 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FisrEbp: Enterprise Bankruptcy Prediction via Fusing its Intra-risk and Spillover-Risk
Feb 01, 2022
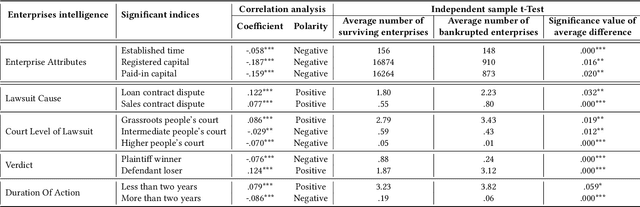
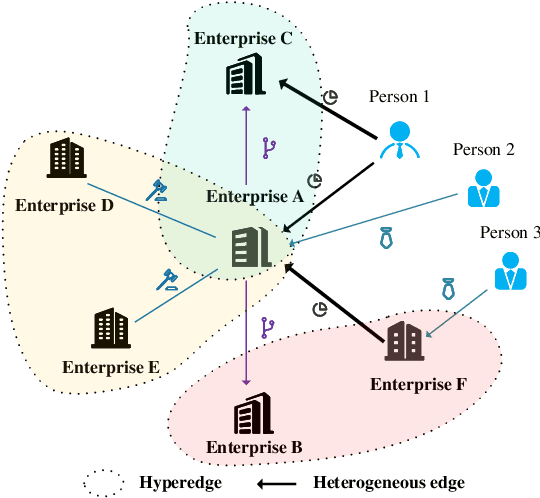
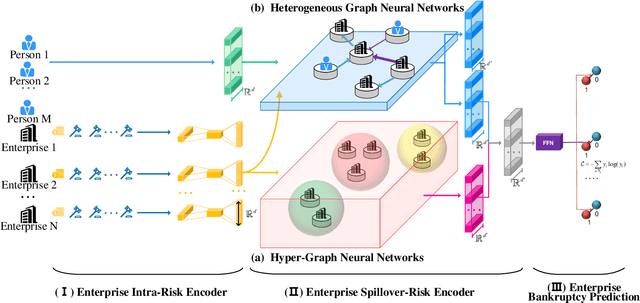
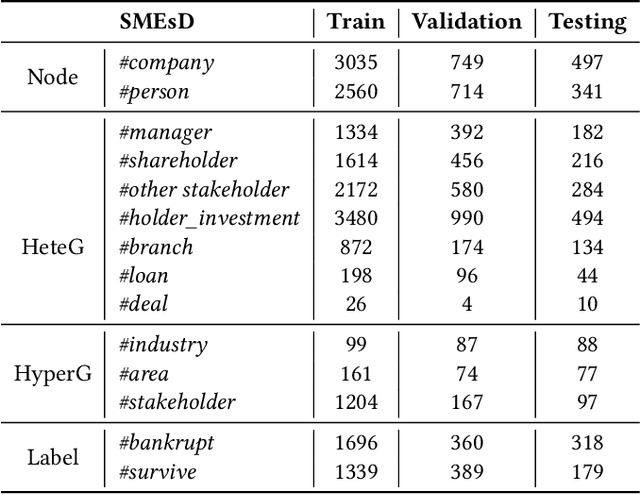
In this paper, we propose to model enterprise bankruptcy risk by fusing its intra-risk and spillover-risk. Under this framework, we propose a novel method that is equipped with an LSTM-based intra-risk encoder and GNNs-based spillover-risk encoder. Specifically, the intra-risk encoder is able to capture enterprise intra-risk using the statistic correlated indicators from the basic business information and litigation information. The spillover-risk encoder consists of hypergraph neural networks and heterogeneous graph neural networks, which aim to model spillover risk through two aspects, i.e. hyperedge and multiplex heterogeneous relations among enterprise knowledge graph, respectively. To evaluate the proposed model, we collect multi-sources SMEs data and build a new dataset SMEsD, on which the experimental results demonstrate the superiority of the proposed method. The dataset is expected to become a significant benchmark dataset for SMEs bankruptcy prediction and promote the development of financial risk study further.
