 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Separate What You Describe: Language-Queried Audio Source Separation
Mar 28, 2022

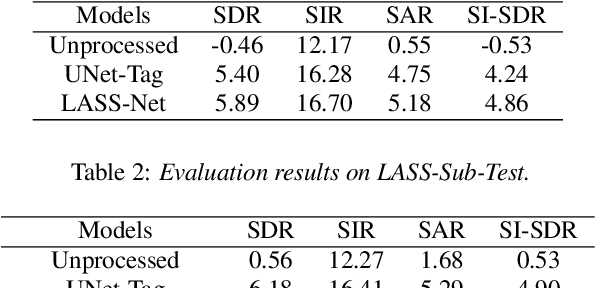

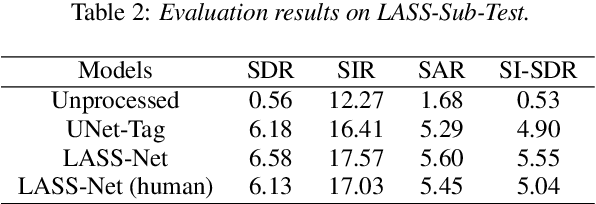
In this paper, we introduce the task of language-queried audio source separation (LASS), which aims to separate a target source from an audio mixture based on a natural language query of the target source (e.g., "a man tells a joke followed by people laughing"). A unique challenge in LASS is associated with the complexity of natural language description and its relation with the audio sources. To address this issue, we proposed LASS-Net, an end-to-end neural network that is learned to jointly process acoustic and linguistic information, and separate the target source that is consistent with the language query from an audio mixture. We evaluate the performance of our proposed system with a dataset created from the AudioCaps dataset. Experimental results show that LASS-Net achieves considerable improvements over baseline methods. Furthermore, we observe that LASS-Net achieves promising generalization results when using diverse human-annotated descriptions as queries, indicating its potential use in real-world scenarios. The separated audio samples and source code are available at https://liuxubo717.github.io/LASS-demopage.
MHTTS: Fast multi-head text-to-speech for spontaneous speech with imperfect transcription
Feb 04, 2022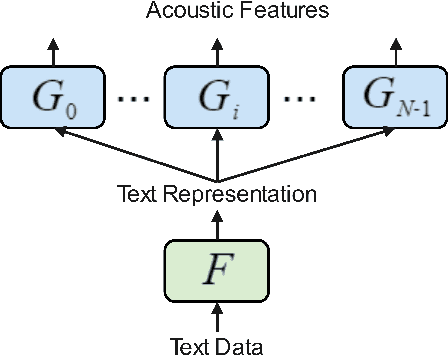
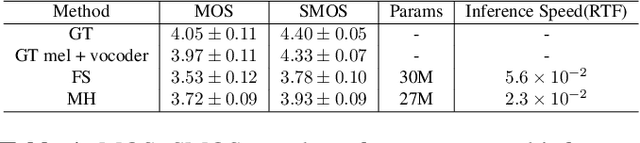
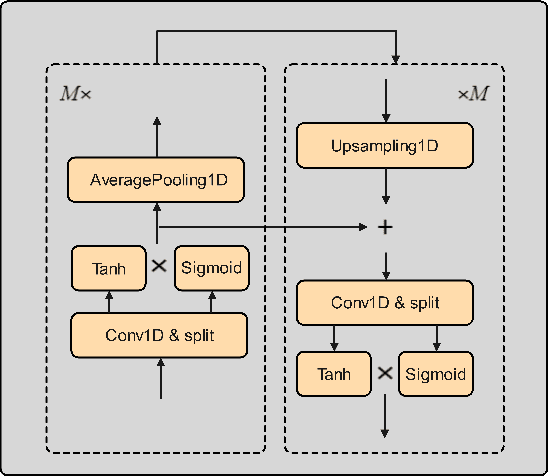
Neural network based end-to-end Text-to-Speech (TTS) has greatly improved the quality of synthesized speech. While how to use massive spontaneous speech without transcription efficiently still remains an open problem. In this paper, we propose MHTTS, a fast multi-speaker TTS system that is robust to transcription errors and speaking style speech data. Specifically, we introduce a multi-head model and transfer text information from high-quality corpus with manual transcription to spontaneous speech with imperfectly recognized transcription by jointly training them. MHTTS has three advantages: 1) Our system synthesizes better quality multi-speaker voice with faster inference speed. 2) Our system is capable of transferring correct text information to data with imperfect transcription, simulated using corruption, or provided by an Automatic Speech Recogniser (ASR). 3) Our system can utilize massive real spontaneous speech with imperfect transcription and synthesize expressive voice.
