 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FS-COCO: Towards Understanding of Freehand Sketches of Common Objects in Context
Mar 04, 2022


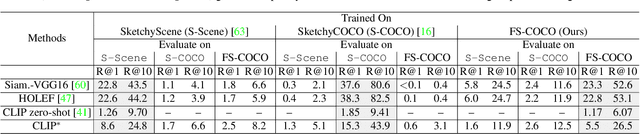
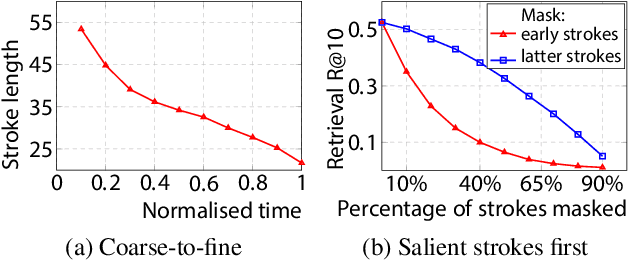
We advance sketch research to scenes with the first dataset of freehand scene sketches, FS-COCO. With practical applications in mind, we collect sketches that convey well scene content but can be sketched within a few minutes by a person with any sketching skills. Our dataset comprises 10,000 freehand scene vector sketches with per point space-time information by 100 non-expert individuals, offering both object- and scene-level abstraction. Each sketch is augmented with its text description. Using our dataset, we study for the first time the problem of the fine-grained image retrieval from freehand scene sketches and sketch captions. We draw insights on (i) Scene salience encoded in sketches with strokes temporal order; (ii) The retrieval performance accuracy from scene sketches against image captions; (iii) Complementarity of information in sketches and image captions, as well as the potential benefit of combining the two modalities. In addition, we propose new solutions enabled by our dataset (i) We adopt meta-learning to show how the retrieval model can be fine-tuned to a new user style given just a small set of sketches, (ii) We extend a popular vector sketch LSTM-based encoder to handle sketches with larger complexity than was supported by previous work. Namely, we propose a hierarchical sketch decoder, which we leverage at a sketch-specific "pretext" task. Our dataset enables for the first time research on freehand scene sketch understanding and its practical applications.
Universal Segmentation of 33 Anatomies
Mar 04, 2022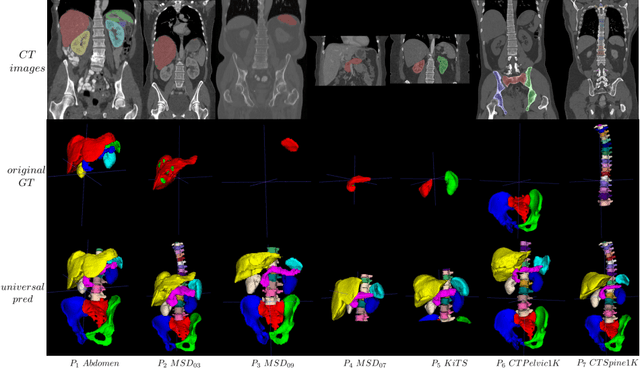
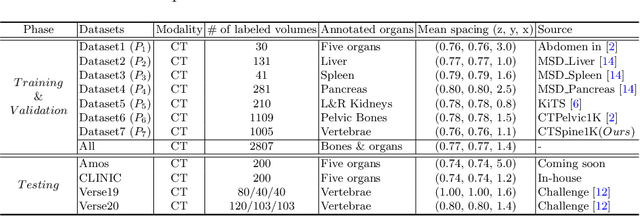
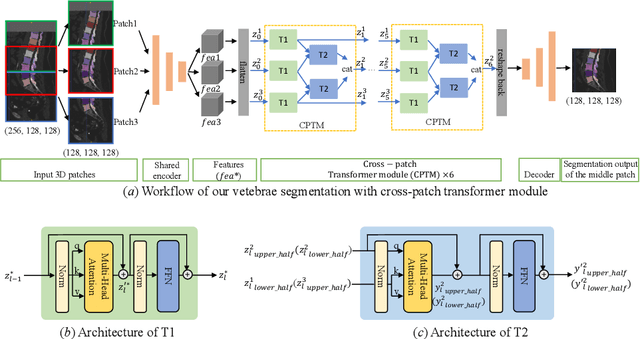
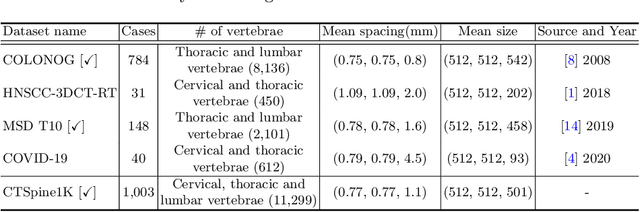
In the paper, we present an approach for learning a single model that universally segments 33 anatomical structures, including vertebrae, pelvic bones, and abdominal organs. Our model building has to address the following challenges. Firstly, while it is ideal to learn such a model from a large-scale, fully-annotated dataset, it is practically hard to curate such a dataset. Thus, we resort to learn from a union of multiple datasets, with each dataset containing the images that are partially labeled. Secondly, along the line of partial labelling, we contribute an open-source, large-scale vertebra segmentation dataset for the benefit of spine analysis community, CTSpine1K, boasting over 1,000 3D volumes and over 11K annotated vertebrae. Thirdly, in