Spatial Information Guided Convolution for Real-Time RGBD Semantic Segmentation
Apr 09, 2020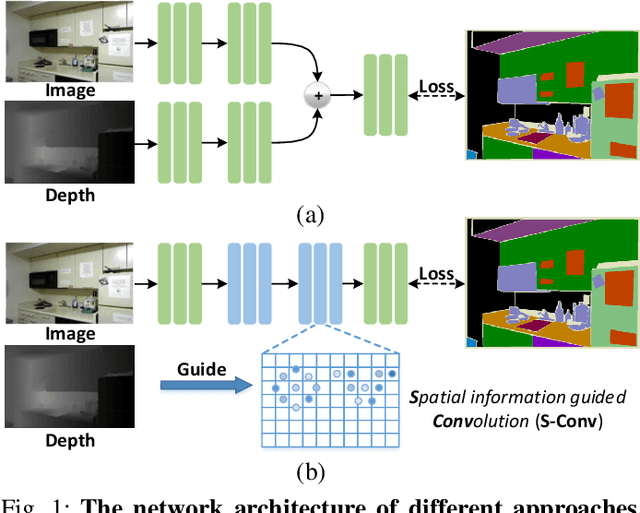
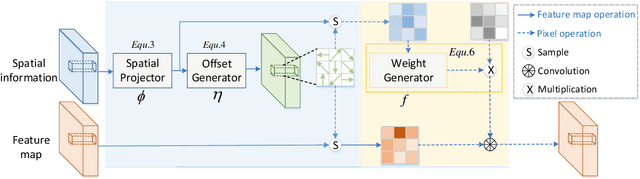
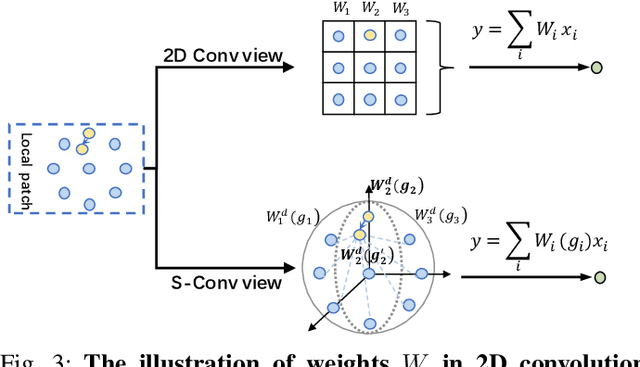
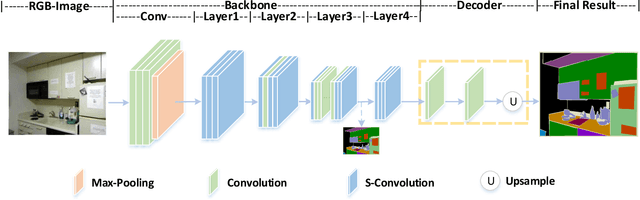
3D spatial information is known to be beneficial to the semantic segmentation task. Most existing methods take 3D spatial data as an additional input, leading to a two-stream segmentation network that processes RGB and 3D spatial information separately. This solution greatly increases the inference time and severely limits its scope for real-time applications. To solve this problem, we propose Spatial information guided Convolution (S-Conv), which allows efficient RGB feature and 3D spatial information integration. S-Conv is competent to infer the sampling offset of the convolution kernel guided by the 3D spatial information, helping the convolutional layer adjust the receptive field and adapt to geometric transformations. S-Conv also incorporates geometric information into the feature learning process by generating spatially adaptive convolutional weights. The capability of perceiving geometry is largely enhanced without much affecting the amount of parameters and computational cost. We further embed S-Conv into a semantic segmentation network, called Spatial information Guided convolutional Network (SGNet), resulting in real-time inference and state-of-the-art performance on NYUDv2 and SUNRGBD datasets.
