 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Analysis of Ensemble Sampling
Mar 02, 2022
Ensemble sampling serves as a practical approximation to Thompson sampling when maintaining an exact posterior distribution over model parameters is computationally intractable. In this paper, we establish a Bayesian regret bound that ensures desirable behavior when ensemble sampling is applied to the linear bandit problem. This represents the first rigorous regret analysis of ensemble sampling and is made possible by leveraging information-theoretic concepts and novel analytic techniques that may prove useful beyond the scope of this paper.
Iranian Modal Music (Dastgah) detection using deep neural networks
Mar 29, 2022
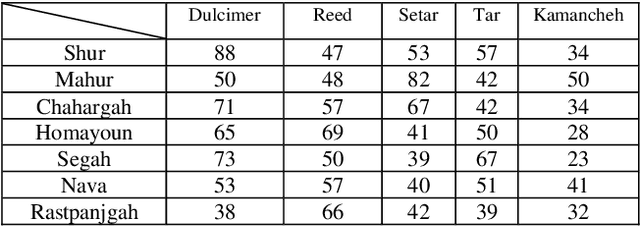

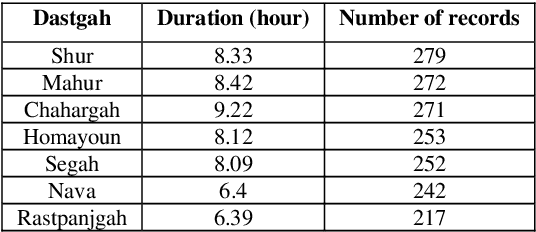
In this work, several deep neural networks are implemented to recognize Iranian modal music in seven high correlated categories. The best model, which achieved 92 percent overall accuracy, uses an architecture inspired by autoencoder, including BiLSTM and BiGRU layers. This model is trained using the Nava dataset, with 1786 records and up to 55 hours of music played solo by Kamanche, Tar, Setar, Reed, and Santoor (Dulcimer). Features that have been studied through this research contain MFCC, Chroma CENS, and Mel spectrogram. The results indicate that MFCC carries more valuable information for detecting Iranian modal music (Dastgah) than other sound representations. Moreover, the architecture, which is inspired by autoencoder, is robust in distinguishing high correlated data like Dastgahs. It also shows that because of the precise order in Iranian Dastgah Music, Bidirectional Recurrent networks are more efficient than any other networks that have been implemented in this study.
Projection: A Mixed-Initiative Research Process
Jan 09, 2022
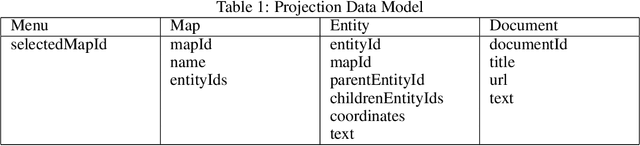
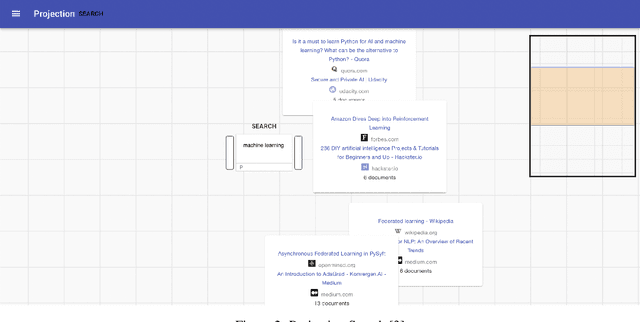
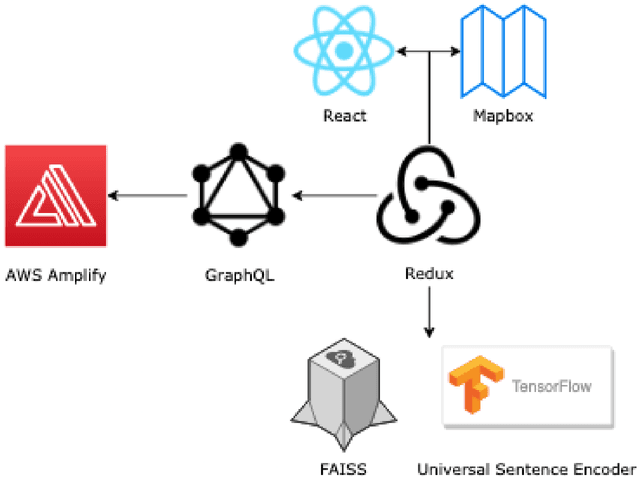
Communication of dense information between humans and machines is relatively low bandwidth. Many modern search and recommender systems operate as machine learning black boxes, giving little insight as to how they represent information or why they take certain actions. We present Projection, a mixed-initiative interface that aims to increase the bandwidth of communication between humans and machines throughout the research process. The interface supports adding context to searches and visualizing information in multiple dimensions with techniques such as hierarchical clustering and spatial projections. Potential customers have shown interest in the application integrating their research outlining and search processes, enabling them to structure their searches in hierarchies, and helping them visualize related spaces of knowledge.
