 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Local Equivariant Representations for Large-Scale Atomistic Dynamics
Apr 11, 2022
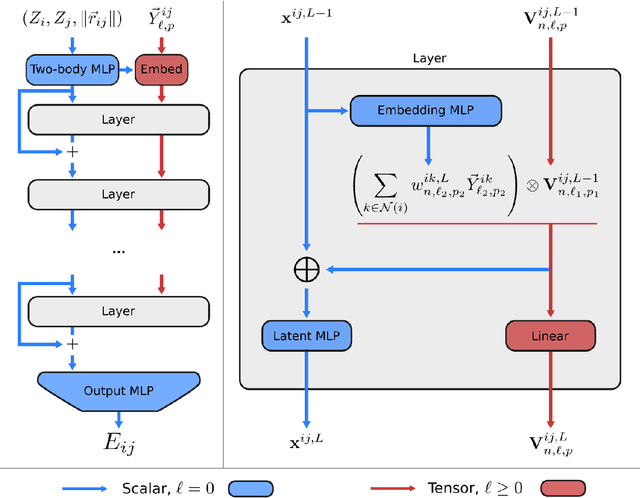
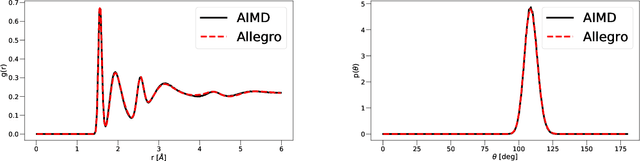
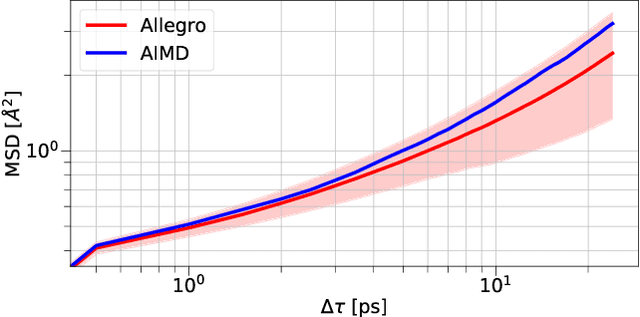
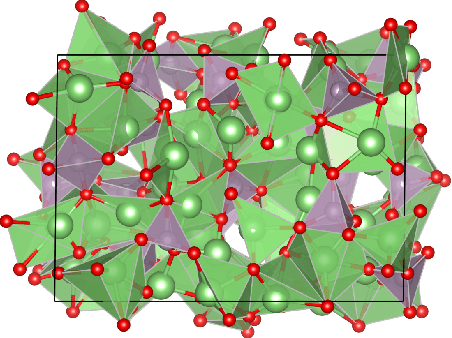
A simultaneously accurate and computationally efficient parametrization of the energy and atomic forces of molecules and materials is a long-standing goal in the natural sciences. In pursuit of this goal, neural message passing has lead to a paradigm shift by describing many-body correlations of atoms through iteratively passing messages along an atomistic graph. This propagation of information, however, makes parallel computation difficult and limits the length scales that can be studied. Strictly local descriptor-based methods, on the other hand, can scale to large systems but do not currently match the high accuracy observed with message passing approaches. This work introduces Allegro, a strictly local equivariant deep learning interatomic potential that simultaneously exhibits excellent accuracy and scalability of parallel computation. Allegro learns many-body functions of atomic coordinates using a series of tensor products of learned equivariant representations, but without relying on message passing. Allegro obtains improvements over state-of-the-art methods on the QM9 and revised MD-17 data sets. A single tensor product layer is shown to outperform existing deep message passing neural networks and transformers on the QM9 benchmark. Furthermore, Allegro displays remarkable generalization to out-of-distribution data. Molecular dynamics simulations based on Allegro recover structural and kinetic properties of an amorphous phosphate electrolyte in excellent agreement with first principles calculations. Finally, we demonstrate the parallel scaling of Allegro with a dynamics simulation of 100 million atoms.