a 3D medical image segmentation task, due to the limitation of GPU memory, we always train a model using cropped patches as inputs instead a whole 3D volume, which limits the amount of contextual information to be learned. To this, we propose a cross-patch transformer module to fuse more information in adjacent patches, which enlarges the aggregated receptive field for improved segmentation performance. This is especially important for segmenting, say, the elongated spine. Based on 7 partially labeled datasets that collectively contain about 2,800 3D volumes, we successfully learn such a universal model. Finally, we evaluate the universal model on multiple open-source datasets, proving that our model has a good generalization performance and can potentially serve as a solid foundation for downstream tasks.
Multi-Modal Attribute Extraction for E-Commerce
Mar 07, 2022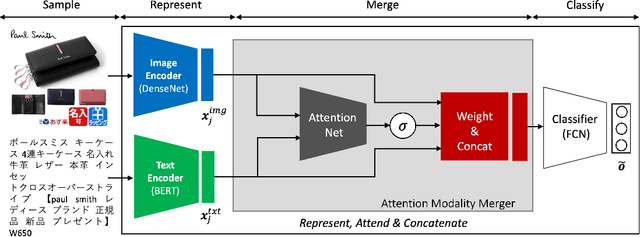
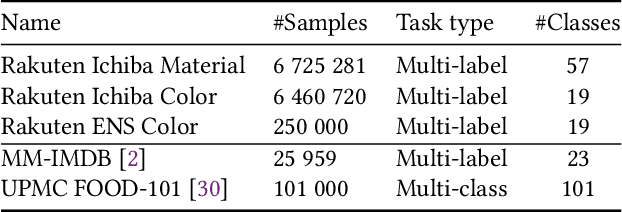

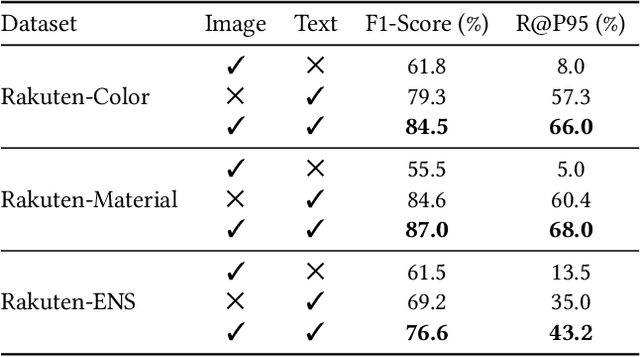
To improve users' experience as they navigate the myriad of options offered by online marketplaces, it is essential to have well-organized product catalogs. One key ingredient to that is the availability of product attributes such as color or material. However, on some marketplaces such as Rakuten-Ichiba, which we focus on, attribute information is often incomplete or even missing. One promising solution to this problem is to rely on deep models pre-trained on large corpora to predict attributes from unstructured data, such as product descriptive texts and images (referred to as modalities in this paper). However, we find that achieving satisfactory performance with this approach is not straightforward but rather the result of several refinements, which we discuss in this paper. We provide a detailed description of our approach to attribute extraction, from investigating strong single-modality methods, to building a solid multimodal model combining textual and visual information. One key component of our multimodal architecture is a novel approach to seamlessly combine modalities, which is inspired by our single-modality investigations. In practice, we notice that this new modality-merging method may suffer from a modality collapse issue, i.e., it neglects one modality. Hence, we further propose a mitigation to this problem based on a principled regularization scheme. Experiments on Rakuten-Ichiba data provide empirical evidence for the benefits of our approach, which has been also successfully deployed to Rakuten-Ichiba. We also report results on publicly available datasets showing that our model is competitive compared to several recent multimodal and unimodal baselines.
