 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Twitter-Demographer: A Flow-based Tool to Enrich Twitter Data
Jan 26, 2022


Twitter data have become essential to Natural Language Processing (NLP) and social science research, driving various scientific discoveries in recent years. However, the textual data alone are often not enough to conduct studies: especially social scientists need more variables to perform their analysis and control for various factors. How we augment this information, such as users' location, age, or tweet sentiment, has ramifications for anonymity and reproducibility, and requires dedicated effort. This paper describes Twitter-Demographer, a simple, flow-based tool to enrich Twitter data with additional information about tweets and users. Twitter-Demographer is aimed at NLP practitioners and (computational) social scientists who want to enrich their datasets with aggregated information, facilitating reproducibility, and providing algorithmic privacy-by-design measures for pseudo-anonymity. We discuss our design choices, inspired by the flow-based programming paradigm, to use black-box components that can easily be chained together and extended. We also analyze the ethical issues related to the use of this tool, and the built-in measures to facilitate pseudo-anonymity.
Deep Page-Level Interest Network in Reinforcement Learning for Ads Allocation
Apr 01, 2022
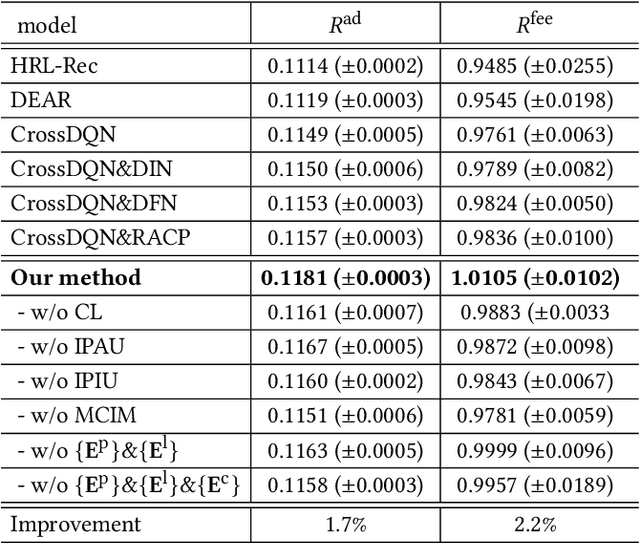
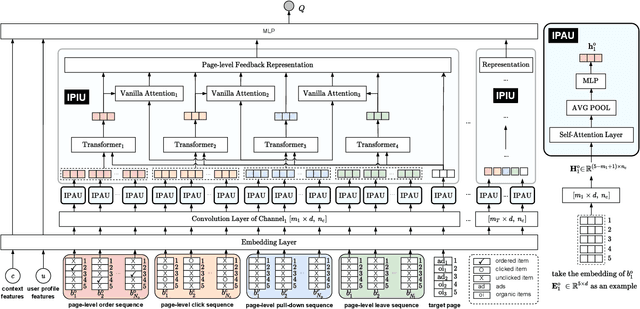
A mixed list of ads and organic items is usually displayed in feed and how to allocate the limited slots to maximize the overall revenue is a key problem. Meanwhile, modeling user preference with historical behavior is essential in recommendation and advertising (e.g., CTR prediction and ads allocation). Most previous works for user behavior modeling only model user's historical point-level positive feedback (i.e., click), which neglect the page-level information of feedback and other types of feedback. To this end, we propose Deep Page-level Interest Network (DPIN) to model the page-level user preference and exploit multiple types of feedback. Specifically, we introduce four different types of page-level feedback as input, and capture user preference for item arrangement under different receptive fields through the multi-channel interaction module. Through extensive offline and online experiments on Meituan food delivery platform, we demonstrate that DPIN can effectively model the page-level user preference and increase the revenue for the platform.