Parameter-Efficient Tuning by Manipulating Hidden States of Pretrained Language Models For Classification Tasks
Apr 13, 2022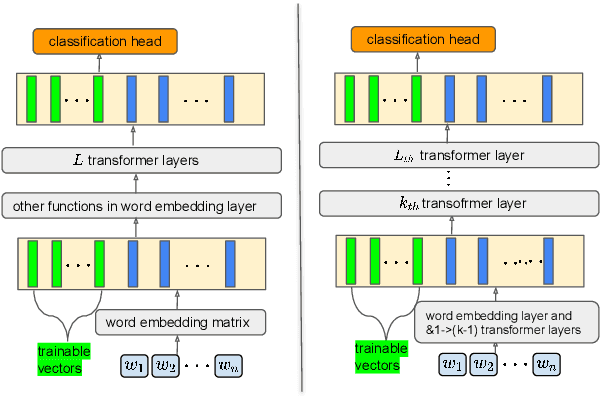
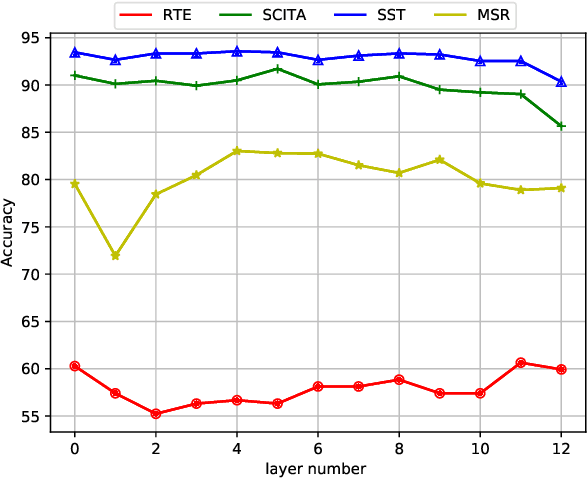
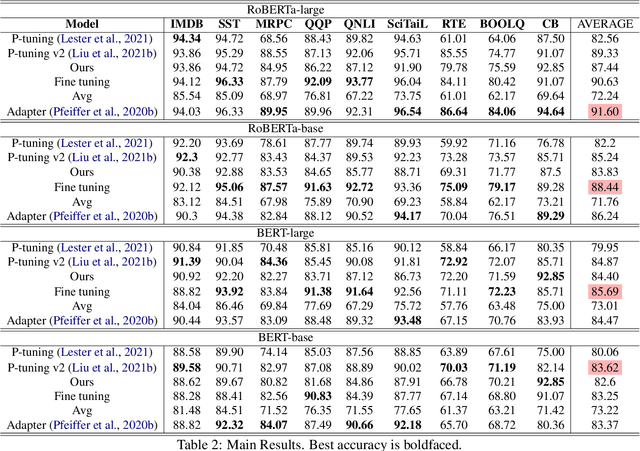
Parameter-efficient tuning aims to distill knowledge for downstream tasks by optimizing a few introduced parameters while freezing the pretrained language models (PLMs). Continuous prompt tuning which prepends a few trainable vectors to the embeddings of input is one of these methods and has drawn much attention due to its effectiveness and efficiency. This family of methods can be illustrated as exerting nonlinear transformations of hidden states inside PLMs. However, a natural question is ignored: can the hidden states be directly used for classification without changing them? In this paper, we aim to answer this question by proposing a simple tuning method which only introduces three trainable vectors. Firstly, we integrate all layers hidden states using the introduced vectors. And then, we input the integrated hidden state(s) to a task-specific linear classifier to predict categories. This scheme is similar to the way ELMo utilises hidden states except that they feed the hidden states to LSTM-based models. Although our proposed tuning scheme is simple, it achieves comparable performance with prompt tuning methods like P-tuning and P-tuning v2, verifying that original hidden states do contain useful information for classification tasks. Moreover, our method has an advantage over prompt tuning in terms of time and the number of parameters.
