 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Noisy Boundaries: Lemon or Lemonade for Semi-supervised Instance Segmentation?
Mar 25, 2022
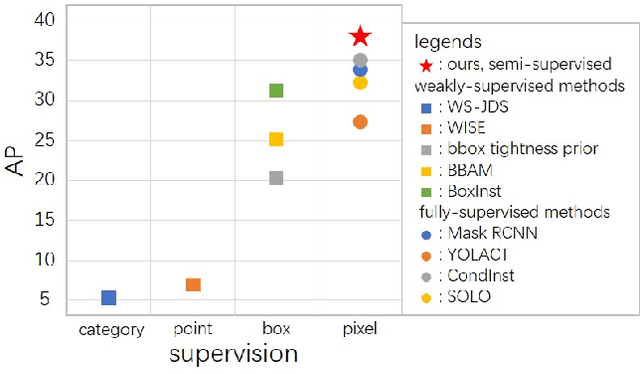
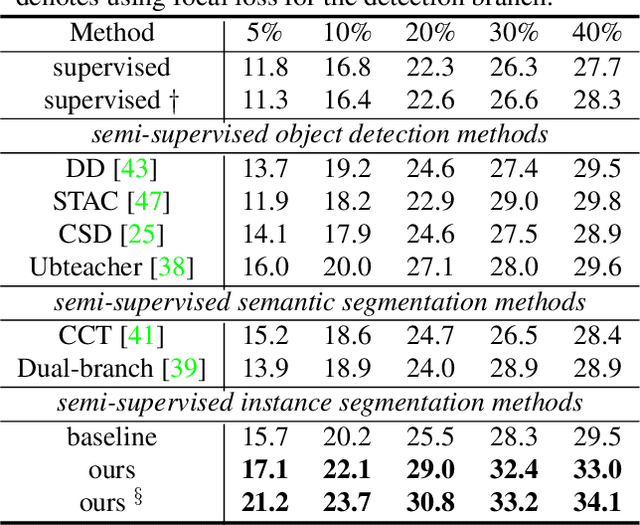
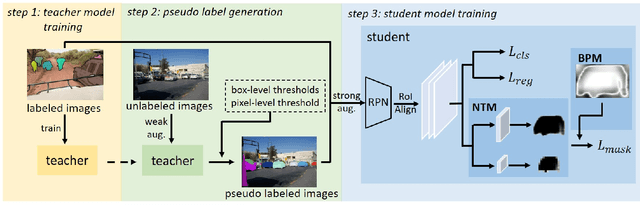
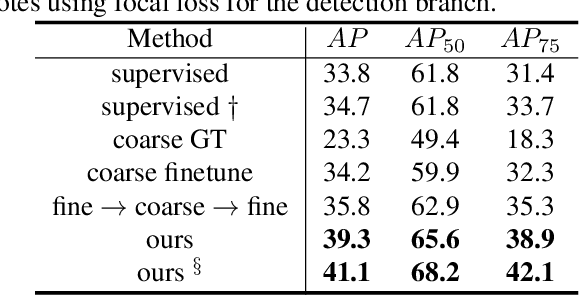
Current instance segmentation methods rely heavily on pixel-level annotated images. The huge cost to obtain such fully-annotated images restricts the dataset scale and limits the performance. In this paper, we formally address semi-supervised instance segmentation, where unlabeled images are employed to boost the performance. We construct a framework for semi-supervised instance segmentation by assigning pixel-level pseudo labels. Under this framework, we point out that noisy boundaries associated with pseudo labels are double-edged. We propose to exploit and resist them in a unified manner simultaneously: 1) To combat the negative effects of noisy boundaries, we propose a noise-tolerant mask head by leveraging low-resolution features. 2) To enhance the positive impacts, we introduce a boundary-preserving map for learning detailed information within boundary-relevant regions. We evaluate our approach by extensive experiments. It behaves extraordinarily, outperforming the supervised baseline by a large margin, more than 6% on Cityscapes, 7% on COCO and 4.5% on BDD100k. On Cityscapes, our method achieves comparable performance by utilizing only 30% labeled images.
