 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Machine Learning-Based CSI Feedback With Variable Length in FDD Massive MIMO
Apr 10, 2022
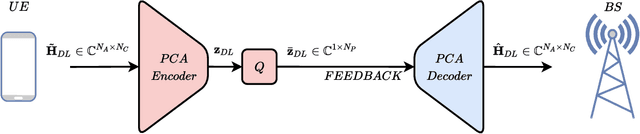
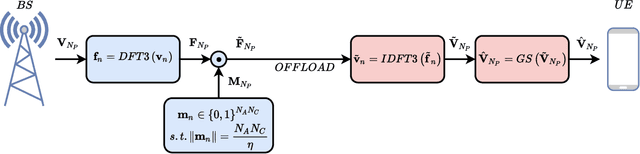
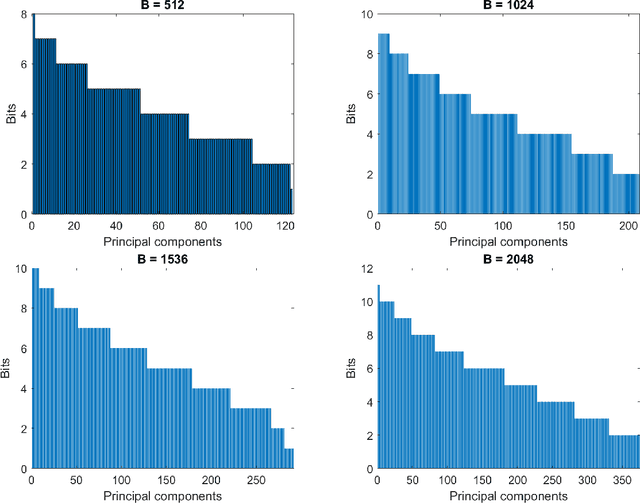
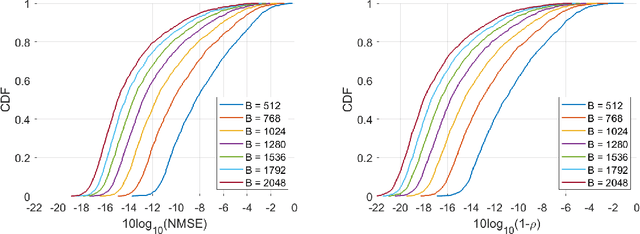
To fully unlock the benefits of multiple-input multiple-output (MIMO) networks, downlink channel state information (CSI) is required at the base station (BS). In frequency division duplex (FDD) systems, the CSI is acquired through a feedback signal from the user equipment (UE). However, this may lead to an important overhead in FDD massive MIMO systems. Focusing on these systems, in this study, we propose a novel strategy to design the CSI feedback. Our strategy allows to optimally design the feedback with variable length, while reducing the parameter number at the UE. Specifically, principal component analysis (PCA) is used to compress the channel into a latent space with adaptive dimensionality. To quantize this compressed channel, the feedback bits are smartly allocated to the latent space dimensions by minimizing the normalized mean squared error (NMSE) distortion. Finally, the quantization codebook is determined with k-means clustering. Numerical simulations show that our strategy improves the zeroforcing beamforming sum rate by 26.8%, compared with the popular CsiNet. The number of model parameters is reduced by 24.9 times, thus causing a significantly smaller offloading overhead. At the same time, PCA is characterized by a lightweight unsupervised training, requiring eight times fewer training samples than CsiNet.