Unseen Object Instance Segmentation with Fully Test-time RGB-D Embeddings Adaptation
Apr 21, 2022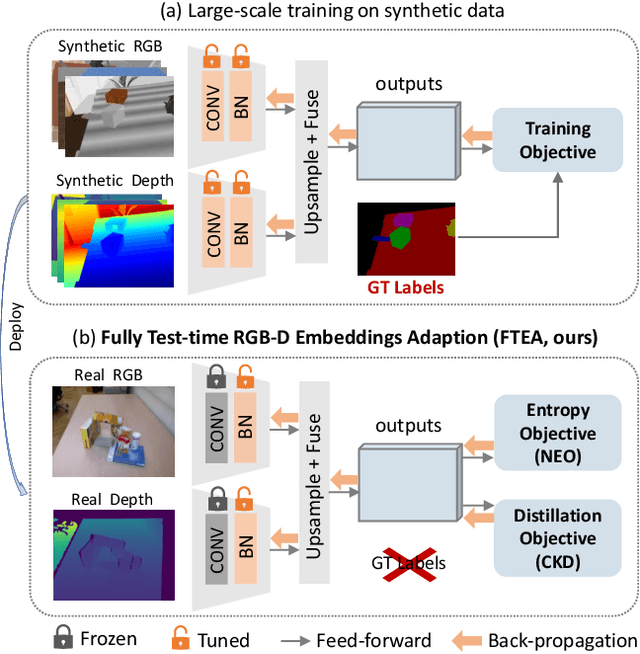
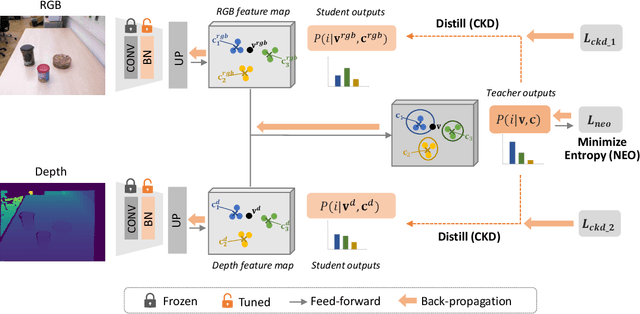
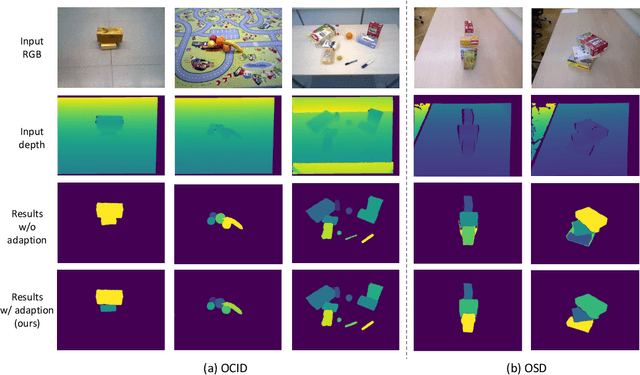
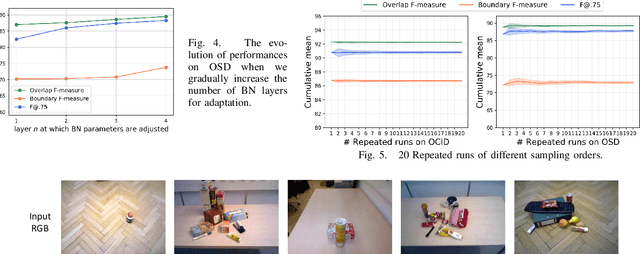
Segmenting unseen objects is a crucial ability for the robot since it may encounter new environments during the operation. Recently, a popular solution is leveraging RGB-D features of large-scale synthetic data and directly applying the model to unseen real-world scenarios. However, even though depth data have fair generalization ability, the domain shift due to the Sim2Real gap is inevitable, which presents a key challenge to the unseen object instance segmentation (UOIS) model. To tackle this problem, we re-emphasize the adaptation process across Sim2Real domains in this paper. Specifically, we propose a framework to conduct the Fully Test-time RGB-D Embeddings Adaptation (FTEA) based on parameters of the BatchNorm layer. To construct the learning objective for test-time back-propagation, we propose a novel non-parametric entropy objective that can be implemented without explicit classification layers. Moreover, we design a cross-modality knowledge distillation module to encourage the information transfer during test time. The proposed method can be efficiently conducted with test-time images, without requiring annotations or revisiting the large-scale synthetic training data. Besides significant time savings, the proposed method consistently improves segmentation results on both overlap and boundary metrics, achieving state-of-the-art performances on two real-world RGB-D image datasets. We hope our work could draw attention to the test-time adaptation and reveal a promising direction for robot perception in unseen environments.
