 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
In-N-Out Generative Learning for Dense Unsupervised Video Segmentation
Apr 11, 2022

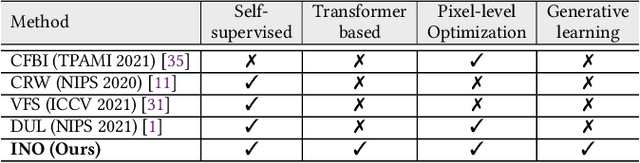
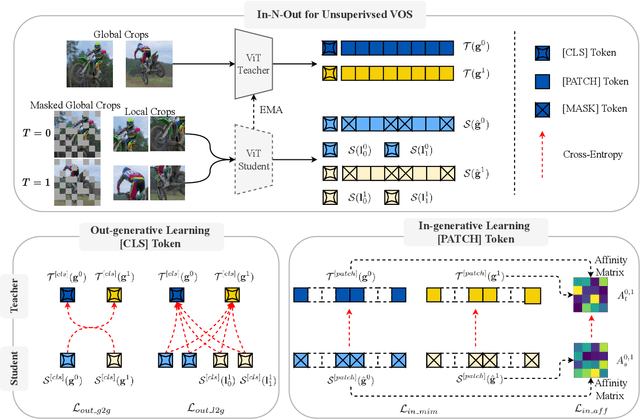
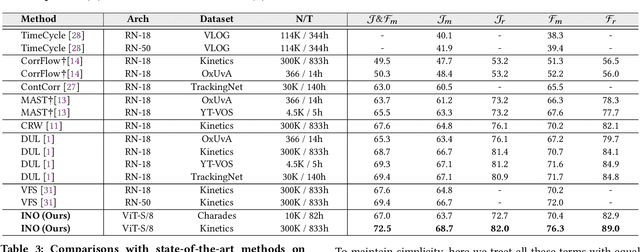
In this paper, we focus on the unsupervised learning for Video Object Segmentation (VOS) which learns visual correspondence (i.e., similarity between pixel-level features) from unlabeled videos. Previous methods are mainly based on the contrastive learning paradigm, which optimize either in image level or pixel level. Image-level optimization (e.g., the spatially pooled feature of ResNet) learns robust high-level semantics but is sub-optimal since the pixel-level features are optimized implicitly. By contrast, pixel-level optimization is more explicit, however, it is sensitive to the visual quality of training data and is not robust to object deformation. To complementarily perform these two levels of optimization in a unified framework, we propose the In-aNd-Out (INO) generative learning from a purely generative perspective with the help of naturally designed class tokens and patch tokens in Vision Transformer (ViT). Specifically, for image-level optimization, we force the out-view imagination from local to global views on class tokens, which helps capturing high-level semantics, and we name it as out-generative learning. As to pixel-level optimization, we perform in-view masked image modeling on patch tokens, which recovers the corrupted parts of an image via inferring its fine-grained structure, and we term it as in-generative learning. To better discover the temporal information, we additionally force the inter-frame consistency from both feature level and affinity matrix level. Extensive experiments on DAVIS-2017 val and YouTube-VOS 2018 val show that our INO outperforms previous state-of-the-art methods by significant margins.
