 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Robust Multimodal Remote Sensing Image Registration Method and System Using Steerable Filters with First- and Second-order Gradients
Feb 27, 2022


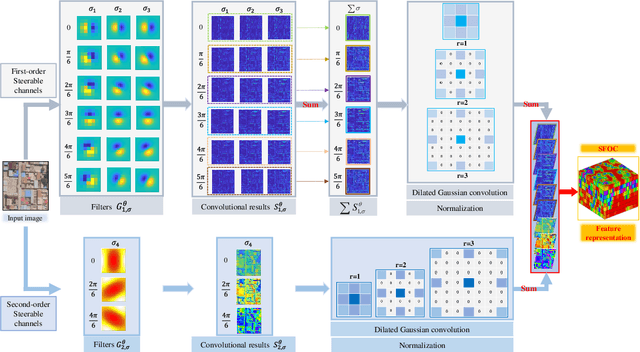

Co-registration of multimodal remote sensing images is still an ongoing challenge because of nonlinear radiometric differences (NRD) and significant geometric distortions (e.g., scale and rotation changes) between these images. In this paper, a robust matching method based on the Steerable filters is proposed consisting of two critical steps. First, to address severe NRD, a novel structural descriptor named the Steerable Filters of first- and second-Order Channels (SFOC) is constructed, which combines the first- and second-order gradient information by using the steerable filters with a multi-scale strategy to depict more discriminative structure features of images. Then, a fast similarity measure is established called Fast Normalized Cross-Correlation (Fast-NCCSFOC), which employs the Fast Fourier Transform technique and the integral image to improve the matching efficiency. Furthermore, to achieve reliable registration performance, a coarse-to-fine multimodal registration system is designed consisting of two pivotal modules. The local coarse registration is first conducted by involving both detection of interest points (IPs) and local geometric correction, which effectively utilizes the prior georeferencing information of RS images to address global geometric distortions. In the fine registration stage, the proposed SFOC is used to resist significant NRD, and to detect control points between multimodal images by a template matching scheme. The performance of the proposed matching method has been