 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the dynamics of credit history and social interaction features, and their impact on creditworthiness assessment performance
Apr 13, 2022

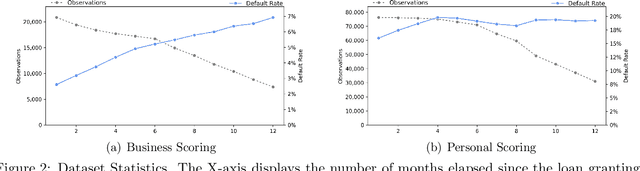
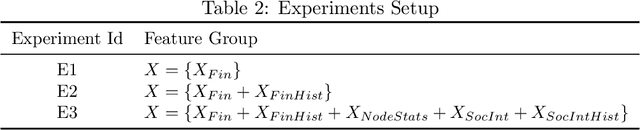
For more than a half-century, credit risk management has used credit scoring models in each of its well-defined stages to manage credit risk. Application scoring is used to decide whether to grant a credit or not, while behavioral scoring is used mainly for portfolio management and to take preventive actions in case of default signals. In both cases, network data has recently been shown to be valuable to increase the predictive power of these models, especially when the borrower's historical data is scarce or not available. This study aims to understand the creditworthiness assessment performance dynamics and how it is influenced by the credit history, repayment behavior, and social network features. To accomplish this, we introduced a machine learning classification framework to analyze 97.000 individuals and companies from the moment they obtained their first loan to 12 months afterward. Our novel and massive dataset allow us to characterize each borrower according to their credit behavior, and social and economic relationships. Our research shows that borrowers' history increases performance at a decreasing rate during the first six months and then stabilizes. The most notable effect on perfomance of social networks features occurs at loan application; in personal scoring, this effect prevails a few months, while in business scoring adds value throughout the study period. These findings are of great value to improve credit risk management and optimize the use of traditional information and alternative data sources.
Human Preferences as Dueling Bandits
Apr 21, 2022
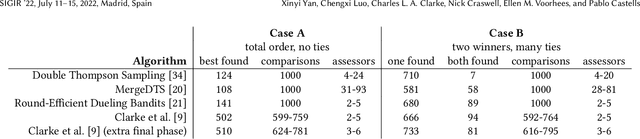
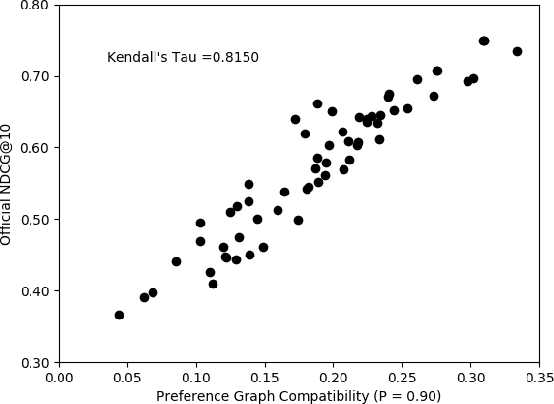
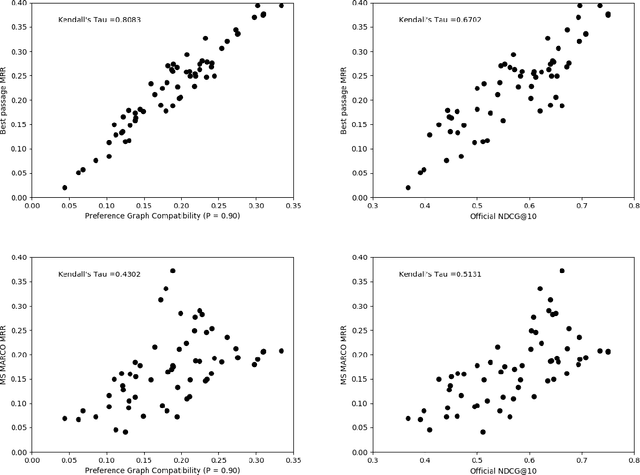
The dramatic improvements in core information retrieval tasks engendered by neural rankers create a need for novel evaluation methods. If every ranker returns highly relevant items in the top ranks, it becomes difficult to recognize meaningful differences between them and to build reusable test collections. Several recent papers explore pairwise preference judgments as an alternative to traditional graded relevance assessments. Rather than viewing items one at a time, assessors view items side-by-side and indicate the one that provides the better response to a query, allowing fine-grained distinctions. If we employ preference judgments to identify the probably best items for each query, we can measure rankers by their ability to place these items as high as possible. We frame the problem of finding best items as a dueling bandits problem. While many papers explore dueling bandits for online ranker evaluation via interleaving, they have not been considered as a framework for offline evaluation via human preference judgments. We review the literature for possible solutions. For human preference judgments, any usable algorithm must tolerate ties, since two items may appear nearly equal to assessors, and it must minimize the number of judgments required for any specific pair, since each such comparison requires an independent assessor. Since the theoretical guarantees provided by most algorithms depend on assumptions that are not satisfied by human preference judgments, we simulate selected algorithms on representative test cases to provide insight into their practical utility. Based on these simulations, one algorithm stands out for its potential. Our simulations suggest modifications to further improve its performance. Using the modified algorithm, we collect over 10,000 preference judgments for submissions to the TREC 2021 Deep Learning Track, confirming its suitability.
