 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Theoretical Analysis of Deep Neural Networks in Physical Layer Communication
Feb 21, 2022
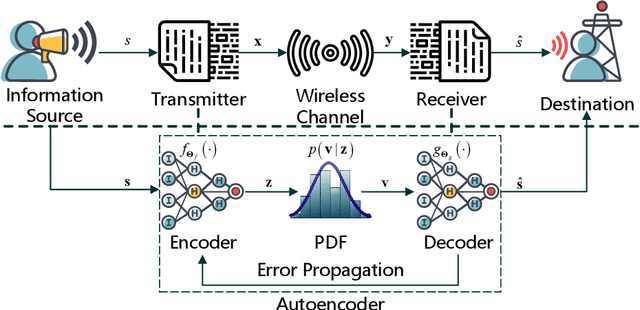
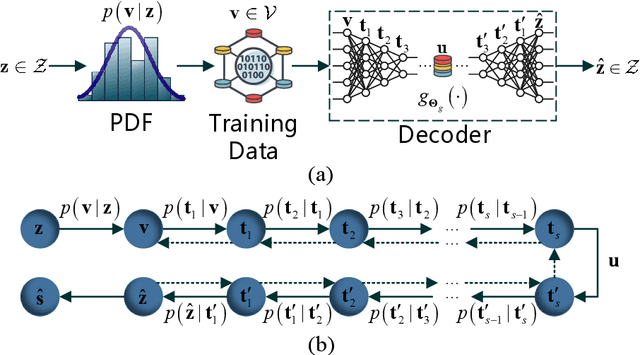
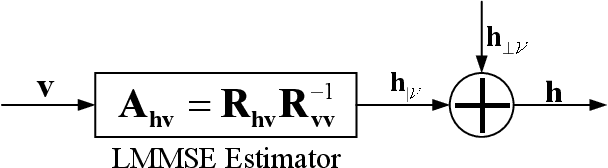
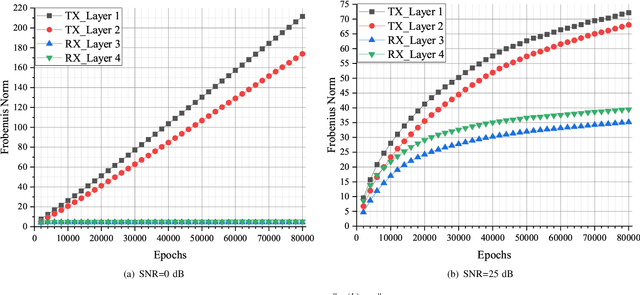
Recently, deep neural network (DNN)-based physical layer communication techniques have attracted considerable interest. Although their potential to enhance communication systems and superb performance have been validated by simulation experiments, little attention has been paid to the theoretical analysis. Specifically, most studies in the physical layer have tended to focus on the application of DNN models to wireless communication problems but not to theoretically understand how does a DNN work in a communication system. In this paper, we aim to quantitatively analyze why DNNs can achieve comparable performance in the physical layer comparing with traditional techniques, and also drive their cost in terms of computational complexity. To achieve this goal, we first analyze the encoding performance of a DNN-based transmitter and compare it to a traditional one. And then, we theoretically analyze the performance of DNN-based estimator and compare it with traditional estimators. Third, we investigate and validate how information is flown in a DNN-based communication system under the information theoretic concepts. Our analysis develops a concise way to open the "black box" of DNNs in physical layer communication, which can be applied to support the design of DNN-based intelligent communication techniques and help to provide explainable performance assessment.