Dealing with Sparse Rewards Using Graph Neural Networks
Mar 25, 2022

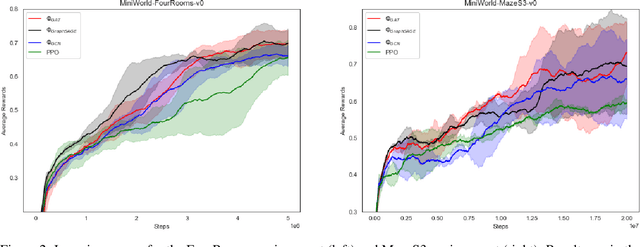
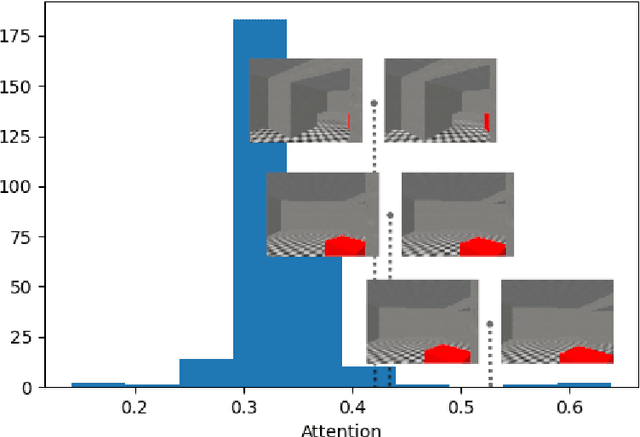
Deep reinforcement learning in partially observable environments is a difficult task in itself, and can be further complicated by a sparse reward signal. Most tasks involving navigation in three-dimensional environments provide the agent with extremely limited information. Typically, the agent receives a visual observation input from the environment and is rewarded once at the end of the episode. A good reward function could substantially improve the convergence of reinforcement learning algorithms for such tasks. The classic approach to increase the density of the reward signal is to augment it with supplementary rewards. This technique is called the reward shaping. In this study, we propose two modifications of one of the recent reward shaping methods based on graph convolutional networks: the first involving advanced aggregation functions, and the second utilizing the attention mechanism. We empirically validate the effectiveness of our solutions for the task of navigation in a 3D environment with sparse rewards. For the solution featuring attention mechanism, we are also able to show that the learned attention is concentrated on edges corresponding to important transitions in 3D environment.
DISCO: Comprehensive and Explainable Disinformation Detection
Mar 09, 2022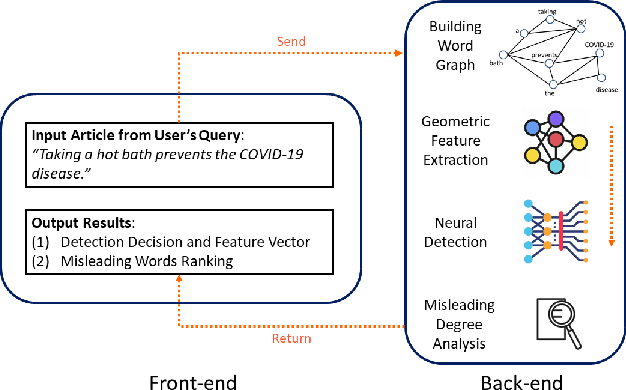

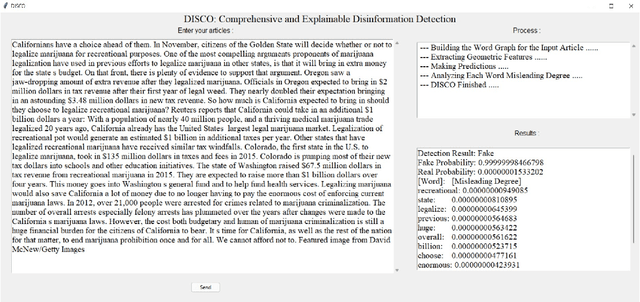
Disinformation refers to false information deliberately spread to influence the general public, and the negative impact of disinformation on society can be observed for numerous issues, such as political agendas and manipulating financial markets. In this paper, we identify prevalent challenges and advances related to automated disinformation detection from multiple aspects, and propose a comprehensive and explainable disinformation detection framework called DISCO. It leverages the heterogeneity of disinformation and addresses the prediction opaqueness. Then we provide a demonstration of DISCO on a real-world fake news detection task with satisfactory detection accuracy and explanation. The demo video and source code of DISCO is now publicly available. We expect that our demo could pave the way for addressing the limitations of identification, comprehension, and explainability as a whole.
