 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Automated Detection of Doxing on Twitter
Feb 02, 2022
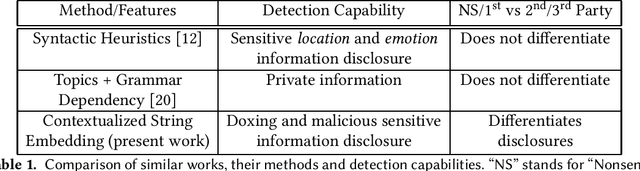
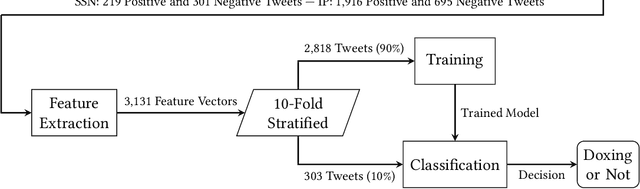
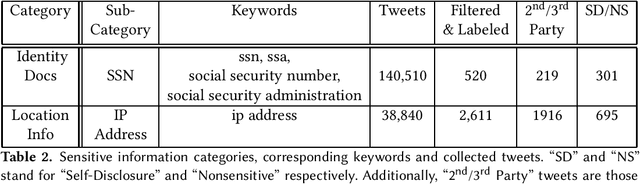
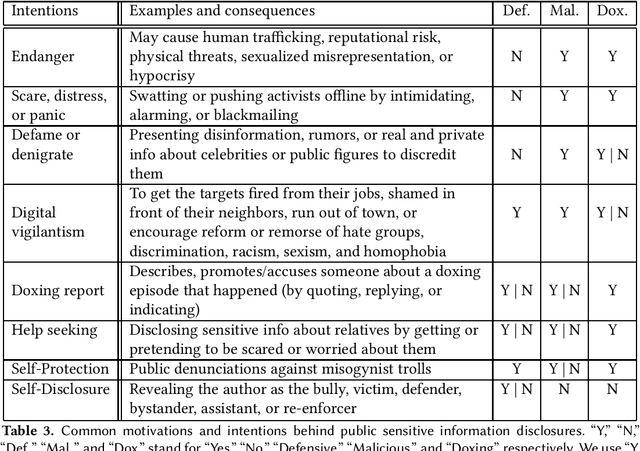
Doxing refers to the practice of disclosing sensitive personal information about a person without their consent. This form of cyberbullying is an unpleasant and sometimes dangerous phenomenon for online social networks. Although prior work exists on automated identification of other types of cyberbullying, a need exists for methods capable of detecting doxing on Twitter specifically. We propose and evaluate a set of approaches for automatically detecting second- and third-party disclosures on Twitter of sensitive private information, a subset of which constitutes doxing. We summarize our findings of common intentions behind doxing episodes and compare nine different approaches for automated detection based on string-matching and one-hot encoded heuristics, as well as word and contextualized string embedding representations of tweets. We identify an approach providing 96.86% accuracy and 97.37% recall using contextualized string embeddings and conclude by discussing the practicality of our proposed methods.
