 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Movies2Scenes: Learning Scene Representations Using Movie Similarities
Feb 22, 2022
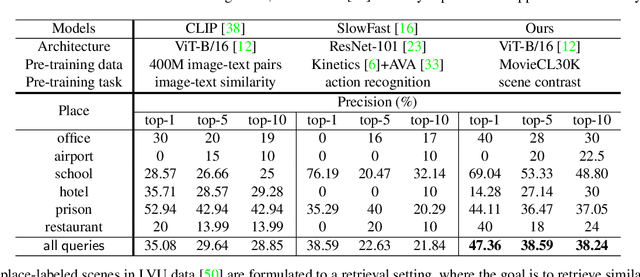
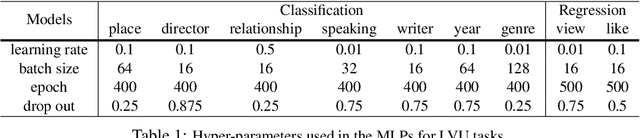
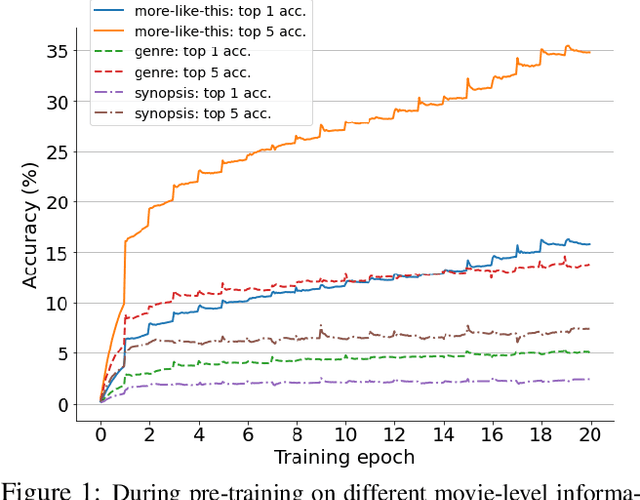
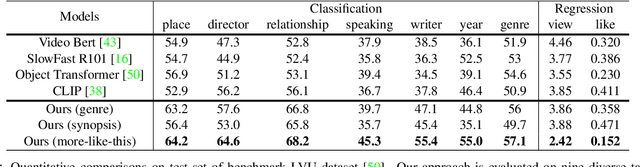
Automatic understanding of movie-scenes is an important problem with multiple downstream applications including video-moderation, search and recommendation. The long-form nature of movies makes labeling of movie scenes a laborious task, which makes applying end-to-end supervised approaches for understanding movie-scenes a challenging problem. Directly applying state-of-the-art visual representations learned from large-scale image datasets for movie-scene understanding does not prove to be effective given the large gap between the two domains. To address these challenges, we propose a novel contrastive learning approach that uses commonly available sources of movie-information (e.g., genre, synopsis, more-like-this information) to learn a general-purpose scene-representation. Using a new dataset (MovieCL30K) with 30,340 movies, we demonstrate that our learned scene-representation surpasses existing state-of-the-art results on eleven downstream tasks from multiple datasets. To further show the effectiveness of our scene-representation, we introduce another new dataset (MCD) focused on large-scale video-moderation with 44,581 clips containing sex, violence, and drug-use activities covering 18,330 movies and TV episodes, and show strong gains over existing state-of-the-art approaches.
