 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Video Salient Object Detection Progressively from Unlabeled Videos
Apr 05, 2022
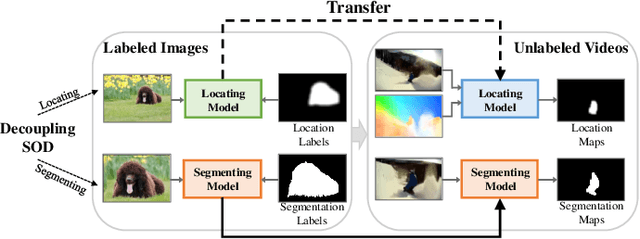
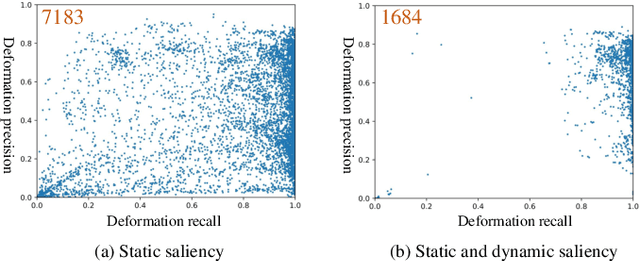
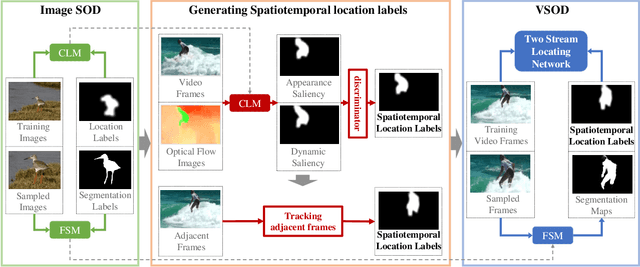
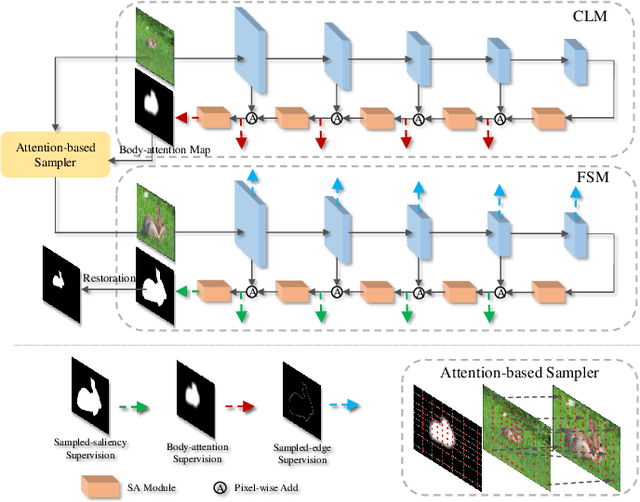
Recent deep learning-based video salient object detection (VSOD) has achieved some breakthrough, but these methods rely on expensive annotated videos with pixel-wise annotations, weak annotations, or part of the pixel-wise annotations. In this paper, based on the similarities and the differences between VSOD and image salient object detection (SOD), we propose a novel VSOD method via a progressive framework that locates and segments salient objects in sequence without utilizing any video annotation. To use the knowledge learned in the SOD dataset for VSOD efficiently, we introduce dynamic saliency to compensate for the lack of motion information of SOD during the locating process but retain the same fine segmenting process. Specifically, an algorithm for generating spatiotemporal location labels, which consists of generating high-saliency location labels and tracking salient objects in adjacent frames, is proposed. Based on these location labels, a two-stream locating network that introduces an optical flow branch for video salient object locating is presented. Although our method does not require labeled video at all, the experimental results on five public benchmarks of DAVIS, FBMS, ViSal, VOS, and DAVSOD demonstrate that our proposed method is competitive with fully supervised methods and outperforms the state-of-the-art weakly and unsupervised methods.