Spectral Unmixing of Hyperspectral Images Based on Block Sparse Structure
Apr 10, 2022

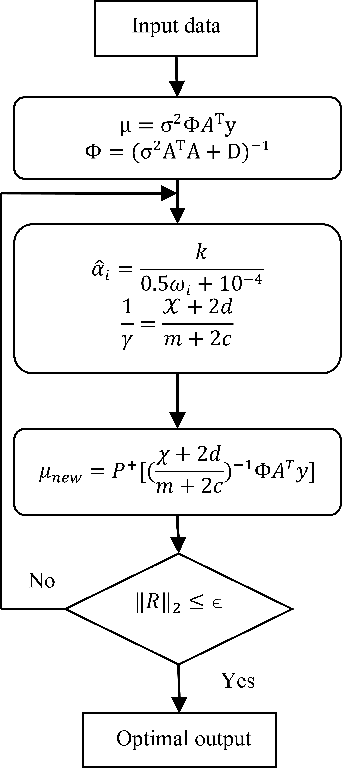
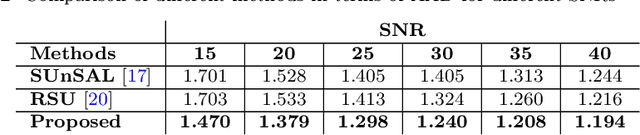
Spectral unmixing (SU) of hyperspectral images (HSIs) is one of the important areas in remote sensing (RS) that needs to be carefully addressed in different RS applications. Despite the high spectral resolution of the hyperspectral data, the relatively low spatial resolution of the sensors may lead to mixture of different pure materials within the image pixels. In this case, the spectrum of a given pixel recorded by the sensor can be a combination of multiple spectra each belonging to a unique material in that pixel. Spectral unmixing is then used as a technique to extract the spectral characteristics of the different materials within the mixed pixels and to recover the spectrum of each pure spectral signature, called endmember. Block-sparsity exists in hyperspectral images as a result of spectral similarity between neighboring pixels. In block-sparse signals, the nonzero samples occur in clusters and the pattern of the clusters is often supposed to be unavailable as prior information. This paper presents an innovative spectral unmixing approach for HSIs based on block-sparse structure and sparse Bayesian learning (SBL) strategy. To evaluate the performance of the proposed SU algorithm, it is tested on both synthetic and real hyperspectral data and the quantitative results are compared to those of other state-of-the-art methods in terms of abundance angel distance (AAD) and mean square error (MSE). The achieved results show the superiority of the proposed algorithm over the other competing methods by a significant margin.
Evolutionary Programmer: Autonomously Creating Path Planning Programs based on Evolutionary Algorithms
Mar 30, 2022
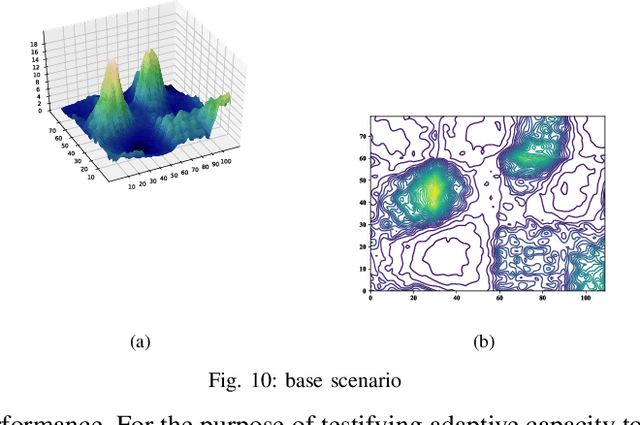
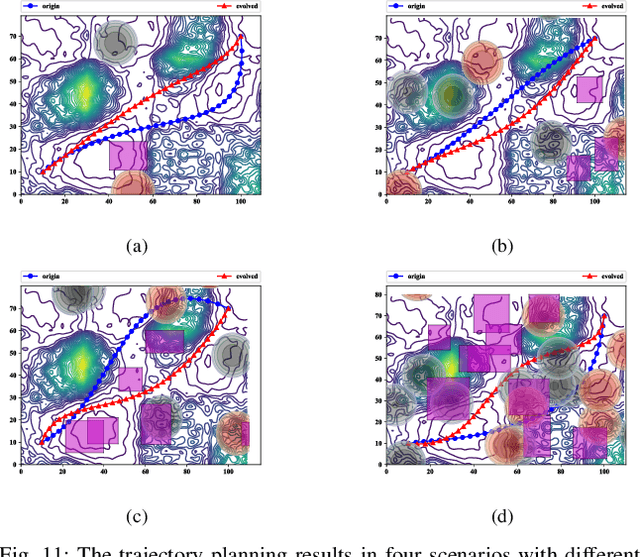