Collapse by Conditioning: Training Class-conditional GANs with Limited Data
Jan 17, 2022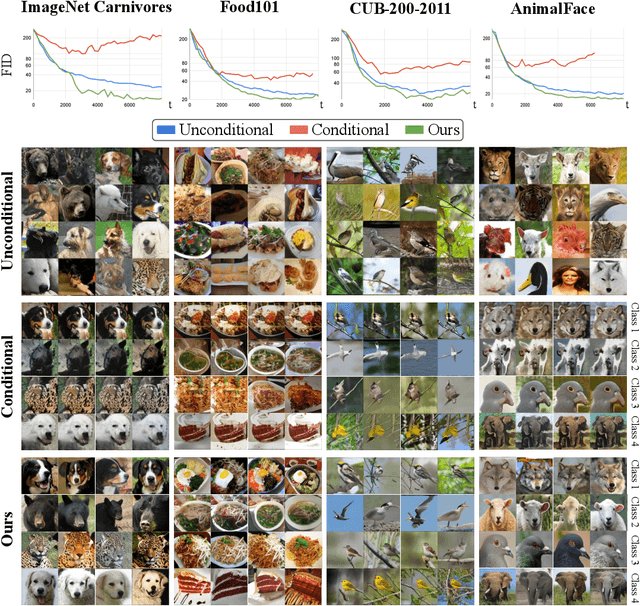
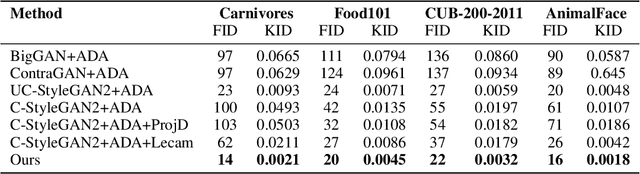

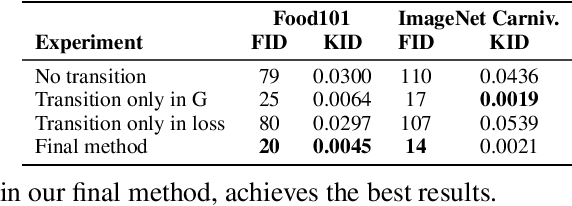
Class-conditioning offers a direct means of controlling a Generative Adversarial Network (GAN) based on a discrete input variable. While necessary in many applications, the additional information provided by the class labels could even be expected to benefit the training of the GAN itself. Contrary to this belief, we observe that class-conditioning causes mode collapse in limited data settings, where unconditional learning leads to satisfactory generative ability. Motivated by this observation, we propose a training strategy for conditional GANs (cGANs) that effectively prevents the observed mode-collapse by leveraging unconditional learning. Our training strategy starts with an unconditional GAN and gradually injects conditional information into the generator and the objective function. The proposed method for training cGANs with limited data results not only in stable training but also in generating high-quality images, thanks to the early-stage exploitation of the shared information across classes. We analyze the aforementioned mode collapse problem in comprehensive experiments on four datasets. Our approach demonstrates outstanding results compared with state-of-the-art methods and established baselines. The code is available at: https://github.com/mshahbazi72/transitional-cGAN
Unsupervised Alignment of Distributional Word Embeddings
Mar 09, 2022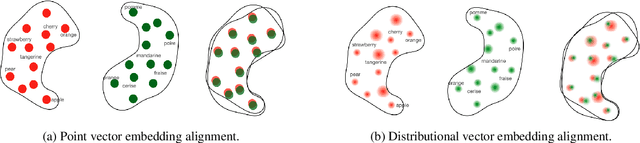
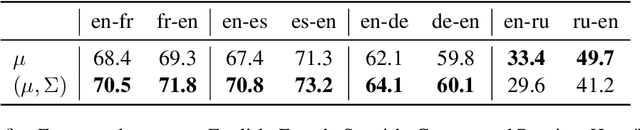
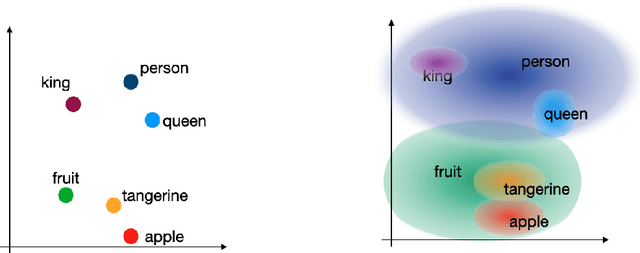