Predicting Intervention Approval in Clinical Trials through Multi-Document Summarization
Apr 01, 2022

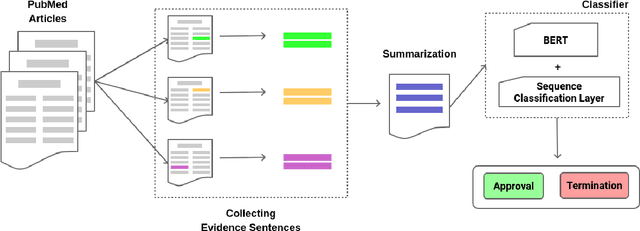
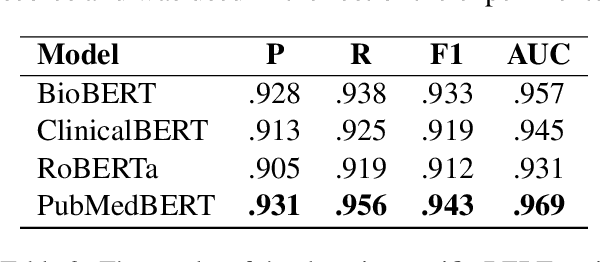
Clinical trials offer a fundamental opportunity to discover new treatments and advance the medical knowledge. However, the uncertainty of the outcome of a trial can lead to unforeseen costs and setbacks. In this study, we propose a new method to predict the effectiveness of an intervention in a clinical trial. Our method relies on generating an informative summary from multiple documents available in the literature about the intervention under study. Specifically, our method first gathers all the abstracts of PubMed articles related to the intervention. Then, an evidence sentence, which conveys information about the effectiveness of the intervention, is extracted automatically from each abstract. Based on the set of evidence sentences extracted from the abstracts, a short summary about the intervention is constructed. Finally, the produced summaries are used to train a BERT-based classifier, in order to infer the effectiveness of an intervention. To evaluate our proposed method, we introduce a new dataset which is a collection of clinical trials together with their associated PubMed articles. Our experiments, demonstrate the effectiveness of producing short informative summaries and using them to predict the effectiveness of an intervention.
MHTTS: Fast multi-head text-to-speech for spontaneous speech with imperfect transcription
Feb 04, 2022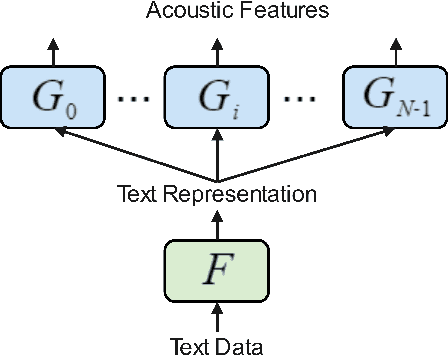
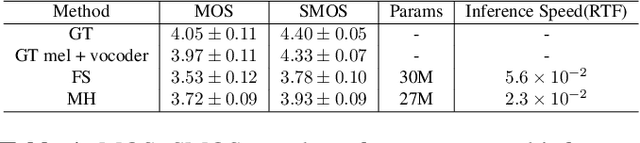
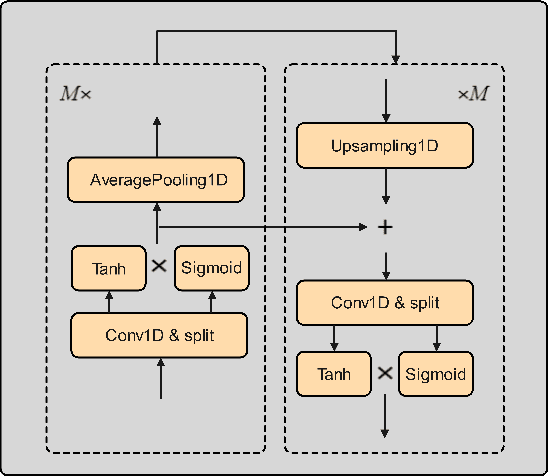
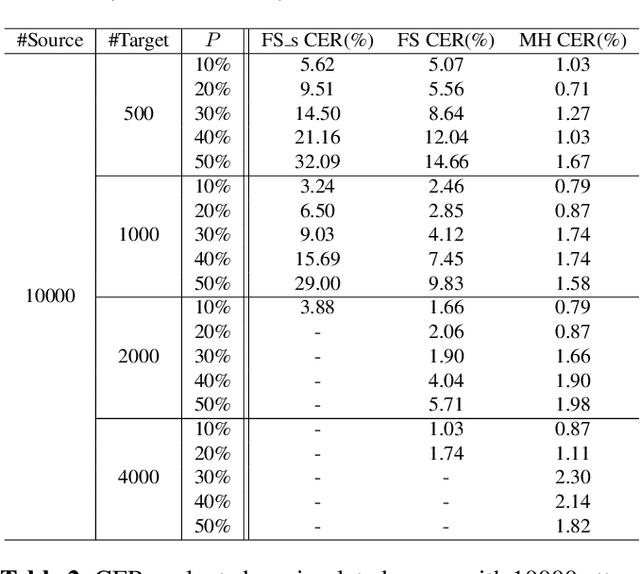
Neural network based end-to-end Text-to-Speech (TTS) has greatly improved the quality of synthesized speech. While how to use massive spontaneous speech without transcription efficiently still remains an open problem. In this paper, we propose MHTTS, a fast multi-speaker TTS system that is robust to transcription errors and speaking style speech data. Specifically, we introduce a multi-head model and transfer text information from high-quality corpus with manual transcription to spontaneous speech with imperfectly recognized transcription by jointly training them. MHTTS has three advantages: 1) Our system synthesizes better quality multi-speaker voice with faster inference speed. 2) Our system is capable of transferring correct text information to data with imperfect transcription, simulated using corruption, or provided by an Automatic Speech Recogniser (ASR). 3) Our system can utilize massive real spontaneous speech with imperfect transcription and synthesize expressive voice.