Controlling Information Capacity of Binary Neural Network
Aug 04, 2020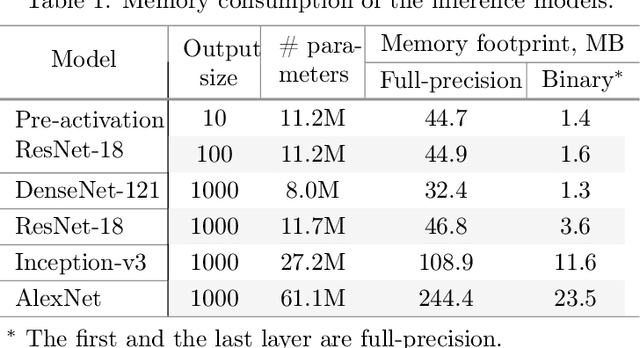
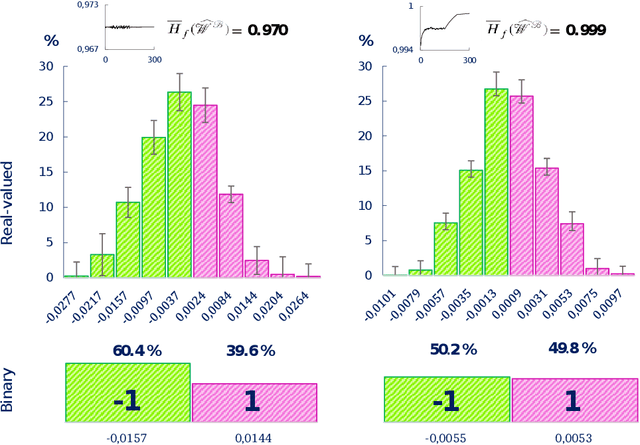
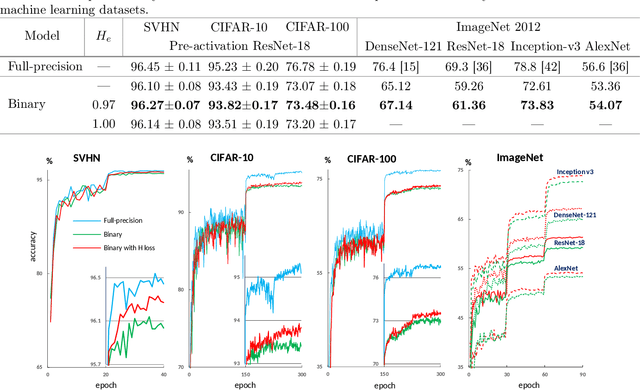
Despite the growing popularity of deep learning technologies, high memory requirements and power consumption are essentially limiting their application in mobile and IoT areas. While binary convolutional networks can alleviate these problems, the limited bitwidth of weights is often leading to significant degradation of prediction accuracy. In this paper, we present a method for training binary networks that maintains a stable predefined level of their information capacity throughout the training process by applying Shannon entropy based penalty to convolutional filters. The results of experiments conducted on SVHN, CIFAR and ImageNet datasets demonstrate that the proposed approach can statistically significantly improve the accuracy of binary networks.