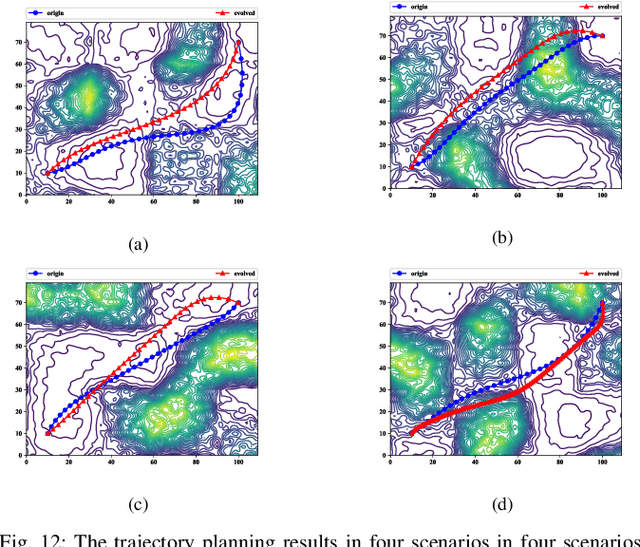
Evolutionary algorithms are wildly used in unmanned aerial vehicle path planning for their flexibility and effectiveness. Nevertheless, they are so sensitive to the change of environment that can't adapt to all scenarios. Due to this drawback, the previously successful planner frequently fail in a new scene. In this paper, a first-of-its-kind machine learning method named Evolutionary Programmer is proposed to solve this problem. Concretely, the most commonly used Evolutionary Algorithms are decomposed into a series of operators, which constitute the operator library of the system. The new method recompose the operators to a integrated planner, thus, the most suitable operators can be selected for adapting to the changing circumstances. Different from normal machine programmers, this method focuses on a specific task with high-level integrated instructions and thus alleviate the problem of huge search space caused by the briefness of instructions. On this basis, a 64-bit sequence is presented to represent path planner and then evolved with the modified Genetic Algorithm. Finally, the most suitable planner is created by utilizing the information of the previous planner and various randomly generated ones.
Graph Convolutional Networks for Multi-modality Medical Imaging: Methods, Architectures, and Clinical Applications
Feb 17, 2022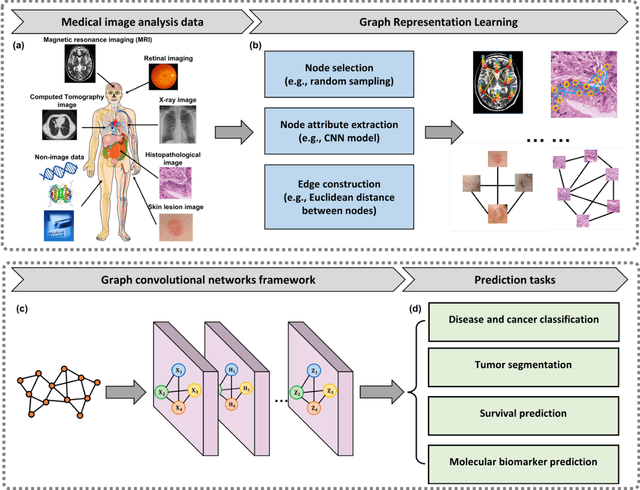

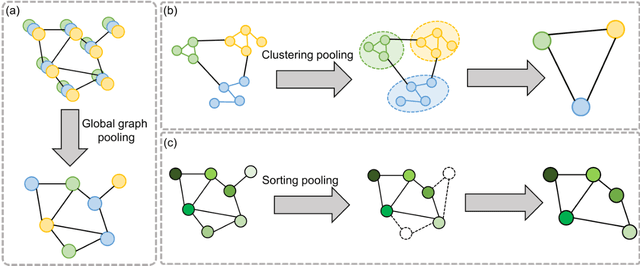
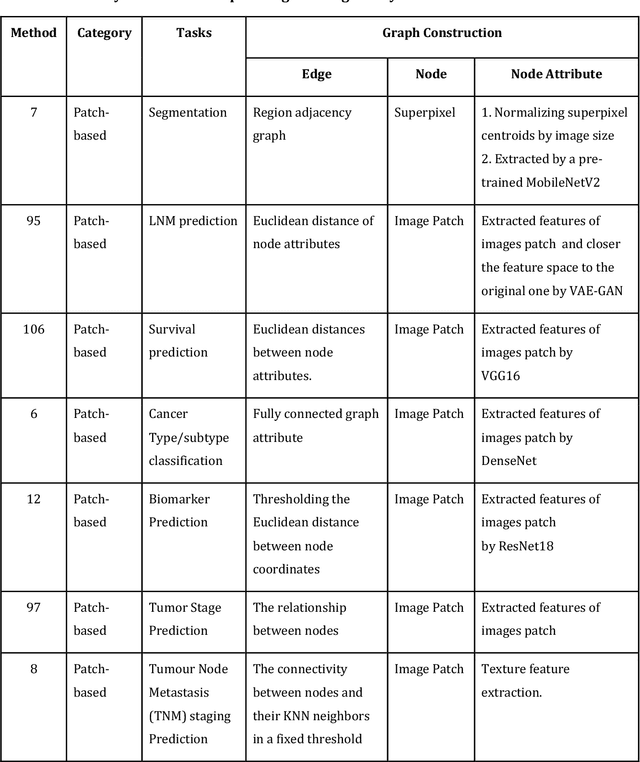
Image-based characterization and disease understanding involve integrative analysis of morphological, spatial, and topological information across biological scales. The development of graph convolutional networks (GCNs) has created the opportunity to address this information complexity via graph-driven architectures, since GCNs can perform feature aggregation, interaction, and