 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DisARM: Displacement Aware Relation Module for 3D Detection
Mar 02, 2022

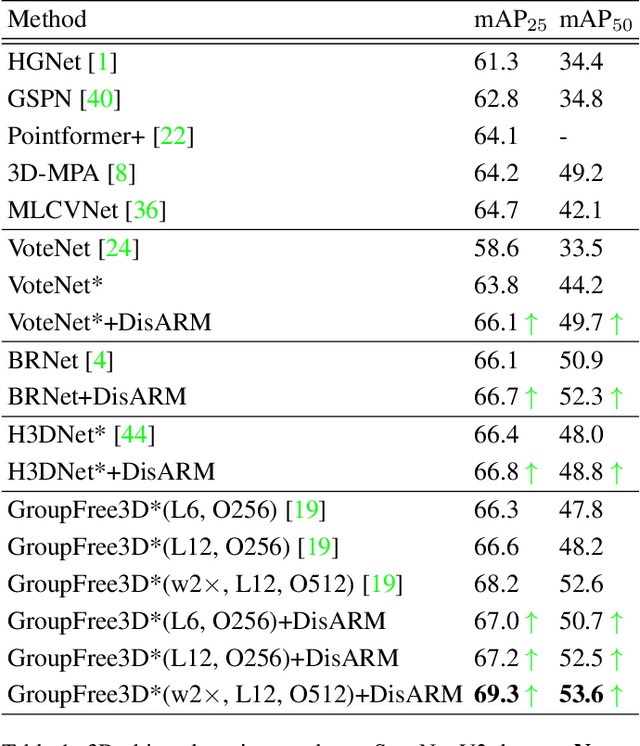
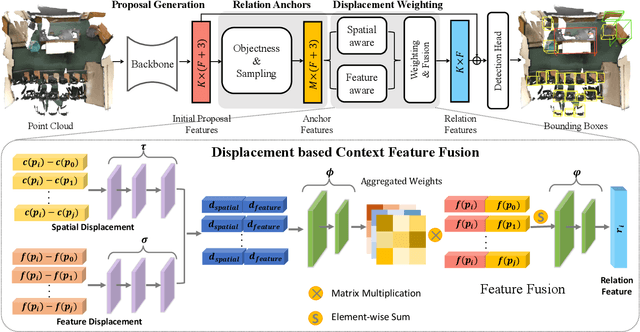
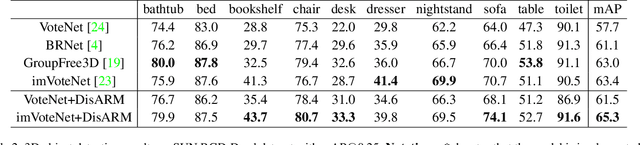
We introduce Displacement Aware Relation Module (DisARM), a novel neural network module for enhancing the performance of 3D object detection in point cloud scenes. The core idea of our method is that contextual information is critical to tell the difference when the instance geometry is incomplete or featureless. We find that relations between proposals provide a good representation to describe the context. However, adopting relations between all the object or patch proposals for detection is inefficient, and an imbalanced combination of local and global relations brings extra noise that could mislead the training. Rather than working with all relations, we found that training with relations only between the most representative ones, or anchors, can significantly boost the detection performance. A good anchor should be semantic-aware with no ambiguity and independent with other anchors as well. To find the anchors, we first perform a preliminary relation anchor module with an objectness-aware sampling approach and then devise a displacement-based module for weighing the relation importance for better utilization of contextual information. This lightweight relation module leads to significantly higher accuracy of object instance detection when being plugged into the state-of-the-art detectors. Evaluations on the public benchmarks of real-world scenes show that our method achieves state-of-the-art performance on both SUN RGB-D and ScanNet V2.
