 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Metasurface-enhanced Light Detection and Ranging Technology
Apr 07, 2022
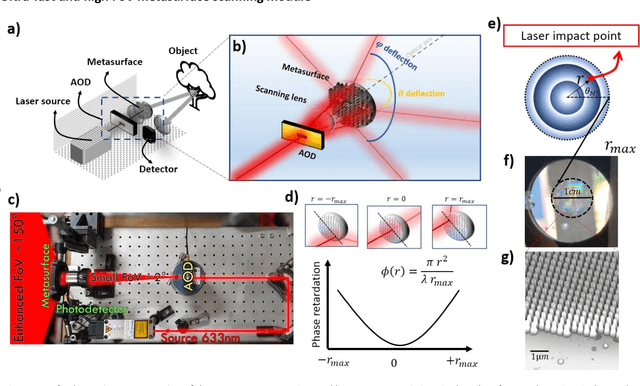
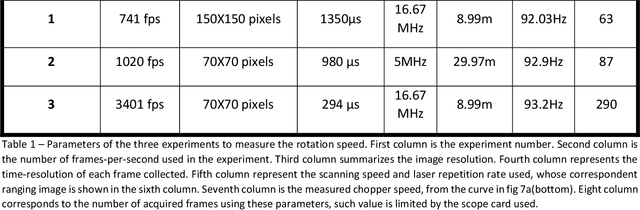
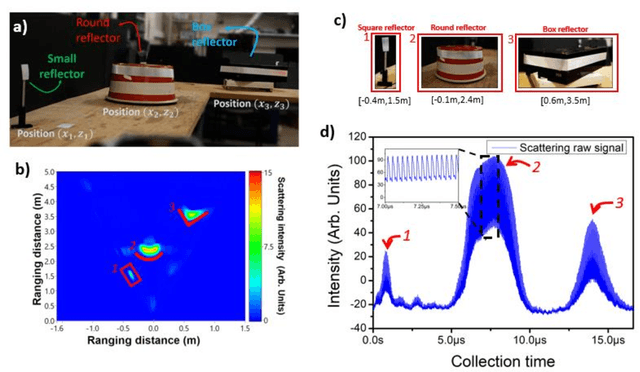
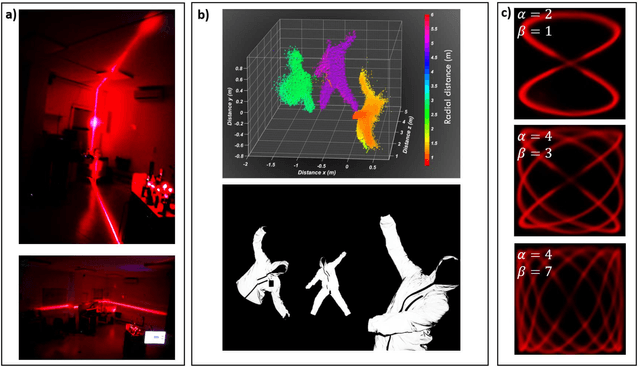
Deploying advanced imaging solutions to robotic and autonomous systems by mimicking human vision requires simultaneous acquisition of multiple fields of views, named the peripheral and fovea regions. Low-resolution peripheral field provides coarse scene exploration to direct the eye to focus to a highly resolved fovea region for sharp imaging. Among 3D computer vision techniques, Light Detection and Ranging (LiDAR) is currently considered at the industrial level for robotic vision. LiDAR is an imaging technique that monitors pulses of light at optical frequencies to sense the space and to recover three-dimensional ranging information. Notwithstanding the efforts on LiDAR integration and optimization, commercially available devices have slow frame rate and low image resolution, notably limited by the performance of mechanical or slow solid-state deflection systems. Metasurfaces (MS) are versatile optical components that can distribute the optical power in desired regions of space. Here, we report on an advanced LiDAR technology that uses ultrafast low FoV deflectors cascaded with large area metasurfaces to achieve large FoV and simultaneous peripheral and central imaging zones. This technology achieves MHz frame rate for 2D imaging, and up to KHz for 3D imaging, with extremely large FoV (up to 150{\deg}deg. on both vertical and horizontal scanning axes). The use of this disruptive LiDAR technology with advanced learning algorithms offers perspectives to improve further the perception capabilities and decision-making process of autonomous vehicles and robotic systems.