FisrEbp: Enterprise Bankruptcy Prediction via Fusing its Intra-risk and Spillover-Risk
Feb 01, 2022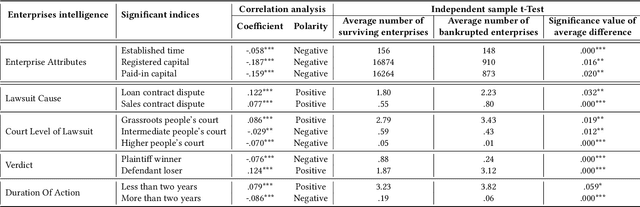
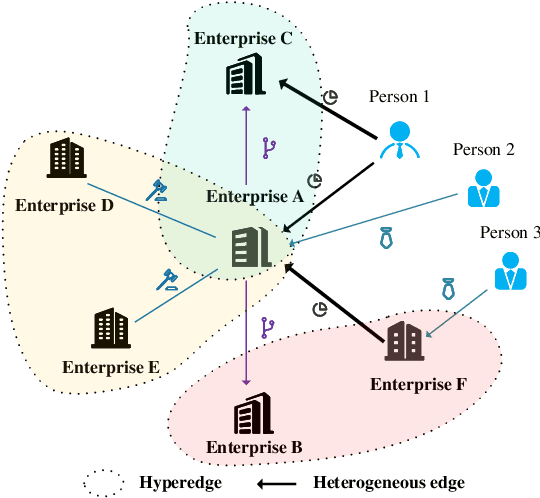
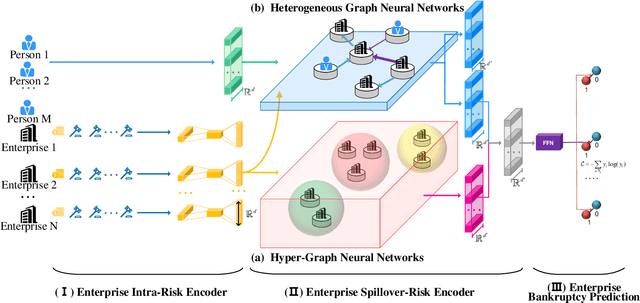
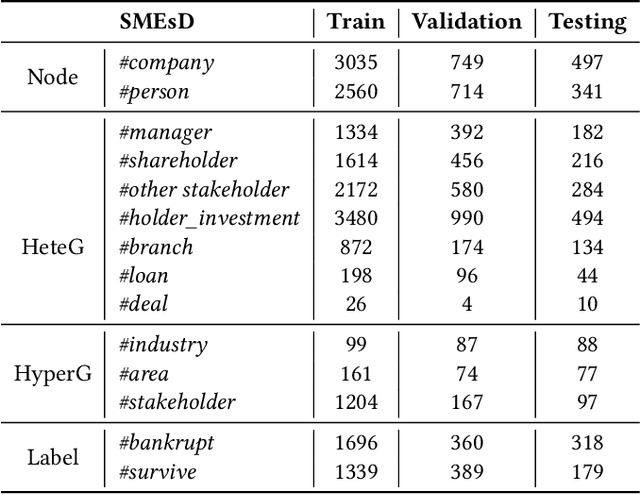
In this paper, we propose to model enterprise bankruptcy risk by fusing its intra-risk and spillover-risk. Under this framework, we propose a novel method that is equipped with an LSTM-based intra-risk encoder and GNNs-based spillover-risk encoder. Specifically, the intra-risk encoder is able to capture enterprise intra-risk using the statistic correlated indicators from the basic business information and litigation information. The spillover-risk encoder consists of hypergraph neural networks and heterogeneous graph neural networks, which aim to model spillover risk through two aspects, i.e. hyperedge and multiplex heterogeneous relations among enterprise knowledge graph, respectively. To evaluate the proposed model, we collect multi-sources SMEs data and build a new dataset SMEsD, on which the experimental results demonstrate the superiority of the proposed method. The dataset is expected to become a significant benchmark dataset for SMEs bankruptcy prediction and promote the development of financial risk study further.
A Novel Capsule Neural Network Based Model for Drowsiness Detection Using Electroencephalography Signals
Apr 04, 2022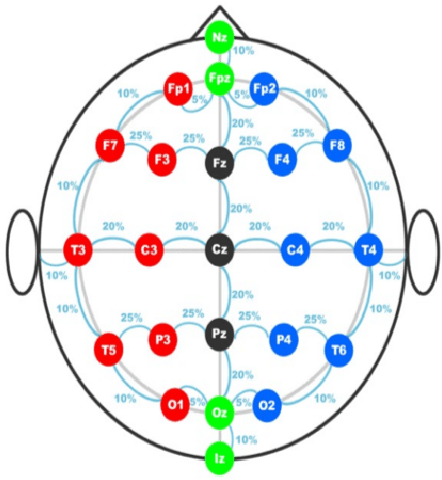
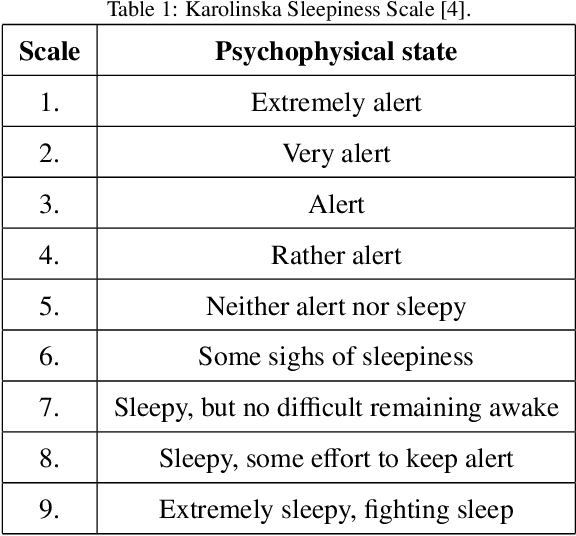
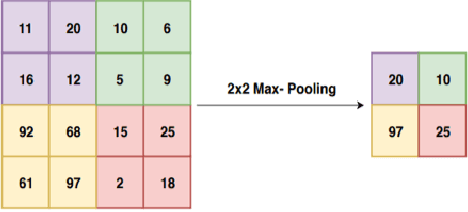
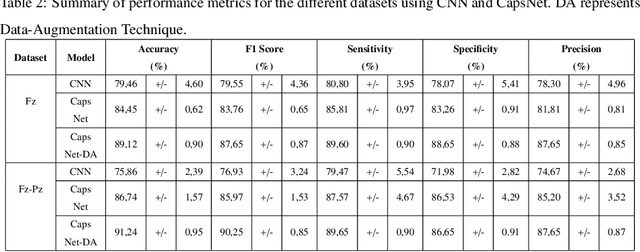
The early detection of drowsiness has become vital to ensure the correct and safe development of several industries' tasks. Due to the transient mental state of a human subject between alertness and drowsiness, automated drowsiness detection is a complex problem to tackle. The electroencephalography signals allow us to record variations in an individual's