Condensing a Sequence to One Informative Frame for Video Recognition
Jan 11, 2022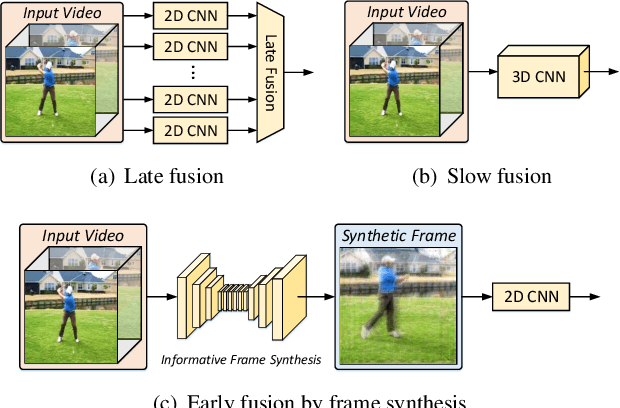
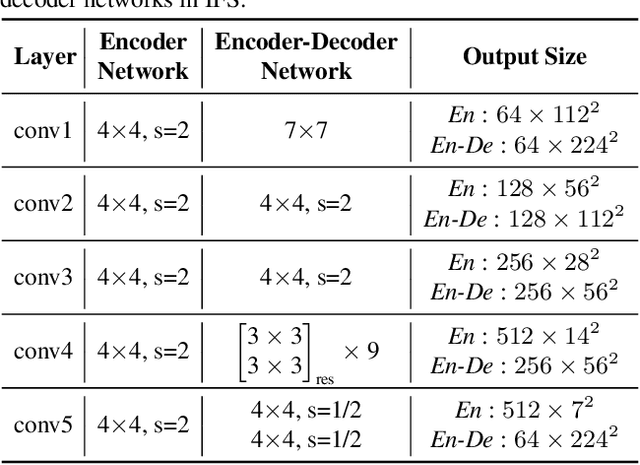
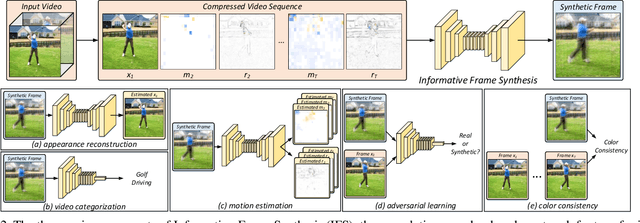
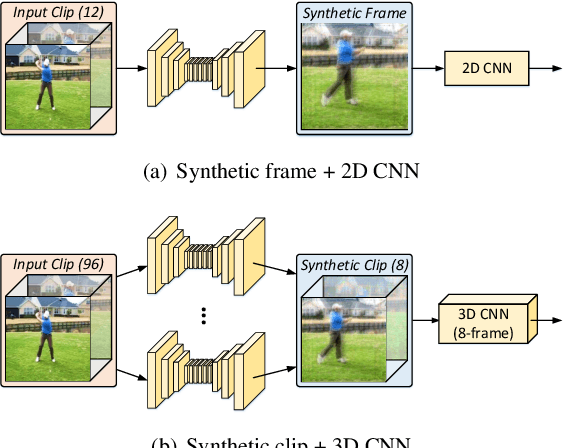
Video is complex due to large variations in motion and rich content in fine-grained visual details. Abstracting useful information from such information-intensive media requires exhaustive computing resources. This paper studies a two-step alternative that first condenses the video sequence to an informative "frame" and then exploits off-the-shelf image recognition system on the synthetic frame. A valid question is how to define "useful information" and then distill it from a video sequence down to one synthetic frame. This paper presents a novel Informative Frame Synthesis (IFS) architecture that incorporates three objective tasks, i.e., appearance reconstruction, video categorization, motion estimation, and two regularizers, i.e., adversarial learning, color consistency. Each task equips the synthetic frame with one ability, while each regularizer enhances its visual quality. With these, by jointly learning the frame synthesis in an end-to-end manner, the generated frame is expected to encapsulate the required spatio-temporal information useful for video analysis. Extensive experiments are conducted on the large-scale Kinetics dataset. When comparing to baseline methods that map video sequence to a single image, IFS shows superior performance. More remarkably, IFS consistently demonstrates evident improvements on image-based 2D networks and clip-based 3D networks, and achieves comparable performance with the state-of-the-art methods with less computational cost.