A posteriori learning for quasi-geostrophic turbulence parametrization
Apr 08, 2022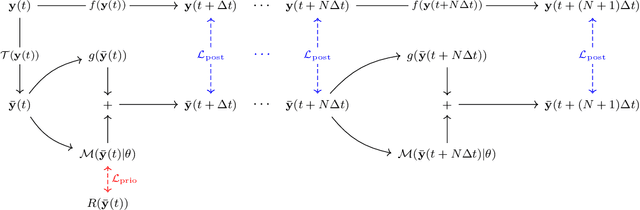

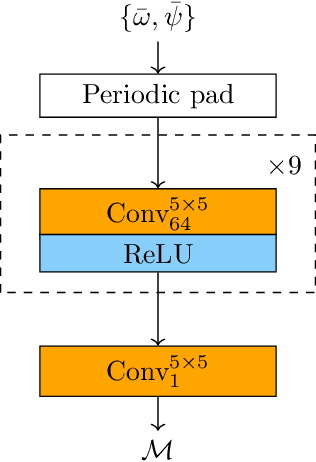
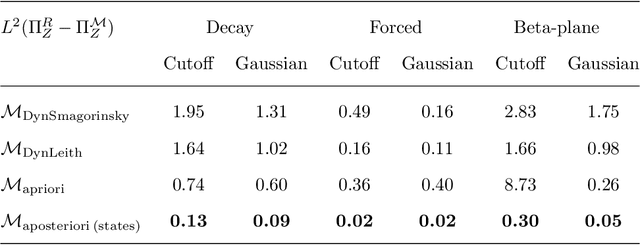
The use of machine learning to build subgrid parametrizations for climate models is receiving growing attention. State-of-the-art strategies address the problem as a supervised learning task and optimize algorithms that predict subgrid fluxes based on information from coarse resolution models. In practice, training data are generated from higher resolution numerical simulations transformed in order to mimic coarse resolution simulations. By essence, these strategies optimize subgrid parametrizations to meet so-called $\textit{a priori}$ criteria. But the actual purpose of a subgrid parametrization is to obtain good performance in terms of $\textit{a posteriori}$ metrics which imply computing entire model trajectories. In this paper, we focus on the representation of energy backscatter in two dimensional quasi-geostrophic turbulence and compare parametrizations obtained with different learning strategies at fixed computational complexity. We show that strategies based on $\textit{a priori}$ criteria yield parametrizations that tend to be unstable in direct simulations and describe how subgrid parametrizations can alternatively be trained end-to-end in order to meet $\textit{a posteriori}$ criteria. We illustrate that end-to-end learning strategies yield parametrizations that outperform known empirical and data-driven schemes in terms of performance, stability and ability to apply to different flow configurations. These results support the relevance of differentiable programming paradigms for climate models in the future.
PICASSO: Unleashing the Potential of GPU-centric Training for Wide-and-deep Recommender Systems
Apr 17, 2022

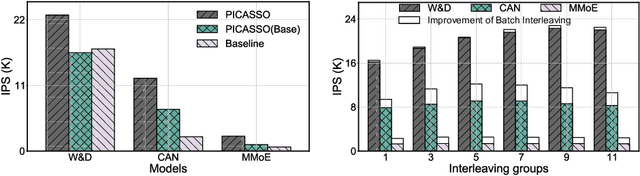
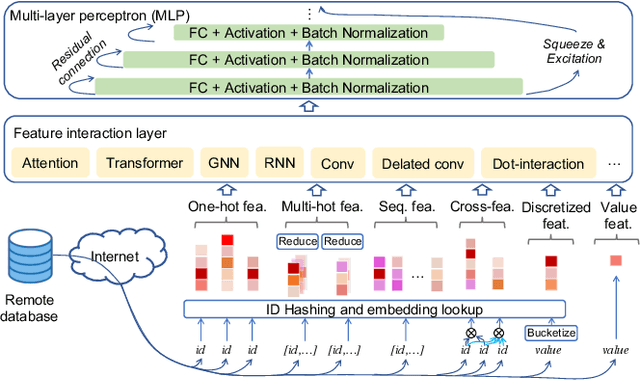
The development of personalized recommendation has significantly improved the accuracy of information matching and the revenue of e-commerce platforms. Recently, it has 2 trends: 1) recommender systems must be trained timely to cope with ever-growing new products and ever-changing user interests from online marketing and social network; 2) SOTA recommendation models introduce DNN modules to improve prediction accuracy. Traditional CPU-based recommender systems cannot meet these two trends, and GPU- centric training has become a trending approach. However, we observe that GPU devices in training recommender systems are underutilized, and they cannot attain an expected throughput improvement as what it has achieved in CV and NLP areas. This issue can be explained by two characteristics of these recommendation models: First, they contain up to a thousand input feature fields, introducing fragmentary and memory-intensive operations; Second, the multiple constituent feature interaction submodules introduce substantial small-sized compute kernels. To remove this roadblock to the development of recommender systems, we propose a novel framework named PICASSO to accelerate the training of recommendation models on commodity hardware. Specifically, we conduct a systematic analysis to reveal the bottlenecks encountered in training recommendation models. We leverage the model structure and data distribution to unleash the potential of hardware through our packing, interleaving, and caching optimization. Experiments show that PICASSO increases the hardware utilization by an order of magnitude on the basis of SOTA baselines and brings up to 6x throughput improvement for a variety of industrial recommendation models. Using the same hardware budget in production, PICASSO on average shortens the walltime of daily training tasks by 7 hours, significantly reducing the delay of continuous delivery.
