 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Audio-Visual Speech Codecs: Rethinking Audio-Visual Speech Enhancement by Re-Synthesis
Mar 31, 2022
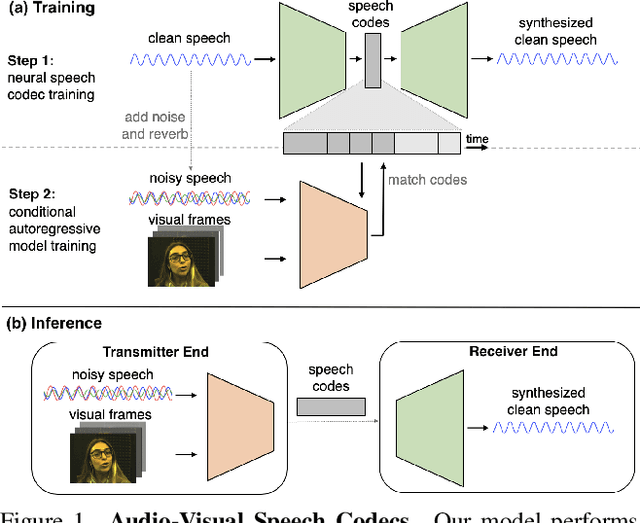
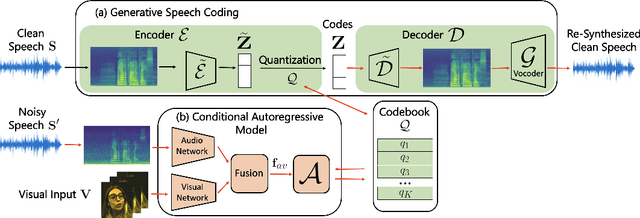

Since facial actions such as lip movements contain significant information about speech content, it is not surprising that audio-visual speech enhancement methods are more accurate than their audio-only counterparts. Yet, state-of-the-art approaches still struggle to generate clean, realistic speech without noise artifacts and unnatural distortions in challenging acoustic environments. In this paper, we propose a novel audio-visual speech enhancement framework for high-fidelity telecommunications in AR/VR. Our approach leverages audio-visual speech cues to generate the codes of a neural speech codec, enabling efficient synthesis of clean, realistic speech from noisy signals. Given the importance of speaker-specific cues in speech, we focus on developing personalized models that work well for individual speakers. We demonstrate the efficacy of our approach on a new audio-visual speech dataset collected in an unconstrained, large vocabulary setting, as well as existing audio-visual datasets, outperforming speech enhancement baselines on both quantitative metrics and human evaluation studies. Please see the supplemental video for qualitative results at https://github.com/facebookresearch/facestar/releases/download/paper_materials/video.mp4.
ImpDet: Exploring Implicit Fields for 3D Object Detection
Mar 31, 2022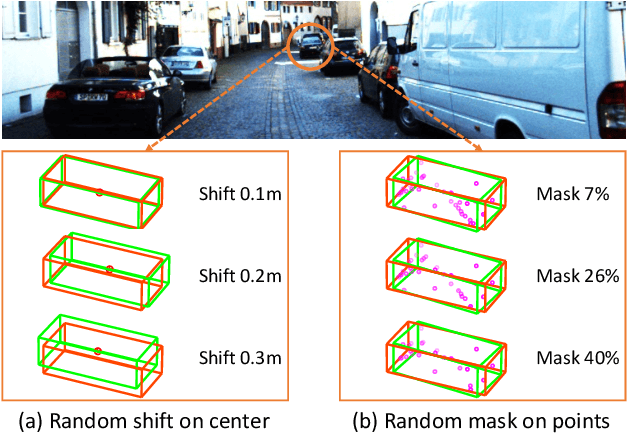
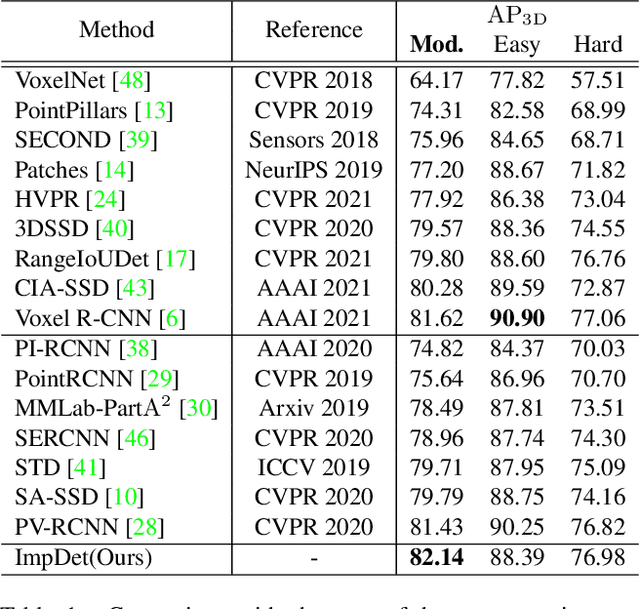
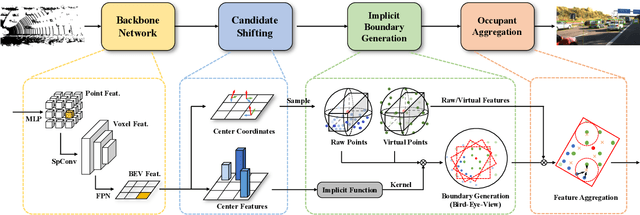
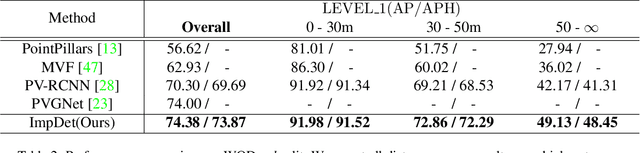
Conventional 3D object detection approaches concentrate on bounding boxes representation learning with several parameters, i.e., localization, dimension, and orientation. Despite its popularity and universality, such a straightforward paradigm is sensitive to slight numerical deviations, especially in localization. By exploiting the property that point clouds are naturally captured on the surface of objects along with accurate location and