When Transformer Meets Robotic Grasping: Exploits Context for Efficient Grasp Detection
Feb 24, 2022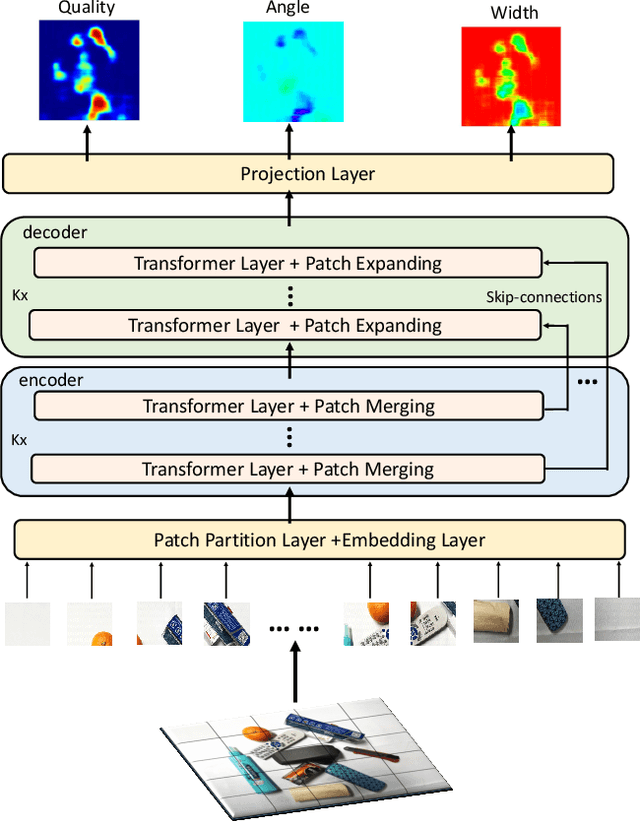
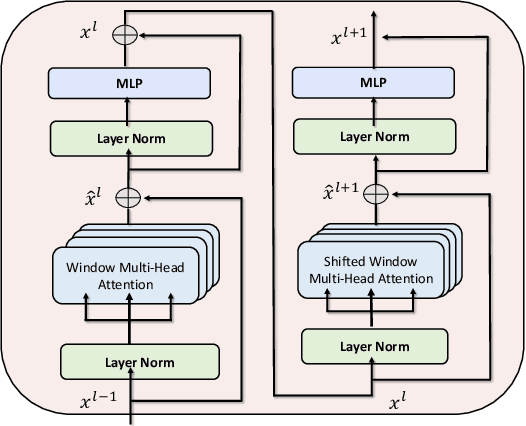


In this paper, we present a transformer-based architecture, namely TF-Grasp, for robotic grasp detection. The developed TF-Grasp framework has two elaborate designs making it well suitable for visual grasping tasks. The first key design is that we adopt the local window attention to capture local contextual information and detailed features of graspable objects. Then, we apply the cross window attention to model the long-term dependencies between distant pixels. Object knowledge, environmental configuration, and relationships between different visual entities are aggregated for subsequent grasp detection. The second key design is that we build a hierarchical encoder-decoder architecture with skip-connections, delivering shallow features from encoder to decoder to enable a multi-scale feature fusion. Due to the powerful attention mechanism, the TF-Grasp can simultaneously obtain the local information (i.e., the contours of objects), and model long-term connections such as the relationships between distinct visual concepts in clutter. Extensive computational experiments demonstrate that the TF-Grasp achieves superior results versus state-of-art grasping convolutional models and attain a higher accuracy of 97.99% and 94.6% on Cornell and Jacquard grasping datasets, respectively. Real-world experiments using a 7DoF Franka Emika Panda robot also demonstrate its capability of grasping unseen objects in a variety of scenarios. The code and pre-trained models will be available at https://github.com/WangShaoSUN/grasp-transformer
IOP-FL: Inside-Outside Personalization for Federated Medical Image Segmentation
