 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Text is no more Enough! A Benchmark for Profile-based Spoken Language Understanding
Jan 12, 2022
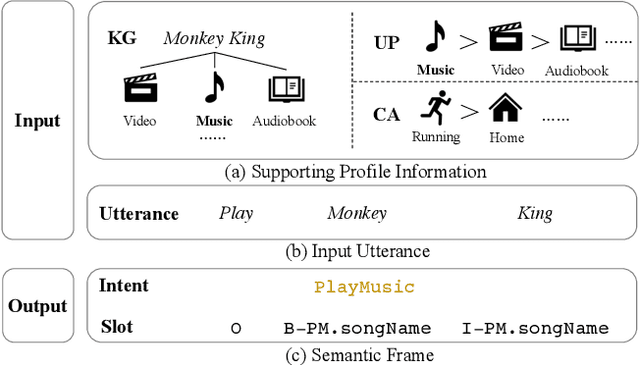
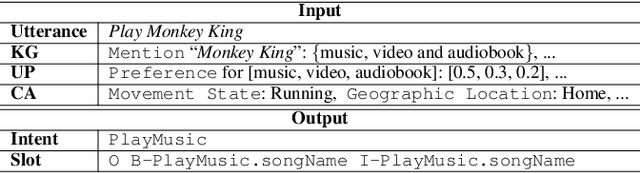
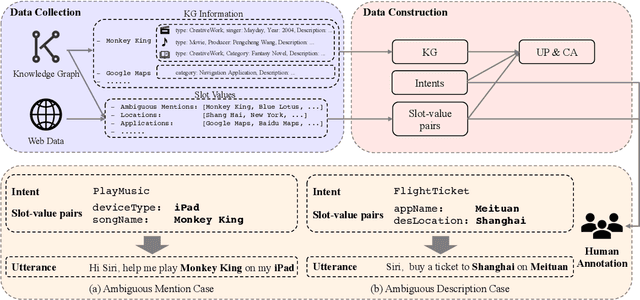
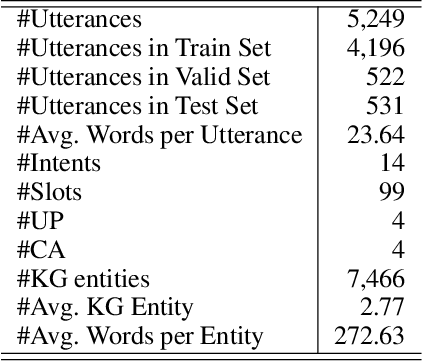
Current researches on spoken language understanding (SLU) heavily are limited to a simple setting: the plain text-based SLU that takes the user utterance as input and generates its corresponding semantic frames (e.g., intent and slots). Unfortunately, such a simple setting may fail to work in complex real-world scenarios when an utterance is semantically ambiguous, which cannot be achieved by the text-based SLU models. In this paper, we first introduce a new and important task, Profile-based Spoken Language Understanding (ProSLU), which requires the model that not only relies on the plain text but also the supporting profile information to predict the correct intents and slots. To this end, we further introduce a large-scale human-annotated Chinese dataset with over 5K utterances and their corresponding supporting profile information (Knowledge Graph (KG), User Profile (UP), Context Awareness (CA)). In addition, we evaluate several state-of-the-art baseline models and explore a multi-level knowledge adapter to effectively incorporate profile information. Experimental results reveal that all existing text-based SLU models fail to work when the utterances are semantically ambiguous and our proposed framework can effectively fuse the supporting information for sentence-level intent detection and token-level slot filling. Finally, we summarize key challenges and provide new points for future directions, which hopes to facilitate the research.