Attention in Attention: Modeling Context Correlation for Efficient Video Classification
Apr 20, 2022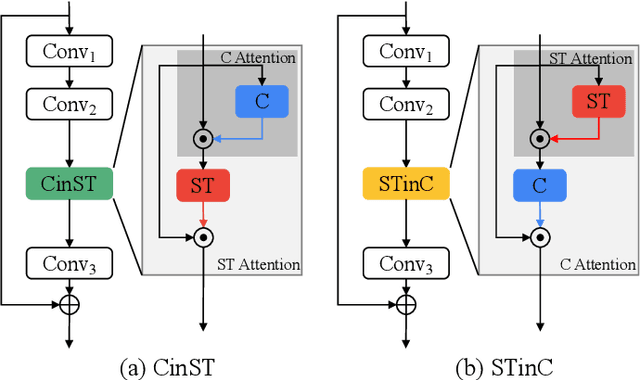
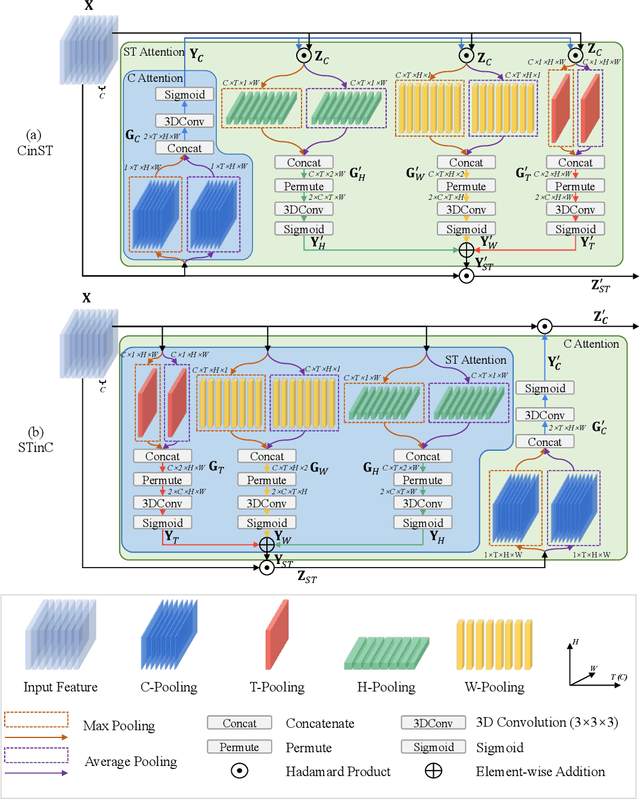
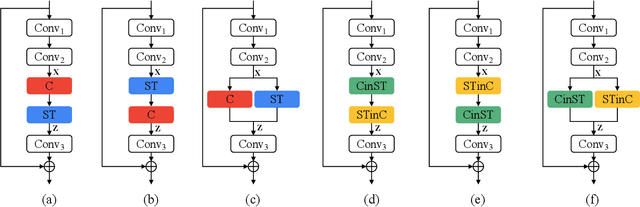
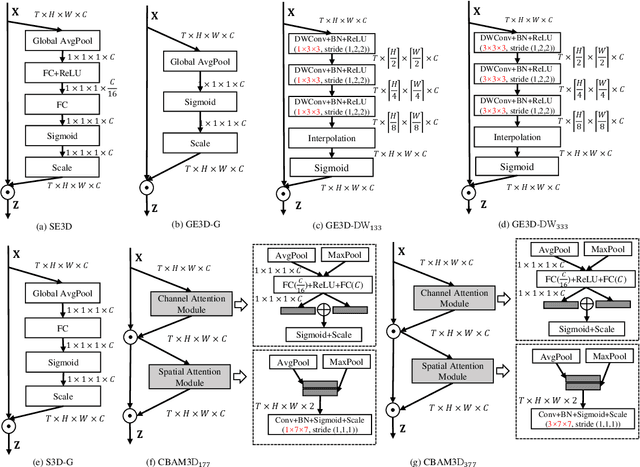
Attention mechanisms have significantly boosted the performance of video classification neural networks thanks to the utilization of perspective contexts. However, the current research on video attention generally focuses on adopting a specific aspect of contexts (e.g., channel, spatial/temporal, or global context) to refine the features and neglects their underlying correlation when computing attentions. This leads to incomplete context utilization and hence bears the weakness of limited performance improvement. To tackle the problem, this paper proposes an efficient attention-in-attention (AIA) method for element-wise feature refinement, which investigates the feasibility of inserting the channel context into the spatio-temporal attention learning module, referred to as CinST, and also its reverse variant, referred to as STinC. Specifically, we instantiate the video feature contexts as dynamics aggregated along a specific axis with global average and max pooling operations. The workflow of an AIA module is that the first attention block uses one kind of context information to guide the gating weights calculation of the second attention that targets at the other context. Moreover, all the computational operations in attention units act on the pooled dimension, which results in quite few computational cost increase ($<$0.02\%). To verify our method, we densely integrate it into two classical video network backbones and conduct extensive experiments on several standard video classification benchmarks. The source code of our AIA is available at \url{https://github.com/haoyanbin918/Attention-in-Attention}.