Apr 16, 2022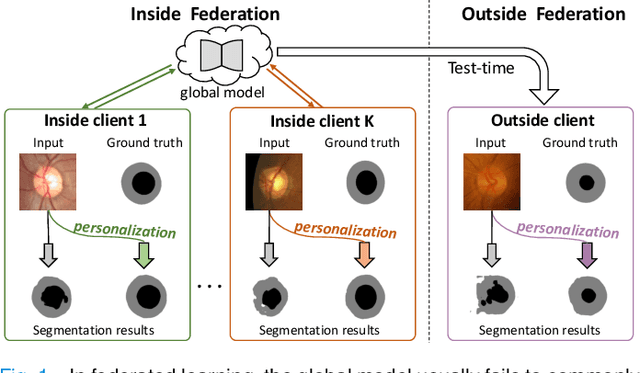
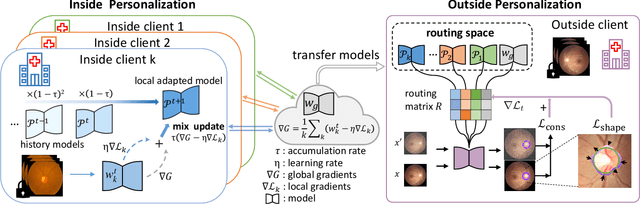
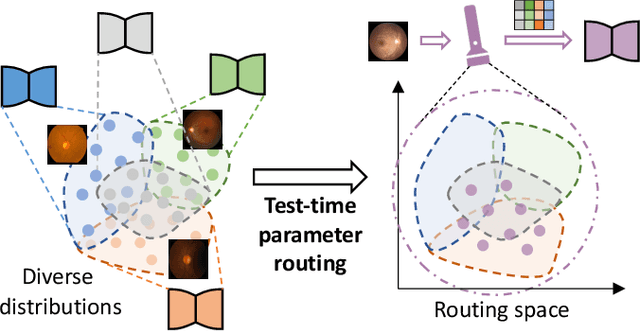
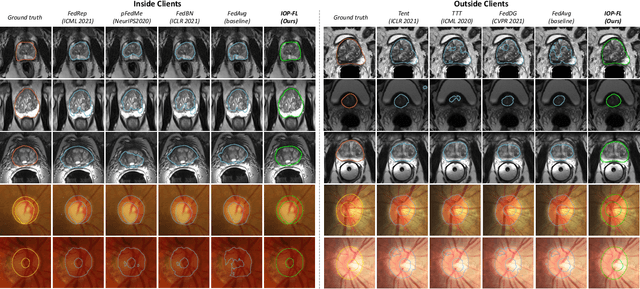
Federated learning (FL) allows multiple medical institutions to collaboratively learn a global model without centralizing all clients data. It is difficult, if possible at all, for such a global model to commonly achieve optimal performance for each individual client, due to the heterogeneity of medical data from various scanners and patient demographics. This problem becomes even more significant when deploying the global model to unseen clients outside the FL with new distributions not presented during federated training. To optimize the prediction accuracy of each individual client for critical medical tasks, we propose a novel unified framework for both Inside and Outside model Personalization in FL (IOP-FL). Our inside personalization is achieved by a lightweight gradient-based approach that exploits the local adapted model for each client, by accumulating both the global gradients for common knowledge and local gradients for client-specific optimization. Moreover, and importantly, the obtained local personalized models and the global model can form a diverse and informative routing space to personalize a new model for outside FL clients. Hence, we design a new test-time routing scheme inspired by the consistency loss with a shape constraint to dynamically incorporate the models, given the distribution information conveyed by the test data. Our extensive experimental results on two medical image segmentation tasks present significant improvements over SOTA methods on both inside and outside personalization, demonstrating the great potential of our IOP-FL scheme for clinical practice. Code will be released at https://github.com/med-air/IOP-FL.