Beamspace MIMO for Satellite Swarms
Dec 16, 2021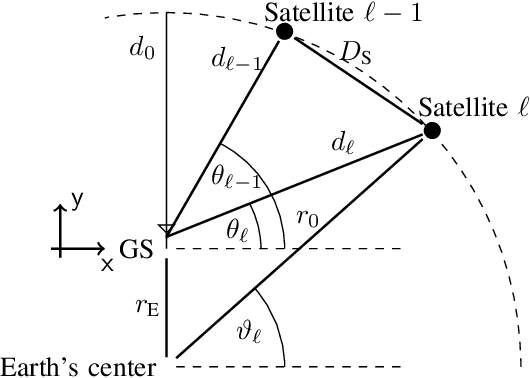
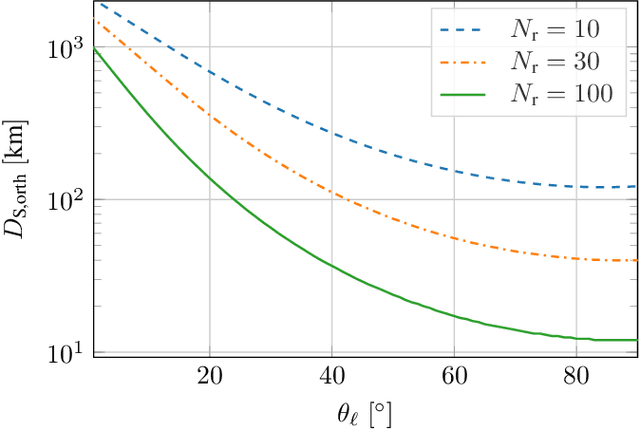
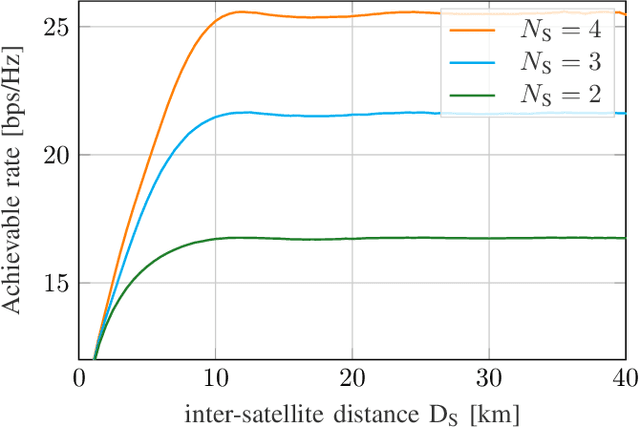
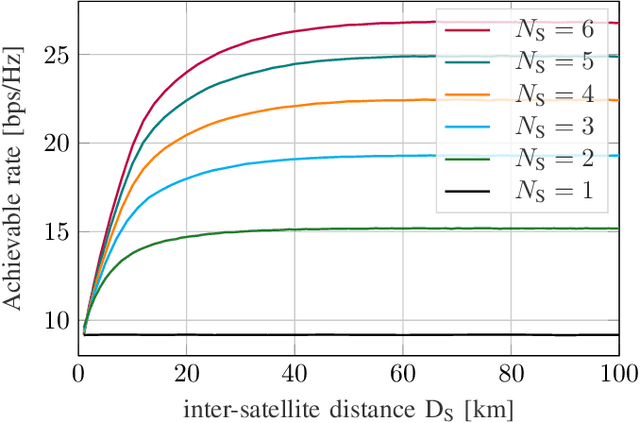
Systems of small distributed satellites in low Earth orbit (LEO) transmitting cooperatively to a multiple antenna ground station (GS) are investigated. These satellite swarms have the benefit of much higher spatial separation in the transmit antennas than traditional big satellites with antenna arrays, promising a massive increase in spectral efficiency. However, this would require instantaneous perfect channel state information (CSI) and strong cooperation between satellites. In practice, orbital velocities around 7.5 km/s lead to very short channel coherence times on the order of fractions of the inter-satellite propagation delay, invalidating these assumptions. In this paper, we propose a distributed linear precoding scheme and a GS equalizer relying on local position information. In particular, each satellite only requires information about its own position and that of the GS, while the GS has complete positional information. Due to the deterministic nature of satellite movement this information is easily obtained and no inter-satellite information exchange is required during transmission. Based on the underlying geometrical channel approximation, the optimal inter-satellite distance is obtained analytically. Numerical evaluations show that the proposed scheme is, on average, within 99.8% of the maximum achievable rate for instantaneous CSI and perfect cooperation
An efficient approach for tracking the aerosol-cloud interactions formed by ship emissions using GOES-R satellite imagery and AIS ship tracking information
Aug 20, 2021