Locality-Aware Inter-and Intra-Video Reconstruction for Self-Supervised Correspondence Learning
Mar 29, 2022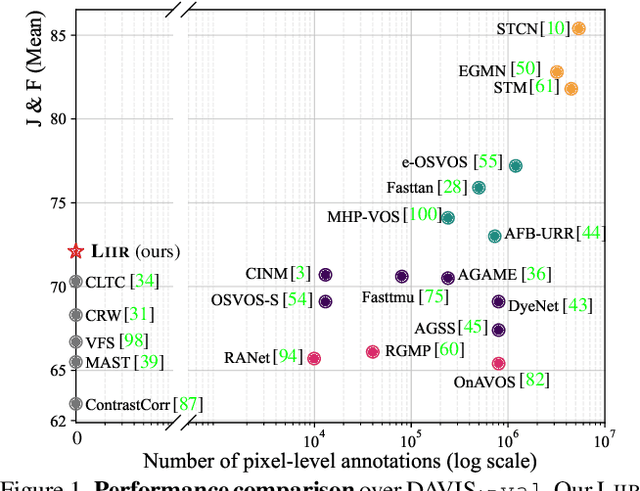
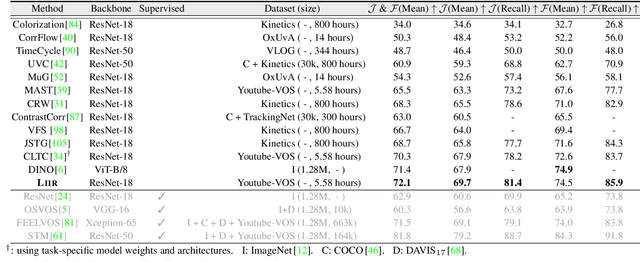
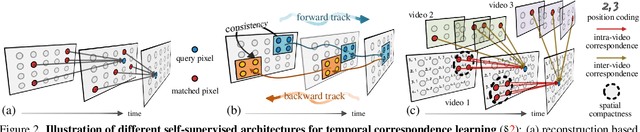
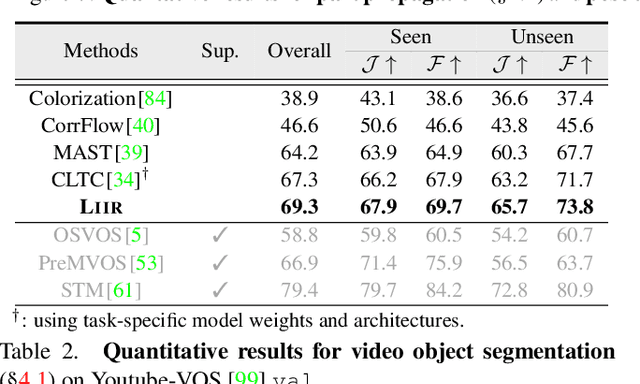
Our target is to learn visual correspondence from unlabeled videos. We develop LIIR, a locality-aware inter-and intra-video reconstruction framework that fills in three missing pieces, i.e., instance discrimination, location awareness, and spatial compactness, of self-supervised correspondence learning puzzle. First, instead of most existing efforts focusing on intra-video self-supervision only, we exploit cross video affinities as extra negative samples within a unified, inter-and intra-video reconstruction scheme. This enables instance discriminative representation learning by contrasting desired intra-video pixel association against negative inter-video correspondence. Second, we merge position information into correspondence matching, and design a position shifting strategy to remove the side-effect of position encoding during inter-video affinity computation, making our LIIR location-sensitive. Third, to make full use of the spatial continuity nature of video data, we impose a compactness-based constraint on correspondence matching, yielding more sparse and reliable solutions. The learned representation surpasses self-supervised state-of-the-arts on label propagation tasks including objects, semantic parts, and keypoints.
Responsible AI in Healthcare
Feb 19, 2022This article discusses open problems, implemented solutions, and future research in the area of responsible AI in healthcare. In particular, we illustrate two main research themes related to the work of two laboratories within the Department of Informatics, Systems, and Communication at the University of Milano-Bicocca. The problems addressed concern, in particular, {uncertainty in medical data and machine advice}, and the problem of online health information disorder.
