 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Quantifying Relevance in Learning and Inference
Feb 01, 2022
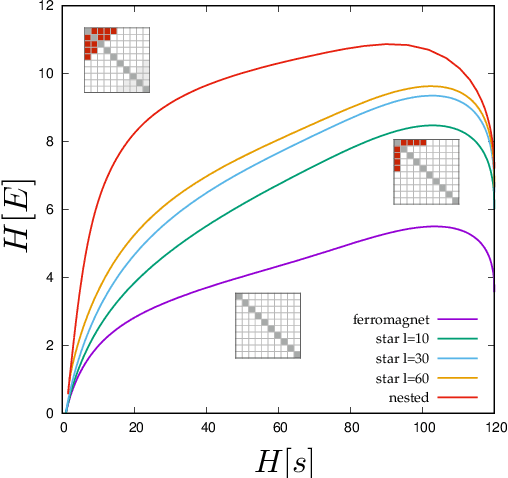
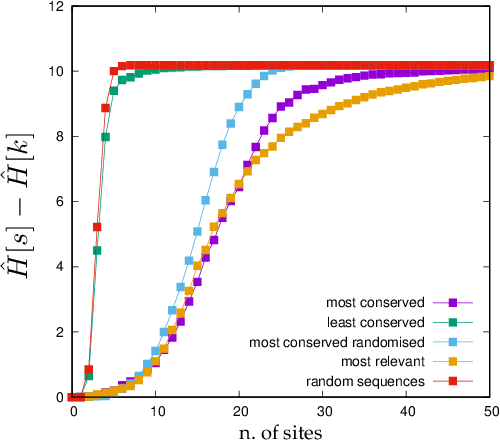
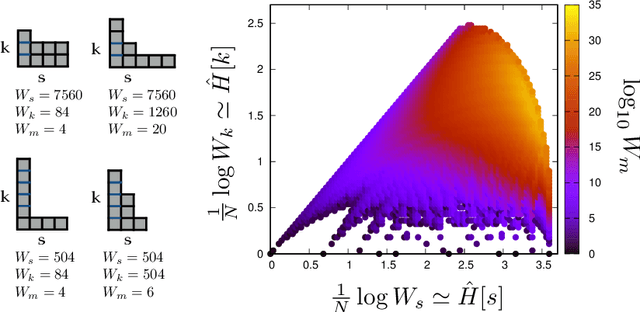
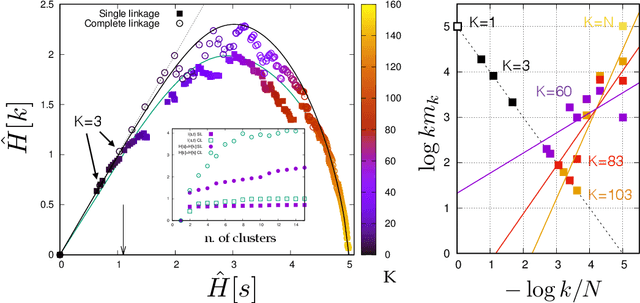
Learning is a distinctive feature of intelligent behaviour. High-throughput experimental data and Big Data promise to open new windows on complex systems such as cells, the brain or our societies. Yet, the puzzling success of Artificial Intelligence and Machine Learning shows that we still have a poor conceptual understanding of learning. These applications push statistical inference into uncharted territories where data is high-dimensional and scarce, and prior information on "true" models is scant if not totally absent. Here we review recent progress on understanding learning, based on the notion of "relevance". The relevance, as we define it here, quantifies the amount of information that a dataset or the internal representation of a learning machine contains on the generative model of the data. This allows us to define maximally informative samples, on one hand, and optimal learning machines on the other. These are ideal limits of samples and of machines, that contain the maximal amount of information about the unknown generative process, at a given resolution (or level of compression). Both ideal limits exhibit critical features in the statistical sense: Maximally informative samples are characterised by a power-law frequency distribution (statistical criticality) and optimal learning machines by an anomalously large susceptibility. The trade-off between resolution (i.e. compression) and relevance distinguishes the regime of noisy representations from that of lossy compression. These are separated by a special point characterised by Zipf's law statistics. This identifies samples obeying Zipf's law as the most compressed loss-less representations that are optimal in the sense of maximal relevance. Criticality in optimal learning machines manifests in an exponential degeneracy of energy levels, that leads to unusual thermodynamic properties.