GENEOnet: A new machine learning paradigm based on Group Equivariant Non-Expansive Operators. An application to protein pocket detection
Jan 31, 2022Nowadays there is a big spotlight cast on the development of techniques of explainable machine learning. Here we introduce a new computational paradigm based on Group Equivariant Non-Expansive Operators, that can be regarded as the product of a rising mathematical theory of information-processing observers. This approach, that can be adjusted to different situations, may have many advantages over other common tools, like Neural Networks, such as: knowledge injection and information engineering, selection of relevant features, small number of parameters and higher transparency. We chose to test our method, called GENEOnet, on a key problem in drug design: detecting pockets on the surface of proteins that can host ligands. Experimental results confirmed that our method works well even with a quite small training set, providing thus a great computational advantage, while the final comparison with other state-of-the-art methods shows that GENEOnet provides better or comparable results in terms of accuracy.
Localized Feature Aggregation Module for Semantic Segmentation
Dec 03, 2021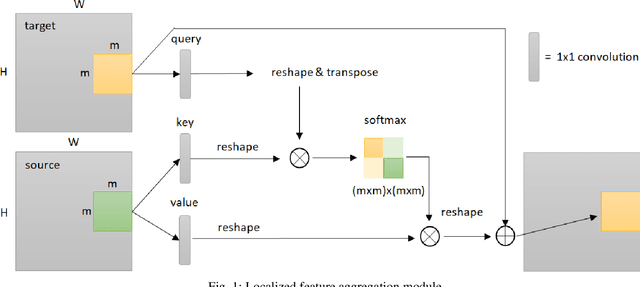
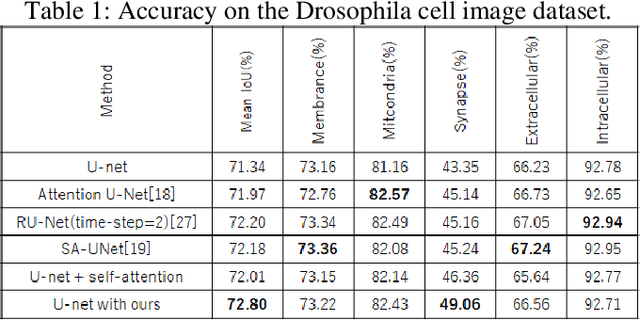
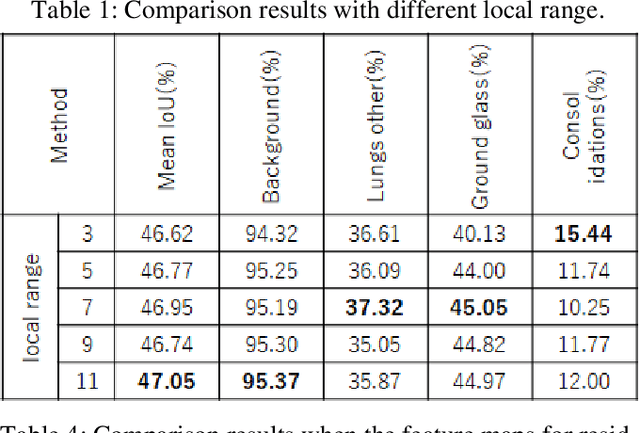
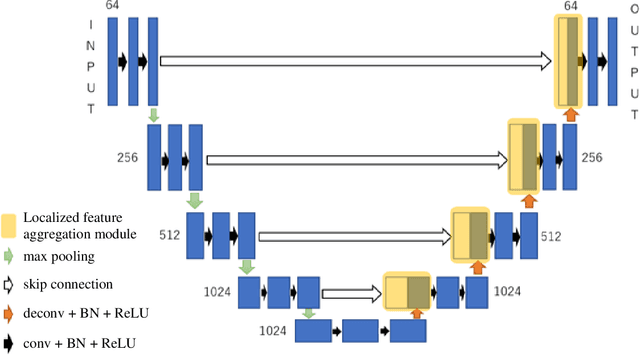
We propose a new information aggregation method which called Localized Feature Aggregation Module based on the similarity between the feature maps of an encoder and a decoder. The proposed method recovers positional information by emphasizing the similarity between decoder's feature maps with superior semantic information and encoder's feature maps with superior positional information. The proposed method can learn positional information more efficiently than conventional concatenation in the U-net and attention U-net. Additionally, the proposed method also uses localized attention range to reduce the computational cost. Two innovations contributed to improve the segmentation accuracy with lower computational cost. By experiments on the Drosophila cell image dataset and COVID-19 image dataset, we confirmed that our method outperformed conventional methods.