intensity information, we introduce a new perspective that views bounding box regression as an implicit function. This leads to our proposed framework, termed Implicit Detection or ImpDet, which leverages implicit field learning for 3D object detection. Our ImpDet assigns specific values to points in different local 3D spaces, thereby high-quality boundaries can be generated by classifying points inside or outside the boundary. To solve the problem of sparsity on the object surface, we further present a simple yet efficient virtual sampling strategy to not only fill the empty region, but also learn rich semantic features to help refine the boundaries. Extensive experimental results on KITTI and Waymo benchmarks demonstrate the effectiveness and robustness of unifying implicit fields into object detection.
Improved Relation Networks for End-to-End Speaker Verification and Identification
Mar 31, 2022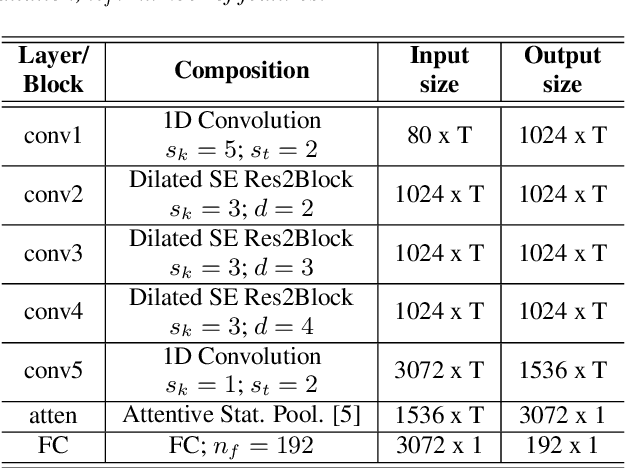
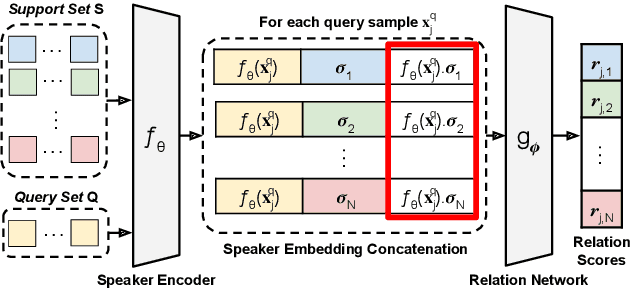

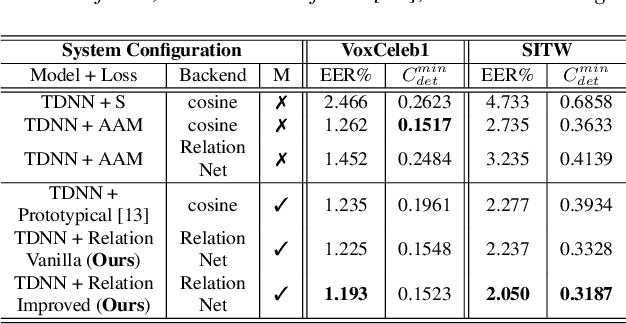
Speaker identification systems in a real-world scenario are tasked to identify a speaker amongst a set of enrolled speakers given just a few samples for each enrolled speaker. This paper demonstrates the effectiveness of meta-learning and relation networks for this use case. We propose improved relation networks for speaker verification and few-shot (unseen) speaker identification. The use of relation networks facilitates joint training of the frontend speaker encoder and the backend model. Inspired by the use of prototypical networks in speaker verification and to increase the discriminability of the speaker embeddings, we train the model to classify samples in the current episode amongst all speakers present in the training set. Furthermore, we propose a new training regime for faster model convergence by extracting more information from a given meta-learning episode with negligible extra computation. We evaluate the proposed techniques on VoxCeleb, SITW and VCTK datasets on the tasks of speaker verification and unseen speaker identification. The proposed approach outperforms the existing approaches consistently on both tasks.