Integrating Contrastive Learning with Dynamic Models for Reinforcement Learning from Images
Mar 02, 2022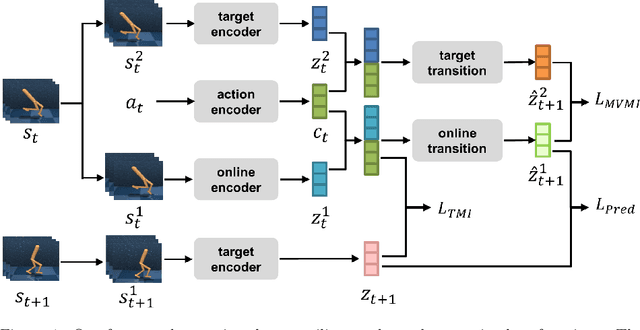

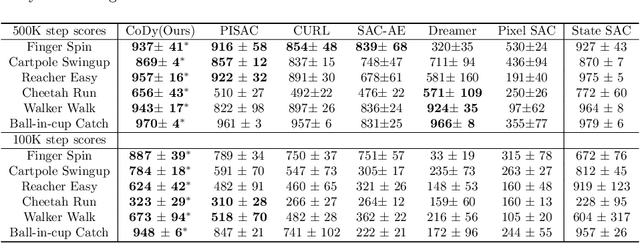
Recent methods for reinforcement learning from images use auxiliary tasks to learn image features that are used by the agent's policy or Q-function. In particular, methods based on contrastive learning that induce linearity of the latent dynamics or invariance to data augmentation have been shown to greatly improve the sample efficiency of the reinforcement learning algorithm and the generalizability of the learned embedding. We further argue, that explicitly improving Markovianity of the learned embedding is desirable and propose a self-supervised representation learning method which integrates contrastive learning with dynamic models to synergistically combine these three objectives: (1) We maximize the InfoNCE bound on the mutual information between the state- and action-embedding and the embedding of the next state to induce a linearly predictive embedding without explicitly learning a linear transition model, (2) we further improve Markovianity of the learned embedding by explicitly learning a non-linear transition model using regression, and (3) we maximize the mutual information between the two nonlinear predictions of the next embeddings based on the current action and two independent augmentations of the current state, which naturally induces transformation invariance not only for the state embedding, but also for the nonlinear transition model. Experimental evaluation on the Deepmind control suite shows that our proposed method achieves higher sample efficiency and better generalization than state-of-art methods based on contrastive learning or reconstruction.
* 28 pages, 11 figures, 5 tables
Learning Robust Representations via Multi-View Information Bottleneck
Feb 18, 2020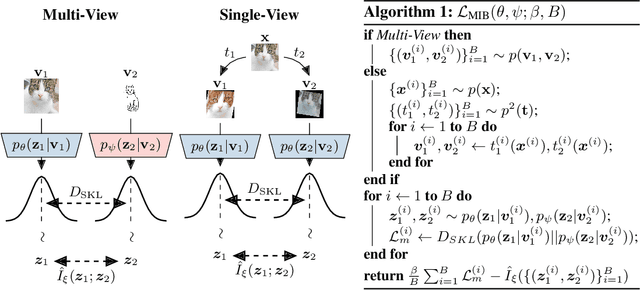
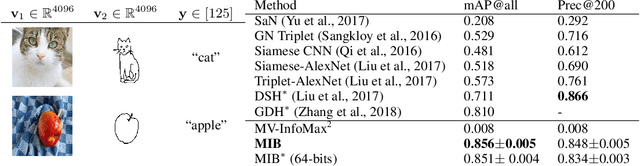
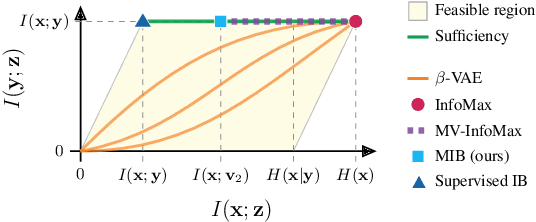

The information bottleneck principle provides an information-theoretic method for representation learning, by training an encoder to retain all information which is relevant for predicting the label while minimizing the amount of other, excess information in the representation. The original formulation, however, requires labeled data to identify the superfluous information. In this work, we extend this ability to the multi-view unsupervised setting, where two views of the same underlying entity are provided but the label is unknown. This enables us to identify superfluous information as that not shared by both views. A theoretical analysis leads to the definition of a new multi-view model that produces state-of-the-art results on the Sketchy dataset and label-limited versions of the MIR-Flickr dataset. We also extend our theory to the single-view setting by taking advantage of standard data augmentation techniques, empirically showing better generalization capabilities when compared to common unsupervised approaches for representation learning.