Open-Ended Knowledge Tracing
Feb 21, 2022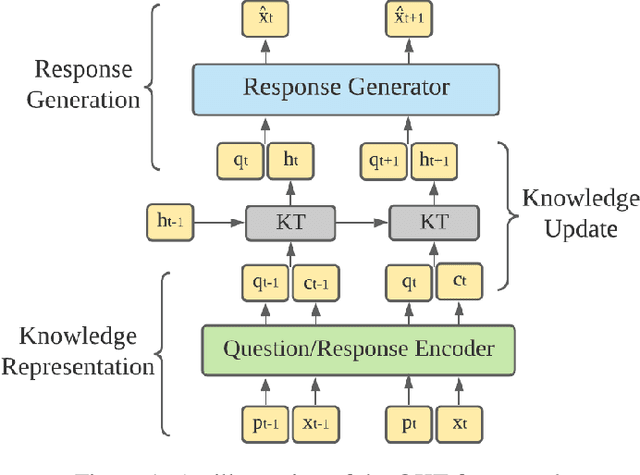
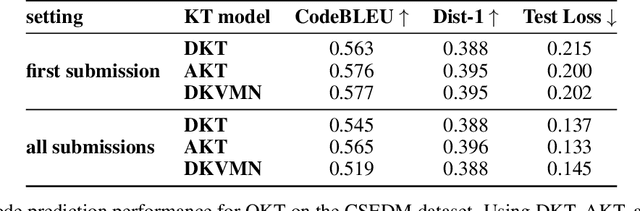
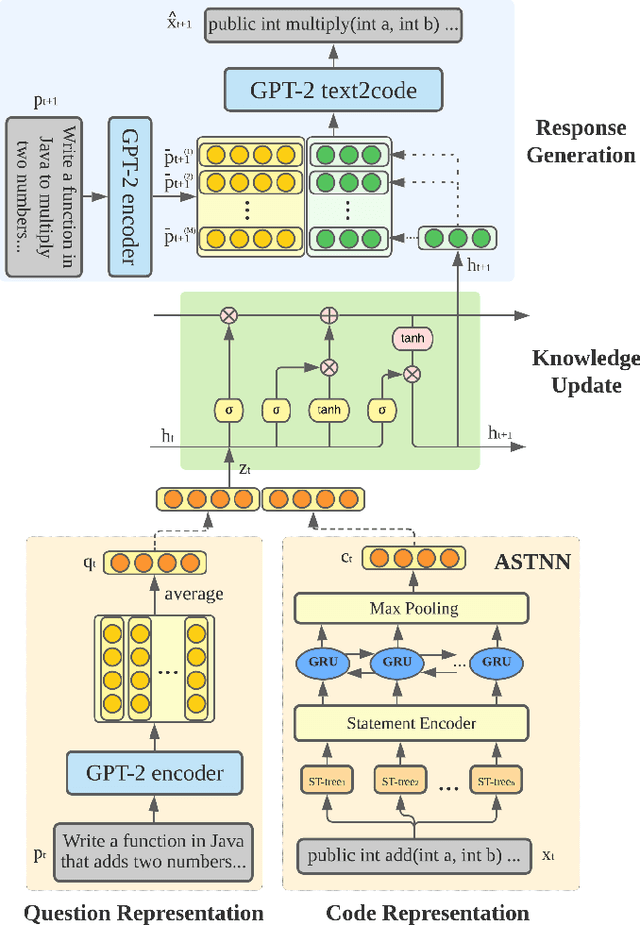
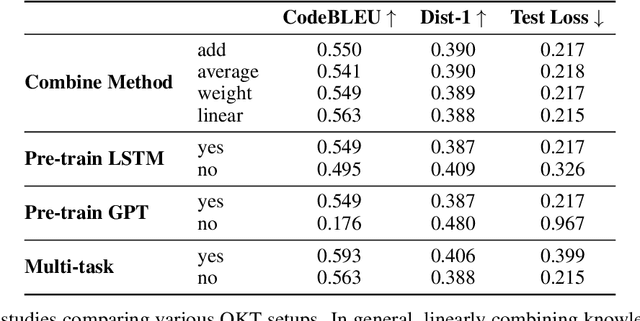
Knowledge tracing refers to the problem of estimating each student's knowledge component/skill mastery level from their past responses to questions in educational applications. One direct benefit knowledge tracing methods provide is the ability to predict each student's performance on the future questions. However, one key limitation of most existing knowledge tracing methods is that they treat student responses to questions as binary-valued, i.e., whether the responses are correct or incorrect. Response correctness analysis/prediction is easy to navigate but loses important information, especially for open-ended questions: the exact student responses can potentially provide much more information about their knowledge states than only response correctness. In this paper, we present our first exploration into open-ended knowledge tracing, i.e., the analysis and prediction of students' open-ended responses to questions in the knowledge tracing setup. We first lay out a generic framework for open-ended knowledge tracing before detailing its application to the domain of computer science education with programming questions. We define a series of evaluation metrics in this domain and conduct a series of quantitative and qualitative experiments to test the boundaries of open-ended knowledge tracing methods on a real-world student code dataset.