Localized Feature Aggregation Module for Semantic Segmentation
Dec 03, 2021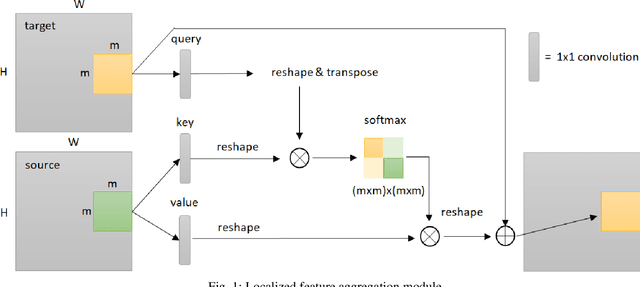
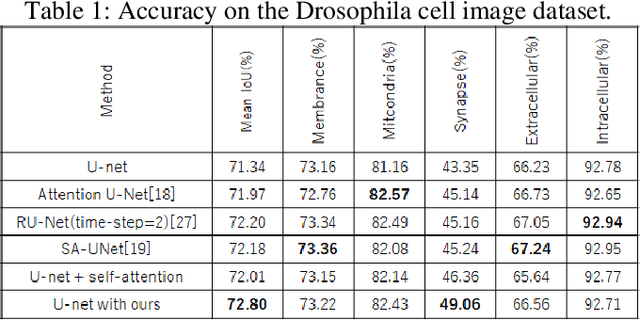
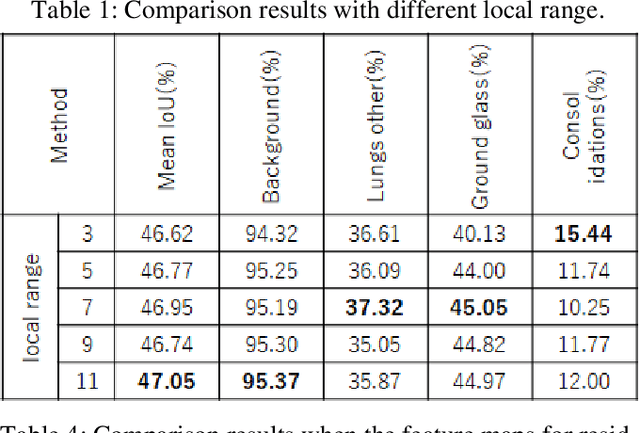
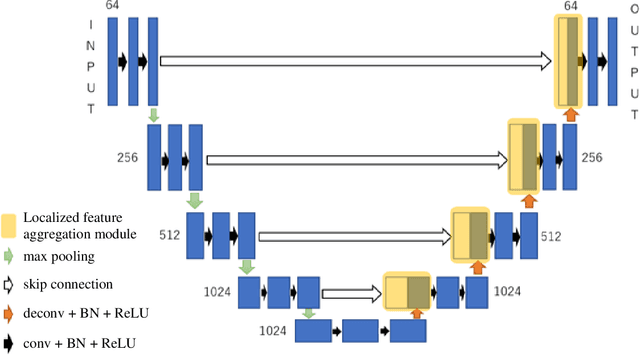
We propose a new information aggregation method which called Localized Feature Aggregation Module based on the similarity between the feature maps of an encoder and a decoder. The proposed method recovers positional information by emphasizing the similarity between decoder's feature maps with superior semantic information and encoder's feature maps with superior positional information. The proposed method can learn positional information more efficiently than conventional concatenation in the U-net and attention U-net. Additionally, the proposed method also uses localized attention range to reduce the computational cost. Two innovations contributed to improve the segmentation accuracy with lower computational cost. By experiments on the Drosophila cell image dataset and COVID-19 image dataset, we confirmed that our method outperformed conventional methods.
Significant Low-dimensional Spectral-temporal Features for Seizure Detection
Feb 13, 2022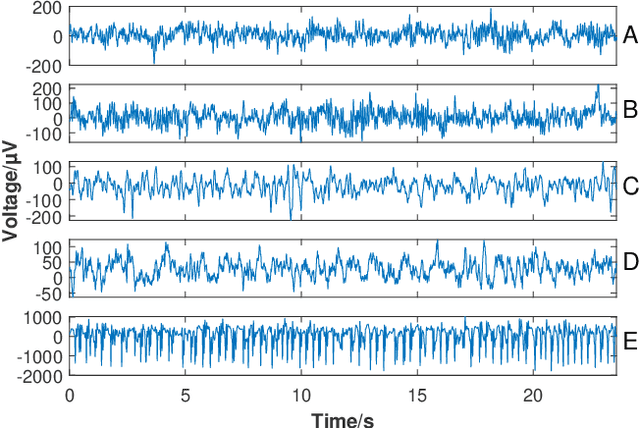
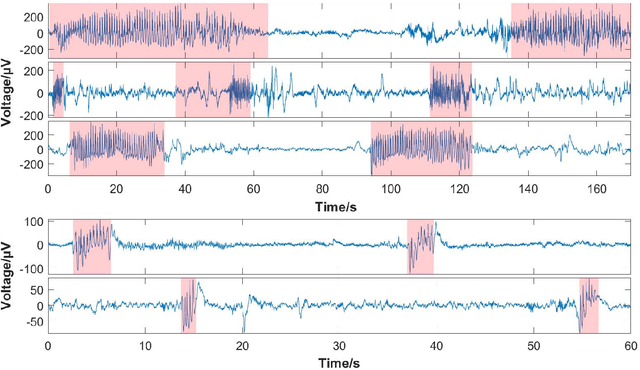
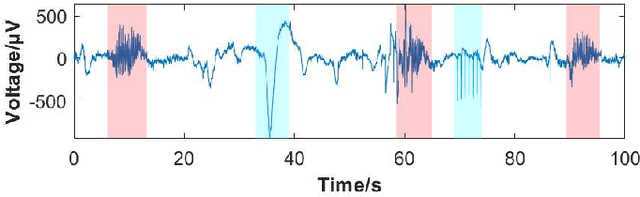
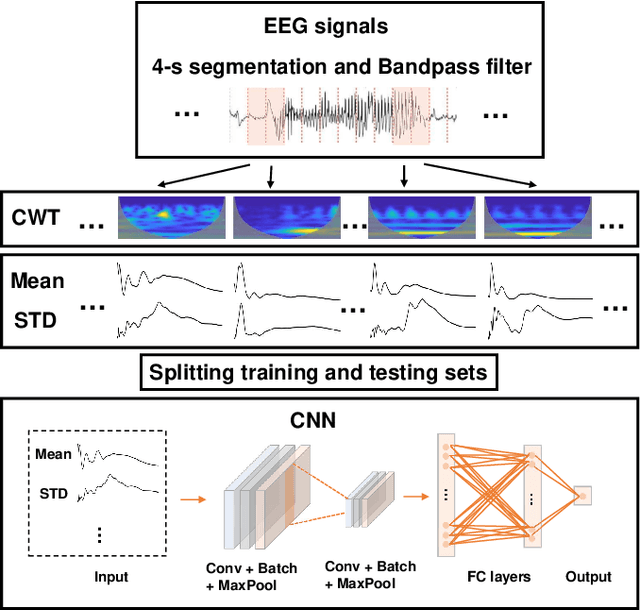
Seizure onset detection in electroencephalography (EEG) signals is a challenging task due to the non-stereotyped seizure activities as well as their stochastic and non-stationary characteristics in nature. Joint spectral-temporal features are believed to contain sufficient and powerful feature information for absence seizure detection. However, the resulting high-dimensional features involve redundant information and require heavy computational load. Here, we discover significant low-dimensional spectral-temporal features in