Deep learning based closed-loop optimization of geothermal reservoir production
Apr 15, 2022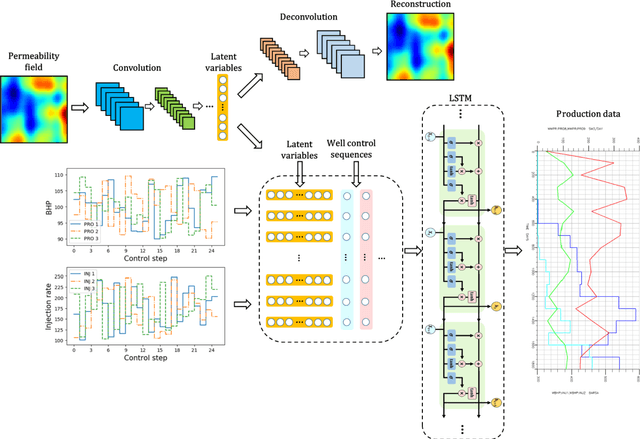
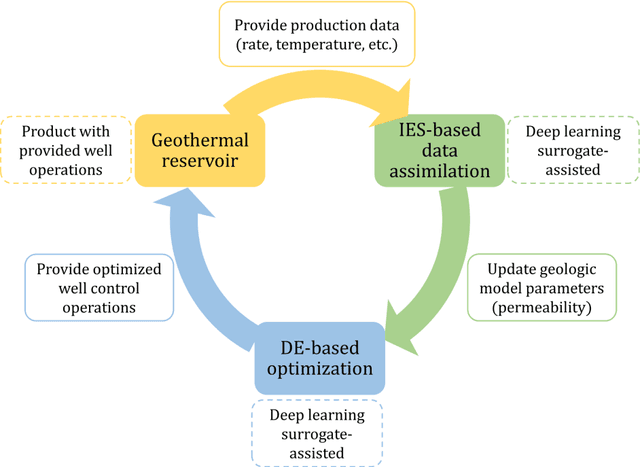
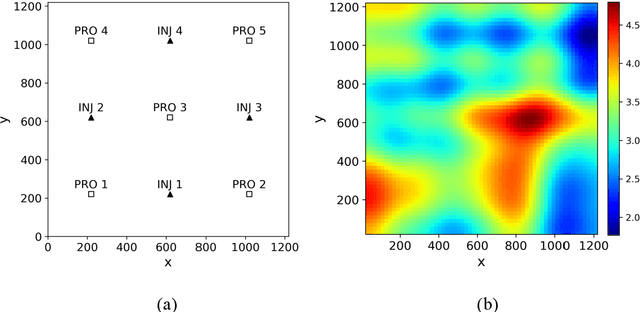
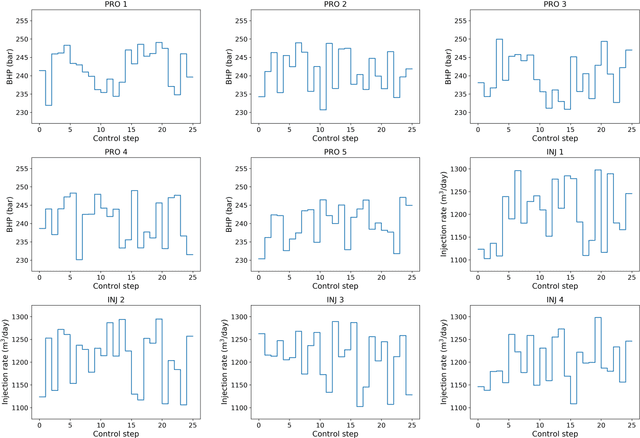
To maximize the economic benefits of geothermal energy production, it is essential to optimize geothermal reservoir management strategies, in which geologic uncertainty should be considered. In this work, we propose a closed-loop optimization framework, based on deep learning surrogates, for the well control optimization of geothermal reservoirs. In this framework, we construct a hybrid convolution-recurrent neural network surrogate, which combines the convolution neural network (CNN) and long short-term memory (LSTM) recurrent network. The convolution structure can extract spatial information of geologic parameter fields and the recurrent structure can approximate sequence-to-sequence mapping. The trained model can predict time-varying production responses (rate, temperature, etc.) for cases with different permeability fields and well control sequences. In the closed-loop optimization framework, production optimization based on the differential evolution (DE) algorithm, and data assimilation based on the iterative ensemble smoother (IES), are performed alternately to achieve real-time well control optimization and geologic parameter estimation as the production proceeds. In addition, the averaged objective function over the ensemble of geologic parameter estimations is adopted to consider geologic uncertainty in the optimization process. Several geothermal reservoir development cases are designed to test the performance of the proposed production optimization framework. The results show that the proposed framework can achieve efficient and effective real-time optimization and data assimilation in the geothermal reservoir production process.
