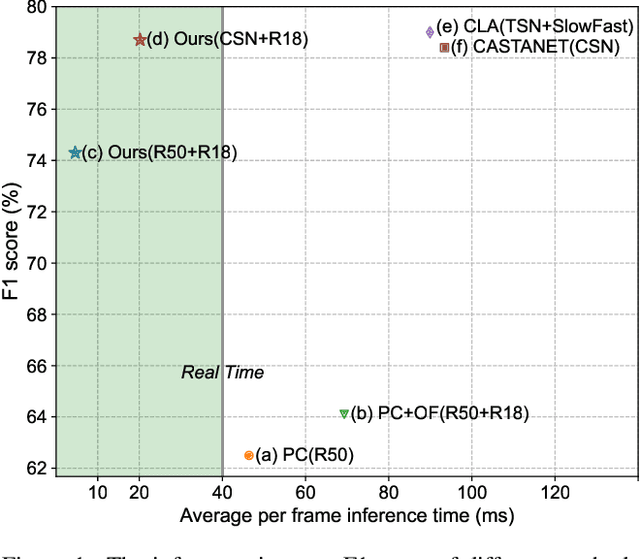
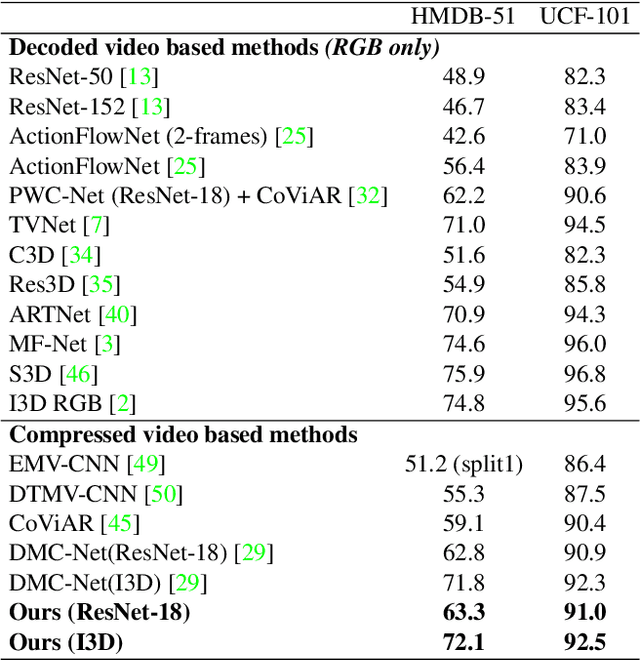
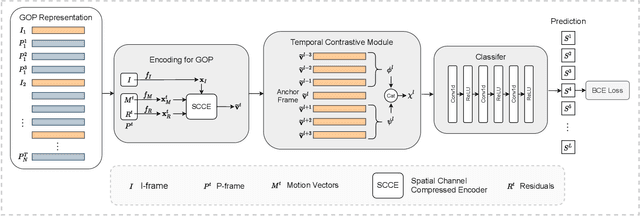
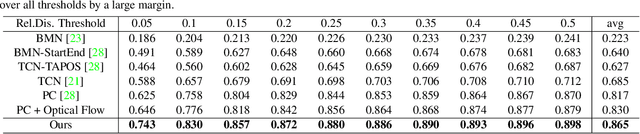
Generic event boundary detection aims to localize the generic, taxonomy-free event boundaries that segment videos into chunks. Existing methods typically require video frames to be decoded before feeding into the network, which demands considerable computational power and storage space. To that end, we propose a new end-to-end compressed video representation learning for event boundary detection that leverages the rich information in the compressed domain, i.e., RGB, motion vectors, residuals, and the internal group of pictures (GOP) structure, without fully decoding the video. Specifically, we first use the ConvNets to extract features of the I-frames in the GOPs. After that, a light-weight spatial-channel compressed encoder is designed to compute the feature representations of the P-frames based on the motion vectors, residuals and representations of their dependent I-frames. A temporal contrastive module is proposed to determine the event boundaries of video sequences. To remedy the ambiguities of annotations and speed up the training process, we use the Gaussian kernel to preprocess the ground-truth event boundaries. Extensive experiments conducted on the Kinetics-GEBD dataset demonstrate that the proposed method achieves comparable results to the state-of-the-art methods with $4.5\times$ faster running speed.