Panoptic NeRF: 3D-to-2D Label Transfer for Panoptic Urban Scene Segmentation
Mar 29, 2022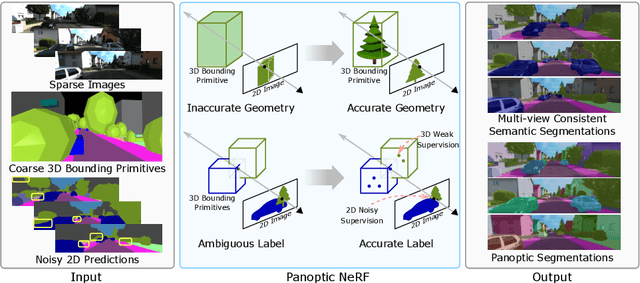
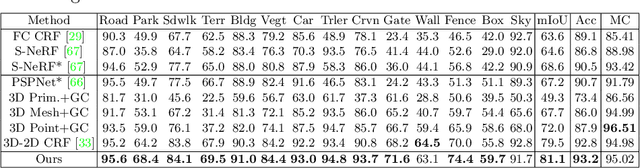
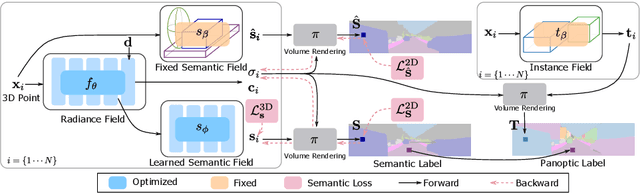

Large-scale training data with high-quality annotations is critical for training semantic and instance segmentation models. Unfortunately, pixel-wise annotation is labor-intensive and costly, raising the demand for more efficient labeling strategies. In this work, we present a novel 3D-to-2D label transfer method, Panoptic NeRF, which aims for obtaining per-pixel 2D semantic and instance labels from easy-to-obtain coarse 3D bounding primitives. Our method utilizes NeRF as a differentiable tool to unify coarse 3D annotations and 2D semantic cues transferred from existing datasets. We demonstrate that this combination allows for improved geometry guided by semantic information, enabling rendering of accurate semantic maps across multiple views. Furthermore, this fusion process resolves label ambiguity of the coarse 3D annotations and filters noise in the 2D predictions. By inferring in 3D space and rendering to 2D labels, our 2D semantic and instance labels are multi-view consistent by design. Experimental results show that Panoptic NeRF outperforms existing semantic and instance label transfer methods in terms of accuracy and multi-view consistency on challenging urban scenes of the KITTI-360 dataset.
Graph-based Approximate NN Search: A Revisit
Apr 02, 2022
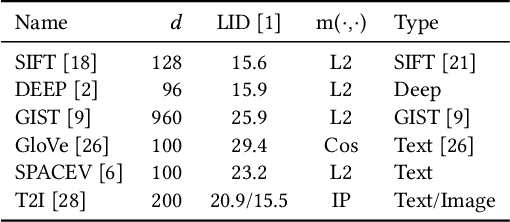
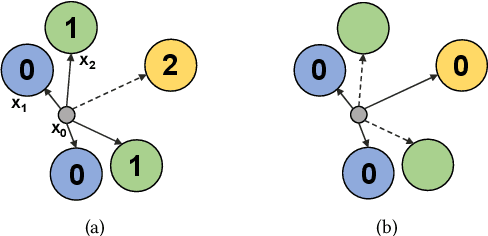
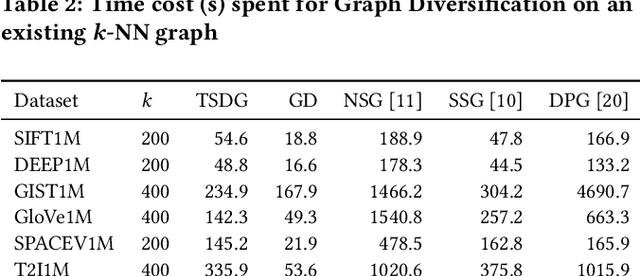
Nearest neighbor search plays a fundamental role in many disciplines such as multimedia information retrieval, data-mining, and machine learning. The graph-based search approaches show superior performance over other types of approaches in recent studies. In this paper, the graph-based NN search is revisited. We optimize two key components in the approach, namely the search procedure and the graph that supports the search. For the graph construction, a two-stage graph diversification scheme is proposed, which makes a good trade-off between the efficiency and reachability for the search procedure that builds upon it. Moreover, the proposed diversification scheme allows the search procedure to decide dynamically how many nodes should be visited in one node's neighborhood. By this way, the computing power of the devices is fully utilized when the search is carried out under different circumstances. Furthermore, two NN search procedures are designed respectively for small and large batch queries on the GPU. The optimized NN search, when being supported by the two-stage diversified graph, outperforms all the state-of-the-art approaches on both the CPU and the GPU across all the considered large-scale datasets.