KNIFE: Kernelized-Neural Differential Entropy Estimation
Feb 14, 2022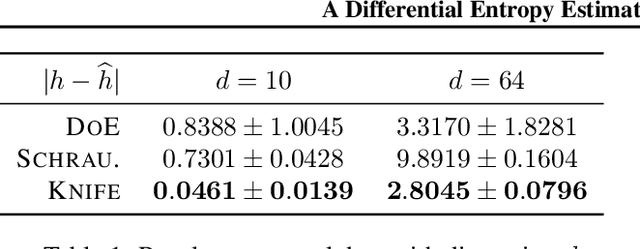
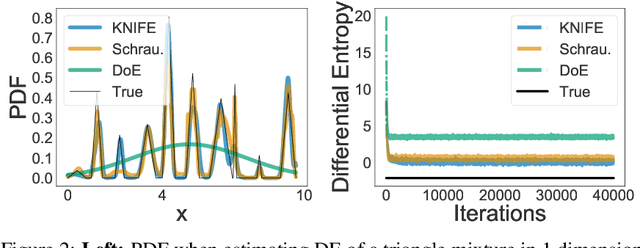
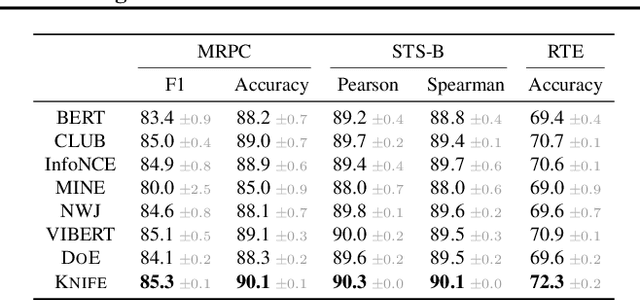
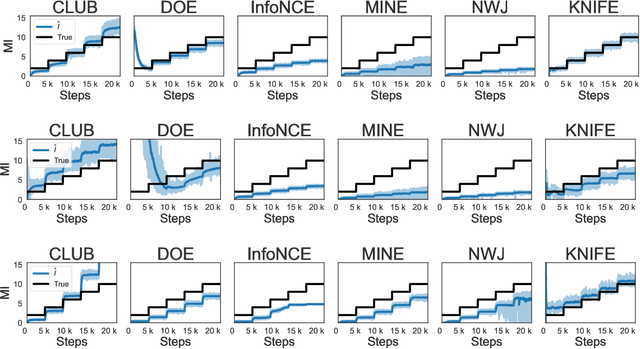
Mutual Information (MI) has been widely used as a loss regularizer for training neural networks. This has been particularly effective when learn disentangled or compressed representations of high dimensional data. However, differential entropy (DE), another fundamental measure of information, has not found widespread use in neural network training. Although DE offers a potentially wider range of applications than MI, off-the-shelf DE estimators are either non differentiable, computationally intractable or fail to adapt to changes in the underlying distribution. These drawbacks prevent them from being used as regularizers in neural networks training. To address shortcomings in previously proposed estimators for DE, here we introduce KNIFE, a fully parameterized, differentiable kernel-based estimator of DE. The flexibility of our approach also allows us to construct KNIFE-based estimators for conditional (on either discrete or continuous variables) DE, as well as MI. We empirically validate our method on high-dimensional synthetic data and further apply it to guide the training of neural networks for real-world tasks. Our experiments on a large variety of tasks, including visual domain adaptation, textual fair classification, and textual fine-tuning demonstrate the effectiveness of KNIFE-based estimation. Code can be found at https://github.com/g-pichler/knife.
Natural Language Descriptions of Deep Visual Features
Jan 26, 2022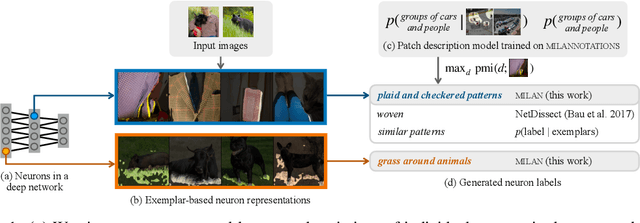
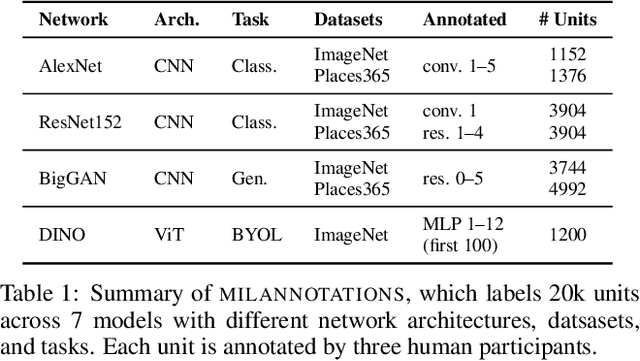
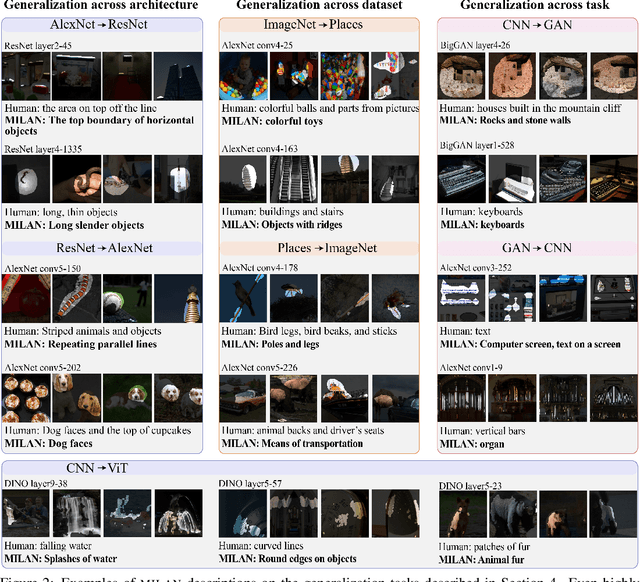
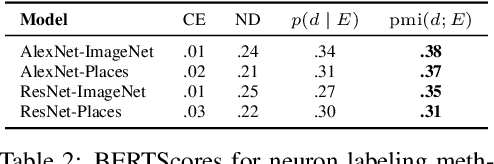
Some neurons in deep networks specialize in recognizing highly specific perceptual, structural, or semantic features of inputs. In computer vision, techniques exist for identifying neurons that respond to individual concept categories like colors, textures, and object classes. But these techniques are limited in scope, labeling only a small subset of neurons and behaviors in any network. Is a richer characterization of neuron-level computation possible? We introduce a procedure (called MILAN, for mutual-information-guided linguistic annotation of neurons) that automatically labels neurons with