reasoning with remarkable flexibility and efficiency. These GCNs capabilities have spawned a new wave of research in medical imaging analysis with the overarching goal of improving quantitative disease understanding, monitoring, and diagnosis. Yet daunting challenges remain for designing the important image-to-graph transformation for multi-modality medical imaging and gaining insights into model interpretation and enhanced clinical decision support. In this review, we present recent GCNs developments in the context of medical image analysis including imaging data from radiology and histopathology. We discuss the fast-growing use of graph network architectures in medical image analysis to improve disease diagnosis and patient outcomes in clinical practice. To foster cross-disciplinary research, we present GCNs technical advancements, emerging medical applications, identify common challenges in the use of image-based GCNs and their extensions in model interpretation, large-scale benchmarks that promise to transform the scope of medical image studies and related graph-driven medical research.
Change Detection from Synthetic Aperture Radar Images via Graph-Based Knowledge Supplement Network
Feb 09, 2022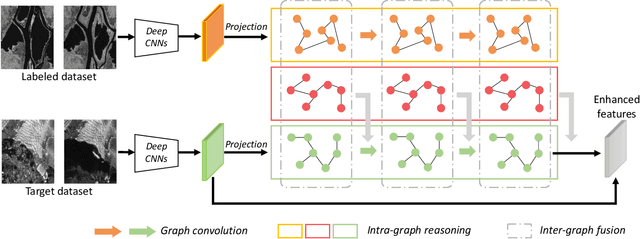
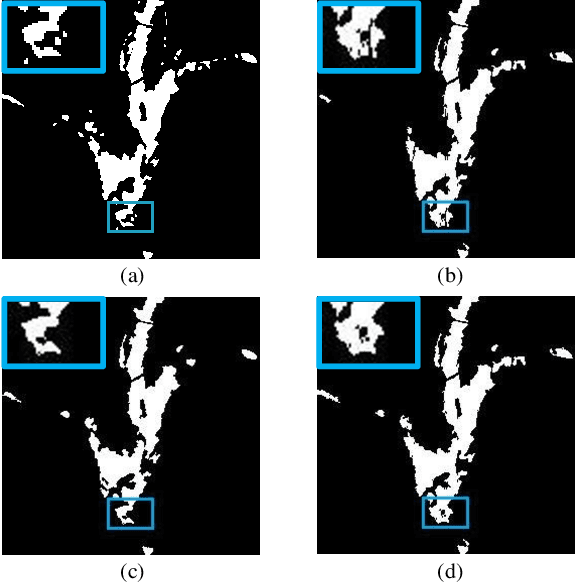
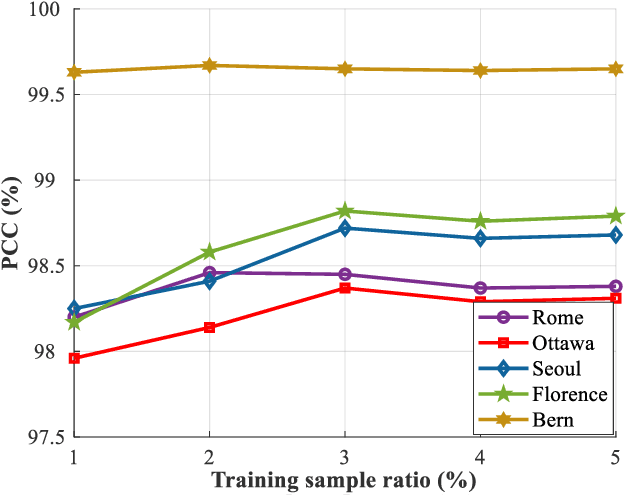
Synthetic aperture radar (SAR) image change detection is a vital yet challenging task in the field of remote sensing image analysis. Most previous works adopt a self-supervised method which uses pseudo-labeled samples to guide subsequent training and testing. However, deep networks commonly require many high-quality samples for parameter optimization. The noise in pseudo-labels inevitably affects the final change detection performance. To solve the problem, we propose a Graph-based Knowledge Supplement Network (GKSNet). To be more specific, we extract