The TalkMoves Dataset: K-12 Mathematics Lesson Transcripts Annotated for Teacher and Student Discursive Moves
Apr 06, 2022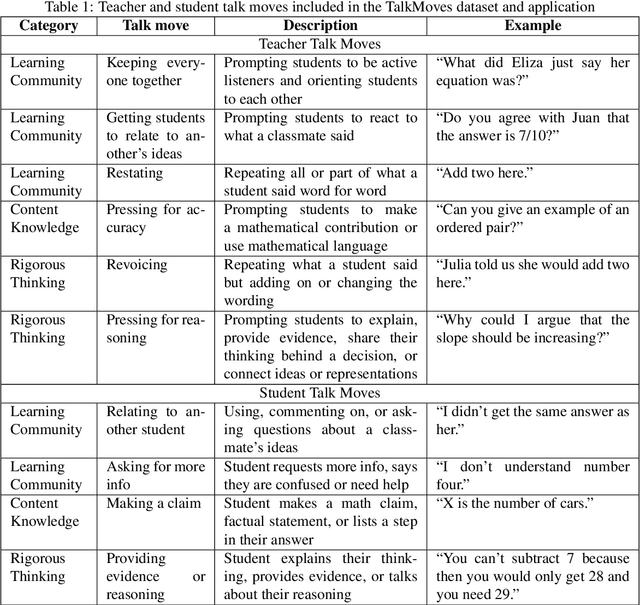
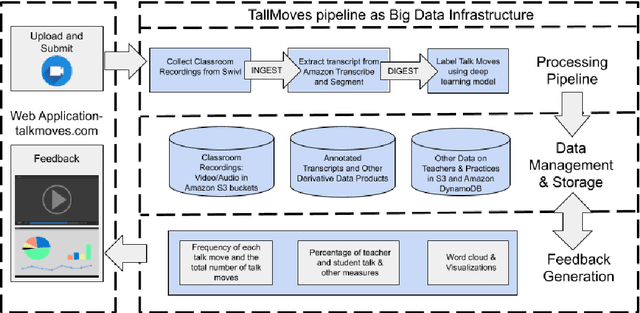
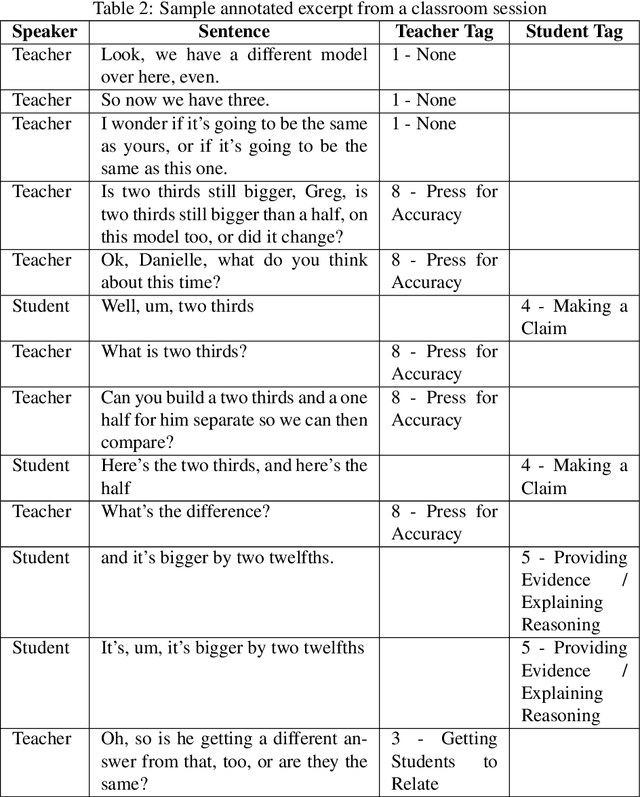
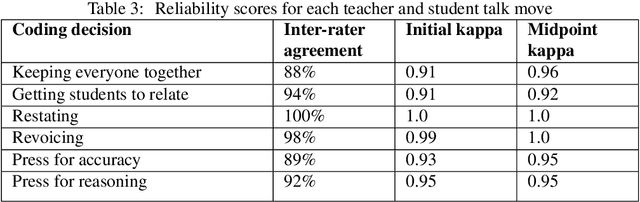
Transcripts of teaching episodes can be effective tools to understand discourse patterns in classroom instruction. According to most educational experts, sustained classroom discourse is a critical component of equitable, engaging, and rich learning environments for students. This paper describes the TalkMoves dataset, composed of 567 human-annotated K-12 mathematics lesson transcripts (including entire lessons or portions of lessons) derived from video recordings. The set of transcripts primarily includes in-person lessons with whole-class discussions and/or small group work, as well as some online lessons. All of the transcripts are human-transcribed, segmented by the speaker (teacher or student), and annotated at the sentence level for ten discursive moves based on accountable talk theory. In addition, the transcripts include utterance-level information in the form of dialogue act labels based on the Switchboard Dialog Act Corpus. The dataset can be used by educators, policymakers, and researchers to understand the nature of teacher and student discourse in K-12 math classrooms. Portions of this dataset have been used to develop the TalkMoves application, which provides teachers with automated, immediate, and actionable feedback about their mathematics instruction.