Back to Reality: Weakly-supervised 3D Object Detection with Shape-guided Label Enhancement
Mar 27, 2022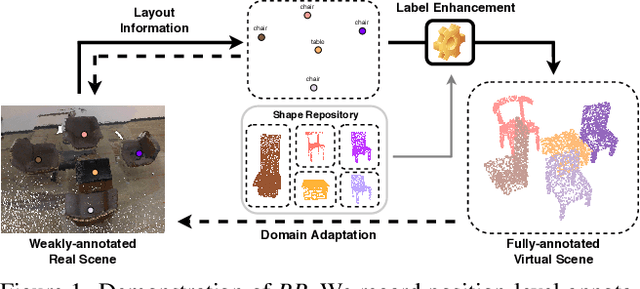

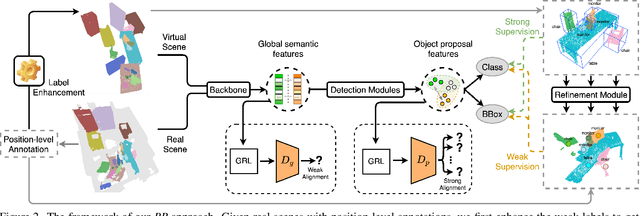

In this paper, we propose a weakly-supervised approach for 3D object detection, which makes it possible to train a strong 3D detector with position-level annotations (i.e. annotations of object centers). In order to remedy the information loss from box annotations to centers, our method, namely Back to Reality (BR), makes use of synthetic 3D shapes to convert the weak labels into fully-annotated virtual scenes as stronger supervision, and in turn utilizes the perfect virtual labels to complement and refine the real labels. Specifically, we first assemble 3D shapes into physically reasonable virtual scenes according to the coarse scene layout extracted from position-level annotations. Then we go back to reality by applying a virtual-to-real domain adaptation method, which refine the weak labels and additionally supervise the training of detector with the virtual scenes. Furthermore, we propose a more challenging benckmark for indoor 3D object detection with more diversity in object sizes to better show the potential of BR. With less than 5% of the labeling labor, we achieve comparable detection performance with some popular fully-supervised approaches on the widely used ScanNet dataset. Code is available at: https://github.com/wyf-ACCEPT/BackToReality
Stochastic Contextual Dueling Bandits under Linear Stochastic Transitivity Models
Feb 09, 2022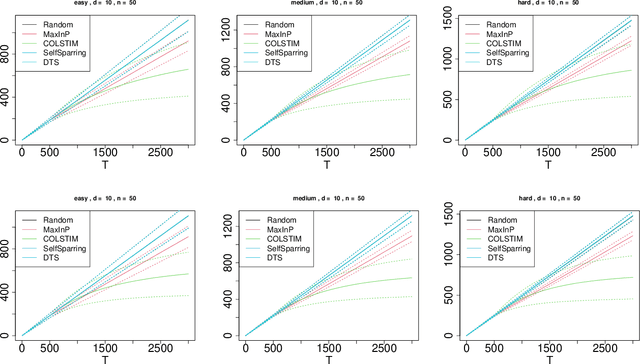
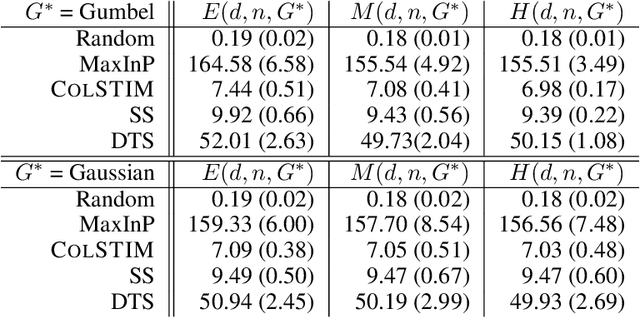
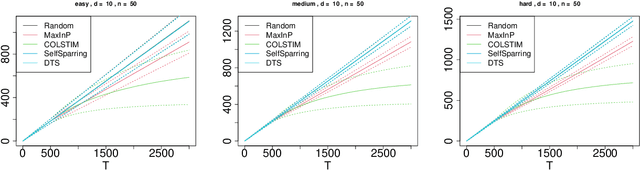
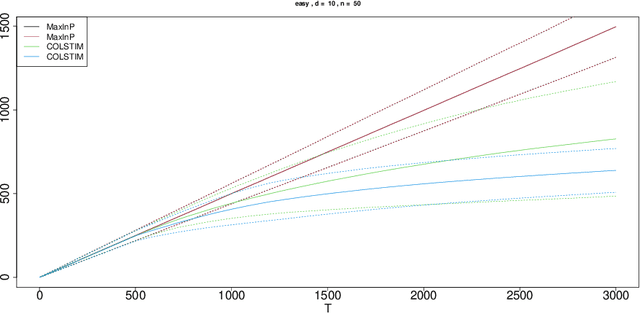
We consider the regret minimization task in a dueling bandits problem with context information. In every round of the sequential decision problem, the learner makes a context-dependent selection of two choice alternatives (arms) to be compared with each other and receives feedback in the form of noisy preference information. We assume that the feedback process is determined by a linear stochastic transitivity model with contextualized utilities (CoLST), and