DynaMixer: A Vision MLP Architecture with Dynamic Mixing
Jan 28, 2022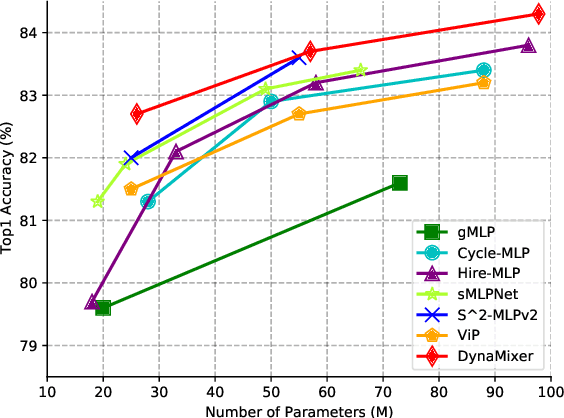
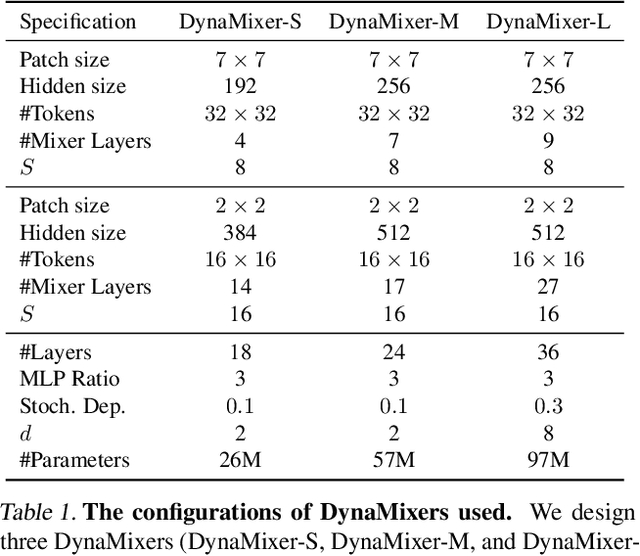
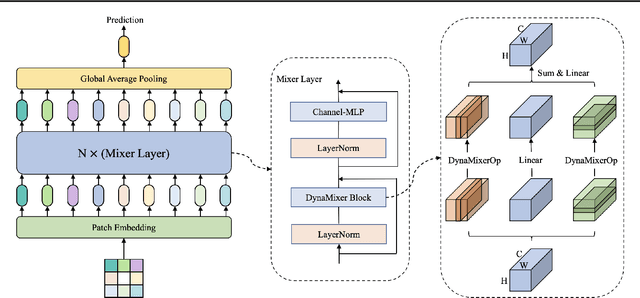
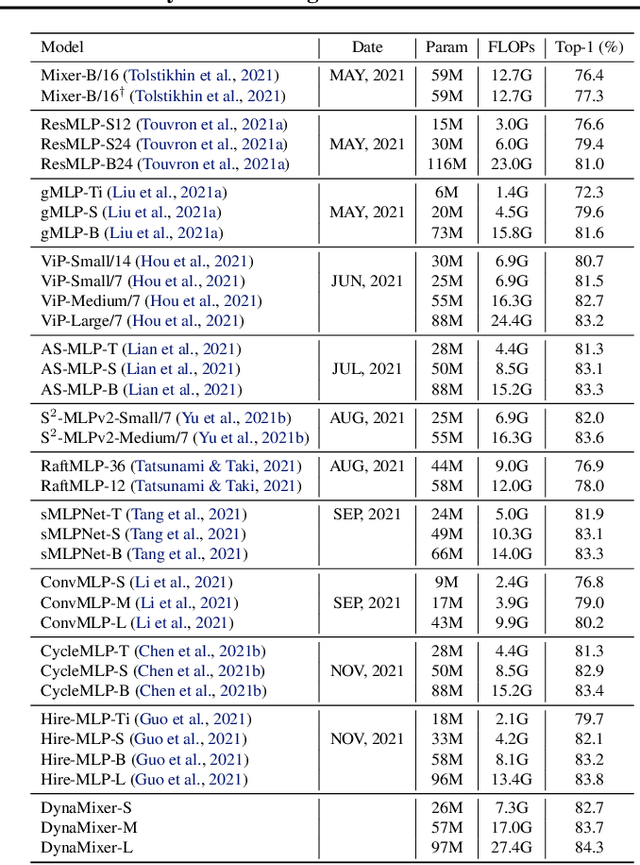
Recently, MLP-like vision models have achieved promising performances on mainstream visual recognition tasks. In contrast with vision transformers and CNNs, the success of MLP-like models shows that simple information fusion operations among tokens and channels can yield a good representation power for deep recognition models. However, existing MLP-like models fuse tokens through static fusion operations, lacking adaptability to the contents of the tokens to be mixed. Thus, customary information fusion procedures are not effective enough. To this end, this paper presents an efficient MLP-like network architecture, dubbed DynaMixer, resorting to dynamic information fusion. Critically, we propose a procedure, on which the DynaMixer model relies, to dynamically generate mixing matrices by leveraging the contents of all the tokens to be mixed. To reduce the time complexity and improve the robustness, a dimensionality reduction technique and a multi-segment fusion mechanism are adopted. Our proposed DynaMixer model (97M parameters) achieves 84.3\% top-1 accuracy on the ImageNet-1K dataset without extra training data, performing favorably against the state-of-the-art vision MLP models. When the number of parameters is reduced to 26M, it still achieves 82.7\% top-1 accuracy, surpassing the existing MLP-like models with a similar capacity. The implementation of DynaMixer will be made available to the public.