Boolean Observation Games
Feb 08, 2022

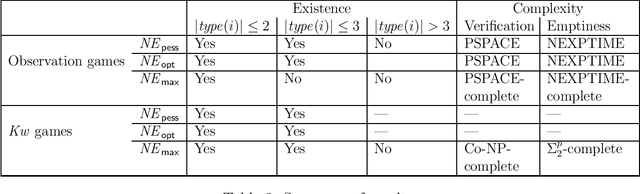
We introduce Boolean Observation Games, a subclass of multi-player finite strategic games with incomplete information and qualitative objectives. In Boolean observation games, each player is associated with a finite set of propositional variables of which only it can observe the value, and it controls whether and to whom it can reveal that value. It does not control the given, fixed, value of variables. Boolean observation games are a generalization of Boolean games, a well-studied subclass of strategic games but with complete information, and wherein each player controls the value of its variables. In Boolean observation games player goals describe multi-agent knowledge of variables. As in classical strategic games, players choose their strategies simultaneously and therefore observation games capture aspects of both imperfect and incomplete information. They require reasoning about sets of outcomes given sets of indistinguishable valuations of variables. What a Nash equilibrium is, depends on an outcome relation between such sets. We present various outcome relations, including a qualitative variant of ex-post equilibrium. We identify conditions under which, given an outcome relation, Nash equilibria are guaranteed to exist. We also study the complexity of checking for the existence of Nash equilibria and of verifying if a strategy profile is a Nash equilibrium. We further study the subclass of Boolean observation games with `knowing whether' goal formulas, for which the satisfaction does not depend on the value of variables. We show that each such Boolean observation game corresponds to a Boolean game and vice versa, by a different correspondence, and that both correspondences are precise in terms of existence of Nash equilibria.
DeepAD: A Robust Deep Learning Model of Alzheimer's Disease Progression for Real-World Clinical Applications
Apr 08, 2022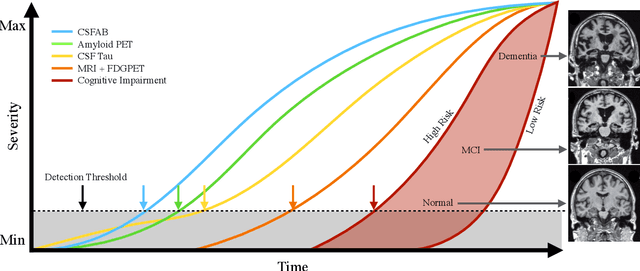
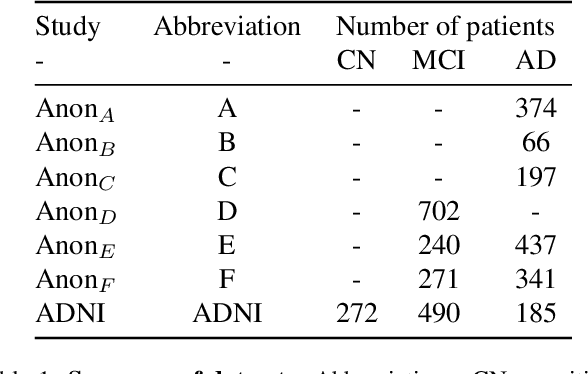
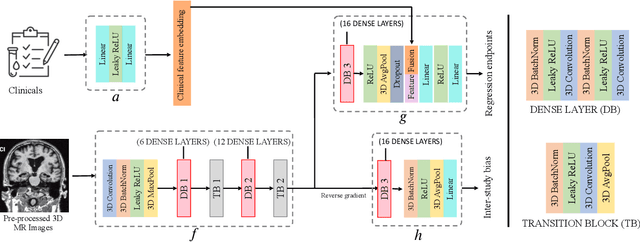
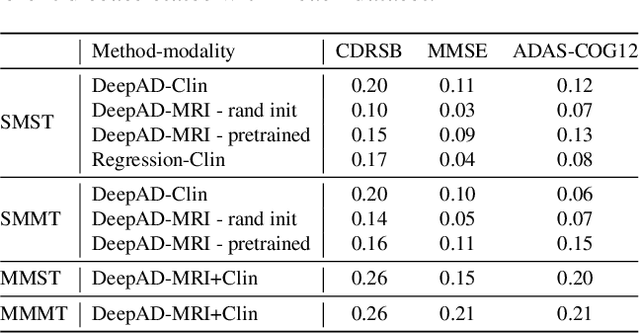
The ability to predict the future trajectory of a patient is a key step toward the development of therapeutics for complex diseases such as Alzheimer's disease (AD). However, most machine learning approaches developed for prediction of disease progression are either single-task or single-modality models, which can not be directly adopted to our setting involving multi-task learning with high dimensional images. Moreover, most of those approaches are trained on a single dataset (i.e. cohort), which can not be generalized to