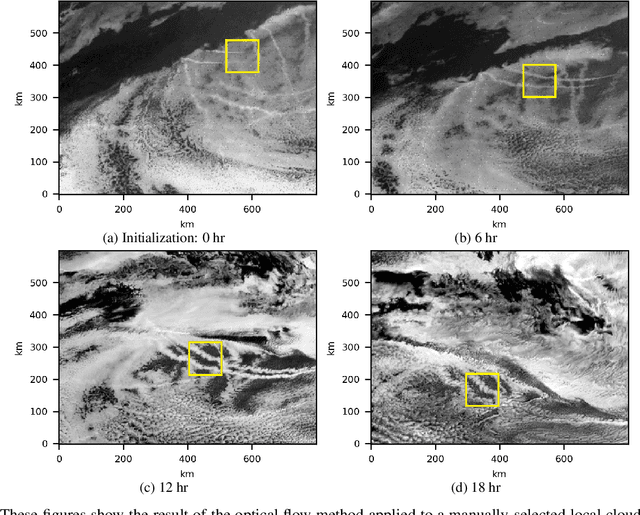

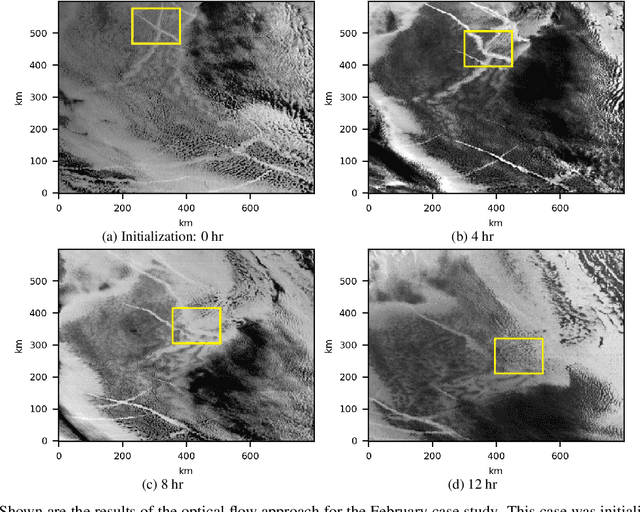
Ship emissions can form linear cloud features, or ship tracks, when atmospheric water vapor condenses on aerosols in the ship exhaust. These features are of interest because they are observable and traceable examples of marine cloud brightening, a mechanism that has been studied as a potential approach for solar climate intervention. Ship tracks can be observed throughout the diurnal cycle via space-borne assets like the Advanced Baseline Imagers on the National Oceanic and Atmospheric Administration Geostationary Operational Environmental Satellites, the GOES-R series. Due to complex atmospheric dynamics, it can be difficult to track these aerosol perturbations over space and time to precisely characterize how long a single emission source can significantly contribute to indirect radiative forcing. We combine GOES-17 satellite imagery with ship location information to demonstrate two feasible methods of tracing the trajectories of ship-emitted aerosols after they begin mixing with low boundary layer clouds in three test cases. The first method uses the parcel trajectory model HYSPLIT, which was driven by well-studied physical processes but often could not follow the ship track beyond 8 hours. The second method uses the image processing technique, optical flow, which could follow the track throughout its lifetime, but requires high contrast features for best performance. These approaches show that ship tracks persist as visible, linear features beyond 9 hr and sometimes longer than 24 hr. This research sets the stage for a more thorough exploration of the atmospheric conditions and exhaust compositions that produce ship tracks and factors that determine track persistence.