Bayesian community detection for networks with covariates
Mar 04, 2022


The increasing prevalence of network data in a vast variety of fields and the need to extract useful information out of them have spurred fast developments in related models and algorithms. Among the various learning tasks with network data, community detection, the discovery of node clusters or "communities," has arguably received the most attention in the scientific community. In many real-world applications, the network data often come with additional information in the form of node or edge covariates that should ideally be leveraged for inference. In this paper, we add to a limited literature on community detection for networks with covariates by proposing a Bayesian stochastic block model with a covariate-dependent random partition prior. Under our prior, the covariates are explicitly expressed in specifying the prior distribution on the cluster membership. Our model has the flexibility of modeling uncertainties of all the parameter estimates including the community membership. Importantly, and unlike the majority of existing methods, our model has the ability to learn the number of the communities via posterior inference without having to assume it to be known. Our model can be applied to community detection in both dense and sparse networks, with both categorical and continuous covariates, and our MCMC algorithm is very efficient with good mixing properties. We demonstrate the superior performance of our model over existing models in a comprehensive simulation study and an application to two real datasets.
Cross-View-Prediction: Exploring Contrastive Feature for Hyperspectral Image Classification
Mar 14, 2022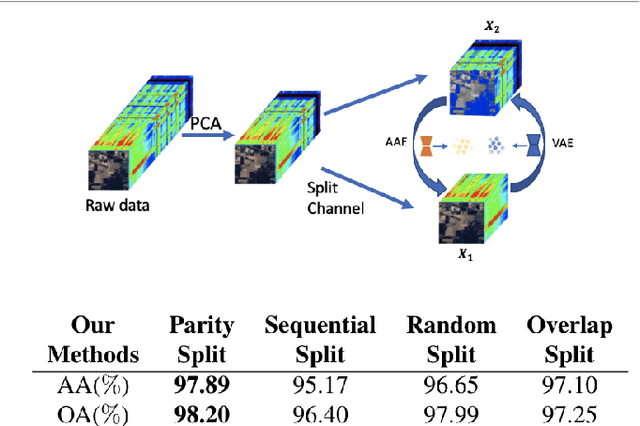

This paper presents a self-supervised feature learning method for hyperspectral image classification. Our method tries to construct two different views of the raw hyperspectral image through a cross-representation learning method. And then to learn semantically consistent representation over the created views by contrastive learning method. Specifically, four cross-channel-prediction based augmentation methods are naturally designed to utilize the high dimension characteristic of hyperspectral data for the view construction. And the better representative features are learned by maximizing mutual information and minimizing conditional entropy across different views from our contrastive network. This 'Cross-View-Predicton' style is straightforward and gets the state-of-the-art performance of unsupervised classification with a simple SVM classifier.