discriminative information from the existing labeled dataset as additional knowledge, to suppress the adverse effects of noisy samples to some extent. Afterwards, we design a graph transfer module to distill contextual information attentively from the labeled dataset to the target dataset, which bridges feature correlation between datasets. To validate the proposed method, we conducted extensive experiments on four SAR datasets, which demonstrated the superiority of the proposed GKSNet as compared to several state-of-the-art baselines. Our codes are available at https://github.com/summitgao/SAR_CD_GKSNet.
Spatial-Temporal Parallel Transformer for Arm-Hand Dynamic Estimation
Mar 30, 2022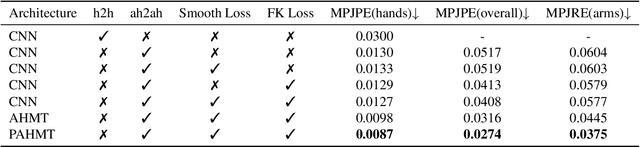
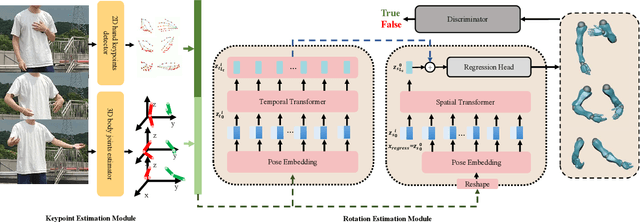

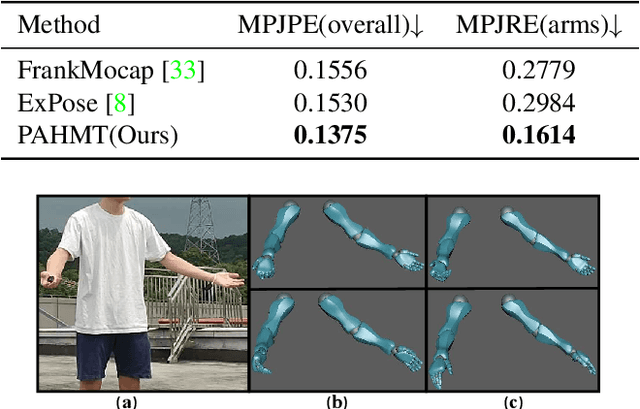
We propose an approach to estimate arm and hand dynamics from monocular video by utilizing the relationship between arm and hand. Although monocular full human motion capture technologies have made great progress in recent years, recovering accurate and plausible arm twists and hand gestures from in-the-wild videos still remains a challenge. To solve this problem, our solution is proposed based on the fact that arm poses and hand gestures are highly correlated in most real situations. To fully exploit arm-hand correlation as well as inter-frame information, we carefully design a Spatial-Temporal Parallel Arm-Hand Motion Transformer (PAHMT) to predict the arm and hand dynamics simultaneously. We also introduce new losses to encourage the estimations to be smooth and accurate. Besides, we collect a motion capture dataset including 200K frames of hand gestures and use this data to train our model. By integrating a 2D hand pose estimation model and a 3D human pose estimation model, the proposed method can produce plausible arm and hand dynamics from monocular video. Extensive evaluations demonstrate that the proposed method has advantages over previous state-of-the-art approaches and shows robustness under various challenging scenarios.