brain's electrical potential, where each of them gives specific information about a subject's mental state. However, due to this type of signal's nature, its acquisition, in general, is complex, so it is hard to have a large volume of data to apply techniques of Deep Learning for processing and classification optimally. Nevertheless, Capsule Neural Networks are a brand-new Deep Learning algorithm proposed for work with reduced amounts of data. It is a robust algorithm to handle the data's hierarchical relationships, which is an essential characteristic for work with biomedical signals. Therefore, this paper presents a Deep Learning-based method for drowsiness detection with CapsNet by using a concatenation of spectrogram images of the electroencephalography signals channels. The proposed CapsNet model is compared with a Convolutional Neural Network, which is outperformed by the proposed model, which obtains an average accuracy of 86,44% and 87,57% of sensitivity against an average accuracy of 75,86% and 79,47% sensitivity for the CNN, showing that CapsNet is more suitable for this kind of datasets and tasks.
Usable Information and Evolution of Optimal Representations During Training
Oct 06, 2020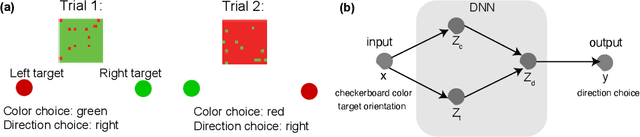
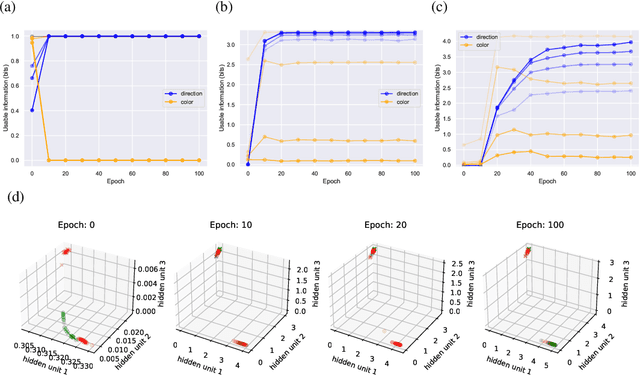
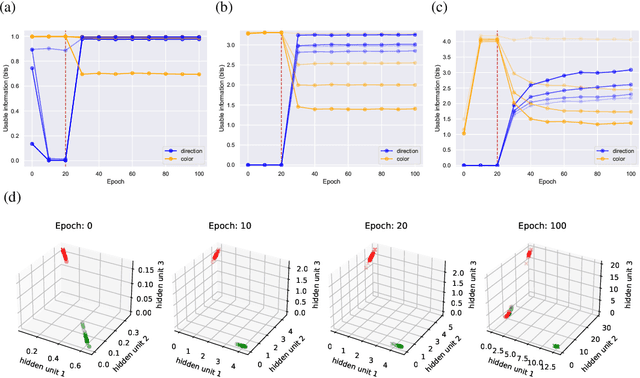
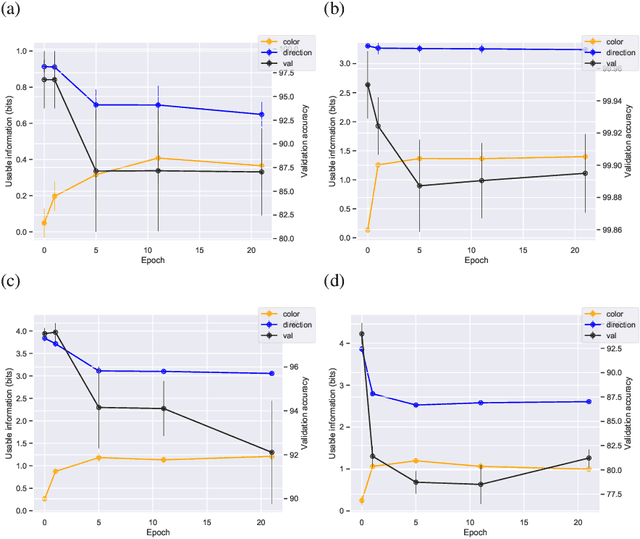
We introduce a notion of usable information contained in the representation learned by a deep network, and use it to study how optimal representations for the task emerge during training, and how they adapt to different tasks. We use this to characterize the transient dynamics of deep neural networks on perceptual decision-making tasks inspired by neuroscience literature. In particular, we show that both the random initialization and the implicit regularization from Stochastic Gradient Descent play an important role in learning minimal sufficient representations for the task. If the network is not randomly initialized, we show that the training may not recover an optimal representation, increasing the chance of overfitting.