XAutoML: A Visual Analytics Tool for Establishing Trust in Automated Machine Learning
Feb 24, 2022
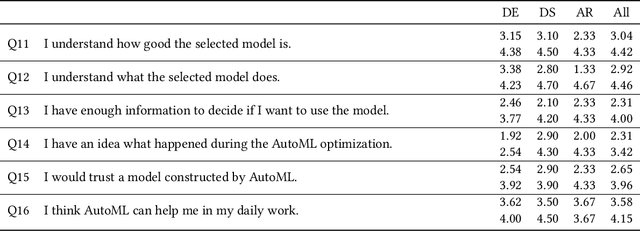
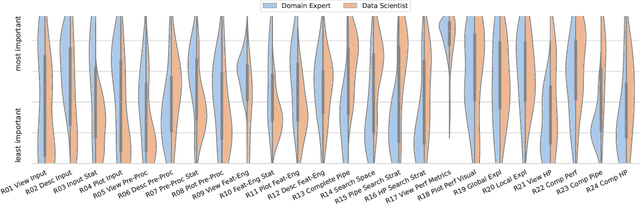

In the last ten years, various automated machine learning (AutoML) systems have been proposed to build end-to-end machine learning (ML) pipelines with minimal human interaction. Even though such automatically synthesized ML pipelines are able to achieve a competitive performance, recent studies have shown that users do not trust models constructed by AutoML due to missing transparency of AutoML systems and missing explanations for the constructed ML pipelines. In a requirements analysis study with 26 domain experts, data scientists, and AutoML researchers from different professions with vastly different expertise in ML, we collect detailed informational needs to establish trust in AutoML. We propose XAutoML, an interactive visual analytics tool for explaining arbitrary AutoML optimization procedures and ML pipelines constructed by AutoML. XAutoML combines interactive visualizations with established techniques from explainable artificial intelligence (XAI) to make the complete AutoML procedure transparent and explainable. By integrating XAutoML with JupyterLab, experienced users can extend the visual analytics with ad-hoc visualizations based on information extracted from XAutoML. We validate our approach in a user study with the same diverse user group from the requirements analysis. All participants were able to extract useful information from XAutoML, leading to a significantly increased trust in ML pipelines produced by AutoML and the AutoML optimization itself.
The Galactic 3D large-scale dust distribution via Gaussian process regression on spherical coordinates
Apr 25, 2022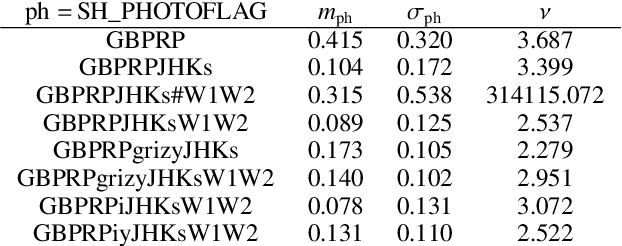
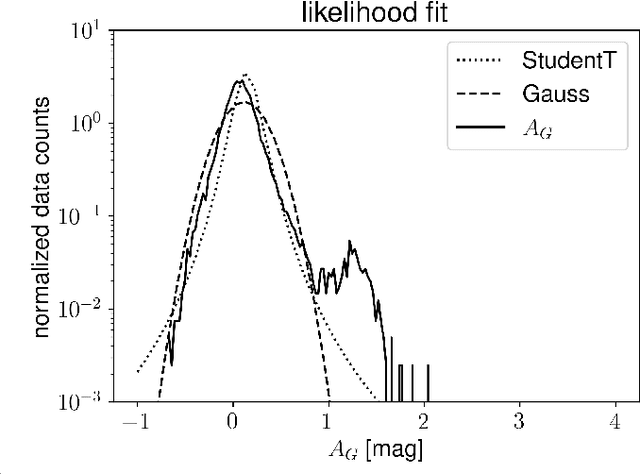
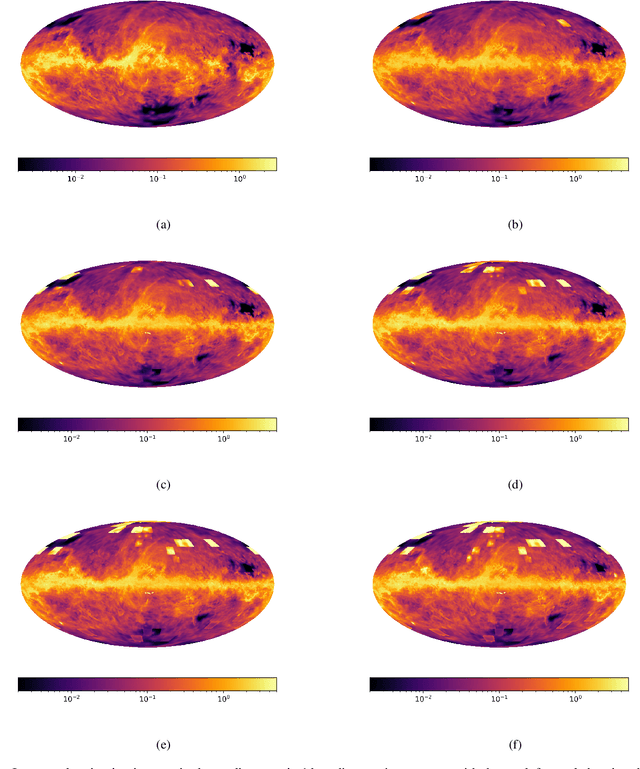