HIME: Efficient Headshot Image Super-Resolution with Multiple Exemplars
Mar 28, 2022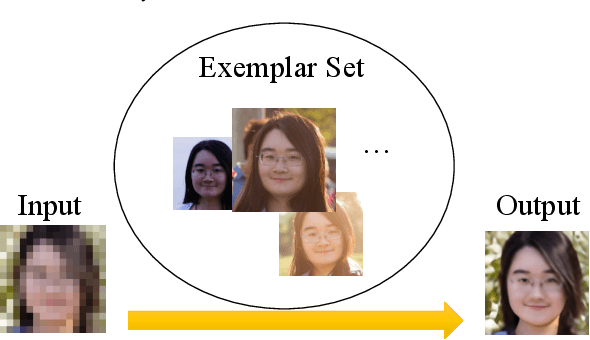
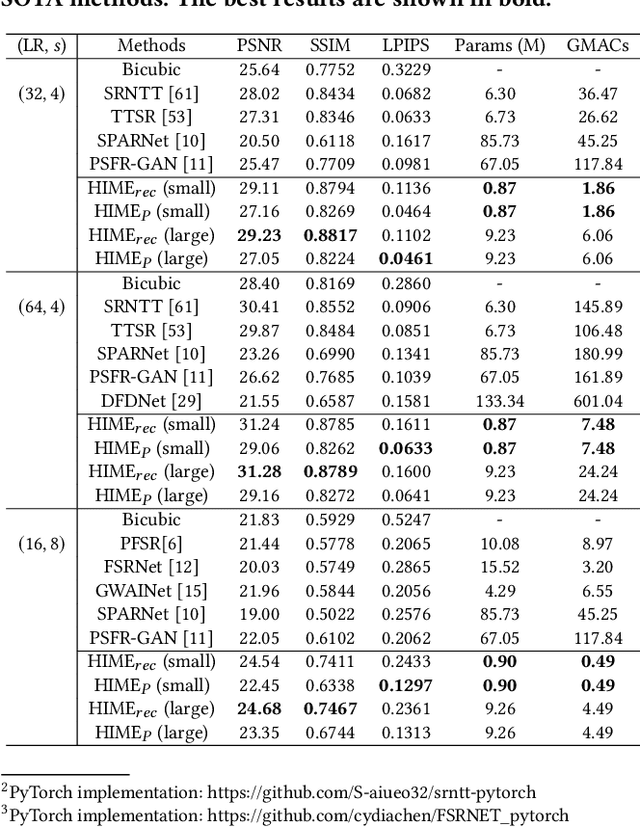
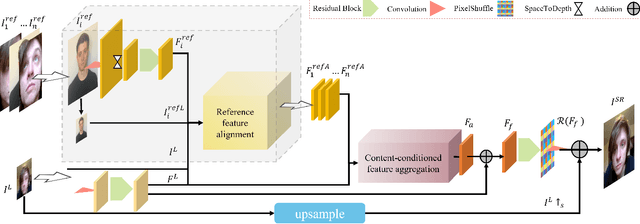
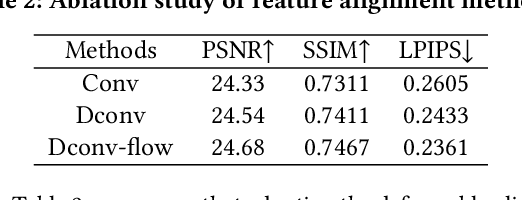
A promising direction for recovering the lost information in low-resolution headshot images is utilizing a set of high-resolution exemplars from the same identity. Complementary images in the reference set can improve the generated headshot quality across many different views and poses. However, it is challenging to make the best use of multiple exemplars: the quality and alignment of each exemplar cannot be guaranteed. Using low-quality and mismatched images as references will impair the output results. To overcome these issues, we propose an efficient Headshot Image Super-Resolution with Multiple Exemplars network (HIME) method. Compared with previous methods, our network can effectively handle the misalignment between the input and the reference without requiring facial priors and learn the aggregated reference set representation in an end-to-end manner. Furthermore, to reconstruct more detailed facial features, we propose a correlation loss that provides a rich representation of the local texture in a controllable spatial range. Experimental results demonstrate that the proposed framework not only has significantly fewer computation cost than recent exemplar-guided methods but also achieves better qualitative and quantitative performance.