the learner's task is to include the best arm (with highest latent context-dependent utility) in the duel. We propose a computationally efficient algorithm, $\texttt{CoLSTIM}$, which makes its choice based on imitating the feedback process using perturbed context-dependent utility estimates of the underlying CoLST model. If each arm is associated with a $d$-dimensional feature vector, we show that $\texttt{CoLSTIM}$ achieves a regret of order $\tilde O( \sqrt{dT})$ after $T$ learning rounds. Additionally, we also establish the optimality of $\texttt{CoLSTIM}$ by showing a lower bound for the weak regret that refines the existing average regret analysis. Our experiments demonstrate its superiority over state-of-art algorithms for special cases of CoLST models.
A Survey of Information Cascade Analysis: Models, Predictions and Recent Advances
May 25, 2020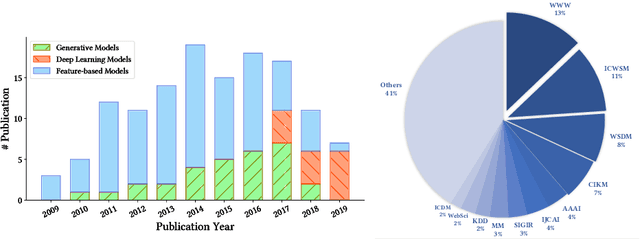
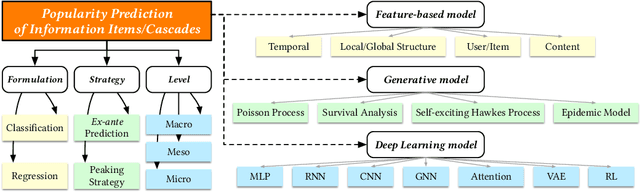

The deluge of digital information in our daily life -- from user-generated content such as microblogs and scientific papers, to online business such as viral marketing and advertising -- offers unprecedented opportunities to explore and exploit the trajectories and structures of the evolution of information cascades. Abundant research efforts, both academic and industrial, have aimed to reach a better understanding of the mechanisms driving the spread of information and quantifying the outcome of information diffusion. This article presents a comprehensive review and categorization of information popularity prediction methods, from feature engineering and stochastic processes, through graph representation, to deep learning-based approaches. Specifically, we first formally define different types of information cascades and summarize the perspectives of existing studies. We then present a taxonomy that categorizes existing works into the aforementioned three main groups as well as the main subclasses in each group, and we systematically review cutting-edge research work. Finally, we summarize the pros and cons of existing research efforts and outline the open challenges and opportunities in this field.
