 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SegTransVAE: Hybrid CNN -- Transformer with Regularization for medical image segmentation
Jan 26, 2022
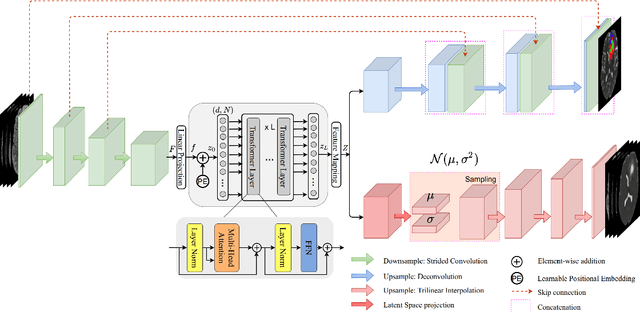
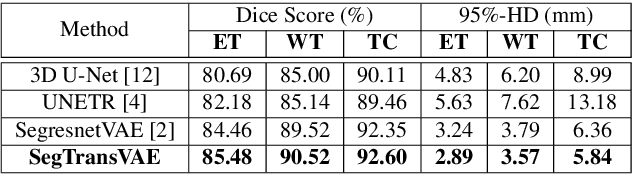
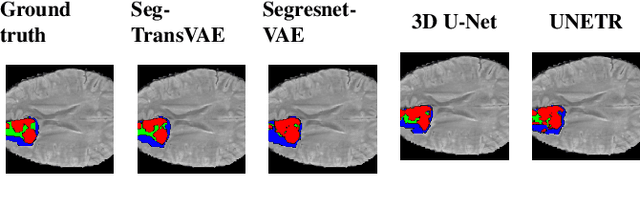
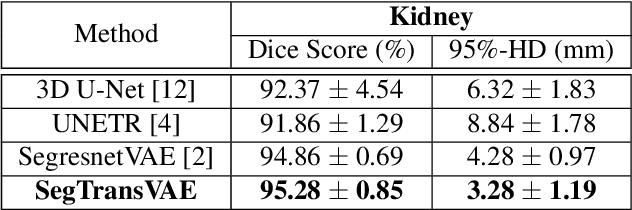
Current research on deep learning for medical image segmentation exposes their limitations in learning either global semantic information or local contextual information. To tackle these issues, a novel network named SegTransVAE is proposed in this paper. SegTransVAE is built upon encoder-decoder architecture, exploiting transformer with the variational autoencoder (VAE) branch to the network to reconstruct the input images jointly with segmentation. To the best of our knowledge, this is the first method combining the success of CNN, transformer, and VAE. Evaluation on various recently introduced datasets shows that SegTransVAE outperforms previous methods in Dice Score and $95\%$-Haudorff Distance while having comparable inference time to a simple CNN-based architecture network. The source code is available at: https://github.com/itruonghai/SegTransVAE.
Multivariate Time Series Regression with Graph Neural Networks
Jan 10, 2022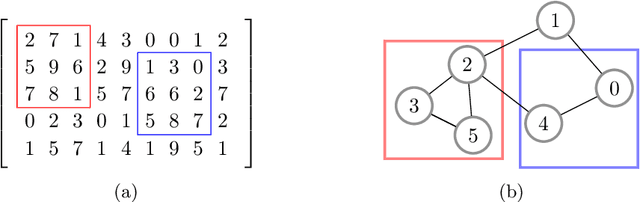
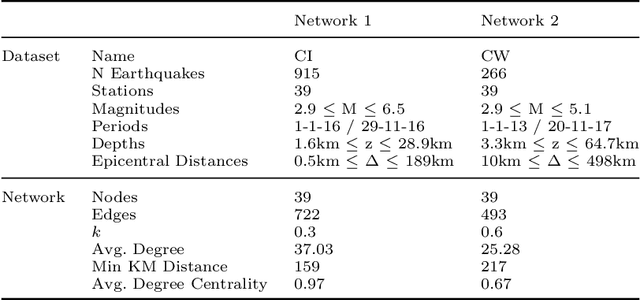
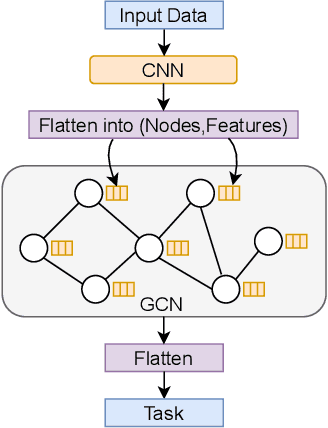
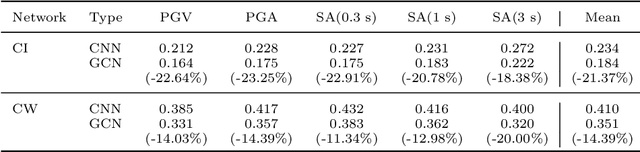
Machine learning, with its advances in Deep Learning has shown great potential in analysing time series in the past. However, in many scenarios, additional information is available that can potentially improve predictions, by incorporating it into the learning methods. This is crucial for data that arises from e.g., sensor networks that contain information about sensor locations. Then, such spatial information can be exploited by modeling it via graph structures, along with the sequential (time) information. Recent advances in adapting Deep Learning to graphs have shown promising potential in various graph-related tasks. However, these methods have not been adapted for time series related tasks to a great extent. Specifically, most