Leveraging Tacit Information Embedded in CNN Layers for Visual Tracking
Oct 02, 2020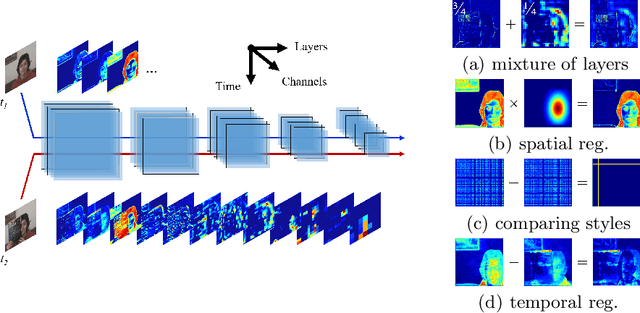
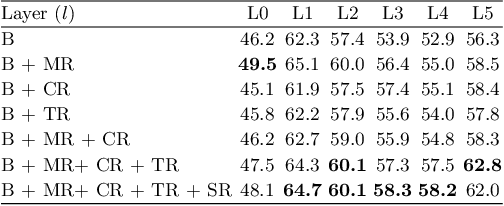
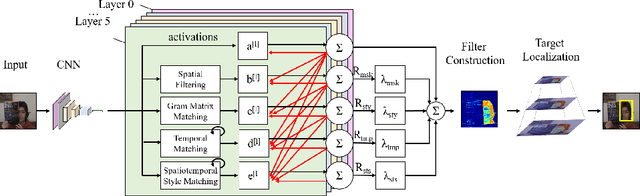

Different layers in CNNs provide not only different levels of abstraction for describing the objects in the input but also encode various implicit information about them. The activation patterns of different features contain valuable information about the stream of incoming images: spatial relations, temporal patterns, and co-occurrence of spatial and spatiotemporal (ST) features. The studies in visual tracking literature, so far, utilized only one of the CNN layers, a pre-fixed combination of them, or an ensemble of trackers built upon individual layers. In this study, we employ an adaptive combination of several CNN layers in a single DCF tracker to address variations of the target appearances and propose the use of style statistics on both spatial and temporal properties of the target, directly extracted from CNN layers for visual tracking. Experiments demonstrate that using the additional implicit data of CNNs significantly improves the performance of the tracker. Results demonstrate the effectiveness of using style similarity and activation consistency regularization in improving its localization and scale accuracy.