MmWave 6D Radio Localization with a Snapshot Observation from a Single BS
Apr 11, 2022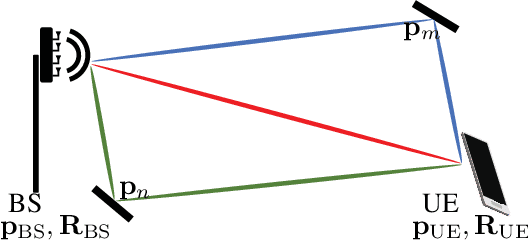
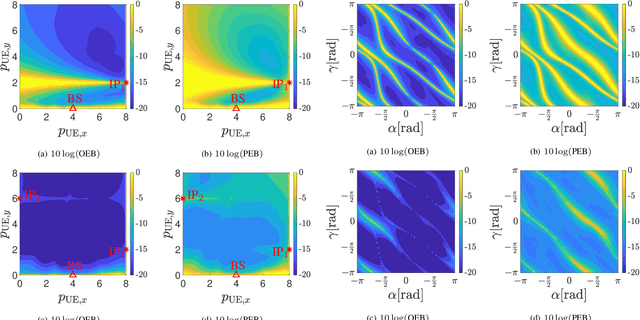
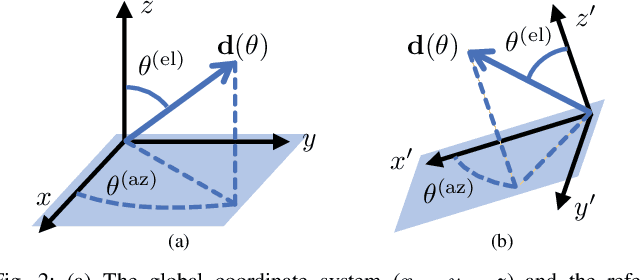
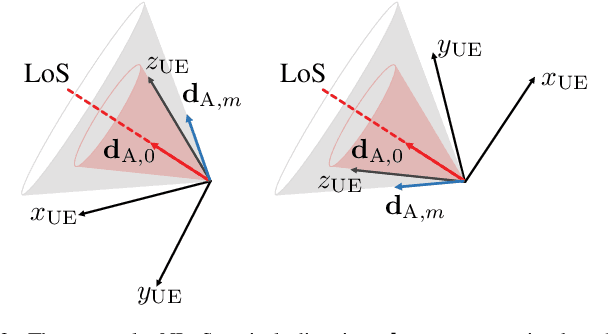
Accurate and ubiquitous localization is crucial for a variety of applications such as logistics, navigation, intelligent transport, monitoring, and control. Exploiting mmWave signals in 5G and Beyond 5G systems can provide accurate localization with limited infrastructure. We consider the single base station localization problem and extend it to 3D position and 3D orientation estimation of an unsynchronized multi-antenna user, using downlink MIMO-OFDM signals. Through a Fisher information analysis, we show that the problem is often identifiable, provided that there is at least one additional multipath component, even if the position of corresponding incidence point is a priori unknown. Subsequently, we pose a maximum likelihood (ML) estimation problem, to jointly estimate the 3D position and 3D orientation of the user as well as several nuisance parameters (the user clock offset and the positions of incidence points corresponding to the multipath). The ML problem is a high-dimensional non-convex optimization problem over a product of Euclidean and Riemannian manifolds. To avoid complex exhaustive search procedures, we propose a geometric initial estimate of all parameters, which reduces the problem to a 1-dimensional search over a finite interval. Numerical results show the efficiency of the proposed ad-hoc estimation, whose gap to the CRB is tightened using ML estimation.
Pin the Memory: Learning to Generalize Semantic Segmentation
Apr 07, 2022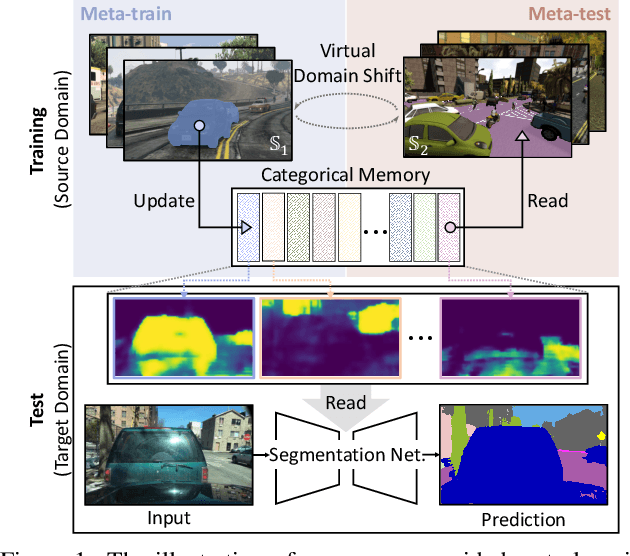
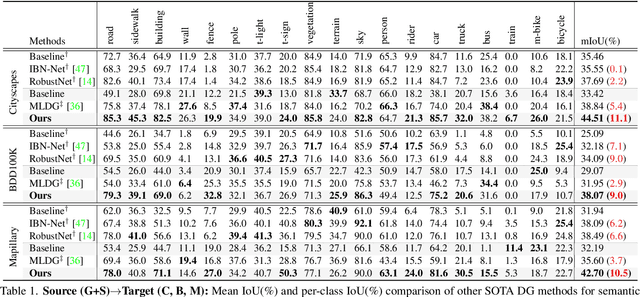
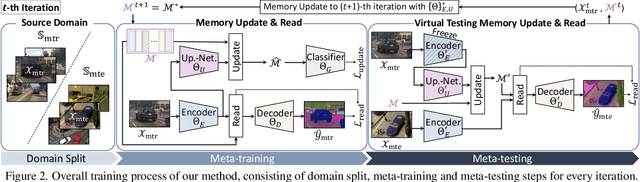
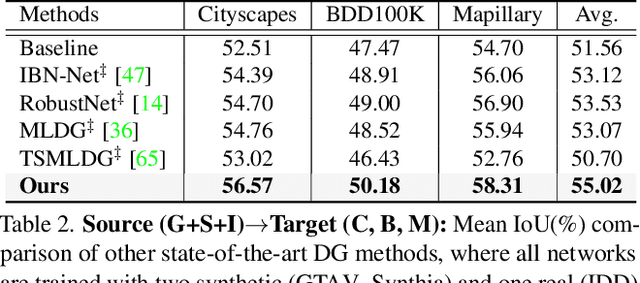