attempts have essentially consolidated around Spatial-Temporal Graph Neural Networks for time series forecasting with small sequence lengths. Generally, these architectures are not suited for regression or classification tasks that contain large sequences of data. Therefore, in this work, we propose an architecture capable of processing these long sequences in a multivariate time series regression task, using the benefits of Graph Neural Networks to improve predictions. Our model is tested on two seismic datasets that contain earthquake waveforms, where the goal is to predict intensity measurements of ground shaking at a set of stations. Our findings demonstrate promising results of our approach, which are discussed in depth with an additional ablation study.
Evaluation of Fake News Detection with Knowledge-Enhanced Language Models
Apr 01, 2022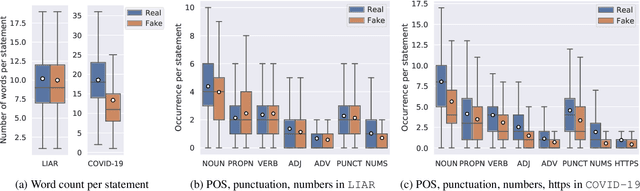
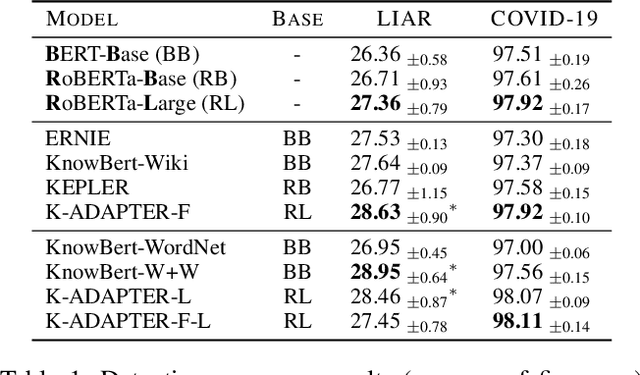
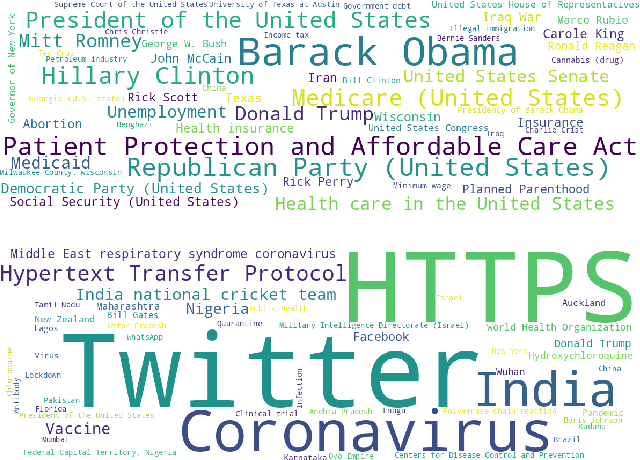
Recent advances in fake news detection have exploited the success of large-scale pre-trained language models (PLMs). The predominant state-of-the-art approaches are based on fine-tuning PLMs on labelled fake news datasets. However, large-scale PLMs are generally not trained on structured factual data and hence may not possess priors that are grounded in factually accurate knowledge. The use of existing knowledge bases (KBs) with rich human-curated factual information has thus the potential to make fake news detection more effective and robust. In this paper, we investigate the impact of knowledge integration into PLMs for fake news detection. We study several state-of-the-art approaches for knowledge integration, mostly using Wikidata as KB, on two popular fake news datasets - LIAR, a politics-based dataset, and COVID-19, a dataset of messages posted on social media relating to the COVID-19 pandemic. Our experiments show that knowledge-enhanced models can significantly improve fake news detection on LIAR where the KB is relevant and up-to-date. The mixed results on COVID-19 highlight the reliance on stylistic features and the importance of domain specific and current KBs.