Leveraging Visual Knowledge in Language Tasks: An Empirical Study on Intermediate Pre-training for Cross-modal Knowledge Transfer
Mar 17, 2022
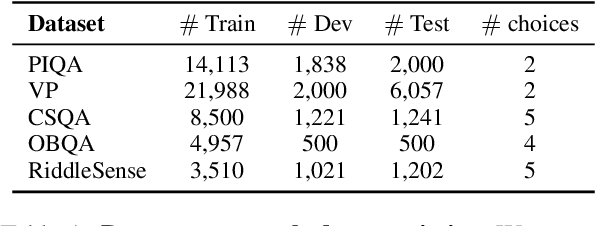
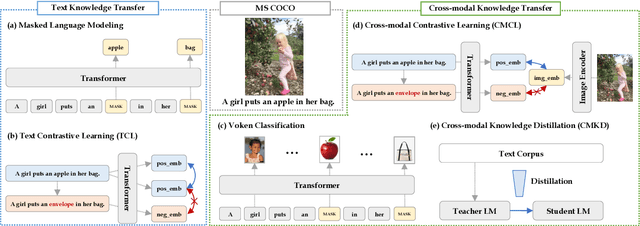
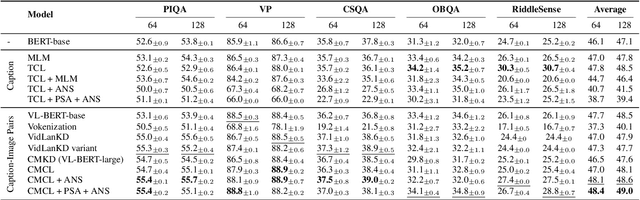
Pre-trained language models are still far from human performance in tasks that need understanding of properties (e.g. appearance, measurable quantity) and affordances of everyday objects in the real world since the text lacks such information due to reporting bias. In this work, we study whether integrating visual knowledge into a language model can fill the gap. We investigate two types of knowledge transfer: (1) text knowledge transfer using image captions that may contain enriched visual knowledge and (2) cross-modal knowledge transfer using both images and captions with vision-language training objectives. On 5 downstream tasks that may need visual knowledge to solve the problem, we perform extensive empirical comparisons over the presented objectives. Our experiments show that visual knowledge transfer can improve performance in both low-resource and fully supervised settings.
Learning from Untrimmed Videos: Self-Supervised Video Representation Learning with Hierarchical Consistency
Apr 06, 2022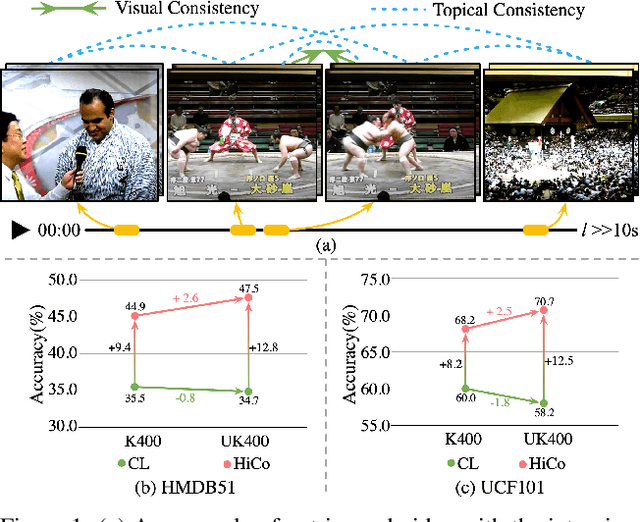
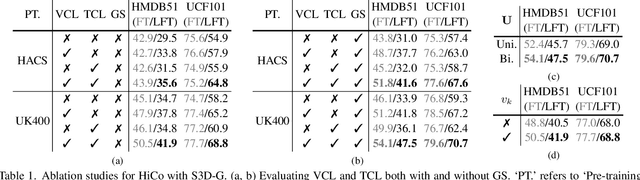
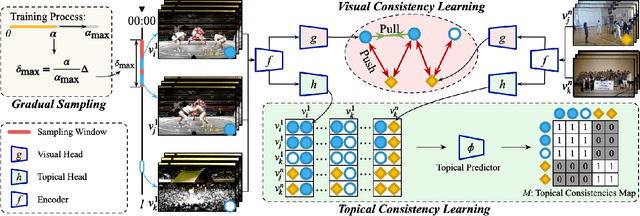
Natural videos provide rich visual contents for self-supervised learning. Yet most existing approaches for learning spatio-temporal representations rely on manually trimmed videos, leading to limited diversity in visual patterns and limited performance gain. In this work, we aim to learn representations by leveraging more abundant information in untrimmed videos. To this end, we propose to learn a hierarchy of consistencies in videos, i.e., visual consistency and topical consistency, corresponding respectively to clip pairs that tend to be visually similar when separated by a short time span and share similar topics when separated by a long time span. Specifically, a hierarchical consistency learning framework HiCo is presented, where the visually consistent pairs are encouraged to have the same representation through contrastive learning, while the topically consistent pairs are coupled through a topical classifier that distinguishes whether they are topic related. Further, we impose a gradual sampling algorithm for proposed hierarchical consistency learning, and demonstrate its theoretical superiority. Empirically, we show that not only HiCo can generate stronger representations on untrimmed videos, it also improves the representation quality when applied to trimmed videos. This is in contrast to standard contrastive learning that fails to learn appropriate representations from untrimmed videos.