Interactive Evolutionary Multi-Objective Optimization via Learning-to-Rank
Apr 06, 2022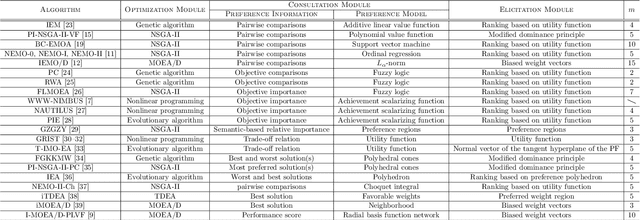
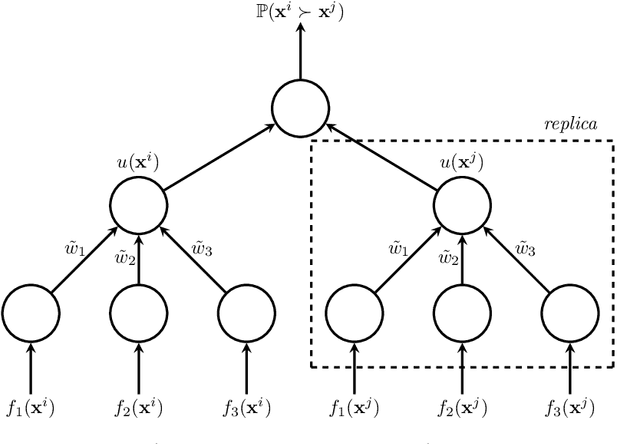
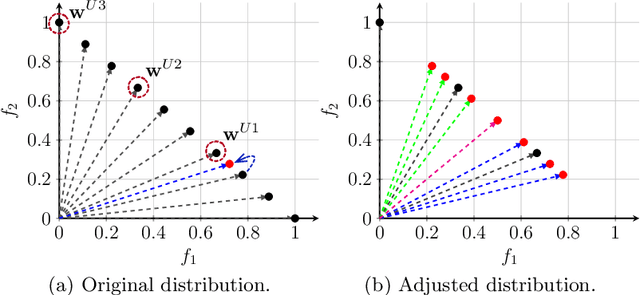
In practical multi-criterion decision-making, it is cumbersome if a decision maker (DM) is asked to choose among a set of trade-off alternatives covering the whole Pareto-optimal front. This is a paradox in conventional evolutionary multi-objective optimization (EMO) that always aim to achieve a well balance between convergence and diversity. In essence, the ultimate goal of multi-objective optimization is to help a decision maker (DM) identify solution(s) of interest (SOI) achieving satisfactory trade-offs among multiple conflicting criteria. Bearing this in mind, this paper develops a framework for designing preference-based EMO algorithms to find SOI in an interactive manner. Its core idea is to involve human in the loop of EMO. After every several iterations, the DM is invited to elicit her feedback with regard to a couple of incumbent candidates. By collecting such information, her preference is progressively learned by a learning-to-rank neural network and then applied to guide the baseline EMO algorithm. Note that this framework is so general that any existing EMO algorithm can be applied in a plug-in manner. Experiments on $48$ benchmark test problems with up to 10 objectives fully demonstrate the effectiveness of our proposed algorithms for finding SOI.