Modular Adaptive Policy Selection for Multi-Task Imitation Learning through Task Division
Mar 28, 2022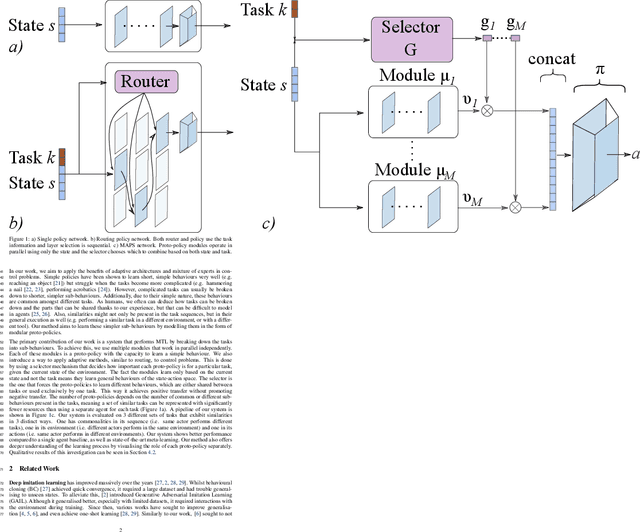

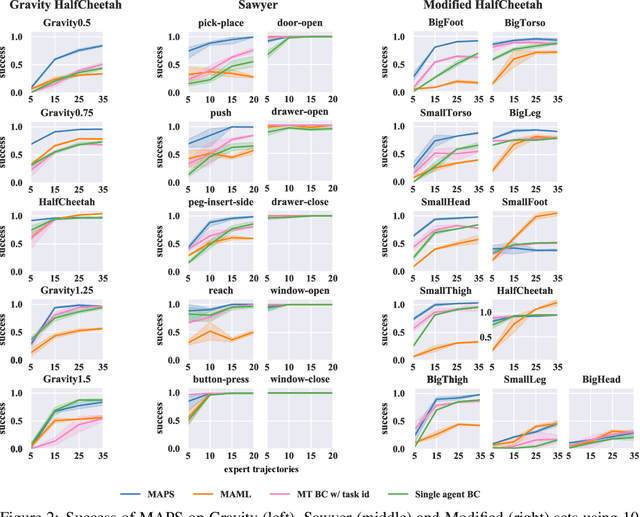
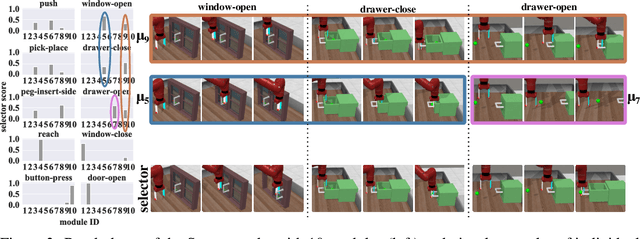
Deep imitation learning requires many expert demonstrations, which can be hard to obtain, especially when many tasks are involved. However, different tasks often share similarities, so learning them jointly can greatly benefit them and alleviate the need for many demonstrations. But, joint multi-task learning often suffers from negative transfer, sharing information that should be task-specific. In this work, we introduce a method to perform multi-task imitation while allowing for task-specific features. This is done by using proto-policies as modules to divide the tasks into simple sub-behaviours that can be shared. The proto-policies operate in parallel and are adaptively chosen by a selector mechanism that is jointly trained with the modules. Experiments on different sets of tasks show that our method improves upon the accuracy of single agents, task-conditioned and multi-headed multi-task agents, as well as state-of-the-art meta learning agents. We also demonstrate its ability to autonomously divide the tasks into both shared and task-specific sub-behaviours.