Visibility-Inspired Models of Touch Sensors for Navigation
Mar 04, 2022

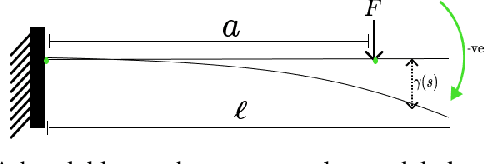

This paper introduces mathematical models of touch sensors for mobile robotics based on visibility. Serving a purpose similar to the pinhole camera model for computer vision, the introduced models are expected to provide a useful, idealized characterization of task-relevant information that can be inferred from their outputs or observations. This allows direct comparisons to be made between traditional depth sensors, highlighting cases in which touch sensing may be interchangeable with time of flight or vision sensors, and characterizing unique advantages provided by touch sensing. The models include contact detection, compression, load bearing, and deflection. The results could serve as a basic building block for innovative touch sensor designs for mobile robot sensor fusion systems.
Look-Ahead Acquisition Functions for Bernoulli Level Set Estimation
Mar 18, 2022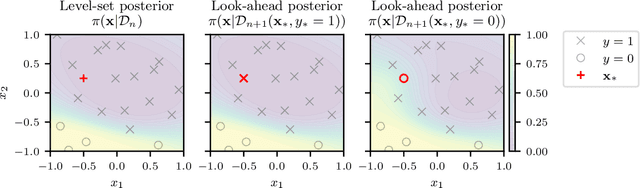
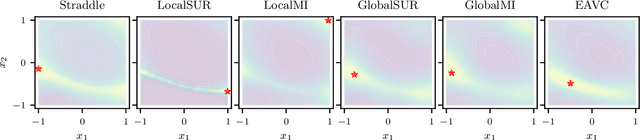
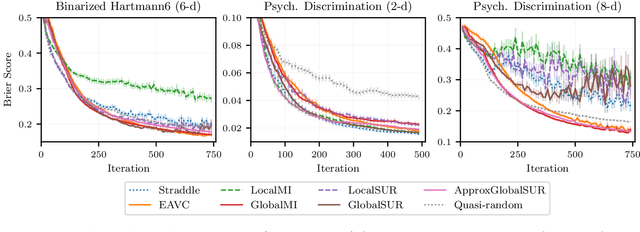

Level set estimation (LSE) is the problem of identifying regions where an unknown function takes values above or below a specified threshold. Active sampling strategies for efficient LSE have primarily been studied in continuous-valued functions. Motivated by applications in human psychophysics where common experimental designs produce binary responses, we study LSE active sampling with Bernoulli outcomes. With Gaussian process classification surrogate models, the look-ahead model posteriors used by state-of-the-art continuous-output methods are intractable. However, we derive analytic expressions for look-ahead posteriors of sublevel set membership, and show how these lead to analytic expressions for a class of look-ahead LSE acquisition functions, including information-based methods. Benchmark experiments show the importance of considering the global look-ahead impact on the entire posterior. We demonstrate a clear benefit to using this new class of acquisition functions on benchmark problems, and on a challenging real-world task of estimating a high-dimensional contrast sensitivity function.