Quantification of Occlusion Handling Capability of a 3D Human Pose Estimation Framework
Mar 08, 2022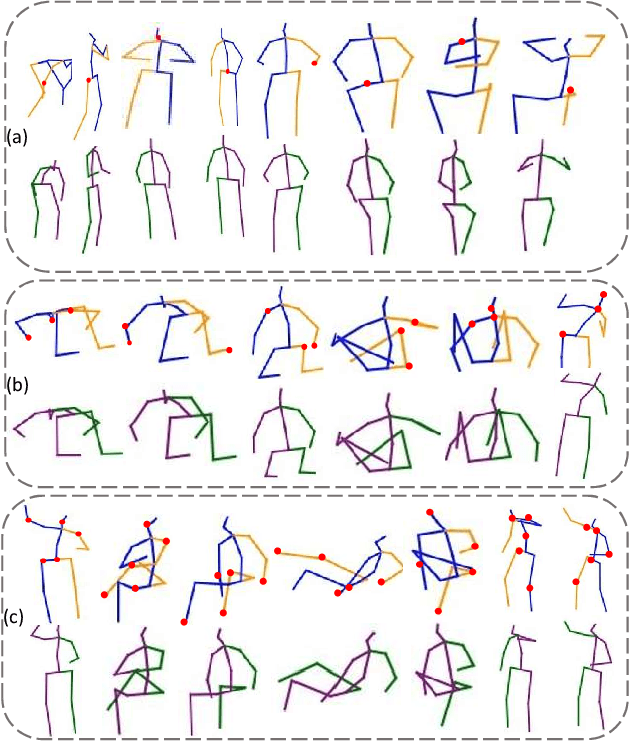
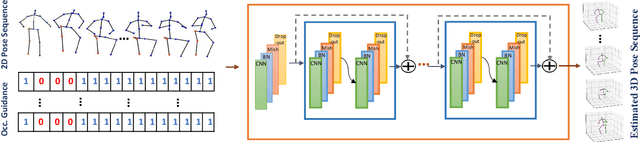
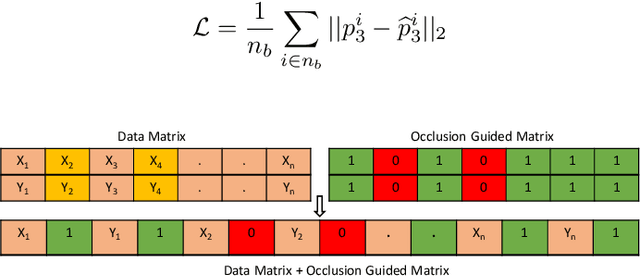
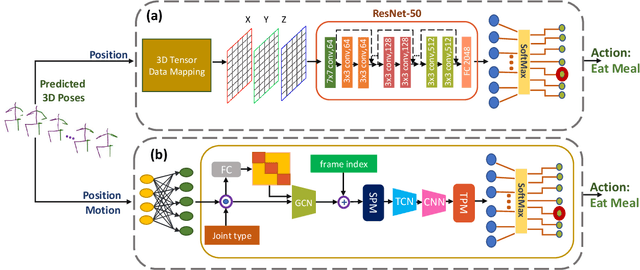
3D human pose estimation using monocular images is an important yet challenging task. Existing 3D pose detection methods exhibit excellent performance under normal conditions however their performance may degrade due to occlusion. Recently some occlusion aware methods have also been proposed, however, the occlusion handling capability of these networks has not yet been thoroughly investigated. In the current work, we propose an occlusion-guided 3D human pose estimation framework and quantify its occlusion handling capability by using different protocols. The proposed method estimates more accurate 3D human poses using 2D skeletons with missing joints as input. Missing joints are handled by introducing occlusion guidance that provides extra information about the absence or presence of a joint. Temporal information has also been exploited to better estimate the missing joints. A large number of experiments are performed for the quantification of occlusion handling capability of the proposed method on three publicly available datasets in various settings including random missing joints, fixed body parts missing, and complete frames missing, using mean per joint position error criterion. In addition to that, the quality of the predicted 3D poses is also evaluated using action classification performance as a criterion. 3D poses estimated by the proposed method achieved significantly improved action recognition performance in the presence of missing joints. Our experiments demonstrate the effectiveness of the proposed framework for handling the missing joints as well as quantification of the occlusion handling capability of the deep neural networks.