Webpage Segmentation for Extracting Images and Their Surrounding Contextual Information
May 18, 2020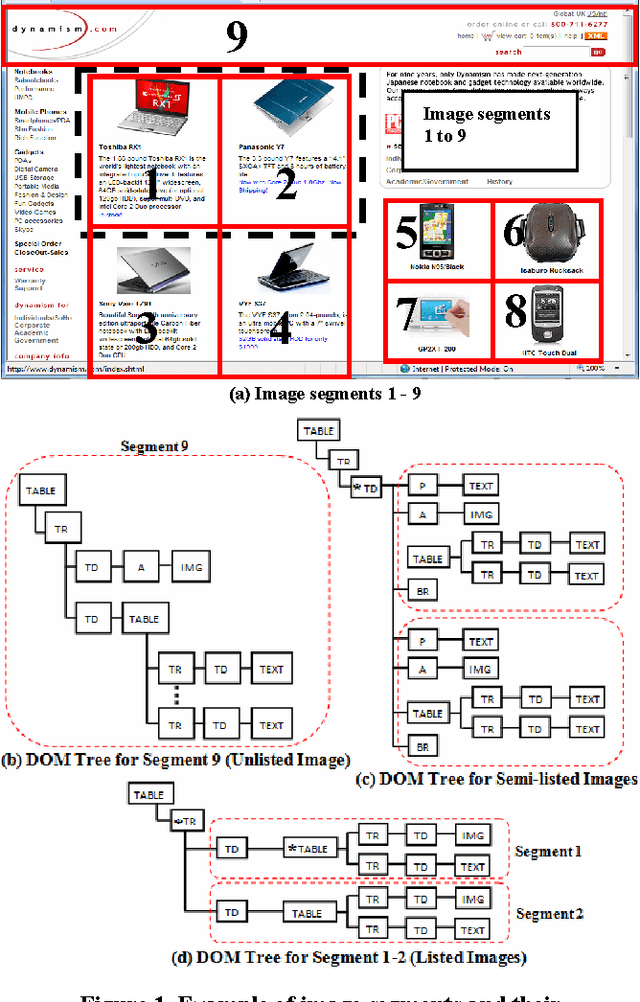
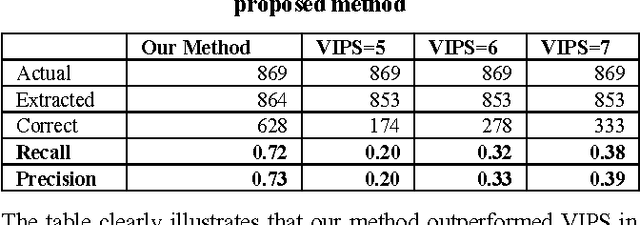
Web images come in hand with valuable contextual information. Although this information has long been mined for various uses such as image annotation, clustering of images, inference of image semantic content, etc., insufficient attention has been given to address issues in mining this contextual information. In this paper, we propose a webpage segmentation algorithm targeting the extraction of web images and their contextual information based on their characteristics as they appear on webpages. We conducted a user study to obtain a human-labeled dataset to validate the effectiveness of our method and experiments demonstrated that our method can achieve better results compared to an existing segmentation algorithm.
Human Preferences as Dueling Bandits
Apr 21, 2022
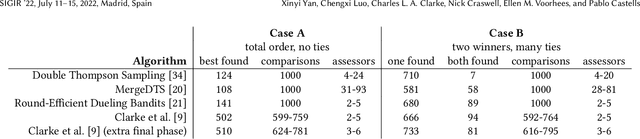
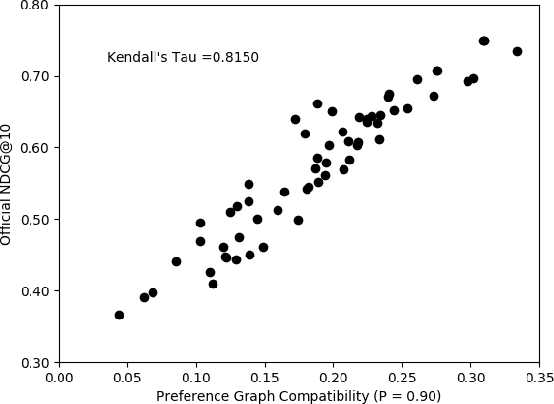
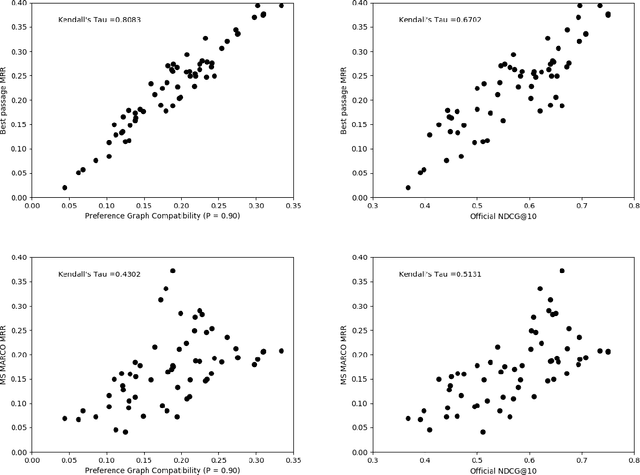
The dramatic improvements in core information retrieval tasks engendered by neural rankers create a need for novel evaluation methods. If every ranker returns highly relevant items in the top ranks, it becomes difficult to recognize meaningful differences between them and to build reusable test collections. Several recent papers explore pairwise preference judgments as an alternative to traditional graded relevance assessments. Rather than viewing items one at a time, assessors view items side-by-side and indicate the one that provides the better response to a query, allowing fine-grained distinctions. If we employ preference judgments to identify the probably best items for each query, we can measure rankers by their ability to place these items as high as possible. We frame the problem of finding best items as a dueling bandits problem. While many papers explore dueling bandits for online ranker evaluation via interleaving, they have not been considered as a framework for offline evaluation via human preference judgments. We review the literature for possible solutions. For human preference judgments, any usable algorithm must tolerate ties, since two items may appear nearly equal to assessors, and it must minimize the number of judgments required for any specific pair, since each such comparison requires an independent assessor. Since the theoretical guarantees provided by most algorithms depend on assumptions that are not satisfied by human preference judgments, we simulate selected algorithms on representative test cases to provide insight into their practical utility. Based on these simulations, one algorithm stands out for its potential. Our simulations suggest modifications to further improve its performance. Using the modified algorithm, we collect over 10,000 preference judgments for submissions to the TREC 2021 Deep Learning Track, confirming its suitability.