Bandit Sampling for Multiplex Networks
Feb 08, 2022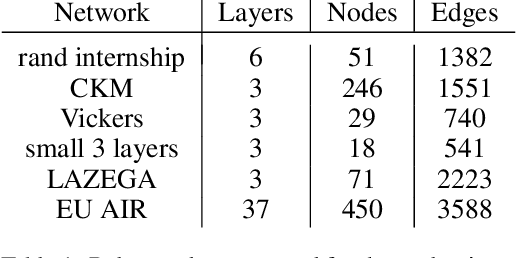
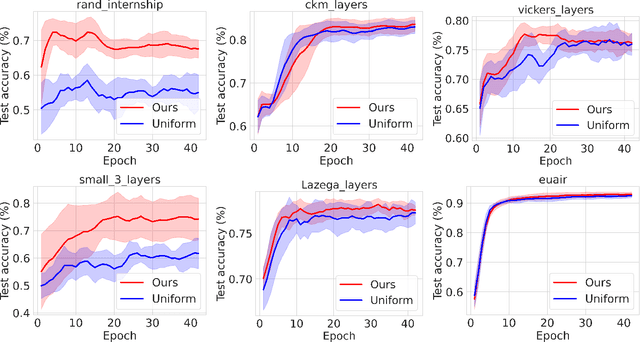
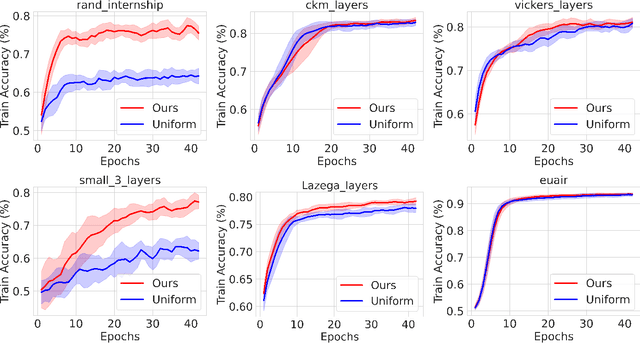
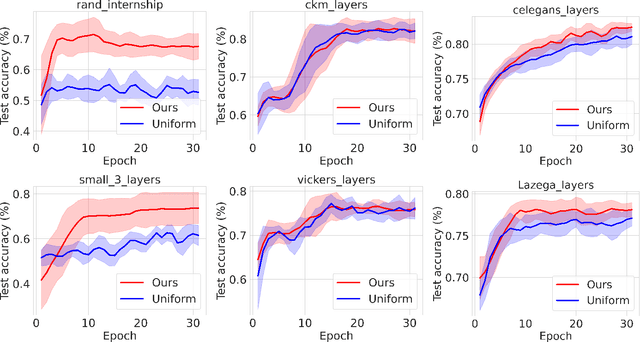
Graph neural networks have gained prominence due to their excellent performance in many classification and prediction tasks. In particular, they are used for node classification and link prediction which have a wide range of applications in social networks, biomedical data sets, and financial transaction graphs. Most of the existing work focuses primarily on the monoplex setting where we have access to a network with only a single type of connection between entities. However, in the multiplex setting, where there are multiple types of connections, or \emph{layers}, between entities, performance on tasks such as link prediction has been shown to be stronger when information from other connection types is taken into account. We propose an algorithm for scalable learning on multiplex networks with a large number of layers. The efficiency of our method is enabled by an online learning algorithm that learns how to sample relevant neighboring layers so that only the layers with relevant information are aggregated during training. This sampling differs from prior work, such as MNE, which aggregates information across \emph{all} layers and consequently leads to computational intractability on large networks. Our approach also improves on the recent layer sampling method of \textsc{DeePlex} in that the unsampled layers do not need to be trained, enabling further increases in efficiency.We present experimental results on both synthetic and real-world scenarios that demonstrate the practical effectiveness of our proposed approach.