EndoMapper dataset of complete calibrated endoscopy procedures
Apr 29, 2022
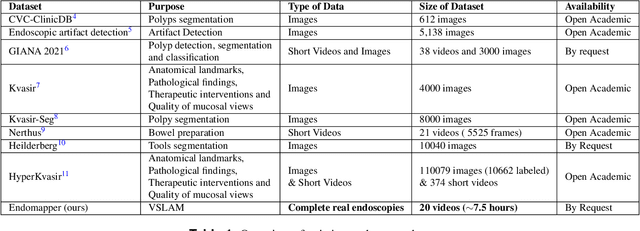


Computer-assisted systems are becoming broadly used in medicine. In endoscopy, most research focuses on automatic detection of polyps or other pathologies, but localization and navigation of the endoscope is completely performed manually by physicians. To broaden this research and bring spatial Artificial Intelligence to endoscopies, data from complete procedures are needed. This data will be used to build a 3D mapping and localization systems that can perform special task like, for example, detect blind zones during exploration, provide automatic polyp measurements, guide doctors to a polyp found in a previous exploration and retrieve previous images of the same area aligning them for easy comparison. These systems will provide an improvement in the quality and precision of the procedures while lowering the burden on the physicians. This paper introduces the Endomapper dataset, the first collection of complete endoscopy sequences acquired during regular medical practice, including slow and careful screening explorations, making secondary use of medical data. Its original purpose is to facilitate the development and evaluation of VSLAM (Visual Simultaneous Localization and Mapping) methods in real endoscopy data. The first release of the dataset is composed of 59 sequences with more than 15 hours of video. It is also the first endoscopic dataset that includes both the computed geometric and photometric endoscope calibration with the original calibration videos. Meta-data and annotations associated to the dataset varies from anatomical landmark and description of the procedure labeling, tools segmentation masks, COLMAP 3D reconstructions, simulated sequences with groundtruth and meta-data related to special cases, such as sequences from the same patient. This information will improve the research in endoscopic VSLAM, as well as other research lines, and create new research lines.
Interactive Inference under Information Constraints
Aug 18, 2020
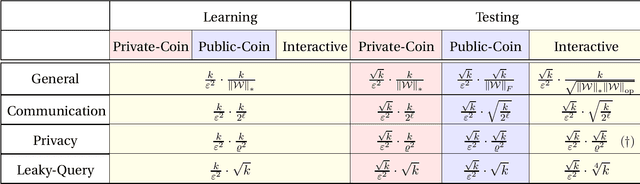
We consider distributed inference using sequentially interactive protocols. We obtain lower bounds on the minimax sample complexity of interactive protocols under local information constraints, a broad family of resource constraints which captures communication constraints, local differential privacy, and noisy binary queries as special cases. We focus on the inference tasks of learning (density estimation) and identity testing (goodness-of-fit) for discrete distributions under total variation distance, and establish general lower bounds that take into account the local constraints modeled as a channel family. Our main technical contribution is an approach to handle the correlation that builds due to interactivity and quantifies how effectively one can exploit this correlation in spite of the local constraints. Using this, we fill gaps in some prior works and characterize the optimal sample complexity of learning and testing discrete distributions under total variation distance, for both communication and local differential privacy constraints. Prior to our work, this was known only for the problem of testing under local privacy constraints (Amin, Joseph, and Mao (2020); Berrett and Butucea (2020)). Our results show that interactivity does not help for learning or testing under these two constraints. Finally, we provide the first instance of a natural family of "leaky query" local constraints under which interactive protocols strictly outperform the noninteractive ones for distribution testing.