Reconstruction of Incomplete Wildfire Data using Deep Generative Models
Jan 16, 2022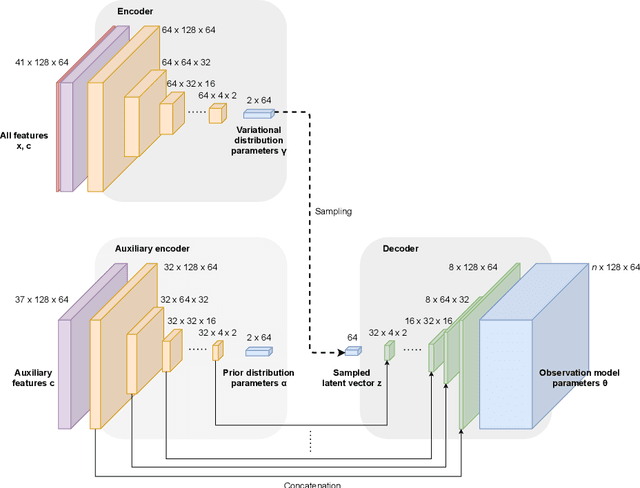
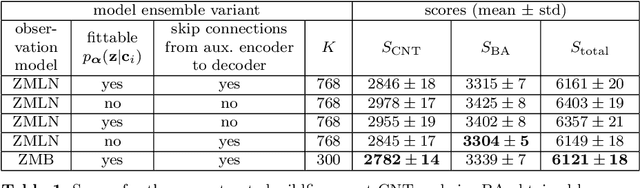
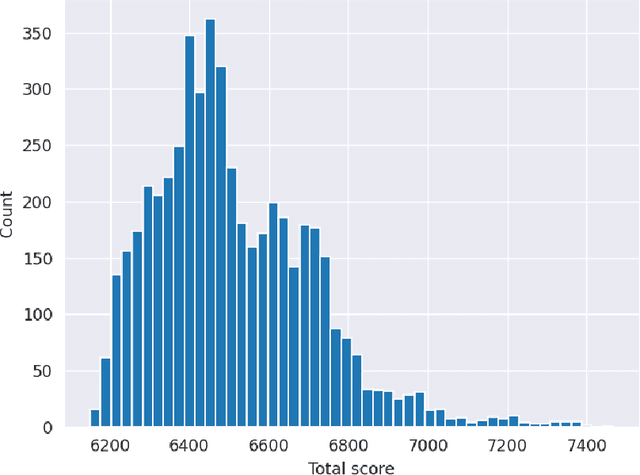
We present our submission to the Extreme Value Analysis 2021 Data Challenge in which teams were asked to accurately predict distributions of wildfire frequency and size within spatio-temporal regions of missing data. For the purpose of this competition we developed a variant of the powerful variational autoencoder models dubbed the Conditional Missing data Importance-Weighted Autoencoder (CMIWAE). Our deep latent variable generative model requires little to no feature engineering and does not necessarily rely on the specifics of scoring in the Data Challenge. It is fully trained on incomplete data, with the single objective to maximize log-likelihood of the observed wildfire information. We mitigate the effects of the relatively low number of training samples by stochastic sampling from a variational latent variable distribution, as well as by ensembling a set of CMIWAE models trained and validated on different splits of the provided data. The presented approach is not domain-specific and is amenable to application in other missing data recovery tasks with tabular or image-like information conditioned on auxiliary information.