terms of mean-standard deviation of wavelet transform coefficient (MS-WTC), based on which a novel absence seizure detection framework is developed. The EEG signals are transformed into the spectral-temporal domain, with their low-dimensional features fed into a convolutional neural network. Superior detection performance is achieved on the widely-used benchmark dataset as well as a clinical dataset from the Chinese 301 Hospital. For the former, seven classification tasks were evaluated with the accuracy from 99.8% to 100.0%, while for the latter, the method achieved a mean accuracy of 94.7%, overwhelming other methods with low-dimensional temporal and spectral features. Experimental results on two seizure datasets demonstrate reliability, efficiency and stability of our proposed MS-WTC method, validating the significance of the extracted low-dimensional spectral-temporal features.
Context Enhanced Short Text Matching using Clickthrough Data
Mar 03, 2022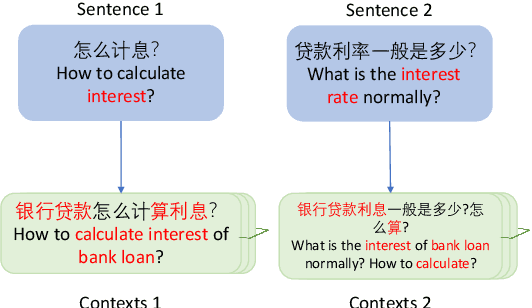
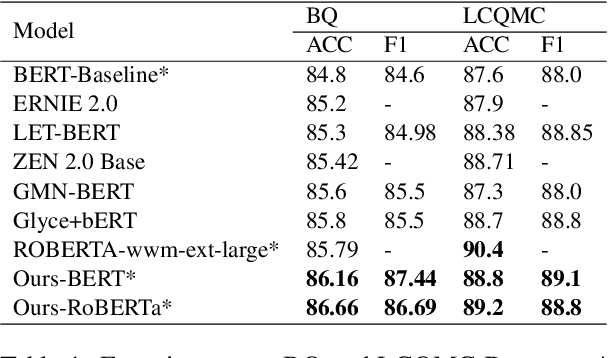
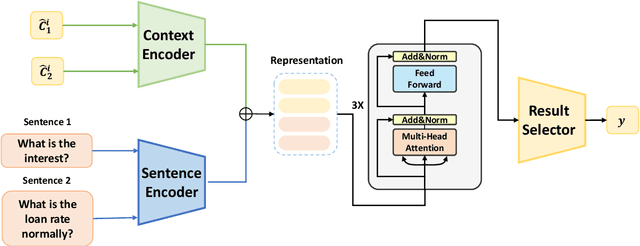
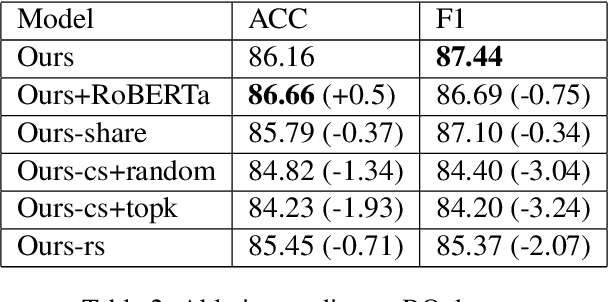
The short text matching task employs a model to determine whether two short texts have the same semantic meaning or intent. Existing short text matching models usually rely on the content of short texts which are lack information or missing some key clues. Therefore, the short texts need external knowledge to complete their semantic meaning. To address this issue, we propose a new short text matching framework for introducing external knowledge to enhance the short text contextual representation. In detail, we apply a self-attention mechanism to enrich short text representation with external contexts. Experiments on two Chinese datasets and one English dataset demonstrate that our framework outperforms the state-of-the-art short text matching models.