Secure Joint Communication and Sensing
Feb 22, 2022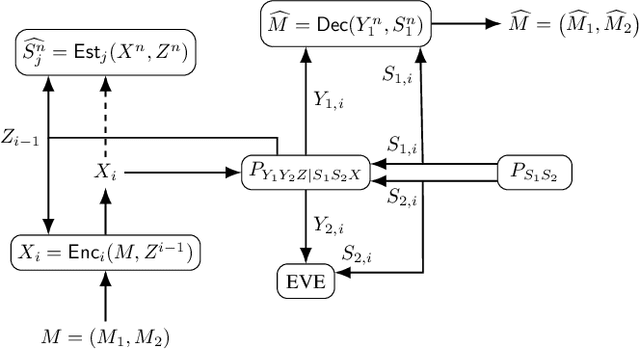
This work considers mitigation of information leakage between communication and sensing operations in joint communication and sensing systems. Specifically, a discrete memoryless state-dependent broadcast channel model is studied in which (i) the presence of feedback enables a transmitter to simultaneously achieve reliable communication and channel state estimation; (ii) one of the receivers is treated as an eavesdropper whose state should be estimated but which should remain oblivious to a part of the transmitted information. The model abstracts the challenges behind security for joint communication and sensing if one views the channel state as a characteristic of the receiver, e.g., its location. For independent identically distributed (i.i.d.) states, perfect output feedback, and when part of the transmitted message should be kept secret, a partial characterization of the secrecy-distortion region is developed. The characterization is exact when the broadcast channel is either physically-degraded or reversely-physically-degraded. The characterization is also extended to the situation in which the entire transmitted message should be kept secret. The benefits of a joint approach compared to separation-based secure communication and state-sensing methods are illustrated with a binary joint communication and sensing model.
Cylin-Painting: Seamless 360° Panoramic Image Outpainting and Beyond with Cylinder-Style Convolutions
Apr 18, 2022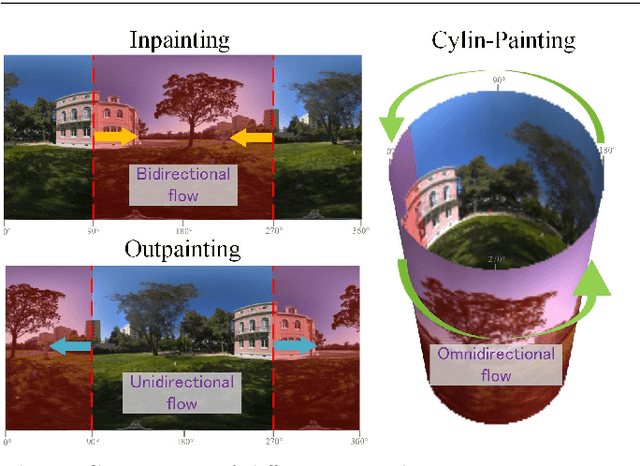
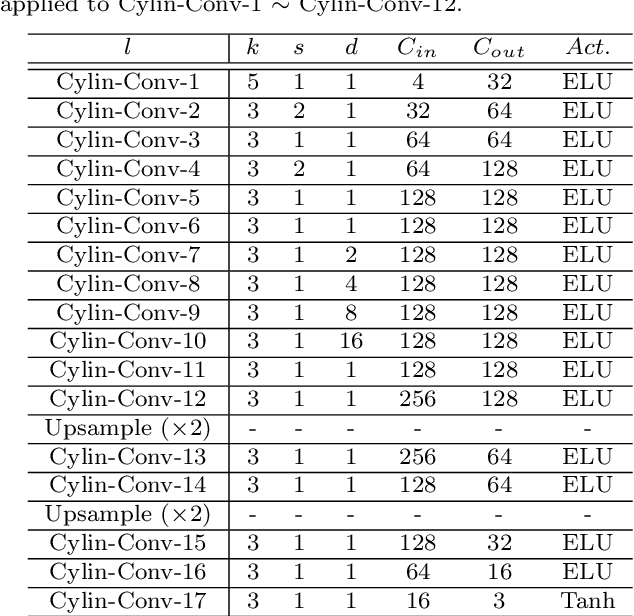
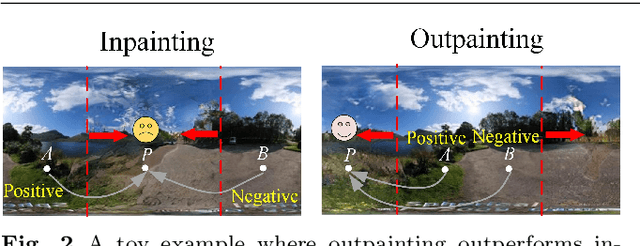
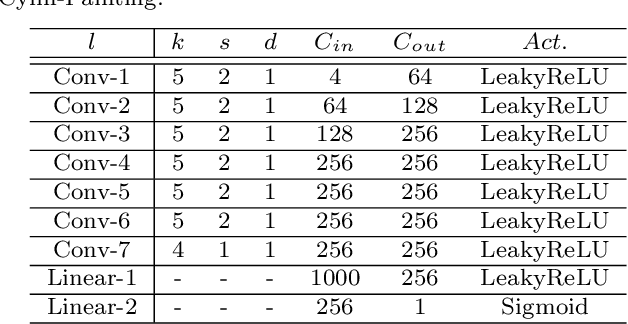
Image outpainting gains increasing attention since it can generate the complete scene from a partial view, providing a valuable solution to construct 360{\deg} panoramic images. As image outpainting suffers from the intrinsic issue of unidirectional completion flow, previous methods convert the original problem into inpainting, which allows a bidirectional flow. However, we find that inpainting has its own limitations and is inferior to outpainting in certain situations. The question of how they may be combined for the best of both has as yet remained under-explored. In this paper, we provide a deep analysis of the differences between inpainting and outpainting, which essentially depends on how the source pixels contribute to the unknown regions under different spatial arrangements. Motivated by