open-ended, compositional, natural language descriptions. Given a neuron, MILAN generates a description by searching for a natural language string that maximizes pointwise mutual information with the image regions in which the neuron is active. MILAN produces fine-grained descriptions that capture categorical, relational, and logical structure in learned features. These descriptions obtain high agreement with human-generated feature descriptions across a diverse set of model architectures and tasks, and can aid in understanding and controlling learned models. We highlight three applications of natural language neuron descriptions. First, we use MILAN for analysis, characterizing the distribution and importance of neurons selective for attribute, category, and relational information in vision models. Second, we use MILAN for auditing, surfacing neurons sensitive to protected categories like race and gender in models trained on datasets intended to obscure these features. Finally, we use MILAN for editing, improving robustness in an image classifier by deleting neurons sensitive to text features spuriously correlated with class labels.
Look-Ahead Acquisition Functions for Bernoulli Level Set Estimation
Mar 18, 2022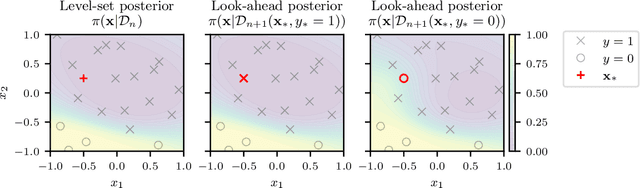
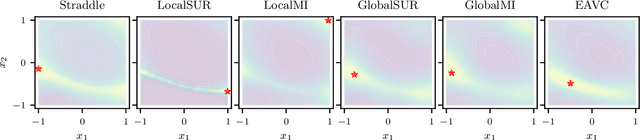
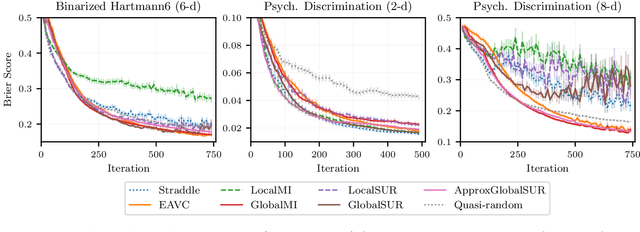

Level set estimation (LSE) is the problem of identifying regions where an unknown function takes values above or below a specified threshold. Active sampling strategies for efficient LSE have primarily been studied in continuous-valued functions. Motivated by applications in human psychophysics where common experimental designs produce binary responses, we study LSE active sampling with Bernoulli outcomes. With Gaussian process classification surrogate models, the look-ahead model posteriors used by state-of-the-art continuous-output methods are intractable. However, we derive analytic expressions for look-ahead posteriors of sublevel set membership, and show how these lead to analytic expressions for a class of look-ahead LSE acquisition functions, including information-based methods. Benchmark experiments show the importance of considering the global look-ahead impact on the entire posterior. We demonstrate a clear benefit to using this new class of acquisition functions on benchmark problems, and on a challenging real-world task of estimating a high-dimensional contrast sensitivity function.