A Knowledge-driven Business Process Analysis Canvas
Jan 18, 2022Business process (BP) analysis represents a first key phase of information system development. It consists in the gathering of domain knowledge and its organization to be later used in the software development, and beyond (e.g., for Business Process Reengineering). The quality of the developed information system largely depends on how the BP analysis has been carried out and the quality of the produced requirement specification documents. Despite the fact that the issue is on the table for decades, business process analysis is still a critical phase of information systems development. One promising strategy is an early and more important involvement of business experts in the BP analysis. This paper presents a methodology that aims at an early involvement of business experts while providing a formal grounding that guarantees the quality of the produced specifications. To this end, we propose the Business Process Analysis Canvas, a knowledge framework organized in eight knowledge sections aimed at supporting the business expert in carrying out the analysis, eventually yielding a BP analysis Ontology.
Separate What You Describe: Language-Queried Audio Source Separation
Mar 28, 2022
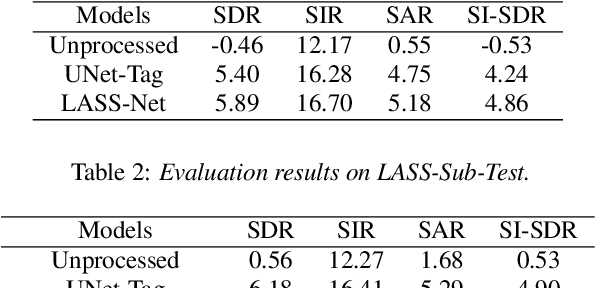

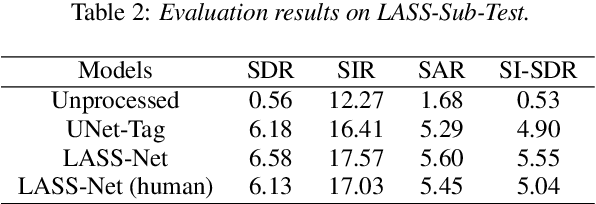
In this paper, we introduce the task of language-queried audio source separation (LASS), which aims to separate a target source from an audio mixture based on a natural language query of the target source (e.g., "a man tells a joke followed by people laughing"). A unique challenge in LASS is associated with the complexity of natural language description and its relation with the audio sources. To address this issue, we proposed LASS-Net, an end-to-end neural network that is learned to jointly process acoustic and linguistic information, and separate the target source that is consistent with the language query from an audio mixture. We evaluate the performance of our proposed system with a dataset created from the AudioCaps dataset. Experimental results show that LASS-Net achieves considerable improvements over baseline methods. Furthermore, we observe that LASS-Net achieves promising generalization results when using diverse human-annotated descriptions as queries, indicating its potential use in real-world scenarios. The separated audio samples and source code are available at https://liuxubo717.github.io/LASS-demopage.