this analysis, we present a Cylin-Painting framework that involves meaningful collaborations between inpainting and outpainting and efficiently fuses the different arrangements, with a view to leveraging their complementary benefits on a consistent and seamless cylinder. Nevertheless, directly applying the cylinder-style convolution often generates visually unpleasing results as it could discard important positional information. To address this issue, we further present a learnable positional embedding strategy and incorporate the missing component of positional encoding into the cylinder convolution, which significantly improves the panoramic results. Note that while developed for image outpainting, the proposed solution can be effectively extended to other panoramic vision tasks, such as object detection, depth estimation, and image super resolution.
Scalable and Real-time Multi-Camera Vehicle Detection, Re-Identification, and Tracking
Apr 15, 2022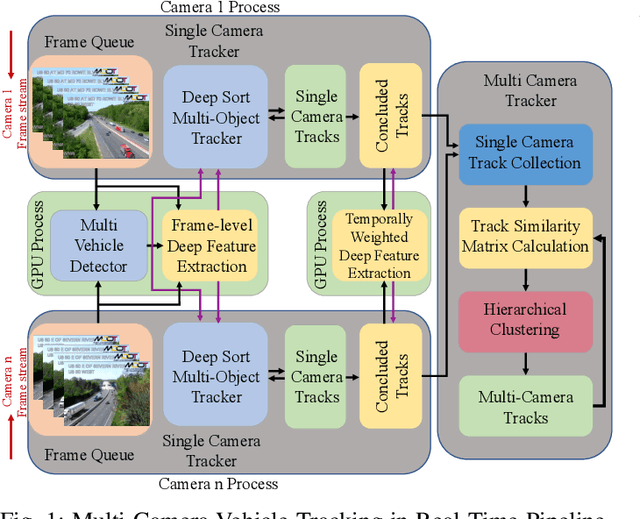

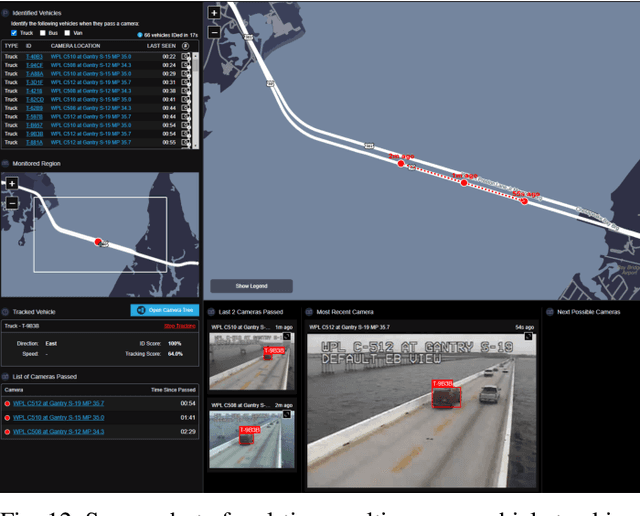
Multi-camera vehicle tracking is one of the most complicated tasks in Computer Vision as it involves distinct tasks including Vehicle Detection, Tracking, and Re-identification. Despite the challenges, multi-camera vehicle tracking has immense potential in transportation applications including speed, volume, origin-destination (O-D), and routing data generation. Several recent works have addressed the multi-camera tracking problem. However, most of the effort has gone towards improving accuracy on high-quality benchmark datasets while disregarding lower camera resolutions, compression artifacts and the overwhelming amount of computational power and time needed to carry out this task on its edge and thus making it prohibitive for large-scale and real-time deployment. Therefore, in this work we shed light on practical issues that should be addressed for the design of a multi-camera tracking system to provide actionable and timely insights. Moreover, we propose a real-time city-scale multi-camera vehicle tracking system that compares favorably to computationally intensive alternatives and handles real-world, low-resolution CCTV instead of idealized and curated video streams. To show its effectiveness, in addition to integration into the Regional Integrated Transportation Information System (RITIS), we participated in the 2021 NVIDIA AI City multi-camera tracking challenge and our method is ranked among the top five performers on the public leaderboard.