Look Backward and Forward: Self-Knowledge Distillation with Bidirectional Decoder for Neural Machine Translation
Mar 10, 2022

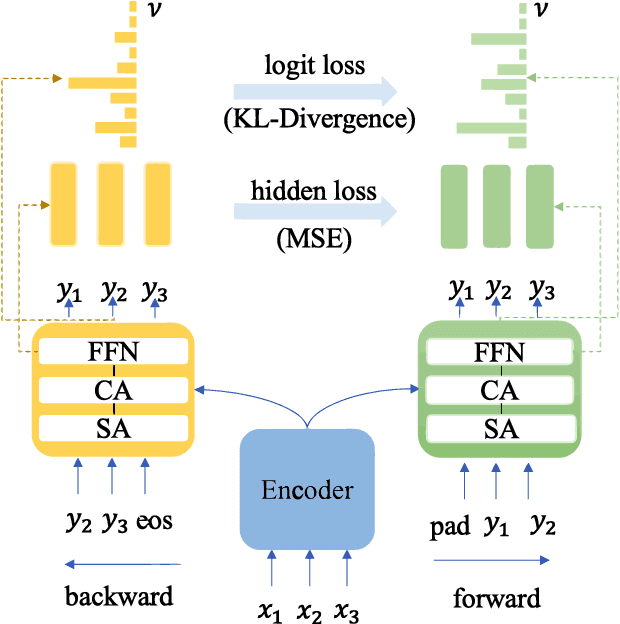
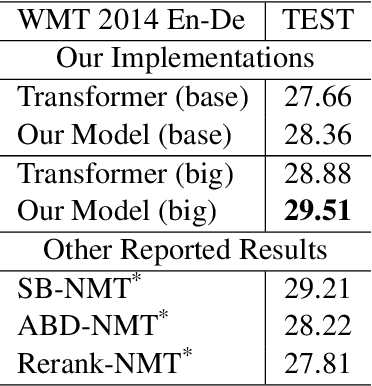
Neural Machine Translation(NMT) models are usually trained via unidirectional decoder which corresponds to optimizing one-step-ahead prediction. However, this kind of unidirectional decoding framework may incline to focus on local structure rather than global coherence. To alleviate this problem, we propose a novel method, Self-Knowledge Distillation with Bidirectional Decoder for Neural Machine Translation(SBD-NMT). We deploy a backward decoder which can act as an effective regularization method to the forward decoder. By leveraging the backward decoder's information about the longer-term future, distilling knowledge learned in the backward decoder can encourage auto-regressive NMT models to plan ahead. Experiments show that our method is significantly better than the strong Transformer baselines on multiple machine translation data sets. Our codes will be released on github soon.