Mixed-Phoneme BERT: Improving BERT with Mixed Phoneme and Sup-Phoneme Representations for Text to Speech
Mar 31, 2022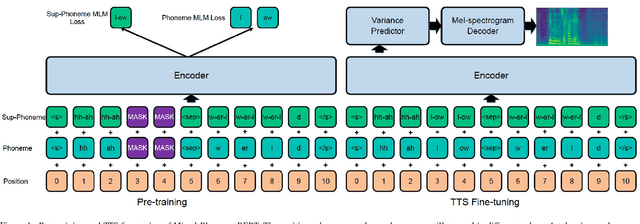
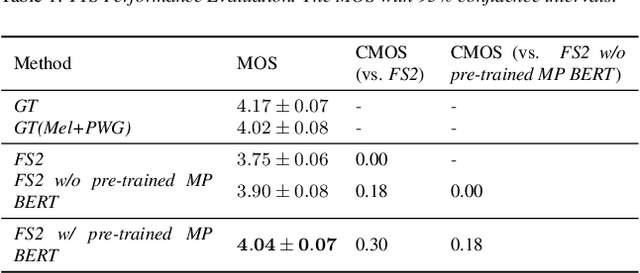

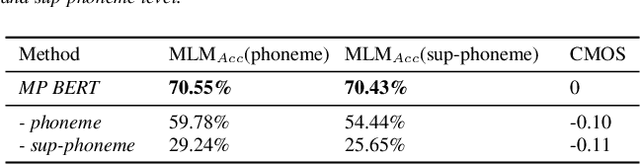
Recently, leveraging BERT pre-training to improve the phoneme encoder in text to speech (TTS) has drawn increasing attention. However, the works apply pre-training with character-based units to enhance the TTS phoneme encoder, which is inconsistent with the TTS fine-tuning that takes phonemes as input. Pre-training only with phonemes as input can alleviate the input mismatch but lack the ability to model rich representations and semantic information due to limited phoneme vocabulary. In this paper, we propose MixedPhoneme BERT, a novel variant of the BERT model that uses mixed phoneme and sup-phoneme representations to enhance the learning capability. Specifically, we merge the adjacent phonemes into sup-phonemes and combine the phoneme sequence and the merged sup-phoneme sequence as the model input, which can enhance the model capacity to learn rich contextual representations. Experiment results demonstrate that our proposed Mixed-Phoneme BERT significantly improves the TTS performance with 0.30 CMOS gain compared with the FastSpeech 2 baseline. The Mixed-Phoneme BERT achieves 3x inference speedup and similar voice quality to the previous TTS pre-trained model PnG BERT
SPNet: A novel deep neural network for retinal vessel segmentation based on shared decoder and pyramid-like loss
Feb 19, 2022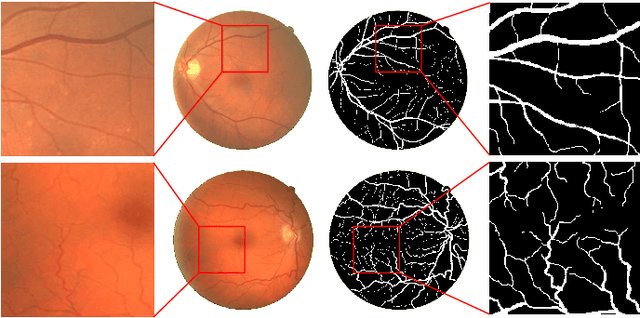
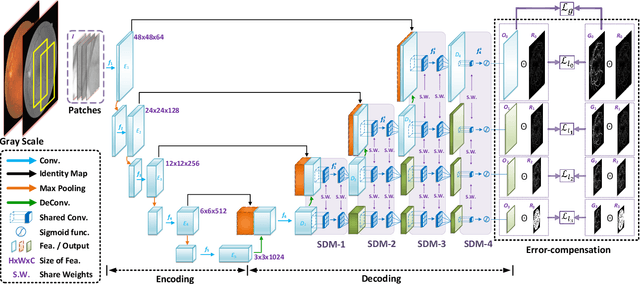
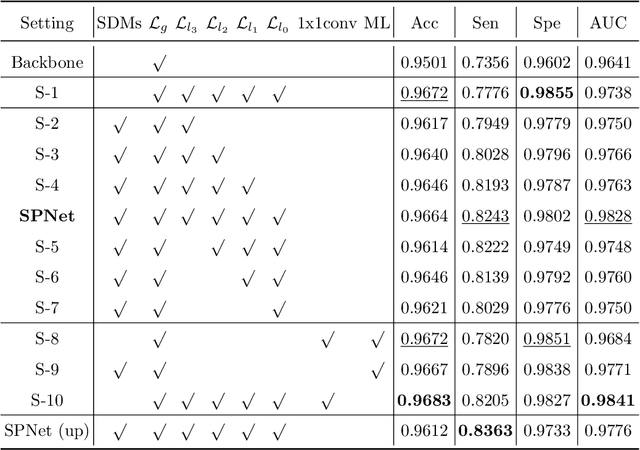
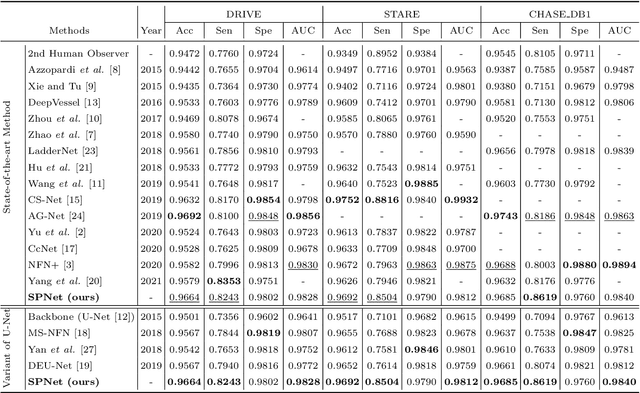
Segmentation of retinal vessel images is critical to the diagnosis of retinopathy. Recently, convolutional neural networks have shown significant ability to extract the blood vessel structure. However, it remains challenging to refined segmentation for the capillaries and the edges of retinal vessels due to thickness inconsistencies and blurry boundaries. In this paper, we propose a novel deep neural network for retinal vessel segmentation based on shared decoder and pyramid-like loss (SPNet) to address the above problems. Specifically, we introduce a decoder-sharing mechanism to capture multi-scale semantic information, where feature maps at diverse scales are decoded through a sequence of weight-sharing decoder modules. Also, to strengthen characterization on the capillaries and the edges of blood vessels, we define a residual pyramid architecture which decomposes the spatial information in the decoding phase. A pyramid-like loss function is designed to compensate possible segmentation errors progressively. Experimental results on public benchmarks show that the proposed method outperforms the backbone network and the state-of-the-art methods, especially in the regions of the capillaries and the vessel contours. In addition, performances on cross-datasets verify that SPNet shows stronger generalization ability.