Learning Dual-Pixel Alignment for Defocus Deblurring
Apr 26, 2022



It is a challenging task to recover all-in-focus image from a single defocus blurry image in real-world applications. On many modern cameras, dual-pixel (DP) sensors create two-image views, based on which stereo information can be exploited to benefit defocus deblurring. Despite existing DP defocus deblurring methods achieving impressive results, they directly take naive concatenation of DP views as input, while neglecting the disparity between left and right views in the regions out of camera's depth of field (DoF). In this work, we propose a Dual-Pixel Alignment Network (DPANet) for defocus deblurring. Generally, DPANet is an encoder-decoder with skip-connections, where two branches with shared parameters in the encoder are employed to extract and align deep features from left and right views, and one decoder is adopted to fuse aligned features for predicting the all-in-focus image. Due to that DP views suffer from different blur amounts, it is not trivial to align left and right views. To this end, we propose novel encoder alignment module (EAM) and decoder alignment module (DAM). In particular, a correlation layer is suggested in EAM to measure the disparity between DP views, whose deep features can then be accordingly aligned using deformable convolutions. And DAM can further enhance the alignment of skip-connected features from encoder and deep features in decoder. By introducing several EAMs and DAMs, DP views in DPANet can be well aligned for better predicting latent all-in-focus image. Experimental results on real-world datasets show that our DPANet is notably superior to state-of-the-art deblurring methods in reducing defocus blur while recovering visually plausible sharp structures and textures.