other cohorts. We propose a novel multimodal multi-task deep learning model to predict AD progression by analyzing longitudinal clinical and neuroimaging data from multiple cohorts. Our proposed model integrates high dimensional MRI features from a 3D convolutional neural network with other data modalities, including clinical and demographic information, to predict the future trajectory of patients. Our model employs an adversarial loss to alleviate the study-specific imaging bias, in particular the inter-study domain shifts. In addition, a Sharpness-Aware Minimization (SAM) optimization technique is applied to further improve model generalization. The proposed model is trained and tested on various datasets in order to evaluate and validate the results. Our results showed that 1) our model yields significant improvement over the baseline models, and 2) models using extracted neuroimaging features from 3D convolutional neural network outperform the same models when applied to MRI-derived volumetric features.
Micro-Behavior Encoding for Session-based Recommendation
Apr 05, 2022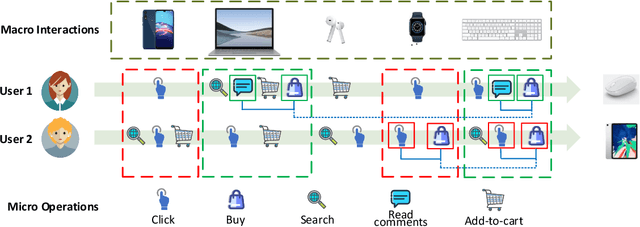
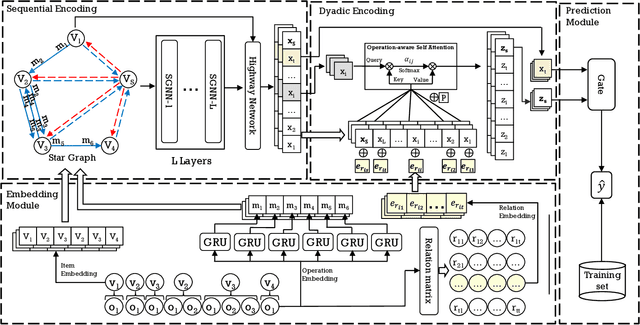
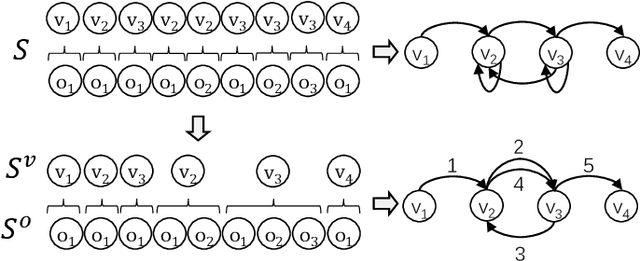
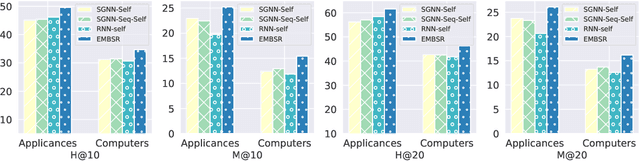
Session-based Recommendation (SR) aims to predict the next item for recommendation based on previously recorded sessions of user interaction. The majority of existing approaches to SR focus on modeling the transition patterns of items. In such models, the so-called micro-behaviors describing how the user locates an item and carries out various activities on it (e.g., click, add-to-cart, and read-comments), are simply ignored. A few recent studies have tried to incorporate the sequential patterns of micro-behaviors into SR models. However, those sequential models still cannot effectively capture all the inherent interdependencies between micro-behavior operations. In this work, we aim to investigate the effects of the micro-behavior information in SR systematically. Specifically, we identify two different patterns of micro-behaviors: "sequential patterns" and "dyadic relational patterns". To build a unified model of user micro-behaviors, we first devise a multigraph to aggregate the sequential patterns from different items via a graph neural network, and then utilize an extended self-attention network to exploit the pair-wise relational patterns of micro-behaviors. Extensive experiments on three public real-world datasets show the superiority of the proposed approach over the state-of-theart baselines and confirm the usefulness of these two different micro-behavior patterns for SR.