Self-attention Multi-view Representation Learning with Diversity-promoting Complementarity
Jan 01, 2022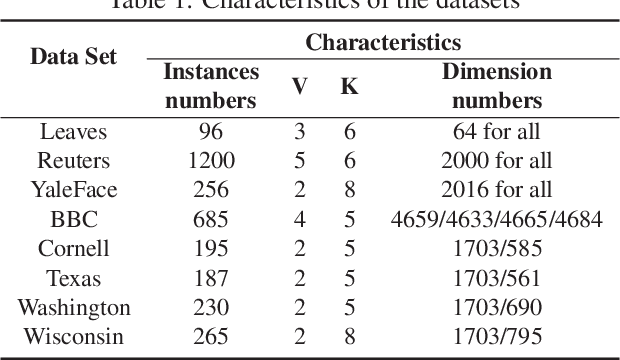
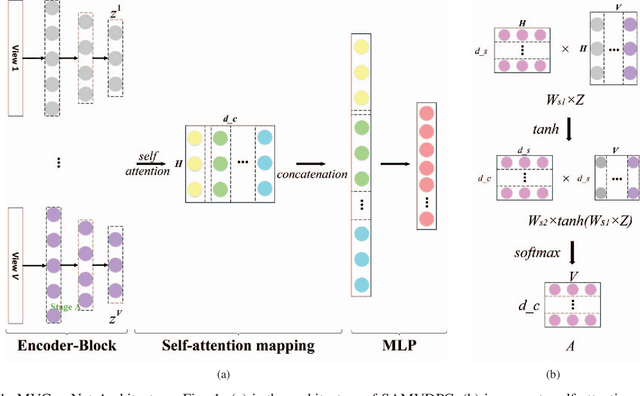
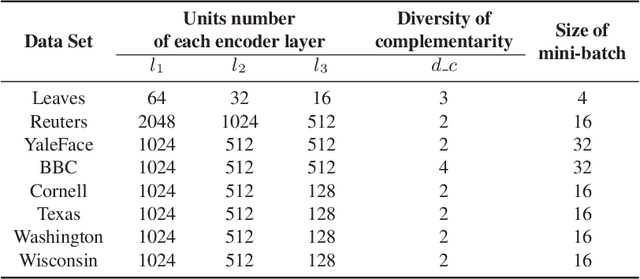
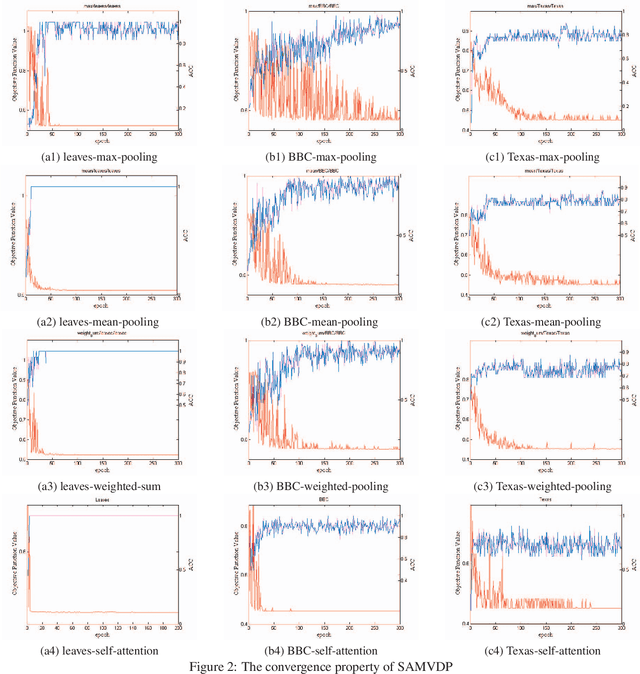
Multi-view learning attempts to generate a model with a better performance by exploiting the consensus and/or complementarity among multi-view data. However, in terms of complementarity, most existing approaches only can find representations with single complementarity rather than complementary information with diversity. In this paper, to utilize both complementarity and consistency simultaneously, give free rein to the potential of deep learning in grasping diversity-promoting complementarity for multi-view representation learning, we propose a novel supervised multi-view representation learning algorithm, called Self-Attention Multi-View network with Diversity-Promoting Complementarity (SAMVDPC), which exploits the consistency by a group of encoders, uses self-attention to find complementary information entailing diversity. Extensive experiments conducted on eight real-world datasets have demonstrated the effectiveness of our proposed method, and show its superiority over several baseline methods, which only consider single complementary information.