evaluated with many different kinds of multimodal RS images. The results show its superior matching performance compared with the state-of-the-art methods. Moreover, the designed registration system also outperforms the popular commercial software in both registration accuracy and computational efficiency. Our system is available at https://github.com/yeyuanxin110.
AutoSNN: Towards Energy-Efficient Spiking Neural Networks
Jan 30, 2022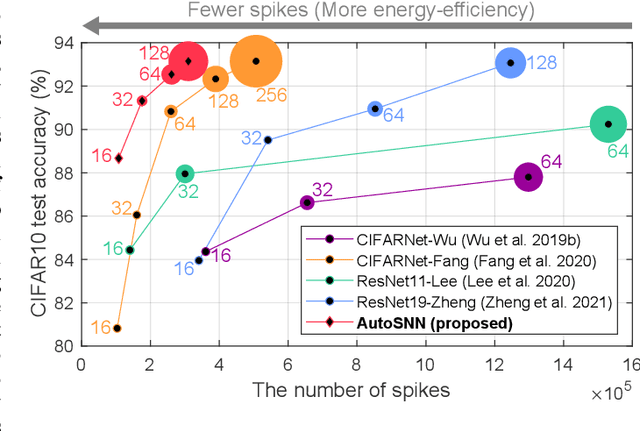
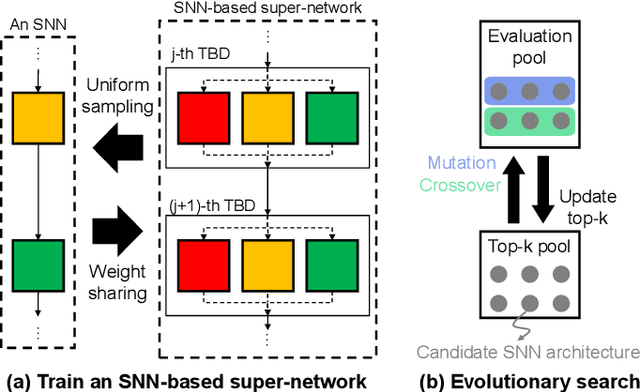
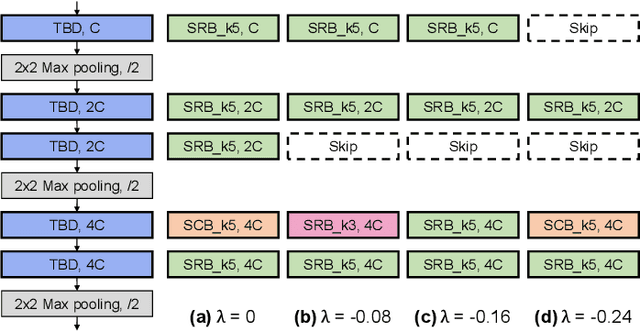
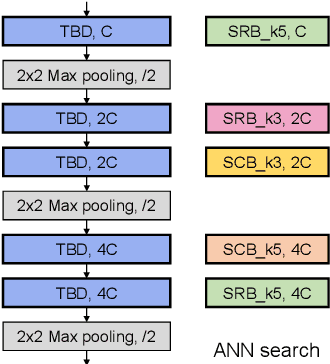
Spiking neural networks (SNNs) that mimic information transmission in the brain can energy-efficiently process spatio-temporal information through discrete and sparse spikes, thereby receiving considerable attention. To improve accuracy and energy efficiency of SNNs, most previous studies have focused solely on training methods, and the effect of architecture has rarely been studied. We investigate the design choices used in the previous studies in terms of the accuracy and number of spikes and figure out that they are not best-suited for SNNs. To further improve the accuracy and reduce the spikes generated by SNNs, we propose a spike-aware neural architecture search framework called AutoSNN. We define a search space consisting of architectures without undesirable design choices. To enable the spike-aware architecture search, we introduce a fitness that considers both the accuracy and number of spikes. AutoSNN successfully searches for SNN architectures that outperform hand-crafted SNNs in accuracy and energy efficiency. We thoroughly demonstrate the effectiveness of AutoSNN on various datasets including neuromorphic datasets.
Information Scrambling in Quantum Neural Networks