Evaluating Deep Vs. Wide & Deep Learners As Contextual Bandits For Personalized Email Promo Recommendations
Jan 31, 2022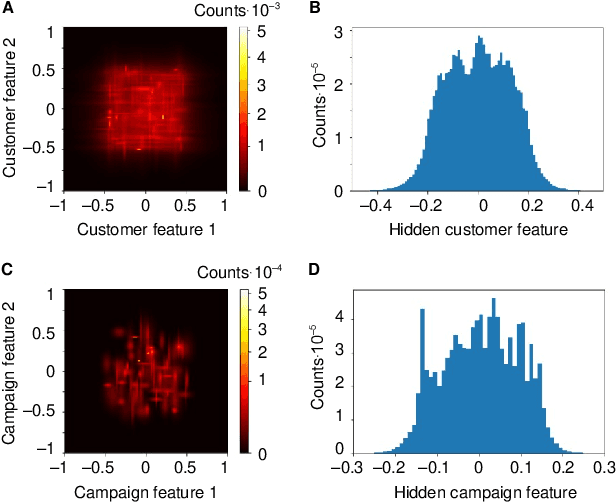

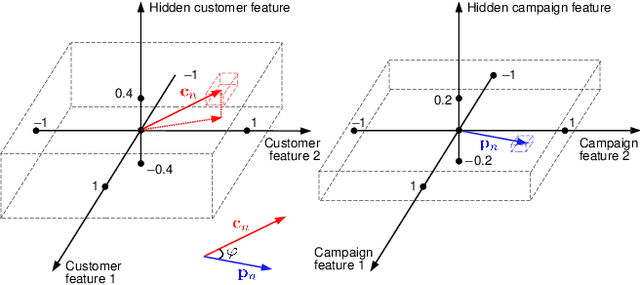

Personalization enables businesses to learn customer preferences from past interactions and thus to target individual customers with more relevant content. We consider the problem of predicting the optimal promotional offer for a given customer out of several options as a contextual bandit problem. Identifying information for the customer and/or the campaign can be used to deduce unknown customer/campaign features that improve optimal offer prediction. Using a generated synthetic email promo dataset, we demonstrate similar prediction accuracies for (a) a wide and deep network that takes identifying information (or other categorical features) as input to the wide part and (b) a deep-only neural network that includes embeddings of categorical features in the input. Improvements in accuracy from including categorical features depends on the variability of the unknown numerical features for each category. We also show that selecting options using upper confidence bound or Thompson sampling, approximated via Monte Carlo dropout layers in the wide and deep models, slightly improves model performance.
Deep Image Compression using Decoder Side Information
Jan 14, 2020
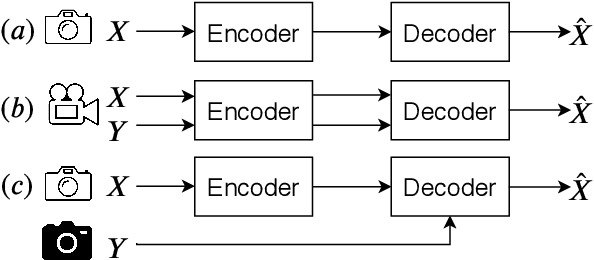
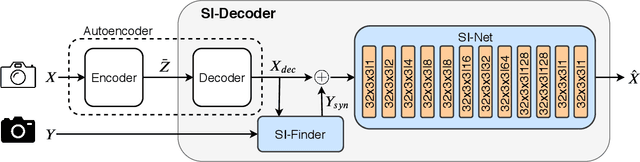
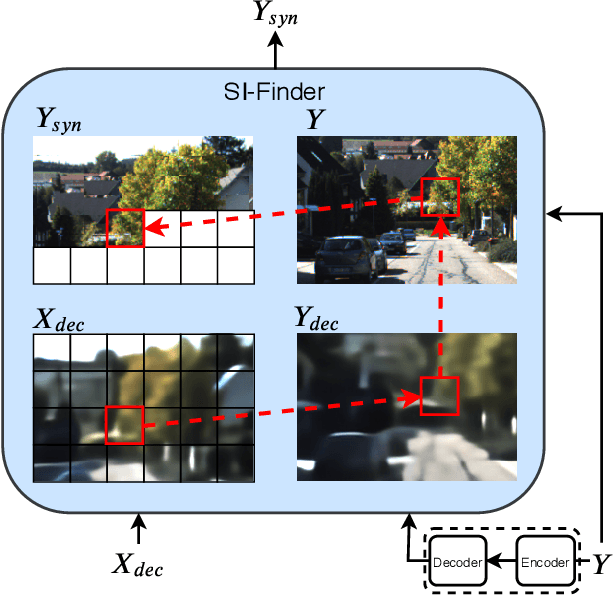
We present a Deep Image Compression neural network that relies on side information, which is only available to the decoder. We base our algorithm on the assumption that the image available to the encoder and the image available to the decoder are correlated, and we let the network learn these correlations in the training phase. Then, at run time, the encoder side encodes the input image without knowing anything about the decoder side image and sends it to the decoder. The decoder then uses the encoded input image and the side information image to reconstruct the original image. This problem is known as Distributed Source Coding in Information Theory, and we discuss several use cases for this technology. We compare our algorithm to several image compression algorithms and show that adding decoder-only side information does indeed improve results. Our code is publicly available at https://github.com/ayziksha/DSIN.