Clutter Edges Detection Algorithms for Structured Clutter Covariance Matrices
Feb 03, 2022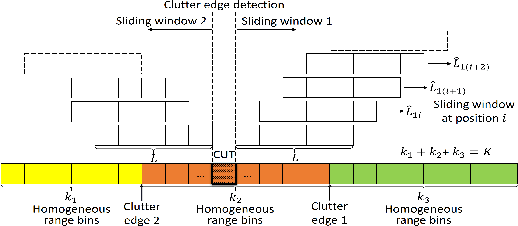
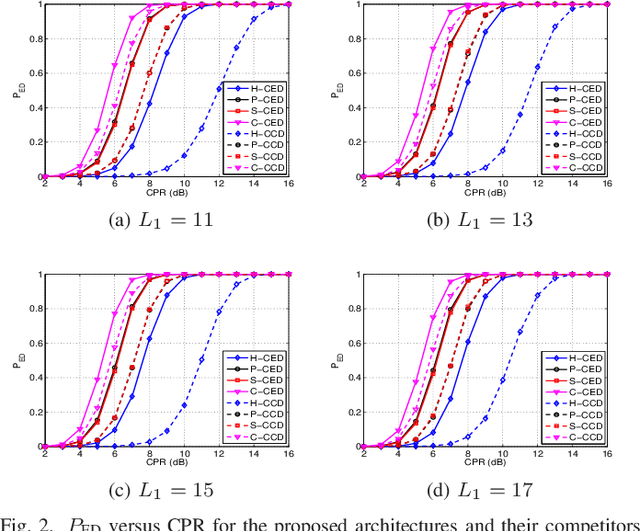
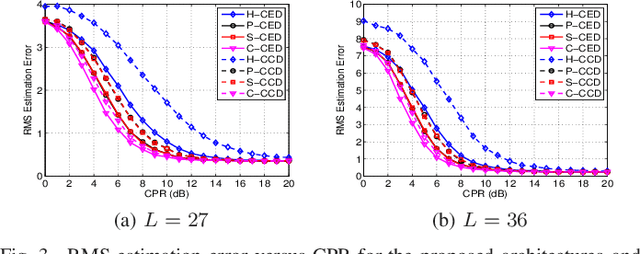
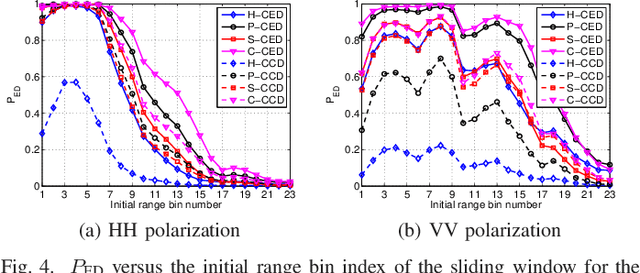
This letter deals with the problem of clutter edge detection and localization in training data. To this end, the problem is formulated as a binary hypothesis test assuming that the ranks of the clutter covariance matrix are known, and adaptive architectures are designed based on the generalized likelihood ratio test to decide whether the training data within a sliding window contains a homogeneous set or two heterogeneous subsets. In the design stage, we utilize four different covariance matrix structures (i.e., Hermitian, persymmetric, symmetric, and centrosymmetric) to exploit the a priori information. Then, for the case of unknown ranks, the architectures are extended by devising a preliminary estimation stage resorting to the model order selection rules. Numerical examples based on both synthetic and real data highlight that the proposed solutions possess superior detection and localization performance with respect to the competitors that do not use any a priori information.