Sep 26, 2019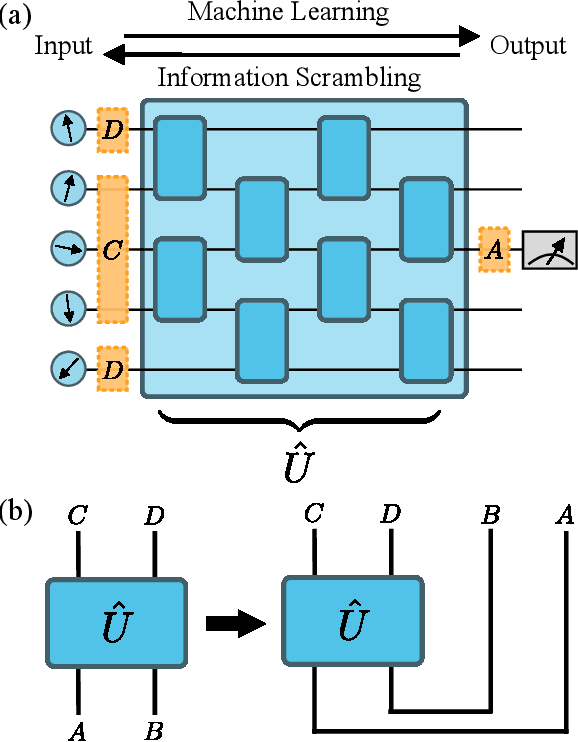
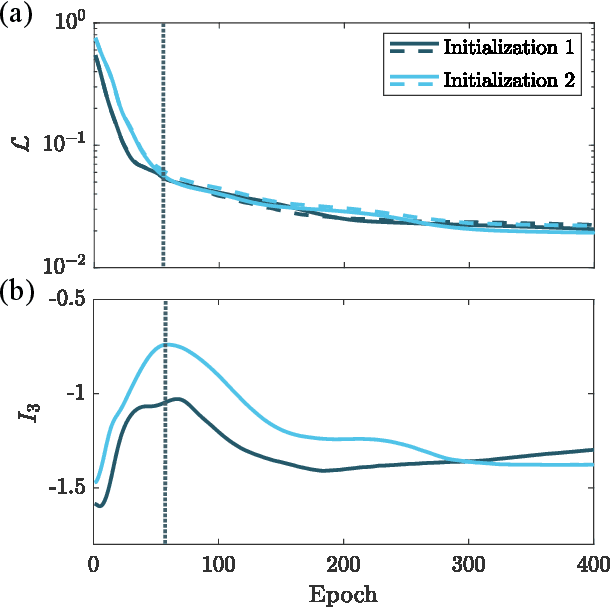
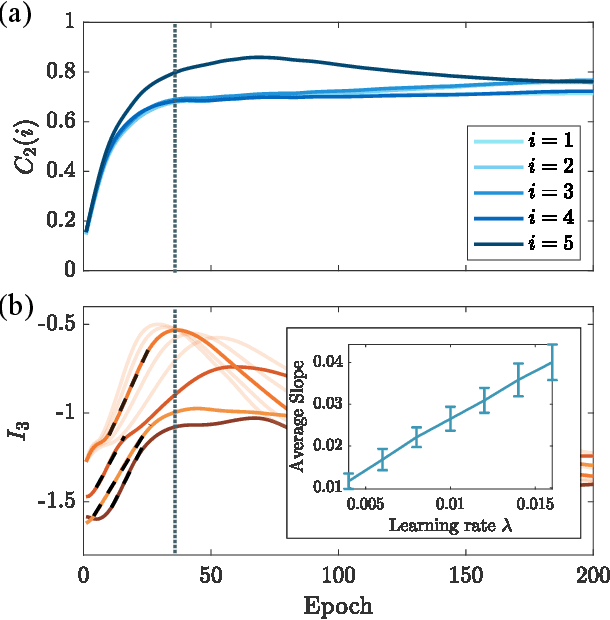
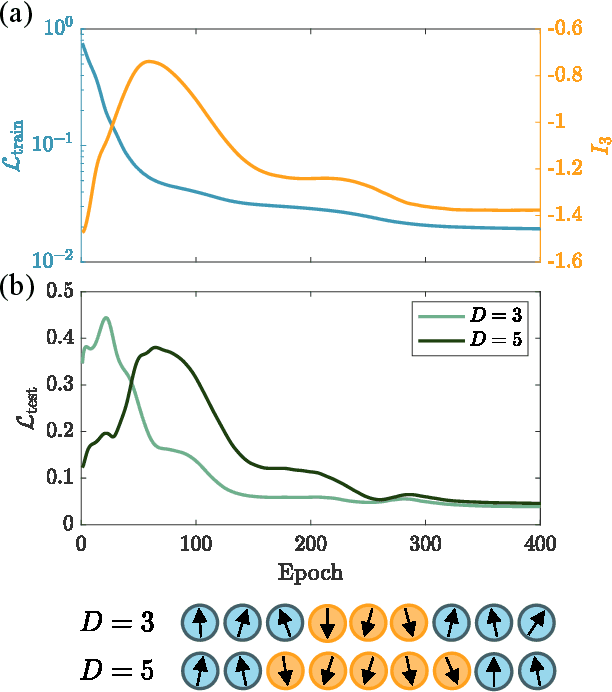
Quantum neural networks are one of the promising applications for near-term noisy intermediate-scale quantum computers. A quantum neural network distills the information from the input wavefunction into the output qubits. In this Letter, we show that this process can also be viewed from the opposite direction: the quantum information in the output qubits is scrambled into the input. This observation motivates us to use the tripartite information, a quantity recently developed to characterize information scrambling, to diagnose the training dynamics of quantum neural networks. We empirically find strong correlation between the dynamical behavior of the tripartite information and the loss function in the training process, from which we identify that the training process has two stages for randomly initialized networks. In the early stage, the network performance improves rapidly and the tripartite information increases linearly with a universal slope, meaning that the neural network becomes less scrambled than the random unitary. In the latter stage, the network performance improves slowly while the tripartite information decreases. We present evidences that the network constructs local correlations in the early stage and learns large-scale structures in the latter stage. We believe this two-stage training dynamics is universal and is applicable to a wide range of problems. Our work builds bridges between two research subjects of quantum neural networks and information scrambling, which opens up a new perspective to understand quantum neural networks.