On the Complementarity of Images and Text for the Expression of Emotions in Social Media
Feb 11, 2022
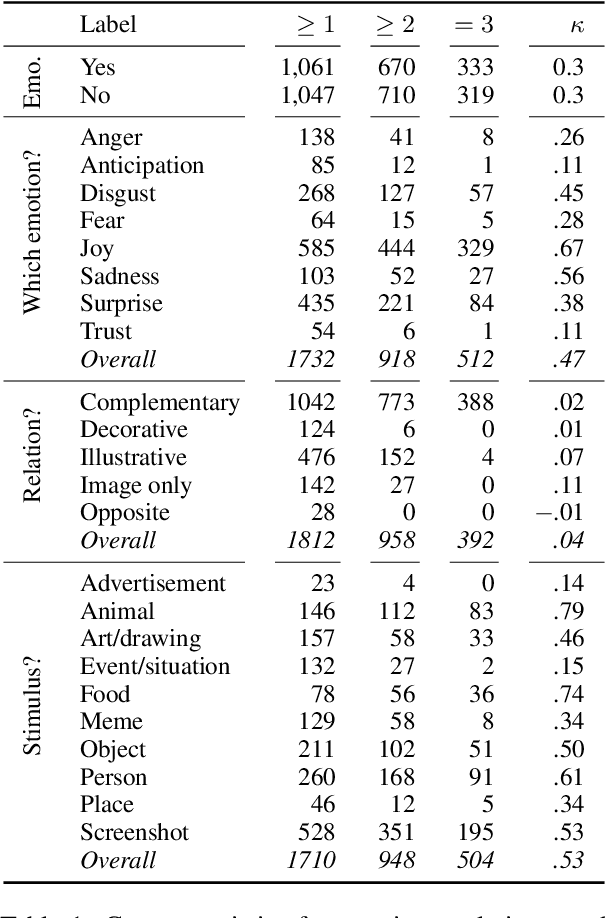


Authors of posts in social media communicate their emotions and what causes them with text and images. While there is work on emotion and stimulus detection for each modality separately, it is yet unknown if the modalities contain complementary emotion information in social media. We aim at filling this research gap and contribute a novel, annotated corpus of English multimodal Reddit posts. On this resource, we develop models to automatically detect the relation between image and text, an emotion stimulus category and the emotion class. We evaluate if these tasks require both modalities and find for the image-text relations, that text alone is sufficient for most categories (complementary, illustrative, opposing): the information in the text allows to predict if an image is required for emotion understanding. The emotions of anger and sadness are best predicted with a multimodal model, while text alone is sufficient for disgust, joy, and surprise. Stimuli depicted by objects, animals, food, or a person are best predicted by image-only models, while multimodal models are most effective on art, events, memes, places, or screenshots.
Boolean Observation Games
Feb 08, 2022

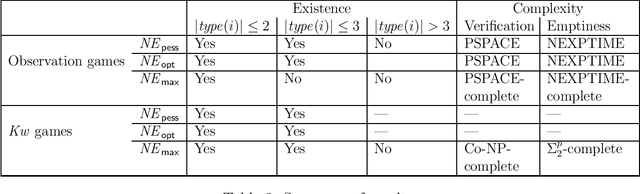
We introduce Boolean Observation Games, a subclass of multi-player finite strategic games with incomplete information and qualitative objectives. In Boolean observation games, each player is associated with a finite set of propositional variables of which only it can observe the value, and it controls whether and to whom it can reveal that value. It does not control the given, fixed, value of variables. Boolean observation games are a generalization of Boolean games, a well-studied subclass of strategic games but with complete information, and wherein each player controls the value of its variables. In Boolean observation games player goals describe multi-agent knowledge of variables. As in classical strategic games, players choose their strategies simultaneously and therefore observation games capture aspects of both imperfect and incomplete information. They require reasoning about sets of outcomes given sets of indistinguishable valuations of variables. What a Nash equilibrium is, depends on an outcome relation between such sets. We present various outcome relations, including a qualitative variant of ex-post equilibrium. We identify conditions under which, given an outcome relation, Nash equilibria are guaranteed to exist. We also study the complexity of checking for the existence of Nash equilibria and of verifying if a strategy profile is a Nash equilibrium. We further study the subclass of Boolean observation games with `knowing whether' goal formulas, for which the satisfaction does not depend on the value of variables. We show that each such Boolean observation game corresponds to a Boolean game and vice versa, by a different correspondence, and that both correspondences are precise in terms of existence of Nash equilibria.