Transformers for 1D Signals in Parkinson's Disease Detection from Gait
Apr 01, 2022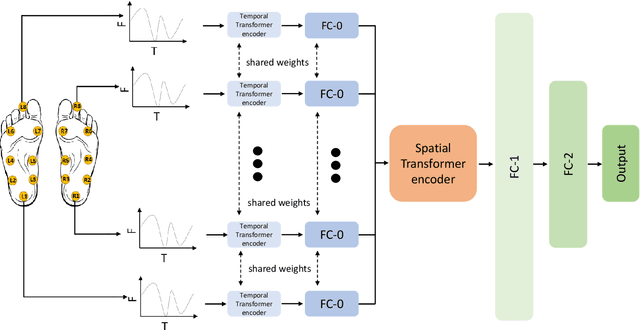
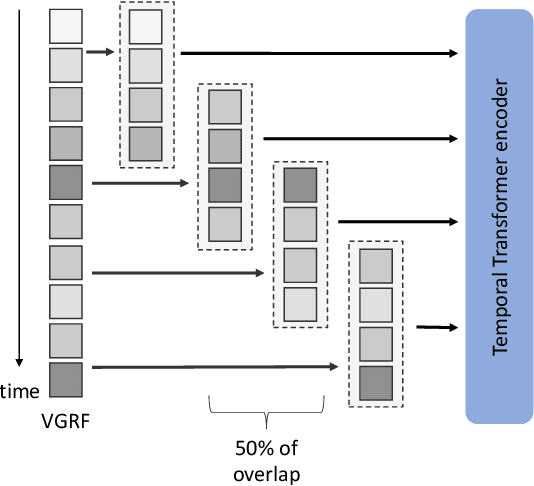
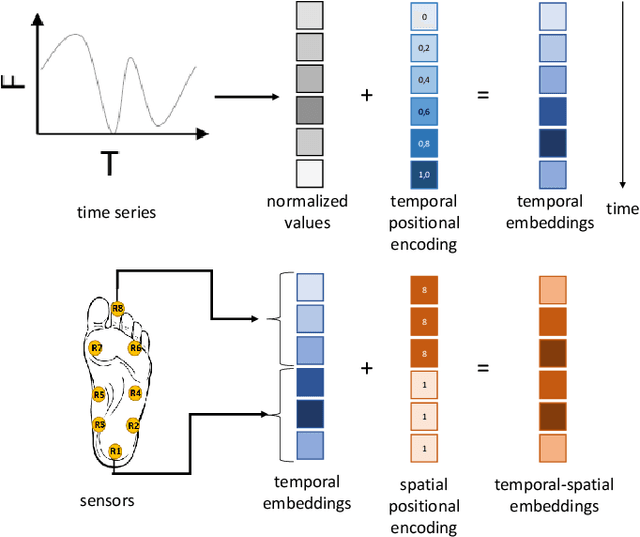
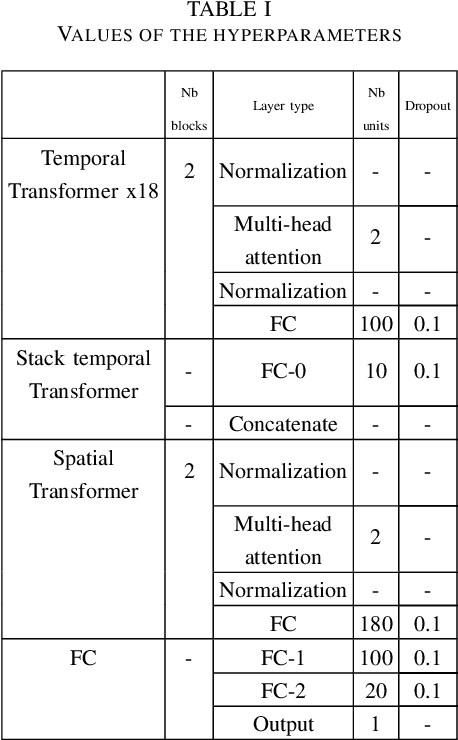
This paper focuses on the detection of Parkinson's disease based on the analysis of a patient's gait. The growing popularity and success of Transformer networks in natural language processing and image recognition motivated us to develop a novel method for this problem based on an automatic features extraction via Transformers. The use of Transformers in 1D signal is not really widespread yet, but we show in this paper that they are effective in extracting relevant features from 1D signals. As Transformers require a lot of memory, we decoupled temporal and spatial information to make the model smaller. Our architecture used temporal Transformers, dimension reduction layers to reduce the dimension of the data, a spatial Transformer, two fully connected layers and an output layer for the final prediction. Our model outperforms the current state-of-the-art algorithm with 95.2\% accuracy in distinguishing a Parkinsonian patient from a healthy one on the Physionet dataset. A key learning from this work is that Transformers allow for greater stability in results. The source code and pre-trained models are released in https://github.com/DucMinhDimitriNguyen/Transformers-for-1D-signals-in-Parkinson-s-disease-detection-from-gait.git
Automatic Image Content Extraction: Operationalizing Machine Learning in Humanistic Photographic Studies of Large Visual Archives