Visibility-Inspired Models of Touch Sensors for Navigation
Mar 04, 2022

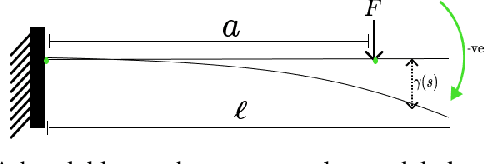

This paper introduces mathematical models of touch sensors for mobile robotics based on visibility. Serving a purpose similar to the pinhole camera model for computer vision, the introduced models are expected to provide a useful, idealized characterization of task-relevant information that can be inferred from their outputs or observations. This allows direct comparisons to be made between traditional depth sensors, highlighting cases in which touch sensing may be interchangeable with time of flight or vision sensors, and characterizing unique advantages provided by touch sensing. The models include contact detection, compression, load bearing, and deflection. The results could serve as a basic building block for innovative touch sensor designs for mobile robot sensor fusion systems.
Incentive Mechanism Design for Joint Resource Allocation in Blockchain-based Federated Learning
Feb 18, 2022
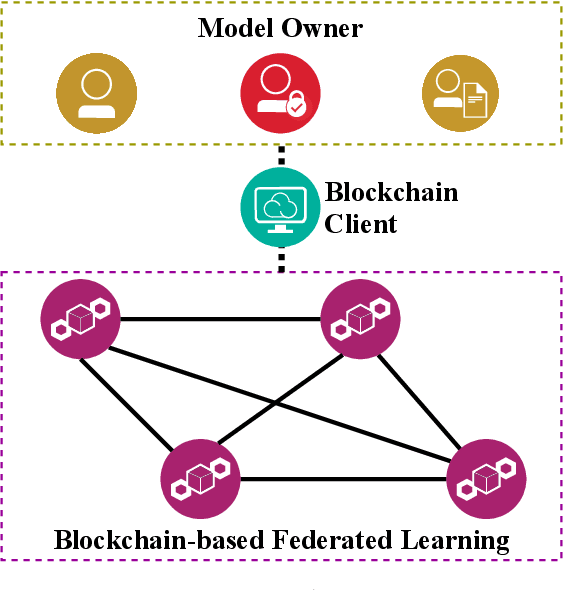
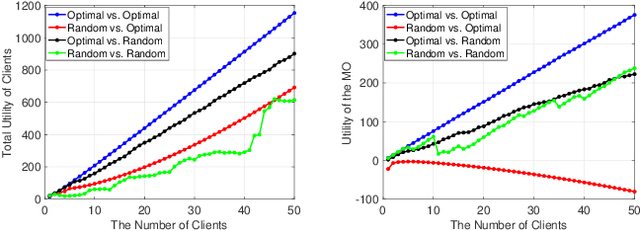
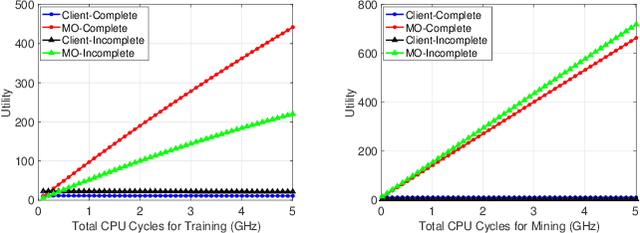
Blockchain-based federated learning (BCFL) has recently gained tremendous attention because of its advantages such as decentralization and privacy protection of raw data. However, there has been few research focusing on the allocation of resources for clients in BCFL. In the BCFL framework where the FL clients and the blockchain miners are the same devices, clients broadcast the trained model updates to the blockchain network and then perform mining to generate new blocks. Since each client has a limited amount of computing resources, the problem of allocating computing resources into training and mining needs to be carefully addressed. In this paper, we design an incentive mechanism to assign each client appropriate rewards for training and mining, and then the client will determine the amount of computing power to allocate for each subtask based on these rewards using the two-stage Stackelberg game. After analyzing the utilities of the model owner (MO) (i.e., the BCFL task publisher) and clients, we transform the game model into two optimization problems, which are sequentially solved to derive the optimal strategies for both the MO and clients. Further, considering the fact that local training related information of each client may not be known by others, we extend the game model with analytical solutions to the incomplete information scenario. Extensive experimental results demonstrate the validity of our proposed schemes.