Disentanglement by Cyclic Reconstruction
Dec 24, 2021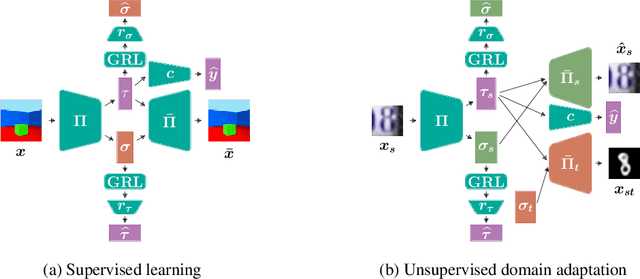

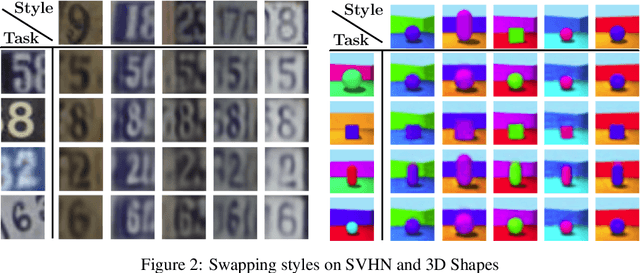
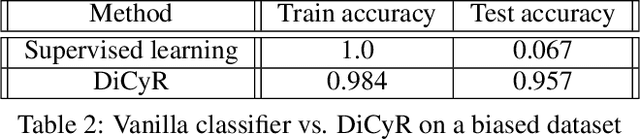
Deep neural networks have demonstrated their ability to automatically extract meaningful features from data. However, in supervised learning, information specific to the dataset used for training, but irrelevant to the task at hand, may remain encoded in the extracted representations. This remaining information introduces a domain-specific bias, weakening the generalization performance. In this work, we propose splitting the information into a task-related representation and its complementary context representation. We propose an original method, combining adversarial feature predictors and cyclic reconstruction, to disentangle these two representations in the single-domain supervised case. We then adapt this method to the unsupervised domain adaptation problem, consisting of training a model capable of performing on both a source and a target domain. In particular, our method promotes disentanglement in the target domain, despite the absence of training labels. This enables the isolation of task-specific information from both domains and a projection into a common representation. The task-specific representation allows efficient transfer of knowledge acquired from the source domain to the target domain. In the single-domain case, we demonstrate the quality of our representations on information retrieval tasks and the generalization benefits induced by sharpened task-specific representations. We then validate the proposed method on several classical domain adaptation benchmarks and illustrate the benefits of disentanglement for domain adaptation.