Apr 05, 2022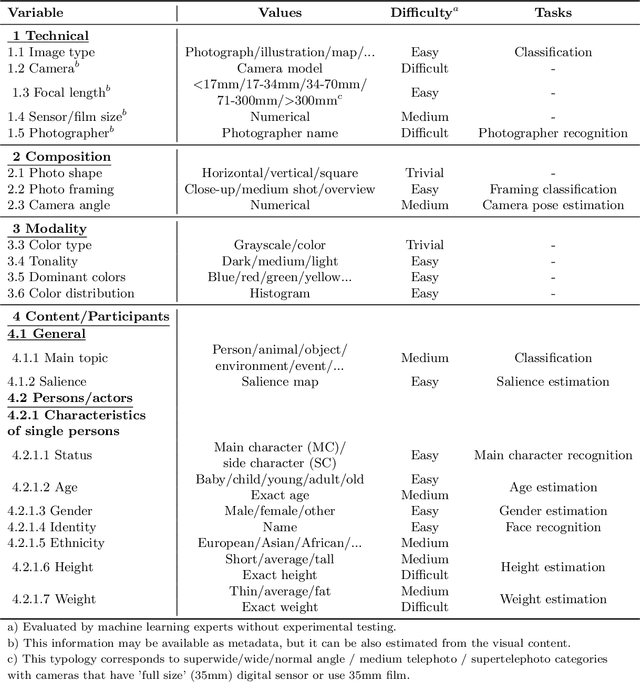
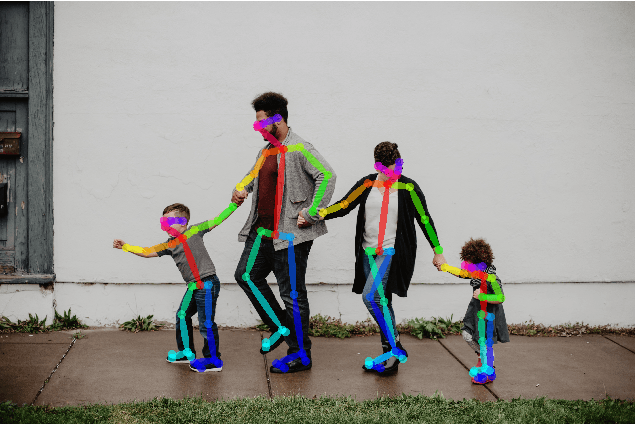
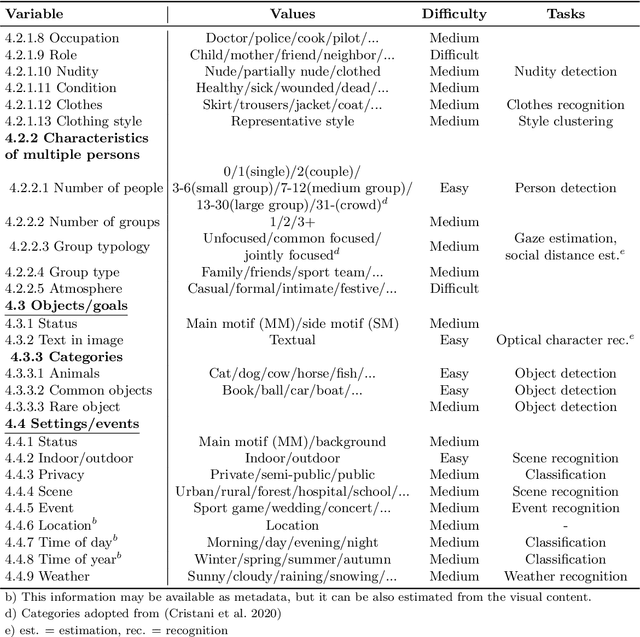

Applying machine learning tools to digitized image archives has a potential to revolutionize quantitative research of visual studies in humanities and social sciences. The ability to process a hundredfold greater number of photos than has been traditionally possible and to analyze them with an extensive set of variables will contribute to deeper insight into the material. Overall, these changes will help to shift the workflow from simple manual tasks to more demanding stages. In this paper, we introduce Automatic Image Content Extraction (AICE) framework for machine learning-based search and analysis of large image archives. We developed the framework in a multidisciplinary research project as framework for future photographic studies by reformulating and expanding the traditional visual content analysis methodologies to be compatible with the current and emerging state-of-the-art machine learning tools and to cover the novel machine learning opportunities for automatic content analysis. The proposed framework can be applied in several domains in humanities and social sciences, and it can be adjusted and scaled into various research settings. We also provide information on the current state of different machine learning techniques and show that there are already various publicly available methods that are suitable to a wide-scale of visual content analysis tasks.