Improving Fraud detection via Hierarchical Attention-based Graph Neural Network
Feb 12, 2022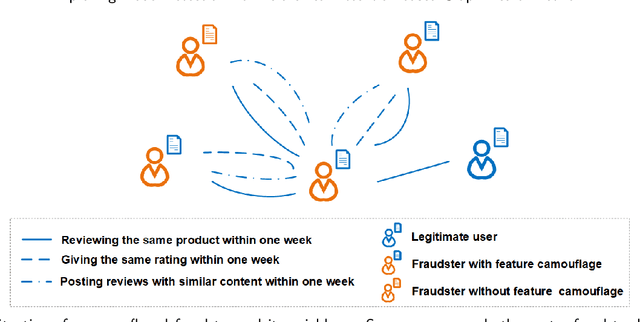
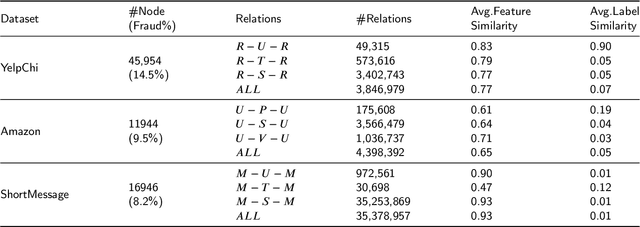
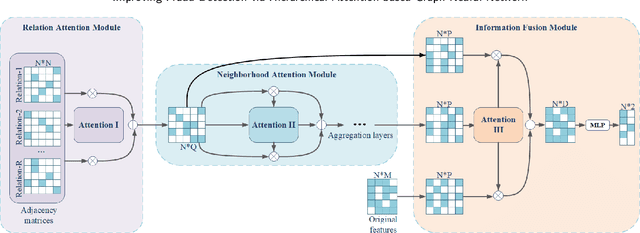
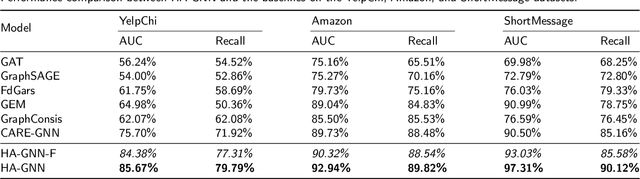
Graph neural networks (GNN) have emerged as a powerful tool for fraud detection tasks, where fraudulent nodes are identified by aggregating neighbor information via different relations. To get around such detection, crafty fraudsters resort to camouflage via connecting to legitimate users (i.e., relation camouflage) or providing seemingly legitimate feedbacks (i.e., feature camouflage). A wide-spread solution reinforces the GNN aggregation process with neighbor selectors according to original node features. This method may carry limitations when identifying fraudsters not only with the relation camouflage, but with the feature camouflage making them hard to distinguish from their legitimate neighbors. In this paper, we propose a Hierarchical Attention-based Graph Neural Network (HA-GNN) for fraud detection, which incorporates weighted adjacency matrices across different relations against camouflage. This is motivated in the Relational Density Theory and is exploited for forming a hierarchical attention-based graph neural network. Specifically, we design a relation attention module to reflect the tie strength between two nodes, while a neighborhood attention module to capture the long-range structural affinity associated with the graph. We generate node embeddings by aggregating information from local/long-range structures and original node features. Experiments on three real-world datasets demonstrate the effectiveness of our model over the state-of-the-arts.