Contrastive Learning from Demonstrations
Jan 30, 2022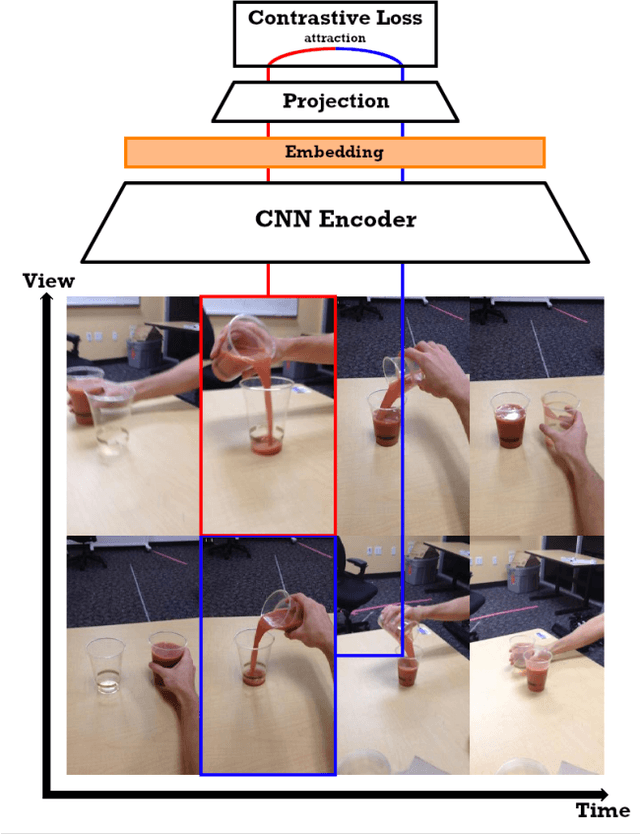
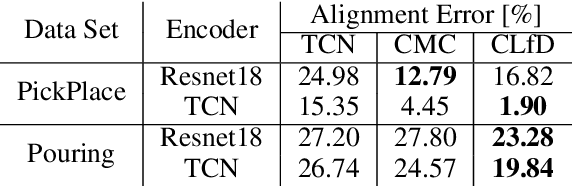

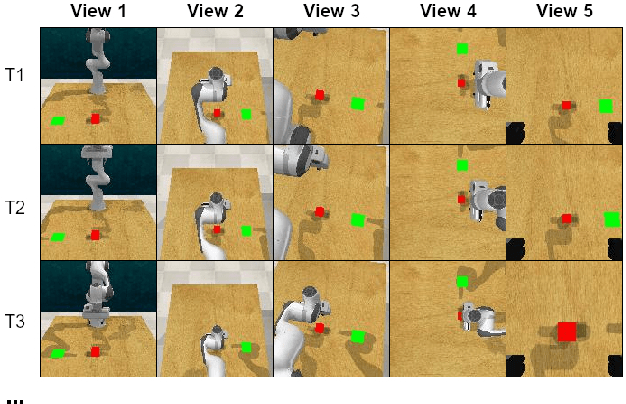
This paper presents a framework for learning visual representations from unlabeled video demonstrations captured from multiple viewpoints. We show that these representations are applicable for imitating several robotic tasks, including pick and place. We optimize a recently proposed self-supervised learning algorithm by applying contrastive learning to enhance task-relevant information while suppressing irrelevant information in the feature embeddings. We validate the proposed method on the publicly available Multi-View Pouring and a custom Pick and Place data sets and compare it with the TCN triplet baseline. We evaluate the learned representations using three metrics: viewpoint alignment, stage classification and reinforcement learning, and in all cases the results improve when compared to state-of-the-art approaches, with the added benefit of reduced number of training iterations.