Three-dimensional Microstructural Image Synthesis from 2D Backscattered Electron Image of Cement Paste
Apr 04, 2022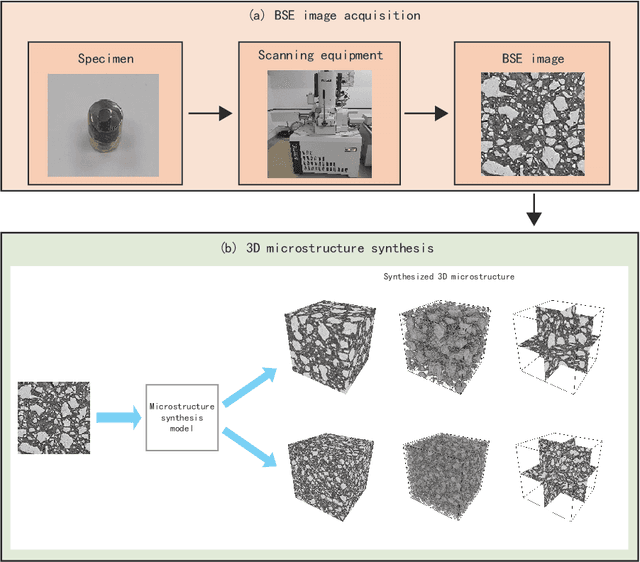
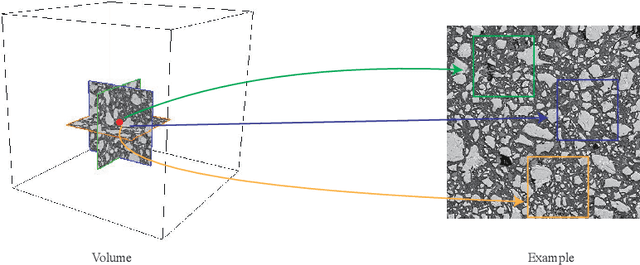
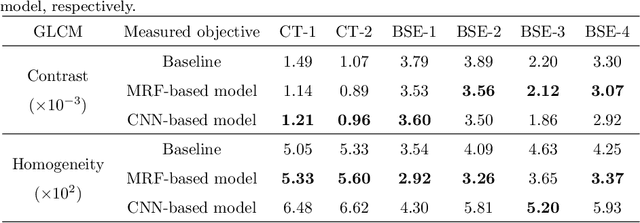
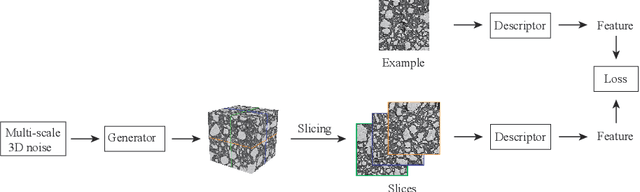
The microstructure is significant for exploring the physical properties of hardened cement paste. In general, the microstructures of hardened cement paste are obtained by microscopy. As a popular method, scanning electron microscopy (SEM) can acquire high-quality 2D images but fails to obtain 3D microstructures.Although several methods, such as microtomography (Micro-CT) and Focused Ion Beam Scanning Electron Microscopy (FIB-SEM), can acquire 3D microstructures, these fail to obtain high-quality 3D images or consume considerable cost. To address these issues, a method based on solid texture synthesis is proposed, synthesizing high-quality 3D microstructural image of hardened cement paste. This method includes 2D backscattered electron (BSE) image acquisition and 3D microstructure synthesis phases. In the approach, the synthesis model is based on solid texture synthesis, capturing microstructure information of the acquired 2D BSE image and generating high-quality 3D microstructures. In experiments, the method is verified on actual 3D Micro-CT images and 2D BSE images. Finally, qualitative experiments demonstrate that the 3D microstructures generated by our method have similar visual characteristics to the given 2D example. Furthermore, quantitative experiments prove that the synthetic 3D results are consistent with the actual instance in terms of porosity, particle size distribution, and grey scale co-occurrence matrix.