A two-step approach to leverage contextual data: speech recognition in air-traffic communications
Feb 08, 2022

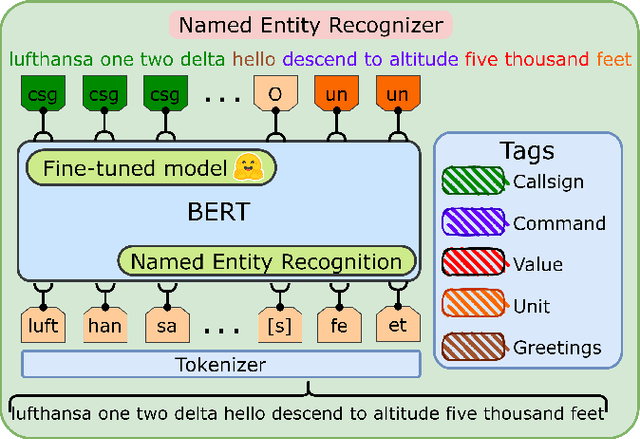
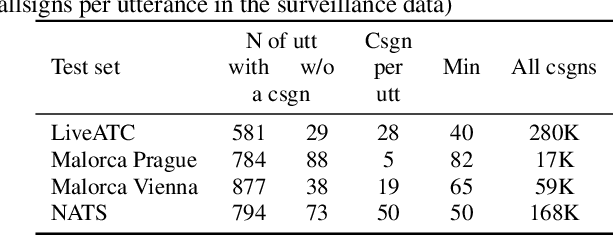
Automatic Speech Recognition (ASR), as the assistance of speech communication between pilots and air-traffic controllers, can significantly reduce the complexity of the task and increase the reliability of transmitted information. ASR application can lead to a lower number of incidents caused by misunderstanding and improve air traffic management (ATM) efficiency. Evidently, high accuracy predictions, especially, of key information, i.e., callsigns and commands, are required to minimize the risk of errors. We prove that combining the benefits of ASR and Natural Language Processing (NLP) methods to make use of surveillance data (i.e. additional modality) helps to considerably improve the recognition of callsigns (named entity). In this paper, we investigate a two-step callsign boosting approach: (1) at the 1 step (ASR), weights of probable callsign n-grams are reduced in G.fst and/or in the decoding FST (lattices), (2) at the 2 step (NLP), callsigns extracted from the improved recognition outputs with Named Entity Recognition (NER) are correlated with the surveillance data to select the most suitable one. Boosting callsign n-grams with the combination of ASR and NLP methods eventually leads up to 53.7% of an absolute, or 60.4% of a relative, improvement in callsign recognition.
* 20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. arXiv admin note: text overlap with arXiv:2108.12156
SubOmiEmbed: Self-supervised Representation Learning of Multi-omics Data for Cancer Type Classification
Feb 03, 2022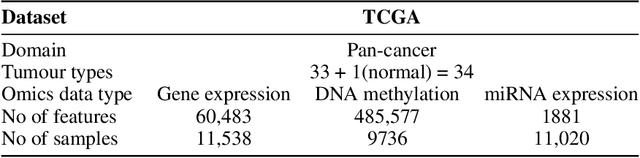
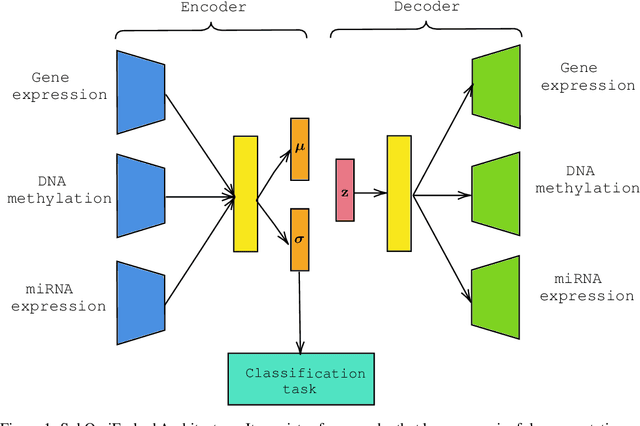
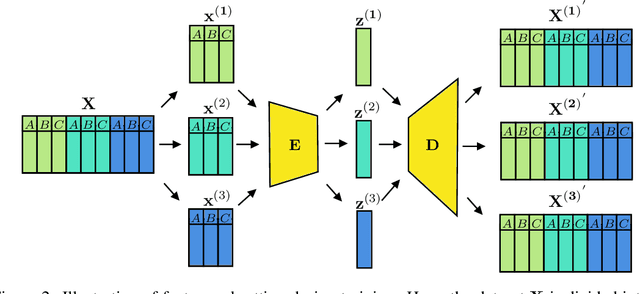

For personalized medicines, very crucial intrinsic information is present in high dimensional omics data which is difficult to capture due to the large number of molecular features and small number of available samples. Different types of omics data show various aspects of samples. Integration and analysis of multi-omics data give us a broad view of tumours, which can improve clinical decision making. Omics data, mainly DNA methylation and gene expression profiles are usually high dimensional data