Scalable Semi-Modular Inference with Variational Meta-Posteriors
Apr 01, 2022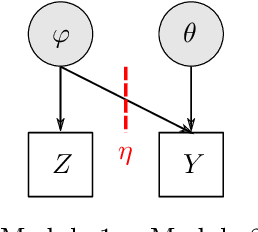
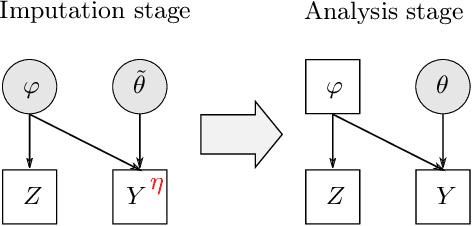
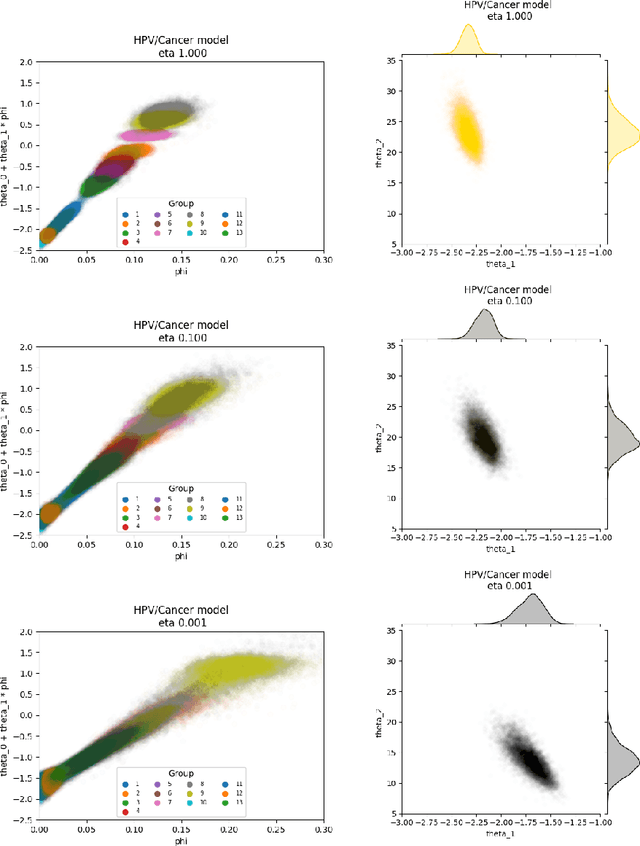
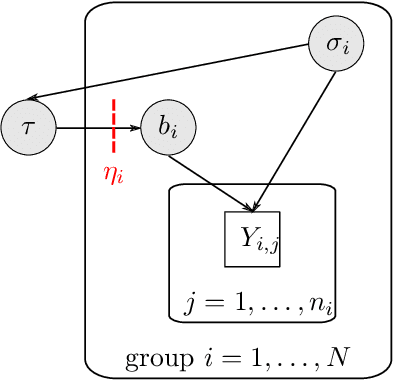
The Cut posterior and related Semi-Modular Inference are Generalised Bayes methods for Modular Bayesian evidence combination. Analysis is broken up over modular sub-models of the joint posterior distribution. Model-misspecification in multi-modular models can be hard to fix by model elaboration alone and the Cut posterior and SMI offer a way round this. Information entering the analysis from misspecified modules is controlled by an influence parameter $\eta$ related to the learning rate. This paper contains two substantial new methods. First, we give variational methods for approximating the Cut and SMI posteriors which are adapted to the inferential goals of evidence combination. We parameterise a family of variational posteriors using a Normalising Flow for accurate approximation and end-to-end training. Secondly, we show that analysis of models with multiple cuts is feasible using a new Variational Meta-Posterior. This approximates a family of SMI posteriors indexed by $\eta$ using a single set of variational parameters.