Pre-Training Transformer Decoder for End-to-End ASR Model with Unpaired Speech Data
Mar 31, 2022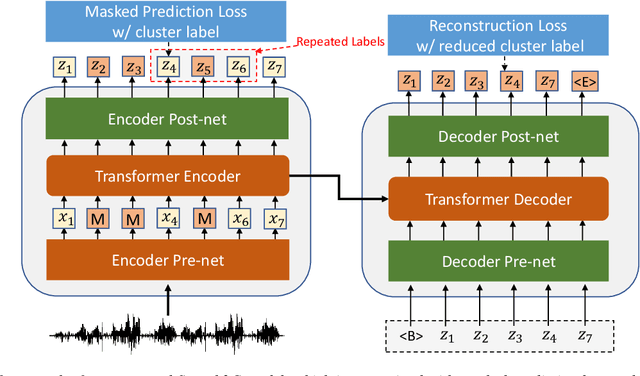
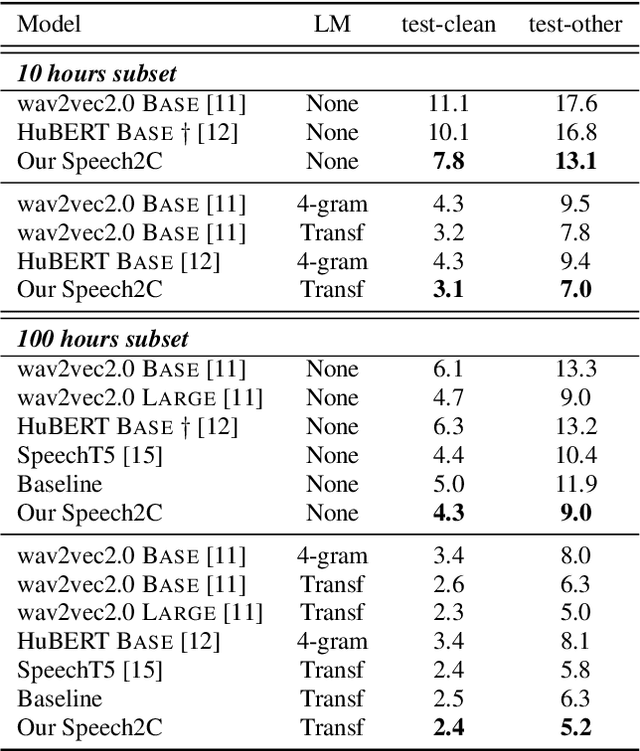

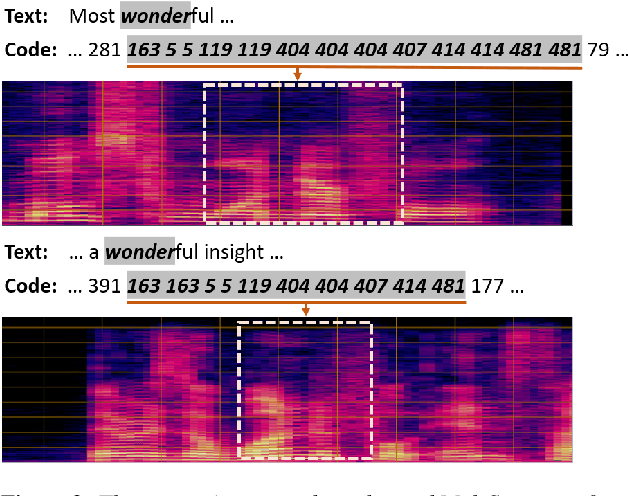
This paper studies a novel pre-training technique with unpaired speech data, Speech2C, for encoder-decoder based automatic speech recognition (ASR). Within a multi-task learning framework, we introduce two pre-training tasks for the encoder-decoder network using acoustic units, i.e., pseudo codes, derived from an offline clustering model. One is to predict the pseudo codes via masked language modeling in encoder output, like HuBERT model, while the other lets the decoder learn to reconstruct pseudo codes autoregressively instead of generating textual scripts. In this way, the decoder learns to reconstruct original speech information with codes before learning to generate correct text. Comprehensive experiments on the LibriSpeech corpus show that the proposed Speech2C can relatively reduce the word error rate (WER) by 19.2% over the method without decoder pre-training, and also outperforms significantly the state-of-the-art wav2vec 2.0 and HuBERT on fine-tuning subsets of 10h and 100h.