The rise of deep neural networks has led to several breakthroughs for semantic segmentation. In spite of this, a model trained on source domain often fails to work properly in new challenging domains, that is directly concerned with the generalization capability of the model. In this paper, we present a novel memory-guided domain generalization method for semantic segmentation based on meta-learning framework. Especially, our method abstracts the conceptual knowledge of semantic classes into categorical memory which is constant beyond the domains. Upon the meta-learning concept, we repeatedly train memory-guided networks and simulate virtual test to 1) learn how to memorize a domain-agnostic and distinct information of classes and 2) offer an externally settled memory as a class-guidance to reduce the ambiguity of representation in the test data of arbitrary unseen domain. To this end, we also propose memory divergence and feature cohesion losses, which encourage to learn memory reading and update processes for category-aware domain generalization. Extensive experiments for semantic segmentation demonstrate the superior generalization capability of our method over state-of-the-art works on various benchmarks.
A Nano-Architecture for Fertility Monitoring via Intra-body Communication
Feb 04, 2022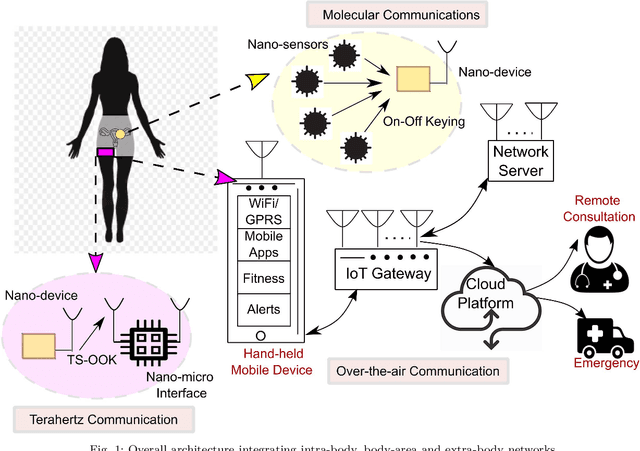
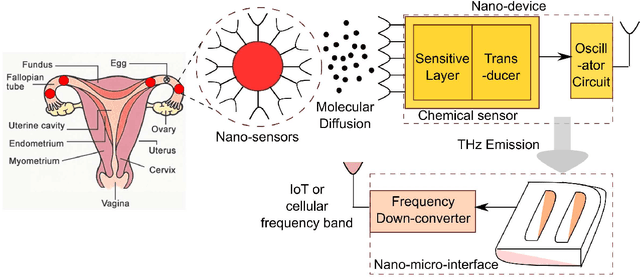
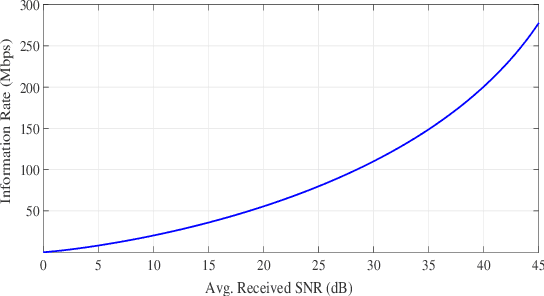
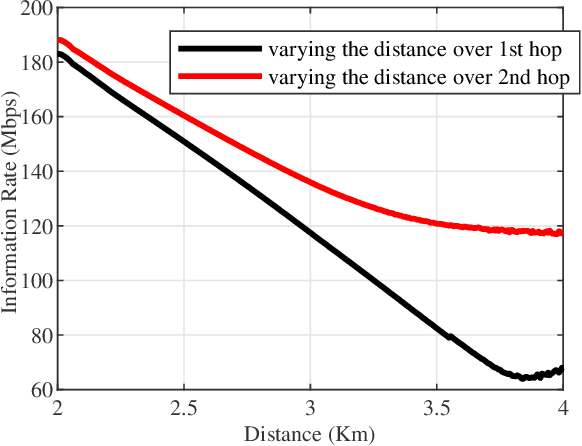
Fertility monitoring in humans for either natural conception or artificial insemination and fertilization has been a critical challenge both for the treating physician and the treated patients. Eggs in human female can be fertilized when they reach the Fallopian tube from the upper parts of the reproductive system. However, no technology, till date, on its own could detect the presence of eggs in the Fallopian tube and communicate their presence to the consulting physician or nurse and the patient, so that the next step can be initiated in a timely fashion. In this paper, we propose a conceptual architecture from a