Cross-domain alignment play a key roles in tasks ranging from machine translation to transfer learning. Recently, purely unsupervised methods operating on monolingual embeddings have successfully been used to infer a bilingual lexicon without relying on supervision. However, current state-of-the art methods only focus on point vectors although distributional embeddings have proven to embed richer semantic information when representing words. In this paper, we propose stochastic optimization approach for aligning probabilistic embeddings. Finally, we evaluate our method on the problem of unsupervised word translation, by aligning word embeddings trained on monolingual data. We show that the proposed approach achieves good performance on the bilingual lexicon induction task across several language pairs and performs better than the point-vector based approach.
Enhance Topics Analysis based on Keywords Properties
Mar 09, 2022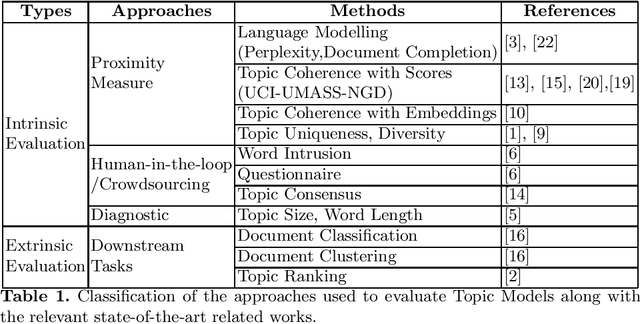
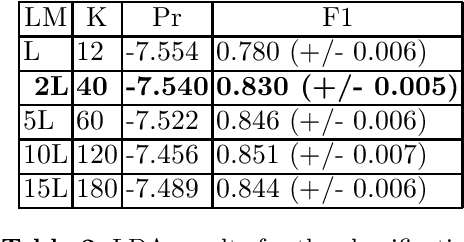
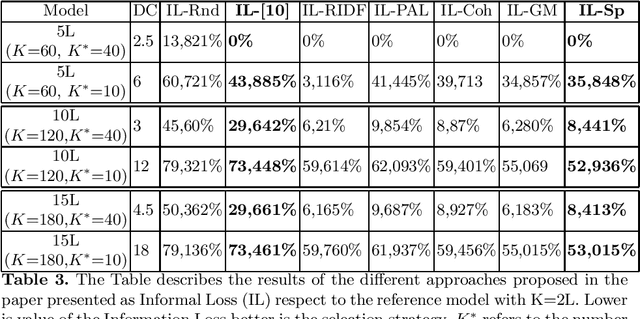
Topic Modelling is one of the most prevalent text analysis technique used to explore and retrieve collection of documents. The evaluation of the topic model algorithms is still a very challenging tasks due to the absence of gold-standard list of topics to compare against for every corpus. In this work, we present a specificity score based on keywords properties that is able to select the most informative topics. This approach helps the user to focus on the most informative topics. In the experiments, we show that we are able to compress the state-of-the-art topic modelling results of different factors with an information loss that is much lower than the solution based on the recent coherence score presented in literature.