Is Non-IID Data a Threat in Federated Online Learning to Rank?
Apr 20, 2022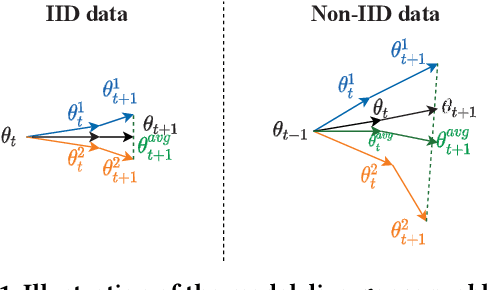
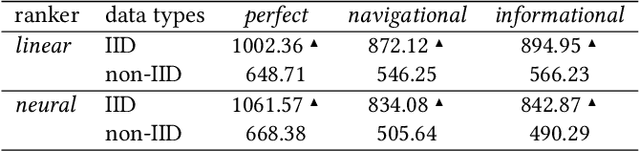
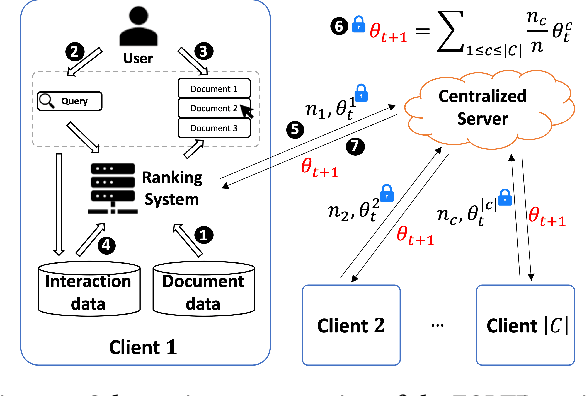
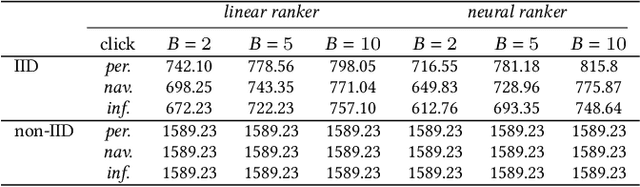
In this perspective paper we study the effect of non independent and identically distributed (non-IID) data on federated online learning to rank (FOLTR) and chart directions for future work in this new and largely unexplored research area of Information Retrieval. In the FOLTR process, clients join a federation to jointly create an effective ranker from the implicit click signal originating in each client, without the need to share data (documents, queries, clicks). A well-known factor that affects the performance of federated learning systems, and that poses serious challenges to these approaches, is the fact that there may be some type of bias in the way the data is distributed across clients. While FOLTR systems are on their own rights a type of federated learning system, the presence and effect of non-IID data in FOLTR has not been studied. To this aim, we first enumerate possible data distribution settings that may showcase data bias across clients and thus give rise to the non-IID problem. Then, we study the impact of each of these settings on the performance of the current state-of-the-art FOLTR approach, the Federated Pairwise Differentiable Gradient Descent (FPDGD), and we highlight which data distributions may pose a problem for FOLTR methods. We also explore how common approaches proposed in the federated learning literature address non-IID issues in FOLTR. This allows us to unveil new research gaps that, we argue, future research in FOLTR should consider. This is an important contribution to the current state of the field of FOLTR because, for FOLTR systems to be deployed, the factors affecting their performance, including the impact of non-IID data, need to thoroughly be understood.