Visual Abductive Reasoning
Mar 26, 2022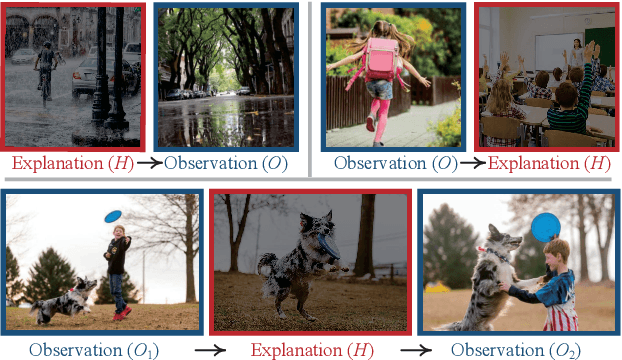
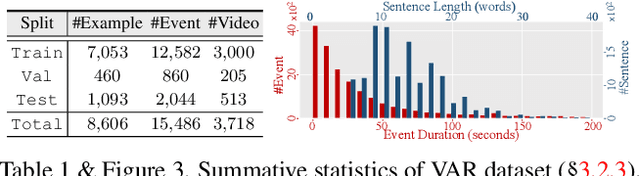
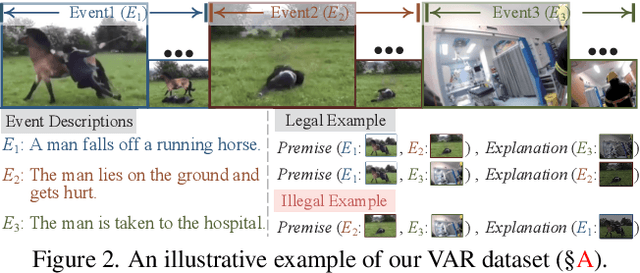
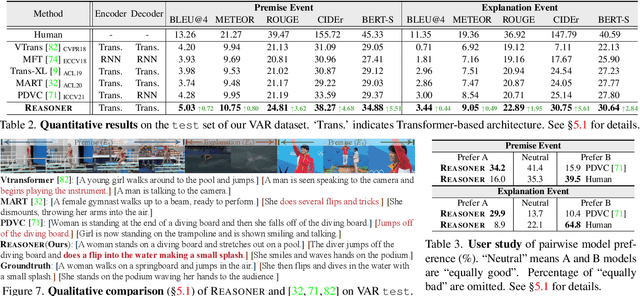
Abductive reasoning seeks the likeliest possible explanation for partial observations. Although abduction is frequently employed in human daily reasoning, it is rarely explored in computer vision literature. In this paper, we propose a new task and dataset, Visual Abductive Reasoning (VAR), for examining abductive reasoning ability of machine intelligence in everyday visual situations. Given an incomplete set of visual events, AI systems are required to not only describe what is observed, but also infer the hypothesis that can best explain the visual premise. Based on our large-scale VAR dataset, we devise a strong baseline model, Reasoner (causal-and-cascaded reasoning Transformer). First, to capture the causal structure of the observations, a contextualized directional position embedding strategy is adopted in the encoder, that yields discriminative representations for the premise and hypothesis. Then, multiple decoders are cascaded to generate and progressively refine the premise and hypothesis sentences. The prediction scores of the sentences are used to guide cross-sentence information flow in the cascaded reasoning procedure. Our VAR benchmarking results show that Reasoner surpasses many famous video-language models, while still being far behind human performance. This work is expected to foster future efforts in the reasoning-beyond-observation paradigm.