Online panoptic 3D reconstruction as a Linear Assignment Problem
Apr 01, 2022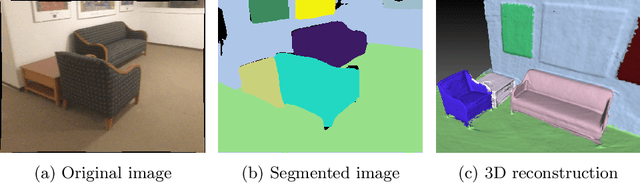
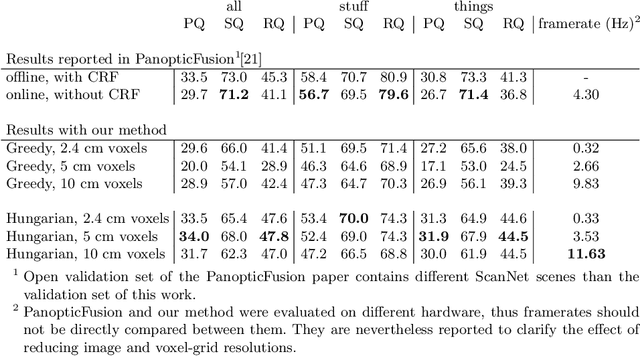

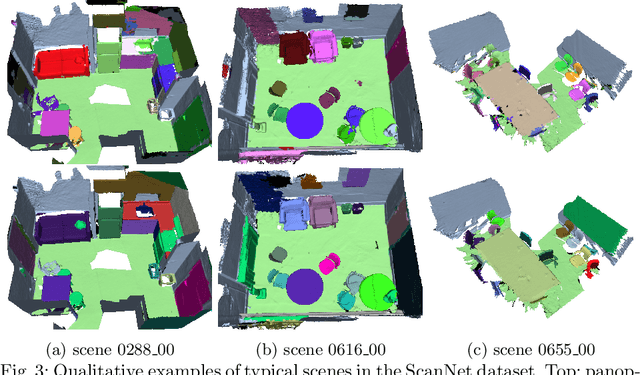
Real-time holistic scene understanding would allow machines to interpret their surrounding in a much more detailed manner than is currently possible. While panoptic image segmentation methods have brought image segmentation closer to this goal, this information has to be described relative to the 3D environment for the machine to be able to utilise it effectively. In this paper, we investigate methods for sequentially reconstructing static environments from panoptic image segmentations in 3D. We specifically target real-time operation: the algorithm must process data strictly online and be able to run at relatively fast frame rates. Additionally, the method should be scalable for environments large enough for practical applications. By applying a simple but powerful data-association algorithm, we outperform earlier similar works when operating purely online. Our method is also capable of reaching frame-rates high enough for real-time applications and is scalable to larger environments as well. Source code and further demonstrations are released to the public at: \url{https://tutvision.github.io/Online-Panoptic-3D/}
Indoor SLAM Using a Foot-mounted IMU and the local Magnetic Field
Mar 29, 2022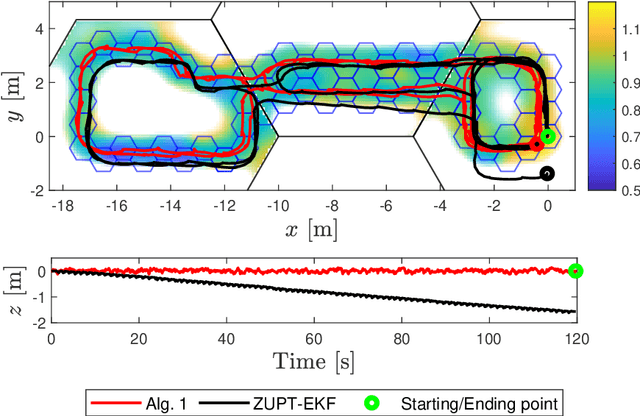
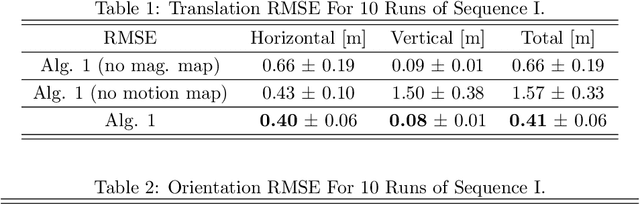

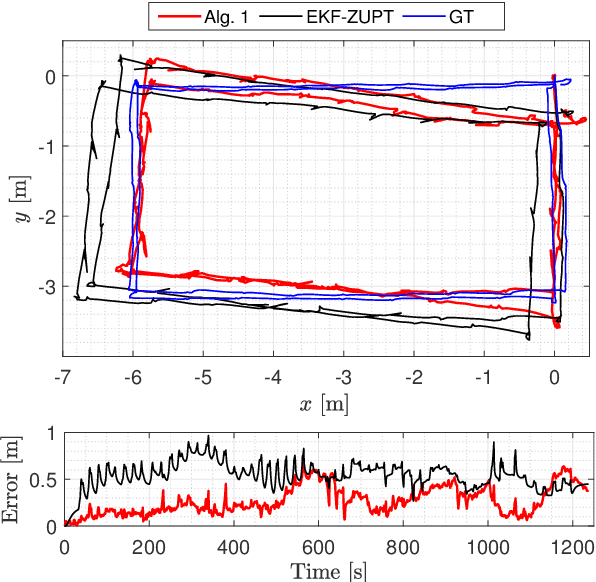
In this paper, a simultaneous localization and mapping (SLAM) algorithm for tracking the motion of a pedestrian with a foot-mounted inertial measurement unit (IMU) is proposed. The algorithm uses two maps, namely, a motion map and a magnetic field map. The motion map