Information Bottleneck Constrained Latent Bidirectional Embedding for Zero-Shot Learning
Sep 16, 2020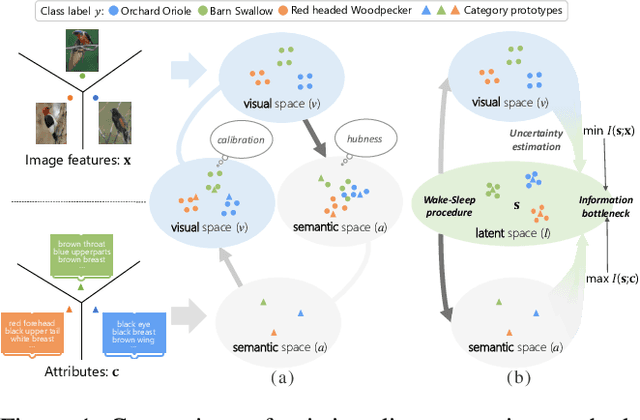
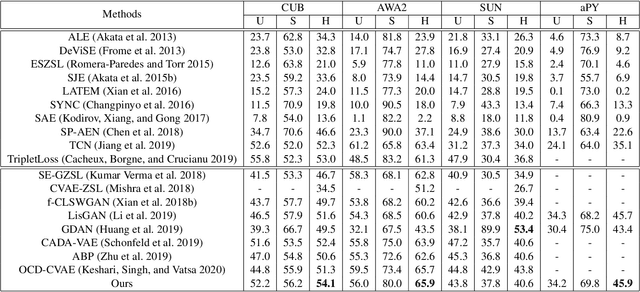
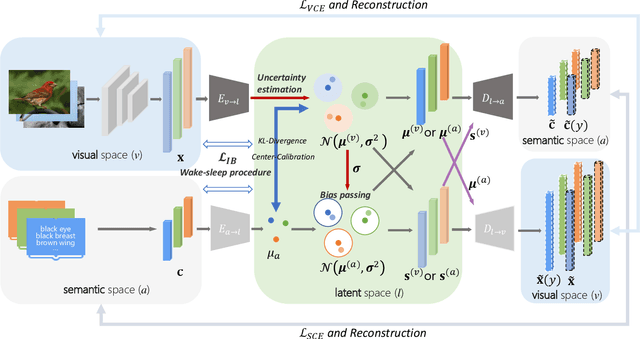
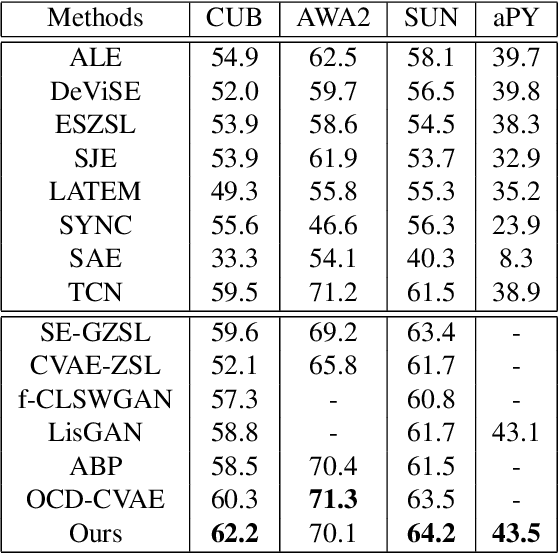
Zero-shot learning (ZSL) aims to recognize novel classes by transferring semantic knowledge from seen classes to unseen classes. Though many ZSL methods rely on a direct mapping between the visual and the semantic space, the calibration deviation and hubness problem limit the generalization capability to unseen classes. Recently emerged generative ZSL methods generate unseen image features to transform ZSL into a supervised classification problem. However, most generative models still suffer from the seen-unseen bias problem as only seen data is used for training. To address these issues, we propose a novel bidirectional embedding based generative model with a tight visual-semantic coupling constraint. We learn a unified latent space that calibrates the embedded parametric distributions of both visual and semantic spaces. Since the embedding from high-dimensional visual features comprise much non-semantic information, the alignment of visual and semantic in latent space would inevitably been deviated. Therefore, we introduce information bottleneck (IB) constraint to ZSL for the first time to preserve essential attribute information during the mapping. Specifically, we utilize the uncertainty estimation and the wake-sleep procedure to alleviate the noises and improve model abstraction capability. We evaluate the learned latent features on four benchmark datasets. Extensive experimental results show that our method outperforms the state-of-the-art methods in different ZSL settings on most benchmark datasets. The code will be available at https://github.com/osierboy/IBZSL.