Spatial Information Guided Convolution for Real-Time RGBD Semantic Segmentation
Apr 09, 2020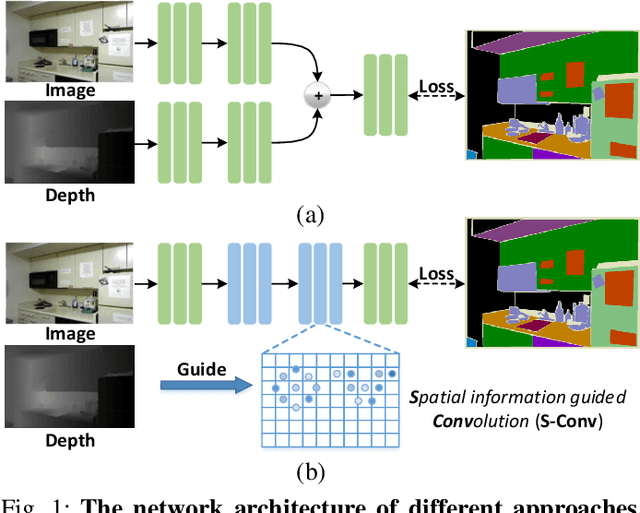
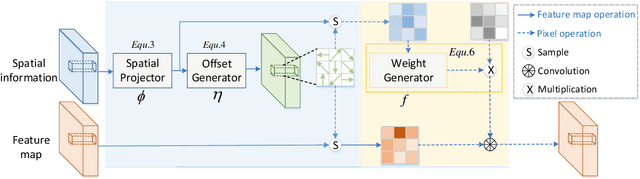
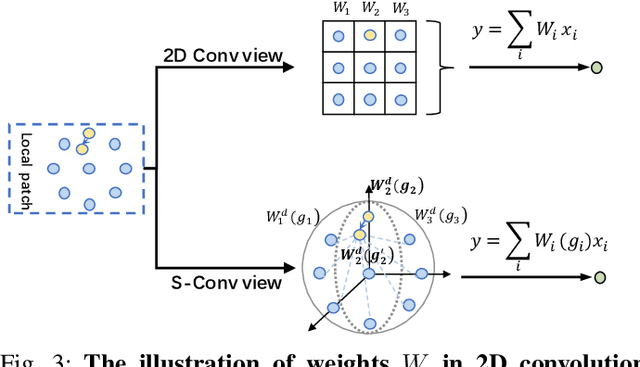
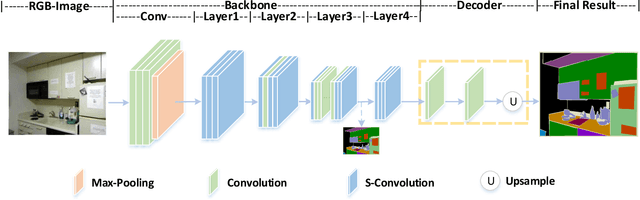
3D spatial information is known to be beneficial to the semantic segmentation task. Most existing methods take 3D spatial data as an additional input, leading to a two-stream segmentation network that processes RGB and 3D spatial information separately. This solution greatly increases the inference time and severely limits its scope for real-time applications. To solve this problem, we propose Spatial information guided Convolution (S-Conv), which allows efficient RGB feature and 3D spatial information integration. S-Conv is competent to infer the sampling offset of the convolution kernel guided by the 3D spatial information, helping the convolutional layer adjust the receptive field and adapt to geometric transformations. S-Conv also incorporates geometric information into the feature learning process by generating spatially adaptive convolutional weights. The capability of perceiving geometry is largely enhanced without much affecting the amount of parameters and computational cost. We further embed S-Conv into a semantic segmentation network, called Spatial information Guided convolutional Network (SGNet), resulting in real-time inference and state-of-the-art performance on NYUDv2 and SUNRGBD datasets.