Aggregating Global Features into Local Vision Transformer
Jan 30, 2022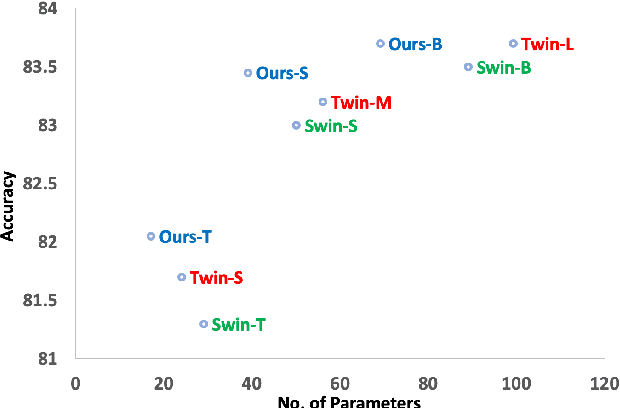
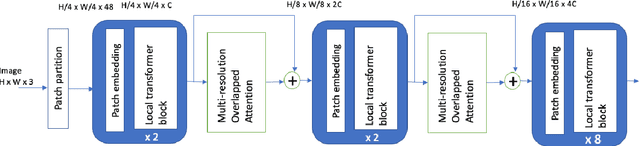
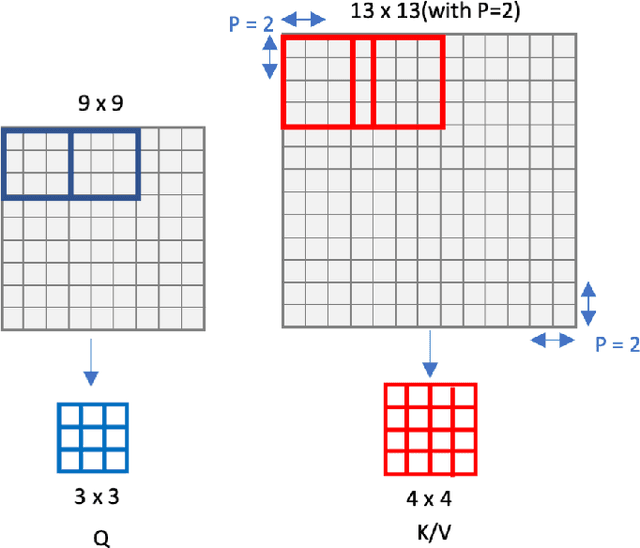

Local Transformer-based classification models have recently achieved promising results with relatively low computational costs. However, the effect of aggregating spatial global information of local Transformer-based architecture is not clear. This work investigates the outcome of applying a global attention-based module named multi-resolution overlapped attention (MOA) in the local window-based transformer after each stage. The proposed MOA employs slightly larger and overlapped patches in the key to enable neighborhood pixel information transmission, which leads to significant performance gain. In addition, we thoroughly investigate the effect of the dimension of essential architecture components through extensive experiments and discover an optimum architecture design. Extensive experimental results CIFAR-10, CIFAR-100, and ImageNet-1K datasets demonstrate that the proposed approach outperforms previous vision Transformers with a comparatively fewer number of parameters.