Explicitising The Implicit Intrepretability of Deep Neural Networks Via Duality
Mar 01, 2022

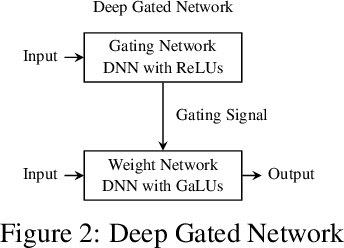

Recent work by Lakshminarayanan and Singh [2020] provided a dual view for fully connected deep neural networks (DNNs) with rectified linear units (ReLU). It was shown that (i) the information in the gates is analytically characterised by a kernel called the neural path kernel (NPK) and (ii) most critical information is learnt in the gates, in that, given the learnt gates, the weights can be retrained from scratch without significant loss in performance. Using the dual view, in this paper, we rethink the conventional interpretations of DNNs thereby explicitsing the implicit interpretability of DNNs. Towards this, we first show new theoretical properties namely rotational invariance and ensemble structure of the NPK in the presence of convolutional layers and skip connections respectively. Our theory leads to two surprising empirical results that challenge conventional wisdom: (i) the weights can be trained even with a constant 1 input, (ii) the gating masks can be shuffled, without any significant loss in performance. These results motivate a novel class of networks which we call deep linearly gated networks (DLGNs). DLGNs using the phenomenon of dual lifting pave way to more direct and simpler interpretation of DNNs as opposed to conventional interpretations. We show via extensive experiments on CIFAR-10 and CIFAR-100 that these DLGNs lead to much better interpretability-accuracy tradeoff.
Multi-Modal Causal Inference with Deep Structural Equation Models
Mar 21, 2022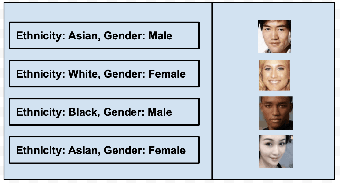
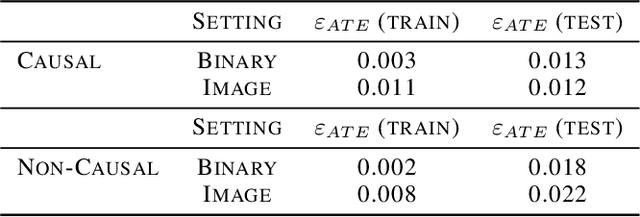
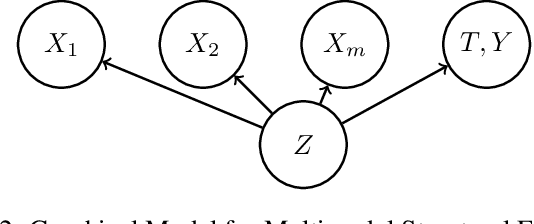

Accounting for the effects of confounders is one of the central challenges in causal inference. Unstructured multi-modal data (images, time series, text) contains valuable information about diverse types of confounders, yet it is typically left unused by most existing methods. This paper seeks to develop techniques that leverage this unstructured data within causal inference to correct for additional confounders that may otherwise not be accounted for. We formalize this task and we propose algorithms based on deep structural equations that treat multi-modal unstructured data as proxy variables. We empirically demonstrate on tasks in genomics and healthcare that unstructured data can be used to correct for diverse sources of confounding, potentially enabling the use of large amounts of data that were previously not used in causal inference.