Fashionformer: A simple, Effective and Unified Baseline for Human Fashion Segmentation and Recognition
Apr 10, 2022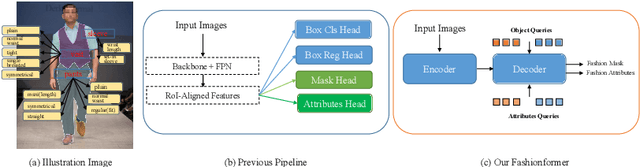
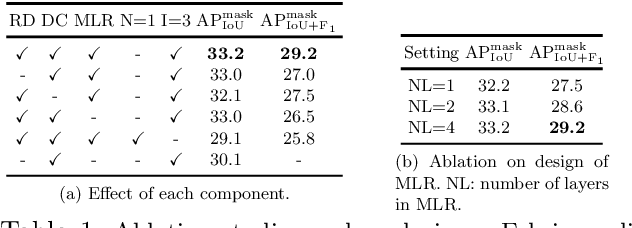
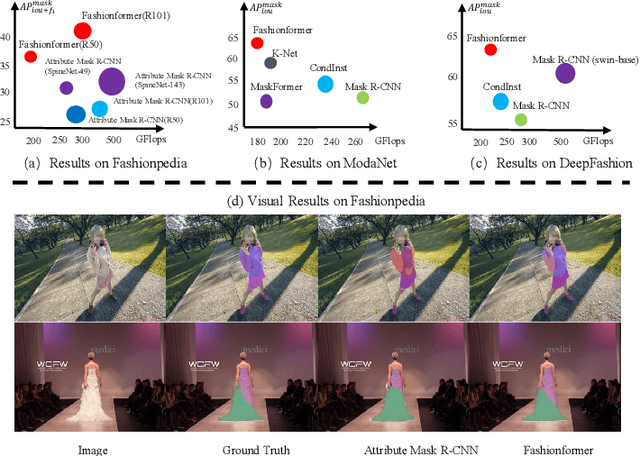
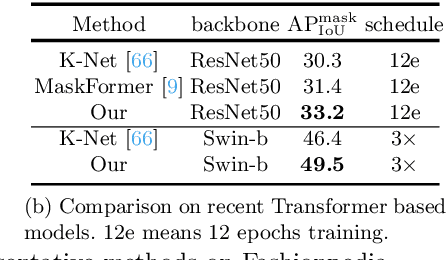
Human fashion understanding is one important computer vision task since it has the comprehensive information that can be used for real-world applications. In this work, we focus on joint human fashion segmentation and attribute recognition. Contrary to the previous works that separately model each task as a multi-head prediction problem, our insight is to bridge these two tasks with one unified model via vision transformer modeling to benefit each task. In particular, we introduce the object query for segmentation and the attribute query for attribute prediction. Both queries and their corresponding features can be linked via mask prediction. Then we adopt a two-stream query learning framework to learn the decoupled query representations. For attribute stream, we design a novel Multi-Layer Rendering module to explore more fine-grained features. The decoder design shares the same spirits with DETR, thus we name the proposed method Fahsionformer. Extensive experiments on three human fashion datasets including Fashionpedia, ModaNet and Deepfashion illustrate the effectiveness of our approach. In particular, our method with the same backbone achieve relative 10% improvements than previous works in case of \textit{a joint metric ( AP$^{\text{mask}}_{\text{IoU+F}_1}$) for both segmentation and attribute recognition}. To the best of our knowledge, we are the first unified end-to-end vision transformer framework for human fashion analysis. We hope this simple yet effective method can serve as a new flexible baseline for fashion analysis. Code will be available at https://github.com/xushilin1/FashionFormer.