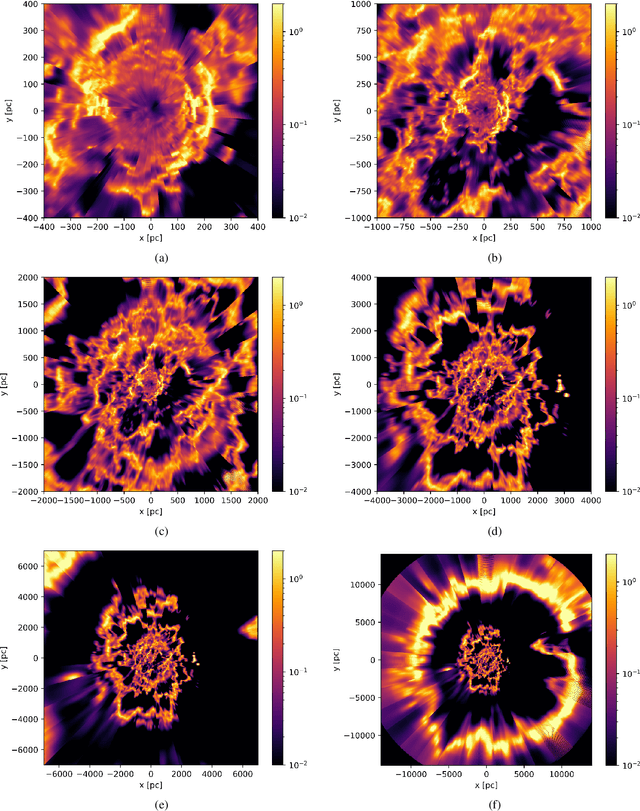
Knowing the Galactic 3D dust distribution is relevant for understanding many processes in the interstellar medium and for correcting many astronomical observations for dust absorption and emission. Here, we aim for a 3D reconstruction of the Galactic dust distribution with an increase in the number of meaningful resolution elements by orders of magnitude with respect to previous reconstructions, while taking advantage of the dust's spatial correlations to inform the dust map. We use iterative grid refinement to define a log-normal process in spherical coordinates. This log-normal process assumes a fixed correlation structure, which was inferred in an earlier reconstruction of Galactic dust. Our map is informed through 111 Million data points, combining data of PANSTARRS, 2MASS, Gaia DR2 and ALLWISE. The log-normal process is discretized to 122 Billion degrees of freedom, a factor of 400 more than our previous map. We derive the most probable posterior map and an uncertainty estimate using natural gradient descent and the Fisher-Laplace approximation. The dust reconstruction covers a quarter of the volume of our Galaxy, with a maximum coordinate distance of $16\,\text{kpc}$, and meaningful information can be found up to at distances of $4\,$kpc, still improving upon our earlier map by a factor of 5 in maximal distance, of $900$ in volume, and of about eighteen in angular grid resolution. Unfortunately, the maximum posterior approach chosen to make the reconstruction computational affordable introduces artifacts and reduces the accuracy of our uncertainty estimate. Despite of the apparent limitations of the presented 3D dust map, a good part of the reconstructed structures are confirmed by independent maser observations. Thus, the map is a step towards reliable 3D Galactic cartography and already can serve for a number of tasks, if used with care.