DiffSkill: Skill Abstraction from Differentiable Physics for Deformable Object Manipulations with Tools
Mar 31, 2022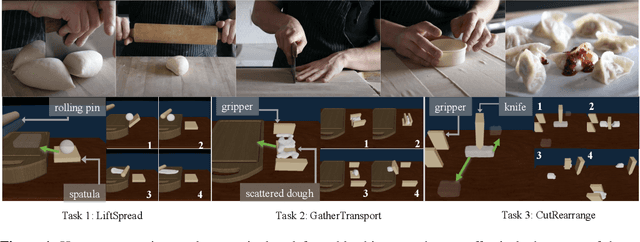
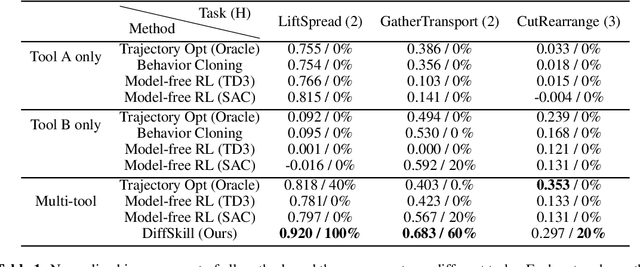
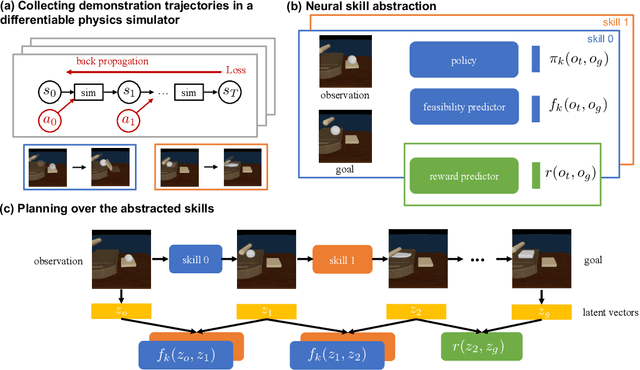
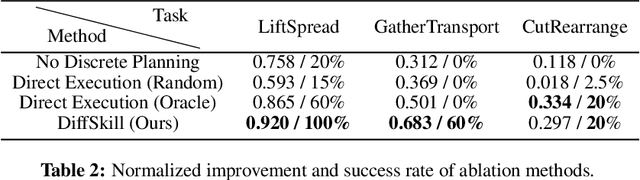
We consider the problem of sequential robotic manipulation of deformable objects using tools. Previous works have shown that differentiable physics simulators provide gradients to the environment state and help trajectory optimization to converge orders of magnitude faster than model-free reinforcement learning algorithms for deformable object manipulation. However, such gradient-based trajectory optimization typically requires access to the full simulator states and can only solve short-horizon, single-skill tasks due to local optima. In this work, we propose a novel framework, named DiffSkill, that uses a differentiable physics simulator for skill abstraction to solve long-horizon deformable object manipulation tasks from sensory observations. In particular, we first obtain short-horizon skills using individual tools from a gradient-based optimizer, using the full state information in a differentiable simulator; we then learn a neural skill abstractor from the demonstration trajectories which takes RGBD images as input. Finally, we plan over the skills by finding the intermediate goals and then solve long-horizon tasks. We show the advantages of our method in a new set of sequential deformable object manipulation tasks compared to previous reinforcement learning algorithms and compared to the trajectory optimizer.
Point Cloud Denoising via Momentum Ascent in Gradient Fields
Mar 15, 2022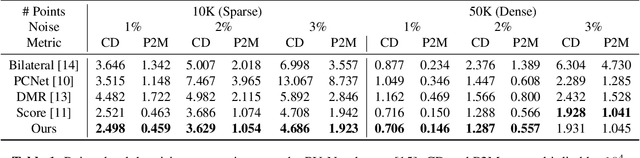
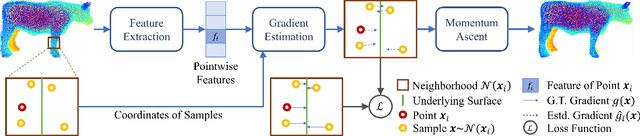

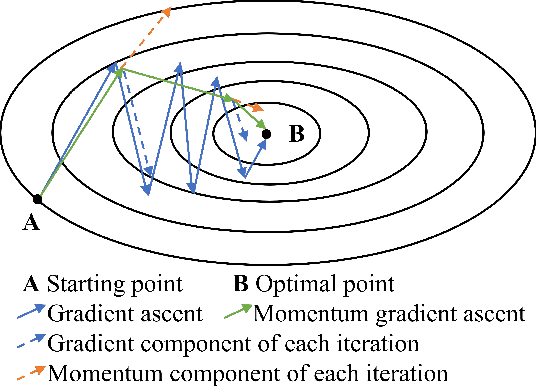
To achieve point cloud denoising, traditional methods heavily rely on geometric priors, and most learning-based approaches suffer from outliers and loss of details. Recently, the gradient-based method was proposed to estimate the gradient fields from the noisy point clouds using neural networks, and refine the position of each point according to the estimated gradient. However, the predicted gradient could fluctuate, leading to perturbed and unstable solutions, as well as a large inference time. To address these issues, we develop the momentum gradient ascent method that leverages the information of previous iterations in determining the trajectories of the points, thus improving the stability of the solution and reducing the inference time. Experiments demonstrate that the proposed method outperforms state-of-the-art methods with a variety of point clouds and noise levels.