with a lot of molecular features. In recent years, variational autoencoders (VAE) have been extensively used in embedding image and text data into lower dimensional latent spaces. In our project, we extend the idea of using a VAE model for low dimensional latent space extraction with the self-supervised learning technique of feature subsetting. With VAEs, the key idea is to make the model learn meaningful representations from different types of omics data, which could then be used for downstream tasks such as cancer type classification. The main goals are to overcome the curse of dimensionality and integrate methylation and expression data to combine information about different aspects of same tissue samples, and hopefully extract biologically relevant features. Our extension involves training encoder and decoder to reconstruct the data from just a subset of it. By doing this, we force the model to encode most important information in the latent representation. We also added an identity to the subsets so that the model knows which subset is being fed into it during training and testing. We experimented with our approach and found that SubOmiEmbed produces comparable results to the baseline OmiEmbed with a much smaller network and by using just a subset of the data. This work can be improved to integrate mutation-based genomic data as well.
The Curse of Dense Low-Dimensional Information Retrieval for Large Index Sizes
Dec 28, 2020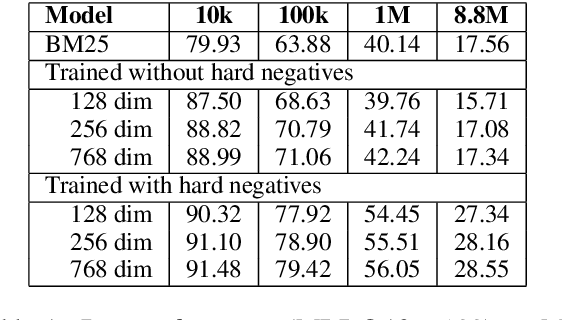
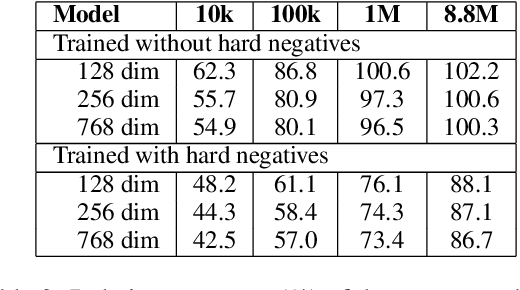
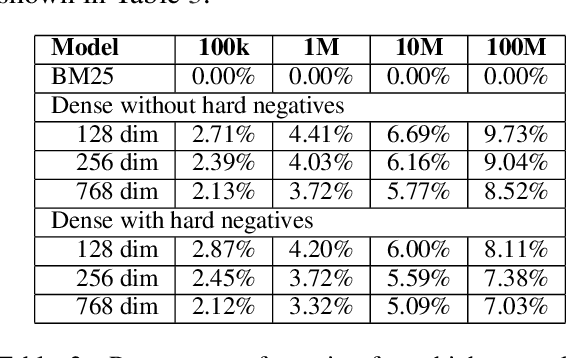
Information Retrieval using dense low-dimensional representations recently became popular and showed out-performance to traditional sparse-representations like BM25. However, no previous work investigated how dense representations perform with large index sizes. We show theoretically and empirically that the performance for dense representations decreases quicker than sparse representations for increasing index sizes. In extreme cases, this can even lead to a tipping point where at a certain index size sparse representations outperform dense representations. We show that this behavior is tightly connected to the number of dimensions of the representations: The lower the dimension, the higher the chance for false positives, i.e. returning irrelevant documents.