Weakly Supervised Learning with Side Information for Noisy Labeled Images
Sep 04, 2020
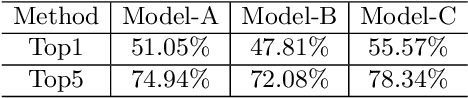
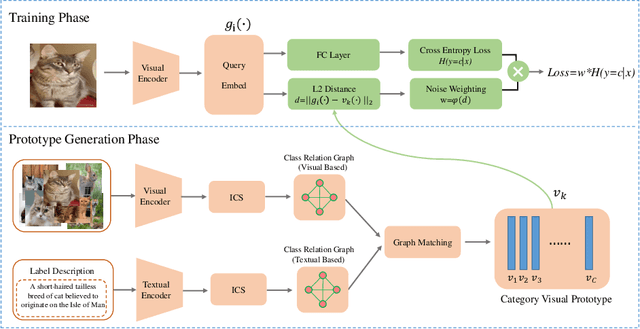

In many real-world datasets, like WebVision, the performance of DNN based classifier is often limited by the noisy labeled data. To tackle this problem, some image related side information, such as captions and tags, often reveal underlying relationships across images. In this paper, we present an efficient weakly supervised learning by using a Side Information Network (SINet), which aims to effectively carry out a large scale classification with severely noisy labels. The proposed SINet consists of a visual prototype module and a noise weighting module. The visual prototype module is designed to generate a compact representation for each category by introducing the side information. The noise weighting module aims to estimate the correctness of each noisy image and produce a confidence score for image ranking during the training procedure. The propsed SINet can largely alleviate the negative impact of noisy image labels, and is beneficial to train a high performance CNN based classifier. Besides, we released a fine-grained product dataset called AliProducts, which contains more than 2.5 million noisy web images crawled from the internet by using queries generated from 50,000 fine-grained semantic classes. Extensive experiments on several popular benchmarks (i.e. Webvision, ImageNet and Clothing-1M) and our proposed AliProducts achieve state-of-the-art performance. The SINet has won the first place in the classification task on WebVision Challenge 2019, and outperformed other competitors by a large margin.
PAnDR: Fast Adaptation to New Environments from Offline Experiences via Decoupling Policy and Environment Representations
Apr 06, 2022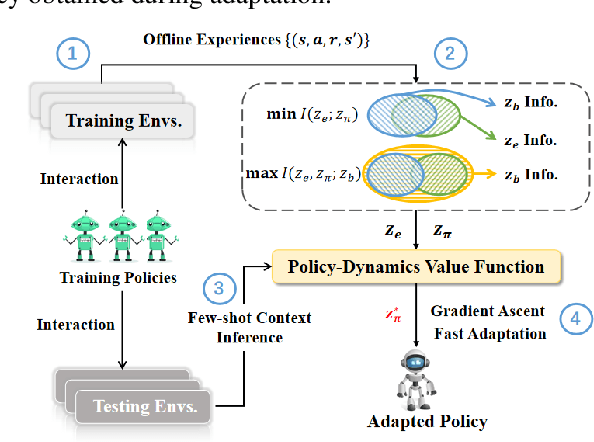
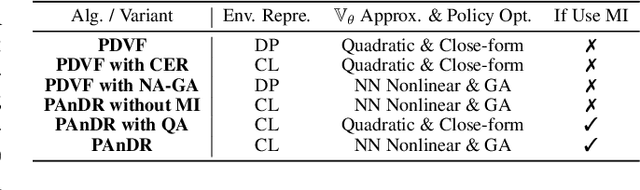
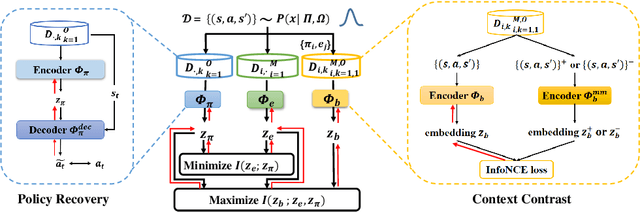