communications engineering point of view. The architecture combines intra-body nano-sensor network for detecting Fallopian tube activity, with body-area network for receiving information from the intra-body network and communicating the same over-the-air to the involved personnel (physician/nurse/patient). Preliminary simulations have been conducted using particle based stochastic simulator to investigate the relationship between achievable information rates, signal to noise ratio (SNR) and distance. It has been found that data rate as high as 300 Mbps is achievable at SNR 45. Hence, the proposed architecture ensures transfer of information with near-zero latency and minimum energy along with high throughput, so that necessary action can be taken within the short time-window of the Fallopian tube activity.
An Overview & Analysis of Sequence-to-Sequence Emotional Voice Conversion
Mar 29, 2022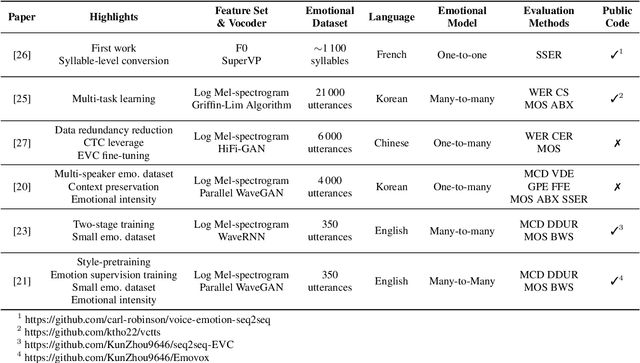
Emotional voice conversion (EVC) focuses on converting a speech utterance from a source to a target emotion; it can thus be a key enabling technology for human-computer interaction applications and beyond. However, EVC remains an unsolved research problem with several challenges. In particular, as speech rate and rhythm are two key factors of emotional conversion, models have to generate output sequences of differing length. Sequence-to-sequence modelling is recently emerging as a competitive paradigm for models that can overcome those challenges. In an attempt to stimulate further research in this promising new direction, recent sequence-to-sequence EVC papers were systematically investigated and reviewed from six perspectives: their motivation, training strategies, model architectures, datasets, model inputs, and evaluation methods. This information is organised to provide the research community with an easily digestible overview of the current state-of-the-art. Finally, we discuss existing challenges of sequence-to-sequence EVC.