Learning Pixel-Level Distinctions for Video Highlight Detection
Apr 10, 2022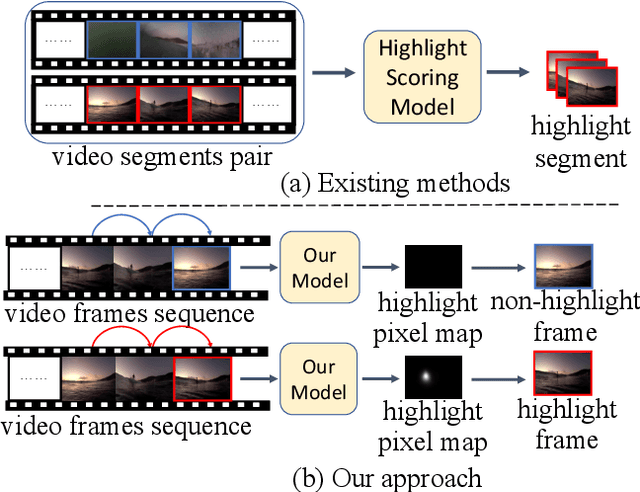

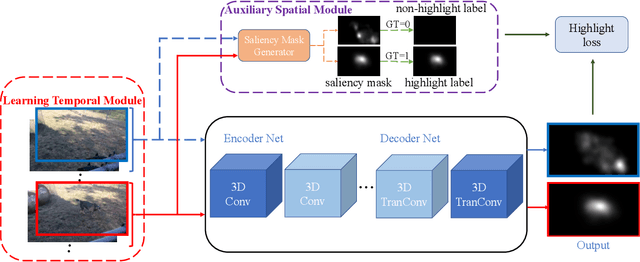
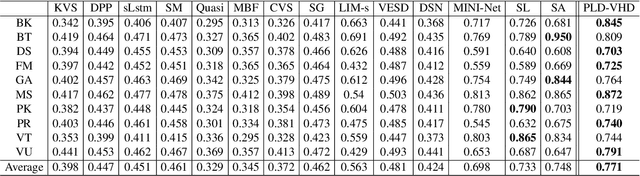
The goal of video highlight detection is to select the most attractive segments from a long video to depict the most interesting parts of the video. Existing methods typically focus on modeling relationship between different video segments in order to learning a model that can assign highlight scores to these segments; however, these approaches do not explicitly consider the contextual dependency within individual segments. To this end, we propose to learn pixel-level distinctions to improve the video highlight detection. This pixel-level distinction indicates whether or not each pixel in one video belongs to an interesting section. The advantages of modeling such fine-level distinctions are two-fold. First, it allows us to exploit the temporal and spatial relations of the content in one video, since the distinction of a pixel in one frame is highly dependent on both the content before this frame and the content around this pixel in this frame. Second, learning the pixel-level distinction also gives a good explanation to the video highlight task regarding what contents in a highlight segment will be attractive to people. We design an encoder-decoder network to estimate the pixel-level distinction, in which we leverage the 3D convolutional neural networks to exploit the temporal context information, and further take advantage of the visual saliency to model the spatial distinction. State-of-the-art performance on three public benchmarks clearly validates the effectiveness of our framework for video highlight detection.