Deep Reinforcement Learning (DRL) has been a promising solution to many complex decision-making problems. Nevertheless, the notorious weakness in generalization among environments prevent widespread application of DRL agents in real-world scenarios. Although advances have been made recently, most prior works assume sufficient online interaction on training environments, which can be costly in practical cases. To this end, we focus on an \textit{offline-training-online-adaptation} setting, in which the agent first learns from offline experiences collected in environments with different dynamics and then performs online policy adaptation in environments with new dynamics. In this paper, we propose Policy Adaptation with Decoupled Representations (PAnDR) for fast policy adaptation. In offline training phase, the environment representation and policy representation are learned through contrastive learning and policy recovery, respectively. The representations are further refined by mutual information optimization to make them more decoupled and complete. With learned representations, a Policy-Dynamics Value Function (PDVF) (Raileanu et al., 2020) network is trained to approximate the values for different combinations of policies and environments. In online adaptation phase, with the environment context inferred from few experiences collected in new environments, the policy is optimized by gradient ascent with respect to the PDVF. Our experiments show that PAnDR outperforms existing algorithms in several representative policy adaptation problems.
Category Guided Attention Network for Brain Tumor Segmentation in MRI
Mar 29, 2022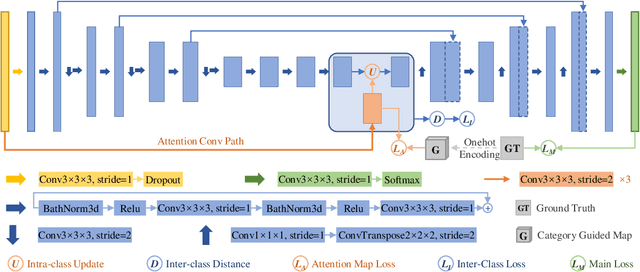
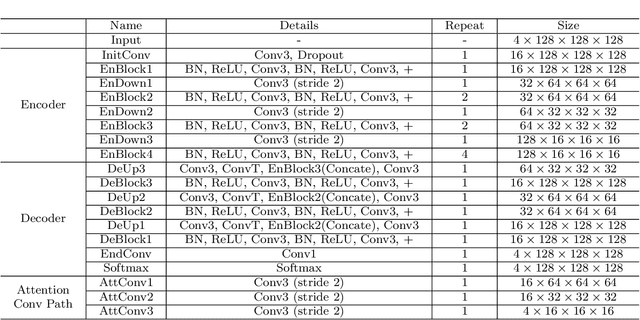
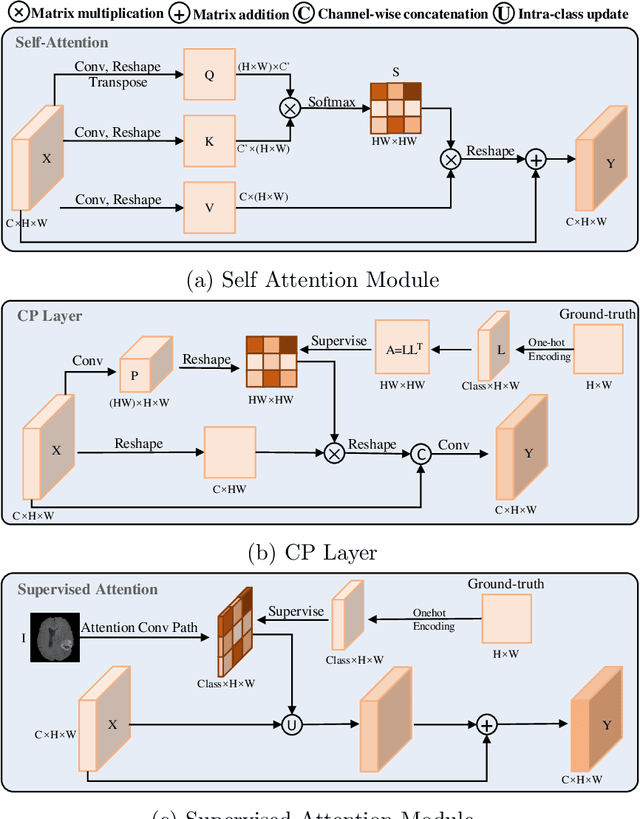
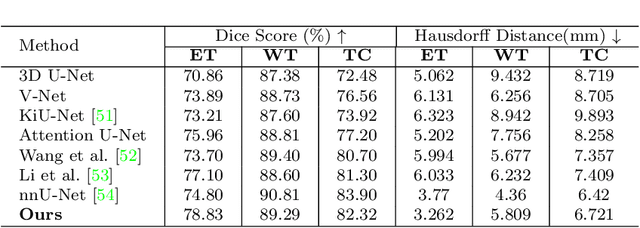
Objective: Magnetic resonance imaging (MRI) has been widely used for the analysis and diagnosis of brain diseases. Accurate and automatic brain tumor segmentation is of paramount importance for radiation treatment. However, low tissue contrast in tumor regions makes it a challenging task.Approach: We propose a novel segmentation network named Category Guided Attention U-Net (CGA U-Net). In this model, we design a Supervised Attention Module (SAM) based on the attention mechanism, which can capture more accurate and stable long-range dependency in feature maps without introducing much computational cost. Moreover, we propose an intra-class update approach to reconstruct feature maps by aggregating pixels of the same category. Main results: Experimental results on the BraTS 2019 datasets show that the proposed method outperformers the state-of-the-art algorithms in both segmentation performance and computational complexity. Significance: The CGA U-Net can effectively capture the global semantic information in the MRI image by using the SAM module, while significantly reducing the computational cost. Code is available at https://github.com/delugewalker/CGA-U-Net.
Emergence of hierarchical reference systems in multi-agent communication
Mar 24, 2022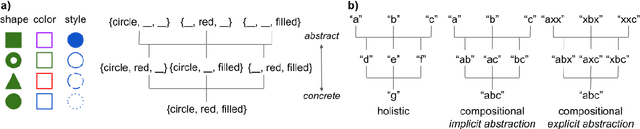
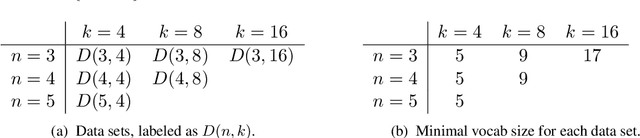
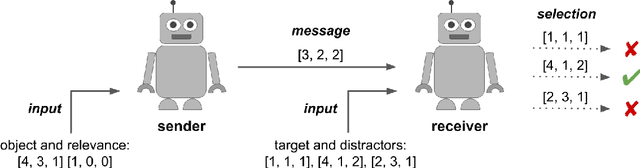
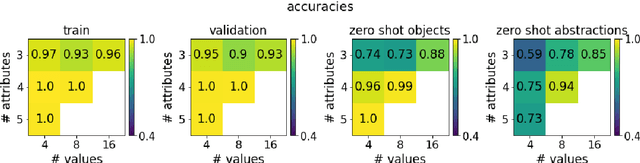
In natural language, referencing objects at different levels of specificity is a fundamental pragmatic mechanism for efficient communication in context. We develop a novel communication game, the hierarchical reference game, to study the emergence of such reference systems in artificial agents. We consider a simplified world, in which concepts are abstractions over a set of primitive attributes (e.g., color, style, shape). Depending on how many attributes are combined, concepts are more general ("circle") or more specific ("red dotted circle"). Based on the context, the agents have to communicate at different levels of this hierarchy. Our results show, that the agents learn to play the game successfully and can even generalize to novel concepts. To achieve abstraction, they use implicit (omitting irrelevant information) and explicit (indicating that attributes are irrelevant) strategies. In addition, the compositional structure underlying the concept hierarchy is reflected in the emergent protocols, indicating that the need to develop hierarchical reference systems supports the emergence of compositionality.