Leveraging Phone Mask Training for Phonetic-Reduction-Robust E2E Uyghur Speech Recognition
Apr 02, 2022
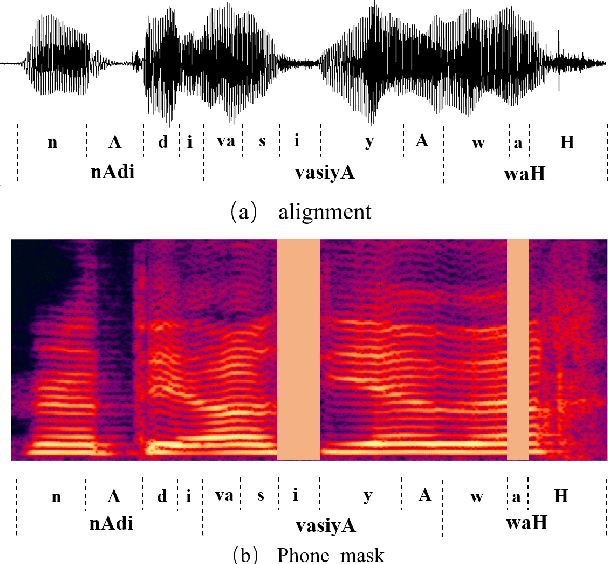

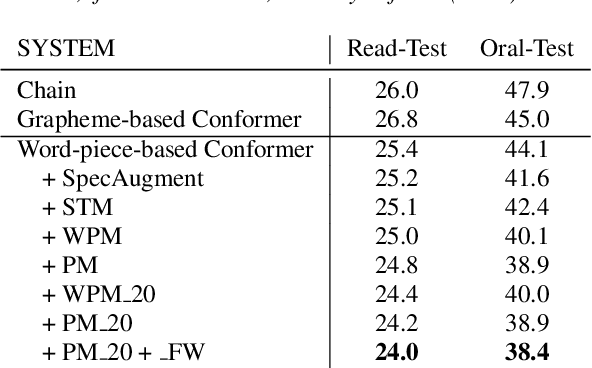
In Uyghur speech, consonant and vowel reduction are often encountered, especially in spontaneous speech with high speech rate, which will cause a degradation of speech recognition performance. To solve this problem, we propose an effective phone mask training method for Conformer-based Uyghur end-to-end (E2E) speech recognition. The idea is to randomly mask off a certain percentage features of phones during model training, which simulates the above verbal phenomena and facilitates E2E model to learn more contextual information. According to experiments, the above issues can be greatly alleviated. In addition, deep investigations are carried out into different units in masking, which shows the effectiveness of our proposed masking unit. We also further study the masking method and optimize filling strategy of phone mask. Finally, compared with Conformer-based E2E baseline without mask training, our model demonstrates about 5.51% relative Word Error Rate (WER) reduction on reading speech and 12.92% on spontaneous speech, respectively. The above approach has also been verified on test-set of open-source data THUYG-20, which shows 20% relative improvements.
* Accepted by INTERSPEECH 2021
Enhancing Causal Estimation through Unlabeled Offline Data
Feb 16, 2022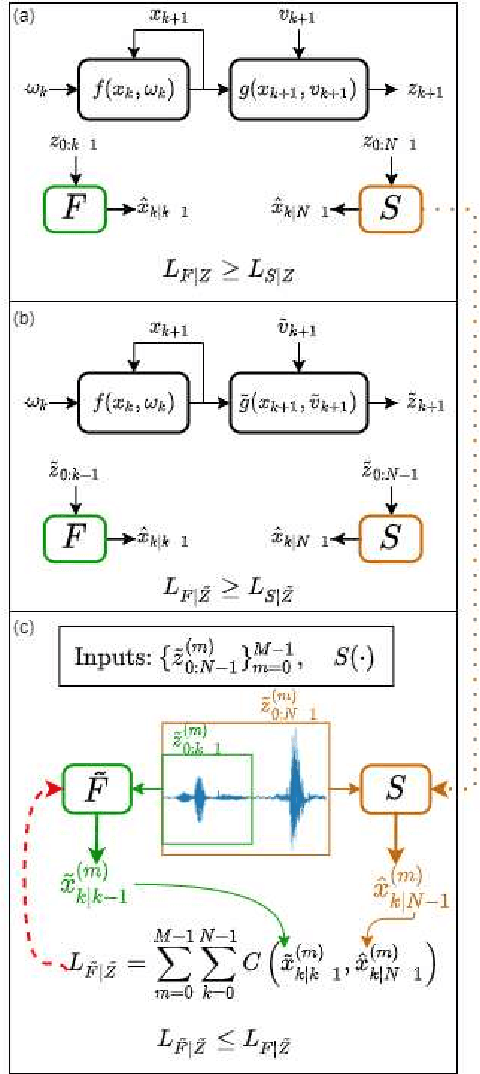
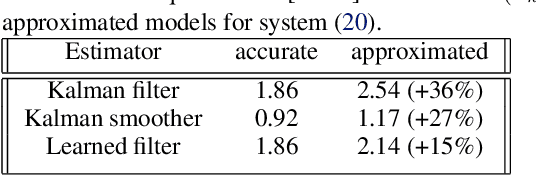
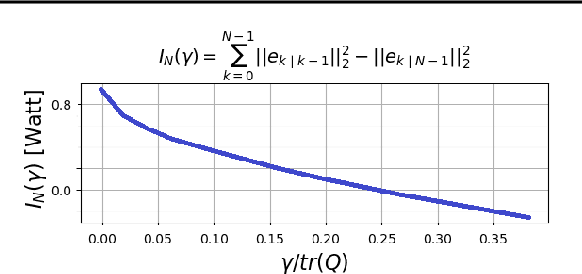
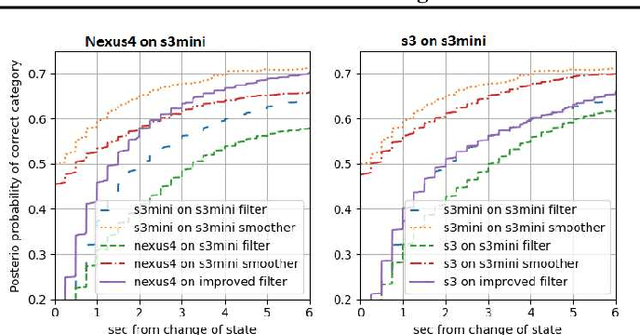
Consider a situation where a new patient arrives in the Intensive Care Unit (ICU) and is monitored by multiple sensors. We wish to assess relevant unmeasured physiological variables (e.g., cardiac contractility and output and vascular resistance) that have a strong effect on the patients diagnosis and treatment. We do not have any information about this specific patient, but, extensive offline information is available about previous patients, that may only be partially related to the present patient (a case of