OWL (Observe, Watch, Listen): Localizing Actions in Egocentric Video via Audiovisual Temporal Context
Feb 10, 2022
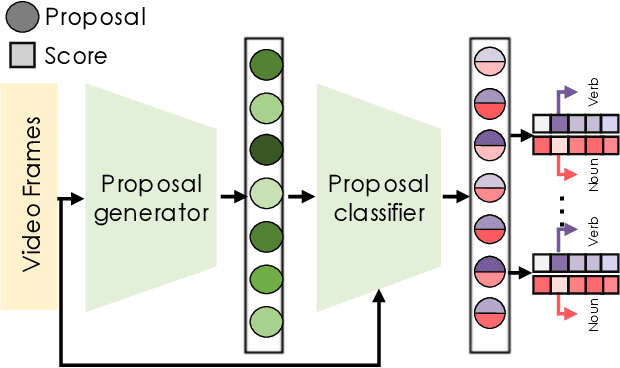

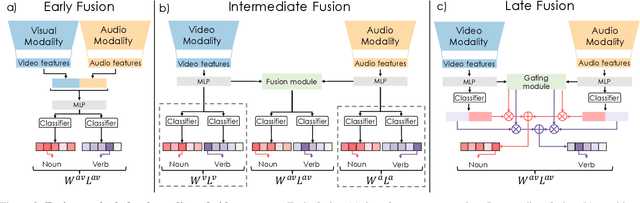
Temporal action localization (TAL) is an important task extensively explored and improved for third-person videos in recent years. Recent efforts have been made to perform fine-grained temporal localization on first-person videos. However, current TAL methods only use visual signals, neglecting the audio modality that exists in most videos and that shows meaningful action information in egocentric videos. In this work, we take a deep look into the effectiveness of audio in detecting actions in egocentric videos and introduce a simple-yet-effective approach via Observing, Watching, and Listening (OWL) to leverage audio-visual information and context for egocentric TAL. For doing that, we: 1) compare and study different strategies for where and how to fuse the two modalities; 2) propose a transformer-based model to incorporate temporal audio-visual context. Our experiments show that our approach achieves state-of-the-art performance on EPIC-KITCHENS-100.
Linguistic communication as (inverse) reward design
Apr 11, 2022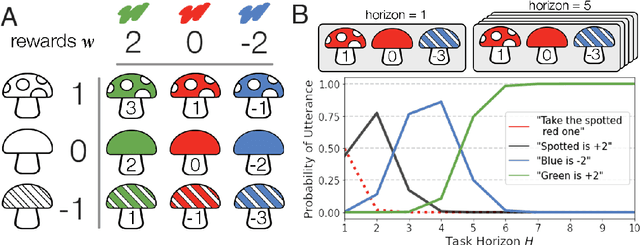
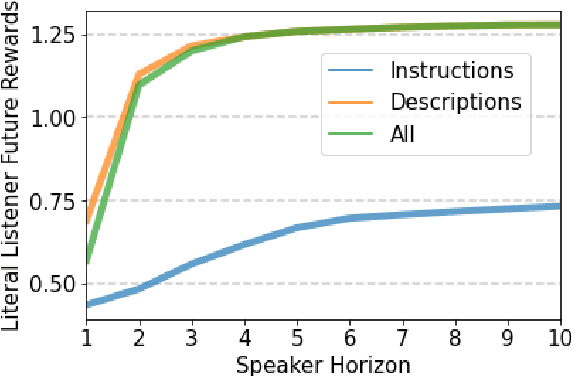
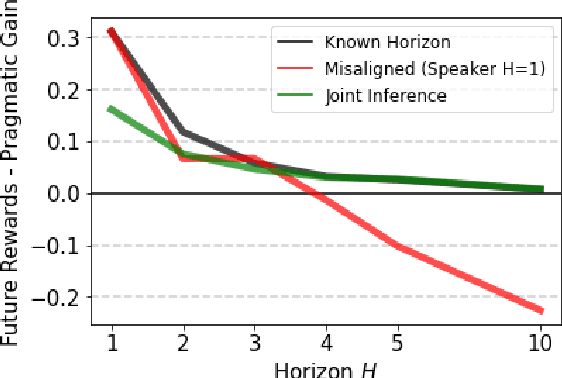
Natural language is an intuitive and expressive way to communicate reward information to autonomous agents. It encompasses everything from concrete instructions to abstract descriptions of the world. Despite this, natural language is often challenging to learn from: it is difficult for machine learning methods to make appropriate inferences from such a wide range of input. This paper proposes a generalization of reward design as a unifying principle to ground linguistic communication: speakers choose utterances to maximize expected rewards from the listener's future behaviors. We first extend reward design to incorporate reasoning about unknown future states in a linear bandit setting. We then define a speaker model which chooses utterances according to this objective. Simulations show that short-horizon speakers (reasoning primarily about a single, known state) tend to use instructions, while long-horizon speakers (reasoning primarily about unknown, future states) tend to describe the reward function. We then define a pragmatic listener which performs inverse reward design by jointly inferring the speaker's latent horizon and rewards. Our findings suggest that this extension of reward design to linguistic communication, including the notion of a latent speaker horizon, is a promising direction for achieving more robust alignment outcomes from natural language supervision.