ESNI: Domestic Robots Design for Elderly and Disabled People
Mar 30, 2022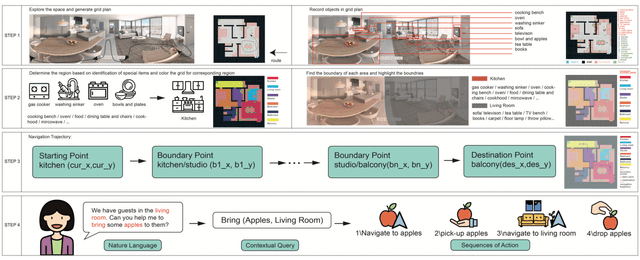
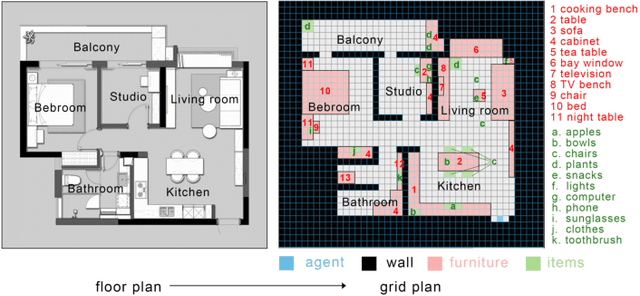
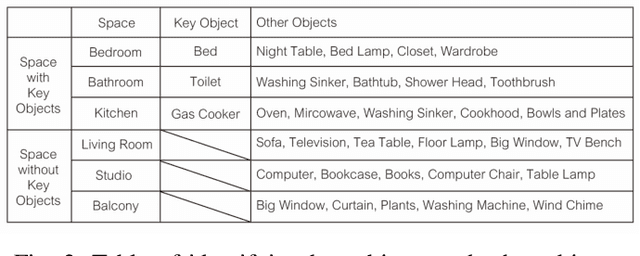
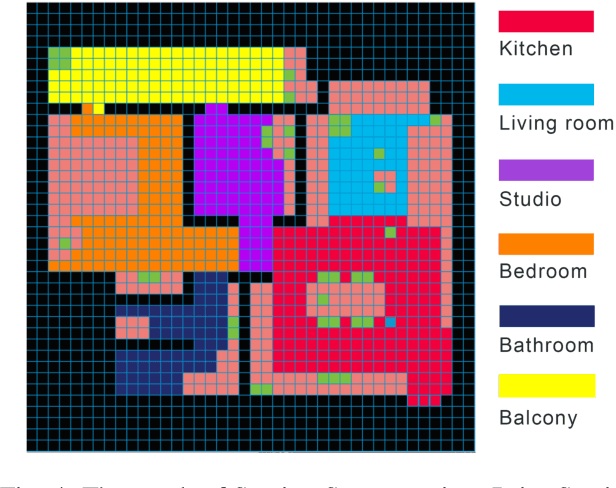
Our paper focuses on the research of the possibility for speech recognition intelligent agents to assist the elderly and disabled people's lives, to improve their life quality by utilizing cutting-edge technologies. After researching the attitude of elderly and disabled people toward the household agent, we propose a design framework: ESNI(Exploration, Segmentation, Navigation, Instruction) that apply to mobile agent, achieve some functionalities such as processing human commands, picking up a specified object, and moving an object to another location. The agent starts the exploration in an unseen environment, stores each item's information in the grid cells to his memory and analyzes the corresponding features for each section. We divided our indoor environment into 6 sections: Kitchen, Living room, Bedroom, Studio, Bathroom, Balcony. The agent uses algorithms to assign sections for each grid cell then generates a navigation trajectory base on the section segmentation. When the user gives a command to the agent, feature words will be extracted and processed into a sequence of sub-tasks.