Low-rank features based double transformation matrices learning for image classification
Jan 28, 2022Linear regression is a supervised method that has been widely used in classification tasks. In order to apply linear regression to classification tasks, a technique for relaxing regression targets was proposed. However, methods based on this technique ignore the pressure on a single transformation matrix due to the complex information contained in the data. A single transformation matrix in this case is too strict to provide a flexible projection, thus it is necessary to adopt relaxation on transformation matrix. This paper proposes a double transformation matrices learning method based on latent low-rank feature extraction. The core idea is to use double transformation matrices for relaxation, and jointly projecting the learned principal and salient features from two directions into the label space, which can share the pressure of a single transformation matrix. Firstly, the low-rank features are learned by the latent low rank representation (LatLRR) method which processes the original data from two directions. In this process, sparse noise is also separated, which alleviates its interference on projection learning to some extent. Then, two transformation matrices are introduced to process the two features separately, and the information useful for the classification is extracted. Finally, the two transformation matrices can be easily obtained by alternate optimization methods. Through such processing, even when a large amount of redundant information is contained in samples, our method can also obtain projection results that are easy to classify. Experiments on multiple data sets demonstrate the effectiveness of our approach for classification, especially for complex scenarios.
Medical Application of Geometric Deep Learning for the Diagnosis of Glaucoma
Apr 14, 2022
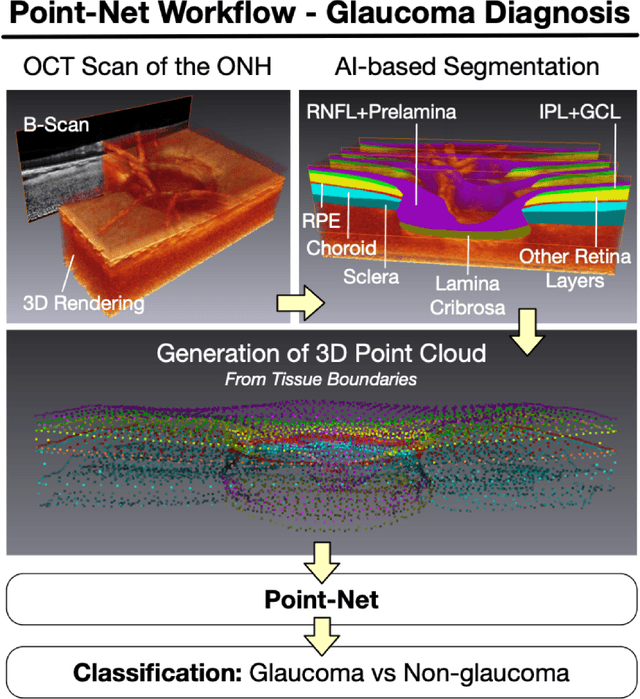
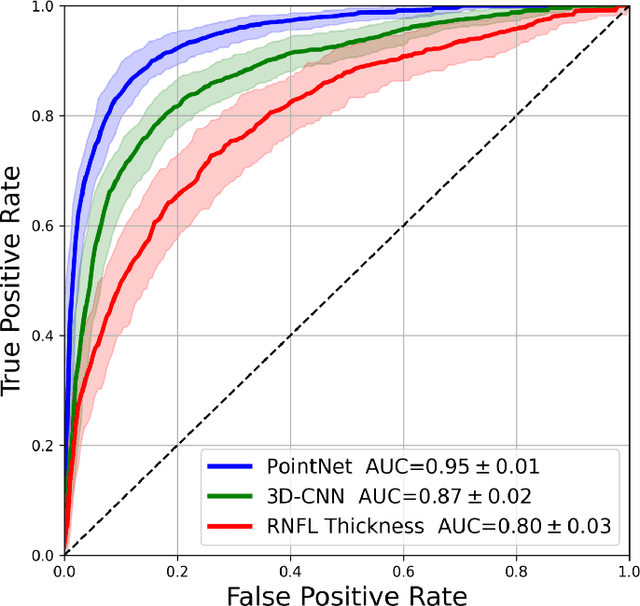
Purpose: (1) To assess the performance of geometric deep learning (PointNet) in diagnosing glaucoma from a single optical coherence tomography (OCT) 3D scan of the optic nerve head (ONH); (2) To compare its performance to that obtained with a standard 3D convolutional neural network (CNN), and with a gold-standard glaucoma parameter, i.e. retinal nerve fiber layer (RNFL) thickness. Methods: 3D raster scans of the ONH were acquired with Spectralis OCT for 477 glaucoma and 2,296 non-glaucoma subjects at the Singapore National Eye Centre. All volumes were automatically segmented using deep learning to identify 7 major neural and connective tissues including the RNFL, the prelamina, and the