WiFiEye -- Seeing over WiFi Made Accessible
Apr 06, 2022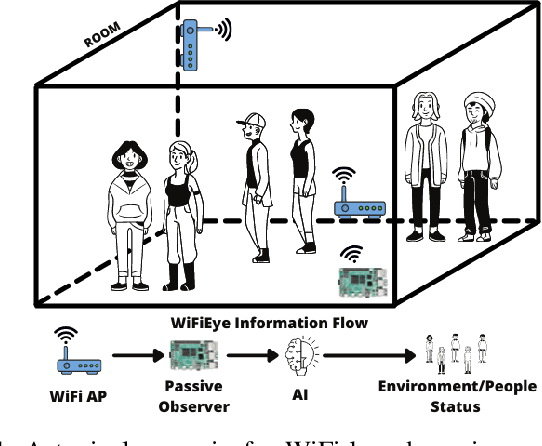
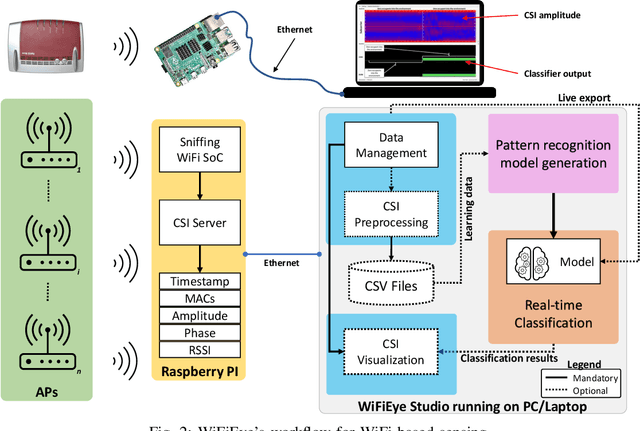


While commonly used for communication purposes, an increasing number of recent studies consider WiFi for sensing. In particular, wireless signals are altered (e.g., reflected and attenuated) by the human body and objects in the environment. This can be perceived by an observer to infer information on human activities or changes in the environment and, hence, to "see" over WiFi. Until now, works on WiFi-based sensing have resulted in a set of custom software tools - each designed for a specific purpose. Moreover, given how scattered the literature is, it is difficult to even identify all steps/functions necessary to build a basic system for WiFi-based sensing. This has led to a high entry barrier, hindering further research in this area. There has been no effort to integrate these tools or to build a general software framework that can serve as the basis for further research, e.g., on using machine learning to interpret the altered WiFi signals. To address this issue, in this paper, we propose WiFiEye - a generic software framework that makes all necessary steps/functions available "out of the box". This way, WiFiEye allows researchers to easily bootstrap new WiFi-based sensing applications, thereby, focusing on research rather than on implementation aspects. To illustrate WiFiEye's workflow, we present a case study on WiFi-based human activity recognition.