NeuraGen-A Low-Resource Neural Network based approach for Gender Classification
Mar 29, 2022
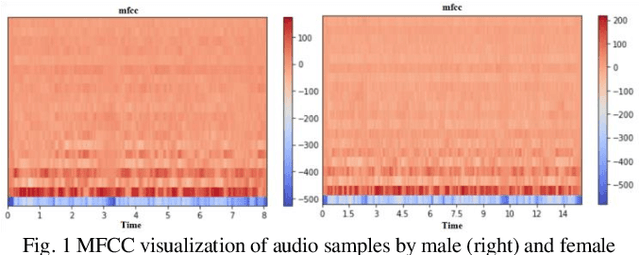
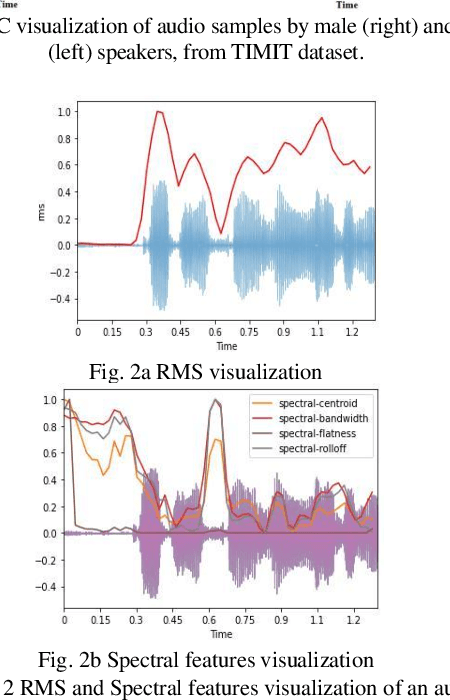
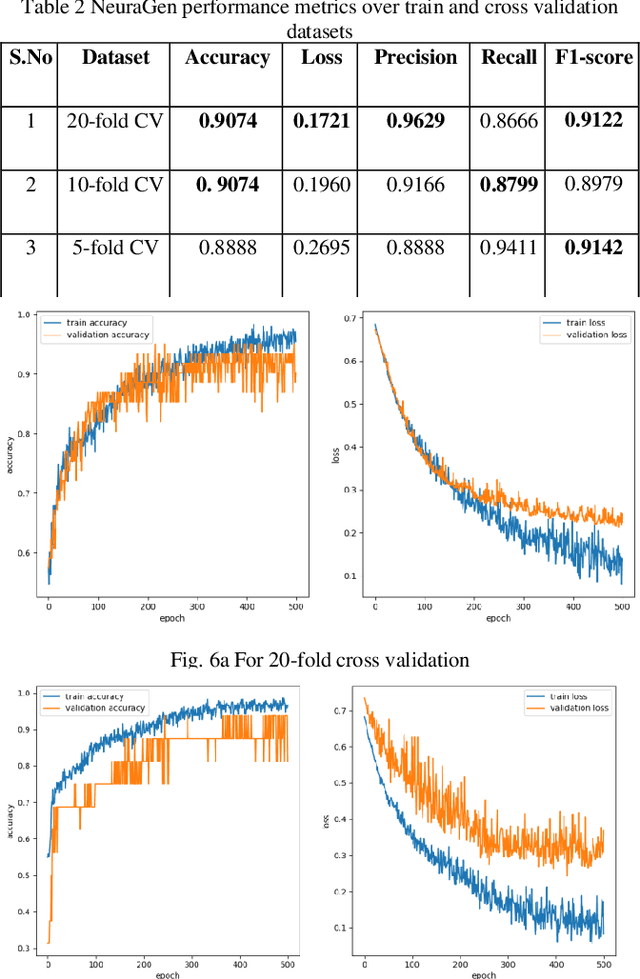
Human voice is the source of several important information. This is in the form of features. These Features help in interpreting various features associated with the speaker and speech. The speaker dependent work researchersare targeted towards speaker identification, Speaker verification, speaker biometric, forensics using feature, and cross-modal matching via speech and face images. In such context research, it is a very difficult task to come across clean, and well annotated publicly available speech corpus as data set. Acquiring volunteers to generate such dataset is also very expensive, not to mention the enormous amount of effort and time researchers spend to gather such data. The present paper work, a Neural Network proposal as NeuraGen focused which is a low-resource ANN architecture. The proposed tool used to classify gender of the speaker from the speech recordings. We have used speech recordings collected from the ELSDSR and limited TIMIT datasets, from which we extracted 8 speech features, which were pre-processed and then fed into NeuraGen to identify the gender. NeuraGen has successfully achieved accuracy of 90.7407% and F1 score of 91.227% in train and 20-fold cross validation dataset.