Depth-resolved Laue microdiffraction with coded-apertures
Mar 03, 2022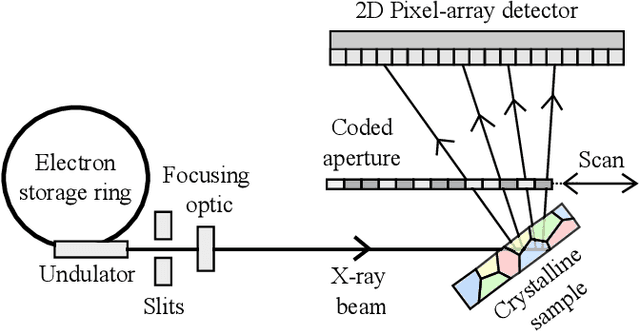

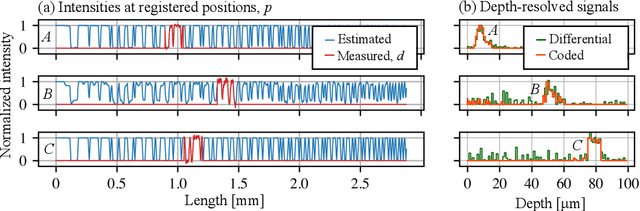
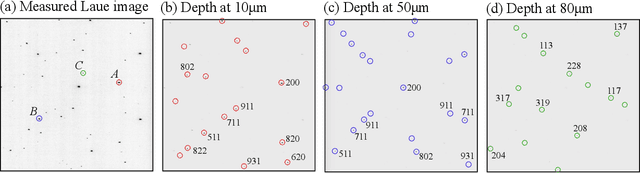
We introduce a rapid data acquisition and reconstruction method to image the crystalline structure of materials and associated strain and orientations at micrometer resolution using Laue diffraction. Our method relies on scanning a coded-aperture across the diffracted x-ray beams from a broadband illumination, and a reconstruction algorithm to resolve Laue microdiffraction patterns as a function of depth along the incident illumination path. This method provides a rapid access to full diffraction information at sub-micrometer volume elements in bulk materials. Here we present the theory as well as the experimental validation of this imaging approach.
How Do We Answer Complex Questions: Discourse Structure of Long-form Answers
Mar 21, 2022
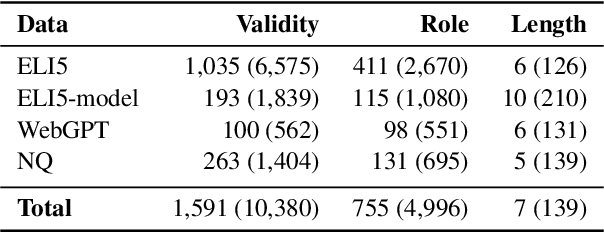
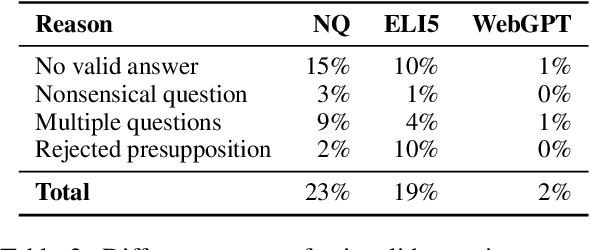
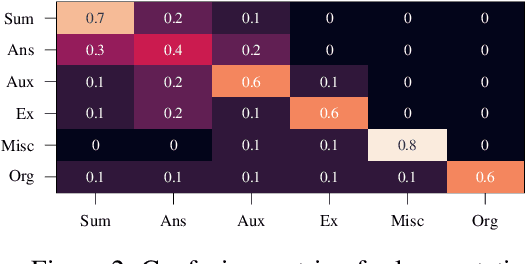
Long-form answers, consisting of multiple sentences, can provide nuanced and comprehensive answers to a broader set of questions. To better understand this complex and understudied task, we study the functional structure of long-form answers collected from three datasets, ELI5, WebGPT and Natural Questions. Our main goal is to understand how humans organize information to craft complex answers. We develop an ontology of six sentence-level functional roles for long-form answers, and annotate 3.9k sentences in 640 answer paragraphs. Different answer collection methods manifest in different discourse structures. We further analyze model-generated answers -- finding that annotators agree less with each other when annotating model-generated answers compared to annotating human-written answers. Our annotated data enables training a strong classifier that can be used for automatic analysis. We hope our work can inspire future research on discourse-level modeling and evaluation of long-form QA systems.