Which side are you on? Insider-Outsider classification in conspiracy-theoretic social media
Mar 30, 2022
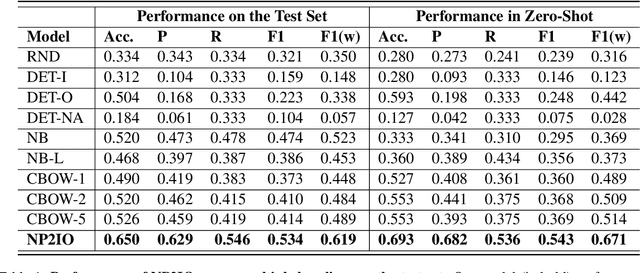
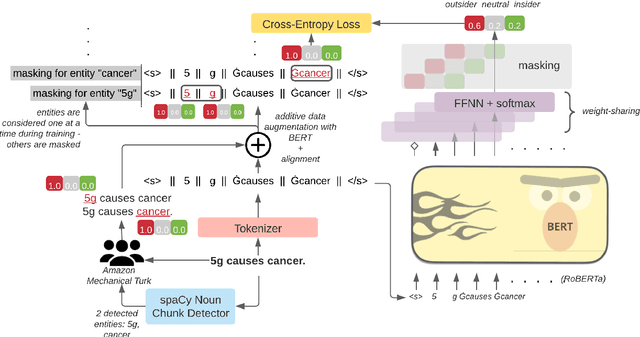
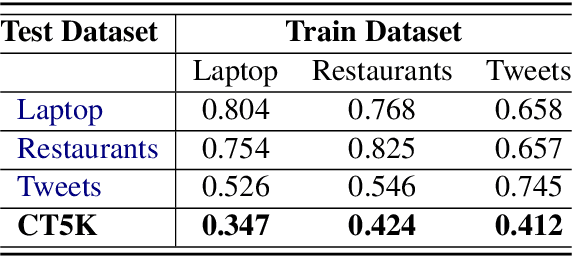
Social media is a breeding ground for threat narratives and related conspiracy theories. In these, an outside group threatens the integrity of an inside group, leading to the emergence of sharply defined group identities: Insiders -- agents with whom the authors identify and Outsiders -- agents who threaten the insiders. Inferring the members of these groups constitutes a challenging new NLP task: (i) Information is distributed over many poorly-constructed posts; (ii) Threats and threat agents are highly contextual, with the same post potentially having multiple agents assigned to membership in either group; (iii) An agent's identity is often implicit and transitive; and (iv) Phrases used to imply Outsider status often do not follow common negative sentiment patterns. To address these challenges, we define a novel Insider-Outsider classification task. Because we are not aware of any appropriate existing datasets or attendant models, we introduce a labeled dataset (CT5K) and design a model (NP2IO) to address this task. NP2IO leverages pretrained language modeling to classify Insiders and Outsiders. NP2IO is shown to be robust, generalizing to noun phrases not seen during training, and exceeding the performance of non-trivial baseline models by $20\%$.
Differential Privacy Amplification in Quantum and Quantum-inspired Algorithms
Mar 07, 2022
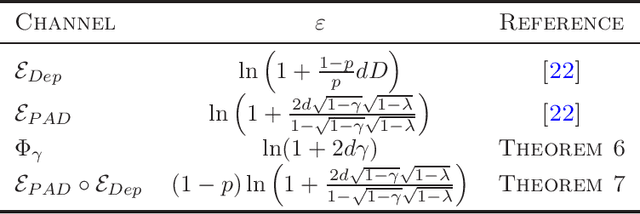
Differential privacy provides a theoretical framework for processing a dataset about $n$ users, in a way that the output reveals a minimal information about any single user. Such notion of privacy is usually ensured by noise-adding mechanisms and amplified by several processes, including subsampling, shuffling, iteration, mixing and diffusion. In this work, we provide privacy amplification bounds for quantum and quantum-inspired algorithms. In particular, we show for the first time, that algorithms running on quantum encoding of a classical dataset or the outcomes of quantum-inspired classical sampling, amplify differential privacy. Moreover, we prove that a quantum version of differential privacy is amplified by the composition of quantum channels, provided that they satisfy some mixing conditions.