A multi-task semi-supervised framework for Text2Graph & Graph2Text
Feb 12, 2022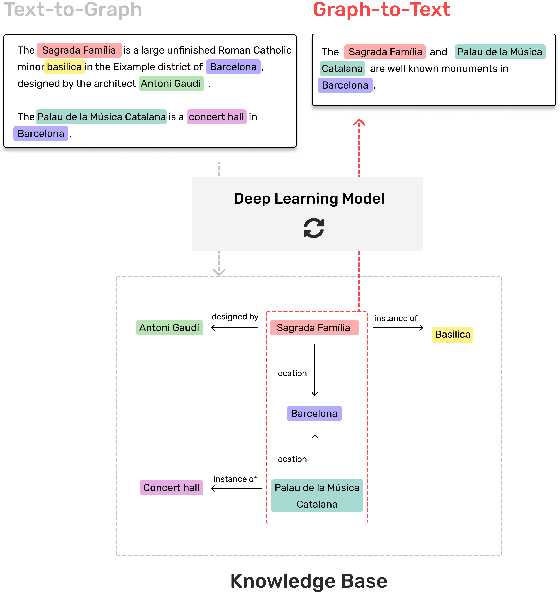

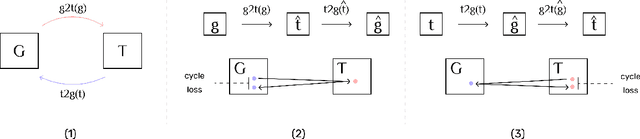
The Artificial Intelligence industry regularly develops applications that mostly rely on Knowledge Bases, a data repository about specific, or general, domains, usually represented in a graph shape. Similar to other databases, they face two main challenges: information ingestion and information retrieval. We approach these challenges by jointly learning graph extraction from text and text generation from graphs. The proposed solution, a T5 architecture, is trained in a multi-task semi-supervised environment, with our collected non-parallel data, following a cycle training regime. Experiments on WebNLG dataset show that our approach surpasses unsupervised state-of-the-art results in text-to-graph and graph-to-text. More relevantly, our framework is more consistent across seen and unseen domains than supervised models. The resulting model can be easily trained in any new domain with non-parallel data, by simply adding text and graphs about it, in our cycle framework.
Scalable Motif Counting for Large-scale Temporal Graphs
Apr 20, 2022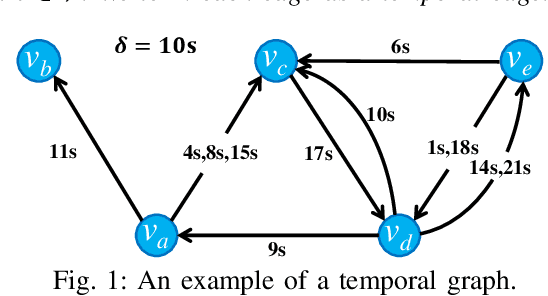
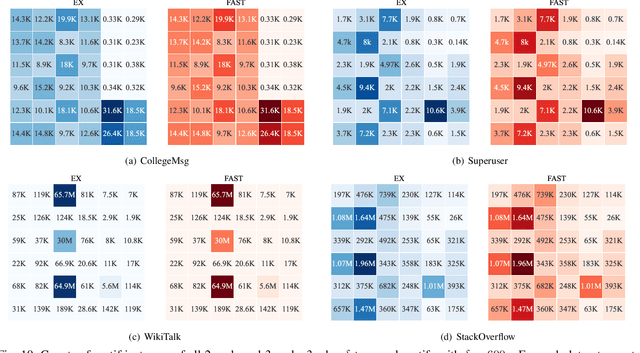
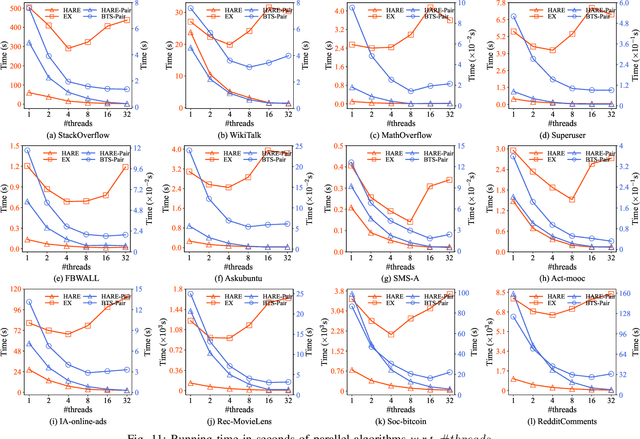