lamina cribrosa (LC). Each ONH was then represented as a 3D point cloud with 1,000 points chosen randomly from all tissue boundaries. To simplify the problem, all ONH point clouds were aligned with respect to the plane and center of Bruch's membrane opening. Geometric deep learning (PointNet) was then used to provide a glaucoma diagnosis from a single OCT point cloud. The performance of our approach was compared to that obtained with a 3D CNN, and with RNFL thickness. Results: PointNet was able to provide a robust glaucoma diagnosis solely from the ONH represented as a 3D point cloud (AUC=95%). The performance of PointNet was superior to that obtained with a standard 3D CNN (AUC=87%) and with that obtained from RNFL thickness alone (AUC=80%). Discussion: We provide a proof-of-principle for the application of geometric deep learning in the field of glaucoma. Our technique requires significantly less information as input to perform better than a 3D CNN, and with an AUC superior to that obtained from RNFL thickness alone. Geometric deep learning may have wide applicability in the field of Ophthalmology.
A Hybrid Framework for Sequential Data Prediction with End-to-End Optimization
Mar 25, 2022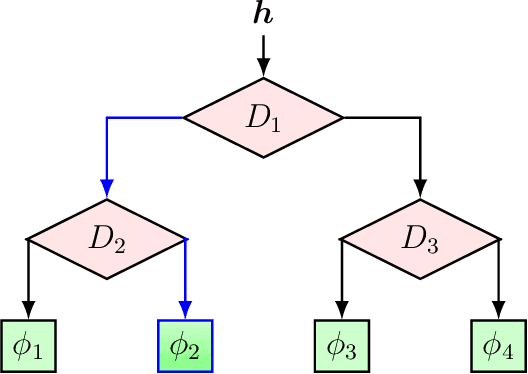
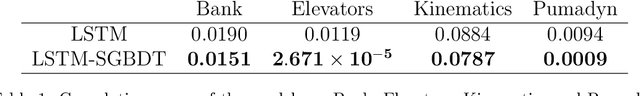
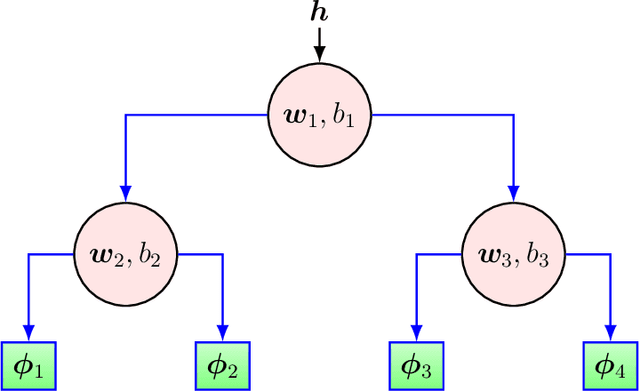

We investigate nonlinear prediction in an online setting and introduce a hybrid model that effectively mitigates, via an end-to-end architecture, the need for hand-designed features and manual model selection issues of conventional nonlinear prediction/regression methods. In particular, we use recursive structures to extract features from sequential signals, while preserving the state information, i.e., the history, and boosted decision trees to produce the final output. The connection is in an end-to-end fashion and we jointly optimize the whole architecture using stochastic gradient descent, for which we also provide the backward pass update equations. In particular, we employ a recurrent neural network (LSTM) for adaptive feature extraction from sequential data and a gradient boosting machinery (soft GBDT) for effective supervised regression. Our framework is generic so that one can use other deep learning architectures for feature extraction (such as RNNs and GRUs) and machine learning algorithms for decision making as long as they are differentiable. We demonstrate the learning behavior of our algorithm on synthetic data and the significant performance improvements over the conventional methods over various real life datasets. Furthermore, we openly share the source code of the proposed method to facilitate further research.