User-Level Differential Privacy against Attribute Inference Attack of Speech Emotion Recognition in Federated Learning
Apr 05, 2022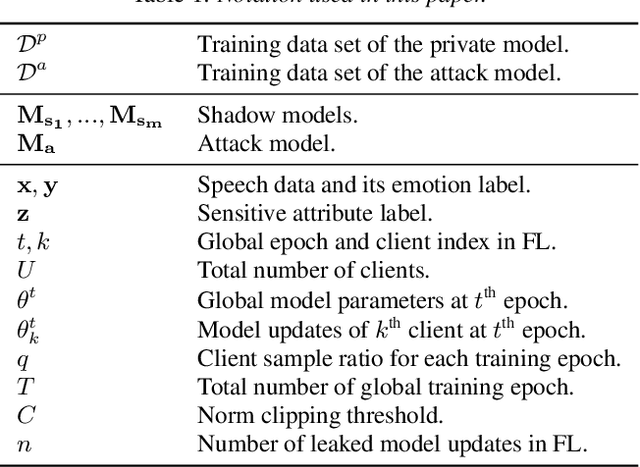
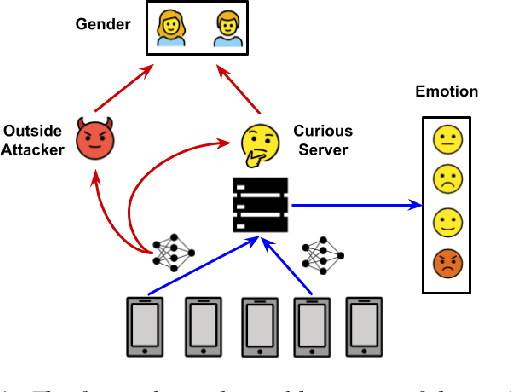
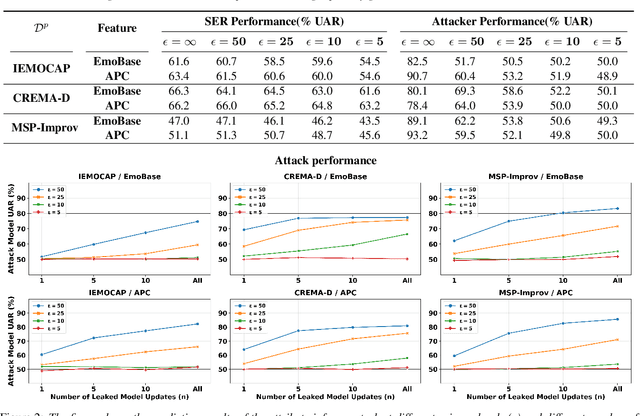
Many existing privacy-enhanced speech emotion recognition (SER) frameworks focus on perturbing the original speech data through adversarial training within a centralized machine learning setup. However, this privacy protection scheme can fail since the adversary can still access the perturbed data. In recent years, distributed learning algorithms, especially federated learning (FL), have gained popularity to protect privacy in machine learning applications. While FL provides good intuition to safeguard privacy by keeping the data on local devices, prior work has shown that privacy attacks, such as attribute inference attacks, are achievable for SER systems trained using FL. In this work, we propose to evaluate the user-level differential privacy (UDP) in mitigating the privacy leaks of the SER system in FL. UDP provides theoretical privacy guarantees with privacy parameters $\epsilon$ and $\delta$. Our results show that the UDP can effectively decrease attribute information leakage while keeping the utility of the SER system with the adversary accessing one model update. However, the efficacy of the UDP suffers when the FL system leaks more model updates to the adversary. We make the code publicly available to reproduce the results in https://github.com/usc-sail/fed-ser-leakage.