Self-supervised Speaker Recognition Training Using Human-Machine Dialogues
Feb 07, 2022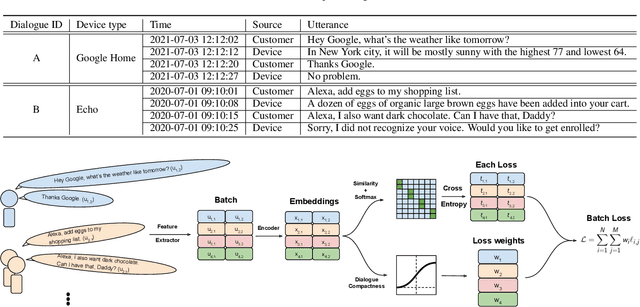
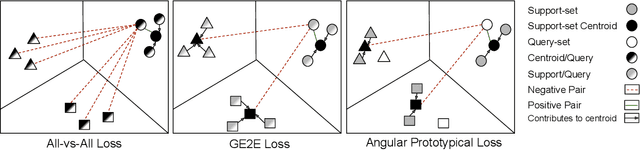
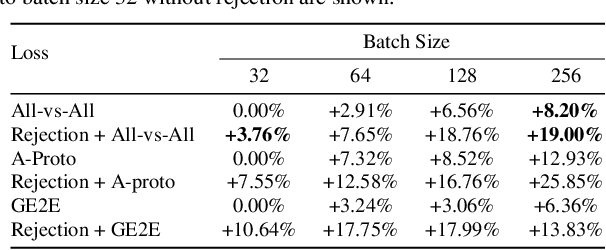
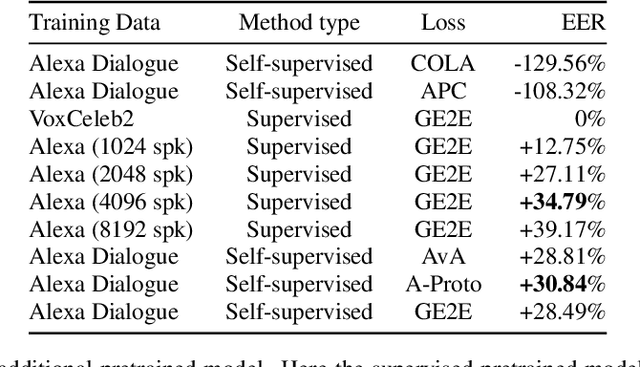
Speaker recognition, recognizing speaker identities based on voice alone, enables important downstream applications, such as personalization and authentication. Learning speaker representations, in the context of supervised learning, heavily depends on both clean and sufficient labeled data, which is always difficult to acquire. Noisy unlabeled data, on the other hand, also provides valuable information that can be exploited using self-supervised training methods. In this work, we investigate how to pretrain speaker recognition models by leveraging dialogues between customers and smart-speaker devices. However, the supervisory information in such dialogues is inherently noisy, as multiple speakers may speak to a device in the course of the same dialogue. To address this issue, we propose an effective rejection mechanism that selectively learns from dialogues based on their acoustic homogeneity. Both reconstruction-based and contrastive-learning-based self-supervised methods are compared. Experiments demonstrate that the proposed method provides significant performance improvements, superior to earlier work. Dialogue pretraining when combined with the rejection mechanism yields 27.10% equal error rate (EER) reduction in speaker recognition, compared to a model without self-supervised pretraining.