M^2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation
Apr 11, 2022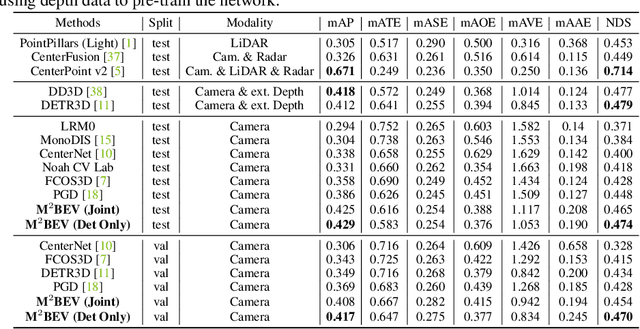
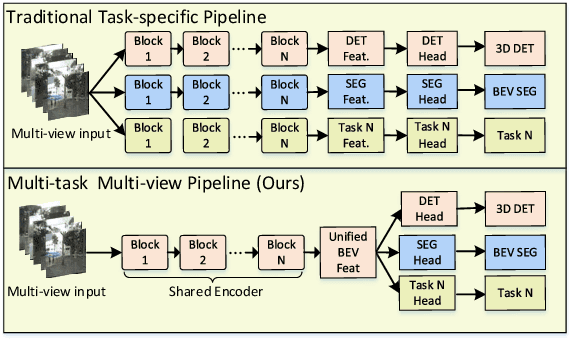
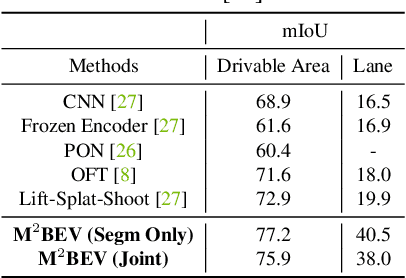
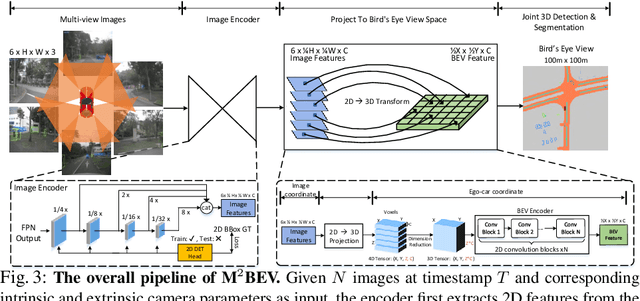
In this paper, we propose M$^2$BEV, a unified framework that jointly performs 3D object detection and map segmentation in the Birds Eye View~(BEV) space with multi-camera image inputs. Unlike the majority of previous works which separately process detection and segmentation, M$^2$BEV infers both tasks with a unified model and improves efficiency. M$^2$BEV efficiently transforms multi-view 2D image features into the 3D BEV feature in ego-car coordinates. Such BEV representation is important as it enables different tasks to share a single encoder. Our framework further contains four important designs that benefit both accuracy and efficiency: (1) An efficient BEV encoder design that reduces the spatial dimension of a voxel feature map. (2) A dynamic box assignment strategy that uses learning-to-match to assign ground-truth 3D boxes with anchors. (3) A BEV centerness re-weighting that reinforces with larger weights for more distant predictions, and (4) Large-scale 2D detection pre-training and auxiliary supervision. We show that these designs significantly benefit the ill-posed camera-based 3D perception tasks where depth information is missing. M$^2$BEV is memory efficient, allowing significantly higher resolution images as input, with faster inference speed. Experiments on nuScenes show that M$^2$BEV achieves state-of-the-art results in both 3D object detection and BEV segmentation, with the best single model achieving 42.5 mAP and 57.0 mIoU in these two tasks, respectively.