Measuring Diversity in Heterogeneous Information Networks
Jan 10, 2020
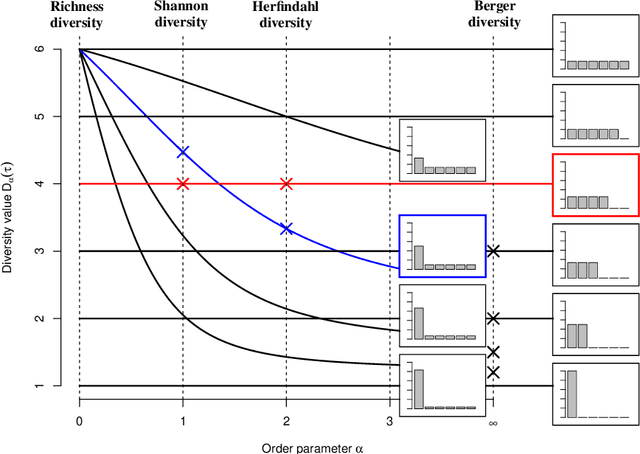
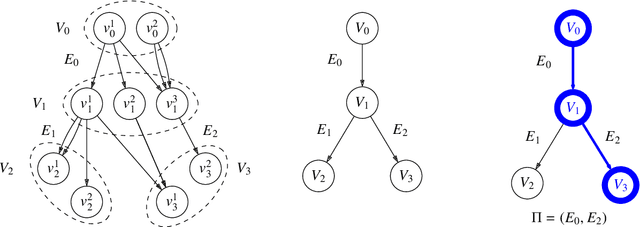

Diversity is a concept relevant to numerous domains of research varying from ecology, to information theory, and to economics, to cite a few. It is a notion that is steadily gaining attention in the information retrieval, network analysis, and artificial neural networks communities. While the use of diversity measures in network-structured data counts a growing number of applications, no clear and comprehensive description is available for the different ways in which diversities can be measured. In this article, we develop a formal framework for the application of a large family of diversity measures to heterogeneous information networks (HINs), a flexible, widely-used network data formalism. This extends the application of diversity measures, from systems of classifications and apportionments, to more complex relations that can be better modeled by networks. In doing so, we not only provide an effective organization of multiple practices from different domains, but also unearth new observables in systems modeled by heterogeneous information networks. We illustrate the pertinence of our approach by developing different applications related to various domains concerned by both diversity and networks. In particular, we illustrate the usefulness of these new proposed observables in the domains of recommender systems and social media studies, among other fields.