Homography Loss for Monocular 3D Object Detection
Apr 02, 2022
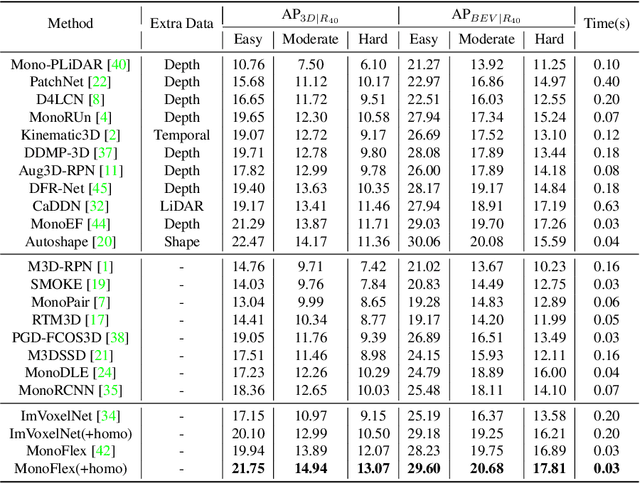
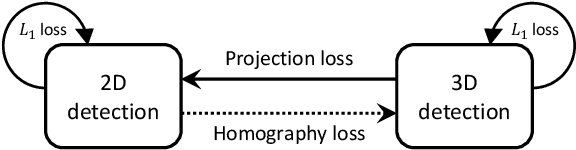
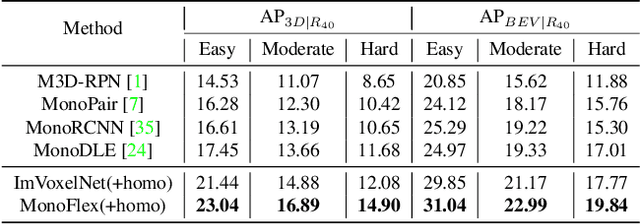
Monocular 3D object detection is an essential task in autonomous driving. However, most current methods consider each 3D object in the scene as an independent training sample, while ignoring their inherent geometric relations, thus inevitably resulting in a lack of leveraging spatial constraints. In this paper, we propose a novel method that takes all the objects into consideration and explores their mutual relationships to help better estimate the 3D boxes. Moreover, since 2D detection is more reliable currently, we also investigate how to use the detected 2D boxes as guidance to globally constrain the optimization of the corresponding predicted 3D boxes. To this end, a differentiable loss function, termed as Homography Loss, is proposed to achieve the goal, which exploits both 2D and 3D information, aiming at balancing the positional relationships between different objects by global constraints, so as to obtain more accurately predicted 3D boxes. Thanks to the concise design, our loss function is universal and can be plugged into any mature monocular 3D detector, while significantly boosting the performance over their baseline. Experiments demonstrate that our method yields the best performance (Nov. 2021) compared with the other state-of-the-arts by a large margin on KITTI 3D datasets.
Pop-Out Motion: 3D-Aware Image Deformation via Learning the Shape Laplacian
Mar 29, 2022We propose a framework that can deform an object in a 2D image as it exists in 3D space. Most existing methods for 3D-aware image manipulation are limited to (1) only changing the global scene information or depth, or (2) manipulating an object of specific categories. In this paper, we present a 3D-aware image deformation method with minimal restrictions on shape category and deformation type. While our framework leverages 2D-to-3D reconstruction, we argue that reconstruction is not sufficient for realistic deformations due to the vulnerability to topological errors. Thus, we propose to take a supervised learning-based approach to predict the shape Laplacian of the underlying volume of a 3D reconstruction represented as a point cloud. Given the deformation energy calculated using the predicted shape Laplacian and user-defined deformation handles (e.g., keypoints), we obtain bounded biharmonic weights to model plausible handle-based image deformation. In the experiments, we present our results of deforming 2D character and clothed human images. We also quantitatively show that our approach can produce more accurate deformation weights compared to alternative methods (i.e., mesh reconstruction and point cloud Laplacian methods).