Natural Language Descriptions of Deep Visual Features
Jan 26, 2022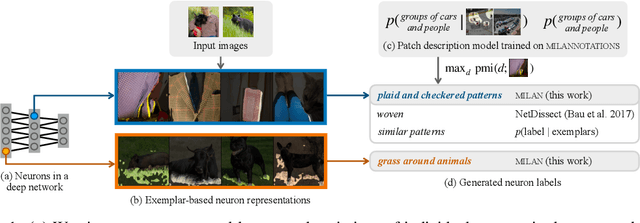
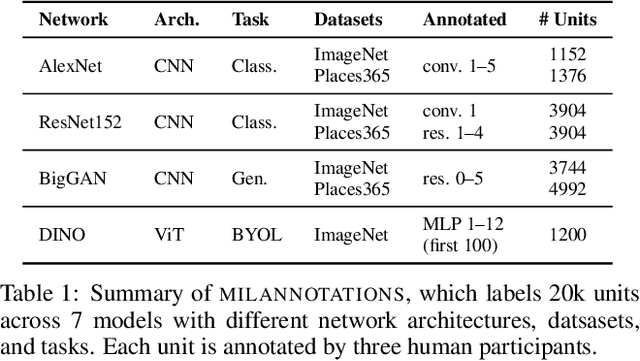
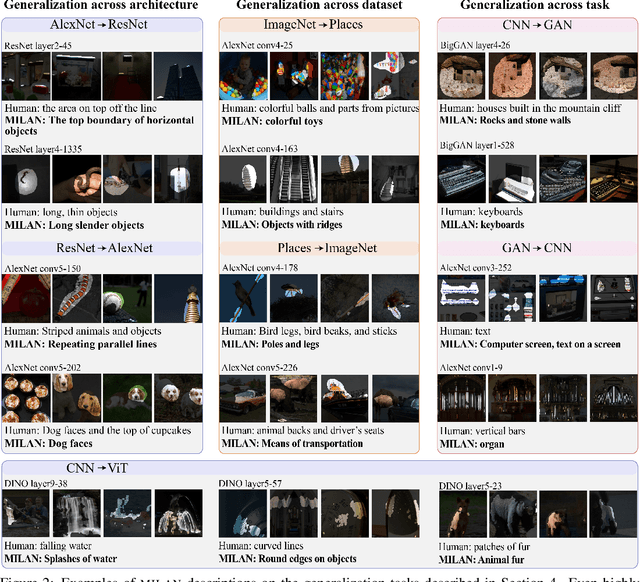
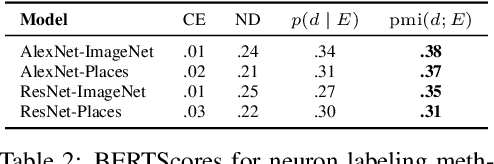
Some neurons in deep networks specialize in recognizing highly specific perceptual, structural, or semantic features of inputs. In computer vision, techniques exist for identifying neurons that respond to individual concept categories like colors, textures, and object classes. But these techniques are limited in scope, labeling only a small subset of neurons and behaviors in any network. Is a richer characterization of neuron-level computation possible? We introduce a procedure (called MILAN, for mutual-information-guided linguistic annotation of neurons) that automatically labels neurons with open-ended, compositional, natural language descriptions. Given a neuron, MILAN generates a description by searching for a natural language string that maximizes pointwise mutual information with the image regions in which the neuron is active. MILAN produces fine-grained descriptions that capture categorical, relational, and logical structure in learned features. These descriptions obtain high agreement with human-generated feature descriptions across a diverse set of model architectures and tasks, and can aid in understanding and controlling learned models. We highlight three applications of natural language neuron descriptions. First, we use MILAN for analysis, characterizing the distribution and importance of neurons selective for attribute, category, and relational information in vision models. Second, we use MILAN for auditing, surfacing neurons sensitive to protected categories like race and gender in models trained on datasets intended to obscure these features. Finally, we use MILAN for editing, improving robustness in an image classifier by deleting neurons sensitive to text features spuriously correlated with class labels.