Soundness of Data-Aware Processes with Arithmetic Conditions
Mar 28, 2022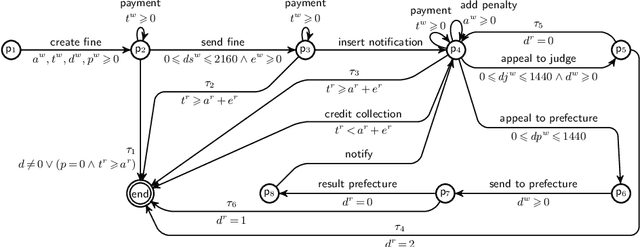
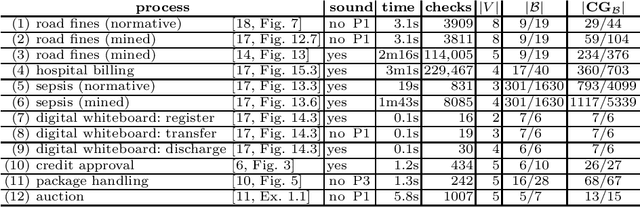
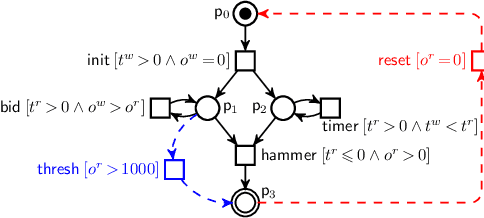
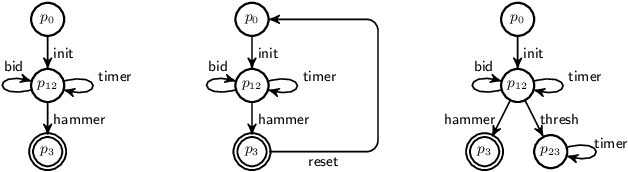
Data-aware processes represent and integrate structural and behavioural constraints in a single model, and are thus increasingly investigated in business process management and information systems engineering. In this spectrum, Data Petri nets (DPNs) have gained increasing popularity thanks to their ability to balance simplicity with expressiveness. The interplay of data and control-flow makes checking the correctness of such models, specifically the well-known property of soundness, crucial and challenging. A major shortcoming of previous approaches for checking soundness of DPNs is that they consider data conditions without arithmetic, an essential feature when dealing with real-world, concrete applications. In this paper, we attack this open problem by providing a foundational and operational framework for assessing soundness of DPNs enriched with arithmetic data conditions. The framework comes with a proof-of-concept implementation that, instead of relying on ad-hoc techniques, employs off-the-shelf established SMT technologies. The implementation is validated on a collection of examples from the literature, and on synthetic variants constructed from such examples.
Deep Collaborative Embedding for information cascade prediction
Jan 18, 2020
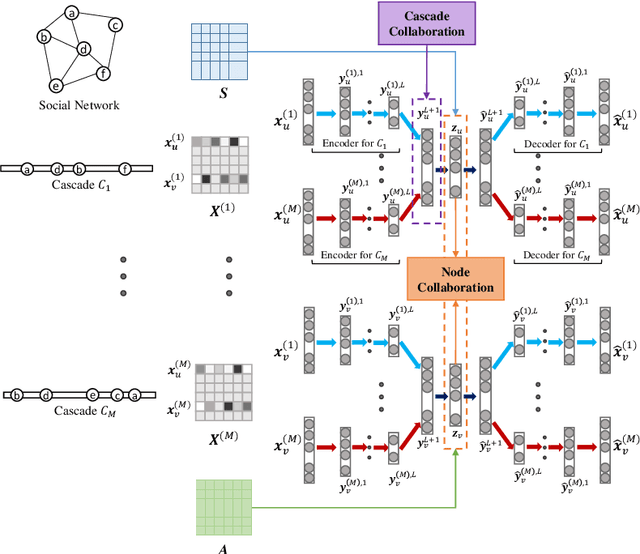
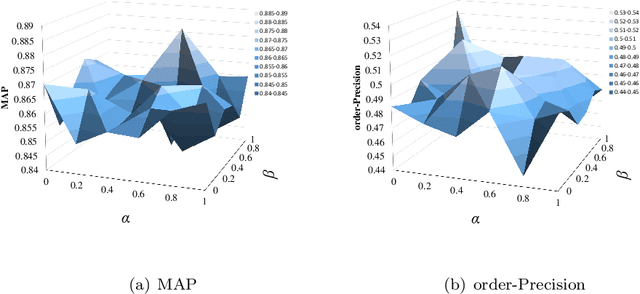
Recently, information cascade prediction has attracted increasing interest from researchers, but it is far from being well solved partly due to the three defects of the existing works. First, the existing works often assume an underlying information diffusion model, which is impractical in real world due to the complexity of information diffusion. Second, the existing works often ignore the prediction of the infection order, which also plays an important role in social network analysis. At last, the existing works often depend on the requirement of underlying diffusion networks which are likely unobservable in practice. In this paper, we aim at the prediction of both node infection and infection order without requirement of the knowledge about the underlying diffusion mechanism