Continuous Detection, Rapidly React: Unseen Rumors Detection based on Continual Prompt-Tuning
Mar 16, 2022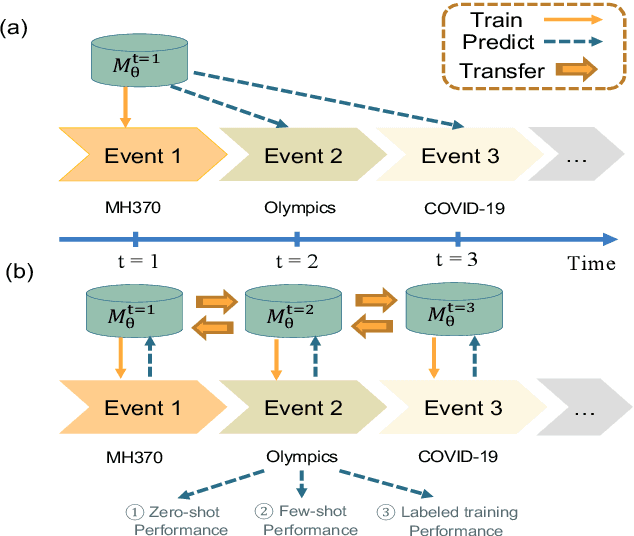
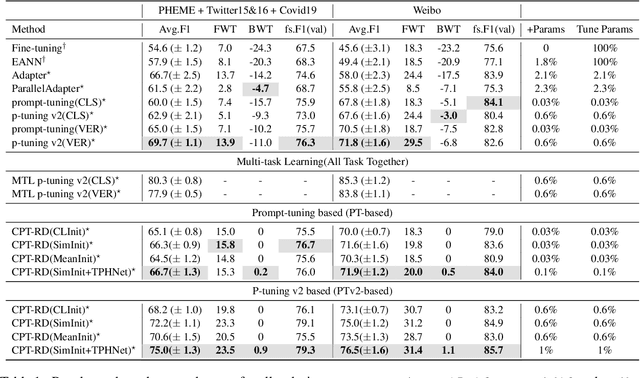
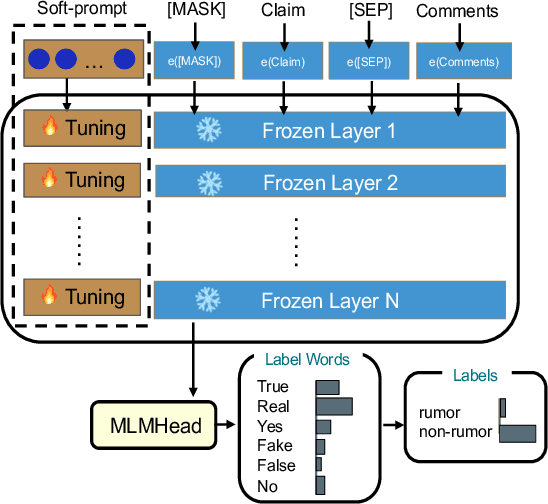
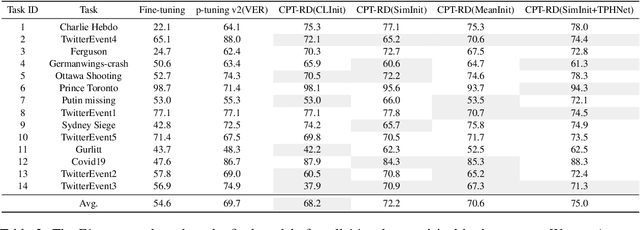
Since open social platforms allow for a large and continuous flow of unverified information, rumors can emerge unexpectedly and spread quickly. However, existing rumor detection (RD) models often assume the same training and testing distributions and cannot cope with the continuously changing social network environment. This paper proposes a Continual Prompt-Tuning RD (CPT-RD) framework, which avoids catastrophic forgetting of upstream tasks during sequential task learning and enables knowledge transfer between domain tasks. To avoid forgetting, we optimize and store task-special soft-prompt for each domain. Furthermore, we also propose several strategies to transfer knowledge of upstream tasks to deal with emergencies and a task-conditioned prompt-wise hypernetwork (TPHNet) to consolidate past domains, enabling bidirectional knowledge transfer. Finally, CPT-RD is evaluated on English and Chinese RD datasets and is effective and efficient compared to state-of-the-art baselines, without data replay techniques and with only a few parameter tuning.