The Curse of Dense Low-Dimensional Information Retrieval for Large Index Sizes
Dec 28, 2020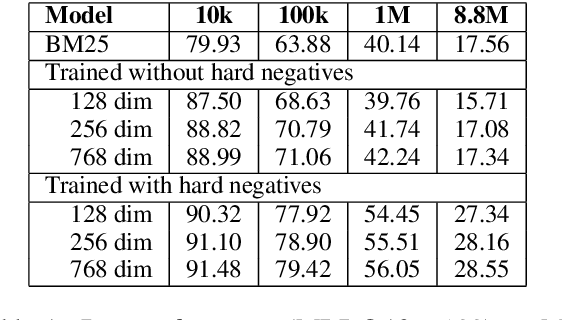
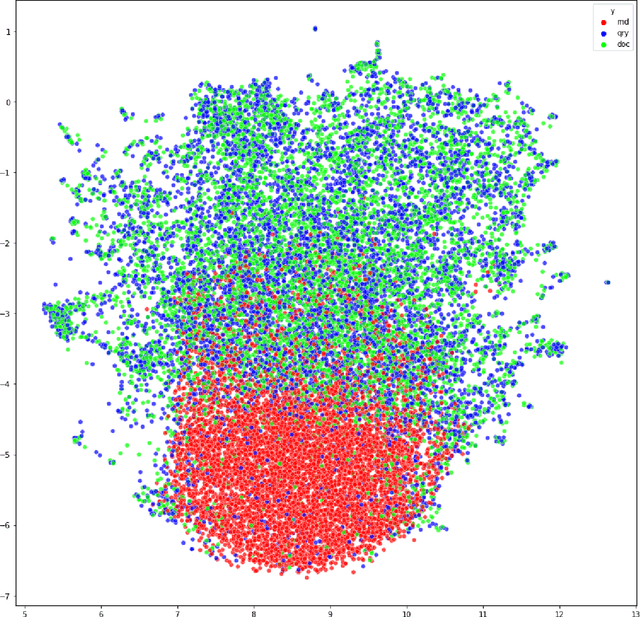
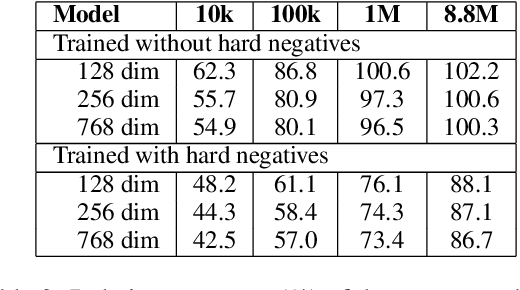
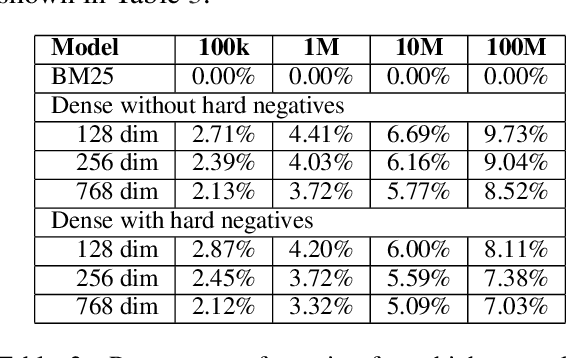
Information Retrieval using dense low-dimensional representations recently became popular and showed out-performance to traditional sparse-representations like BM25. However, no previous work investigated how dense representations perform with large index sizes. We show theoretically and empirically that the performance for dense representations decreases quicker than sparse representations for increasing index sizes. In extreme cases, this can even lead to a tipping point where at a certain index size sparse representations outperform dense representations. We show that this behavior is tightly connected to the number of dimensions of the representations: The lower the dimension, the higher the chance for false positives, i.e. returning irrelevant documents.
A Survey on Deep Graph Generation: Methods and Applications
Mar 13, 2022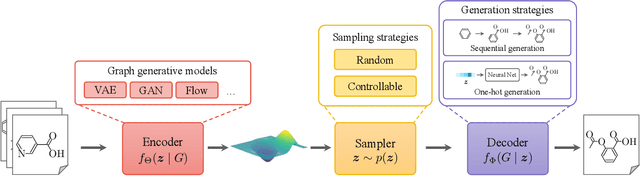

Graphs are ubiquitous in encoding relational information of real-world objects in many domains. Graph generation, whose purpose is to generate new graphs from a distribution similar to the observed graphs, has received increasing attention thanks to the recent advances of deep learning models. In this paper, we conduct a comprehensive review on the existing literature of graph generation from a variety of emerging methods to its wide application areas. Specifically, we first formulate the problem of deep graph generation and discuss its difference with several related graph learning tasks. Secondly, we divide the state-of-the-art methods into three categories based on model architectures and summarize their generation strategies. Thirdly, we introduce three key application areas of deep graph generation. Lastly, we highlight challenges and opportunities in the future study of deep graph generation.