Towards Textual Out-of-Domain Detection without In-Domain Labels
Mar 22, 2022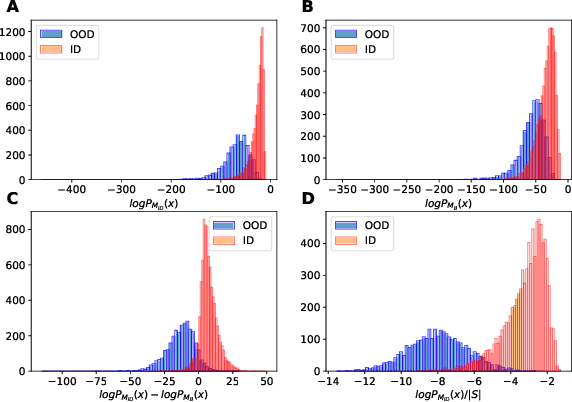
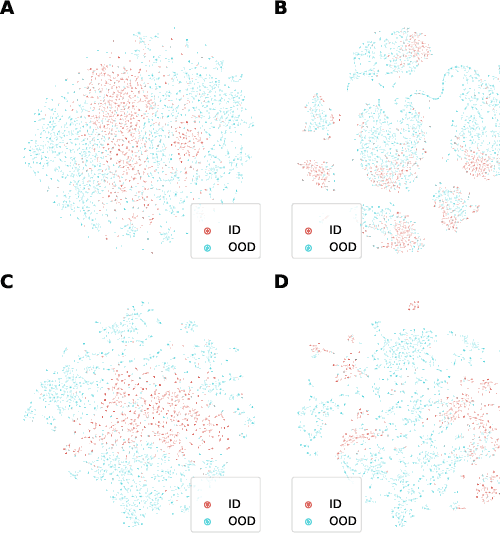
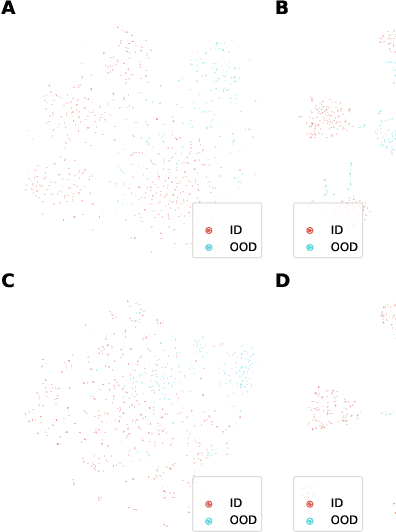
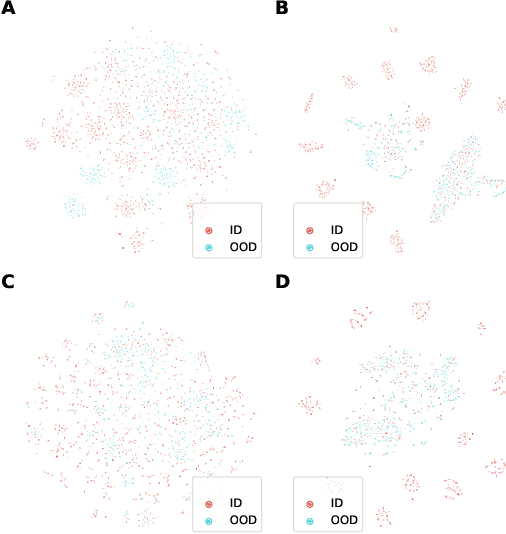
In many real-world settings, machine learning models need to identify user inputs that are out-of-domain (OOD) so as to avoid performing wrong actions. This work focuses on a challenging case of OOD detection, where no labels for in-domain data are accessible (e.g., no intent labels for the intent classification task). To this end, we first evaluate different language model based approaches that predict likelihood for a sequence of tokens. Furthermore, we propose a novel representation learning based method by combining unsupervised clustering and contrastive learning so that better data representations for OOD detection can be learned. Through extensive experiments, we demonstrate that this method can significantly outperform likelihood-based methods and can be even competitive to the state-of-the-art supervised approaches with label information.