and the diffusion network, where the challenges are two-fold. The first is what cascading characteristics of nodes should be captured and how to capture them, and the second is that how to model the non-linear features of nodes in information cascades. To address these challenges, we propose a novel model called Deep Collaborative Embedding (DCE) for information cascade prediction, which can capture not only the node structural property but also two kinds of node cascading characteristics. We propose an auto-encoder based collaborative embedding framework to learn the node embeddings with cascade collaboration and node collaboration, in which way the non-linearity of information cascades can be effectively captured. The results of extensive experiments conducted on real-world datasets verify the effectiveness of our approach.
BeeTS: Smart Distributed Sensor Tuple Spaces combined with Agents using Bluetooth and IP Broadcasting
Apr 05, 2022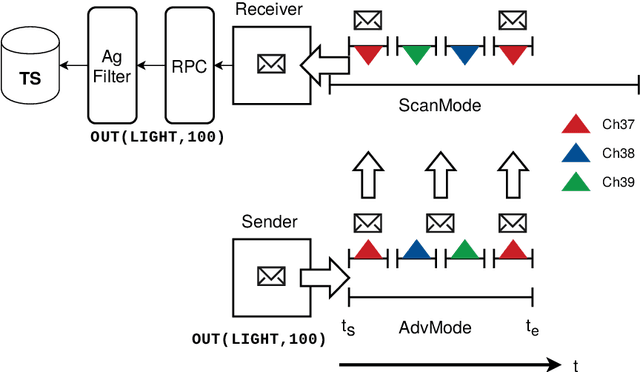
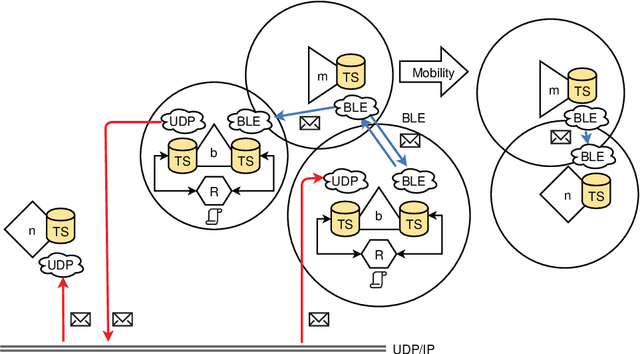
Most Internet-of-Things (IoT) devices and smart sensors are connected via the Internet using IP communication driectly accessed by a server that collect sensor information periodically or event-based. Although, Internet access is widely available, there are places that are not covered and WLAN and mobile cell communication requires a descent amount of power not always available. Finally, the spatial context (the environment in which the sensor or devices is situated) is not considered (or lost) by Internet connectivity. In this work, smart devices communicate connectionless and ad-hoc by using low-energy Bluetooth broadcasting available in any smartphone and in most embedded computers, e.g., the Raspberry PI devices. Bi-directional connectionless communication is established via the advertisements and scanning modes. The communication nodes can exchange data via functional tuples using a tuple space service on each node. Tuple space access is performed by simple evenat-based agents. Mobile devices act as tuple carriers that can carry tuples between different locations. Additionally, UDP-based Intranet communication can be used to access tuple spaces on a wider spatial range. The Bluetooth Low Energy Tuple Space (BeeTS) service enables opportunistic, ad-hoc and loosely coupled device communication with a spatial context.