A Knowledge Graph Embeddings based Approach for Author Name Disambiguation using Literals
Jan 24, 2022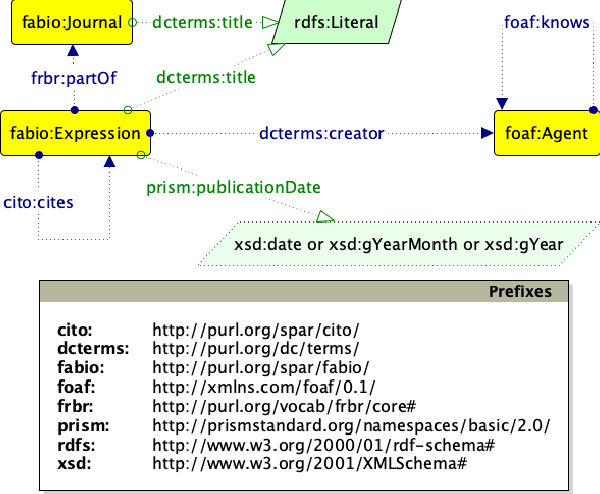

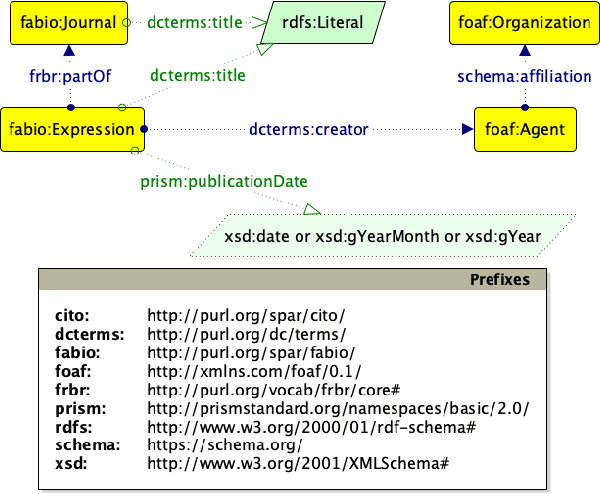

Scholarly data is growing continuously containing information about the articles from plethora of venues including conferences, journals, etc. Many initiatives have been taken to make scholarly data available in the for of Knowledge Graphs (KGs). These efforts to standardize these data and make them accessible have also lead to many challenges such as exploration of scholarly articles, ambiguous authors, etc. This study more specifically targets the problem of Author Name Disambiguation (AND) on Scholarly KGs and presents a novel framework, Literally Author Name Disambiguation (LAND), which utilizes Knowledge Graph Embeddings (KGEs) using multimodal literal information generated from these KGs. This framework is based on three components: 1) Multimodal KGEs, 2) A blocking procedure, and finally, 3) Hierarchical Agglomerative Clustering. Extensive experiments have been conducted on two newly created KGs: (i) KG containing information from Scientometrics Journal from 1978 onwards (OC-782K), and (ii) a KG extracted from a well-known benchmark for AND provided by AMiner (AMiner-534K). The results show that our proposed architecture outperforms our baselines of 8-14\% in terms of F$_1$ score and shows competitive performances on a challenging benchmark such as AMiner. The code and the datasets are publicly available through Github (https://github.com/sntcristian/and-kge) and Zenodo (https://zenodo.org/record/5675787\#.YcCJzL3MJTY) respectively.