Holistic Combination of Structural and Textual Code Information for Context based API Recommendation
Oct 15, 2020


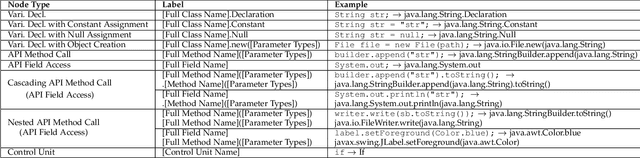
Context based API recommendation is an important way to help developers find the needed APIs effectively and efficiently. For effective API recommendation, we need not only a joint view of both structural and textual code information, but also a holistic view of correlated API usage in control and data flow graph as a whole. Unfortunately, existing API recommendation methods exploit structural or textual code information separately. In this work, we propose a novel API recommendation approach called APIRec-CST (API Recommendation by Combining Structural and Textual code information). APIRec-CST is a deep learning model that combines the API usage with the text information in the source code based on an API Context Graph Network and a Code Token Network that simultaneously learn structural and textual features for API recommendation. We apply APIRec-CST to train a model for JDK library based on 1,914 open-source Java projects and evaluate the accuracy and MRR (Mean Reciprocal Rank) of API recommendation with another 6 open-source projects. The results show that our approach achieves respectively a top-1, top-5, top-10 accuracy and MRR of 60.3%, 81.5%, 87.7% and 69.4%, and significantly outperforms an existing graph-based statistical approach and a tree-based deep learning approach for API recommendation. A further analysis shows that textual code information makes sense and improves the accuracy and MRR. We also conduct a user study in which two groups of students are asked to finish 6 programming tasks with or without our APIRec-CST plugin. The results show that APIRec-CST can help the students to finish the tasks faster and more accurately and the feedback on the usability is overwhelmingly positive.
Jacobian Norm for Unsupervised Source-Free Domain Adaptation
Apr 07, 2022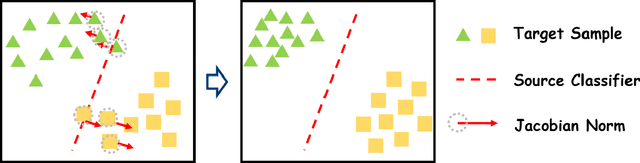
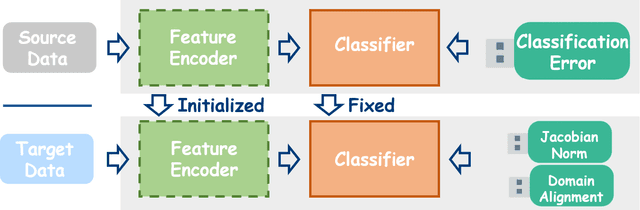
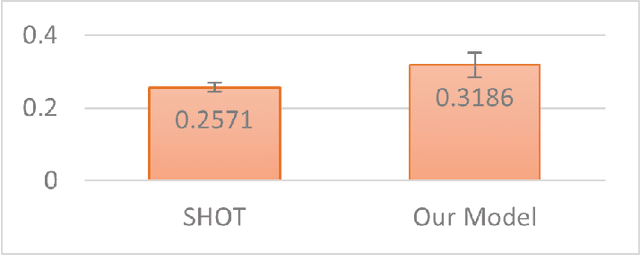
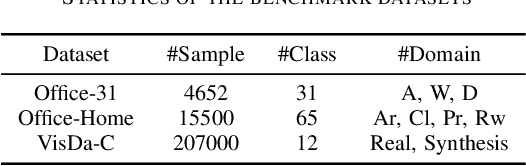
Unsupervised Source (data) Free domain adaptation (USFDA) aims to transfer knowledge from a well-trained source model to a related but unlabeled target domain. In such a scenario, all conventional adaptation methods that require source data fail. To combat this challenge, existing USFDAs turn to transfer knowledge by aligning the target feature to the latent distribution hidden in the source model. However, such information is naturally limited. Thus, the alignment in such a scenario is not only difficult but also insufficient, which degrades the target generalization performance. To relieve this dilemma in current USFDAs, we are motivated to explore a new perspective to boost their performance. For this purpose and gaining necessary insight, we look back upon the origin of the domain adaptation and first theoretically derive a new-brand target generalization error bound based on the model smoothness. Then, following the theoretical insight, a general and model-smoothness-guided Jacobian norm (JN) regularizer is designed and imposed on the target domain to mitigate this dilemma. Extensive experiments are conducted to validate its effectiveness. In its implementation, just with a few lines of codes added to the existing USFDAs, we achieve superior results on various benchmark datasets.