Exploring Optical-Flow-Guided Motion and Detection-Based Appearance for Temporal Sentence Grounding
Mar 06, 2022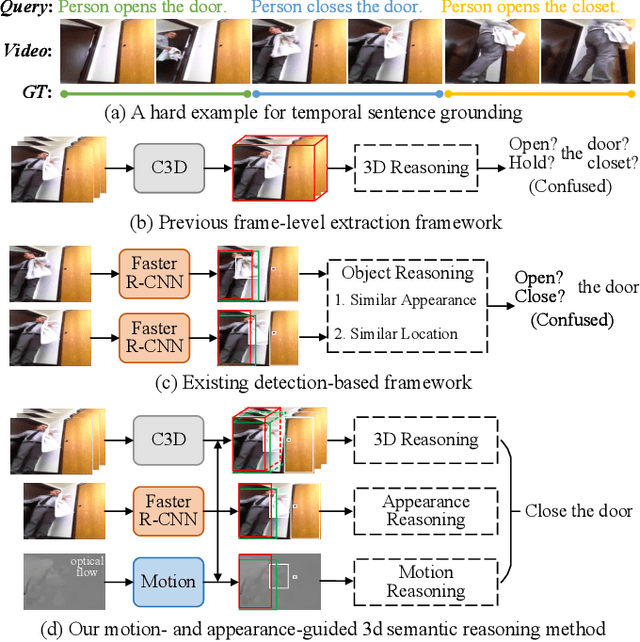
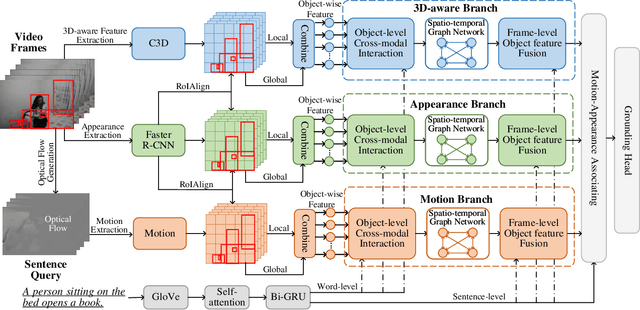
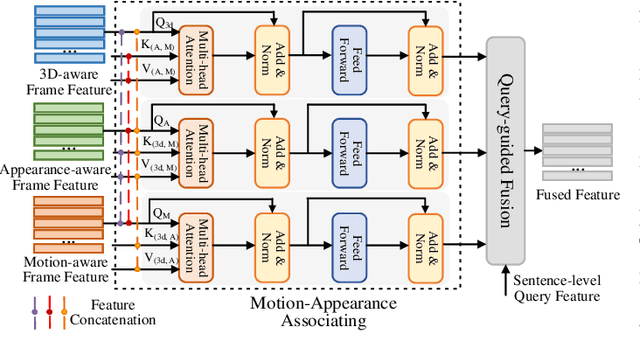
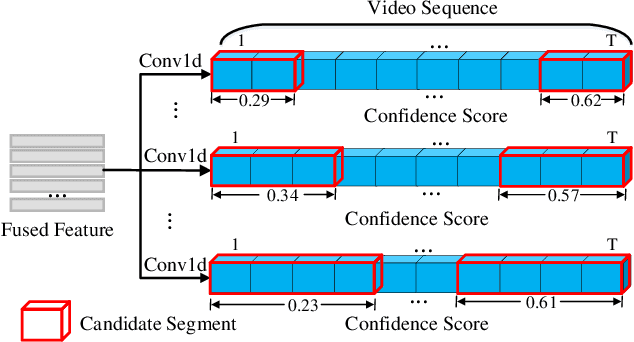
Temporal sentence grounding aims to localize a target segment in an untrimmed video semantically according to a given sentence query. Most previous works focus on learning frame-level features of each whole frame in the entire video, and directly match them with the textual information. Such frame-level feature extraction leads to the obstacles of these methods in distinguishing ambiguous video frames with complicated contents and subtle appearance differences, thus limiting their performance. In order to differentiate fine-grained appearance similarities among consecutive frames, some state-of-the-art methods additionally employ a detection model like Faster R-CNN to obtain detailed object-level features in each frame for filtering out the redundant background contents. However, these methods suffer from missing motion analysis since the object detection module in Faster R-CNN lacks temporal modeling. To alleviate the above limitations, in this paper, we propose a novel Motion- and Appearance-guided 3D Semantic Reasoning Network (MA3SRN), which incorporates optical-flow-guided motion-aware, detection-based appearance-aware, and 3D-aware object-level features to better reason the spatial-temporal object relations for accurately modelling the activity among consecutive frames. Specifically, we first develop three individual branches for motion, appearance, and 3D encoding separately to learn fine-grained motion-guided, appearance-guided, and 3D-aware object features, respectively. Then, both motion and appearance information from corresponding branches are associated to enhance the 3D-aware features for the final precise grounding. Extensive experiments on three challenging datasets (ActivityNet Caption, Charades-STA and TACoS) demonstrate that the proposed MA3SRN model achieves a new state-of-the-art.