Certified machine learning: A posteriori error estimation for physics-informed neural networks
Mar 31, 2022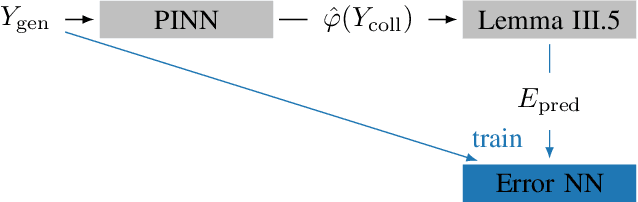
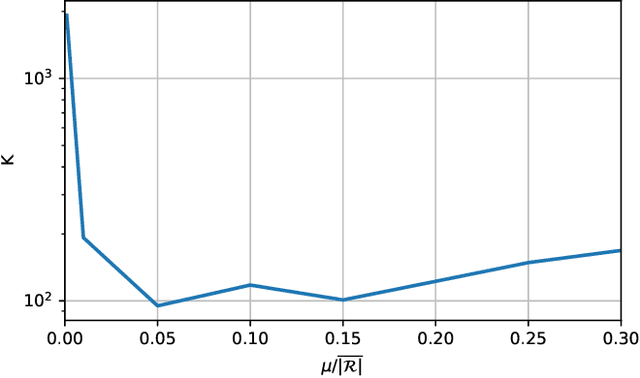
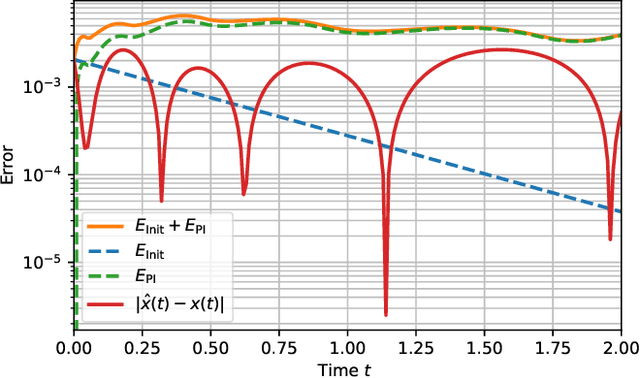
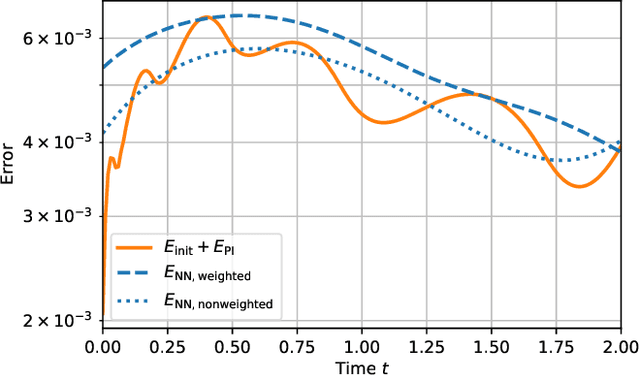
Physics-informed neural networks (PINNs) are one popular approach to introduce a priori knowledge about physical systems into the learning framework. PINNs are known to be robust for smaller training sets, derive better generalization problems, and are faster to train. In this paper, we show that using PINNs in comparison with purely data-driven neural networks is not only favorable for training performance but allows us to extract significant information on the quality of the approximated solution. Assuming that the underlying differential equation for the PINN training is an ordinary differential equation, we derive a rigorous upper limit on the PINN prediction error. This bound is applicable even for input data not included in the training phase and without any prior knowledge about the true solution. Therefore, our a posteriori error estimation is an essential step to certify the PINN. We apply our error estimator exemplarily to two academic toy problems, whereof one falls in the category of model-predictive control and thereby shows the practical use of the derived results.