dataset shift). This information constitutes our prior knowledge, and is both partial and approximate. The basic question is how to best use this prior knowledge, combined with online patient data, to assist in diagnosing the current patient most effectively. Our proposed approach consists of three stages: (i) Use the abundant offline data in order to create both a non-causal and a causal estimator for the relevant unmeasured physiological variables. (ii) Based on the non-causal estimator constructed, and a set of measurements from a new group of patients, we construct a causal filter that provides higher accuracy in the prediction of the hidden physiological variables for this new set of patients. (iii) For any new patient arriving in the ICU, we use the constructed filter in order to predict relevant internal variables. Overall, this strategy allows us to make use of the abundantly available offline data in order to enhance causal estimation for newly arriving patients. We demonstrate the effectiveness of this methodology on a (non-medical) real-world task, in situations where the offline data is only partially related to the new observations. We provide a mathematical analysis of the merits of the approach in a linear setting of Kalman filtering and smoothing, demonstrating its utility.
UKP-SQUARE: An Online Platform for Question Answering Research
Mar 28, 2022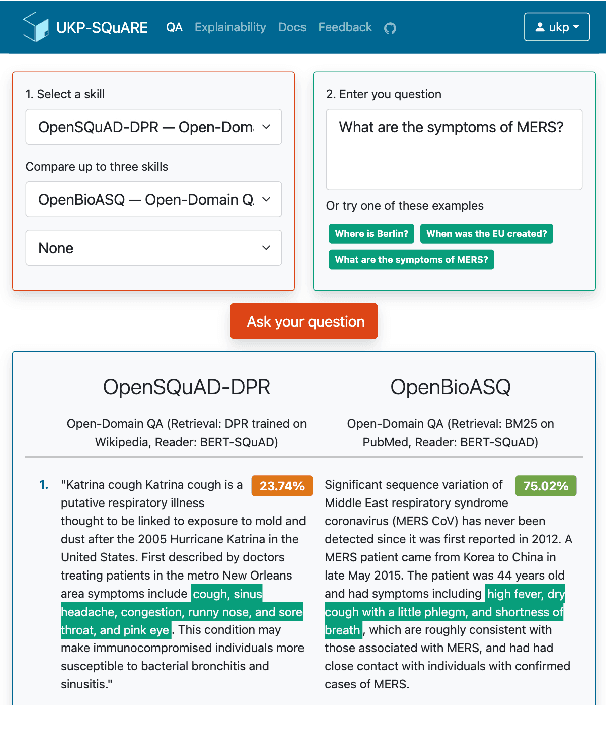

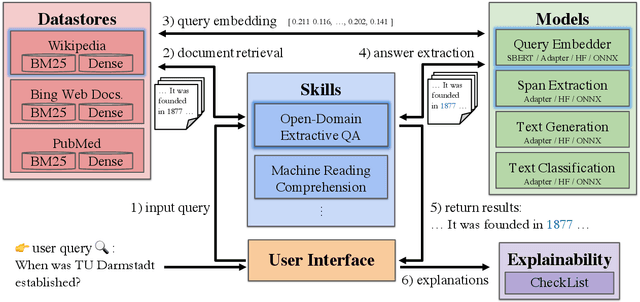
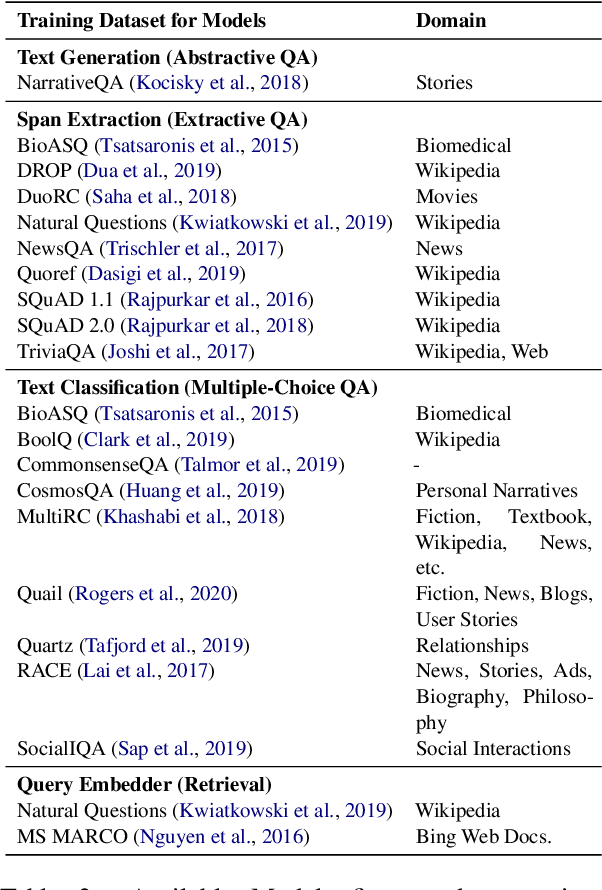
Recent advances in NLP and information retrieval have given rise to a diverse set of question answering tasks that are of different formats (e.g., extractive, abstractive), require different model architectures (e.g., generative, discriminative), and setups (e.g., with or without retrieval). Despite having a large number of powerful, specialized QA pipelines (which we refer to as Skills) that consider a single domain, model or setup, there exists no framework where users can easily explore and compare such pipelines and can extend them according to their needs. To address this issue, we present UKP-SQUARE, an extensible online