Speech and the n-Back task as a lens into depression. How combining both may allow us to isolate different core symptoms of depression
Mar 30, 2022
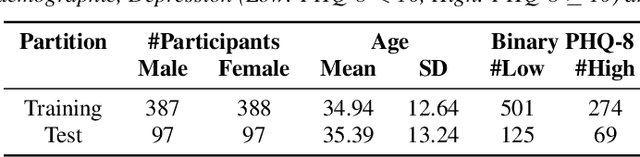
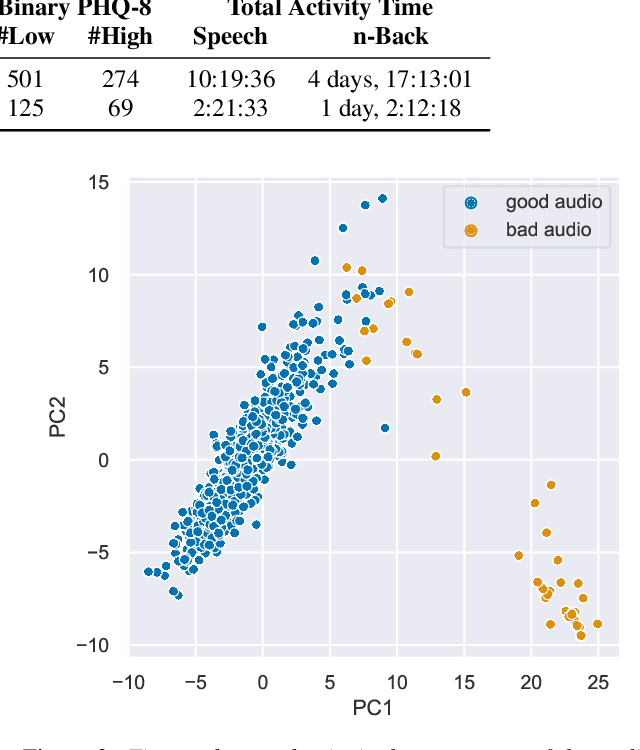
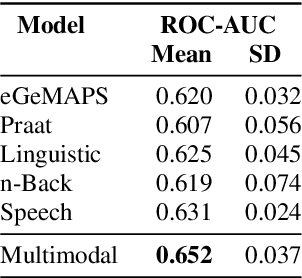
Embedded in any speech signal is a rich combination of cognitive, neuromuscular and physiological information. This richness makes speech a powerful signal in relation to a range of different health conditions, including major depressive disorders (MDD). One pivotal issue in speech-depression research is the assumption that depressive severity is the dominant measurable effect. However, given the heterogeneous clinical profile of MDD, it may actually be the case that speech alterations are more strongly associated with subsets of key depression symptoms. This paper presents strong evidence in support of this argument. First, we present a novel large, cross-sectional, multi-modal dataset collected at Thymia. We then present a set of machine learning experiments that demonstrate that combining speech with features from an n-Back working memory assessment improves classifier performance when predicting the popular eight-item Patient Health Questionnaire depression scale (PHQ-8). Finally, we present a set of experiments that highlight the association between different speech and n-Back markers at the PHQ-8 item level. Specifically, we observe that somatic and psychomotor symptoms are more strongly associated with n-Back performance scores, whilst the other items: anhedonia, depressed mood, change in appetite, feelings of worthlessness and trouble concentrating are more strongly associated with speech changes.
Towards Abstractive Grounded Summarization of Podcast Transcripts
Mar 22, 2022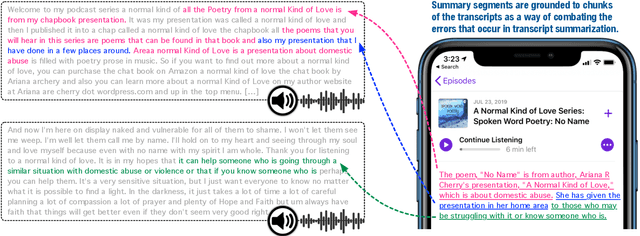

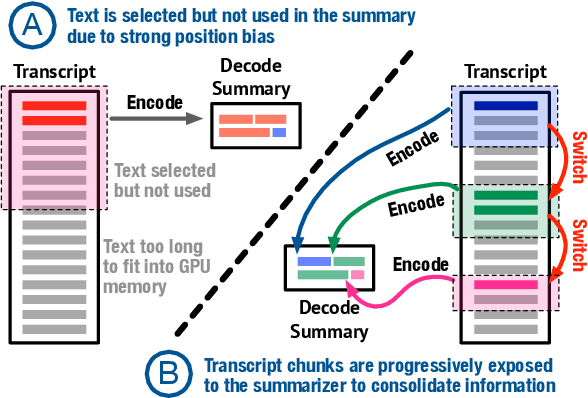
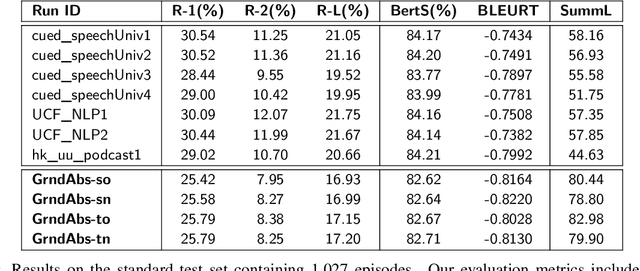
Podcasts have recently shown a rapid rise in popularity. Summarization of podcast transcripts is of practical benefit to both content providers and consumers. It helps consumers to quickly decide whether they will listen to the podcasts and reduces the cognitive load of content providers to write summaries. Nevertheless, podcast summarization faces significant challenges including factual inconsistencies with respect to the inputs. The problem is exacerbated by speech disfluencies and recognition errors in transcripts of spoken language. In this paper, we explore a novel abstractive summarization method to alleviate these challenges. Specifically, our approach learns to produce an abstractive summary while grounding summary segments in specific portions of the transcript to allow for full inspection of summary details. We conduct a series of analyses of the proposed approach on a large podcast dataset and show that the approach can achieve promising results. Grounded summaries bring clear benefits in locating the summary and transcript segments that contain inconsistent information, and hence significantly improve summarization quality in both automatic and human evaluation metrics.