A Survey of Information Cascade Analysis: Models, Predictions and Recent Advances
May 25, 2020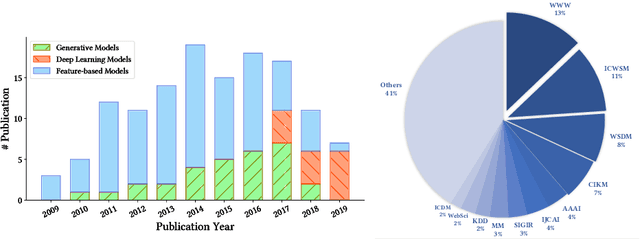
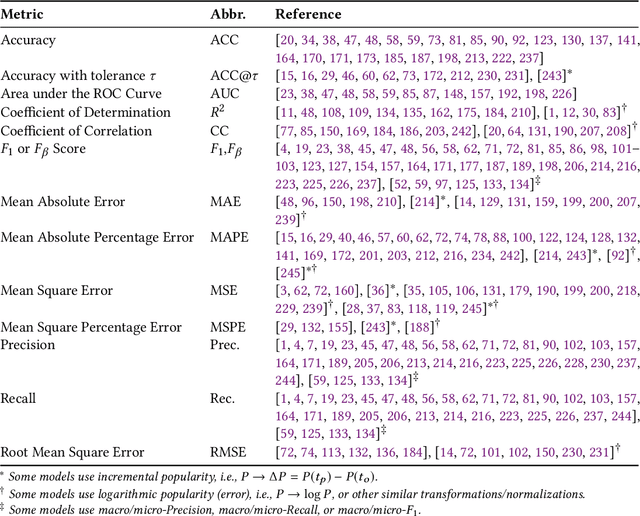
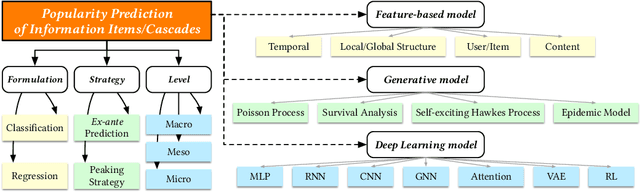

The deluge of digital information in our daily life -- from user-generated content such as microblogs and scientific papers, to online business such as viral marketing and advertising -- offers unprecedented opportunities to explore and exploit the trajectories and structures of the evolution of information cascades. Abundant research efforts, both academic and industrial, have aimed to reach a better understanding of the mechanisms driving the spread of information and quantifying the outcome of information diffusion. This article presents a comprehensive review and categorization of information popularity prediction methods, from feature engineering and stochastic processes, through graph representation, to deep learning-based approaches. Specifically, we first formally define different types of information cascades and summarize the perspectives of existing studies. We then present a taxonomy that categorizes existing works into the aforementioned three main groups as well as the main subclasses in each group, and we systematically review cutting-edge research work. Finally, we summarize the pros and cons of existing research efforts and outline the open challenges and opportunities in this field.