QA platform for researchers which allows users to query and analyze a large collection of modern Skills via a user-friendly web interface and integrated behavioural tests. In addition, QA researchers can develop, manage, and share their custom Skills using our microservices that support a wide range of models (Transformers, Adapters, ONNX), datastores and retrieval techniques (e.g., sparse and dense). UKP-SQUARE is available on https://square.ukp-lab.de.
Simultaneous Alignment and Surface Regression Using Hybrid 2D-3D Networks for 3D Coherent Layer Segmentation of Retina OCT Images
Mar 04, 2022

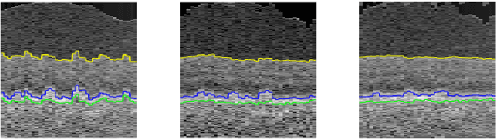
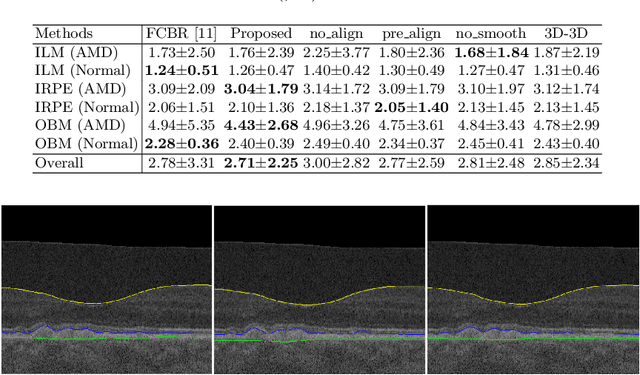
Automated surface segmentation of retinal layer is important and challenging in analyzing optical coherence tomography (OCT). Recently, many deep learning based methods have been developed for this task and yield remarkable performance. However, due to large spatial gap and potential mismatch between the B-scans of OCT data, all of them are based on 2D segmentation of individual B-scans, which may loss the continuity information across the B-scans. In addition, 3D surface of the retina layers can provide more diagnostic information, which is crucial in quantitative image analysis. In this study, a novel framework based on hybrid 2D-3D convolutional neural networks (CNNs) is proposed to obtain continuous 3D retinal layer surfaces from OCT. The 2D features of individual B-scans are extracted by an encoder consisting of 2D convolutions. These 2D features are then used to produce the alignment displacement field and layer segmentation by two 3D decoders, which are coupled via a spatial transformer module. The entire framework is trained end-to-end. To the best of our knowledge, this is the first study that attempts 3D retinal layer segmentation in volumetric OCT images based on CNNs. Experiments on a publicly available dataset show that our framework achieves superior results to state-of-the-art 2D methods in terms of both layer segmentation accuracy and cross-B-scan 3D continuity, thus offering more clinical values than previous works.