CLUB: A Contrastive Log-ratio Upper Bound of Mutual Information
Jun 23, 2020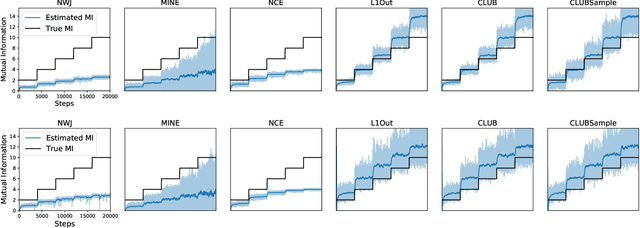
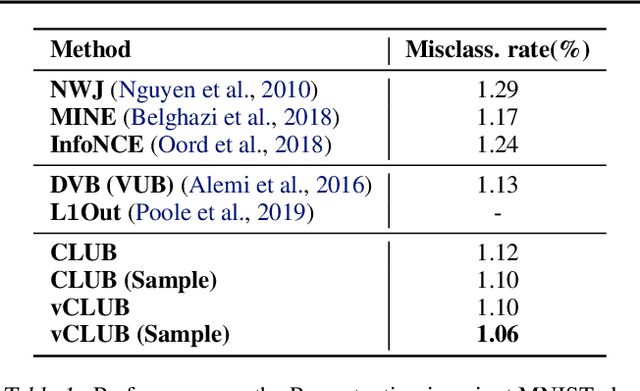
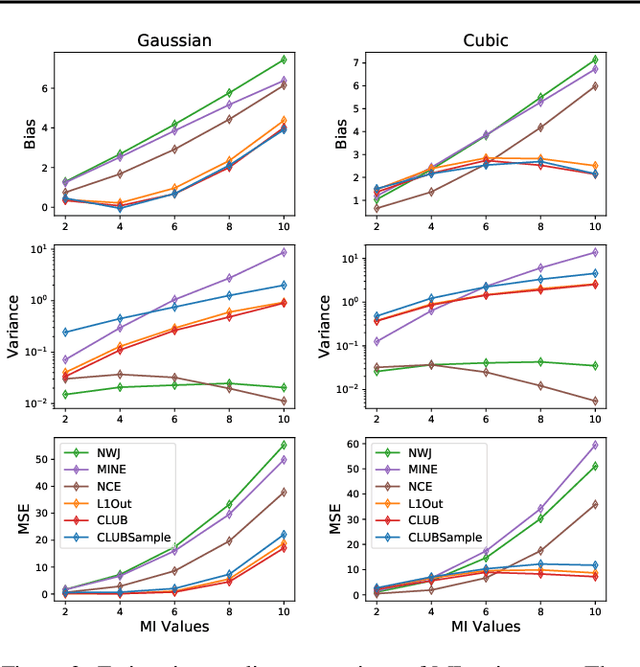
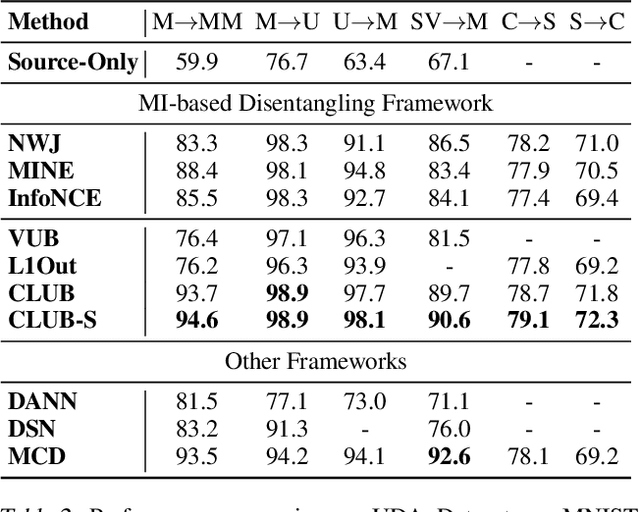
Mutual information (MI) minimization has gained considerable interests in various machine learning tasks. However, estimating and minimizing MI in high-dimensional spaces remains a challenging problem, especially when only samples, rather than distribution forms, are accessible. Previous works mainly focus on MI lower bound approximation, which is not applicable to MI minimization problems. In this paper, we propose a novel Contrastive Log-ratio Upper Bound (CLUB) of mutual information. We provide a theoretical analysis of the properties of CLUB and its variational approximation. Based on this upper bound, we introduce an accelerated MI minimization training scheme, which bridges MI minimization with negative sampling. Simulation studies on Gaussian distributions show the reliable estimation ability of CLUB. Real-world MI minimization experiments, including domain adaptation and information bottleneck, further demonstrate the effectiveness of the proposed method.