Adaptive and Cascaded Compressive Sensing
Mar 21, 2022
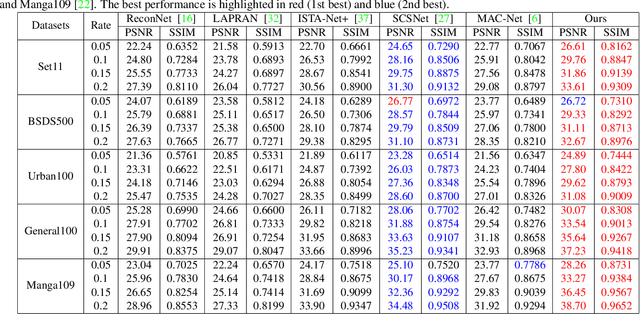
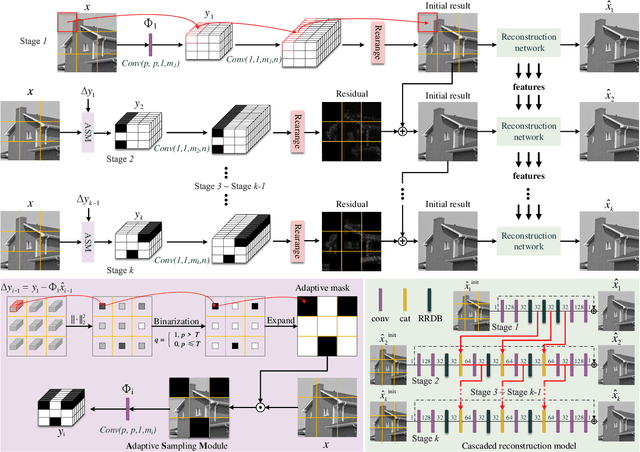
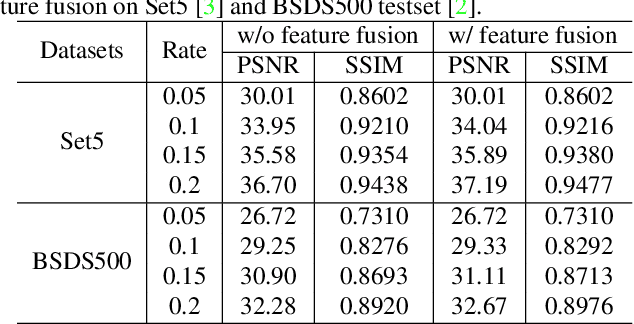
Scene-dependent adaptive compressive sensing (CS) has been a long pursuing goal which has huge potential in significantly improving the performance of CS. However, without accessing to the ground truth image, how to design the scene-dependent adaptive strategy is still an open-problem and the improvement in sampling efficiency is still quite limited. In this paper, a restricted isometry property (RIP) condition based error clamping is proposed, which could directly predict the reconstruction error, i.e. the difference between the currently-stage reconstructed image and the ground truth image, and adaptively allocate samples to different regions at the successive sampling stage. Furthermore, we propose a cascaded feature fusion reconstruction network that could efficiently utilize the information derived from different adaptive sampling stages. The effectiveness of the proposed adaptive and cascaded CS method is demonstrated with extensive quantitative and qualitative results, compared with the state-of-the-art CS algorithms.