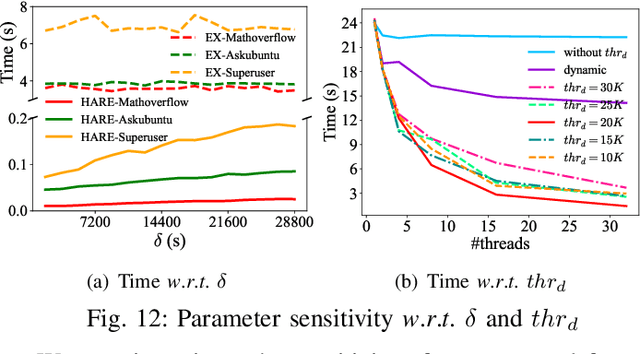
One fundamental problem in temporal graph analysis is to count the occurrences of small connected subgraph patterns (i.e., motifs), which benefits a broad range of real-world applications, such as anomaly detection, structure prediction, and network representation learning. However, existing works focused on exacting temporal motif are not scalable to large-scale temporal graph data, due to their heavy computational costs or inherent inadequacy of parallelism. In this work, we propose a scalable parallel framework for exactly counting temporal motifs in large-scale temporal graphs. We first categorize the temporal motifs based on their distinct properties, and then design customized algorithms that offer efficient strategies to exactly count the motif instances of each category. Moreover, our compact data structures, namely triple and quadruple counters, enable our algorithms to directly identify the temporal motif instances of each category, according to edge information and the relationship between edges, therefore significantly improving the counting efficiency. Based on the proposed counting algorithms, we design a hierarchical parallel framework that features both inter- and intra-node parallel strategies, and fully leverages the multi-threading capacity of modern CPU to