The Severity Prediction of The Binary And Multi-Class Cardiovascular Disease -- A Machine Learning-Based Fusion Approach
Mar 09, 2022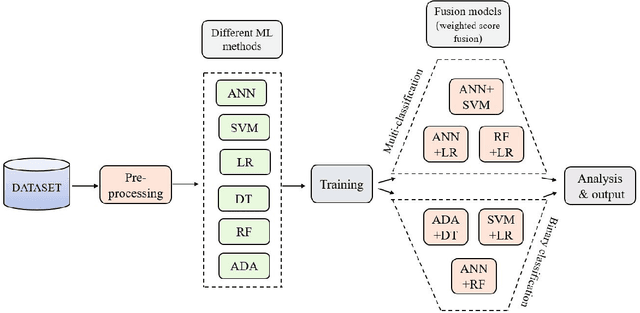
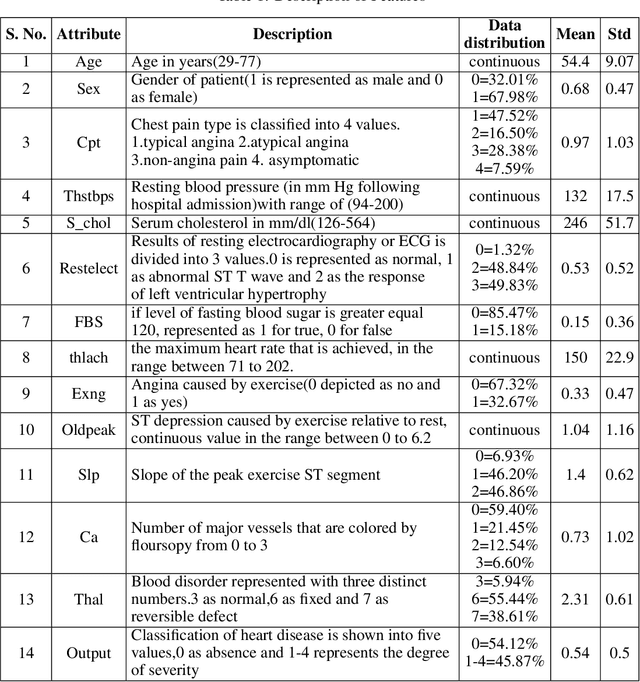
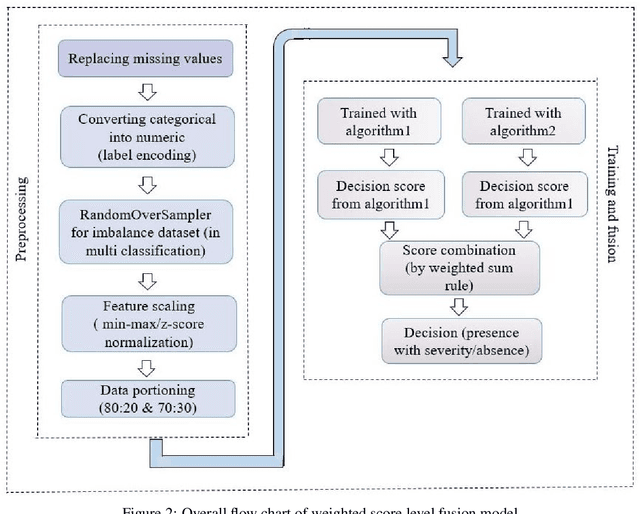
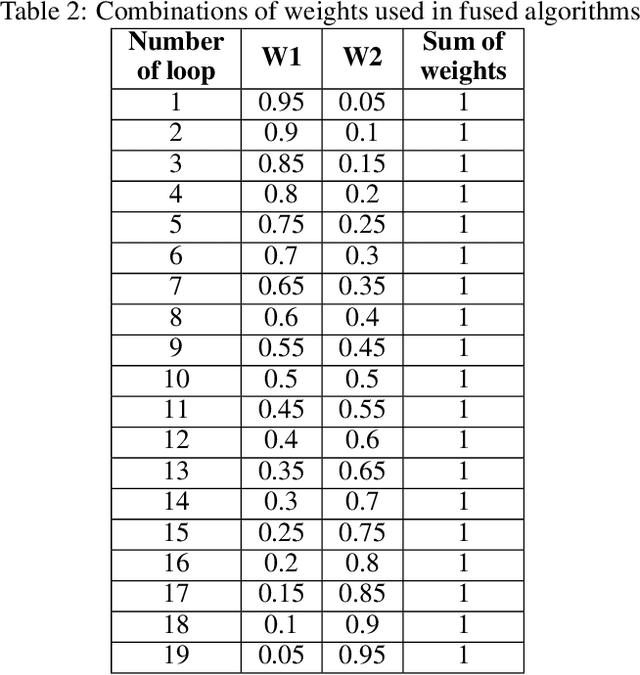
In today's world, a massive amount of data is available in almost every sector. This data has become an asset as we can use this enormous amount of data to find information. Mainly health care industry contains many data consisting of patient and disease-related information. By using the machine learning technique, we can look for hidden data patterns to predict various diseases. Recently CVDs, or cardiovascular disease, have become a leading cause of death around the world. The number of death due to CVDs is frightening. That is why many researchers are trying their best to design a predictive model that can save many lives using the data mining model. In this research, some fusion models have been constructed to diagnose CVDs along with its severity. Machine learning(ML) algorithms like artificial neural network, SVM, logistic regression, decision tree, random forest, and AdaBoost have been applied to the heart disease dataset to predict disease. Randomoversampler was implemented because of the class imbalance in multiclass classification. To improve the performance of classification, a weighted score fusion approach was taken. At first, the models were trained. After training, two algorithms' decision was combined using a weighted sum rule. A total of three fusion models have been developed from the six ML algorithms. The results were promising in the performance parameter. The proposed approach has been experimented with different test training ratios for binary and multiclass classification problems, and for both of them, the fusion models performed well. The highest accuracy for multiclass classification was found as 75%, and it was 95% for binary. The code can be found in : https://github.com/hafsa-kibria/Weighted_score_fusion_model_heart_disease_prediction