Challenges in Information Seeking QA:Unanswerable Questions and Paragraph Retrieval
Oct 22, 2020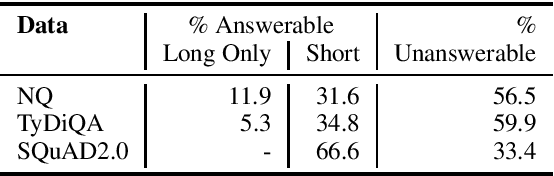
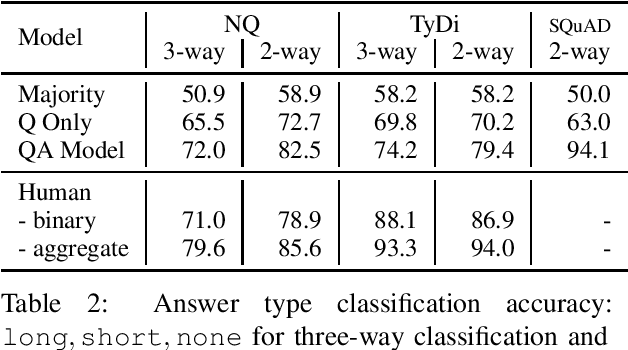
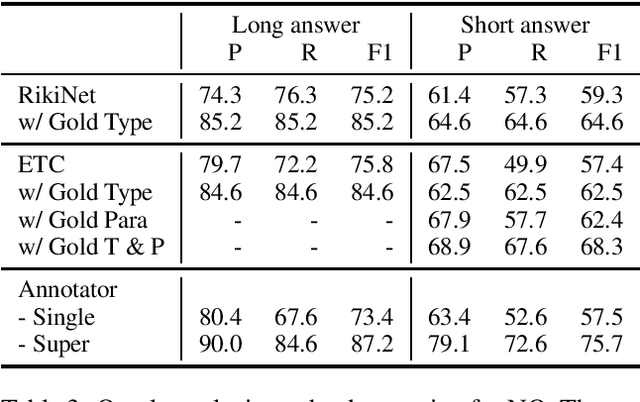
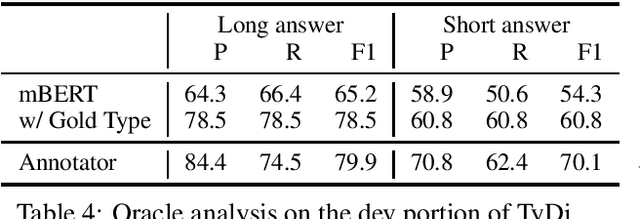
Recent progress in pretrained language model "solved" many reading comprehension benchmark datasets. Yet information-seeking Question Answering (QA) datasets, where questions are written without the evidence document, remain unsolved. We analyze two such datasets (Natural Questions and TyDi QA) to identify remaining headrooms: paragraph selection and answerability classification, i.e. determining whether the paired evidence document contains the answer to the query or not. In other words, given a gold paragraph and knowing whether it contains an answer or not, models easily outperform a single annotator in both datasets. After identifying unanswerability as a bottleneck, we further inspect what makes questions unanswerable. Our study points to avenues for future research, both for dataset creation and model development.