Generative Modeling for Low Dimensional Speech Attributes with Neural Spline Flows
Mar 07, 2022
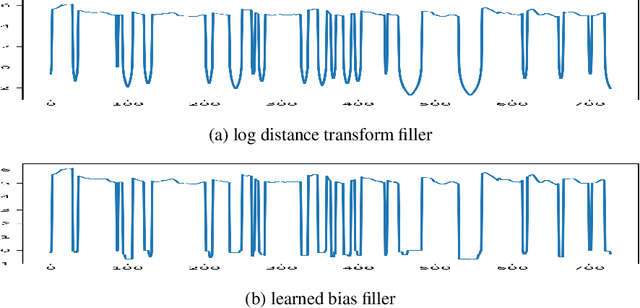
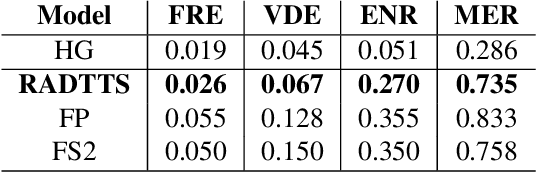
Despite recent advances in generative modeling for text-to-speech synthesis, these models do not yet have the same fine-grained adjustability of pitch-conditioned deterministic models such as FastPitch and FastSpeech2. Pitch information is not only low-dimensional, but also discontinuous, making it particularly difficult to model in a generative setting. Our work explores several techniques for handling the aforementioned issues in the context of Normalizing Flow models. We also find this problem to be very well suited for Neural Spline flows, which is a highly expressive alternative to the more common affine-coupling mechanism in Normalizing Flows.
Unsupervised Learning of Temporal Abstractions with Slot-based Transformers
Mar 25, 2022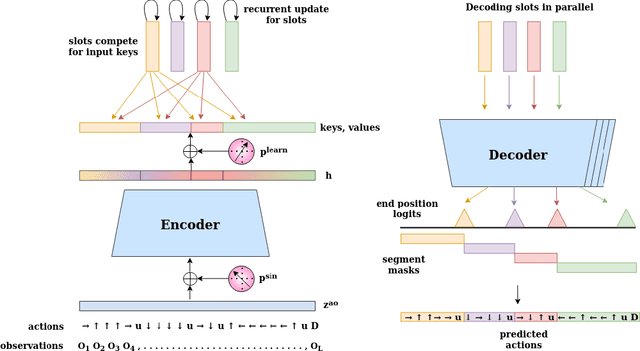
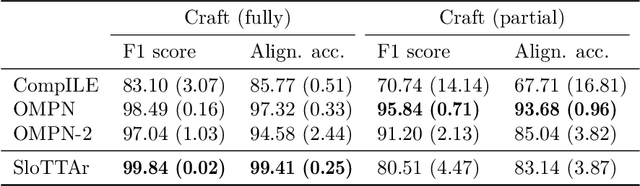
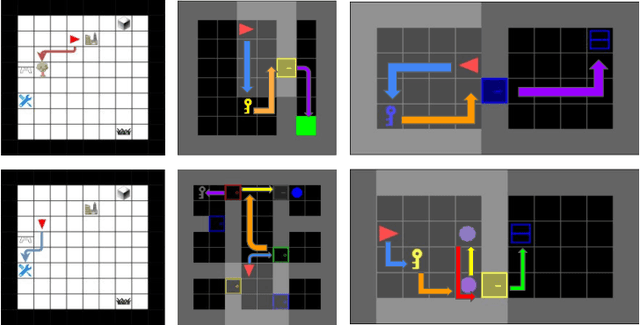
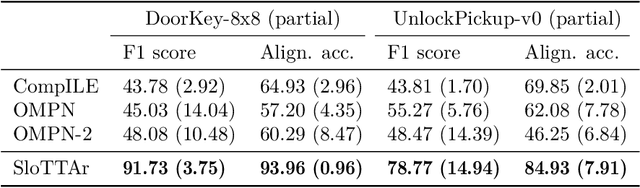
The discovery of reusable sub-routines simplifies decision-making and planning in complex reinforcement learning problems. Previous approaches propose to learn such temporal abstractions in a purely unsupervised fashion through observing state-action trajectories gathered from executing a policy. However, a current limitation is that they process each trajectory in an entirely sequential manner, which prevents them from revising earlier decisions about sub-routine boundary points in light of new incoming information. In this work we propose SloTTAr, a fully parallel approach that integrates sequence processing Transformers with a Slot Attention module and adaptive computation for learning about the number of such sub-routines in an unsupervised fashion. We demonstrate how SloTTAr is capable of outperforming strong baselines in terms of boundary point discovery, even for sequences containing variable amounts of sub-routines, while being up to 7x faster to train on existing benchmarks.