Fully End-to-end Autonomous Driving with Semantic Depth Cloud Mapping and Multi-Agent
Apr 12, 2022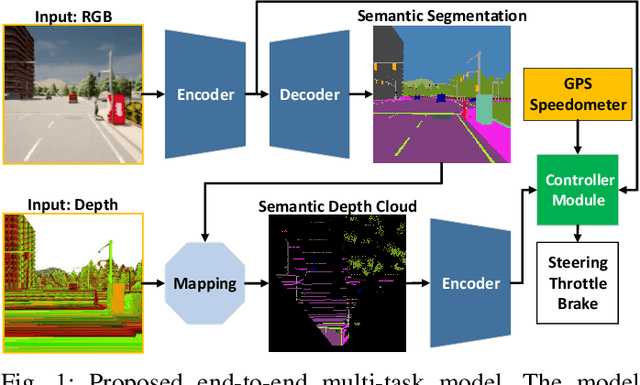
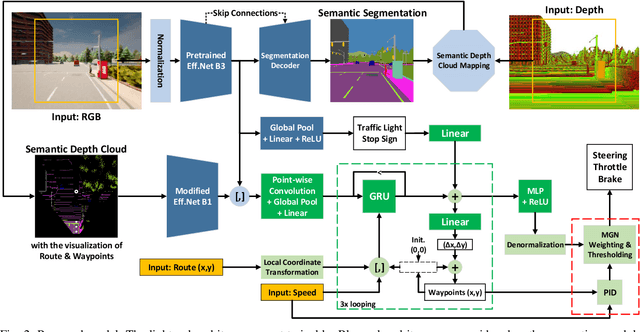
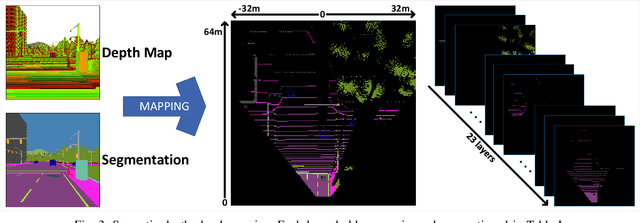
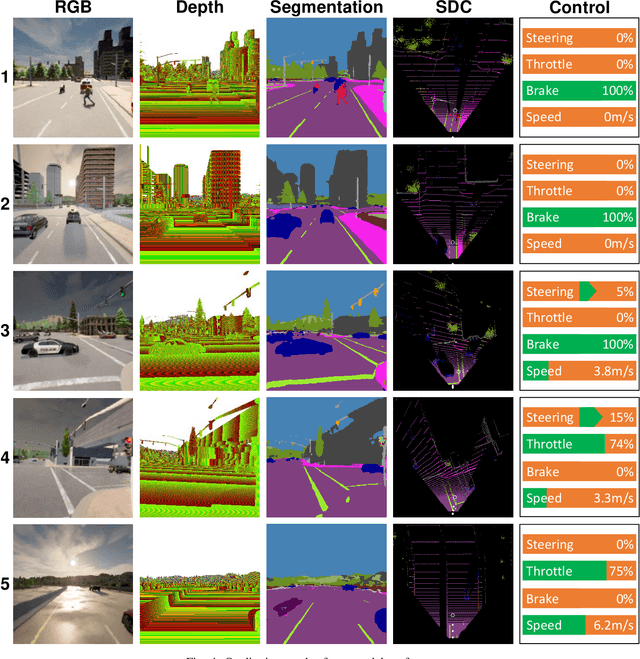
Focusing on the task of point-to-point navigation for an autonomous driving vehicle, we propose a novel deep learning model trained with end-to-end and multi-task learning manners to perform both perception and control tasks simultaneously. The model is used to drive the ego vehicle safely by following a sequence of routes defined by the global planner. The perception part of the model is used to encode high-dimensional observation data provided by an RGBD camera while performing semantic segmentation, semantic depth cloud (SDC) mapping, and traffic light state and stop sign prediction. Then, the control part decodes the encoded features along with additional information provided by GPS and speedometer to predict waypoints that come with a latent feature space. Furthermore, two agents are employed to process these outputs and make a control policy that determines the level of steering, throttle, and brake as the final action. The model is evaluated on CARLA simulator with various scenarios made of normal-adversarial situations and different weathers to mimic real-world conditions. In addition, we do a comparative study with some recent models to justify the performance in multiple aspects of driving. Moreover, we also conduct an ablation study on SDC mapping and multi-agent to understand their roles and behavior. As a result, our model achieves the highest driving score even with fewer parameters and computation load. To support future studies, we share our codes at https://github.com/oskarnatan/end-to-end-driving.