Resurrecting Trust in Facial Recognition: Mitigating Backdoor Attacks in Face Recognition to Prevent Potential Privacy Breaches
Feb 18, 2022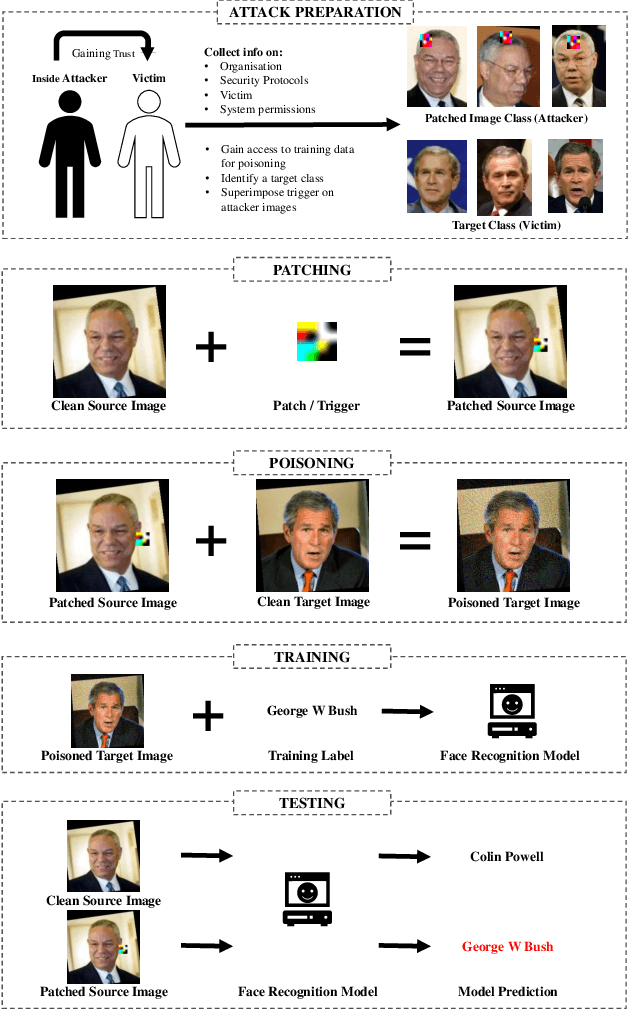
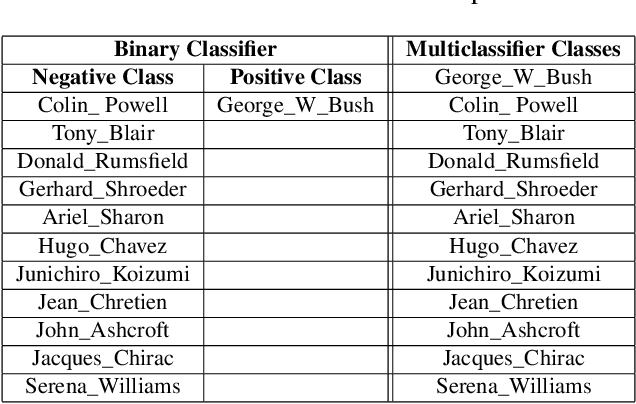
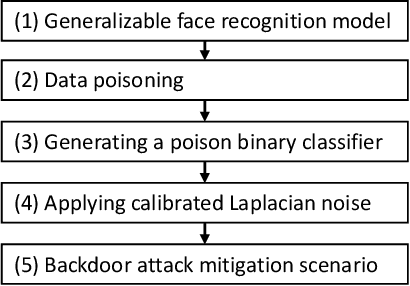
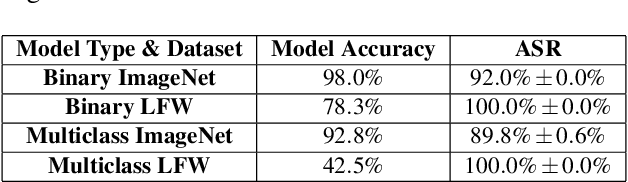
Biometric data, such as face images, are often associated with sensitive information (e.g medical, financial, personal government records). Hence, a data breach in a system storing such information can have devastating consequences. Deep learning is widely utilized for face recognition (FR); however, such models are vulnerable to backdoor attacks executed by malicious parties. Backdoor attacks cause a model to misclassify a particular class as a target class during recognition. This vulnerability can allow adversaries to gain access to highly sensitive data protected by biometric authentication measures or allow the malicious party to masquerade as an individual with higher system permissions. Such breaches pose a serious privacy threat. Previous methods integrate noise addition mechanisms into face recognition models to mitigate this issue and improve the robustness of classification against backdoor attacks. However, this can drastically affect model accuracy. We propose a novel and generalizable approach (named BA-BAM: Biometric Authentication - Backdoor Attack Mitigation), that aims to prevent backdoor attacks on face authentication deep learning models through transfer learning and selective image perturbation. The empirical evidence shows that BA-BAM is highly robust and incurs a maximal accuracy drop of 2.4%, while reducing the attack success rate to a maximum of 20%. Comparisons with existing approaches show that BA-BAM provides a more practical backdoor mitigation approach for face recognition.