TANet: Thread-Aware Pretraining for Abstractive Conversational Summarization
Apr 09, 2022
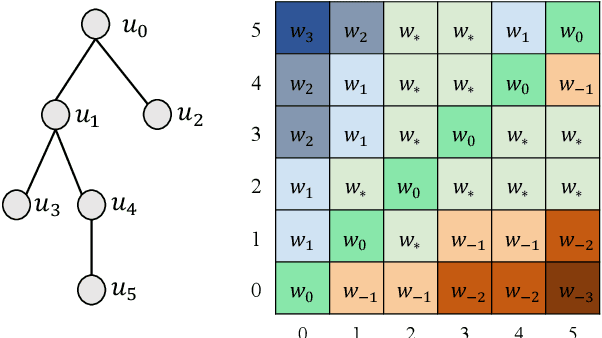
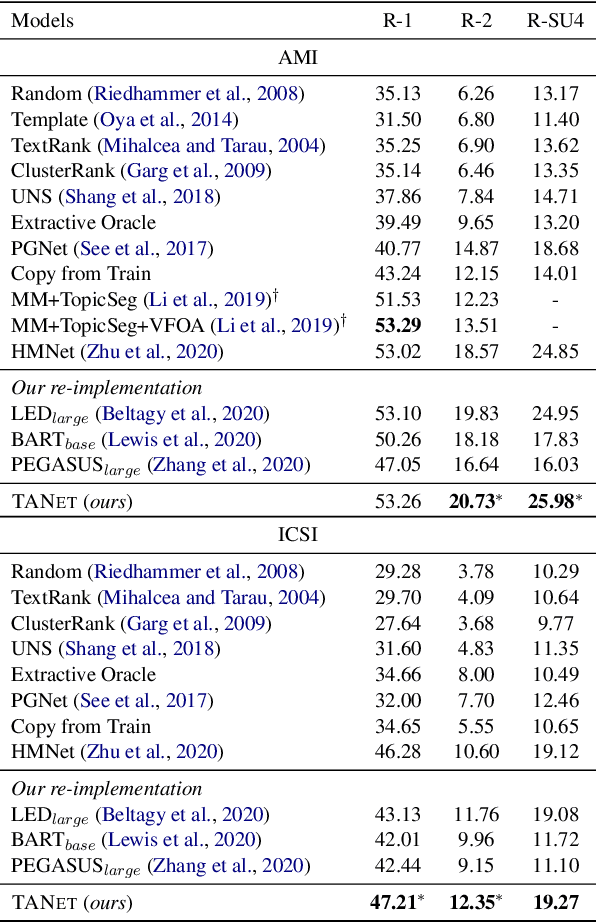
Although pre-trained language models (PLMs) have achieved great success and become a milestone in NLP, abstractive conversational summarization remains a challenging but less studied task. The difficulty lies in two aspects. One is the lack of large-scale conversational summary data. Another is that applying the existing pre-trained models to this task is tricky because of the structural dependence within the conversation and its informal expression, etc. In this work, we first build a large-scale (11M) pretraining dataset called RCS, based on the multi-person discussions in the Reddit community. We then present TANet, a thread-aware Transformer-based network. Unlike the existing pre-trained models that treat a conversation as a sequence of sentences, we argue that the inherent contextual dependency among the utterances plays an essential role in understanding the entire conversation and thus propose two new techniques to incorporate the structural information into our model. The first is thread-aware attention which is computed by taking into account the contextual dependency within utterances. Second, we apply thread prediction loss to predict the relations between utterances. We evaluate our model on four datasets of real conversations, covering types of meeting transcripts, customer-service records, and forum threads. Experimental results demonstrate that TANET achieves a new state-of-the-art in terms of both automatic evaluation and human judgment.