A Novel Self-Supervised Cross-Modal Image Retrieval Method In Remote Sensing
Feb 23, 2022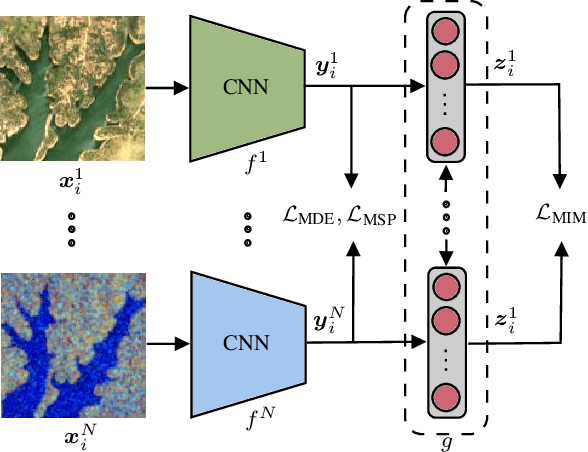
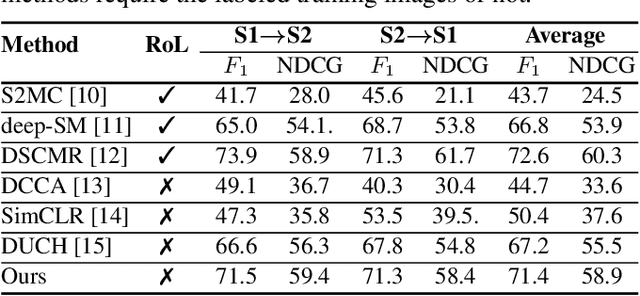

Due to the availability of multi-modal remote sensing (RS) image archives, one of the most important research topics is the development of cross-modal RS image retrieval (CM-RSIR) methods that search semantically similar images across different modalities. Existing CM-RSIR methods require annotated training images (which is time-consuming, costly and not feasible to gather in large-scale applications) and do not concurrently address intra- and inter-modal similarity preservation and inter-modal discrepancy elimination. In this paper, we introduce a novel self-supervised cross-modal image retrieval method that aims to: i) model mutual-information between different modalities in a self-supervised manner; ii) retain the distributions of modal-specific feature spaces similar; and iii) define most similar images within each modality without requiring any annotated training images. To this end, we propose a novel objective including three loss functions that simultaneously: i) maximize mutual information of different modalities for inter-modal similarity preservation; ii) minimize the angular distance of multi-modal image tuples for the elimination of inter-modal discrepancies; and iii) increase cosine similarity of most similar images within each modality for the characterization of intra-modal similarities. Experimental results show the effectiveness of the proposed method compared to state-of-the-art methods. The code of the proposed method is publicly available at https://git.tu-berlin.de/rsim/SS-CM-RSIR.
EnCBP: A New Benchmark Dataset for Finer-Grained Cultural Background Prediction in English
Mar 28, 2022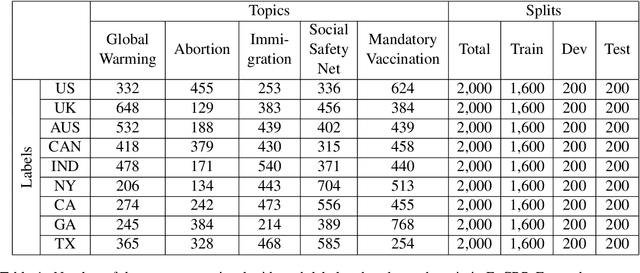

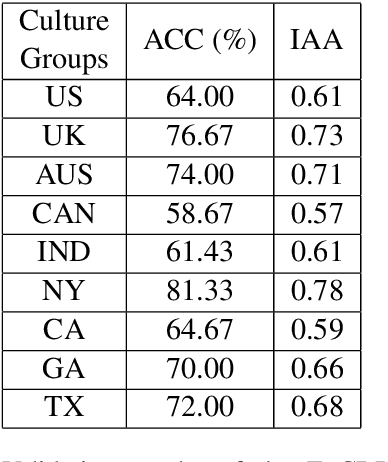
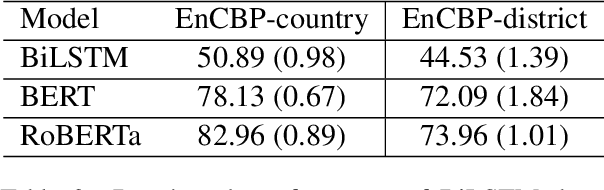
While cultural backgrounds have been shown to affect linguistic expressions, existing natural language processing (NLP) research on culture modeling is overly coarse-grained and does not examine cultural differences among speakers of the same language. To address this problem and augment NLP models with cultural background features, we collect, annotate, manually validate, and benchmark EnCBP, a finer-grained news-based cultural background prediction dataset in English. Through language modeling (LM) evaluations and manual analyses, we confirm that there are noticeable differences in linguistic expressions among five English-speaking countries and across four states in the US. Additionally, our evaluations on nine syntactic (CoNLL-2003), semantic (PAWS-Wiki, QNLI, STS-B, and RTE), and psycholinguistic tasks (SST-5, SST-2, Emotion, and Go-Emotions) show that, while introducing cultural background information does not benefit the Go-Emotions task due to text domain conflicts, it noticeably improves deep learning (DL) model performance on other tasks. Our findings strongly support the importance of cultural background modeling to a wide variety of NLP tasks and demonstrate the applicability of EnCBP in culture-related research.