BioRED: A Comprehensive Biomedical Relation Extraction Dataset
Apr 08, 2022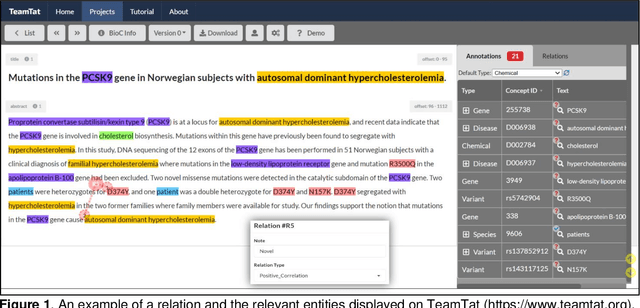
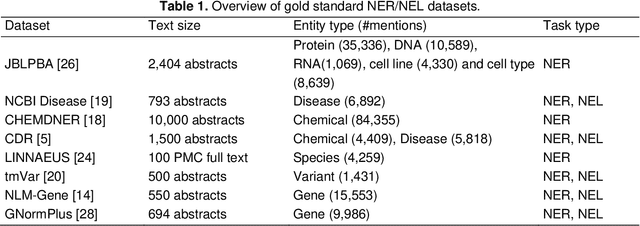
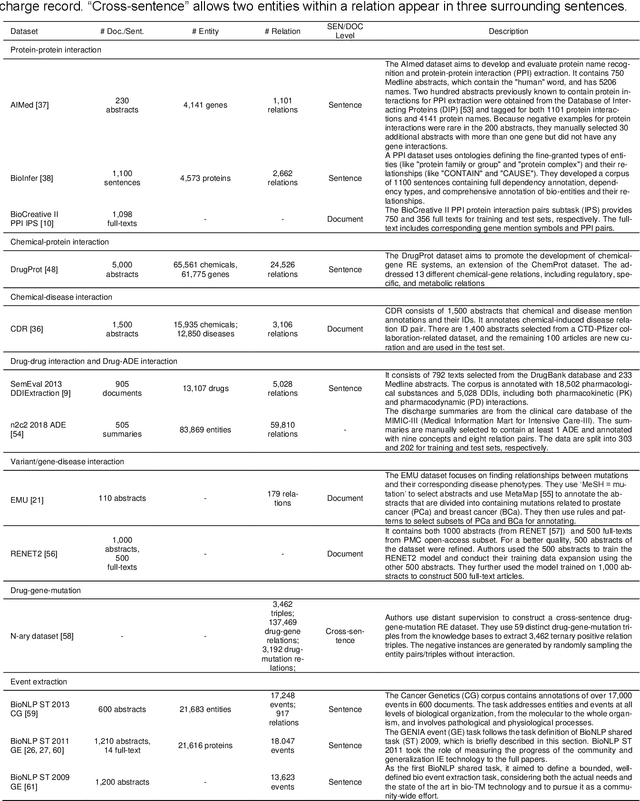
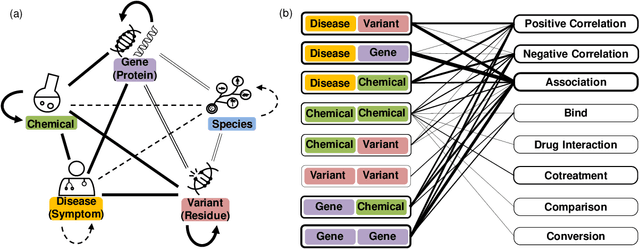
Automated relation extraction (RE) from biomedical literature is critical for many downstream text mining applications in both research and real-world settings. However, most existing benchmarking datasets for bio-medical RE only focus on relations of a single type (e.g., protein-protein interactions) at the sentence level, greatly limiting the development of RE systems in biomedicine. In this work, we first review commonly used named entity recognition (NER) and RE datasets. Then we present BioRED, a first-of-its-kind biomedical RE corpus with multiple entity types (e.g., gene/protein, disease, chemical) and relation pairs (e.g., gene-disease; chemical-chemical), on a set of 600 PubMed articles. Further, we label each relation as describing either a novel finding or previously known background knowledge, enabling automated algorithms to differentiate between novel and background information. We assess the utility of BioRED by benchmarking several existing state-of-the-art methods, including BERT-based models, on the NER and RE tasks. Our results show that while existing approaches can reach high performance on the NER task (F-score of 89.3%), there is much room for improvement for the RE task, especially when extracting novel relations (F-score of 47.7%). Our experiments also demonstrate that such a comprehensive dataset can successfully facilitate the development of more accurate, efficient, and robust RE systems for biomedicine.