Clutter Edges Detection Algorithms for Structured Clutter Covariance Matrices
Feb 03, 2022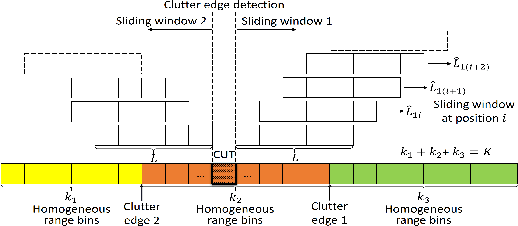
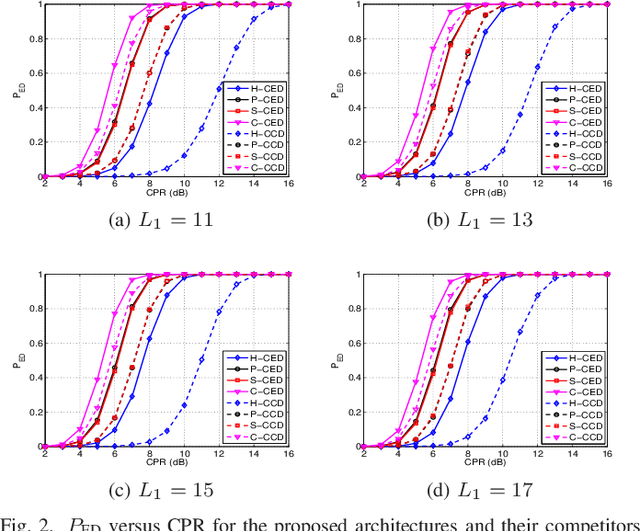
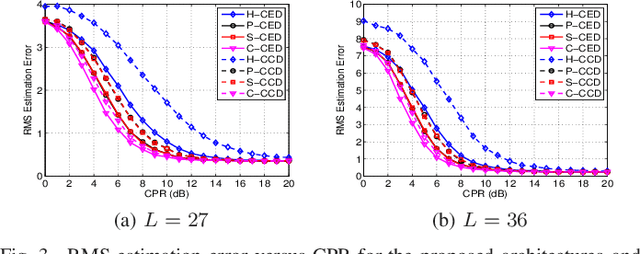
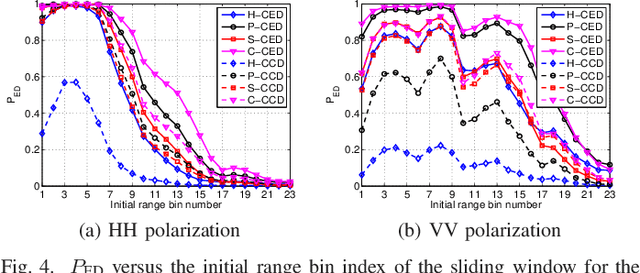
This letter deals with the problem of clutter edge detection and localization in training data. To this end, the problem is formulated as a binary hypothesis test assuming that the ranks of the clutter covariance matrix are known, and adaptive architectures are designed based on the generalized likelihood ratio test to decide whether the training data within a sliding window contains a homogeneous set or two heterogeneous subsets. In the design stage, we utilize four different covariance matrix structures (i.e., Hermitian, persymmetric, symmetric, and centrosymmetric) to exploit the a priori information. Then, for the case of unknown ranks, the architectures are extended by devising a preliminary estimation stage resorting to the model order selection rules. Numerical examples based on both synthetic and real data highlight that the proposed solutions possess superior detection and localization performance with respect to the competitors that do not use any a priori information.