Self-attention Multi-view Representation Learning with Diversity-promoting Complementarity
Jan 01, 2022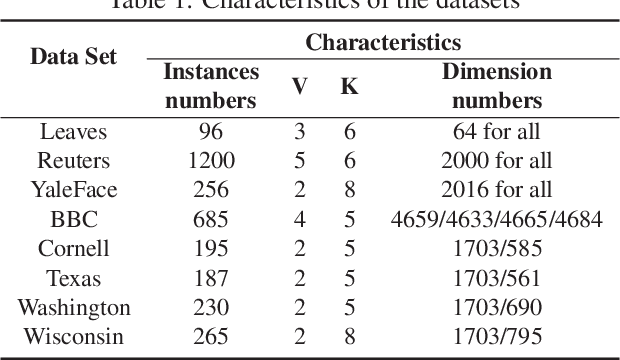
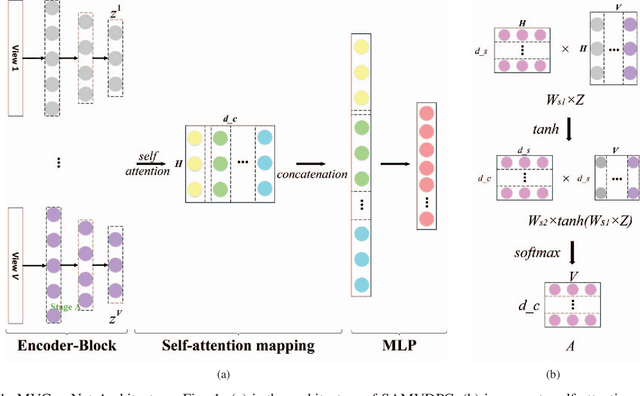
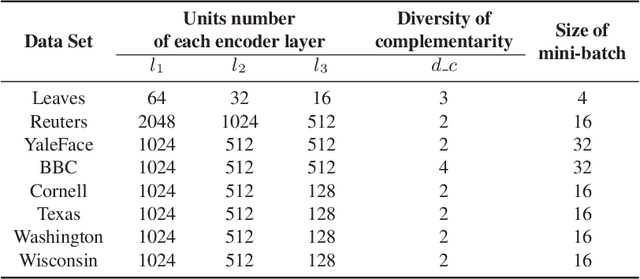
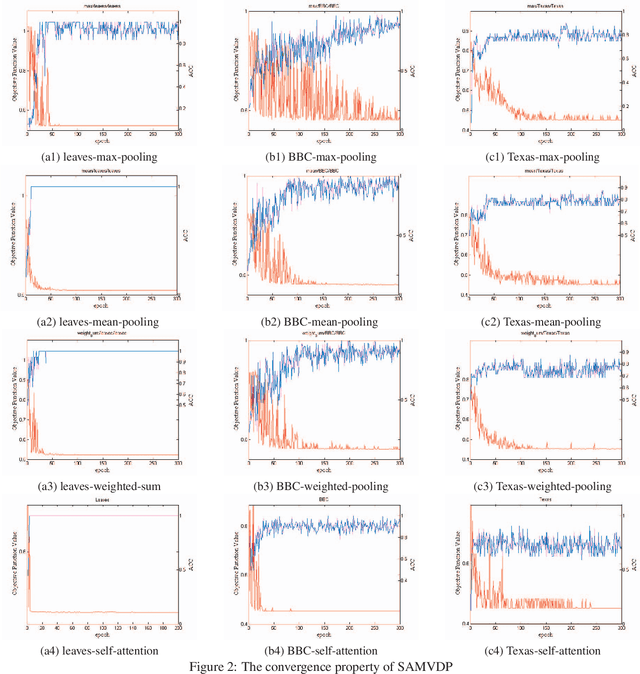
Multi-view learning attempts to generate a model with a better performance by exploiting the consensus and/or complementarity among multi-view data. However, in terms of complementarity, most existing approaches only can find representations with single complementarity rather than complementary information with diversity. In this paper, to utilize both complementarity and consistency simultaneously, give free rein to the potential of deep learning in grasping diversity-promoting complementarity for multi-view representation learning, we propose a novel supervised multi-view representation learning algorithm, called Self-Attention Multi-View network with Diversity-Promoting Complementarity (SAMVDPC), which exploits the consistency by a group of encoders, uses self-attention to find complementary information entailing diversity. Extensive experiments conducted on eight real-world datasets have demonstrated the effectiveness of our proposed method, and show its superiority over several baseline methods, which only consider single complementary information.