concurrently count all temporal motifs. Extensive experiments on sixteen real-world temporal graph datasets demonstrate the superiority and capability of our proposed framework for temporal motif counting, achieving up to 538* speedup compared to the state-of-the-art methods. The source code of our method is available at: https://github.com/steven-ccq/FAST-temporal-motif.
Explainability and Graph Learning from Social Interactions
Mar 14, 2022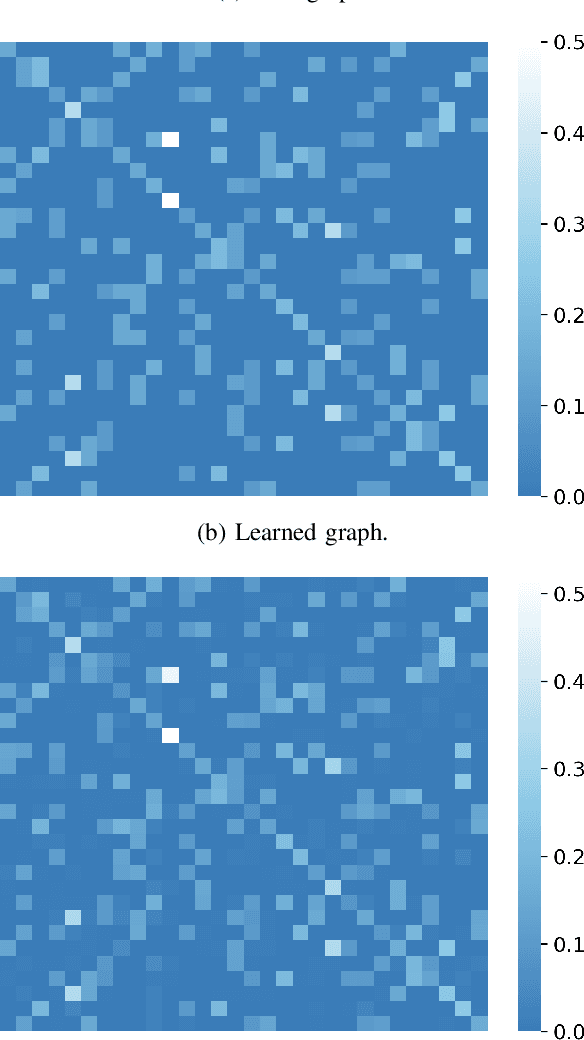
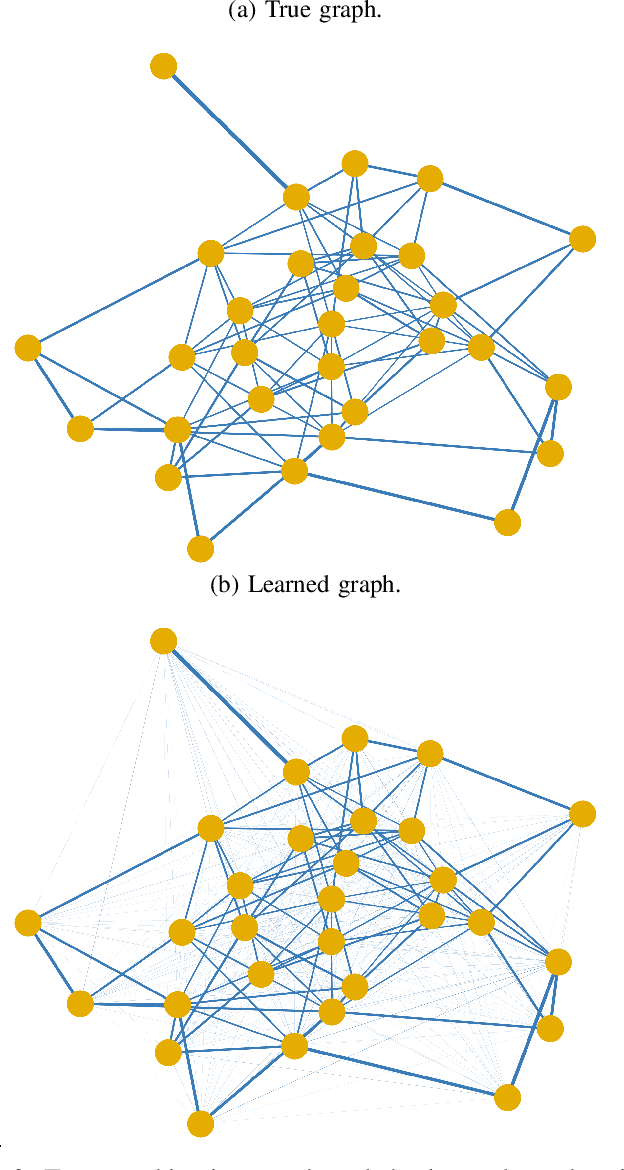
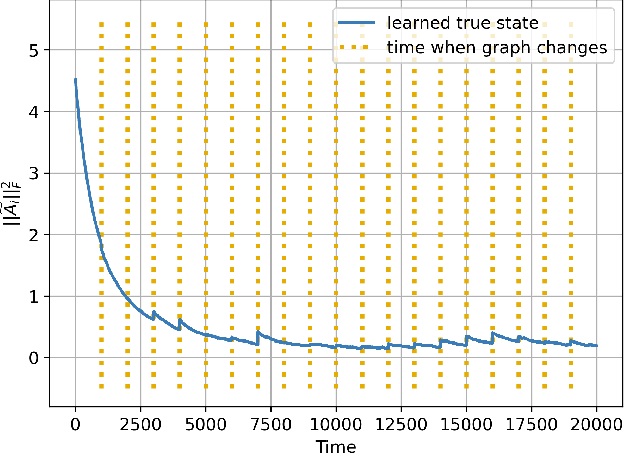
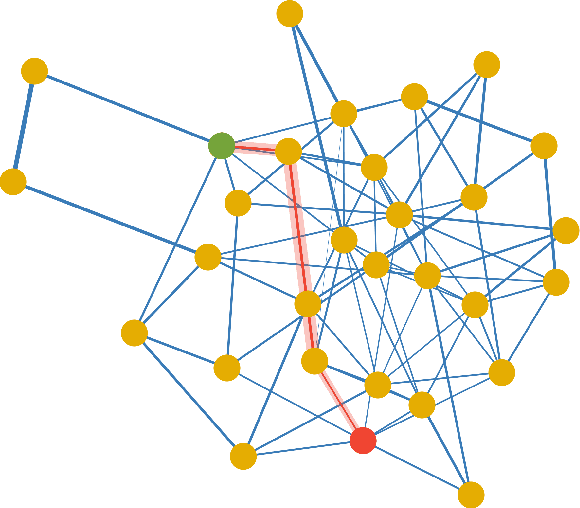
Social learning algorithms provide models for the formation of opinions over social networks resulting from local reasoning and peer-to-peer exchanges. Interactions occur over an underlying graph topology, which describes the flow of information among the agents. In this work, we propose a technique that addresses questions of explainability and interpretability when the graph is hidden. Given observations of the evolution of the belief over time, we aim to infer the underlying graph topology, discover pairwise influences between the agents, and identify significant trajectories in the network. The proposed framework is online in nature and can adapt dynamically to changes in the graph topology or the true hypothesis.