LP-BERT: Multi-task Pre-training Knowledge Graph BERT for Link Prediction
Jan 13, 2022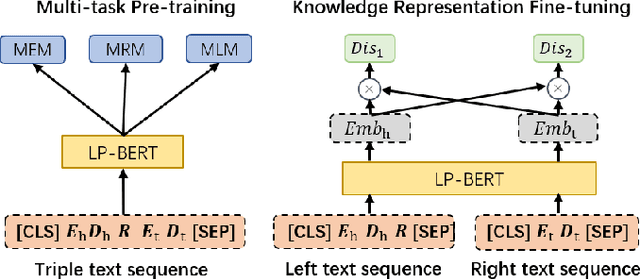
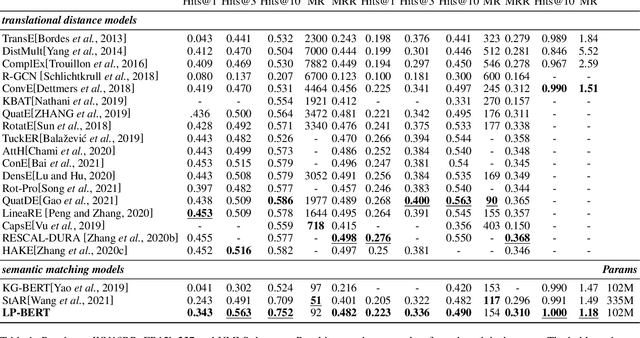
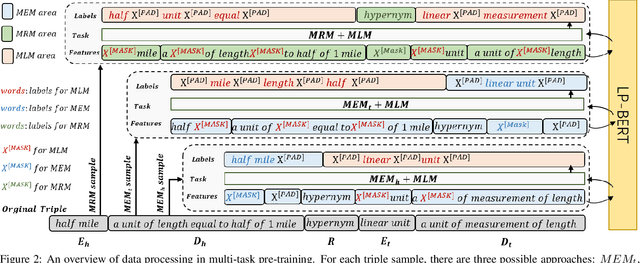
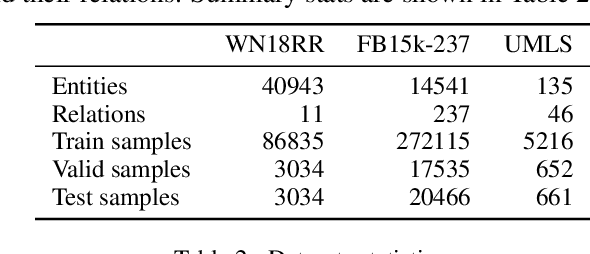
Link prediction plays an significant role in knowledge graph, which is an important resource for many artificial intelligence tasks, but it is often limited by incompleteness. In this paper, we propose knowledge graph BERT for link prediction, named LP-BERT, which contains two training stages: multi-task pre-training and knowledge graph fine-tuning. The pre-training strategy not only uses Mask Language Model (MLM) to learn the knowledge of context corpus, but also introduces Mask Entity Model (MEM) and Mask Relation Model (MRM), which can learn the relationship information from triples by predicting semantic based entity and relation elements. Structured triple relation information can be transformed into unstructured semantic information, which can be integrated into the pre-training model together with context corpus information. In the fine-tuning phase, inspired by contrastive learning, we carry out a triple-style negative sampling in sample batch, which greatly increased the proportion of negative sampling while keeping the training time almost unchanged. Furthermore, we propose a data augmentation method based on the inverse relationship of triples to further increase the sample diversity. We achieve state-of-the-art results on WN18RR and UMLS datasets, especially the Hits@10 indicator improved by 5\% from the previous state-of-the-art result on WN18RR dataset.