captures typical motion patterns of pedestrians in buildings that are constrained by e.g. corridors and doors. The magnetic map models local magnetic field anomalies in the environment using a Gaussian process (GP) model and uses them as position information. These maps are used in a Rao-Blackwellized particle filter (RBPF) to correct the pedestrian position and orientation estimates from the pedestrian dead-reckoning (PDR). The PDR is computed using an extended Kalman filter with zero-velocity updates (ZUPT-EKF). The algorithm is validated using real experimental sequences and the results show the efficacy of the algorithm in localizing pedestrians in indoor environments.
Learning Unbiased Representations via Mutual Information Backpropagation
Mar 13, 2020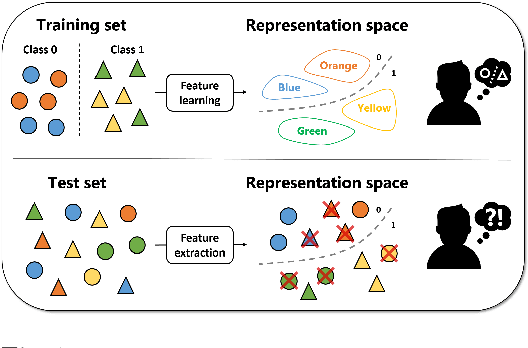
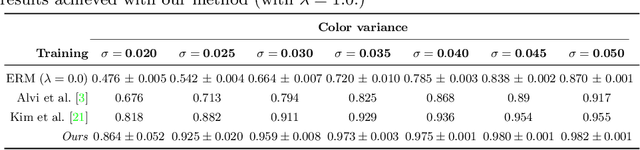
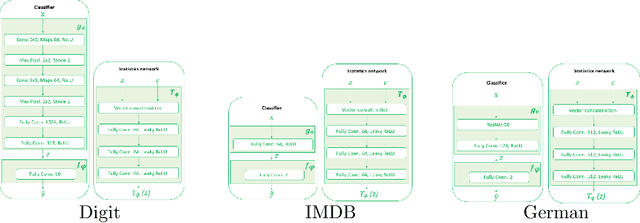
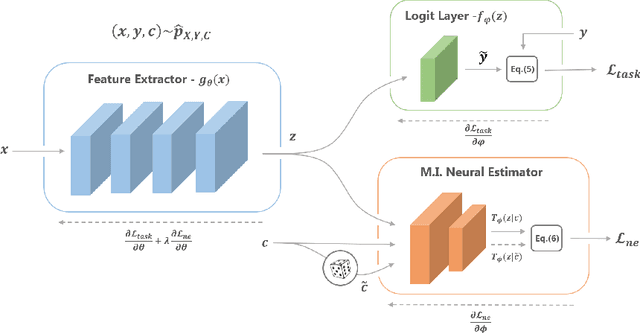
We are interested in learning data-driven representations that can generalize well, even when trained on inherently biased data. In particular, we face the case where some attributes (bias) of the data, if learned by the model, can severely compromise its generalization properties. We tackle this problem through the lens of information theory, leveraging recent findings for a differentiable estimation of mutual information. We propose a novel end-to-end optimization strategy, which simultaneously estimates and minimizes the mutual information between the learned representation and the data attributes. When applied on standard benchmarks, our model shows comparable or superior classification performance with respect to state-of-the-art approaches. Moreover, our method is general enough to be applicable to the problem of ``algorithmic fairness'', with competitive results.