Machine Learning Information Fusion in Earth Observation: A Comprehensive Review of Methods, Applications and Data Sources
Dec 07, 2020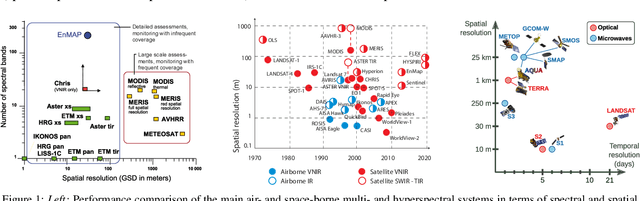
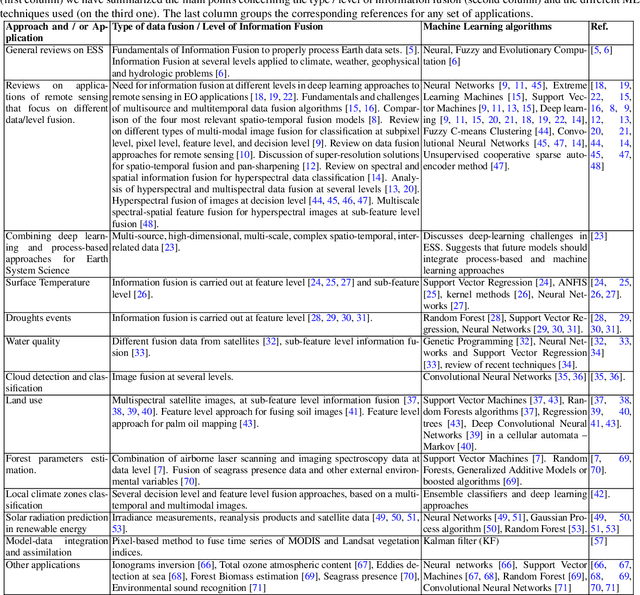
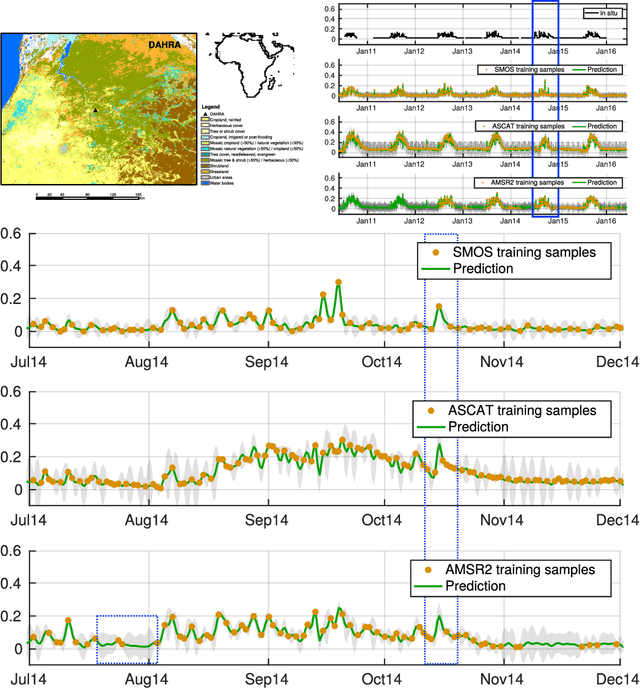
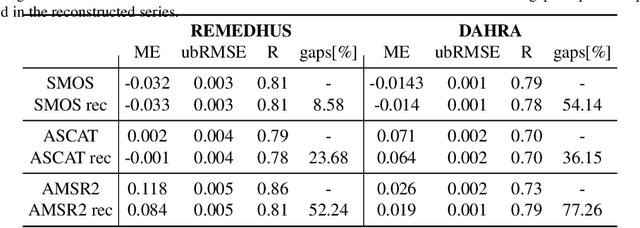
This paper reviews the most important information fusion data-driven algorithms based on Machine Learning (ML) techniques for problems in Earth observation. Nowadays we observe and model the Earth with a wealth of observations, from a plethora of different sensors, measuring states, fluxes, processes and variables, at unprecedented spatial and temporal resolutions. Earth observation is well equipped with remote sensing systems, mounted on satellites and airborne platforms, but it also involves in-situ observations, numerical models and social media data streams, among other data sources. Data-driven approaches, and ML techniques in particular, are the natural choice to extract significant information from this data deluge. This paper produces a thorough review of the latest work on information fusion for Earth observation, with a practical intention, not only focusing on describing the most relevant previous works in the field, but also the most important Earth observation applications where ML information fusion has obtained significant results. We also review some of the most currently used data sets, models and sources for Earth observation problems, describing their importance and how to obtain the data when needed. Finally, we illustrate the application of ML data fusion with a representative set of case studies, as well as we discuss and outlook the near future of the field.